
Abstract
Determination of the frequency of large earthquakes is of paramount importance for seismic risk assessment as large events contribute to significant fraction of the total deformation and these long return period events with low probability of occurrence are not easily captured by classical distributions. Generally, with a small catalogue these larger events follow different distribution function from the smaller and intermediate events. It is thus of special importance to use statistical methods that analyse as closely as possible the range of its extreme values or the tail of the distributions in addition to the main distributions. The generalised Pareto distribution family is widely used for modelling the events which are crossing a specified threshold value. The Pareto, Truncated Pareto, and Tapered Pareto are the special cases of the generalised Pareto family. In this work, the probability of earthquake occurrence has been estimated using the Pareto, Truncated Pareto, and Tapered Pareto distributions. As a case study, the Himalayas whose orogeny lies in generation of large earthquakes and which is one of the most active zones of the world, has been considered. The whole Himalayan region has been divided into five seismic source zones according to seismotectonic and clustering of events. Estimated probabilities of occurrence of earthquakes have also been compared with the modified Gutenberg–Richter distribution and the characteristics recurrence distribution. The statistical analysis reveals that the Tapered Pareto distribution better describes seismicity for the seismic source zones in comparison to other distributions considered in the present study.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The frequency-size distribution of earthquakes has attracted interest from many researchers starting with its first discussion by Ishimoto and Iida (1939) followed by Gutenberg and Richter (1944) which is one of the most common magnitude–frequency relations used in seismology. The Gutenberg–Richter law is effective with high accuracy for small and moderate magnitudes, but for small space–time volumes provides highly uncertain and sometimes unstable estimates because of the power-law character of the earthquake size distribution and insufficient instrumental and historical earthquake records for relatively small seismic regions (McCaffrey 1997; Holt et al. 2000). The law depends on the size of the catalogue and reveals no information about maximum magnitude.
The largest earthquake in a region is an important parameter in earthquake hazard assessment and disaster management. These large events contribute significantly to the total deformation, and the long return period events with low probability of occurrence are not easily captured by the classical distributions. The seismic hazard assessment exercises may fail to capture the very long return period events due to relatively short catalogue data available and may fail to model the tail portion of the occurrence models, for example with a Poisson model. The general methodologies to assess the largest magnitude are based on a seismotectonic modelling using past earthquake data and tectonics of the region. The absence of a well-documented earthquake cycle is a considerable impediment to quantifying seismic risk correctly. It is thus of special importance to develop statistical methods that analyse as closely as possible the range of its extreme values or the tail of the distributions in addition to the whole of the distributions. Several investigations (Bird and Kagan 2004; Cosentino et al. 1977; Kagan 1991, 1996, 1999, 2002a, b; Kijko and Sellevoll 1989, 1992; Knopoff et al. 1982; Main et al. 1999; Ogata and Katsura 1993; Pisarenko and Sornette 2003, 2004; Utsu 1999; Wu 2000; Pisarenko and Rodkin 2007) were conducted in the past for finding a suitable description of the tail of the magnitude frequency distribution. For the large event distribution Pacheco and Sykes (1992) suggested visual inspection, Sornette et al. (1996) pointed out Monte-Carlo simulations, Kagan (1997, 1999) and Kagan and Schoenberg (2001) suggested Maximum likelihood estimation of the proposed Pareto distribution tapered by an exponential distribution. Several parametric families, such as Gamma distributions (Main and Burton 1984; Kagan 1994, 1997), modified Pareto distribution (Kagan and Schoenberg 2001) and Weibull distributions (Laherrere and Sornette 1998) were suggested for earthquake moment distributions including the tail range, but none of these models could be universally accepted. One of the best known modifications of the G–R distribution (Kagan 1997; Kagan and Schoenberg 2001; Bird and Kagan 2004) was multiplication of the power law distribution of seismic moments (which corresponds to the modified G–R distribution of magnitudes) by an exponential taper.
To look into the behaviour of large events the Himalaya region has been taken as a case study. The Himalayan tectonic zone, where Indian plate drives under the Eurasian plate, rapidly releases strain over large areas generating great earthquakes with long intervals. The Himalayan arc extends over a distance of about 2900 km and has experienced five great earthquakes (1505, 1803, 1897, 1934 and 2015) with magnitudes exceeding 8 (M w) and numerous magnitudes 7 (M w). In the present study, theoretical distributions of earthquake size, especially dealing with large return periods of earthquakes, have been considered for testing various distributions.
1.1 Seismic Hazard Assessment Approaches
The distribution of earthquake magnitude in a given period of time can be described by a recurrence low. The following section describes the classical approach using the G–R distribution along with three of the probability distributions being used in the present study namely: Pareto, Truncated Pareto, and Tapered Pareto distributions.
