
Abstract
Under α stable distribution impulse noise environment, the least mean p-power algorithm (LMP) cannot handle the instability of the algorithm well, due to the large amplitude of the input signal and the large number of useless small weight coefficients in the sparse channel, which delay the convergence speed of the algorithm. In this paper, we develop a new adaptive filtering algorithm, named the proportional normalization least mean p-power (PNLMP) adaptive filtering algorithm. We first introduce a step size control matrix to improve the overall convergence speed and convergence accuracy of the algorithm. Next, to reduce the influence of a large impulse response on the LMP algorithm, a high-order tongue-line function about error is introduced in the normalization processing. Finally, we extend the tongue-line function to ensure that the cost function can also switch freely between V-shaped and M-shaped. This new algorithm overcomes the problem that the traditional LMP algorithm is only applicable to a specific environment and solves the problem of slow convergence speed and low convergence accuracy. Under α stable distribution impulse noise environment, the simulations show that the PNLMP algorithm can improve the convergence speed and stronger system tracking capability compared with existing algorithms, overcoming the problems of slow overall convergence and low convergence accuracy in the traditional algorithm.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
In the adaptive filtering algorithm, the least mean square (LMS) algorithm uses the least mean square of the error as the cost function and has been widely studied and applied in the Gaussian noise environment because of its simplicity and robustness [15]. To improve the convergence speed and steady-state accuracy of the algorithm, researchers introduced the normalization LMS (NLMS) algorithm based on the LMS algorithm [8, 14], which uses normalization to reduce the impact of large impulse responses on the LMS algorithm and enhance the stability performance of the algorithm. In addition, based on the normalized algorithm, Chien proposed several improved affine projection algorithms (APAs) [4,5,6], which alleviated the contradiction between the convergence speed and the steady-state misalignment of the NLMS algorithm and increased its adaptability to different sparse and noise characteristics of the system. Duttweiler [9] first proposed the proportional NLMS (PNLMS) algorithm, which references the step control matrix \(G(n)\) [17] based on the traditional LMS algorithm, so that the step parameters at each moment vary with the weight coefficients of the filter at the current moment, with larger coefficients obtaining a larger step size and smaller coefficients obtaining a smaller step size, thus both speeding up the convergence of the adaptive filtering algorithm and reducing the steady-state error of the adaptive filtering algorithm.
However, whether LMS, NLMS, APAs or PNLMS, the convergence performance will deteriorate or even fail to converge in a non-Gaussian noise environment. This is due to the poor resistance of the least mean-square error criterion (MSE) to impulse response. To solve this problem researchers have proposed various solutions, and the least mean p-power error criterion (MPE) [18, 19] instead of the MSE is one of the most commonly used methods at present. When \(p = 2\), the LMP algorithm is equivalent to the LMS algorithm, and when \(p < 2\), the LMP algorithm can obtain good performance in a non-Gaussian noise environment.
Based on the above analysis, in this paper we propose an improved proportional normalized least mean p-power algorithm (PNLMP). Based on the LMP algorithm, a proportional control factor and an improved error high-order tongue-line function are introduced for normalization processing. The stability and convergence of the algorithm and the influence of parameters on the performance of the algorithm are analyzed. Experiments show that the PNLMP algorithm has a faster convergence speed and stronger system tracking ability than some comparison algorithms.
