
Abstract
The Elderly is a human being over 60 years old. Humans over the age of 60 years have the potential to fall due to balance and gait disturbances. The disturbance is caused by a decrease in the sensory system that focuses the view. This impact will result in the risk of developing fractures and even death if it cannot be treated quickly. Previous research has conducted tests on Human Activity Recognition. In this study, we will test the selection of feature extraction and machine learning methods regarding Human Activity Recognition. The extraction features tested in this study are the mean, median, maximum, minimum, skewness, kurtosis, and variance with Fast Fourier Transform from each value obtained by the IMU sensor. The machine learning methods studied were Stochastic Gradient Descent, Random Forest, K-Nearest Neighbor, Decision Tree, and Gaussian Naive Bayes. The test results demonstrate that Y-Axis Gyroscope means, X-Axis Acceleration skewness, X-Axis Gyroscope variance, and X-Axis Gyroscope max are the optimum extraction features for machine learning. The most accurate machine learning algorithm is Random Forest, which has a 99.59% accuracy rate. Therefore, the author made this Human Activity Recognition system to monitor the activities of the elderly. With this research, elderly monitors can keep track of the elderly’s activities and concentrate more attention on all of the elderly’s activities, especially fall activities. Thus, monitors can provide early assistance to the elderly.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Because more than 37 million falls each year necessitate medical attention, falls are a severe public health issue [1]. One of them is the elderly, who can put themselves in danger of serious harm which can be hip fractures or even death [2, 3]. In 2030, there will be 1.4 billion elderly, and by 2050, there will be 2.1 billion. Ages 65 and older have a higher risk of falling (by 28–35%) than seniors 65 and older. For those who are older than 70, this risk rises to 32–42% [4, 5]. This research was created to be able to do early prevention of the elderly in the case of a fall incident because it is a severe concern. There is a system that can detect human behaviors using a variety of algorithms has been developed through several experiments. The recognized target in this system has a human movement feature. Human Activity Recognition has been the subject of several investigations. There are a several research on HAR that using radar [6,7,8,9], a system of computer vision [10,11,12,13,14], and an inertial sensor [11, 15, 16]. Because it is inexpensive and suitable for use by the elderly during activities, the author employed an inertial sensor for HAR investigation.
Several academics have investigated the use of different algorithms to Utilize inertial sensors to detect human activity. In a study [17], deep neural network (DNN), bidirectional-long short-term memory (BLSTM), CNN, and CNN-LSTM algorithms were used to create a wearable device with an IMU sensor. In this study, the maximum accuracy obtained was 90%. According to research [18], the Hidden Markov model (HMM) method outperformed the k-nearest neighbor (KNN), Naïve Bayes (NB), and LSM methods (ANN) with an average accuracy classification rate was 93.2%. A dataset from 91 participants that were kept for 27.76 h was used in the research [19] used a dataset stored for 27.76 h from 91 people. The CNN approach was employed in this investigation. Extraction Features take part in these studies that impact the accuracy value. Because feature extraction may characterize data that provides information about the most prominent aspects, it has become absolutely important in terms of data-related issues [20].
The goal of this research is to develop a HAR that can detect the activities of the elderly using datasets. The dataset consists of each axis’ acceleration and gyroscope data. This dataset was created from a sample of 10 individuals, split into 4 classes. Walking, Falling, Sitting to Standing, and Standing to Sitting are the four classes in question. From the collected dataset, it is continued with the preprocessing stage with an amount of data 28,958. Using the XGBoost method, the data from the preprocessing results will select the top 4 extraction features. The top 4 extraction features were chosen to improve system performance during classifying operations. The four most successful extraction characteristics will be used as the data for processing using stochastic gradient descent, random forest, K-nearest neighbor, decision tree, and Gaussian Naive Bayes. We will select one of the best machine learning methods from among the five by comparing the average accuracy values acquired. The best machine learning method produced will be followed by an evaluation of the training data results utilizing the confusion matrix.
