
Abstract
Face forgery detection in compressed images is an active area of research. However, previous frequency-based methods are subject to two limitations. One aspect to consider is that they apply the same weight to different frequency bands. Moreover, they exhibit an equal treatment of regions that contain distinct semantic information. To address these limitations above, we propose the Central Attention Network (CAN), a multi-modal architecture comprising two bright components: Adaptive Frequency Embedding (AFE) and Central Attention (CA) block. The AFE module adaptively embeds practical frequency information to enhance forged traces and minimize the impact of redundant interference. Moreover, the CA block can achieve fine-grained trace observation by concentrating on facial regions where indications of forgery frequently manifest. CAN is efficient in extracting forgery traces and robust to noise. It effectively reduces the unnecessary focus of our model on irrelevant factors. Extensive experiments on multiple datasets validate the advantages of CAN over existing state-of-the-art methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Deep learning advancements and the widespread availability of online resources make tools like deepfakes [1] and face2face [2] easily accessible, allowing individuals without professional training to easily manipulate facial expressions, attributes, and identities within images. However, criminals misuse these technologies, resulting in a proliferation of high-quality fake photographs on social media, making it difficult to distinguish between genuine and modified faces.
The above issues prompt the development of face forgery detection based on deep neural networks [3,4,5,6,7,8,9,10,11]. However, they perform poorly in compressed images. Recent works [12,13,14,15] highlight the effectiveness of capturing forgery traces in the frequency domain under high compression. While decent detection results are achieved by combining RGB and frequency information, their method of information processing is coarse-grained, which causes two limitations.
For one thing, previous studies usually obtain frequency domain information through Discrete Cosine Transform and then use hand-crafted filters to extract it into high, middle, and low frequency bands. According to [15], the low and middle frequency preserve rich semantic information, such as human faces and backgrounds, which is highly consistent with RGB input. Meanwhile, the high frequency reveals small-scale details, often related to forging sensitive edges and textures. These show that the role and importance of these three frequency bands are completely different. Previous works show excellent performance by combining frequency information. They apply the same weight for different frequency bands, which may not be optimal for using frequency information and may lead to magnifying irrelevant noise and ignoring the more valuable components.
For another thing, the equal treatment of regions with different semantic information prevails in existing methods. However, as shown in Fig. 1(b), most of the differences between real image and fake image are obviously clustered in the central region (in the red box). This means that the central region can provide rich traces of forgery compared to other regions (outside the red box). Treating the regions equally not only results in superfluous noise but also neglects significant evidence.

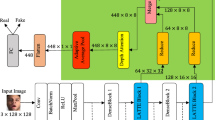
(a) Overview of our proposed CAN. Combining FDD with AFE allows for extracting fine-grained frequency information and highlighting the components most useful for forgery detection. The CA block enables the network to focus more on key central areas. (b) Illustration of the differences between Real and Fake. The forgery traces are clustered in the central region (in the red box), indicating that the center is more important than the other areas. (Color figure online)
To address these limitations, we propose a new approach to detect face forgery, termed as Central Attention Network (CAN), as shown in Fig. 1(a). The CAN consists of four main modules: Frequency Domain Decomposition (FDD), Adaptive Frequency Embedding (AFE), Multi-modal Attention Fusion (MAF), and Central Attention (CA) block. CAN initially uses FDD to extract low, middle, and high frequency information from input images. Then our AFE module concatenates the three frequency bands for richer frequency perception cues. In terms of information extraction granularity and channel allocation, it prioritizes high frequency information. Subsequently, the frequency is fused into the RGB branch by the MAF module. Finally, we add the CA block, which is similar to the Transformer block [16], to prevent the network from focusing on irrelevant areas. The module uses different scale attention mechanisms for the central and global regions, enabling the network to prioritize the central region more efficiently.
Extensive experiments have demonstrated that our proposed Central Attention Network effectively captures forgery traces and significantly improves upon the shortcomings of existing detection methods. Our work makes the following primary contributions:
-
We propose the AFE module aiming at mining the more valuable fine-grained frequency components to uncover subtle nuances and hidden artifacts.
