
Abstract
Anchored neighborhood regression (ANR) single-image super-resolution (SISR) method demonstrates great superiority in speed and performance. However, ridge regression adopted by ANR didn’t take the prior knowledge of regression parameters into account, which easily leads to over-fitting and is not robust to noise. To mitigate this problem, a Bayesian ANR method is proposed for SISR, called B-ANR. B-ANR uses sparse Bayesian regression model to build the mapping relationship between the low resolution (LR) image patch and its neighbors. The parameters of Bayesian regression model as well as its variance are estimated using maximum a posterior. Since our proposed B-ANR is deduced in the probabilistic framework, it has stronger generalization performance and robustness to noise. Experimental results verify that our method is superior to ANR in performance.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The primary purpose of single image super-resolution (SISR) is to restore a high-resolution (HR) image from a single low-resolution (LR) image. Since HR image contain abundant high-frequency detailed information, it can facilitate many computervision tasks. Image SR techniques has been extensively adopted to enhance the image’s resolution to overcome the limitation of low-quality imaging devices [24, 27, 29]. For example, the LR images such as positron emission tomography (PET) images [16], magnetic resonance images (MRI) [3], can be reconstructed using image SR technique to improve its resolution, leading to an improved diagnosis accuracy.
Due to it’s ill-posed characteristic, image SR still remains a challenging problem. Over the past few decades, many researchers have conducted extensive studies on SR and a large amount of methods have been proposed in the literature. These approaches can be categorized into two broad categories, interpolation-based SR methods and learning-based SR methods.
Interpolation-based SR methods [15, 20, 23, 35] use different interpolation approaches, such as nearest neighbor interpolation, bilinear and bicubic interpolation, to approximate the unknown pixels in the HR grid. Interpolation-based methods are difficult to recover lost high-frequency details due to their low-pass filtering characteristics, resulting in excessively smooth HR images. Even more, jagged artifacts tend to arise at the edges of the reconstructed HR image.
Freeman et al. [11] believed that it is possible to recover lost details in the LR image by learning from an external training set and proposed an example-based SR method. The basic idea of example-based SR method is to establish a mapping relationship between HR and LR image patches. Following Freeman’s idea, many learning-based SR methods had been proposed, which can be divided into three categories: neighborhood embedding (NE) based methods, sparse coding based methods and regression-based methods. NE SR method was presented by Chang et al. in [1], which assumes that the two manifolds in the HR and LR space have the same geometric structure, and the target LR patch can be represented by a linear combination of its neighborhood patches. NE SR method can recover a HR image with less complexity of computation, however it’s SR performance still remains great room for improvement. Li et al. [21] proposed an neighbor embedding SR method based on local preservation constraints (LPC), which explicitly emphasize the local consistency on the two manifolds, resulting in reduced blurring and artifacts. Gao et al. [12] divided the entire training set into several subsets using histogram of gradient clustering (HOG), and then, the method finds neighbors for a given patch in the corresponding subset using Robust-SL0 algorithm. Chen et al. [2] use kernel trick to learn the nonlinear mapping between LR and HR image patches. Yu et al. [38] presented an improved NE method by enlarging neighborhood range to all neighbors.
Another class of learning-based SR methods is sparse coding based methods, which was originally proposed by Yang et al. [36]. The sparse coding based SR (ScSR) method encodes the LR or HR image patches in the training set as a linear combination of a LR or HR dictionary, respectively. Under the premise that the LR and HR patches have the same sparse representation coefficients, the target HR patch for a given LR patch can be reconstructed by linearly combining the sparse representation coefficients of the given LR patch and HR dictionary. ScSR method has demonstrated it’s excellent performance and possesses robustness to noise. However, several disadvantages are still associated with ScSR. The sparse coding of LR patch is time-consuming. To speed up the sparse coding process, Zeyde et al. [39] proposed to use principal component analysis (PCA) and orthogonal matching pursuit (OMP) for LR patches sparse coding. As well, a coupled dictionary method [37], Bayesian dictionary [14] learning method had also been proposed for addressing this problem. In addition, the hypothesis that the LR and HR patches have the same sparse representation coefficients is not fully reasonable, which leads to performance drop. In [6], Dong et al. incorporate the difference of sparse coefficients between LR and HR features into the sparse coding of process LR patches.
