
Abstract
Communication is an essential need for every person in society. This socializing can be in audio, video and text forms. Gestures are the natural expressions of communication to facilitate a specific meaning. These gestures are combined with facial expressions to form a tool for the speech impaired and the hearing impaired which is known as Sign language. It varies according to the country’s native language as American Sign Language, British Sign Language, Japanese Sign Language, Indian Sign Language, etc. The researches in the field of SL recognition have been increased tremendously in the last 10 decades. This paper mainly aims at developing a Human Machine Interface based on gestures. Indian Sign Language is a visual-gestural language used to bridge the gap of differences within society and speech and hearing impaired, exclusion of translators and independent expressiveness. This system is designed with a wearable glove utilizing ten flex sensors and two accelerometers to recognize the words in the sign language vocabulary. The classified results are sent to voice module, where the voice corresponding to the gesture is played back through a speaker. The results of the first version of glove without accelerometers had an accuracy of 74.12%. The accuracy was improved to 97.2% in the second version by the placement of accelerometers over the back side of palm on both hands. Both the versions were verified with datasets varying with gender and signer. The proposed glove excels the existing gloves on constraints of sign misclassification, expenses and others related to image-based gesture recognition. Future extensions of this glove would be modification for other country’s sign language recognition or gesture-based controlled devices.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Sign Language plays a pivot role in the social life of speech and hearing impaired people. To exchange the information between normal people, the gestures of SL are translated into English words text or voice outputs by Sign Language Recognition (SLR) using HMI. Fingers and hand shapes possess maximum information related to HMI. The input forms of HMI can be gesture voltages or images. The common hindrances in image-based gesture recognition were complex backgrounds, fixed Field of View (FOV), more number of cameras required, overlapping of face expressions with hand movements and occlusion. The most preferred SLR is sensor-based because of cost effectiveness, portability and less power consumption. Sign language is not universal all over the world. There exist 135 legally approved Sign languages like Ukrainian Sign Language (USL), Japanese Sign Language (JSL), Arabic Sign Language (ArSL), etc. In this paper, ISL gestures are considered. ISL is a combination of verbal and nonverbal signs, a combination of single and double handed gestures and it has its own grammatical structuring style.
According to India’s National Association of the Deaf, there are about 1.3 million populations are speech and hearing impaired people. Among them the working percentage as main, marginal and non-workers are shown in Fig.1. It depicts that due to the inconvenience of expressing themselves they could not obtain good education and occupation facilities available in the society. Hence, an ISL-based prototype has been designed to excel the obstructions of the technology and the emotional issues of the speech and hearing impaired people.

Source 2011 census
Disabled worker population state wise in India.
The other sections of this paper are organized as follows. Section II provides the related papers dealing with SLR based on sensors and stimulation results using Lab VIEW. Section III describes the components used in this setup, workflow of the glove and the generation of two datasets. Section IV presents the results of sensor over two datasets, variation between them and the classification procedure using MMSE algorithm and it discusses the recognition rate based on sensor fusion. Finally, Section V includes the conclusion of this study.
2 Literature Survey
The studies in the field of SLR started in the early 70’s itself. Researchers have developed glove-based systems for sign languages and other gesture control applications. A word recognition in time normalization using slope constraint and symmetric form algorithms [1]. The Markov model was used to recognize a 40-word lexicon for American Sign Language (ASL) images [2]. The gray scale images of the American Sign Language (ASL) by morphological filtering to classify hand gestures [3]. The gestures were recognized for the survey of feature extraction and acquisition for transitions and adoptions [4]. German Sign Language (GSL) was analyzed by intrinsic mode entropy by three native signers and differentials processed [5]. ISL was recognized for 10 images including ‘UP’ and ‘DOWN’ positions feature point method into text [6]. For the conversion of Unified Arabic Sign Language (UASL) to the American Sign Language (ASL), a dictionary was designed on the basis of a web-based application. It was presented using a graphical interface for 1400 signs and various categories as colors. These video sequences were captured at a width and height of 1920 × 1080 [7]. A set of 18 gestures were described and recognized using a 3-axis accelerometer and determined the corresponding actions by the concept of random projection [8]. A sign language recognition system based on Hindi language was designed with Cepstral features. The images were processed for two models processed using Support Vector Machine (SVM) and Neural Network (NN) and testes for best score efficiency [9]. The converted gestures of British Sign Language to text output using sensor gloves for single handed. Adithya et al. [10] designed a neural network with the images of finger spelling of ISL gestures [11]. The detection of the finger bending using piezoresistive sensors and by the method of MMSE text converted to speech [12].