-
We propose the Central Attention mechanism that provides a refined perspective of forged regions and reduces the attention to irrelevant areas.
-
Numerous experiments demonstrate that our proposed Central Attention block is highly versatile and can be seamlessly integrated into various existing networks, resulting in a significant enhancement of their detection capabilities.
2 Related Work
Face Forgery Detection. With the rise of deep learning, the adverse effects of image forgery techniques on political credibility, social stability, and personal reputation have increasingly received attention from society.
Therefore, various image forgery detection technologies have developed rapidly in recent years. Previous works [7,8,9,10,11] use deep CNN models to predict whether a face region is real or fake. Unfortunately, they are only partially effective in high compression scenarios.
Inspired by [13], recent studies try to improve detection performance in high compression scenes by incorporating frequency domain information into existing detection techniques. Qian et al. [15] proposes a dual-stream network named F\(^3\)-Net, where one branch utilizes three filters to perform frequency decomposition on RGB information. Chen et al. [17] uses the Spatial Rich Model to extract residual noise to guide the RGB features. Li et al. [18] and Gu et al. [14] further decompose fine-grained frequency domain information from the perspective of image compression. While previous methods demonstrate significant effects, they either underutilize frequency information or treat all levels of frequency equally. In contrast, our method involves decomposing frequency domain information and adaptive embedding to leverage the available frequency fully.
Vision Transformers. Transformers are known for their powerful remote contextual information modeling capabilities and high performance in natural language processing tasks. While various backbones are proposed to handle computer vision tasks, conventional transformers treat each patch at a single scale. Recent works [19,20,21] introduce multiple scales to focus on objects of different sizes, [22] proposes a multi-modal framework that integrates multi-scale transformer. Nevertheless, these approaches are generic and not tailored to the specific characteristics of forgery image detection. In this paper, we propose a Central Attention block that addresses the fact that fake regions tend to be concentrated in the central area of an image while other areas contain interference information.
3 Proposed Method
3.1 FDD: Frequency Domain Decomposition
For the input \({rgb} \in \mathbb {R}^{3 \times H \times W} \), where H and W are the height and width of the image. First, we apply \(\mathcal {DCT}\) as Discrete Cosine Transform to transform the RGB domain to the frequency domain. Based on [15], we devise \(N={3}\) filters that are capable of effectively decomposing the frequency into three distinct frequency bands: high, middle, and low:
We utilize \(\mathcal{I}\mathcal{D}\) as Inverse Discrete Cosine Transform to transform the frequency domain into RGB domain to obtain the \(\tilde{freq} \in \mathbb {R}^{3N \times H \times W}\) which is concatenated by \({freq}^n\) along the channel dimension. This manipulation helps to preserve the shift invariance and local consistency of natural images.
To achieve a more refined analysis of the frequency information, we apply \(\mathcal {M}\) as the median filter to extract noise information from the input features \(\tilde{freq}\):
To magnify subtle forgery clues, we utilize the following formula:
Specifically, a \(1\times 1\) convolution layer followed by a Sigmoid activation function is used to generate a noise mask, which is then added back to the original feature maps to enhance the frequency input.

The illustration of the proposed AFE allocates weight based on the value of frequency levels.
3.2 AFE: Adaptive Frequency Embedding
Previous works show excellent performance by combining frequency information. Applying the same weight to different frequency bands might be the general method in their works. It may not be optimal for using frequency domain information because it may magnify irrelevant noise or misuse the valuable components. To address this point, we propose the AFE module that fully exploits the role of different frequency components, as shown in Fig. 2. The AFE module extracts information from different frequency bands via different convolution kernels. Tampering artifacts reside mainly in the high-frequency spectrum. Therefore, we use a \(2 \times 2\) convolution kernel to extract fine-grained texture information from it. For middle and low frequency that still contain basic information, which provides a solid foundation for fusing Frequency and RGB, we adopt \(4 \times 4\) and \(8 \times 8\) convolution kernels to extract semantic features, respectively. The channel outputs generated by these convolutions are also treated differently based on their importance in different frequency bands. Specifically, \(\frac{d}{2}\) channels are allocated for high frequency channels while middle and low frequency each occupy \(\frac{d}{4} \) channels. The d represents the number of output feature channels. Ultimately, the three branches are concatenated along the channel to obtain the \({\hat{freq}}\).