1.2 Classical Approach
The classical approach relates the cumulative occurrence rate of earthquakes. Usually the G–R distribution indicated a linear relationship on a log linear plot between earthquake magnitude M and the total number of events N(M) greater than equal to M. The completeness is considered with bounded G–R distribution. If the catalogue completeness threshold is constant in time, we can analyse two distributions a temporal sequence of earthquake numbers and earthquake size. Usually the temporal distribution of the number of events follows memoryless distribution, i.e., all events are independent of other events (Molchan and Podgaetskaya 1973; Kijko and Graham 1998). The density function, n(M), defining the occurrence rate of earthquakes per unit magnitude at magnitude M can be defined as
where M min is lower threshold magnitude and N(M min) is the cumulative rate of occurrence of earthquakes with magnitude M ≥ M min and β = b × ln 10 where b is the seismicity constant in the G–R distribution. In reality, the earthquake magnitude for a seismic source has to be characterised by an upper bound. Thus, a truncation of the density function of Eq. (1) is necessary in practical hazard analysis applications. The corresponding density function n(M) becomes
where H(·) is the Heaviside step function. To have correct number of earthquakes with magnitude greater than or equal to M min, this needs to be normalised by \( (1 - {\text{e}}^{{ - \beta (M_{\hbox{max} } - M_{\hbox{min} } )}} ) \)
The corresponding cumulative distribution function is obtained as
In the relationship given by Eq. (4), the occurrence rate N(M) reduces exponentially to zero as M approaches M max, but the total number N(M min) of earthquakes with magnitudes greater than or equal to the threshold magnitude M min remains unaltered. This model is therefore termed as the modified Gutenberg–Richter or exponential recurrence model.
Some seismic sources are seen to produce more frequent earthquakes in a narrow range of magnitude around M max than that described by the exponentially decaying model of Eqs. (3) and (4). For such cases, characteristic recurrence model described by Aki (1983) and Schwartz and Coppersmith (1984) may be considered as more appropriate. Youngs and Coppersmith (1985) proposed the characteristic earthquake model for certain faults which experience the large earthquakes. The density function for the characteristics recurrence model can be defined as
where \( M_{\text{ch}} = M_{ \hbox{max} } - 1 \) and \( M^{\prime } = M_{\text{ch}} - 0.5. \) The corresponding cumulative distribution function can be written as
The characteristic recurrence model is supported theoretically as well as by observations by Swan et al. (1980), Papageorgiou and Aki (1983) and others.
1.3 Pareto Distribution
The classical approach of Gutenberg and Richter (1944) shows a power-law decay of magnitude size. The Pareto distribution is used to describe a phenomenon which exhibit power-law decay of sizes above a minimum threshold size. The Pareto distribution (Coles 2001) is useful to study the tail of the distribution of the earthquake events with magnitude above a predefined threshold. The Pareto distribution allows fitting efficiently the seismic moment–frequency distribution only in the tail portion which contains reliable moment and occurrence times of the extreme largest events. Therefore, even an incomplete seismicity containing reliable seismic moment and times of the largest events becomes useful to estimate seismic hazard parameters together with the Pareto distribution (Kagan 1993).
Statistical tests of whether a Pareto or some other distribution best describes the tail of a given empirical distribution are discussed by Kagan (2002a) and Clauset et al. (2009). The earthquake magnitude is related to the scalar seismic moment M 0 as (Hanks and Kanamori 1979)
where \( M_{0} = a \mu d \) expressed in dyne-cm units (where \( \mu \) is an average shear elastic coefficient of the crust, d is the average slip of the earthquake over a surface d of rupture). The G–R distribution translated from magnitude to seismic moment using Eq. (7) and the number \( N\left( {M_{0} } \right) \) of earthquakes with seismic moment above \( M_{0} \) becomes
where β = 2/3 × b is the index parameter of the distribution. Introducing the appropriate threshold seismic moment \( M_{0t} \), one obtains the complementary of the distribution function of Pareto for seismic moments:
The Tails function \( \bar{F}\left( {M_{0} } \right) \) as having power-law tails. This description is especially useful when describing and modelling processes with large deviations, a situation where one is primarily interested in the largest possible observations. In seismology, the Pareto distribution describes the distribution of the seismic moment released in earthquakes as a power-law.
1.4 Truncated Pareto distribution
The Pareto distribution is unbounded; however, each seismic source zone can release only limited energy, implicating that the Pareto distribution must be modified for large seismic moments. This problem is solved by introducing an additional parameter called the maximum moment \( M_{0U} \) into the distribution. Anderson and Luco (1983) proposed a truncation from above at \( M_{0U} \) of either the cumulative distribution, or its density distribution.
For the Pareto distribution with truncation at both ends, the probability density is
and the Tail function is
Similar considerations led to the use of the Tapered Pareto distribution by Jackson and Kagan (1999), Vere-Jones et al. (2001) and Kagan and Schoenberg (2001).
1.5 Tapered Pareto distribution
The Tapered distribution has an exponential taper applied to the cumulative number of events with seismic moment larger than \( M_{0} \). The corresponding Tail function becomes
The corresponding probability density function is
where \( M_{0x} \) is the seismic moment for the largest earthquake event. Some researchers (Jackson and Kagan 1999; Vere-Jones et al. 2001; Kagan and Schoenberg 2001) have proposed that earthquake sizes may be well described by a Tapered Pareto distribution which has small exponential tails but is otherwise similar to the Pareto distribution.