Regression-based methods also play an essential role in learning-based methods. Kim et al. [18] first adopted the kernel ridge regression to learn the mapping relationship between LR and HR patches. The sparse solution is derived by combining kernel matching pursuit with gradient descent. To acquire sharper edge information in reconstructed HR image, Tang et al. [28] utilized multiple matrix-valued kernel regression for nonlinear mapping. In [22], the linear kernel regression is employed to establish the regression relationship between HR image and fuzzy HR image patches. Furthermore, a kernel regression method with an adaptive Gaussian kernel was proposed in [26]. To overcome over-fitting problem, Ogawa et al. [25] presented a new SR method which combines Gaussian mixture model (GMM) and partial least squares (PLS) regression. The Gaussian process regression (GPR) [13] is introduced into image SR to improve the generalization ability of regression models.
Apart from the those learning-based SR methods mentioned above, Timoft et al. [31] proposed ANR for image SR. This method combines NE method with sparse coding method, which exhibits outstanding SR performance. So far, many improved ANR variants have been proposed. With the aim of exploring the nonlinear relationship between the LR and HR spaces, Jiang et al. [17] exploited the local geometric prior to regularize the neighborhood regression, and meanwhile, the quality of reconstructed HR image is further enhanced using non-local self-similarity. In [40], MI-KSVD method is introduced into dictionary training, and the neighborhoods of a given LR patch is found according to the coherence between dictionary atoms and training samples. In [41], a modified ANR method was proposed using clustering and collaborative representation, in which the whole training set is divided into 1024 clusters using k-means clustering algorithm and each center of clustering represents an atom. In [42], Zhang et al. introduced a collaborative representation cascade (CRC) method to learn the multilayered mapping model between the LR and HR feature space.
With the continuous development of deep learning, more and more researchers have started to apply deep learning to SR reconstruction. Deep learning-based SR methods extract the high-level abstract features from LR/HR images in the train set through multiple-layer convolutional operation and nonlinear transformations, and then reconstruct a HR image by aggregating the extracted features. In 2014, Dong et al. proposed an image SR method based on deep convolutional networks (called SRCNN) [4]. After SRCNN, many deep learning models for image SR had been proposed. To speed up the convergence of SRCNN and obtain global optimal solution, Wang et al. introduced deep and shallow convolution networks [34] for image SR. Tian et al. proposed a lightweight enhanced SRCNN (LESRCNN) [30], which is more computationally frugal than SRCNN. Esmaeilzehi et al. [9] described image SR reconstruction as a three-priority optimization problem and developed an ultra-lightweight convolutional neural network for image SR. In [7], a new residual depth network called ComNet was proposed to solve image SR problem. In [8], Esmaeilzehi et al. proposed a new image restoration network, using pixel by pixel feature attention to calibrate the feature maps extracted by the network. Compared with most existing SR methods, deep learning-based image SR methods have demonstrated great advantage in performance. Though it is, the deep learning-based SR methods have a great deal of demanding on computational resource and power. In addition, the training of deep learning models are time-consuming.
Though ANR and its variants have demonstrated excellent performance, however, there sill has certain disadvantages. In ANR and it’s variants, the ridge regression is adopted to establish the relationship between the target patch and its neighbors in the LR/HR feature space. The coefficients of the ridge regression model are obtained by the least square method. The least square is not the optimal estimator because it does not take the prior distribution of the coefficients into account, which make it less robust to noise and lead to over-fitting. To address the above issues, we propose a new image SR method called B-ANR. B-ANR uses sparse Bayesian regression model to establish the mapping relationship between the LR image patch and its neighbors. The parameter’s of Bayesian regression model and its variance are obtained by maximum a posterior, which is more accurate than the least square. Since our B-ANR is derived in the probabilistic framework, it performs better in terms of generalization and robustness to noise. Experimental results verify that our approach is superior to ANR.
The remainder of this paper is organized as follows. Section 2 characterizes the details our proposed B-ANR method, Sect. 3 presents the experimental results and analysis, Sect. 4 discusses the advantages and disadvantages of the proposed method and deep learning methods, and Sect. 5 derives conclusions to conclude.