2 Least Mean P-Power (LMP) Algorithm
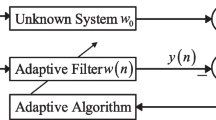
Figure 1 shows the general structure of the adaptive filter. where \({\varvec{u}}(n)\) is the input signal at the nth moment of the filter, and the expected signal \({\varvec{d}}(n)\) is the \({\varvec{u}}(n)\) that passes through the unknown system \({\varvec{w}}_{0}\) and is affected by the noise signal \({\varvec{v}}(n)\). Set \({\varvec{y}}(n)\) as the output signal of the adaptive filter, to make \({\varvec{y}}(n)\) as close as possible to \({\varvec{d}}(n)\). To achieve the best filtering effect, a cost function \(J(n)\) is needed to gradually reduce the error signal \({\varvec{e}}(n) = {\varvec{d}}(n) - {\varvec{y}}(n)\) by iteration so that the filter weight vector \({\varvec{w}}(n)\) approaches the unknown system impulse response \({\varvec{w}}_{0}\)
where \({\varvec{u}}(n) = [u(n),u(n - 1), \cdot \cdot \cdot ,u(n - M + 1)]^{{\text{T}}}\) is the input vector; \(M\) is the length of the adaptive filter; \({\varvec{w}}_{0}\) is the unknown system that can be estimated; and the superscript \(( \cdot )^{{\text{T}}}\) is the transpose of a vector or matrix. The desired signal can be expressed as.

Adaptive filter structure for system identification
The instantaneous error of the filter can be expressed as
The cost function the LMS algorithm is based on the least mean square error criterion (MSE).
Under α stable distribution impulse noise environment, is used to the least mean p-power replace the least mean square of error. Therefore, the cost function can be expressed as \(\min J(n) = \left| {e(n)} \right|^{p}\), and the weight update of the LMP algorithm is obtained by using the stochastic gradient algorithm.
In [24], the weight vector update of the adaptive filtering algorithm is summarized as a nonlinear even function with respect to the error in three shapes, V-shaped, Λ-shaped, and M-shaped algorithms, and \(\mu > 0\) is the step size. The weight update with error nonlinearity can also be defined as.
Since the Λ-shaped algorithms cannot converge quickly in both Gaussian and non-Gaussian noises, we want to find an algorithm that has V-shaped and M-shaped characteristics. Inspired by [17] and [24], the robust proportional normalization least mean p-power (PNLMP) algorithm is proposed.
3 PNLMP Algorithm
In this paper, we present a novel robust proportional normalized least mean p-power (PNLMP) algorithm to improve the steady-state accuracy and convergence speed of the algorithm, which introduced the proportional control matrix algorithm and normalization method. First, the proportional control matrix \(G(n)\) is introduced for Eq. (5).
where \(G(n) = diag\left[ {g_{1} (n),g_{2} (n),...,g_{M} (n)} \right]\) is a time-varying step control matrix with the following expressions for the diagonal elements.
The parameters \(\theta\) and \(\rho\) are both smaller positive numbers, which are used to avoid stopping the algorithm from updating because the filter coefficients are too small.
It is proposed in [24] that the \(f(e(n))\) shape should be related to the power of the estimation error, so it is proposed that in the \(f(e(n))\) weight update, the p-order moments of the input vector are used instead of the commonly used 2-norm, and the (p-q)-order moments of the error are used to perform the normalization. The weight update equation is obtained.
where \(a\) is a positive constant and \(p\) is a constant from 0 to 2. It is mentioned in [17] that since the pulsed excitation signal can make the algorithm unstable, \(\left\| {{\varvec{u}}(n)} \right\|_{2}^{P}\) is rewritten as \(\left\| {{\varvec{u}}(n)} \right\|_{G}^{P} = {\varvec{u}}^{T} (n)G(n){\varvec{u}}(n)\). The resulting nonlinear function is
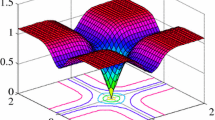
Assume that the input signal is a smooth sequence of independent zero-mean Gaussian random variables with finite variance \(\delta_{u}^{2} = 0.01\) and dimension \(N = 128\). Setting \(p = 4\), \(a = 1\), \(G(n) = I(n)\) unit diagonal matrix, we plot Eq. (12) with respect to the error in Fig. 2, where \({\varvec{u}}(n)\) is the average of 200 independent runs. As shown in Fig. 2\(f(e(n))\) is usually an M-shaped algorithm, but when \(q = 2\) \(f(e(n))\) is a V-shaped algorithm.

