
Abstract
In this paper, a simple but efficient concept of epistemic reliability index (ERI) is introduced for sampling uncertainty in input random variables under conditions where the input variables are independent Gaussian, and samples are unbiased. The increased uncertainty due to the added epistemic uncertainty requires a higher level of target reliability, which is called the conservative reliability index (CRI). In this paper, it is assumed that CRI can additively be decomposed into the aleatory part (the target reliability index) and the epistemic part (the ERI). It is shown theoretically and numerically that ERI remains same for different designs, which is critically important for computational efficiency in reliability-based design optimization. Novel features of the proposed ERI include: (a) it is unnecessary to have a double-loop uncertainty quantification for handling both aleatory and epistemic uncertainty; (b) the effect of two different sources of uncertainty can be separated so that designers can better understand the optimization outcome; and (c) the ERI needs to be calculated once and remains the same throughout the design process. The proposed method is demonstrated with two analytical and one numerical examples.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
In a design problem, which requires a high accuracy and confidence (e.g., aerospace structural design), epistemic uncertainty cannot be ignored because it has been known to have a significant impact on the design (Der Kiureghian and Ditlevsen 2009). Especially, sampling uncertainty, one of epistemic uncertainty, has an impact on the quantification of aleatory uncertainty. For example, the manufacturing variability, one of aleatory uncertainty, is often quantified by several samples. The accuracy of the quantification depends on the number of samples. Since the number of samples is often limited and insufficient, the quantification of variability has an error, which is called sampling uncertainty. Therefore, when the number of samples is limited, it is necessary to consider both aleatory and epistemic uncertainties to obtain a robust design (Cho et al. 2012, 2016). In this paper, we focus on a design problem that has manufacturing variability with sampling uncertainty and propose a new method to handle epistemic uncertainty. Normal distribution is generally applied to the probabilistic model of manufacturing variability and to other models such as measurement error model. When input variables show non-Gaussian distributions, it is possible to transform a non-Gaussian distribution to Gaussian using, for example, Rosenblatt and Nataf transformation. This type of transformation is commonly used in the first-order reliability analysis (FORM) as it is formulated in the space of standard normal random variables. Since the proposed epistemic reliability index approach is based on the FORM, all random variables are transformed to the standard normal random variables, which inevitably induces an error. However, this error in FORM has already been reported and well recognized in the community. Therefore, the accuracy of the proposed method should be understood in the same context.
In general, both aleatory and epistemic uncertainties are considered using double-loop algorithms (Helton and Breedin 1993). The inner loop quantifies the aleatory uncertainty, while the outer loop is for epistemic uncertainty (Park et al. 2014). Using Monte Carlo sampling, for example, the inner loop evaluates the probability of failure for a given realization of epistemic uncertainty. On the other hand, the outer loop calculates the distribution of the probability of failure, from which a conservative estimate can be used for obtaining a reliable design. The conservative estimate provides additional safety by imposing a smaller probability of failure than that of ignoring sampling uncertainty. Such double-loop algorithms are computationally expensive, especially in design optimization, where the process of quantification is repeated at different designs.
In this paper, the conservative estimate of the probability of failure is represented using a conservative reliability index (CRI). From the assumption that the conservative reliability index can be decomposed additively into aleatory and epistemic portions, it is used in reliability-based design optimization (RBDO) considering sampling uncertainty for input variables. A novel contribution of this paper is to show that the epistemic portion of the reliability index remains constant for different designs in this condition. Therefore, only the aleatory portion is reevaluated at every design iteration, which makes the process almost the same as the conventional RBDO without considering epistemic uncertainty.
Due to the new epistemic reliability index (ERI), it is easy to visualize the effect of epistemic uncertainty in the design process. In the conventional study considering epistemic uncertainty (Cho et al. 2012, 2016; Gunawan and Papalambros 2006; Srivastava and Deb 2013), the effects from both uncertainties are melted. However, this paper is the first attempt to separate their effects on optimal solutions. The proposed method divides these effects into the two sources of uncertainty and their effects can be quantified using the new reliability index (see Section 2.3). In practice, this visualization is important because it can help to make a decision whether it is beneficial to reduce the epistemic uncertainty or not.
Designers can recognize the effect of epistemic uncertainty for each limit state function before the optimization process. The evaluation of the new reliability index is required only one time in the entire design process as explained the following section (see Sections 2.1 and 2.4). In the conventional RBDO, this effect can only be found implicitly after performing RBDO. That is, if designers are not satisfied with the RBDO results, they have to try the evaluation RBDO process again with reduced epistemic uncertainty in this case with more number of samples. The proposed method, however, does not require performing RBDO to estimate the effect of epistemic uncertainty. In fact, the proposed method provides an explicit magnitude of additional reliability index due to the epistemic uncertainty from the beginning.
Since the ERI can be calculated explicitly and the two reliability indices are additively decomposed, the proposed method can be applicable to general RBDO problems considering sampling uncertainty of input variables (see Section 2.3). According to many past studies (Aoues and Chateauneuf 2009), many different tools can be used to perform RBDO with the proposed method. In addition, the proposed method makes it easy to compare the results with and without considering epistemic uncertainty (see Section 5).
The paper is organized as follows: Section 2 presents the proposed method of calculating the CRI, and Section 3 discusses the feature of CRI. One important fact that is presented in Section 3 is that the epistemic reliability is independent of design variables under the modeling we set in Section 2. In Section 4, the proposed method is compared with other methods that can handle both aleatory and epistemic uncertainty. Section 5 illustrates the validity of the proposed method through two analytical examples as well as the example of displacement magnifying structure, followed by conclusions in Section 6.
2 Conservative index approach
2.1 Sampling uncertainty modeling
In this study, we consider aleatory and epistemic uncertainty in manufacturing tolerance based on a small number of data. First, to consider aleatory uncertainty, a manufacturing output variable, such as a dimension, x i is regarded as a random variable following a normal distribution, as
where μp(i) and σp(i) are the mean and standard deviation of x i , respectively. The subscript p means that the parameters are for “population”.
However, due to the lack of information, the accurate values of these parameters are unknown. Instead, they are estimated using a limited number of samples. Therefore, the parameters of population distribution have epistemic uncertainty, which is called sampling uncertainty. In statistics, the sampling uncertainty is represented in the form of probability distribution. Therefore, the two parameters, μp(i) and σp(i), are considered random variables and rewritten as \(\hat {\mu }_{\mathrm {p}(i)}\) and \(\hat {\sigma }_{\mathrm {p}(i)}\). Therefore, (1) can be rewritten as
The distribution of the mean \(\hat {\mu }_{\mathrm {p}(i)}\) is estimated as
where d i is the i th design variable and n is the number of samples. The subscript s means that the parameters are for “sample”. σs(i) is the standard deviation of the samples. Additionally, the distribution of the standard deviation \(\hat {\sigma }_{\mathrm {p}(i)}\) is estimated as
where χ(n(i) − 1) is the chi distribution of the degree of freedom n(i) − 1.
2.2 RBDO formulation with aleatory and epistemic uncertainty
When only aleatory uncertainty is considered, the RBDO is formulated as follows:
where \(\boldsymbol {d}=[d_{1}, {\cdots } , d_{n_{d}}]^{T}\) denotes the vector of design variables with n d dimensions and x = [x1,⋯\(,x_{n_{d}}]^{T}\) denotes the vector of random variables. In this paper, it is assumed that x follows a normal distribution, whose mean values are set as design variables d. The function f(⋅) is the objective function to be minimized, and the constraint function g j (⋅) is the j th limit state function. \({\beta _{j}^{T}}\) is the j th target reliability index. \({d_{i}^{L}}\) and \({d_{i}^{U}}\) represent the lower and upper bounds of i th design variable, respectively. This formulation considers only aleatory uncertainty, where a single value of the probability of failure exists for a given design.
When epistemic uncertainty is considered in addition to aleatory uncertainty, the probability of failure is not a deterministic value although the design variables are fixed. As shown in Fig. 1, a number of samples can first be generated from the distribution of parameters to evaluate the distribution of the probability of failure. This part corresponds to the outer-loop for epistemic uncertainty. Then, for each pair of parameter samples, the distribution of x(i) can be defined, from which the probability of failure can be calculated. This part is the inner-loop for aleatory uncertainty. Since there are many samples of probability of failure, they can be used to determine a conservative probability of failure using a confidence level. Therefore, when there is epistemic uncertainty, the conventional RBDO is modified to a confidence-based RBDO as
where \(P_{f(j)}^{\alpha }\) represents the α percentile of the probability of failure. This means that the result has the reliability with the α percentage confidence level.