2 Method and Material
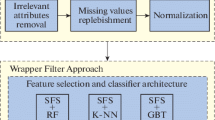
This experiment uses a dataset that looks at the inertial sensor’s acceleration and gyroscope values as an input. The position of inertial sensor is placed on the user’s chest so that the measuring point of this inertia sensor is on the chest. This dataset will be preprocessed first using the fast Fourier transform method. After using the fast Fourier transform method is continued by looking at the mean, median, maximum, minimum, skewness, kurtosis, and variance values. From all the extraction features obtained, the selection of the best four feature extractions is carried out using the XGBoost algorithm. Training will be carried out on the four extraction features using the Stochastic Gradient Descent, Random Forest, K-Nearest Neighbor, Decision Tree, and Gaussian Naive Bayes methods to compare the average accuracy values of each machine learning method. The output of this system is the identification of human activity after selecting feature extraction and machine learning approaches. The drilling process is carried out as shown in Fig. 1.

Proposed method
2.1 Datasets
The dataset used is a dataset obtained from 10 samples of subjects for each movement. The dataset sample will be 4 classes. These 4 classes are walking, standing to sitting, sitting to standing, and falling as seen from the acceleration and gyroscope values for every 0.01 s. Each person performs the movement from standing to sitting ten times, sitting to standing ten times, walking for 1 min, and falling 15 times. From the 15 falling activities, there are three variations of the falling movement, five times fall forward, five times fall on the right side, and five times fall on the left side. The method used for sampling is by connecting a push button to the wearable device. When the participant is doing an activity, the participant will press the push button until the activity is over. The wearable device placement system for participants is shown in Fig. 2.

Wearable device placement
2.2 Preprocessing
The preprocessing used in this system is Fast Fourier Transform (FFT). A signal is shifted from the time domain to the frequency domain using the fast Fourier transform. The first step in preprocessing is to analyze the data and utilize the Fast Fourier Transform technique to transform the signal from the time domain to the frequency domain [21]. The best technique for signal processing is called Fast Fourier Trans-form [22]. The general equations for the Fast Fourier Transform are in Eqs. (1) and (2) [23].
where \({X}_{(k)}\) is the value of FFT, N is the size of its domain, and xn is a periodic signal with period n.
2.3 Extraction Features
The preprocessing used in this system is a fast Fourier transform. The next process is grouping the data after collecting the acceleration and gyroscope data in the frequency domain. The data is grouped for every 1 s when frequency domain data is being processed. Using feature extraction, the mean, median, maximum, minimum, skewness, kurtosis, and variance values are obtained from the data every second.
Mean is the statistical formula to calculate the average value of the results of data collection with a formula shown in Eq. (3).
where \(\sum x\) Sum of data and N Number of data.
Median is one of the statistical formulas that aim to get the median value of data collection that has been ordered. The formula for the median can be seen in Eq. (4).
Maximum is a statistical method that has a function in determining the highest value in the collected data.
Minimum is a statistical method with a function that is inversely proportional to the maximum, which is getting the lowest value from the data collected.
Skewness is a statistical method by looking at the level of asymmetry of the data obtained. The following is the formula for the Skewness method, which can be seen in Eq. (5).
where N is Number of data, \({x}_{i}\) is Random variable, \(\overline{x }\) is Mean of the data, and \({\sigma }^{3}\) is Standard Deviation.
Kurtosis is a method by looking at the sharpness of the collected data. To get the sharpness value, it can be shown in Eq. (6).
where \({\mu }_{4}\) is Central moment and \({\sigma }^{4}\) is Standard Deviation.
Variance is a method to find out how far the data is spread. The value can be found in Eq. (7).
where \({S}^{2}\) is Variance, \({x}_{i}\) is Data per index, \(\overline{x }\) is Mean, and n is number of data.
With a dataset in the form of acceleration and gyroscope, Fig. 3 shows a representation of the feature extraction process used in this experiment. The acceleration and gyroscope dataset consists of 3 axes, namely the X, Y, and Z axes. Using the Fast Fourier Transform technique, each of these axes will be transformed into a frequency domain. The data that has been translated into the frequency domain will provide the mean, median, maximum, minimum, skewness, kurtosis, and variance. In order to achieve this, 42 extraction features were used in this experiment.