3.3 MAF: Multi-modal Attention Fusion
The complementary relationship between RGB and Freq is acknowledged. The MAF module integrates them by means of an attention mechanism. The RGB feature map is denoted as \(\mathcal {}{\hat{rgb}} \in \mathbb {R}^{d \times h \times w}\), while the frequency feature map is represented as \(\mathcal {}{\hat{freq}} \in \mathbb {R}^{d \times h \times w}\). We obtain the query vector Q from \(\hat{rgb}\) using a \(1 \times 1\) convolution layer. Similarly, we obtain the key vector K and value vector V from \(\hat{freq}\) using \(1 \times 1\) convolution layers. Then, we flatten them along the spatial dimension to get 2D embeddings \(Q_e\), \(K_e\), \(V_e\). Using the self-attention mechanism, we generate an attention map that represents relevance between the input features \(\hat{rgb}\) and \(\hat{freq}\):
where \(\boldsymbol{D}\) is the dimensionality of the key vectors. After obtaining attention weights, we compute weighted values via a \(3 \times 3\) convolution. Additionally, we adopt residual connections to add them to the original input, alleviating the potential gradient vanishing issue during the training process.
3.4 CA Block: Central Attention Block

The proposed Central Attention mechanism when \(\alpha \) is 0.5.
The conventional transformer models treat all patches of an image equally without taking into account the relative significance of distinct areas. Recent studies [20, 22] show that incorporating multi-scale information can improve detection accuracy. Yet these models are not optimized for detecting forged face images. Our observation is that forged regions tend to cluster around the centre of input images. Based on this insight, we propose Central Attention, which aids the network in concentrating on key regions.
For the input global feature \(f^g \in \mathbb {R}^{c \times h \times w}\), we commence by initializing a Mask of size \(h \times w\). Subsequently, we selectively filled the central region, characterized by dimensions of \(\alpha h \times \alpha w\), with the value 1. The surrounding area is then filled with the value 0 to complete the mask initialization process. \(\alpha \) is the proportion that determines the size of the central region. We then apply this Mask to the input \(f^g\), resulting in a central feature map \(f^c\) = \(f^g \odot mask\). Figure 3 illustrates the framework of the Central Attention mechanism, with a value of 0.5 for parameter \(\alpha \).
For the global feature \(f^g\), we downsample it into \(\frac{h}{2} \times \frac{w}{2}\) by convolution to obtain \(f^d\). We obtain the embedding \(Q_{g}\) from \(f^g\), the embeddings \(K_{g}\) and \(V_{g}\) from \(f^d\). Inspired by [21], we define the operation of dividing the input into \(G\times G\) patches through sliding windows and grouping as \(SW^G(\cdot )\).
Similarly, for the central feature \(f^c\), we embed \(f^c\) into \(Q_{c}\), \(K_{c}\), \(V_{c}\).
where MHSA represents Multi-Head Self-Attention.
This allows the network to focus more on the central region while still considering the surrounding areas. In order to maintain spatial coherence, the grouping features are rearranged and subsequently substituted with \(f^c\) to replace the corresponding position features. [\(\cdot \)] denotes the above operations.
The CA block can be described mathematically:
where Norm and FFN mean BatchNorm, Feed Forward Network separately.
3.5 Overall Loss
After passing through several CA blocks, the feature is sent into the remaining backbone network to extract richer features f. Then a fully connected layer and a sigmoid function are used to obtain the final prediction probability y. So the Binary cross-entropy loss is defined as:
where y is set to 1 if the face image has been manipulated, otherwise it is set to 0. To ensure feature consistency, we use the Consistency loss function \(\mathcal {L}_{Cos}\) in [23] to constrain the feature distribution. \(f_{1}\) and \(f_{2}\) are the final features obtained from the same input image after through distinct data augmentation and being passed through the network. Mathematically:
where \(\tilde{f} = \frac{f}{{\parallel f\parallel }_{2}}\) denotes the normalized vector of the representation vector f.