2 The Proposed Method
In this section, the proposed method is detailed explained. For the convenience of narration, we first recall the fundamentals of ANR and then explain our proposed B-ANR model.
2.1 Anchored Neighborhood Regression(ANR)
In [31], Timofte et al. introduced an ANR based SR method, which can be viewed as a combination of sparse coding method and NE SR method. ANR starts from a learned LR and HR sparse dictionary pair. ANR takes each atom \(\textbf{d}_j\) in the learned LR dictionary (via the method of [39]) as an anchor point. Then, one finds K nearest neighbors \(\varvec{N}_{l}\) for anchor \(\textbf{d}_j\) in the LR dictionary based on the correlation between the dictionary atoms. Denotes \(\varvec{N}_{l}\) as
Using the same assumptions as [1], the input LR image patch \(\varvec{x}_t\) can be approximated as a linear combination of its neighbors \(\varvec{N}_l\) and the weight coefficients \(\varvec{w}\), which can be mathematically expressed as
In Eq. (2), the optimal coefficients \(\varvec{w}\) are found by using ridge regression, that is,
where \(\lambda \) is a regularization parameter controlling the balance between the reconstruction error of \(\varvec{x}_t\) and the smoothness of \(\varvec{w}\). The closed algebraic solution for ridge regression problem (3) is
Then, the HR output patch can be calculated using the same weight coefficients on HR neighborhood \(\varvec{N}_h\) as
where \(\varvec{y}_t\) is the HR output patch and \(\varvec{N}_h\) is the HR neighborhood corresponding to \(\varvec{N}_l\). Once the neighborhood is defined, an individual projection matrix \(\varvec{P}_j\) is calculated based on the neighborhood for each anchor \(\varvec{d}_j\) as
After building the projection matrix for each anchor \(\varvec{d}_j\), one can use the projection matrices to super-resolve a LR image. The process is described as following. First, for each input LR patch \(\varvec{x}_i\), we calculate the correlation between \(\varvec{x}_i\) and all the atoms in the LR dictionary as
Let
then, the m-th atom in the LR dictionary is selected as the neighbor atom of the input LR patch \(\varvec{x}_i\). Then, the corresponding HR output \(\varvec{y}_i\) patch is reconstructed using the m-th projection matrix as
2.2 Bayesian Anchored Neighborhood Regression
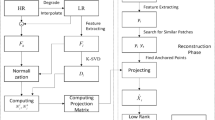
In ANR [31], ridge regression is adopted to build the relationship between the target patch and its neighbors. The coefficients of the ridge regression model are calculated by the least squares method. From a probabilistic perspective, the least squares method is equal to maximum likelihood estimation when the regression error follows a Gaussian distribution. Maximum likelihood estimation does not take the parameter prior into account, leading to less robustness to noise and over-fitting. To build an accurate model to characterize the relationship between the input image patch and its neighbors, we propose B-ANR, which introduces the prior of the weight coefficients into the regression process. Meanwhile, we estimate the model weight coefficients and it’s variance using maximum a posterior estimate method. The overall framework of the proposed B-ANR algorithm is shown in Fig. 1. The following will provide a detailed introduction to our proposed method.

