
Abstract
Heart disorders are leading cause of deaths worldwide. If in case a risk of heart disease may include for the patient, the healthcare department people are mostly depending on the data of a patient. The data cannot be verified in-detail by the doctors all the time and predict accurately. However, it is concerning as the risky and time consuming as well. This paper aims at developing a deep learning-based heart disease prediction system that can be used to diagnose a patient’s condition based on the medical record. Several parameters like fasting blood sugar, cholesterol, chest pain type, and resting blood pressure have been studied and used for the detection of heart disease. The parameters have been fed to a 1D convolutional neural network (CNN). The network is designed with convolution 2D layer, ReLU layer, softmax layer, fully-connected layer, and classification layer. The UCI heart dataset has been used for the experiments. The proposed system has produced an accuracy of 90% during training and 82% during testing.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Any health problem that impacts the structure or functioning of the heart is a disease [1] of the heart. It is sometimes wrongly believed that there is only one type, when in fact, heart disease is numerous. The causes of these health problems are diverse. There are several kinds of heart diseases. They can be classified in particular according to how they affect the heart [2].
-
1.
Coronary artery disease and other vascular diseases: These occur when the blood vessels harden (atherosclerosis). The coronary artery disease is characterized by narrowing or blockage of a coronary artery (of the heart). It is the most common form of heart disease and the major cause of heart attack and of angina (chest pain). A vascular disease tends to affect other vessels. It reduces blood flow and affects the functioning of the heart.
-
2.
Heart rhythm disturbances (arrhythmias): They make the heart beat too slowly, too quickly, or irregularly. Millions of people have arrhythmia which disrupts blood circulation. There are several types: some show no symptoms (asymptomatic) or warning signs; others are sudden and deadly.
-
3.
Structural heart disease: These are caused by abnormalities in the structure of the heart, including valves, heart walls and muscles, or blood vessels near the heart. These heart diseases are sometimes existing at birth (congenital) or occur during life due to infection, wear, or other factors. People living with a heart defect, as well as their families, need lifelong support as they often have to receive ongoing medical care and undergo surgery.
-
4.
Heart failure: This is a serious condition that occurs when the heart is weakened or damaged. The heart failure can be caused by two most common ways such as the heart attack and the high blood pressure. The disease is incurable, but a rapid diagnosis, the adoption of specific lifestyle habits, and the taking of adapted drugs help patients to lead a long normal and active life, without hospitalization.
The diagnosis of the diseases is done by a procedure known as angiogram. A coronary angiogram (also called a coronary angiogram) is a test that involves taking X-rays of the coronary arteries and vessels that helps to supply the blood for the heart. During this procedure, a special stain, an iodine product, is injected into the coronary arteries from a catheter (long and narrow tube) injected into a blood vessel; each of them then becomes visible on the X-ray. Angiography allows doctors to observe the blood flow in the heart separately and sometimes even to pinpoint possible problems with the coronary arteries.
Coronary angiography can be recommended for people with angina (chest pain) or those with symptoms of coronary artery disease [3]. It provides doctors with important information about the condition of the coronary arteries, which can be affected by atherosclerosis, regurgitation (blood pumped back through a damaged valve), or the accumulation of blood in a cavity caused by a malfunction of a heart valve.
Angiography is performed in the hospital or clinic. You will be asked to lie on a table and disinfect the area around where the catheter will be inserted (groin or arm). Through local anaesthesia that you will be given, your skin will be numb, preventing you from feeling any pain. Then, the catheter will be carefully guided through a vein or artery to near the heart [4]. Once the catheter is in place, it will release the special dye into the blood stream; this dye will facilitate the taking of clear and detailed X-rays of the coronary arteries. It should be noted that the injection of the dye could cause a brief feeling of heat, which should, however, dissipate fairly quickly. The duration of an angiography can vary between one and two hours; however, angiography is a very common procedure which, in general, is considered to be safe.
Some cardiologists and engineers invent solutions to better diagnose and predict heart problems by relying on artificial intelligence. As with radiology, only a handful of AI-based tools have so far passed the door of hospitals and received the green light from research, but many see these innovations in cardiology as having immense potential.