Nonlinear function surface of error e(n)
In [23], it is proposed that when \(q\) is a fixed value, \(p - q\) is also a fixed value, so the algorithm can only filter the fixed noise environment. According to the adaptive filtering algorithm, in Fig. 2 it is seen that when the errors are large, we need a small \(q\) to ensure the convergence; in contrast, when the errors are small, we need a large \(q\) to improve the steady-state performance. Therefore, to obtain the varying \(q\), we design \(q(n)\) as a monotonically decreasing function about \(e(n)\), and the function has lower and upper bounds of 0 and 2 to ensure stability and filtering accuracy, which is also explained in [19, 24]. At the same time, motivated by the “S” shape function of the sigmoid function, we design \(q(n)\) as a tongue-like curve monotone decreasing function about the error and symmetry about the y-axis and use the previous moment error and the current error to control the step size of \(q(n)\). The improved algorithm can switch well between V-shaped and M-shaped algorithms. Therefore, \(q(n)\) with different \(p\) can be applied in different noise environments.
The standard tongue-like curve function in [16] is \(Y = \frac{1}{{1 + X^{2} }}\), which is also explained in [3]. \(q(n) \in (0,2]\) is chosen to ensure the stability and filtering accuracy, so we adjust the amplitude of the function, and the \(q(n)\) nonlinear function can be defined as
In (13), \(\beta\) is the smaller positive constant. Combined with (11), (12) and (19), we obtain the PNLMP algorithm weight update formula in this paper. The pseudo code process of the PNLMP algorithm is shown in Table 1.
4 Algorithm Analysis
In this section, the mean square performance analysis is performed to theoretically verify the convergence performance of the PNLMP algorithm. Define the \(n\) moment error vector as (11).
Using \({\text{E}}\left[ {\left\| {\tilde{\user2{w}}{\text{(n)}}} \right\|^{{2}} } \right]\) to represent the mean squared error (MSD) to estimate the accuracy of the filter, we obtain the error as follows:
For theoretical analysis, the following assumptions need to be given.
-
A1: \({\varvec{u}}(n)\) is a zero-mean smooth series of independent and uniformly distributed (i.i.d.) Gaussian random variables with finite variance \(\sigma_{u}^{2}\).
-
A2: The noise \({\varvec{v}}(n)\) is zero-mean, independently and identically distributed, and independent of the input signal \({\varvec{u}}(n)\), with variance \(\sigma_{v}^{2}\).
-
A3: The a priori error \(e_{a} (n) = \tilde{\user2{w}}^{{\text{T}}} (n){\varvec{u}}(n)\) is zero-mean, has a Gaussian distribution and is independent of the noise.
-
A4: The filter runs long enough, \(\left\| {{\varvec{u}}(n)} \right\|_{G}^{P}\) and \(e^{2} (n)\) are asymptotically independent.
Assumptions A1~A4 have been widely used in the theoretical analysis of adaptive filters [3, 21].
4.1 Convergence Analysis
Combining (1) and (10) generates
Taking the square of both sides of the above equation and squaring the expectation gives.
In the LMS algorithm, when the step size is satisfied \(0 < \mu < \frac{2}{3tr(R)}\) the algorithm converges. \(tr( \cdot )\) denotes the trace of the matrix and \(R = E[{\varvec{u}}^{{\text{T}}} ({\text{n}}){\varvec{u}}(n)]\) is the autocorrelation matrix of \({\varvec{u}}(n)\). Therefore, as when \(n \to \infty\) the filter reaches a steady state, in (18) the first term on the right side is equal to the left, so we can simplify the above equation as:
For analytical convenience, for \(p = 2\), while \(q(n)\) converges to 2 when the steady state is reached, \(\left| {e(n)} \right|^{p - q(n)}\) converges to 1; then, \(W\) is defined as the molecular part and simplified as
Similarly, defining the denominator as \(K\), the derivation yields \(K\).
where \(\left\| {{\varvec{u}}(n)} \right\|^{2} = {\varvec{u}}^{{\text{T}}} (n){\varvec{u}}(n) \approx N\delta_{u}^{2}\), which is valid when \(N\) is assumed to be sufficiently large under assumption A1 [11, 12]. Bringing \(W\) and \(K\) respectively into (17), it is derived that the convergence condition of the algorithm needs to be satisfied.