2 Parameter estimation of distributions
In the present study, the parameters β and N(M min) of Eq. (4) are estimated using available data on past earthquakes. The parameter β for a part of the catalogue with the minimum magnitude of completeness M c can then be evaluated using the maximum likelihood method (Aki 1965; Utsu 1965) as \( \left( {\bar{M} - M_{\text{c}} } \right)^{ - 1} \) where \( \bar{M} \) is the average of all the available magnitudes greater than or equal to M C during the period of completeness. Kijko and Smit (2012) have extended the Aki-Utsu b value estimator for magnitude grouped data. If \( M_{\text{C}}^{1} ,{\kern 1pt} \;M_{\text{C}}^{2} , \ldots ,M_{\text{C}}^{S} \) are the minimum magnitudes of completeness for periods \( t_{1} ,\;t_{2} , \ldots ,t_{S} \) with number of events in various intervals as \( n_{1} ,\;n_{2} , \ldots ,n_{S} \), respectively, then the generalised Aki-Utsu \( \beta \)-value estimator is given by
where \( r_{i} = n_{i} /N \) with N as the total number of events in all the intervals of completeness and \( \beta_{i} \) is the classic Aki-Utsu estimator for ith interval. Kijko and Smit (2012) have given an expression for the maximum likelihood estimator of occurrence rate, \( N(M_{\hbox{min} } ) \) of events with magnitude equal to or greater than M min as
If M min is the minimum magnitude of completeness for the entire duration of the catalogue, then there is only one interval with \( M_{l}^{1} = M_{\hbox{min} } \) and t 1 = T for which the relation of Eq. (15) gives \( N(M_{\hbox{min} } ) = N/T \), as expected.
Pareto distribution has one parameter β for estimation and the maximum likelihood estimator method has been used to estimate β. For Pareto distribution the log-likelihood function for n observations of the seismic moment is
The maximum likelihood equation of \( \beta \) (Deemer and Votaw 1955; Aki 1965; Kagan 2002a) is
with standard error \( \sigma_{\beta } = \frac{{\hat{\beta }}}{\sqrt n } \) The Pareto distribution has no upper limit of seismic moment and incorporates the maximum moment \( M_{0u} \) in Truncated Pareto distribution. For the Truncated Pareto distribution the log-likelihood function for n observations of the seismic moment is
The maximum likelihood equation of \( \hat{\beta } \) for Truncated Pareto distribution (Kagan 2002a) is
β value is estimated by solving it iteratively. The standard error of \( \hat{\beta } \) equation is
To estimate \( M_{0u} \), Pisarenko (1991) and Kijko and Graham (1998) proposed a method based on statistical moment of Truncated Pareto distribution which is
The log likelihood equation of Tapered Pareto distribution is
Maximum likelihood equations of \( M_{0} \) x and \( \beta \) for Tapered Pareto distribution are
where \( \theta = \frac{1}{{M_{0x} }} \). For both Tapered and Truncated Pareto distribution, the maximum likelihood equation of β is determined by the Eqs. (23) and (24) by iteration. To look into the behaviour of large events using the above said distributions, their application has been tested by taking the Himalaya region as case study.
3 The Himalayas: A Case Study
The Himalayan front is seismically one of the most active regions of the world and has experienced both great to moderate earthquakes in the recent past. The Himalayan tectonic zone, being a collision plate boundary, is manifested with a number of north-dipping thrusts that are exposed at the surface. During the past few decades the Himalayan region has been studied fairly extensively in terms of present deformation and the seismicity is mostly attributed to the continent–continent collision where the Indian plate is underthrusting the Eurassian plate. India has been thrusting underneath Tibet since ~55 Ma (Besse and Courtillot 1988; Dewey et al. 1989). India’s convergence into Asia is approximately 18 mm/years (Wang et al. 2001). Out of 36 mm/year (SSE) India–Sunda plate motion, about ~16 mm/year motion is accommodated in Indo-Burmese Fold and Thrust Belt, both as normal convergence (~6 mm/year) and active slip (~7–11 mm/year) in this region (Barman et al. 2017). A global GPS measurement was done and published in http://gsrm2.unavco.org/model/velocities/GEM_GSRM_VelocityViewer.html where it is shown that the convergence rate across the Himalaya is well estimated with 13–16 mm/year. This is significantly lower than that claimed by many authors (Bilham et al. 1997; Kundu et al. 2014; Ader et al. 2012). The accumulated strain energy is being released in the form of major earthquakes. The catalogue on the occurrence of earthquakes from Himalayan region has been compiled for its use in the proposed modelling to estimate the various probabilities of occurrence.
4 Data and Resources
The published earthquake information has been used to compile earthquake catalogue for the present study. In addition to the catalogue compiled by I. D. Gupta (personal communication) for the period 1255–2015, the main sources of non-instrumental and historical data considered for periods prior to 1890 are Baird-Smith (Baird Smith 1843a, b), Oldham (1883), Milne (1911), Lee et al. (1976), and Quittmeyer and Jacob (1979). For the consideration of early instrumental data for the period from 1890 to 1964 Gutenberg and Richter (1954), Gutenberg (1956) and Rothe (1969) are considered. Some data have also been added from improved publications also namely Abe (1981), Abe and Noguchi (1983a, b), Pacheco and Sykes (1992), Engdahl and Villaseñor (2002), Ambraseys (2000), Ambraseys and Douglas (2004), and Martin and Szeliga (2010). The instrumental data for 1964–2015 have been collected from the website of International Seismological Centre (ISC) http://www.isc.ac.uk/of UK, National Earthquake Information Centre (NEIC) of USGS http://earthquake.usgs.gov/earthquake/search/and additional data have been taken from Indian Meteorological Department (IMD).
The compiled catalogue is available in local magnitude Richter’s scale M L, surface wave magnitude M s, Body wave magnitude m b, and moment magnitude M w. For the homogenization, all magnitudes of pre instrumental data are converted into moment magnitude M w, by using empirical conversion relations (Gutenberg 1956; Chung and Bernreuter 1981; Hanks and Kanamori 1979). For instrumental data the Scordilis (2006) conversion relation has been used. Scordilis (2006) has developed the conversion relations from new M S and m b to M W using a very large worldwide database from ISC, NEIC and CMT catalogues for the period 1965–2003.