The block diagram of SR algorithm proposed in this paper
Given a target LR patch \(\varvec{x}_t\) and it’s nearest neighbors \(\varvec{N}_l\), in the ANR framework, \(\varvec{x}_t\) can be represented as
where \(\epsilon \) represents mean-zero Gaussian with variance \(\sigma ^2\). Let \(\varvec{w}=(\varvec{w}_1,...\varvec{w}_K)^\textrm{T}\) denote weight the coefficient matrix associated with the target patch, then, \(\varvec{x}_t\) can be written in matrix form as
The likelihood function of the target vector \(\varvec{x}_t\) could be expressed as
Directly estimating the weight coefficients \(\varvec{w}\) and variance \(\sigma ^2\) using maximum likelihood easily leads to over-fitting. To solve this issue, the prior distribution of \(\varvec{w}\) is incorporated into the estimation of \(\varvec{w}\). The prior distribution of \(\varvec{w}\) is assumed to be a zero-mean Gaussian distribution with variance of \(\alpha _k^{-1}\) as
Using the Bayesian formula, the weight coefficients posterior \(p(\varvec{w}|\varvec{x}_t,\varvec{\alpha },\sigma ^2)\) can be written as
Substituting Eqs. (11) and (12) into (13), and after some manipulations, one can get
by ignoring the denominator of Eq. (13). In Eq. (14)
with \(\varvec{A}\)=diag\((\alpha _1,\alpha _2,...\alpha _k)\). The optimal weight coefficients \(\varvec{w}^*\) would be one that maximizes \(p(\varvec{w}|\varvec{x}_t,\varvec{\alpha },\sigma ^2)\), i.e.,
The optimal solution of problem (15) can be obtained by taking derivation of \(p(\varvec{w}|\varvec{x}_t,\varvec{\alpha },\sigma ^2)\) with \(\varvec{w}\) setting it to zero. Since \(p(\varvec{w}|\varvec{x}_t,\varvec{\alpha },\sigma ^2)\) is a Gaussian function, therefore, the optimal solution of (15) is
However, in Eq. (17), the hyper-parameter \(\varvec{\alpha }\) and \(\sigma \) are unknown. Therefore, one should make an estimation for them. This can be done using type-II maximum marginal likelihood procedure. The marginal likelihood is
or its logarithm
where
To improve sparsity and reduce computational requirements, we simplify Eq. (20) using the same method as in [33], updating only a single \(\alpha _i\) rather than the entire vector \(\varvec{\alpha }\) per iteration. Rewritten \(\varvec{C}\) as
where \(\varvec{C}_{-i}\) is \(\varvec{C}\) after removing the contribution of the basis vector i. Using the Woodbury identity for Eq. (21), it is possible to obtain
and using the determinant identity, we get
Substituting Eqs. (22) and (23) into (19), then \(\mathcal {L}(\varvec{\alpha })\) can be written as
For the convenience of simplicity, let
Then, the objective function \(\mathcal {L}(\varvec{\alpha })\) function is decomposed into \(\mathcal {L}(\varvec{\alpha }_{-i})\) and \(\ell (\alpha _i)\), in which the terms in \(\alpha _i\) are now conveniently isolated. Obviously, the unique maximum value of \(\mathcal {L}(\varvec{\alpha })\) is [10]
From Eq. (26) we can determine which basis vectors should be included in the model and which ones should be excluded. Once hyper-parameters \(\alpha _i\) is updated using Eq. (26), the parameters \(q_i\), \(s_i\) \(\mu \) and \(\Sigma \) are updated efficiently. As in [33], \(q_i\), \(s_i\) can be updated as the following formula
where \(\varvec{B}=\sigma ^{-2}\varvec{I}\). Here \(\varvec{N}_l\) and \(\varvec{\Sigma }\) contain only the feature vectors currently included in the model, which is normally a very minor part of the whole K, thus reducing the computational effort considerably.
According to the nature of the marginal likelihood function, we use Eq. (26) as the decision criteria to add or delete the candidate nearest-neighbor features for maximizing the marginal likelihood objective function. In summary, the process of determining the weight coefficients \(\varvec{w}\) is shown in Algorithm 1.
In the reconstruction phase, we assume that LR space and HR space have the same geometry, so the resulting weight coefficients \(\varvec{w}\) can be used to construct the HR image. The HR image patch is calculated by using the HR neighborhood \(\varvec{N}_h\) corresponding to the LR neighborhood \(\varvec{N}_l\) and the weight coefficients \(\varvec{w}\). The SR reconstruction of the image is carried out as follows:
where \(\varvec{y}_t\) is the HR output patch and \(\varvec{N}_h=(\varvec{d}_h^1,...\varvec{d}_h^K)\) is the HR neighborhood.

Maximum a posterior estimation of \(\varvec{w}\)
3 Experimental Results and Analyses
To verify the validity of the proposed method, super-resolution experiments on several datasets are conducted. Meanwhile, the experimental results obtained by the method of this paper are compared with those obtained by several most advanced SR methods SR methods like Yang et al. [36], Zeyde et al. [39], ANR [31] , NE + LS, NE + LLE [1]. We use peak signal-to-noise ratio (PSNR) and structural similarity (SSIM) as evaluation criteria for measuring the performance of image reconstruction. PSNR represents the ratio of the maximum possible power of a signal to the power of the destructive noise that affects the accuracy of its representation. SSIM is a measure of similarity between two images.