Feature extraction diagram
2.4 Feature Selection
From all the extracted features obtained, the extraction feature will be selected. This selection aims to reduce the number of feature extractions used for training data. In this selection, the XGBoost algorithm is used. XGBoost is a gradient boosted decision tree extension. It has been used to solve numerous classification issues in various fields [24]. One of these features is that it can determine the best extraction feature. This best feature extraction is obtained by calculating how many features are used to divide the data across all trees. So it will bring up the most dominating extraction features [25].
2.5 Classifier
From survey of classifier that was used for human activity recognition [11], there are several classifiers which have good accuracy modal. There are KNN, Decision tree, and Random Forest. Therefore in this study, it still used that classifier, but for com-parison, Gaussian NB is added. This research can be described whether the important feature will produce a good model with all classifiers.
Stochastic Gradient Descent. It is a simple statistical-based optimization technique that is efficiently used in finding coefficient values to minimize loss (error) functions on a large scale [26]. Generally, stochastic gradient methods are applied to solve optimization issues using Eq. (8).
where {\(fr : r \in \Gamma\)} is a family of functions from \({\mathbb{R}}^{d}\) to \({\mathbb{R}}\) and γ is a Γ-valued random variable, with respect to which the expectation is taken (these notions will be made precise in the following sections). In supervised learning applications, is typically a uniform random variable taking values in the range of {1, 2, …, n}. \(f\) is the total empirical loss function in this case, while {\(fr : r \in \Gamma\)} are the loss functions resulting from the rth training.
Decision Tree Classifier process consists of converting the data format (table) into a tree model, converting the tree model into rules and simplifying the rules. In building a decision tree using the CART algorithm, impurity or entropy and information gain are used to determine the root node [26]. Entropy and information gain in Decision Tree Classifier have a significant impact on the Decision Tree Classifier algorithm. According to Shannon, entropy is a measurement of the amount of data created and the level of uncertainty in that output. According to Shannon, a discrete system’s entropy value is
where pi is the probability of the event occurring.
Knowing how much meaningful knowledge is gathered about the response variables from the explanatory variable is important to the building of a classification tree. This is known as information gain. Information gain can be used to determine how essential or influential an explanatory variable is in relation to the response variable. In terms of entropy, we can describe it as [27, 28]:
Random Forest is an ensemble technique consisting of several decision trees as classifiers. Classes obtained from this classification process are taken from the most Classes generated by the decision tree in Random Forest [26]. Numerous branches of tree classification are possible as a result of the equation. The process known as “majority voting” is the most popular. This function will select the most frequent class that is classified using a tree [27].
K-Neighbors Classifier is a simple classification in classifying features based on the closest distance to adjacent features [26]. The main idea behind this approach is to determine the distance between two classes. The KNN function by default uses the Euclidean distance, which may be determined using the following equation.
where a is the position for the first class and b is the position for the second class [29].
Gaussian Naive Bayes is a Naive Bayes classification model that uses continuous data types, and each type is characterized by Gaussian multivariate or Normal Probability Density Function (PDF). Gaussian Naive Bayes has two parameters mean and variance [26]. Bayesian classifier can be seen in Eq. 12:
where c is a part of Y, which is the total number of activity categories, Y = {c1, c2, …, cN}. N is the number of activity categories overall. d is the total number of characteristics. The ith characteristic is represented by xi [29].
3 Results and Analysis
3.1 Preprocessing
The goal of preprocessing is to change the incoming data’s format so that it can be processed in the right way. The rapid Fourier transform method is used to first preprocess each axis’ time domain acceleration and gyroscope data into frequency domain data. Following the acquisition of the frequency domain value, the feature extraction features of mean, median, maximum, minimum, skewness, kurtosis, and variance are recorded. XGBoost is used to choose the features from the extracted features. The extraction characteristics of Y-Axis Gyroscope mean, X-Axis Acceleration skewness, X-Axis Gyroscope variance, and X-Axis Gyroscope max are the best extraction features based on the results of selecting the most important extraction features. The feature extraction outcomes that most important affect HAR and the resulting Score are shown in Table 1.