Deep learning is a new area of research in machine learning [5] which aims to bring machine learning closer to one of its initial objectives “intelligence artificial”. It depends on manipulating large amounts of data by adding layers in the artificial neuron network to extract the properties of raw data through several processing layers composed of linear transformations and not linear. The large amount of healthcare data on the heart disease diagnosis in the world is produced by hospitals, and many medical laboratories, to be used in the field of scientific research, correct diagnosis and classification of diseases or to predict diseases.
For heart disease, the risk factors can be considered as alcohol intake, physical inactivity, obesity, high blood pressure, poor diet, cholesterol, family history, smoking, sex, and age. The hereditary risk factors are included diabetes and high blood pressure which leads to the heart disease [6]. It is very tough to evaluate the odds of getting heart disease based on risk factors. For predicting the output from existing information, machine learning methods can be used. In this paper, the application of one such type of machine learning technique like convolutional neural network (CNN) to forecast the heart disease risk from the risk factors is demonstrated.
2 Literature Survey
Sung and Yuan Lee have been utilized genetic algorithm (GA) and SVM to make the feature selection and to categorize the classification, respectively. The effectiveness of this method is validated with its results. In literature, it outclasses two other methods when SVM is implemented without GA by generating an accuracy of 96.38%. The accuracy is increased by 3.14% if GA is applied [7].
Davari et al. [8] have been proposed a method to diagnose the coronary artery disease (CAD) with automation. Using signals of heart rate variability (HRV), normal conditions are determined from an electrocardiogram (ECG). For reduction of dimensionality, the principal component analysis (PCA) is made utilized by the technique, and SVM is applied for the purpose of classification.
Boon et al. [9] have been presented a system to optimize the parameters and to make settings of feature extraction of HRV for multiple algorithms. To maximize the performance of prediction, the best subset of features is chosen by the algorithm, and SVM parameters are tuned at the same time.
Mustaqeem et al. [10] have been gathered sufficient information to create the own dataset. For analyzing the proposed algorithm’s performance, two evaluation measures are utilized such as kappa and accuracy statistics. Purushottam et al. [15] have been ranked the features that are significant clinically. By using t value and classifiers such as SVM, K-nearest neighbour (KNN), and decision tree, these features are obtained in numerous ways. In prior to the SCD with an accuracy of 94.7, 89.4, 89.4, and 97.3%, the sudden cardiac death (SCD) is predicted by the technique for 4, 3, 2, and 1 min, respectively.
Acharya et al. [11] have been proposed nonlinear features to the classifiers such as SVM, decision tree (DT), and KNN. The combination of a nonlinear analysis and discrete wavelet transform (DWT) is utilized for predicting the accuracies of SCD of 92.11 (SVM), 93.42 (KNN), 98.68 (SVM), and 92.11% (KNN) before occurrence of SCD for 4, 3, 2, and 1 min, respectively.
In [12], a CNN-based technique has been proposed that involves 2 pooling layers and 2 convolution layers. Additionally, long short-term memory (LSTM) has been utilized in the sense that an RNN but with an output layer and hidden memory layer. Three gate units have been included in LSTM’s memory block such as input, a self-recurrent connecting neuron, and forget and output.
In [13], a neural network-based technique has been proposed based on the electronic medical data of patients to predict the heart failure. To model and predict HF with LSTM, specifically word vectors and a one- hot encoding have been incorporated.
In [14], a novel technique based on CNN has been used that is targeted to make the classification of pathological and healthy people with the use of an auditory sensor for field programmable gate array (FPGA) which is exploited for decomposing audio to frequency bands in real-time.
Purushottam et al. [15] have been planned a framework to anticipate the patients’ risk levels according to the provided metrics. This rules-based algorithm has been majorly influenced on assisting a non-specialized physician in such a way that taking the right decision in regard to the levels of risk. Yu and Lee [7] have been helped in identifying CAD at an early phase based on the technique of a fuzzy expert system and formulation of rules from doctors.
Long et al. [16] have been used fuzzy logic and presented a method known as the system of interval type-2 fuzzy logic system (IT2FLS). This method is used a procedure of blended learning which contains fuzzy c-mean clustering and tuned in parameters through GA and Firefly. The conducted experiments of IT2FLS are analyzed and are revealed that it outclasses other techniques of ML like ANN, SVM, and NB as this technique’s computation cost is increased due to the involved high dimensionality.
In [17], the ranking of complete set of clinically essential features is done primarily to make easier the experimentation process. After that, these features are incorporated into various classifiers like SVM, DT, and K-nearest neighbour (KNN). The highest accuracy is achieved for the given dataset of SVM. In [11], these two classifiers like SVM and KNN have considered the input as non-linear features. The stated classifiers KNN and SVM are achieved the accuracies of 92.11 and 96.68%, respectively.