So we combine the Binary cross-entropy loss and the Consistency loss function linearly with \(\beta = 2\).
4 Experiments
4.1 Experimental Setup
Datasets. We adopt two widely-used public datasets in our experiments, i.e., FaceForensics++ [27], Celeb-DF [28].
1) FaceForensics++ (FF++) [27] is a large forensics dataset containing 1000 original video sequences and 4000 manipulated video sequences produced by four automated face manipulation methods: i.e., Deepfakes [1], Face2Face [2], FaceSwap [29], NeuralTextures [30]. Raw videos are compressed, resulting in two versions: high quality (HQ) and low quality (LQ). Following the official splits, we utilized 720 videos for training, 140 for validation, and 140 for testing.
2) Celeb-DF [28] dataset comprises 590 authentic videos sourced from YouTube, featuring individuals of varying ages, ethnicities, and genders. Additionally, the dataset includes 5639 corresponding DeepFake videos.
Implementation Detail. The EfficientNet-B4 [31] pre-trained on ImageNet is adopted as the backbone of our network. We insert several CA blocks respectively after the second and third convolutional blocks with \(\alpha = 0.5\). The input images are resized to \(320 \times 320\). The whole network is trained with Adam optimizer with the learning rate of \(2\times {10}^{-4}\), \(\beta _1 = 0.9\), \(\beta _2 = 0.999\). The batch size is 48 split on 4 \(\times \) RTX 3090 GPUs.
Evaluation Metrics. Following the convention [10, 14, 15, 22, 27], we apply Accuracy score (Acc), Area Under the Receiver Operating Characteristic Curve (AUC) as our evaluation metrics.
Comparing Methods. We compare our methods with several advanced methods: MesoNet [6], Xception [24], Face X-ray [7], Two-branch [25], RFM [11], Add-Net [9], F\(^3\)-Net [15], FDFL [18], Multi-Att [8], SIA [26], PEL [14].
4.2 Comparison to the State-of-the-Arts
Following [15, 27], we compare our method with various advanced techniques on the FF++ dataset with different quality settings (i.e., HQ and LQ), and further evaluate the performance of our approach on the Celeb-DF dataset. In Table 1 the best, second, third results are shown in
 . The performance of our proposed method, especially under high compression, is comparable or superior to existing methods, as evidenced by the Acc and AUC metrics. It is worth noting that the method PEL [14] is a two-stream network with twice as many parameters as ours. We achieve competitive results using only half the parameters. These gains mainly come from the CAN’s ability to utilize frequency information and fully reduce interference from irrelevant information.
. The performance of our proposed method, especially under high compression, is comparable or superior to existing methods, as evidenced by the Acc and AUC metrics. It is worth noting that the method PEL [14] is a two-stream network with twice as many parameters as ours. We achieve competitive results using only half the parameters. These gains mainly come from the CAN’s ability to utilize frequency information and fully reduce interference from irrelevant information.
4.3 Ablation Study and Architecture Analysis
Components. As shown in Table 2, we develop several variants and conduct a series of experiments on the FF++ (LQ) dataset to explore the impact of different components in our proposed method. Using only RGB or frequency as input in the single-stream setting leads to similar results. Combining both original streams can slightly improve performance, which demonstrates that frequency and RGB are unique and complementary. Adding an AEF module or CA blocks can significantly improve performance, achieving optimal results using the overall CAN framework. It shows that each module is effective: the AFE module fully mines frequency domain information and filters noise, and the CA blocks strengthen the network to focus on forged regions.
Validity of the CA Block. We insert the CA block into Transformer and CNN to further examine its validity and universality. PoolFormer-S (PF) [32] and ConvNeXt-S (CNX) [33] are chosen as the backbone. The results on FF++ (LQ) are displayed in Table 3, where * means loading pre-trained weight. Embedding CA blocks significantly improves the performance of both baseline networks due to their critical attention to central regions.