4.2 Stability Analysis
To evaluate the filtering accuracy, the instantaneous mean square deviation (MSD) and the excess mean-square error (EMSE) are used to measure the steady-state performance. Thus, we evaluate the limit on both sides of (16).
When the filter reaches steady state, we have \(y(n) = y(n - 1)\), \(\mathop {\lim }\limits_{n \to \infty } E\left[ {\left\| {\tilde{\user2{w}}(n{ + }1)} \right\|^{2} } \right] = \mathop {\lim }\limits_{n \to \infty } E\left[ {\left\| {\tilde{\user2{w}}(n)} \right\|^{2} } \right]\), and the above equation simplifies to.
Combined with assumption A3, we find
Meanwhile, the EMSE denoted by \(\xi (\infty )\) is used to evaluate the steady-state performance and tracking capability of the adaptive filtering algorithm. defined as.
Combining (23) with (24), we generate.
When \(p = 2\), the steady-state EMSE and MSD of PNLMP are the same as those of PNLMS. When \(0 < p < 2\) to ensure the convergence of the algorithm, then \(q(n)\) converges as close as possible to 2 to achieve algorithmic convergence. In fact, when \(a\) is small, the validity of the derived EMSE and MSD can be guaranteed as long as \(\mu\) or \(\beta\) is small enough.
5 Simulation
5.1 Algorithm Verification
To verify the effectiveness of the PNLMP algorithm under α stable distribution impulse noise environment, the parameters \(a\) and \(\beta\) introduced in (9) are analyzed for \(p = 1.55\) and applied to the simulation experiments at a signal-to-noise ratio of 5 dB with the impulse noise parameters \(N1 \, = \, [1.4, \, 0, \, 0.3, \, 0]\). The trial-and-error method [10] was used to obtain the optimal values, setting \(a = 0.01, \, \beta = 2*10^{ - 1} , \, \beta = 2*10^{ - 2} ,\beta = 2*10^{ - 3} ,\beta = 2*10^{ - 4}\) and \(\beta = 0.002\) \( \, a = 0.05, \, a = 0.1, \, a = 0.15, \, a = 0.2\), and the algorithm performance curves are shown in Figs. 2 and 3.

PNLMP performance curve under different values of β
Figures 3 and 4 show that the \(a\) variation has a small effect on the convergence speed of the algorithm, and the parameter \(\beta\) mainly affects the steady-state error when the algorithm converges.

PNLMP performance curve under different values of β
5.2 Algorithm Comparison
To verify the performance of the PNLMP algorithm, we compare it with the PNRMS of [24], the LMP of [1], the NLMS of [20], the GVC of [13], and the GMCC of [2] in the cases of \(a = 0.2\), \(\beta = 0.002\) and their nonlinear functions \(f(e(n))\), as shown in Table 2.
Simulation experiments were applied at a signal-to-noise ratio of 15 dB with other parameters unchanged, the simulated system noise parameters were \(N2 \, = \, [2, \, 0, \, 0.03, \, 0]\), and the simulated MSD was averaged over 100 independent runs. and the system mutates at the \(1 \times 10^{4}\) sampling point moment, i.e., the unknown system weight vector changes from \({\varvec{w}}\) to \(- {\varvec{w}}\), and the algorithm results are shown in Figs. 5 and 6. It can be seen that the PNLMP algorithm converges after approximately 900 iterations, and the MSD value is reduced by 4.17 dB and 5.76 dB compared with the traditional PNRMS and GMCC algorithms, which shows that the PNLMP algorithm can achieve better convergence and system tracking performance under both Gaussian noise and impulsive noise conditions.