The window method is used for removing foreshocks and aftershock proposed by the Uhrhammer (1986). Initially 9050 earthquake events were present in the catalogue and after declustering the catalogue we had 5220 independent earthquake events. The seismicity thus obtained was plotted along with the tectonic of the Himalaya region.
The division of the study area into seismotectonic segments which are homogeneous parts of the seismic source zones is one of the basic requirements for the application of the estimation procedure for seismic hazard parameters. The Himalaya region (26°–38°N and 68°–98°E) is seismically very active and highly complicated from a seismotectonic point of view. The entire Himalayas has been divided into five seismic source zones based on seismotectonic, seismicity distribution, topography variations, and various constraints that were considered in previous studies (Sharma 2003; Sharma and Lindholm 2012; Shanker and Sharma 1997; Sharma and Arora 2005). The five seismic source zones along the tectonic feature of area are as follows:
Seismic Source Zone I 30.92°–36.13°N and 73.71°–79.91°E
Seismic Source Zone II 27.85°–33.09°N and 77.44°–84.39°E
Seismic Source Zone III 26.27°–30.71°N and 82.17°–87.76°E
Seismic Source Zone IV 26.06°–29.94°N and 87.12°–91.09°E
Seismic Source Zone V 26.94°–30.92°N and 91.09°–96.63°E
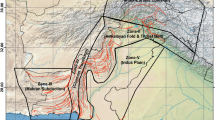
The seismic source zones SSZ I to SSZ V are shown in Fig. 1 which also shows the main regional features and epicentres of M w ≥4.0 that have occurred during the period 1255–2015.

Characterization of 5 seismic source zones in the Himalaya regions on the basis of seismicity and tectonics. The epicentral distribution of independent earthquakes of M W ≥ 5.0 that occurred during the period 1255–2015 are also shown in the figure along with seismic source zones
The number of observed events for all seismic source zones along with the cumulative number of events in each seismic source zone is shown in Fig. 2.

Distribution of number of events with respect to magnitude in each seismic source zone and magnitude of completeness estimated for all seismic source zones as defined in Fig. 1
Further, the magnitude of completeness estimated for the five seismic source zones using Woessner and Wiemer (2005) methods is shown in Fig. 2. The magnitudes of completeness for the five seismic source zones are presented in Table 1. This has been used for further estimation of parameters. The periods of completeness for different magnitude ranges has been estimated by the Stepp (1972) Method.
5 Application of Probability Distributions
As a practical consideration, we simply used five statistical probability models for illustrating the of earthquake occurrence. In the present study, the Tail distribution functions of the Pareto, the Truncated Pareto and the Tapered Pareto distributions are expressed by Eqs. (9), (11), and (12), respectively. For the purpose of comparison with the modified G-R distribution and the characteristics recurrence distribution, Eqs. (4) and (6) have been normalised by \( N(M_{\hbox{min} } \le M < M{}_{\hbox{max} }) \), which gives the complementary of the distribution function of the magnitude. Then the complementary of the distribution function or tail function for modified G–R may be written as
and for the characteristic recurrence distribution as
These probabilistic distributions have been considered for five seismogenic sources to revisit the return periods of large earthquakes for each seismic source zone.
In the present study the Chi Square test has been used to distinguish between the probability distributions. The Pareto, Truncated Pareto, and Tapered Pareto distribution are applied to describe the probability of occurrence of seismic moment for each seismic source zone. Then the results are compared with the modified G–R and the Characteristic earthquake recurrence models.
The modified G–R distribution uses two parameters: β and \( N(M_{ \hbox{min} } ) \) for estimating the probability of earthquake occurrence. To estimate the values of β and \( N(M_{ \hbox{min} } ) \) for each seismic source zone, the maximum likelihood method has been applied and the values of parameters of the G–R distribution are presented in Table 1. The highest and the lowest values of \( N(M_{ \hbox{min} } ) \) have been observed for SSZ V and SSZ II, respectively, which clearly indicates the seismic source zones having the most and least seismic activity within the study area.
Further, the CDF has been estimated using Eqs. (4) and (6) for the modified G–R and the characteristics recurrence models, respectively. While the modified G–R model decays smoothly (say after magnitude 7), the characteristic model shows different behaviour for higher magnitude as shown in Fig. 3. Figure 3 shows that, for each seismic source zone, the modified G–R distribution yields the lowest probability of occurrence of earthquake events while the characteristic distribution estimates the highest for large earthquakes events.

Cumulative rate of occurrence using the modified G–R and the charecteristics recurrence models for each seismic source zone. Observed data is also plotted for each seismic source zone
The Pareto distribution has only one parameter β , which has been estimated using maximum likelihood method along with its standard error \( \sigma_{\beta } \) for all seismic source zones using Eq. (17). The β values thus estimated are given in Table 2. The Truncated Pareto uses two parameters: β and \( M_{0U} \) for estimation of probability of occurrence of earthquake events. The maximum likelihood estimates of the values of β and \( M_{0U} \) for truncated Pareto distribution for each seismic source zones have been estimated using Eqs. (19) and (21) and the same are also reported in Table 2. The Tapered Pareto distribution also uses two parameters: β and \( M_{0x} \), and these two can be estimated by solving maximum likelihood equations of β and \( M_{0x} \) as given in Eqs. (23) and (24), respectively. The values of different parameters used in Pareto, Truncated Pareto, and Tapered Pareto distributions are shown in Table II for all seismic source zones.