The principle of surface electromyography signals was used in Bayesian classifier to manipulate mobile phone working [13]. The multisensory techniques developed to train a classifier to learn hand positions and orientation with a higher pose of reduced error by 30% [14]. The Arabic Sign Language alphabets captured by both image processing and sensor gloves and both were compared on the basis on cost, efficiency, user preference, etc. [15]. An Urdu Sign Language system was designed which has been captured for 9 images whose features have been extracted and classified by PCA [16]. A LabVIEW–VI-based glove was designed and developed for paralyzed patients based on their hand and eye movements. Commands translated were water, food and pain [17]. A rehabilitation robot was proposed for hand for data acquisition from five hands in the VI [18]. A robotic arm was implemented for limb disabled people using servo motors, working based on commands from the flex sensor on the other hand for lifting and other purposes [19]. A gesture controlled vehicle based on Ultrasonic sensors. Any obstacle on the path detected then vehicle would go around the obstacle [20]. A numerically evaluated rehabilitation device for specific set of four exercises were designed from a set of 12 subjects. Based on the degrees of freedom for the shoulder, elbow and wrist joints, different flexions were planned accordingly, to improve an automated therapeutic treatment [21]. Levenberg Fractional Bat Neural Network (LFBNN) was proposed for voice-based recognition system. Evaluation is based on the metric such as FAR, FRR and accuracy achieved till 95 % for any voice-based operating models [22]. A sign language recognition system based on Hindi language was designed with Cepstral features. The images were processed for two models processed using Support Vector Machine (SVM) and Neural Network (NN) and testes for best score efficiency [9].
Summarizing the blocks in the recognition techniques were as follows. The gesture image-based processing, only alphabets detected, implemented for the other countries’ sign languages, words were detected concatenating each letter’s gesture. The general hand gestures were recognized by application based and mostly single handed symbols. In some papers the types of movements were limited to up and down positions only. To overcome the above mentioned problems, this glove is designed and developed.
3 System Design Flow
3.1 Hardware Design
In this SLR an Sign and Sound (SS) glove is designed for both hands as shown in Fig. 2. In the first version of SS Glove, it is equipped with flex sensors stretched over the ten fingers to measure the bending degree of the three joints in the finger phalanges (Distal, Medial and Proximal). These flex sensors can accommodate within age group varying from 18 to 50 years and distinct sizing of fingers. In the second version of SS glove it is included with accelerometer to measure the rotation, orientation and tilt positions of both the hands. The 3-axis accelerometer is located over the metacarpal bones and carpal bones to obtain the entire hand inclinations. These accelerometers are light in weight and accurate in angle outputs. Sensors are stitched to the glove in a fit manner, as it remains fixed even during hand movements. The two different types of flex sensors employed in SS glove are 2.2 in.’ flex sensor (only for baby finger) and 4 in. single axis digital flex sensors are shown in Fig. 3. The bending resistance exhibited by the 2.2 in. is 10 K ohms and 4.5 inch ranges from 60 to 110 K (Source:www.sparkfun.com). Each 4.5 in. flex sensor cost 3800 Rupees and 2.2 in costs 680 rupees.

Glove (First version without accelerometer)

Two variations in the flex sensor
Sensor glove selected material was neoprene nylon glove due to the following reasons:
-
o
Provides fine grip and good tensile strength to fingers attached with sensors.
-
o
Light in weight and durable for long term usage and frequent finger movements.
-
o
Easily stretch back to the original size when fingers are bent fully.
-
o
Absorbs sweat produced by the fingers and reduces the hazards of electrical shocks.
-
o
Does not get affected by any oily substances, as the glove repeals these substances.
-
o
On a large scale usage, Neoprene nylon glove does not provide any allergic to the user’s hand or finger.