Distribution of probability of failure
Uncertainty in input variables leads to conservative design to satisfy reliability requirements. Since it is well known that the epistemic uncertainty is reducible but aleatory uncertainty is not, it is important to understand the contribution of these two sources of uncertainty to the conservatism in the design. If the epistemic uncertainty leads to too conservative design, designers may want to reduce it instead of compensate for it. In the case of sampling uncertainty, increasing the number of samples, n, can reduce the epistemic uncertainty, as shown in (3) and (4). The conservative probability of failure \(P_{f(j)}^{\alpha }\) in (6) includes the contribution from both aleatory and epistemic uncertainty. However, it is not straightforward to identify the contribution of individual uncertainty from the formulation in (6) and the method of evaluating the conservative probability of failure shown in Fig. 1. In the following subsection, a method of separating the contribution of epistemic uncertainty from that of aleatory uncertainty is presented in terms of the reliability index.
2.3 Conservative Reliability Index (CRI) and Epistemic Reliability Index (ERI)
Let dopt be the optimal solution of (5). In RBDO, the reliability index is often used instead of the probability of failure. The reliability index is evaluated in the U-space of standard normal random variable, where the input random variable, x i , is converted into u i in the U-space as
The limit state function g j (x) in (5) is also converted in the U-space by replacing x i with u i using the relationship in (7). In the following derivations, we use the same functional form for the limit state function in the U-space; i.e., g j (u).
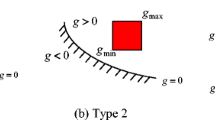
The most probable point (MPP) is defined as the nearest point from the origin to the limit state surface, g j (u) = 0. The distance from the origin to the MPP in the U-space is equal to the j th reliability index \({\beta ^{T}_{j}}\) when the limit state is active as shown in Fig. 2. This figure shows that the limit state function is varied due to epistemic uncertainty for example, g∘(u) and g×(u). Therefore, the nearest point from the origin (MPP) is also varied and as a result, the reliability index is distributed as this figure.