The β estimation for the Pareto distribution resulted in relatively higher values than the Truncated and Tapered Pareto distribution for most of the seismic source zones. Table 2 shows that the β parameter of the Pareto distribution is highest for SSZ V and the estimated upper seismic moment using the Truncated Pareto is larger than the Tapered Pareto for all five seismic source zones.
The probability of occurrence of seismic events or the Tail functions of the Pareto, the Truncated Pareto, and the Tapered Pareto Distributions have been estimated using Eqs. (9), (11), and (12), respectively, for all seismic source zones and are shown in Fig. 4. Figure 4 reveals that the modified G–R yields the lowest probabilities of occurrence while the Characteristic distribution estimates are on the higher side. One of the conspicuous interpretations made from Fig. 4 is the linearity of Pareto distribution on log–log scale showing that it is not capturing the behaviour of other distributions at higher magnitudes as shown in the Fig. 4.

Probability of occurrence with respect to seismic moment for SSZ1, SSZ2, SSZ3, SSZ4, and SSZ5 using various distributions
The performance of Chi Square test on five distributions for all the seismic source zones has been carried out, and permitted acceptance of all considered probabilistic distributions for further use.
The probability of occurrence of large earthquake events, i.e., 6, 7 and 8 (M w) as defined by their seismic moments was estimated in different seismic source zones using the Pareto, Truncated Pareto, and Tapered Pareto distributions. The probabilities are comparable for the three distributions at magnitude 6, but it differs for magnitude 8 viz. while the Pareto gives 0.0013, 0.0024, 0.035, 0.000112, and 0.00052, respectively, for seismic source zone SSZ I to SSZ V, the Tapered Pareto gives 0.000563, 0.0013, 0.0012, 0.0.000131, and 0.000397, respectively, for seismic source zone SSZ I to SSZ V and Truncated Pareto gives values in between. The results are given in Table 3.
One of the conspicuous conclusions obtained is that due to the high seismicity in SSZ V, there is a continuous release of strain energy and hence, the probability of occurrence of a large event is the least here. On the other hand, SSZ III possesses the highest susceptibility of occurrence of a large event. However, the results tend to vary when a different set of distributions has been applied.
For seismic source zone SSZ I, the result shows that the Pareto distribution yields higher probability of occurrence at seismic moment 2E+26 dyne-cm (6.8 M). However, for more than 2E+26 dyne-cm (6.8 M w) the characteristics model shows higher probability (see Fig. 4). The large earthquakes are of magnitude 8.5 and 8 which occurred in 1555 (Kashmir) and 1905 (Kangra), respectively. The seismicity includes activity along the Herat fault north of Kabul, the Chaman fault, and the mountain range in the Pamir Knot with thrust type of faulting. Seismic source zone SSZ II includes the MBT, and the Indus Suture zone and the probability of occurrence for all earthquake events is the highest when estimated using the Pareto Distribution and the lowest for the modified G–R distribution (Fig. 4). The observed largest magnitude is 8.2, which occurred in 1505.
In the seismic source zone SSZ III the largest event was the Nepal–Bihar Earthquake (magnitude 8.1) which occurred in 1934. Recently, a large earthquake of magnitude 7.8 occurred on 25th April 2015 in Nepal. The probability of occurrence estimated by the Pareto Distribution is observed to be higher for all magnitude ranges, and the modified G–R distribution yields the lowest value of the same (Fig. 4). For seismic source zone SSZ IV, the largest event of magnitude 6.8 occurred in 1951. The probability of occurrence estimated by the characteristic distribution is the highest while the modified G–R distribution shows the lowest value of probability of occurrence for entire seismic moment range (Fig. 4).
The seismic source zone SSZ V is the most seismically active region in the Himalayan belt and includes the junction of three plates, namely the Indian plate, Eurasian plate, and Burmese plate. This has experienced great earthquakes of magnitude M w 8.1 in 1897 (Assam), and the probability of occurrence estimated by Characteristic distribution is on the higher side as compared to other distributions for large seismic moment values. The modified G–R distribution shows the lowest value of probability of occurrence for same values (Fig. 4). The modified G–R distribution and the Tapered Pareto distribution show comparable probability of occurrence for all events. The Chi Square test shows the Tapered Pareto distribution is most appropriate one for all seismic source zones viz., SSZ I to SSZ V.
6 Conclusion
There are several statistical distribution models which are used to describe earthquake occurrence. Due to short catalogues it is difficult to select any particular distribution which follows realistic trends as per the size and the return periods, especially in case of large earthquakes. Himalayas are one of the cases where multiple collisions and existence of great earthquakes with large return periods implicates testing of such statistical distributions which considers the large return periods. It is thus of special importance to use statistical methods that analyse as closely as possible the range of its extreme values or the tail of the distributions rather than the whole of the distributions. In the present study, an attempt has been made to compare different distribution of seismic moment for earthquakes in Himalayan region. The whole Himalaya region has been divided into five seismic source zones. The probability of occurrence in Himalaya region has been estimated using the Pareto, the Truncated Pareto, and the Tapered Pareto, and compared with the modified G–R, and the characteristic recurrence distribution using an updated and reliable earthquake catalogue for the period 1255–2015. For each seismic source zone, Chi Square test performed to set the selection criteria of the best fit distribution. The results show that the Tapered Pareto distribution better describes seismicity for each of the seismic source zones. The earthquake occurrence is a complex phenomenon in itself and interaction of sources during pre and post-earthquake along with the assumption that each event considered is an independent event are some of the factors which necessarily implicate fitting of different distributions. The distribution for estimating the probability of occurrence in all seismic source zones considered using various distribution models is informative and useful from engineering point of view. The differences in the probabilities estimated using the different distributions will have bearing on the ultimate results of seismic hazard assessment exercises and hence it is recommended to use different statistical models which fit best in the individual seismic source zones in Himalayas.