Convolution Kernel Size. In the AFE module, we conduct experiments with several convolution kernel combinations under the same settings. The specific results are shown in Table 4. The combination of [2, 4, 8] performs best.
Hyperparameter \(\alpha \). The hyperparameter \(\alpha \) has a significant impact on the CA block’s performance by restricting the size of the central area. In Table 5, we conduct experiments with different value of \(\alpha \) and find that the optimal performance is achieved when the \(\alpha \) is 0.5. It means that the inclusion of too much irrelevant information would weaken the performance, and the center area can supply adequate forgery traces.
4.4 Visualizations
To further understand how our method makes decisions, we use Grad-CAM [34] to show the attention maps of input samples for both the baseline and CAN. Figure 4 demonstrates that all four forgery methods have their faked areas centered in the center. The baseline network is significantly disturbed due to increased noise information after compression. However, with the AFE module filtering out noise information and Central Attention emphasis focused on central areas, the CAN can more reliably capture forgery traces.

The attention maps for different kinds of faces
4.5 Limitations
When applying improper masks, the performance drops significantly, suggesting that a more meticulous attention mechanism is required. Focusing on specific facial components may lead to better results, which we will explore in the future.
5 Conclusion
The paper proposes a Central Attention Network (CAN) framework for detecting forged images. We conduct a comprehensive analysis of the frequency amplification forgery traces, which has laid a strong foundation for the network’s optimal performance. The Central Attention block effectively filters out irrelevant background noise, ensuring the network concentrates primarily on capturing forgery traces. Visualizing class activation mapping explains the internal mechanism and demonstrates the effectiveness of our methodology.
References
Tora: Deepfakes (2018). https://github.com/deepfakes/faceswap/tree/v2.0.0
Thies, J., Zollhofer, M., Stamminger, M., Theobalt, C., Nießner, M.: Face2face: real-time face capture and reenactment of RGB videos. In: Proceedings of CVPR (2016)
Yang, X., Li, Y., Lyu, S.: Exposing deep fakes using inconsistent head poses. In: IEEE International Conference on Acoustics, Speech and Signal Processing (2019)
Matern, F., Riess, C., Stamminger, M.: Exploiting visual artifacts to expose deepfakes and face manipulations. In: IEEE Winter Applications of Computer Vision Workshops (2019)
Haliassos, A., Vougioukas, K., Petridis, S., Pantic, M.: Lips don’t lie: a generalisable and robust approach to face forgery detection. In: Proceedings of CVPR (2021)
Afchar, D., Nozick, V., Yamagishi, J., Echizen, I.: Mesonet: a compact facial video forgery detection network. In: IEEE International Workshop on Information Forensics and Security (2018)
Li, L., et al.: Face X-ray for more general face forgery detection. In: Proceedings of CVPR (2020)
Zhao, H., Zhou, W., Chen, D., Wei, T., Zhang, W., Yu, N.: Multi-attentional deepfake detection. In: Proceedings of CVPR (2021)
Zi, B., Chang, M., Chen, J., Ma, X., Jiang, Y.G.: Wilddeepfake: a challenging real-world dataset for deepfake detection. In: Proceedings of ACM-MM (2020)
Dang, H., Liu, F., Stehouwer, J., Liu, X., Jain, A.K.: On the detection of digital face manipulation. In: Proceedings of CVPR (2020)
Wang, C., Deng, W.: Representative forgery mining for fake face detection. In: Proceedings of CVPR (2021)
Chen, S., Yao, T., Chen, Y., Ding, S., Li, J., Ji, R.: Local relation learning for face forgery detection. In: Proceedings of AAAI (2021)
Frank, J., Eisenhofer, T., Schönherr, L., Fischer, A., Kolossa, D., Holz, T.: Leveraging frequency analysis for deep fake image recognition. In: Proceedings of ICML (2020)