3.1 Experimental Settings
Training Set Learning-based method requires a large amount of image patch pairs for training. In this paper, we use the same training set as Yang et al. [36], Zeyde et al. [39], ANR [31]. We use the images in the training set as HR images and the corresponding LR images are acquired by bicubic interpolation. We divide the HR images into HR image patches of 9 \(\times \) 9 pixel size with an overlap of 6 pixels between neighboring patches. The size of the corresponding LR image patches is set to 3 \(\times \) 3 pixels with an overlap of 2 pixels.
Testing Set To better compare with other methods, we uniformly use Set5 , Set14 and BSD100 as test sets, including 5, 14 and 100 common images, respectively. We perform bicubically interpolation on the images in the test set to obtain LR images for testing and segment the LR images into LR image patches of the same size as in the training set.
Features As the human eye is more susceptible to luminance constituents, we extract features from the luminance channel of the image patches. We use the identical features as Zeyde et al. [39] and Yang et al. [36], who started from the first- and second-order gradients of luminance and performed PCA to reduce the dimension and project the features into a low-dimensional subspace.
Since the features used in the LR patches are not reflective of absolute luminance, we subtract the mean from the luminance-based feature vector for each HR patch. When constructing the target HR image, the patches generated by the SR process are added to the average luminance value of the corresponding LR patches.
Dictionaries In our experiments, We train the dictionaries using the same external images as in Zeyde et al. [39]. For dictionary learning, we use the K-SVD/OMP learning method of Zeyde et al. [39]. To facilitate qualitative comparison with other methods, we uniformly use a dictionary of size 1024.
Neighborhoods As we are calculating weights and reconstructing them based on the neighborhood of the input patch in the dictionary, the method of neighborhood selection is important. For neighborhood selection, we choose neighborhoods on the basis of the correlation between dictionary atoms and image patches. Different sizes of neighborhoods also have different effects on performance, and when comparing methods, we choose the best neighborhood value for each method. In the learning dictionary, the best neighborhood for NN + LS is 12, for NE + LLE [1] and ANR [31] is 40, the best neighborhood chosen for our method is 80.
3.2 Experimental Results
Timofte et al. [31] demonstrate that for the proper set of parameters, such as feature representation, neighborhood size, most current neighborhood embedding methods are capable of achieving a certain quality of performance. Tables 1 and 2 display the PSNR and the SSIM values for each test image at magnification factor \(\times \)3 for the Set5, Set14 and BSD100 dateset. In addition to deep learning-based SR method, it is evident that our results obtain the highest PSNR and SSIM values compared to other methods, both PSNR and SSIM have different degrees of improvement. In Table 3, we show the average PSNR and SSIM values for the amplification factors \(\times \)2,\(\times \)3,\(\times \)4 on the Set5, Set14, BSD100 datasets. With the exception of TPCNN [4], our proposed method is the best among the others in terms of quality, with an average improvement PSNR of 0.14 dB (BSD100, \(\times \)2) to 0.09 dB (Set5, \(\times \)2) over the ANR [31] method. Different amplification factors of SSIM on Set5, Set14 and BSD100 data sets have an average increase of 0.0023 compared to ANR [31].
In order to demonstrate the superior visual quality of our method compared to other methods, we compare our method with others from a visual perspective in Figs. 2, 3, 4, 5 and 6. We select ‘butterfly’ in Set 5 and ‘baboon’, ‘zebra’, ‘foreman’ and ‘pepper’ in Set 14 with the magnified \(\times \)3. From the figure it can be seen that the Bicubic interpolation method has the worst visual results, producing blurred edge information. Yang et al. [36] reconstructed HR images based on dictionary learning, which also resulted in some ringing and artefact effects. Zeyde et al. [39] used PCA dimensionality reduction to greatly reduce the computational complexity, but it did not have good information about the details of the recovered. NE+LS produces serrated edge information and annoying texture details irritating texture details. NE+LLE method can mitigate the fuzzy edges produced in [36] and [39] by the neighborhood embedding reconstruction method, but it also produces a ringing effect at the edges. ANR [31] combined with neighborhood embedding and sparse coding produced favorable image SR performance, but also did not reconstruct edge information well. In contrast, our method recovers the detail information well and yields sharp edges.