References
Abe, K. (1981). Magnitudes of large shallow earthquake from 1904 to 1980. Physics of the Earth and Planetary Interiors, 27, 72–92.
Abe, K., & Naguchi, S. (1983a). Determination of magnitude for large shallow earthquake 1898–1917. Physics of the Earth and Planetary Interiors, 32, 45–59.
Abe, K., & Naguchi, S. (1983b). Revision of magnitude for large shallow earthquake 1897–1912. Physics of the Earth and Planetary Interiors, 33, 1–11.
Ader, T., Avouac, J., Jing, L., Hélène, L., Bollinger, L., Galetzka, J., et al. (2012). Convergence rate across the Nepal Himalaya and interseismic coupling on the Main Himalayan Thrust: Implications for seismic hazard. Journal of Geophysical Research, 117, B04403.
Aki, K. (1965). Maximum likelihood estimate of b in the formula log N = a–bM and its confidence limits. Bulletin Earthquake Research Institute University of Tokyo, 43, 237–239.
Aki, K. (1983). Seismological evidence in support of the existence of “Characteristic Earthquakes”. Earthquake Notes, 54, 60–61.
Ambraseys, N. (2000). Reappraisal of north-Indian earthquakes at the turn of the 20th century. Current Science, 79, 101–114.
Ambraseys, N., & Douglas, J. J. (2004). Magnitude calibration of north Indian earthquakes. Geophysical Journal International, 159, 165–206.
Anderson, J. G., & Luco, J. E. (1983). Consequences of slip rate constraints on earthquake occurrence relation. Bulletin of the Seismological Society of America, 73, 471–496.
Baird Smith, R. (1843a). Memoir of Indian earthquakes—part I. Journal of the Asiatic Society of Bengal, 12(136), 257–293.
Baird Smith, R. (1843b). Memoir of Indian earthquakes—part II. Journal of the Asiatic Society of Bengal, 12(144), 1029–1056.
Barman, P., Jade, S., Shrungeshwara, T. S., Kumar, A., Bhattacharyya, S., Ray, J. D., Jagannathan, S., & Jamir, W. M. (2017). Crustal deformation rates in Assam Valley, Shillong Plateau, Eastern Himalaya, and Indo-Burmese region from 11 years (2002–2013) of GPS measurements. International Journal of Earth Sciences, 106(6), 2025–2038.
Besse, J., & Courtillot, V. (1988). Paleogeographic maps of the continents bordering the Indian Ocean since the early Jurassic. Journal of Geophysical Research, 93(B10), 11791–11808.
Bilham, R., Larson, K., Freymueller, J., & Project ldylhim Members. (1997). GPS measurements of presentday convergence across the Nepal Himalaya. Nature, 386, 61–64.
Bird, P., & Kagan, Y. Y. (2004). Plate-tectonic analysis of shallow seismicity: apparent boundary width, beta, corner magnitude, coupled lithosphere thickness, and coupling in seven tectonic settings. Bulletin of the Seismological Society of America, 94(6), 2380–2399.
Chung, D. H., & Bernreuter, D. L. (1981). Regional relationships among earthquake magnitude scales. Reviews of Geophysics and Space Physics, 19(4), 649–663.
Clauset, A., Shalizi, C. R., & Newman, M. E. J. (2009). Power-law distributions in empirical data. SIAM Review, 51, 661–703.
Coles, S. (2001). An introduction to statistical modelling of extreme values. London: Springer Series in Statistics.
Cosentino, P., Ficara, V., & Luzio, D. (1977). Truncated exponential frequency-magnitude relationship in the earthquake statistics. Bulletin of the Seismological Society of America, 67, 1615–1623.
Deemer, W. L., & Votaw, D. F. (1955). Estimation of parameters of truncated or censored exponential distributions. The Annals of Mathematical Statistics, 26, 498–504.
Dewey, J. F., Cande, S., & Pitman, W. C. (1989). The tectonic evolution of the India/Eurasia collision zone. Ecolgae Geologicae Halvetiae, 82(3), 717–734.
Engdahl, E. R., & Villaseñor, A. (2002). Global Seismicity: 1900–1999, chapter 41. In: Int. Handbook of Earthq. and Eng. Seism., vol. 81A, pp. 665–690.
Gutenberg, B. (1956). Great earthquakes 1896–1903. EOS, 37, 608–614.
Gutenberg, B., & Richter, C. F. (1944). Frequency of earthquakes in California. Bulletin of the Seismological Society of America, 34(4), 1985–1988.
Gutenberg, B., & Richter, C. F. (1954). Seismicity of the earth (2nd ed.). Princeton: Princeton Press.
Hanks, T. H., & Kanamori, H. (1979). A moment magnitude scale. Journal of Geophysical Research, 84, 2348–2350.
Holt, W. E., Chamot-Rooke, N., Le Pichon, X., Haines, A. J., Shen-Tu, B., & Ren, J. (2000). Velocity field in Asia inferred from quaternary fault slip rates and global positioning system observations. Journal of Geophysical Research Solid Earth, 105, 19185–19209.