Distribution of reliability index due to epistemic uncertainty
It is noted that the target reliability index can be approximated by a mean value of this distribution of reliability index because \(E[\hat {\mu }_{\mathrm {p}(i)}]=d_{i}^{\text {opt}}\) and \(E[\hat {\sigma }_{\mathrm {p}(i)}]=\sigma _{\mathrm {s}(i)}\) are introduced by (3) and (4). Since we consider a conservative estimate of reliability, the confidence level of the reliability index P[β ≥ βT] can be used as a reliability constraint.
With epistemic uncertainty, the RBDO formula in (5) can be rewritten as
This formulation simply replaces the reliability index from βT to β∗, and β∗ is larger than βT due to additional epistemic uncertainty. That is, in order to be conservative under epistemic uncertainty, a higher value of the reliability index is required than the case without epistemic uncertainty. The distribution of the reliability index evaluated in (8) is compared with that of the reliability index in (5) in Fig. 3. Based on the approximation that \(E[\hat {\mu }_{\mathrm {p}(i)}]=d_{i}^{\text {opt}}\) and \(E[\hat {\sigma }_{\mathrm {p}(i)}]=\sigma _{\mathrm {s}(i)}\), the mean of the distribution of the reliability index corresponds to βT approximately. It means that about 50% of reliability indices failed to satisfy the reliability constraint. It will be shown in Section 3 that the distribution shape of reliability index is independent of design. Therefore, in the RBDO formulation in (8) with epistemic uncertainty shifts the mean of this distribution from βT to β∗ while keeping its shape. By designing with β∗, the target reliability index βT becomes a conservative one. If the confidence level P[β ≥ βT] satisfies the desired confidence level α%, this optimal result also satisfies the conservative based RBDO conditions.

Shifted reliability index distribution due to conservative target reliability index
In this paper, β∗ is called “Conservative Reliability Index (CRI)”. Additionally, the shifted value, which is due to the epistemic uncertainty, is called “Epistemic Reliability Index (ERI)”. It is defined as
Therefore, the formulation considering aleatory and epistemic uncertainty can be described as (8).
This formulation can be solved in the same way as the traditional RBDO once the CRI (\(\beta _{j}^{*}\)) is obtained. In the following section, the procedure to evaluate CRI and ERI will be described.
2.4 Algorithm of estimating CRI and ERI
In this section, we describe how to estimate the CRI and ERI step by step. Since the distribution of the reliability index is difficult to evaluate mathematically, a numerical method is adopted. This reason will be referred in Section 3.1. The key concept of the proposed method is that for a fixed MPTP (Maximum Performance Target Point (Tu et al. 1999)) x∗ in the design space, the distribution of corresponding u∗ can be found based on the distribution of epistemic uncertainty. The distribution of reliability index can be calculated from that of u∗. In this section, we briefly describe procedures for each step and a flow of evaluating CRI and ERI will be followed.
2.4.1 (Step 0) initialization
First, design variable d and CRI for each limit state function \(\boldsymbol {\beta }_{j}^{*}\) are set as d(0) and \(\boldsymbol {\beta }_{j}^{T}\), respectively. Then, samples for input design variables are prepared and their sample standard deviations are evaluated. And the values of d is fixed on the initial design variables d(0) on each evaluating CRI iteration. For simplicity, we will describe is as d.
2.4.2 (Step 1) MCS sampling for the distribution parameters
In this step, samples of the distribution parameters, mean value \(\hat {\mu }_{\mathrm {p}(i)}\) and standard deviation \(\hat {\sigma }_{\mathrm {p}(i)}\), are generated to make the distribution of the reliability index numerically. As we mentioned above section, these values follow certain distributions as in (3) and (4). Then, the samples of the distribution parameters can be obtained. The number of the samples is set as n k for each variable.
2.4.3 (Step 2) MPTP search in Z-space
In order to find MPTP, we introduce Z-space that is based on the initial design point as
Then, the MPTP of each limit state function can be obtained in Z-space by solving the following optimization problem:
The optimum point z∗ satisfies the condition that the mean of reliability index is approximately equal to CRI, β∗ as shown in Fig. 4. The MPTP z∗ in Z-space can then be converted into the design space to obtain x∗ using the relationship in (10). Note that since the MPTP is found using the sample mean and standard deviation, it is approximately the mean of the reliability index distribution due to epistemic uncertainty.