Comparison of the MSDs in N2 = [2, 0, 0.03, 0]

Comparison of the MSDs in N2 = [2, 0, 0.03, 0] with impulse noise
5.3 Application of Channel Identification
To further investigate the performance of each algorithm, [7] states that the noise parameter of an offshore domain can be represented by \(N3 \, = \, [1.82, \, 0, \, 0.0317, \, 0]\), so this parameter is chosen as the impulse noise parameter in this section. Figure 7 shows the measured channel impact response [22] for a moment in time in the Qingjiang River, Yichang, with a channel length of 400, and this is chosen as the unknown system response to be identified in this section. The five algorithms in the previous comparison are applied to the system at this location while the number of sampling points is \(2 \times 10^{4}\), and at the \(1 \times 10^{4}\) sampling moment, the system undergoes a sudden change, i.e., the channel impulse response is inverted, and the convergence curves of each algorithm are shown in Fig. 8.

Impulse response of a measured hydroacoustic channel

Comparison of MSDs performance of real hydroacoustic channel algorithms
It is obvious that the PNLMP algorithm proposed in this paper has better convergence speed and stronger system tracking capability under different noise and SNR conditions by comparing the simulated and real environment.
6 Conclusion
In this paper, we analyze several existing nonlinear adaptive filtering algorithms and propose a new PNLMP algorithm. This algorithm is based on the error surface of the nonlinear function, which introduces the proportional control matrix and the tongue-line function about the error to change the p-power of the nonlinear function to ensure that it can switch between V-shaped and M-shaped algorithms. Simulation experiments demonstrate that in the α stable distribution environment, whether it is Gaussian noise or impulse noise, the PNLMP algorithm has faster convergence and greater system tracking capability compared to the conventional adaptive algorithm.
Data Availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
O. Arikan, A.E. Cetin, E. Erzin, Adaptive filtering for non-Gaussian stable processes. IEEE Signal Process. Lett. 1(11), 163–165 (1994). https://doi.org/10.1109/97.335063
B. Chen, L. Xing, H. Zhao, N. Zheng, J.C. Principe, Generalized correntropy for robust adaptive filtering. IEEE Trans. Signal Process. 64(13), 3376–3387 (2016). https://doi.org/10.1109/TSP.2016.2539127
B. Chen, L. Xing, J. Liang, N. Zheng, J.C. Principe, Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. IEEE Signal Process. Lett. 21(7), 880–884 (2014). https://doi.org/10.1109/LSP.2014.2319308
Y.-R. Chien, Variable regularization affine projection sign algorithm in impulsive noisy environment. IEICE Trans. Fundam. E102.A(5), 725–728 (2019). https://doi.org/10.1587/transfun.E102.A.725
Y.-R. Chien, L.-Y. Jin, Convex combined adaptive filtering algorithm for acoustic echo cancellation in hostile environments. IEEE Access 6, 16138–16148 (2018). https://doi.org/10.1109/ACCESS.2018.2804298
Y.-R. Chien, C.-H. Yu, H.-W. Tsao, Affine-projection-like maximum correntropy criteria algorithm for robust active noise control. IEEE/ACM Trans. Audio Speech Lang. Process. 30, 2255–2266 (2022). https://doi.org/10.1109/TASLP.2022.3190720
M.A. Chitre, J.R. Potter, S.-H. Ong, Optimal and near-optimal signal detection in snapping shrimp dominated ambient noise. IEEE J. Oceanic Eng. 31(2), 497–503 (2006). https://doi.org/10.1109/JOE.2006.875272
L.D. Davisson, G. Longo, Adaptive Signal Processing (Springer Vienna, Vienna, 1991)