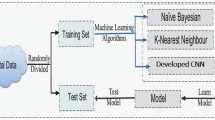
3 Proposed Heart Disease Prediction Using Deep Learning
In different classification tasks such as audio, image, and words, neural networks are utilized. For various purposes, different kinds of neural networks are made used. The recurrent neural networks are used more precisely to predict the sequence of words for an LSTM. In a similar manner, convolutional neural network has been utilized for classification of images. The establishment of basic building block for CNN is discussed in the blog.
Some concepts of neural network are revisited firstly before categorizing into the convolution neural network. Three types of layers are included in a regular neural network.
-
1.
Input Layers: In the input layer, the input is given to the model. The total number of features in the data is equivalent to the number of neurons in this layer. In case of an image, consider the number of pixels.
-
2.
Hidden Layer: From an input layer, the input is fed into the hidden layer. Based on the data size and type of model, different kinds of hidden layers are existed. Various number of neurons can be included in each hidden layer that are greater than the number of features in general. Based on the matrix multiplication of the previous layer output with that layer’s learnable weights, the output from each layer is calculated. By adding the learnable biases that are followed by the function of activation, the network is made nonlinear.
-
3.
Output Layer: As similar as sigmoid or softmax, the hidden layer’s output is incorporated into a logistic function. However, the function of softmax or sigmoid is converted the each class output into the each class’s probability score.
The data is incorporated into the model, and each layer’s output is retrieved the step known as feedforward. Based on an error function, the error is determined. Some of the most widely used error functions are included square loss error, cross entropy, etc. With the calculation of derivatives, it’s better to back propagate into the model. This phase is called as backpropagation which is utilized to reduce the loss basically (Fig. 1).

Neural network structure
Convolution Neural Network
Convolution neural networks or CovNets are one of the type of neural networks that share their metrics. Here, an image is considered, and it is represented as a cuboid that includes the height (generally an image has blue, green, and red channels), width (image’s dimension), and length. Let us assume this image with a small patch and implement a small neural network on it with k outputs with the vertical representation. Across the whole image, the neural network is operated which will lead to retrieve another image with different depth, height, and width. More channels but lesser height and width are considered rather than just B, G, and R channels. However, this operation is termed as convolution. When patch size is similar to that of the actual image, it will be concerned as a regular neural network. Fewer weights have included in the image due to this small patch (Fig. 2).

Convolution process in CNN
Now, it is time to discuss the mathematics part which is included in the complete process of convolution.
-
A set of learnable filters are contained in the convolution layers for the patch in the above image. Small height and width and the same depth like the input volume have been involved in each filter (3 if the input layer is image input).
-
Let us say, the filters’ possible size can be a × a × 3 if the convolution is implemented on an image that has included the dimension of 34 × 34 × 3. Here, “a” can be 3, 5, 7, etc., but it is small than the image dimension.
-
For the whole input volume, each filter slide step by step during forward pass in which each step is called as stride (which can include the values like 2 or 3 or even 4 for images with higher dimensions). The dot product between the input volume’s patch and filters’ weights can be computed.
A 2D output will be retrieved for each filter and will stack them together as the filters slide. The output volume has included a depth which is equivalent to the number of filters as a result. All the filters will be learned by the network.
Layers Used to Build ConvNets
Based on differentiable function, the transformation of one volume to another has been made by each layer in ConvNets which has a sequence of layers. Types of layers: Let us consider an example of an image with the dimension of 32 × 32 × 3 by running a ConvNets.
-
1.
Input Layer: The raw input of image with depth 3, height 32, and width 32 is included in this layer.
-
2.
Convolution Layer: Based on the determination of dot product between image path and all filters, the output volume is computed by this layer. The dimension for output volume 32 × 32 × 12 will be received if the total number of 12 filters are used for this layer.
-
3.
Activation Function Layer: To get the convolution layer’s output, this layer will be implemented based on activation function in an element wise. Some of the different activation functions are included ReLU: Tanh, leaky ReLU, sigmoid: 1/(1 + e^ − x), and max(0, x), etc. The volume is remained in unchanged state so that the output volume will have included the dimension 32 × 32 × 12.
-
4.