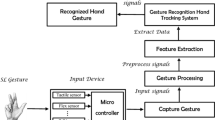
The SLR system for this specialized glove has been divided into three units: a sensor acquisition unit, processing unit and voice module and LCD unit as shown in Fig. 4. The flex sensor and the digital flex sensor are operated at 5 V and 3.3 V @10 Hz respectively to produce an electrical output proportional to the bending of finger. The sensor data are preprocessed prior to feature extraction and then provided to SVM classifier for the recognition of ISL gestures. This SLR is mainly designed to recognize the 18 words of ISL as presented in Table 1. Gestures of the selected words according to the standardized ISL are illustrated in Fig. 5. These words are detected as the output of SVM and they are transferred to the text and voice units using ZigBee technology. The recognized words equivalent to gestures were displayed in LCD and corresponding voice outputs played through speaker. The power supply of 5V for the entire SLR system is provided by the rechargeable Lithium batteries.

Overview of SLR system divided into three unit

Confusion matrix of ISL word dataset
3.2 Experimental System Flow
Trained 24 subjects from speech and hearing impaired educational institutions have participated in the survey. The subjects taken into consideration were in the age group of 15 to 50 (ranging from school, college, trainers). The subjects should not have Upper Limb Disorders (ULDs): Carpal Tunnel Syndrome (CTS), tendonitis and Hand-Arm Vibration Syndrome (HAVS). Four datasets were formed variation in gender and signer.
-
First set (24 male participants signer dependent with varying age groups)
-
Second set (24 male participant signer independent with varying age groups)
-
Third set (24 females’ participant’s signer dependent with varying age groups)
-
Fourth set (24 females’ participant’s signer dependent with varying age groups).
All the subjects performed each word’s gesture repeated 6 times with a duration of 5 s for each word performed. The entire datasets sensor voltages are stored in memory card for further processing.
In the second version of SS glove flex sensors are combined with 3-axis accelerometer to acquire the inclinations of the hand. It is placed on the dorsal (i.e., back side of palm) side of SS glove.
ACC monitors angle, rotation and orientation of each gestures. ACC works on the principle based on a small mass over silicon surface suspended by beams which produces a force. This force displaces according to the movements of the MEMS accelerometer placed over glove and produces X, Y and Z axes measurement. ACC inclusion improves the accuracy of the SS glove without affecting cost and weight parameters.
4 Methodology
Four dataset’s results inferred that sensor outputs vary depending upon subject’s hand size. As for small size variations among results are less and for large hand sizes vice versa. Normalization of data avoids all these problems, subject’s sensor outputs are estimated to mean, standard deviation based on time domain approaches as in Eq. (1). These normalized sensor outputs for two ISL word gesture are shown in Table 2.
where σ is the standard deviation, μ is the mean, N is the number of subjects, xi current sensor output. Similar procedure is conducted for all words from each of the four datasets both flex sensor and accelerometer. Prior to all, sensors are calibrated at divergent positions. Flex sensors
are tested at no bend, half bend and full bend. ACC are tested at hand shapes which are inclined at up, down, tilting right and left to calculate the x, y, z axes measure. The flex sensor output is converted into electrical signal by voltage divide using a 10 k ohm resistor. In the 3-axis accelerometer the chip itself produces voltage output of X, Y and Z axes. These analog voltages values would be transformed into digital values. The process of digitization is done by analog to digital convertor (ADC) within the microprocessor. Hence, the digital output can be applied to observe variations in ISL word’s gestures. Including the difference taken from samples either from a single-user or a multi-user, as the selection of features is based on these factors. This process begins at the press of calibration button on the Arduino lily pad, indicated by blueLED.
4.1 Feature Selection
Words in the dataset, were selected on the frequency of usage by the speech and hearing impaired people on the day to day life. The words are categorized prescribing emotions, public communication, workplace, services, offerings, etc. To recognize these words, a unique differentiation among sensor outputs is required. Flexion degree after calibration, is measured for each word in the dataset. The voltage ranges of no bend (), half bend () and full bend (). Similarly, the ACC axis ranges from X-axis (), Y-axis () and Z-axis (). Flex sensor bends are indicated as no bend-FB0. Halfbend-FB1, full bend-FB2. ACC measures are represented as X-axis (XA), Y-axis (YA) and Z-axis (ZA).