MPTP search in Z-space
2.4.4 (Step 3) evaluating normalized MPTPs for each sample
Once MPTP is found, the next step is to generate the samples of reliability index based on sampling uncertainty. First, n k numbers of sample sets of distribution parameters are generated by (3) and (4) for each random variable. Here, the k th sample set is denoted as \((\boldsymbol {\mu }_{\text {MCS}}^{(k)}, \boldsymbol {\sigma }_{\text {MCS}}^{(k)})\). For a given sample set of distribution parameters, the MPTP point x∗ can be converted into the standard normal space as
Since we have n k sample sets of distribution parameters, the above equation yields n k numbers of normalized MPTP u∗(k)(k = 1,⋯ ,n k ).
2.4.5 (Step 4) evaluating the distribution of the reliability index and updating CRI value
Following the general reliability analysis of FORM (Choi et al. 2007), each reliability index evaluated at each normalized MPTP can be introduced as
Then, the distribution of reliability index is evaluated using n k numbers of the reliability index samples. Using these samples, we can evaluate the α percentile of the reliability index, β(α). Figure 5 illustrates the process of evaluating the distribution of reliability index.

Evaluating the distribution of the reliability index
If β(α) is equal to the target reliability index βT, the value of β∗ can be regarded as the CRI. If not, the value of β∗ is updated as
where Δβ = βT − β(α). \(\beta ^{*}_{\text {new}}\) and \(\beta ^{*}_{\text {old}}\) are represented as the updated CRI value and the old CRI value, respectively. This update is repeated until converged; that is, until Δβ = 0.
Finally, the flowchart of estimating CRI and thus ERI is shown in Fig. 6.

Procedure of evaluating CRI
3 Features of CRI
In this section, the feature of the CRI and the ERI will be discussed. An important property that will be shown in this section is that the CRI and thus ERI is independent on the design variable values. Therefore, designers need to evaluate these indices only once. Here, we present two proofs in the viewpoint of mathematical and numerical approaches.
3.1 Mathematical approach
We consider epistemic uncertainty as shown in Section 2.1, and then, introduce Z-space to find the normalized MPTP. Using the following relationship between \(\hat {z}_{i}\) and \(\hat {x}_{i}\):
we can find the mean and standard deviation of \(\hat {z}_{i}\) as
In the Z-space, the MPTP is searched by solving the optimization problem in (11). The deterministic value z∗ of MPTP in the Z-space can be converted into the design space as
Since the reliability index is generally defined in the U-space, the MPTP x∗ is further converted into the U-space as
Note that even if \(x_{i}^{*}\) is deterministic, \(\hat {u}_{i}^{*}\) is random due to the epistemic uncertainty, which is represented in \(\hat {\mu }_{\mathrm {p}(i)} \) and \(\hat {\sigma }_{\mathrm {p}(i)}\). Then, we can obtain the random reliability index in U-space as the norm of \(\hat {\boldsymbol {u}}^{*}\). That is,
Once we have the distribution of \(\hat {\beta }^{2}\), we can also evaluate the α percentile of reliability index.
Using (18), we can obtain the following relationship for \(\hat {u}_{i}^{*2}\):
Here, to simplify the expression, \(\hat {v}_{i}\) is introduced as
Then,
Note that \(\hat {\sigma }_{z(i)}\) is independent on the index of design variables because it is normalized by design variables. We can introduce the expression of the squared reliability index distribution using (19) and (22) as
Knowing that z∗ satisfies the condition in (11), individual terms in (23) can be expressed as
where \({\sum }_{i = 1}^{n_{d}}z_{i}^{*2}=\beta ^{*2}\). Using the above terms, (23) can be simplified as
where
F and Inv-χ2 are the F distribution and the inverse chi square distribution, respectively.
As shown in (26), it is difficult to handle the squared reliability index distribution. However, this distribution is the independent of the design variables. Rather, it depends on the number of samples and \(\hat {\sigma }_{z(i)}\). That is, the uncertainty in \(\hat {\beta }^{*}\) will be the same at different designs. Since the CRI depends on the uncertainty in \(\hat {\beta }^{*}\), it is independent of design variables. This property is particularly important in the RBDO process because the ERI needs to be evaluated only once. In the next section, we will show the validation of this property using numerical approach.
3.2 Numerical approach
In this section, the following limit-state functions (Youn and Choi 2004) are considered to validate the feature of the CRI and ERI.
For the demonstration purpose, the target reliability index is set to 3.0 for each limit state function. The objective of this section is to show that the ERI is independent of design variable values.
As described in Section 2.4, the evaluation of the ERI requires the number of input samples and the standard deviations of samples. In order to demonstrate epistemic uncertainty, 10 sample sets of design variables x are generated based on the distribution parameters given in Table 1.
In order to show that the ERI is independent of design variables, the ERIs are evaluated at sixteen grid points in the design space as shown Fig. 7. The ERIs on these 16 points of design variable are evaluated for each limit state function.

Grids of the design variable points
The results for each limit state function are shown in Figs. 8, 9 and 10, respectively. The values written in each figure are the ERI values for each design variable. As shown in the three figures, the ERI values are almost same at different designs, which is consistent to the theoretical proof in the previous section. The mean value and the standard deviation are summarized in Table 2. Since the standard deviation is two orders of magnitude smaller than the mean value of the ERI, it can be said that the ERI is constant. The small differences are caused by the convergence tolerance during optimization in (11) and sampling uncertainty in determining β(α). Although the reliability index is defined as the distance between the design point and the limit-state function, the ERI is independent of the distance from the limit-state function.