Pool Layer: In the ConvNets, this layer is incorporated periodically, and the reduction of volume size is the essential function that helps to do the rapid computation based on preventing from over fitting and reducing memory. However, two different common types of pooling are involved average pooling and max pooling. The output volume with the dimension 16 × 16 × 12 will be retrieved when using a max pool with stride 2 and 2 × 2 filters (Fig. 3).
Fig. 3 
Pooling process

Fully-Connected Layer: This layer is a type of regular neural network layer that can be used to compute the class scores by considering the input from the previous layer. Additionally, output is also determined for 1D array of size which is equal to the number of classes.
The Convolution Operator
Convolutional neural networks are already called convolution in their name. This means that the so-called discrete convolution operator, which is common, is used in image and signal processing. Because this operator is the basis for CNNs, it is subsequently for the 1-dimensional and 2-dimensional case defined and illustrated.
1D convolution (discrete convolution) Let A = (a1, ..., an) A = (a1, … , an) be an input vector. Continue to be F a so-called filter vector (also called kernel vector) with F = (f1, … , fk) and k < n. Then, the 1-dimensional convolution operator ∗ is defined as follows:
Eq 1: 1D-Convolution operator To illustrate, consider the following example vectors for A and F:
Obviously n = 7 and k = 3. Then, the result vector after applying the convolution operators on A and F exactly n − k + 1 = 7 − 3 + 1 = 5 entries. According to the definition results:
At first glance, the previous clear convolution operation. Obviously, the filter vector always overlaps a partial area the input. If, on the other hand, the input vector A is taken, for example, as a measurement curve of an electrical signals, the result of the convolution with this choice of F could, for example, be smoothing of the signal. Extreme outliers up (60) or down (10) result no longer included. A different choice of F might have “derived” filtered out. Applying the convolution operator to an input signal a particular filter is a common approach in signal processing.
In the 2-dimensional case, which is defined and explained below, this type opens up processing even more vivid.
4 Experimental Results
Two sections are involved in the experimental results such as training process and testing process. The dataset UDI heart disease repository has been downloaded from kaggle.com. The attributes used are listed below:
-
1.
Age: age in years
-
2.
Sex: (1 = male; 0 = female)
-
3.
cp: chest pain type:
-
Value 1: typical angina
-
Value 2: atypical angina
-
Value 3: non-anginal pain
-
Value 4: asymptomatic
-
-
4.
trestbps: resting blood pressure (in mm Hg on admission to the hospital)
-
5.
chol: serum cholestoral
-
6.
fbs: fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
-
7.
restecg: restingelectrocardiographic results
-
8.
thalach: maximum heart rate achieved
-
9.
exang: exercise induced angina (1 = yes; 0 = no)
-
10.
oldpeak: ST depression induced by exercise relative to rest
-
11.
slope: the slope of the peak exercise ST segment
-
Value 1: upsloping
-
Value 2: flat
-
Value 3: downsloping
-
-
12.
ca: number of major vessels (0–3) coloured by flourosopy
-
13.
thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
-
14.
num: the predicted attribute
Training Process
Figure 4 is showed the 1D CNN network’s training process. The network contains basically two graphs, which are accuracy and loss. If the validation accuracy will reach to final destination, the training process will be completed.

Training process of 1D CNN network
Training
Table 1 shows the confusion matrix of 1D CNNN of training process. The table describes, in which actual class contains two classes, and each class contains 400 samples. In predicted class, it shows predicted samples of actual class.
The overall accuracy of training model is 0.90.
Table 2 describes the performance metrics of actual class. The table contains true negative, false negative, true positive, false positive, precision, sensitivity, and specificity of each class.
Testing
Table 3 shows the confusion matrix of 1D CNN in testing process. The table describes, in which actual class contains two classes, and each class contains 99 and 126 samples, respectively. In predicted class, it shows predicted samples of actual class.
The overall accuracy of testing model is 0.82.
Table 4 describes the performance metrics of actual class. The table contains true positive, false positive, false negative, true negative, precision, sensitivity, and specificity of each class.
Table 5 illustrates the proposed method’s results with the existing classification methods comparatively.
5 Conclusion
To predict the probabilities of having heart disease for a patient, the algorithm of 1D CNN-based heart disease prediction was implemented on the dataset in this paper. The accuracy of training obtained is 90%, and the accuracy of testing obtained is 82%. The precision, sensitivity, and specificity of testing are 0.77, 0.82, and 0.83 for positive heart attack and 0.87, 0.83, and 0.82 negative heart attack, respectively. The proposed method performed better when compared to the existing methods.