3.2 Machine Learning
Using the feature extraction from the outcomes of the preprocessing, compare the machine learning approach with the cross-validation result 3 and test size value 0.2. Table 2 displays a comparison of the average accuracy values for each machine learning method.
The average accuracy value while combining four feature extractions and just one feature extraction is displayed in Table 2. Based on the average accuracy results, the highest average accuracy value is Random Forest with combined feature and Random Forest has the lowest average accuracy value with only using the X-Axis Gyroscope maximum. The average accuracy value of the Random Forest with combined feature is 99.59%, and Random Forest with only using the X-Axis Gyroscope maximum average accuracy value is 61.15%. As a result of Random Forest’s best accuracy with features combined, proceed by looking at the confusion matrix produced by this method. The confusion matrix of Random Forest with combined features can be shown in Fig. 4.

Confusion matrix
Figure 4 demonstrates several errors in the classification of activities in the confusion matrix data. This Figure shows that the test data utilized is a dataset from a 20% split with a total data of 5,791. The amount of each activity’s inaccurate categories are 5 for falling, 0 for walking, 9 for standing to sitting, and 14 for sitting to standing. Table 3 displays the findings of the entire data evaluation.
For each class, Table 3 displays the list of precision, recall, F1-Score, and support values. The data shows that 0.97 and 0.99 correspondingly represent the lowest recall and precision values. The lowest F1 score from this value is 0.98, while the highest F1 score is 1.00. As a result, it can be said that the training results accurately detect HAR due to the value’s high precision, recall, and f1 score. Additionally, it can classify data with a low rate of classification errors in every class.
4 Discussion
These results show that an extraction feature has an impact on how elderly people will classify human activities. We can select the optimal extraction feature for classification using the XGBoost algorithm without using all the acceleration and gyro-scope information on every axis. Therefore, using this discovery, computations for activity classification can be done quickly. Research on HAR using the IMU Sensor has been conducted in the past, such as the [2, 15, 16] research with various inertial sensor placements. The preprocessing method used in this study separates it from that study’s research by time domain to frequency domain conversion and applying statistical techniques. As a result, the dataset used in this study’s training is not made up entirely of raw data for acceleration and gyroscope values from each axis. The mean Y-axis gyroscope, X-axis acceleration skewness, X-axis variance gyroscope, and X-max axis gyroscope are found to be the best combinations for feature extraction in this study using the Xgboost method.
The weakness of this research is that the training process takes a long time. The preprocessing required to obtain a value for machine learning is the explanation. Additionally, the performance of the system decreases with increasing statistical formula complexity. Therefore, a simpler statistical method and a limitation on the amount of extraction features employed during training are required to speed up system performance. Given that falls are frequently experienced by the elderly, the ability to recognize human movement in the elderly makes it possible to administer early treatment in the event of a fall. The consequences of falls in the elderly, which can lead to serious damage or death, necessitate early care.
5 Conclusion
According to the result of this research, this HAR can determine the activities of walking, falling, standing to sitting, and sitting to standing. Feature extraction and machine learning method that is very accurate at detecting HAR has been created. The mean Y-axis gyroscope, X-axis acceleration skewness, X-axis variance gyro-scope, and X-max axis gyroscope are the strongest extraction characteristics discovered in this research. The random forest technique is shown to have the highest average value using these 4 extraction features as training data. 99.59% is the average accuracy value. The training results exhibit high recall, precision, and F1-Score values in addition to high accuracy. The smallest recall value is 0.99, precisely 0.97, and the F1-score 0.98. As a result, using the strongest extraction characteristics and Random Forest method, it is possible to identify HAR, particularly when employed in the elderly with an inertial sensor. This HAR can provide early attention to the elderly by knowing the daily activities of the elderly that can keep track of elderly activities and concentrate more attention on elderly activities, particularly fall activities. Thus, monitors can provide early assistance to the elderly. This research can be expanded by selecting the optimal extraction feature to identify more activity categories, resulting in a better level of accuracy. As well as the installation of inertial sensors to enhance the elderly comfort.