These regions are exclusively listed for each word in the dataset as shown in Table 2. It was noticed that flex sensor exhibits similar outputs for words ‘Question’, ‘Month’, ‘Year’, ‘Family’, ‘Gift’, ‘Help’ and ‘Teacher’. To avoid this misclassification, ACC have been integrated into the SS glove.
Problems of same finger bending are overcome by estimating the inclination of the hand shape of the gesture by ACC. ACC yields three axes measurement wrt gesture hand positioning, palm parallel to ground indicates X-axis, perpendicular to ground indicates Y-axis and at an inclination to the ground indicates Z-axis. The words ‘Month’ and ‘Year’ mostly match in the finger bending, so to distinguish among them the X-axis of ‘Month’ fed an output of 3.45V and Y-axis of ‘Year’ fed an output of 4.01 V. The same pattern is observed to differentiate words like ‘Family’ and ‘Teacher’. Finally, some words ‘Gift’, ‘Help’ and ‘Question’ are yet to be differentiated by the estimated of two other parameters Mean absolute deviation (MAD) and Root Mean square (RMS). ACC exhibit X-axis for both words ‘Gift’ and ‘Help’, so these parameters are employed for further classification. The MAD and RMS of ‘Help’ were 3.57 V and 3.11 V and for ‘Gift’ were 2.99 V and 2.05 V, respectively. Hence MAD and RMS serve as support to complete the classification with high accuracy.
4.2 Gesture Classification
In this glove, the gestures are classified into 18 classes using Support Vector Machine (SVM). An SVM is a supervised machine learning for multiple data classification, since it is theoretical and computational efficient. With the labeled support vectors (among the samples) and optimal hyperplanes, the decision of classes are taken. Raw data are converted into 1D support vectors using kernels and 2D using transforms. The decision boundary should consider all the points in the dataset as stated in Eq. (2):
where x is the sample in dataset, y is the label assigned to dataset, w is the width between hyperplanes and support vectors, b is the proportionality constant. The optimal decision boundaries are selected by satisfying the condition as in Eq. (3).
The smallest distance between the support vectors is calculated for the entire sample size and minimized for optimization purpose. For each correct classified word label y yields +1 and incorrectly classified word yields −1 known as neutral class.
In this SLR, n-classes of SVM classifier are required to distinguish one class from the other. These classifiers average is estimated to a parameter called confidence value. Higher the confidence value (greater than 0.5) indicates the higher probability of selection of the corresponding class.
4.3 Feature Extraction
For the ISL words classification, a feature vector X has been considered which is comprised of 16 built in features. Features were flex sensors over the ten fingers, 3 readings from each ACC over two hands. This feature set is unique for 18 words in the dataset. On collective basis, the total amount of sample size is given as per Eq. 4.
Hence, 25,92,000 sample dataset are trained using SVM in a similar procedure for all words and calculate the accuracy, which is illustrated using a confusion matrix as in Fig. 5. A confusion matrix is a diagrammatic representation of the performance of the classifier and computes performance metrics as mentioned.
-
(1)
Accuracy = TP + TN/(Total)
-
(2)
Misclassification Rate = (FP + FN)/total
-
(3)
Precision (P) = TP/(TP + FP)
-
(4)
Recall (R) = TP/(FN + TP)
-
(5)
F-Score = 2[(P × R)/(P + R).
5 Results Anddiscussion
5.1 Experimental Results
Words were classified into three groups: Home, Public and Work as in Table 1. For the purpose of observing the notable variation, for instance two words ‘Children’ and ‘Gift’ are considered. The gesture for the word ‘Children’ is that both hands are half bend and with both palms facing toward ground side as each finger is bent to form a triangular shape.