References
Desai SD, Giraddi S, Narayankar P, Pudakalakatti NR, Sulegaon S (2019) Back-propagation neural network versus logistic regression in heart disease classification. Advanced computing and communication technologies. Springer, Singapore, pp 133–144
Roca-Luque I, Rivas-Gándara N, Dos Subirà L, Francisco-Pascual J, Pijuan-Domenech A, Pérez-Rodon J, Teresa-Subirana M et al (2018) Mechanisms of intra-atrial re-entrant tachycardias in congenital heart disease: types and predictors. Am J Cardiol 122(4):672–682
Dube H, Madge S, Jagtap P, Potdar P, Bhandare N (2020) Review on heart disease classification. In: Proceedings of the 2020 5th international conference on communication and electronics systems (ICCES). IEEE, New York, pp 1169–1173
Ekız S, Erdoğmuş P (2017) Comparative study of heart disease classification. In: Proceedings of the 2017 electric electronics, computer science, biomedical engineering’s meeting (EBBT). IEEE, New York, pp 1–4
Sowmiya C, Sumitra P (2017) Analytical study of heart disease diagnosis using classification techniques. In: Proceedings of the 2017 IEEE international conference on intelligent techniques in control, optimization and signal processing (INCOS). IEEE, New York, pp 1–5
Zhao T-T, Yuan Y-B, Wang Y-J, Gao J, He P (2017) Heart disease classification based on feature fusion. In: Proceedings of the 2017 international conference on machine learning and cybernetics (ICMLC), vol 1. IEEE, New York, pp 111–117
Yu S, Lee M (2012) Bispectral analysis and genetic algorithm for congestive heart failure recognition based on heart rate variability. Comput Biol Med 42(8):816–825
Davari DA et al (2017) Automated diagnosis of coronary artery disease (CAD) patients using optimized SVM. Comput Methods Prog Biomed 138:117–126
Boon K et al (2018) Paroxysmal atrial fibrillation prediction based on HRV analysis and non- dominated sorting genetic algorithm III. Comput Methods Prog Biomed 153:171–184
Mustaqeem A et al (2017) A statistical analysis based recommender model for heart disease patients. Int J Med Inform 108:134–145
Acharya U et al (2015) An integrated index for detection of sudden cardiac death using discrete wavelet transform and non-linear features. Knowl Based Syst 83:149–158
Tan J, Hagiwara Y, Pang W, Lim I, Oh S, Adam M, Tan R, Chen M, Acharya U (2018) Application of stacked convolutional and long short-term memory network for accurate identification of CAD ECG signals. Comput Biol Med 94:19–26
Jin B, Che C, Liu Z, Zhang S, Yin X, Wei X (2018) Predicting the risk of heart failure with EHR sequential data modeling. IEEE Access 6:9256–9261
Dominguez-Morales J, Jimenez-Fernandez A, Dominguez-Morales M, Jimenez-Moreno G (2018) Deep neural networks for the recognition and classification of heart murmurs using neuromorphic auditory sensors. IEEE Trans Biomed Circ Syst 12(1):24–34
Purushottam M et al (2016) Efficient heart disease prediction system. Proced Comput Sci 85:962–969
Long N et al (2015) A highly accurate firefly based algorithm for heart disease prediction. Exp Syst Appl 42(21):8221–8231
Fujita H et al (2016) Sudden cardiac death (SCD) prediction based on nonlinear heart rate variability features and SCD index. Appl Soft Comput 43:510–519
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Ramachandran, V., Rekha, S.K., Rajesh, B., Narayana, Y.V., Sathish, P. (2023). Heart Disorder Prediction Using 1D Convolutional Neural Network. In: Szymanski, J.R., Chanda, C.K., Mondal, P.K., Khan, K.A. (eds) Energy Systems, Drives and Automations. ESDA 2021. Lecture Notes in Electrical Engineering, vol 1057. Springer, Singapore. https://doi.org/10.1007/978-981-99-3691-5_44
Download citation
DOI: https://doi.org/10.1007/978-981-99-3691-5_44
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-3690-8
Online ISBN: 978-981-99-3691-5
eBook Packages: EnergyEnergy (R0)