The visual qualitative assessment of the ‘baboon’ image is from Set5 magnified \(\times \)3

The visual qualitative assessment of the ‘butterfly’ image is from Set5 magnified \(\times \)3

The visual qualitative assessment of the ‘zebra’ image is from Set14 magnified \(\times \)3

The visual qualitative assessment of the ‘foreman’ image is from Set5 magnified \(\times \)3

The visual qualitative assessment of the ‘pepper’ image is from Set14 magnified \(\times \)3
4 Discussion
In the example-based image SR framework, ANR method achieves the best SR performance compared with other methods using traditional machine-learning techniques. ANR method combines the advantage of sparse coding theory and neighborhood embedding. In ANR, the sparse coding is adopted to extract the feature of image patches and neighborhood embedding to build the relationship among the features. In this paper, we further improved ANR method using Bayesian regression. From theoretic viewpoint and experimental results, one can see that the SR performance of the proposed method indeed has certain improvement.
Though it is, ANR and our proposed method are still associated with some disadvantages compared with deep learning based SR methods. For example, the feature extraction ability of ANR and our proposed method is still weak in a certain extent because only the sparse representation features are utilized. However, the deep learning based methods show powerful ability in extracting the shallow and deep features of images by utilizing a series of convolutional layers. Full utilization of the shallow features and semantic features are helpful for SR performance improvement and enhancement of robustness. This is the essential reason that the deep learning based methods can achieve the breakthrough SR performance.
On the other, the model complexity and computations of deep learning based methods are very large. Because a large number of convolutional layers are involved in deep learning based models, the computation burden in model training and test is huge, therefore, massive computing power are required for most of the deep learning based SR methods. Table 4 lists the rough time required for model training and parameter amount of several deep learning based models and our proposed method. The large computations hampers the application of deep learning based SR methods in the devices with limited computing power such as smart phone and edge-devices.
If we comprehensively take the SR performance and computations into account, ANR and our proposed method are competitive to deep learning based methods.
5 Conclusions
This paper presents an image SR algorithm based Bayesian anchored neighborhood regression. So as to better suppress the noise and increase the generalization performance of SR, we consider the prior distribution of the weight coefficients, using sparse Bayesian regression model to model the mapping relationship between LR image patch and its neighbors. Qualitative comparisons with several state-of-the-art SISR methods are performed to verify the effectiveness and stability of the proposed algorithm. Additionally, we assume that the parameters obey a Gaussian prior distribution, and other probability distributions can also be assumed to verify the validity of the algorithm, which we will investigate in more detail in future work.
Data Availibility
Both training and test datasets used in research study are openly accessible.
References
H. Chang, D. Y. Yeung, Y. Xiong, Super-resolution through neighbor embedding, in Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR) (2004), pp. 275–282
X. Chen, C. Qi, Nonlinear neighbor embedding for single image super-resolution via kernel mapping. Signal Process. 94, 6–22 (2014)
Y. Chen, Y. Xie, Z. Zhou, F. Shi, A. G. Christodoulou, D. Li, Brain MRI super resolution using 3D deep densely connected neural networks, in 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI) (2018), pp. 739–742. https://doi.org/10.1109/ISBI.2018.8363679