References
Saleh M, Abbas M, Prud’Homm J, Somme D, Le Bouquin Jeannes R (2021) A reliable fall detection system based on analyzing the physical activities of older adults living in long-term care facilities. IEEE Trans Neural Syst Rehabil Eng 29:2587–2594. https://doi.org/10.1109/TNSRE.2021.3133616
Lee DW, Jun K, Naheem K, Kim MS (2021) Deep neural network-based double-check method for fall detection using IMU-L sensor and RGB camera data. IEEE Access 9:48064–48079. https://doi.org/10.1109/ACCESS.2021.3065105
Bekibele CO, Gureje O (2010) Fall incidence in a population of elderly persons in Nigeria. Gerontology 56:278–283. https://doi.org/10.1159/000236327
Ibrahim A, Chaccour K, Hassani AHE, Andres E (2021) Bed-fall detection and prediction: a generic classification and review of bed-fall related systems. IEEE Sens J 21:5678–5686. https://doi.org/10.1109/JSEN.2020.3037711
Howland J, Hackman H, Taylor A, O’Hara K, Liu J, Brusch J (2018) Older adult fall prevention practices among primary care providers at accountable care organizations: a pilot study. PLoS ONE 13:1–10. https://doi.org/10.1371/journal.pone.0205279
Cagliyan B, Karabacak C, Gurbuz SZ (2014) Indoor human activity recognition using BumbleBee radar. 1055–1058. https://doi.org/10.1109/siu.2014.6830414
Li X, He Y, Fioranelli F, Jing X (2022) Semisupervised human activity recognition with radar micro-doppler signatures. IEEE Trans Geosci Remote Sens 60:1–12. https://doi.org/10.1109/TGRS.2021.3090106
Cheng C, Ling F, Guo S, Cui G, Jian Q, Jia C, Ran Q (2020) A real-time human activity recognition method for through-the-wall radar. In: IEEE national radar conference—proceedings, 2020 Sept. https://doi.org/10.1109/RadarConf2043947.2020.9266393
Zhu JP, Chen HQ, Ye WB (2020) Classification of human activities based on radar signals using 1D-CNN and LSTM. Proceedings—IEEE international symposium on circuits and systems, 2020 Oct. https://doi.org/10.1109/iscas45731.2020.9181233
Babiker M, Khalifa OO, Htike KK, Hassan A, Zaharadeen M (2018) Automated daily human activity recognition for video surveillance using neural network. In: 2017 IEEE international conference on smart instrumentation, measurement and applications, ICSIMA 2017, 2017 Nov, pp 1–5. https://doi.org/10.1109/ICSIMA.2017.8312024
Gupta A, Gupta K, Gupta K, Gupta K (2020) A survey on human activity recognition and classification. In: Proceedings of the 2020 IEEE international conference on communication and signal processing, ICCSP 2020, pp 915–919. https://doi.org/10.1109/ICCSP48568.2020.9182416
Lamghari S, Bilodeau GA, Saunier N (2020) A grid-based representation for human action recognition. In: Proceedings—international conference on pattern recognition, pp 10500–10507. https://doi.org/10.1109/ICPR48806.2021.9413136
Abdul Manaf F, Singh S (2021) Computer vision-based survey on human activity recognition system, challenges and applications. In: 2021 3rd international conference on signal processing and communication, ICPSC 2021, pp 110–114. https://doi.org/10.1109/ICSPC51351.2021.9451736
Banjarey K, Prakash Sahu S, Kumar Dewangan D (2021) A survey on human activity recognition using sensors and deep learning methods. In: Proceedings—5th international conference on computing methodologies and communication, ICCMC 2021, pp 1610–1617. https://doi.org/10.1109/ICCMC51019.2021.9418255
Zebin T, Scully PJ, Ozanyan KB (2017) Evaluation of supervised classification algorithms for human activity recognition with inertial sensors. In: Proceedings of IEEE Sensors, 2017 Dec, pp 1–3. https://doi.org/10.1109/ICSENS.2017.8234222
Perez-Gamboa S, Sun Q, Zhang Y (2021) Improved sensor based human activity recognition via hybrid convolutional and recurrent neural networks. In: INERTIAL 2021—8th IEEE international symposium on inertial sensors and systems, proceedings, pp 0–3. https://doi.org/10.1109/INERTIAL51137.2021.9430460.