Gu, Q., Chen, S., Yao, T., Chen, Y., Ding, S., Yi, R.: Exploiting fine-grained face forgery clues via progressive enhancement learning. In: Proceedings of AAAI (2022)
Qian, Y., Yin, G., Sheng, L., Chen, Z., Shao, J.: Thinking in frequency: face forgery detection by mining frequency-aware clues. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12357, pp. 86–103. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58610-2_6
Vaswani, A., et al.: Attention is all you need. In: Proceedings of NeurIPS (2017)
Luo, Y., Zhang, Y., Yan, J., Liu, W.: Generalizing face forgery detection with high-frequency features. In: Proceedings of CVPR (2021)
Li, J., Xie, H., Li, J., Wang, Z., Zhang, Y.: Frequency-aware discriminative feature learning supervised by single-center loss for face forgery detection. In: Proceedings of CVPR (2021)
Chen, C.F.R., Fan, Q., Panda, R.: Crossvit: cross-attention multi-scale vision transformer for image classification. In: Proceedings of ICCV (2021)
Ren, S., Zhou, D., He, S., Feng, J., Wang, X.: Shunted self-attention via multi-scale token aggregation. In: Proceedings of CVPR (2022)
Wang, W., et al.: Crossformer: a versatile vision transformer hinging on cross-scale attention. In: Proceedings of ICLR (2022)
Wang, J., et al.: M2TR: multi-modal multi-scale transformers for deepfake detection. In: Proceedings of ICMR (2022)
Ni, Y., Meng, D., Yu, C., Quan, C., Ren, D., Zhao, Y.: Core: consistent representation learning for face forgery detection. In: Proceedings of CVPR Workshops (2022)
Chollet, F.: Xception: deep learning with depthwise separable convolutions. In: Proceedings of CVPR (2017)
Masi, I., Killekar, A., Mascarenhas, R.M., Gurudatt, S.P., AbdAlmageed, W.: Two-branch recurrent network for isolating deepfakes in videos. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12352, pp. 667–684. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58571-6_39
Sun, K., et al.: An information theoretic approach for attention-driven face forgery detection. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) ECCV 2022. LNCS, vol. 13674, pp. 111–127. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-19781-9_7
Rossler, A., Cozzolino, D., Verdoliva, L., Riess, C., Thies, J., Nießner, M.: Faceforensics++: learning to detect manipulated facial images. In: Proceedings of ICCV (2019)
Li, Y., Yang, X., Sun, P., Qi, H., Lyu, S.: Celeb-DF: a large-scale challenging dataset for deepfake forensics. In: Proceedings of CVPR (2020)
Kowalski, M.: Faceswap (2018). https://github.com/marekkowalski/faceswap
Thies, J., Zollhöfer, M., Nießner, M.: Deferred neural rendering: image synthesis using neural textures. ACM Trans. Graph. 38(4), 1–12 (2019)
Tan, M., Le, Q.: Efficientnet: rethinking model scaling for convolutional neural networks. In: Proceedings of ICML (2019)
Yu, W., et al.: Metaformer is actually what you need for vision. In: Proceedings of CVPR (2022)
Liu, Z., Mao, H., Wu, C.Y., Feichtenhofer, C., Darrell, T., Xie, S.: A convnet for the 2020s. In: Proceedings of CVPR (2022)
Li, H., Huang, J.: Localization of deep inpainting using high-pass fully convolutional network. In: Proceedings of ICCV (2019)
Acknowledgment
This research is supported by National Natural Science Foundation of China (Grant No. 62206277) and the University Synergy Innovation Program of Anhui Province (No. GXXT-2022-036). The authors would like to thank Ran He (Professor at CASIA) and Jiaxiang Wang (Ph.D. at AHU) for their valubale suggestions.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Sun, J., Ding, Y., Cao, J., Duan, J., Zheng, A. (2024). Where to Focus: Central Attention-Based Face Forgery Detection. In: Liu, Q., et al. Pattern Recognition and Computer Vision. PRCV 2023. Lecture Notes in Computer Science, vol 14429. Springer, Singapore. https://doi.org/10.1007/978-981-99-8469-5_4
Download citation
DOI: https://doi.org/10.1007/978-981-99-8469-5_4
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-8468-8
Online ISBN: 978-981-99-8469-5
eBook Packages: Computer ScienceComputer Science (R0)