Ishimoto, M., & Iida, K. (1939). Observations of earthquakes registered with the microseismograph constructed recently. Bulletin Earthquake Research Institute University of Tokyo, 17, 443–478.
Jackson, D. D., & Kagan, Y. Y. (1999). Testable earthquake forecasts for 1999. Seismological Research Letters, 70(4), 393–403.
Kagan, Y. Y. (1991). Likelihood analysis of earthquake catalogues. Geophysical Journal International, 106(1), 135–148.
Kagan, Y. Y. (1993). Statistics of characteristic earthquakes. Bulletin of the Seismological Society of America, 83(1), 7–24.
Kagan, Y. Y. (1994). Observational evidence for earthquakes as a nonlinear dynamic process. Physica D Nonlinear Phenomena, 77, 160–192.
Kagan, Y. Y. (1996). Comment on “The Gutenberg–Richter or characteristic earthquake distribution, which is it? By Steven G. Wesnousky. Bulletin of the Seismological Society of America, 86(1a), 274–285.
Kagan, Y. Y. (1997). Earthquake size distribution and earthquake insurance. Communications in statistics. Stachastic Models, 13(4), 775–797.
Kagan, Y. Y. (1999). Universality of seismic moment–frequency relation. Pure and Applied Geophysics, 155, 537–573.
Kagan, Y. Y. (2002a). Seismic moment distribution revisited: I. Statistical results. Geophysical Journal International, 148, 520–541.
Kagan, Y. Y. (2002b). Seismic moment distribution revisited: II. Moment conservation principle. Geophysical Journal International, 149, 731–754.
Kagan, Y. Y., & Schoenberg, F. (2001). Estimation of the upper cut-off parameter for the Tapered Pareto distribution. Journal of Applied Probability, 38A, 158–175. (Supplement: Festscrift for David Vere-Jones, D. Daley, editor).
Kijko, A., & Graham, G. (1998). Parametric-historic procedure for probabilistic seismic hazard analysis. Part I: Estimation of maximum regional magnitude Mmax. Pure and Applied Geophysics, 152, 413–442.
Kijko, A., & Sellevoll, M. A. (1989). Estimation of earthquake hazard parameters from incomplete data files. Part I, Utilization of extreme and complete catalogues with different threshold magnitudes. Bulletin of the Seismological Society of America, 79, 645–654.
Kijko, A., & Sellevoll, M. A. (1992). Estimation of earthquake hazard parameters from incomplete data files. Part II, incorporation of magnitude heterogeneity. Bulletin of the Seismological Society of America, 82, 120–134.
Kijko, A., & Smit, A. (2012). Extension of the Aki-Utsu b-value estimator for incomplete catalogs. Bulletin of the Seismological Society of America, 102(3), 1283–1287.
Knopoff, L., Kagan, Y., & Knopoff, R. (1982). b-values for foreshocks and aftershocks in real and simulated earthquake sequences. Bulletin of the Seismological Society of America, 72(5), 1663–1675.
Kundu, B., Yadav, R. K., Bali, B. S., Chowdhury, S., & Gahalaut, V. K. (2014). Oblique convergence and slip partitioning in the NW Himalaya: Implications from GPS measurements. Tectonics, 33, 2013–2014.
Laherrere, J., & Sornette, D. (1998). Stretched exponential distributions in nature and economy: ‘‘Fat tails’’ with characteristic scales. European Physical Journal B Condensed Matter and Complex Systems, 2, 525–539.
Lee, W. H. K., Wu, F. T., & Jacobsen, C. (1976). A catalog of historical earthquakes in China compiled from recent Chinese publications. Bulletin of the Seismological Society of America, 66, 2003–2016.
Main, I., & Burton, P. W. (1984). Information Theory and the Earthquakes Frequency magnitude Distribution. Bulletin of the Seismological Society of America, 74, 1409–1426.
Main, Y., Irving, D., Musson, R., & Reading, A. (1999). Constraints on frequency-magnitude relation and maximum magnitudes in the UK from observed seismicity and glacio-isostatic recovery rates. Geophysical Journal International, 137, 535–550.
Martin, S., & Szeliga, W. (2010). A catalog of felt intensity data for 570 earthquakes in India from 1636 to 2009. Bulletin of the Seismological Society of America, 100(2), 562–569.
McCaffrey, R. (1997). Statistical significance of the seismic coupling coefficient. Bulletin of the Seismological Society of America, 87, 1069–1073.
Milne, J. (1911). A catalogue of desetructive earthquakes. In: A.Ad. 7 to A.D. 1899. Br. Assoc. Advan. Sci. Rept. Postmouth Meeting, 1911, App.1, pp. 649–740
Molchan, G. M. & V.M. Podgaetskaya (1973). Parameters of global seismicity, I in computational seismology, 6, Kelisborok, V.I., pp. 44–66, Nauka, Mascow.
Ogata, Y., & Katsura, K. (1993). Analysis of temporal and special heterogeneity of magnitude frequency distribution inferred from earthquake catalogues. Geophysical Journal International, 113, 727–738.
Oldham, T. (1883). A catalogue of Indian earthquakes from the earliest time to the end of A.D. 1869. Memoirs of the Geological Survey of India, 29, 163–215.
Pacheco, J. F., & Sykes, L. R. (1992). Seiismic Moment catalog of large earthquake, 1900 to 1989. Bulletin of the Seismological Society of America, 82, 1306–1349.