Bijalwan V, Semwal VB, Gupta V (2022) Wearable sensor-based pattern mining for human activity recognition: deep learning approach. Ind Robot 49:21–33. https://doi.org/10.1108/IR-09-2020-0187
Wang Z, Chen Y (2017) Recognizing human concurrent activities using wearable sensors: a statistical modeling approach based on parallel HMM. Sens Rev 37:330–337. https://doi.org/10.1108/SR-01-2017-0003
Shavit Y, Klein I (2021) Boosting inertial-based human activity recognition with transformers. IEEE Access 9:53540–53547. https://doi.org/10.1109/ACCESS.2021.3070646
Salau AO, Jain S (2019) Feature extraction: a survey of the types, techniques, applications. In: 2019 international conference on signal processing and communication, ICSC 2019, pp 158–164. https://doi.org/10.1109/ICSC45622.2019.8938371
Palupi IR, Raharjo W (2021) The utilization of signal analysis by using short time Fourier transform. In: RSF conference series: engineering and technology, vol 1, pp 30–36. https://doi.org/10.31098/cset.v1i1.445
Cooley JW, Lewis PAW, Welch PD (1969) The fast Fourier transform and its applications. IEEE Trans Educ 12:27–34. https://doi.org/10.1109/TE.1969.4320436
Islam MN, Sulaiman N, Rashid M, Bari BS, Hasan MJ, Mustafa M, Jadin MS (2020) Empirical mode decomposition coupled with fast Fourier transform based feature extraction method for motor imagery tasks classification. In: 2020 IEEE 10th international conference on system engineering and technology, ICSET 2020—proceedings, pp 256–261. https://doi.org/10.1109/ICSET51301.2020.9265370
Cherif IL, Kortebi A (2019) On using eXtreme gradient boosting (XGBoost) machine learning algorithm for home network traffic classification. In: IFIP wireless days, 2019 Apr, pp 1–6. https://doi.org/10.1109/WD.2019.8734193
Hsieh CP, Chen YT, Beh WK, Wu AYA (2019) Feature selection framework for XGBoost based on electrodermal activity in stress detection. In: IEEE workshop on signal processing systems, SiPS: design and implementation, 2019 Oct, pp 330–335. https://doi.org/10.1109/SiPS47522.2019.9020321
Géron A (2017) Hands-on machine learning
Baines O, Chung A, Raval R (2020) Random forest classification algorithm. Math Res J 500
Zhong Y (2016) The analysis of cases based on decision tree. 2016 7th IEEE international conference on software engineering and service science (ICSESS). https://doi.org/10.1109/icsess.2016.7883035
Shen J, Fang H (2020) Human activity recognition using Gaussian Naïve Bayes algorithm in smart home. J Phys Conf Ser 1631:0–5. https://doi.org/10.1088/1742-6596/1631/1/012059
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Ismail, Istiqomah, Mukhtar, H. (2023). Development Human Activity Recognition for the Elderly Using Inertial Sensor and Statistical Feature. In: Triwiyanto, T., Rizal, A., Caesarendra, W. (eds) Proceeding of the 3rd International Conference on Electronics, Biomedical Engineering, and Health Informatics. Lecture Notes in Electrical Engineering, vol 1008. Springer, Singapore. https://doi.org/10.1007/978-981-99-0248-4_21
Download citation
DOI: https://doi.org/10.1007/978-981-99-0248-4_21
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-99-0247-7
Online ISBN: 978-981-99-0248-4
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)