C. Dong, C.C. Loy, K. He, X.O. Tang, Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 38(2), 295–307 (2016). https://doi.org/10.1109/TPAMI.2015.2439281
C. Dong, C. C. Loy, X. O. Tang, Accelerating the super-resolution convolutional neural network, in Computer Vision–ECCV 2016: 14th European Conference (Amsterdam, The Netherlands, 2016b), pp. 391–407
W.S. Dong, L. Zhang, G.M. Shi, X. Li, Nonlocally centralized sparse representation for image restoration. IEEE Trans. Image Process. 22(4), 1620–1630 (2013). https://doi.org/10.1109/TIP.2012.2235847
A. Esmaeilzehi, M.O. Ahmad, M. Swamy, Compnet: a new scheme for single image super resolution based on deep convolutional neural network. IEEE Access 6, 59963–59974 (2018). https://doi.org/10.1109/ACCESS.2018.2874442
A. Esmaeilzehi, M. O. Ahmad, M. Swamy, DSEGAN: a deep light-weight segmentation-based attention network for image restoration, in 2022 IEEE International Symposium on Circuits and Systems (ISCAS) (2022), pp. 1284–1288. https://doi.org/10.1109/ISCAS48785.2022.9937894
A. Esmaeilzehi, M.O. Ahmad, M. Swamy, Ultralight-weight three-prior convolutional neural network for single image super resolution. IEEE Trans. Artif. Intell. 4(6), 1724–1738 (2023). https://doi.org/10.1109/TAI.2022.3224417
A. Faul, M. Tipping, Analysis of sparse Bayesian learning, in Advances in Neural Information Processing Systems (2001), pp. 383–389
W. Freeman, T. Jones, E. Pasztor, Example-based super-resolution. IEEE Comput. Graph. Appl. 22(2), 56–65 (2002). https://doi.org/10.1109/38.988747
X.B. Gao, K.B. Zhang, D.C. Tao, X.L. Li, Image super-resolution with sparse neighbor embedding. IEEE Trans. Image Process. 21(7), 3194–3205 (2012). https://doi.org/10.1109/TIP.2012.2190080
H. He, W. C. Siu, Single image super-resolution using Gaussian process regression, in CVPR 2011 (2011), pp. 449–456. https://doi.org/10.1109/CVPR.2011.5995713
L. He, H. Qi, R. Zaretzki, Non-parametric Bayesian dictionary learning for image super resolution, in 2011 Future of Instrumentation International Workshop (FIIW) Proceedings (2011), pp. 122–125. https://doi.org/10.1109/FIIW.2011.6476831
H.S. Hou, H.C. Andrews, Cubic splines for image interpolation and digital filtering. IEEE Trans. Acoust. Speech Signal Process. 26(6), 508–517 (1978)
Z. L. Hu, T. Li, Y. F. Yang, X. Liu, H. R. Zhang, D. Liang, Super-resolution pet image reconstruction with sparse representation, in 2017 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC) (2017), pp. 1–3. https://doi.org/10.1109/NSSMIC.2017.8532893
J.J. Jiang, X. Ma, C. Chen, T. Lu, Z.Y. Wang, J.Y. Ma, Single image super-resolution via locally regularized anchored neighborhood regression and nonlocal means. IEEE Trans. Multimed. 19(1), 15–26 (2017)
K.I. Kim, Y. Kwon, Single-image super-resolution using sparse regression and natural image prior. IEEE Trans. Pattern Anal. Mach. Intell. 32(6), 1127–1133 (2010). https://doi.org/10.1109/TPAMI.2010.25
F. Kong, M. X. Li, S. W. Liu, D. Liu, J. W. He, Y. Bai, F. G. Chen, L. Fu, Residual local feature network for efficient super-resolution, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2022), pp. 765–775
Z. Lei, X. Wu, An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans. Image Process. 15(8), 2226–2238 (2006)
B. Li, H. Chang, S. G. Shan, X. L. Chen, Locality preserving constraints for super-resolution with neighbor embedding, in 2009 16th IEEE International Conference on Image Processing (ICIP) (2009), pp. 1189–1192. https://doi.org/10.1109/ICIP.2009.5413691
J. M. Li, Y. Y. Qu, Y. Gu, T. Z. Fang, C. H. Li, Super-resolution based on fast linear kernel regression, in 2013 International Conference on Machine Learning and Cybernetics (2013), pp. 333–339. https://doi.org/10.1109/ICMLC.2013.6890490
M. Li, T.Q. Nguyen, Markov random field model-based edge-directed image interpolation. IEEE Trans. Image Process. 17(7), 1121–1128 (2008). https://doi.org/10.1109/TIP.2008.924289