ERI value of g1

ERI value of g2

ERI value of g3
These results provide an illustration of the fact that the ERI is independent on the design variable values. Therefore, the CRI and the ERI are evaluated only one time before solving the RBDO problem. Therefore, the computational cost is one-time cost of evaluating ERI based on the initial design.
4 Related research and comparison
In this section, related researches which address to handle aleatory uncertainty and epistemic uncertainty in optimal design process are shown and compared with our study.
Gunawan and Papalambros (2006) proposed a method for considering the uncertainties using insufficient information. It is noted that this study adopts a multi-objective optimization, which considers a trade-off relationship between the objective value and the confidence level. Additionally, they estimate the reliability distribution using a Bayesian binomial inference technique and beta distribution. Srivastava and Deb (2013) applied an evolutionary algorithm for searching the trade-off Pareto frontier. These studies guaranteed to show the relationship using multi-objective optimization method and approximate the reliability distribution. On the other hand, Cho et al. (2012) and Cho et al. (2016) proposed a new method to estimate the reliability distribution based on sampling. This method addressed directly to evaluate the reliability distribution. Although it takes too much cost due to iterated sampling, they showed this method can deal with even non-normal distribution type. It might guarantee industrial problems, which have insufficient information of the type of distributions.
These past studies are compared with our study in Table 3. On the view of the RBDO formulation, our proposed method has an advantage to perform the optimization problem compared with multi-objective and confidence-based formulation. However, multi-objective formulation can show the relationship between the objective value and the confidence level. That aids designers to know how effective both aleatory and epistemic uncertainty are. It is noted that their effect is not divided. To consider epistemic uncertainty in RBDO, the past studies adopt the distribution of probability of failure, while our study adopts that of reliability index. Then, these distributions are evaluated by sampling or Bayesian binomial inference. Sampling method is easy to obtain accurate distributions, in contrast, Bayesian method is easy to approach because it is assumed as beta distribution. The most important feature is that our proposed method requires only one time to evaluate the distribution although the past studies require several times which is proportional to the number of iteration in RBDO process.
5 Numerical examples
5.1 Linear function model
At first, the following linear RBDO problem is considered.
where the confidence level α = 90% and the target reliability index \({\beta _{j}^{T}}= 3.0, \ (j = 1, 2)\). Since this problem is composed of linear functions for both objective and constraints, and since all input random variables are normally distributed, the calculated reliability index using FORM should be accurate. For epistemic uncertainty, n = 10 sample sets of design variables are generated according to the distribution described in Table 4.
The CRI and the ERI values are obtained using n k = 1000 epistemic samples, as shown in Table 5. These values are evaluated by the procedure mentioned in Section 2.4.
Next, the RBDO problem is performed with and without ERI. In this example, PMA (Performance Measure Approach (Tu et al. 1999)) is adopted. The conventional RBDO without epistemic uncertainty corresponds to an optimal solution with βe = 0, which means it considers only aleatory uncertainty. Additionally, the original RBDO problem is performed using the population distributions of the random variables in Table 4. These results are summarized in Table 6 and the optimal points are shown in Fig. 11. As shown in Table 6, the result using only aleatory uncertainty is also different from that of original RBDO due to sampling error. In fact, the results using only aleatory uncertainty and proposed method fail to satisfy the reliability constraint, however, the proposed method yields more conservative reliability result. As shown in the table and figure, the optimum design with epistemic uncertainty is moved further to the feasible domain from the optimal design only aleatory uncertainty. Based on Table 4, the uncertainty in x2 is three times larger than that of x1. Between the two limit state functions in (28), g1 is proportional to − 3x2, while g2 is to − x2. Therefore, it is obvious that g1 is more sensitive to the epistemic uncertainty. As shown in Table 5, since the effect of epistemic uncertainty on g1 is larger than that of g2, the optimal design moves away further from g1 than g2.

Optimal solution comparing with and without epistemic uncertainty in example1
Finally, to validate this result, Monte Carlo sampling (MCS) is performed. For epistemic uncertainty, 1000 sample sets of distribution parameters are generated by (3) and (4) for each random variable at optimal design. The histograms of the reliability index are evaluated for each limit state function and shown in Fig. 12. The figure shows that the 90 percentile of reliability index almost satisfies the target reliability index (βT = 3.0) for each limit state function.

Validation of the optimal result considering epistemic uncertainty in example 1: histograms of reliability index using MCS sampling
5.2 Nonlinear function model
As the second example, the following nonlinear RBDO problem is considered.
where α = 90% and \({\beta _{j}^{T}}\,=\,3.0 \quad (j\,=\,1,2, 3)\). This problem is composed of nonlinear objective function and the three limit state functions that were studied in Section 3. The same distribution parameters and samples shown in Table 1 are used.
The CRI and the ERI are obtained using n k = 1000 epistemic samples, whose results are shown in Table 7. Similar to the previous example, this table shows that the epistemic uncertainty effect of g1 is largest, because the ERI of g1 is largest in all of these limit state functions.
In the same way as with the previous example, the RBDO problem is solved using the PMA. The optimal solution with βe = 0 and the original RBDO problem using the population distributions are also evaluated to compare with the proposed method with epistemic uncertainty. These results are summarized in Table 8, and the optimal points are shown in Fig. 13. As shown in Table 8, the result using only aleatory uncertainty is also different from that of original RBDO in example 1. In fact, the result using only aleatory uncertainty fails to satisfy the reliability constraint (β = 2.48), while the proposed method yields a conservative reliability result (β = 3.22). In this example, since the constraint functions g2 and g3 are not active, the optimal design is moved away from g1.