D.L. Duttweiler, Proportionate normalized least-mean-squares adaptation in echo cancelers. IEEE Trans. Speech Audio Process. 8(5), 508–518 (2000). https://doi.org/10.1109/89.861368
A.-H. Enrique, B. David, D.P. Ruiz, M.C. Carrion, The averaged, overdetermined, and generalized LMS algorithm. IEEE Trans. Signal Process. 55(12), 5593–5603 (2007). https://doi.org/10.1109/TSP.2007.899375
E. Eweda, A stable normalized least mean fourth algorithm with improved transient and tracking behaviors. IEEE Trans. Signal Process. 64(18), 4805–4816 (2016). https://doi.org/10.1109/TSP.2016.2573747
E. Eweda, Stabilization of high-order stochastic gradient adaptive filtering algorithms. IEEE Trans. Signal Process. 65(15), 3948–3959 (2017). https://doi.org/10.1109/TSP.2017.2698364
F. Huang, J. Zhang, S. Zhang, Maximum versoria criterion-based robust adaptive filtering algorithm. IEEE Trans. Circuits Syst. II Express Briefs 64(10), 1252–1256 (2017). https://doi.org/10.1109/TCSII.2017.2671521
Z. Jin, L. Guo, Y. Li, The bias-compensated proportionate NLMS algorithm with sparse penalty constraint. IEEE Access 8, 4954–4962 (2020). https://doi.org/10.1109/ACCESS.2019.2962861
R.H. Kwong, E.W. Johnston, A variable step size LMS algorithm. IEEE Trans. Signal Process. 40(7), 1633–1642 (1992). https://doi.org/10.1109/78.143435
M. Li, L. Li, H.-M. Tai, Variable step size LMS algorithm based on function control. Circuits Syst. Signal Process. 32(6), 3121–3130 (2013). https://doi.org/10.1007/s00034-013-9598-z
J. Liu, S.L. Grant, A generalized proportionate adaptive algorithm based on convex optimization, in 2014 IEEE China Summit & International Conference on Signal and Information Processing (ChinaSIP). pp. 748–752 (2014). https://doi.org/10.1109/ChinaSIP.2014.6889344.
S.-C. Pei, C.-C. Tseng, Least mean p-power error criterion for adaptive FIR filter. IEEE J. Sel. Areas Commun. 12(9), 1540–1547 (1994). https://doi.org/10.1109/49.339922
S.-C. Pei, C.-C. Tseng, Adaptive IIR notch filter based on least mean p-power error criterion. IEEE Trans. Circuits Syst. II: Analog Digital Signal Process. 40(8), 525–528 (1993). https://doi.org/10.1109/82.242343
M.O. Sayin, N.D. Vanli, S.S. Kozat, A novel family of adaptive filtering algorithms based on the logarithmic cost. IEEE Trans. Signal Process. 62(17), 4411–4424 (2014). https://doi.org/10.1109/TSP.2014.2333559
H.-C. Shin, A.H. Sayed, Mean-square performance of a family of affine projection algorithms. IEEE Trans. Signal Process. 52(1), 90–102 (2004). https://doi.org/10.1109/TSP.2003.820077
B. Wang, T. Fang, Y. Dai, Method of Time reversal filter bank multicarrier underwater acoustic communication. 45(1), 38–44 (2020).
K. Xiong, Y. Zhang, S. Wang, Robust variable normalization least mean p-power algorithm. Sci. China Inf. Sci. 63(9), 199204 (2020). https://doi.org/10.1007/s11432-018-9888-0
S. Zhang, W. Zheng, J. Zhang, H. Han, A family of robust M-shaped error weighted least mean square algorithms: Performance analysis and echo cancellation application. IEEE Access 5, 14716–14727 (2017). https://doi.org/10.1109/ACCESS.2017.2722464
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant 52071164 and in part by the Postgraduate Research & Practice Innovation Program of Jiangsu Province under Grant KYCX22_3844.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no conflicts of interest to declare.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Cai, B., Wang, B., Zhu, B. et al. An Improved Proportional Normalization Least Mean p-Power Algorithm for Adaptive Filtering. Circuits Syst Signal Process 42, 6951–6965 (2023). https://doi.org/10.1007/s00034-023-02441-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00034-023-02441-z