Z. Li, W.J. Leong, M. Durand, I. Howat, K. Wadkowski, B. Yadav, J. Moortgat, Super-resolution deep neural networks for water classification from free multispectral satellite imagery. J. Hydrol. 626, 130248 (2023)
Y. Ogawa, T. Hori, T. Takiguchi, Y. Ariki, Super-resolution using GMM and PLS regression, in 2012 IEEE International Symposium on Multimedia (2012), pp. 298–301. https://doi.org/10.1109/ISM.2012.62
M. E. Philip, G. S. Kumar, An improved color video super-resolution using kernel regression and fuzzy enhancement, in 2012 International Conference on Advances in Computing and Communications (2012), pp. 114–117. https://doi.org/10.1109/ICACC.2012.25
H.P. Song, H. Ma, Y.X. Si, J.Y. Gong, H.Y. Meng, Y.P. Lai, Back projection deep unrolling network for handwritten text image super resolution. Comput. Electr. Eng. 111, 108965 (2023)
Y. Tang, Z. Jiang, J. H. Chen, Single-image super-resolution via multiple matrix-valued kernel regression, in 2019 International Conference on Machine Learning and Cybernetics (ICMLC) (2019), pp. 1–7. https://doi.org/10.1109/ICMLC48188.2019.8949261
Y. Tang, T. Wang, D. Liu, MFFAGAN: generative adversarial network with multilevel feature fusion attention mechanism for remote sensing image super-resolution. IEEE J-STARS. 17, 6860–6874 (2024)
C.W. Tian, R.B. Zhuge, Z.H. Wu, Y. Xu, W.M. Zuo, C. Chen, C.W. Lin, Lightweight image super-resolution with enhanced CNN. Know-Based Syst. 205, 106235 (2020)
R. Timofte, V. De Smet, L. Van Gool, Anchored neighborhood regression for fast example-based super-resolution, in Proceedings of the IEEE International Conference on Computer Vision (2013), pp. 1920–1927
M.E. Tipping, Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 1, 211–244 (2001)
M. E. Tipping, A. C. Faul, Fast marginal likelihood maximisation for sparse Bayesian models, in International Workshop on Artificial Intelligence and Statistics (2003), pp. 276–283
Y.F. Wang, L.J. Wang, H.Y. Wang, P.H. Li, End-to-end image super-resolution via deep and shallow convolutional networks. IEEE Access 7, 31959–31970 (2019). https://doi.org/10.1109/ACCESS.2019.2903582
L. Xin, M.T. Orchard, New edge-directed interpolation. IEEE Trans. Image Process. 10(10), 1521–1527 (2001)
J.C. Yang, J. Wright, T.S. Huang, Y. Ma, Image super-resolution via sparse representation. IEEE Trans. Image Process. 19(11), 2861–2873 (2010)
J. Yang, Z. Wang, Z. Lin, S. Cohen, T. Huang, Coupled dictionary training for image super-resolution. IEEE Trans. Image Process. 21(8), 3467–3478 (2012). https://doi.org/10.1109/TIP.2012.2192127
W.S. Yu, S.Q. Chen, An improved neighbor embedding method to super-resolution reconstruction of a single image. Proc. Eng. 15, 2418–2422 (2011)
R. Zeyde, M. Elad, M. Protter, On single image scale-up using sparse-representations, in Curves and Surfaces (Springer, 2012), pp. 711–730
Y. Zhang, K. Gu, Zhang, J. Zhang, Q. Dai, Image super-resolution based on dictionary learning and anchored neighborhood regression with mutual incoherence, in 2015 IEEE International Conference on Image Processing (ICIP) (2015), pp. 591–595. https://doi.org/10.1109/ICIP.2015.7350867
Y. Zhang, Y. Zhang, J. Zhang, Q. Dai, Ccr: clustering and collaborative representation for fast single image super-resolution. IEEE Trans. Multimed. 18(3), 405–417 (2016). https://doi.org/10.1109/TMM.2015.2512046
Y. Zhang, Y. Zhang, J. Zhang, X. Dong, F. Yun, Y. Wang, X. Ji, Q. Dai, Collaborative representation cascade for single-image super-resolution. IEEE Trans. Syst. Man Cybern. 49(5), 845–860 (2019). https://doi.org/10.1109/TSMC.2017.2705480
Acknowledgements
This work was partly supported by the Provincial Key Laboratory Performance Subsidy Project (22567612H) and Medicine-Engineering Interdisciplinary Special Cultivation Project (UH202208).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Tang, Y., Fan, A. Bayesian Anchored Neighborhood Regression for Single-Image Super-Resolution. Circuits Syst Signal Process 43, 5309–5327 (2024). https://doi.org/10.1007/s00034-024-02720-3
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-024-02720-3