Optimal solution comparing with and without epistemic uncertainty in example 2
The level of conservativeness is evaluated using MCS with 1000 samples, the same procedure explained in the previous example. Since the constraint functions g2 and g3 are not active, only g1 is investigated. Figure 14 shows the histogram of reliability index of g1. The figure shows that the 90 percentile of reliability index satisfies the target reliability index (βT = 3.0).

Validation of the optimal result considering epistemic uncertainty in example 2: histograms of reliability index using MCS sampling
5.3 Displacement Magnifying Structure (DMS) design
In this section, the proposed method is applied to “Displacement Magnifying Structure (DMS)” design problem (Kogiso et al. 2017). To obtain an accurate design, the manufacturing tolerance is evaluated by measuring the dimensions from three prototypes. Since the number of samples are small, it is necessary to consider epistemic uncertainty.
The geometry of the DMS is shown in Fig. 15. This problem has eight design variables, which are the important dimensions for the performance of the DMS. These design variables are independently chosen by sensitivity analysis in the past study (Kogiso et al. 2017). The lower and upper limits of the design variables are shown in Table 9.

Displacement magnifying structure
The function of DMS is to magnify the input forced displacement (A in Fig. 15) and generate the tip displacement (B in Fig. 15). In this case, the input displacement is 0.08mm, which is determined by the ability of the piezoelectric actuator and the output displacement is required over 1mm. Then, this problem can be formulated as the following maximization of the tip displacement problem.
where α = 90 and \({\beta _{j}^{T}}= 3.0 \quad (j = 1, 2)\). The RBDO problem has two constraints. One for the maximum stress and the other for the lowest natural frequency.
To evaluate the manufacturing error, we built 3 copies of the DMS and measured their dimensions using 3D measurement device, whose results are shown in Table 10. Even if the DMS was initially designed as symmetric, the measured dimensions were not symmetric due to the manufacturing error. In the table, “left” and “right” are left side and right side of the DMS design variables, respectively, and “original” means the initial design values which we set before building them. As a result, we have six samples of each design variable, whose statistical properties are shown in Table 11.
When input variables show non-Gaussian distributions, it is possible to transform a non-Gaussian distribution to Gaussian using, for example, Rosenblatt and Nataf transformation. This type of transformation is commonly used in the FORM as it is formulated in the space of standard normal random variables. Since the proposed epistemic reliability index approach is based on the FORM, all random variables are transformed to the standard normal random variables, which inevitably induces an error. However, this error in FORM has already been reported and well recognized in the community. Therefore, the accuracy of the proposed method should be understood in the same context.
When dimensional tolerances are considered as a random variable, it is common that the distribution might be truncated because of the quality control process. If a truncated normal distribution is modeled as a regular normal distribution, there will be an error in the approximation. In the case of 2-sided truncation with ± 2σ, the error in the standard deviation would be 12%. If the truncation occurs at ± 3σ, the error is reduced to 1%. In addition, the regular normal distribution is always conservative compared to the truncated one. To show this fact, we carry out a reliability analysis of maximum stress (g1). The design variables d are set as the deterministic optimal solution which is indicated as “original” in Table 10. The truncated value is set as 2 sigma. The obtained results by Monte Carlo simulation with 107 samples are compared between the untruncated and truncated distributions in Fig. 16. The probability of failure of using normal distribution is 5.68% and that of using truncated normal distribution is 3.49%. This result indicates reliability analysis using regular normal distribution provides more conservative result than that of using truncated one. Therefore, the proposed method can still provide a conservative estimate of the reliability.

Result of reliability analysis comparing truncated and untruncated normal distribution
For the two constraints, the CRI and the ERI values are obtained with n k = 1000 samples, whose results are shown in Table 12. The table shows that the epistemic uncertainty effect of the lowest frequency is larger than that of the maximum stress.
Then, the RBDO problem is performed. In this problem, a computationally efficient optimization method is required, because the physical analysis requires costly computational time. This study adopts a Kriging model to construct surrogates for the objective function and the constraint functions. The details of the optimization framework using the Kriging model are described in Appendix. Here, to compare with and without considering aleatory and epistemic uncertainties, the deterministic optimization and the RBDO considering only aleatory uncertainty are also performed. The optimum results of design variables for all three cases are shown in Table 13, and the configuration of the DMS obtained by proposed method is shown in Fig. 17. As shown in this table, “only aleatory” and “proposed” can be regarded as almost same design.