Papageorgiou, A. A., & Aki, K. (1983). A specific barrier model for the quantitative description of inhomogenous faulting and the prediction of strong ground motion. Bulletin of the Seismological Society of America, 73, 693–722.
Pisarenko, V. F. (1991). Statistical evaluation of maximum possible magnitude. Izvestia, Earth Physics, 27, 757–763.
Pisarenko, V. F., & Rodkin, M. V. (2007). Distributions with heavy tails: Application to the analysis of catastrophes, computational seismology issue 38, 242 p. Pure and Applied Geophysics, 155, 509–535.
Pisarenko, V. F., & Sornette, D. (2003). Characterization of the frequency of extreme earthquake events by the generalized pareto distribution. Pure and Applied Geophysics, 160(2003), 2343–2364.
Pisarenko, V. F., & Sornette, D. (2004). Statistical detection and characterization of a deviation from the Gutenberg–Richter distribution above magnitude 8. Pure and Applied Geophysics, 161, 839–864.
Quittmeyer, R. C., & Jacob, K. H. (1979). Historical and modern seismicity of Pakistan, Afghanistan, Northwest India, and Southeastern Iran. Bulletin of the Seismological Society of America, 69(3), 773–823.
Rothe, J. R. (1969). The Seismicity of the Earth 1953–1965. Earth Sciences: UNESCO.
Schwartz, D. P., & Coppersmith, K. J. (1984). Fault behavior and characteristic earthquakes: Examples from the Wasatch and San Andreas Fault zones. Journal of Geophysical Research: Solid Earth, 89(B7), 5681–5698.
Scordilis, E. M. (2006). Empirical global relations converting M S and m b to moment magnitude. Journal of Seismology, 10, 225–236.
Shanker, D., & Sharma, M. L. (1997). Statistical analysis of completeness of seismicity data of the Himalayas and its effect on earthquake hazard determination. Bulletin of the Indian Society of Earthquake Technology, 34(3), 159–170.
Sharma, M. L. (2003). Seismic hazard in Northern India region. Seismological Research Letters, 74(2), 140–146.
Sharma, M. L., & Arora, M. K. (2005). Prediction of seismicity cycles in the Himalayas using artificial neural network. Acta Geophysica Polonica, 53(3), 299–309.
Sharma, M. L., & Lindholm, C. (2012). Earthquake hazard assessment for Dehradun, Uttarakhand, India, including a characteristic earthquake recurrence model for the Himalaya Frontal Fault (HFF). Pure and Applied Geophysics (PAGEOPH), 169, 1601–1617.
Sornette, D., Knopoff, L., Kagan, Y. Y., & Vanneste, C. (1996). Rank-ordering statistics of extreme events: Application to the distribution of large earthquakes. Journal of Geophysical Research, 101, 13883–13893.
Stepp, J. C. (1972). Analysis of completeness of the earthquake sample in the Puget Sound area and its effect on statistical estimates of earthquake hazard. In: Procs. Int. Conf. on Microzonation, Seattle, Washington, vol. 2, pp. 897–910.
Swan, F. H., III, Schwartz, D. P., & Cluff, L. S. (1980). Recurrence of moderate-to-large magnitude earthquakes produced by surface faulting on the Wasatch fault zone, Utah. Bulletin of the Seismological Society of America, 70, 1431–1462.
Uhrhammer, R. (1986). Characterization of northern and central California Seismicity. Earthquake Notes, 57(1), 21.
Utsu, T. (1965). A method for determining the value of b in the formula log n = a – bM showing the magnitude frequency relation for earthquakes. Geophysical Bulletin Hokkaido University, 13, 99–103.
Utsu, T. (1999). Representation and analysis of the earthquake size distribution: A historical review and some new approaches. Pure and Applied Geophysics, 155(2–4), 509–535.
Vere-Jones, D., Robinson, R., & Yang, W. Z. (2001). Remarks on the accelerated moment release model: Problems of model formulation, simulation and estimation. Geophysical Journal International, 144, 517–531.
Wang, Q., Pei-Zhen Zhang, J. T., Freymueller, R., Bilham, K. M., Larson, X., Lai, X., et al. (2001). Present-day crustal deformation in china constrained by global positioning system measurements. Science, 294, 574.
Woessner, J., & Wiemer, S. (2005). Assessing the quality of earthquake catalogues: Estimating the magnitude of completeness and its uncertainty. Bulletin of the Seismological Society of America, 95(2), 684–698.
Wu, Z. L. (2000). Frequency-size distribution of global seismicity seen from broad-band radiated energy. Geophysical Journal International, 142, 59–66.
Youngs, R. R., & Coppersmith, K. J. (1985). Implications of fault slip rates and earthquake recurrence models to probabilistic seismic hazard estimates. Bulletin of the Seismological Society of America, 75(4), 939–964.
Acknowledgements
The earthquake catalogue has been compiled from various sources, namely IMD, USGS, NEIC, and ISC. The help of Dr. I. D. Gupta in compiling the catalogue for the study is acknowledged thankfully. We would like to show our gratitude to Dr. Conrad C. Lindholm who has very thoroughly reviewed the manuscript which has technically improved the article a lot.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Chaudhary, C., Sharma, M.L. Probabilistic Models For Earthquakes With Large Return Periods In Himalaya Region. Pure Appl. Geophys. 174, 4313–4327 (2017). https://doi.org/10.1007/s00024-017-1667-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00024-017-1667-y