Optimal configuration of the DMS (proposed method)
Next, the values of objective and constraints at the optimum designs are compared in Table 14. Once the optimum designs are obtained using the Kriging surrogate model, the function values are re-evaluated using finite element simulation. As shown in this table, the tip displacement decreases as we consider uncertainties and the values of constraint functions become conservative. That means it is required to take some margins to avoid the effect of these uncertainty. Note that even if the difference in the optimal designs between with and without considered epistemic uncertainty is small in Table 13, the difference in objective and constraints is relatively large in Table 14. This means that the DMS is sensitive to small change in design, which is why it is necessary to consider not only aleatory but also epistemic uncertainty.
Finally, Fig. 18 shows the compared results of normalized margin of each constraint function between “only aleatory” and “proposed” results. The difference of each value between two optimal results (the red arrow) indicates the effect of epistemic uncertainty on each condition. The difference is larger for the first frequency than that of the maximum stress. It can be concluded that the effect of epistemic uncertainty on the first frequency has more impact than that of the maximum stress. We can naturally agree with this fact because the ERI results in Table 12 indicated it.

Comparison of normalized margin of constraint function
6 Conclusions
In this paper, two new reliability indices are introduced for handling sampling uncertainty under conditions where the input variables follow normal distribution and samples are unbiased. The epistemic reliability index (ERI) is for expressing the effect of epistemic uncertainty, and the conservative reliability index (CRI) is the combination of the target reliability index with ERI. By optimizing with CRI, the effect of aleatory and epistemic uncertainty can be considered simultaneously. Based on our literature review, this paper is the first time to explain the effect of epistemic uncertainty using a similar concept of the reliability index. Additionally, three examples are considered as the case of random input variables, however, our concept can also be applied in the case of uncontrollable random parameters because the uncertainty of random parameters are estimated through samples. The most important contribution of the paper is to show that the ERI remains same for different designs, and thus, it needs to be calculated once, which makes the reliability-based design optimization almost the same as the conventional method with aleatory uncertainty only.
Compared to conventional double-loop methods, the proposed method has some advantages. The first is that the proposed method allows to separate the effect of aleatory and epistemic uncertainty under our modeling of sampling uncertainty. Therefore, when the optimal design is not satisfactory, designers can make a decision on either reducing aleatory uncertainty or epistemic uncertainty. The former can be achieved by tightening the manufacturing tolerance, while the latter can be done by making more samples. The second advantage is that the computational cost of the proposed method is almost the same as the conventional RBDO with aleatory uncertainty only. This was possible because the ERI remains same for different designs, which was proved theoretically and numerically under our conditions.
One of the most important future works is an investigation whether the proposed method works for non-Gaussian input distribution. After that, this method will be applied to more complicated design problem, such as heat conditions in the space, which is difficult to test and simulate on ground. In addition to sampling uncertainty, this may involve epistemic uncertainty due to modeling error. The proposed CRI and ERI may or may not be applicable for model-form uncertainty. If the concept of CRI and ERI does not work for model-form uncertainty, then a new index might be required. This work will enhance to obtain an accurate design under aleatory, epistemic and modeling uncertainty and develop integrated method of handling these uncertainties.
References
Aoues Y, Chateauneuf A (2009) Benchmark study of numerical methods for reliability-based design optimization. Struct Multidiscip Optim 41(2):277–294. https://doi.org/10.1007/s00158-009-0412-2
Cho H, Choi KK, Lee I, Gorsich D (2012) Confidence level estimation and design sensitivity analysis for confidence-based RBDO. Proc. of ASME 2012 IDETC and CIEC, DETC2012–70725. https://doi.org/10.1115/DETC2012-70725
Cho H, Choi KK, Gaul NJ, Lee I, Lamb D, Gorsich D (2016) Conservative reliability-based design optimization method with insufficient input data. Struct Multidiscip Optim 54(6):1609–1630. https://doi.org/10.1007/s00158-016-1492-4
Choi SK, Canfield RA, Grandhi RV (2007) Reliability-based structural design. Springer, Berlin
Der Kiureghian A, Ditlevsen O (2009) Aleatory or epistemic? Does it matter?. Struct Saf 31(2):105–112. https://doi.org/10.1016/j.strusafe.2008.06.020
Du X, Chen W (2004) Sequential optimization and reliability assessment method for efficient probabilistic design. J Mech Des 126(2):225–233. https://doi.org/10.1115/1.1649968
Gunawan S, Papalambros PY (2006) A Bayesian approach to reliability-based optimization with incomplete information. J Mech Des 128(4):909–918. https://doi.org/10.1115/1.2204969
Helton JC, Breedin RJ (1993) Calculation of reactor accident safety goals. Reliab Eng Syst Saf 39(2):129–158. https://doi.org/10.1016/0951-8320(93)90038-Z
Hill JR, Wang KW, Fang H, Quijano U (2011) Actuator grouping optimization on flexible space reflectors. Proc SPIE 7977:797725. https://doi.org/10.1117/12.880086
Kogiso N, Furutani N, Naka T, Kimura K, Tanaka H, Iwasa T (2017) Optimum structural design for high-precision space smart reflector. In: Proceedings 12th World Congress of Structural and Multidisciplinary Optimization, p 261
Matheron G (1963) Principles of geostatistics. Econ Geol 58(8):1246–1266. https://doi.org/10.2113/gsecongeo.58.8.1246
Park CY, Kim NH, Haftka RT (2014) How coupon and element tests reduce conservativeness in element failure prediction. Reliab Eng Syst Saf 123:123–136. https://doi.org/10.1016/j.ress.2013.10.012
Srivastava R, Deb K (2013) An evolutionary based Bayesian design optimization approach under incomplete information reliability based design optimization for complete information. Eng Opt 45(2):141–165. https://doi.org/10.1080/0305215X.2012.661730
Tanaka H, Sakamoto H, Inagaki A, Ishimura K, Doi A, Kono Y, Oyama T, Watanabe K, Oikawa Y, Kuratomi T (2016) Development of a smart reconfigurable reflector prototype for an extremely high-frequency antenna. J Intell Mater Syst Struct 27(6):764–773. https://doi.org/10.1177/1045389X15580660
Tu J, Choi KK, Park YH (1999) A new study on reliability-based design optimization. J Mech Des 121 (4):557–564. https://doi.org/10.1115/1.2829499
Youn BD, Choi KK (2004) Selecting probabilistic approaches for reliability-based design optimization. AIAA J 42(1):1–8. https://doi.org/10.2514/1.9036
Acknowledgements
This study is partially supported by JSPS KAKENHI (Grants-in-Aid for Scientific Research) 16K13738.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A: Displacement Magnifying Structure (DMS)
To realize high accuracy and larger antenna system which is required by radio astronomy observation over 100GHz, an antenna system equipped with the smart reconfigurable sub-reflector has been developed (Hill et al. 2011). In the past study of our project, the conceptual figure of this system is shown in Fig. 19. As shown in this figure, the smart reconfigurable sub-reflector corrects the path length error due to the surface deformations.

Smart reflector system (Tanaka et al. 2016)
In the past study of our project, a reconfigurable reflector BBM (breadboard model) is built as shown in Fig. 20. This BBM is composed of the sub-reflector, displacement magnifying structure (DMS) and the piezoelectric actuator. The tip displacement of DMS is required over 1mm although the actuator generates forced displacement less than 0.08mm in order to control the sub-reflector shape. Then, DMS works to magnify the displacement generated by the actuator to over 1 mm. Additionally, DMS is designed as a kind of compliant mechanism. That’s because this improves the reliability by reducing the number of small fastening portions that causes the backlash or friction.

BBM (breadboard model) of a reconfigurable reflector in the past study (Kogiso et al. 2017)
Appendix B: Optimization framework using the Kriging model for DMS design
In this part, the DMS design procedure is described. Considering costs to evaluate its function values, Kriging (Matheron 1963) is adopt to approximate these functions. Kriging is a well-known surrogate technique that is often adopt to approximate computationally expensive functions. Since there are many study about Kriging, details of its technics are skipped.
In this study, first, a deterministic optimization result was already obtained using PSO (Kogiso et al. 2017). An optimal result in (29) can be assumed to place near the deterministic design. Then, we focus on a region near the deterministic result and construct surrogate functions in this region as shown in Fig. 21. The number of design of experiment is 1000 and the correlation model of Kriging is gauss model. The procedure of DMS design is summarized as follows:
- (DMS-Step 1):
-
Sampling points (design of experiment) are generated by the Latin hypercube design (LHD) in the limited region as Fig. 21.
- (DMS-Step 2):
-
Kriging models are constructed in the region. The correlation model is set as the gauss model.
- (DMS-Step 3):
-
RBDO formulated in (29) is performed (use sequential optimization and reliability assessment method (SORA (Du and Chen 2004)) considering costs).

Conceptual figure of the region constructing surrogate models
Additionally, the accuracy of this Kriging model is discussed. Random 50 test points in limited region as shown in Fig. 20 are generated and the values of both numerical simulation and response surface of this Kriging model are evaluated. As an example, accuracy of the objective function is shown in Fig. 22. And the mean of error between the numerical simulation and the response surface is about 0.34%. These results show that the accuracy of this meta-model is small enough in calculating reliability.

Accuracy of the response surface of objective function
Appendix C: Discussion of important factors of ERIx
In this appendix, we discuss what factors effect on ERI values. Since ERI (or CRI) is induced by the distribution of the reliability index, (26) indicates that the important factors are the number of design variables n d and the number of samples n(i). Additionally, it may depend on the limit state function because the limit state function is used when the reliability index is evaluated.
Now, we focus on the effect of the number of samples on ERI values. The relationship between ERI and the number of samples are numerically investigated using numerical example in Section 5.1. In this investigation, the number of samples are set as 5, 10(original), 25, 50, 100 and 500. The result is shown in Fig. 23. It shows that ERI gets smaller as the number of samples increases. This fact clearly indicates getting large number of samples can reduce the epistemic uncertainty caused by the insufficient number of input data.

Relationship between the number of samples and ERI
Rights and permissions
About this article

Cite this article
Ito, M., Kim, N.H. & Kogiso, N. Conservative reliability index for epistemic uncertainty in reliability-based design optimization. Struct Multidisc Optim 57, 1919–1935 (2018). https://doi.org/10.1007/s00158-018-1903-9
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00158-018-1903-9