The ‘Gift’ word gesture was indicated with both hand fully bent and placed over each other in the horizontal direction. Fig. 6a depicted a typical example of the flex sensor value plotting for the words ‘Children’ (blue) and ‘Gift’(orange). The regions which are analyzed are similar to those mentioned in the Table 2. Large and unique variations could not be observed from the flex sensor output which leads to misclassification of words. To solve this, sensor fusion technique has been employed by the inclusion of ACC as shown in Fig. 6b, which yields clear distinction as increase in the Y-axis of the ACC for the word ‘Gift’. By similar ways the misclassification is reduced and the accuracy rate has been increased by 30.2% from the first version to the second version for words ‘Question’, ’Gift’, ’Help’ and ‘Year’ in Table 2.

Sensor plot for ‘Children’ and ‘Gift’ a Flex sensor variation b ACC variation over both hands
Still there were minor misclassifications present in the second version. This was due to the smaller difference in flex sensor and ACC voltage outputs for the most subjects. Thus, half bend was interpreted as no bend and X-axis was combined with Y-axis reading. For instance, while considering words ‘Answers’ and ‘Teacher’ both the similar regions for flexion vector of index and middle fingers and in the same X-axis which produce false classification. To invariant these rates two additional parameters were trained in SVM.
Sensor outputs have heterogeneous features based on time domain, frequency domain and time-frequency domain. From these time-frequency domain characteristics are more complex and time consuming than time-domain characteristics. Therefore, time-domain features have been preferred as they are more advantageous. The first parameter determined was Mean Absolute Deviation (MAD) is a method of calculating average distance from each output to mean. MAD tells how the values in the dataset have been spread which have been analyzed by the Eq. (5).
The second parameter computed based on sensor output was
Root Mean Square (RMS) is the square root of the mean or average value of the squared function of instantaneous value of any AC sinusoidal and non-sinusoidal signals. RMS value can be calculated by Eq. (6).
From the Table 2 it is observed that, sensor output modifies as per the ISL gestures. These outputs are presented along with their standard deviation values. On examining, the gestures can be judged and varied. This was done by the variation in the assessment of the Mean Absolute Deviation (MAD) and Root Mean Square (RMS). Similar approach can be done for all other word’s ISL symbol and gesture can be recognized to their corresponding words.
6 Conclusion
In this study, the specialized SS Glove has been designed and implemented successfully as a smart device to recognize the ISL words using SVM. A voice module with speaker translates the recognized gesture into voice in a time and portable efficient manner. The device was tested personally with the subjects and collected feedback in terms of accuracy, comfort and cost. Depicted in Fig. 6. This glove would serve as an aid to communication from speech and hearing impaired people of age ranging from 15 to 50 years. Kinesics of ISL is conquered by both the right and the left hands. Sensor fusion of Flex sensor and ACC are used to improve accuracy from 74.12% to 97.2 %. Some of the demerits of glove-based system would be to make the gesture movement cumbersome and weigh high due to sensors, which can be rectified in future versions. The possible extension of this proposed glove would be miniaturization of the entire device, inclusion of sentence structure of ISL and experiment gestures of other SL as ASL, JSL, etc.
References
Sakoe H, Chiba S (1978) Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans Acoust Speech Signal Process 26(1):43–49
Starner T, Weaver J, Pentland A (1998) Real-time American sign language recognition using desk and wearable computer based video. IEEE Trans Pattern Anal Mach Intell 20(12):1371–1375
Gupta L, Ma S (2001) Gesture-based interaction and communication: automated classification of hand gesture contours. IEEE Trans Syst Man Cybern Part C (Appl Rev) 31(1):114–120
Ong SC, Ranganath S (2005) Automatic sign language analysis: a survey and the future beyond lexical meaning. IEEE Trans Pattern Anal Mach Intell 6:873–891
Kosmidou VE, Hadjileontiadis LJ (2009) Sign language recognition using in- trinsic-mode sample entropy on sEMG and accelerometer data. IEEE Trans Biomed Eng 56(12):2879–2890
Rajam PS, Balakrishnan G (2011) Real time Indian sign language recognition system to aid deaf-dumb people. In: IEEE 13th international conference on communication technology, pp 737–742
AlQallaf AH (2018) Development of a web-based unified Arabic/American sign language bilingual dictionary. J Eng Res 6(2)
Akl A, Feng C, Valaee S (2011) A novel accelerometer-based gesture recognition system. IEEE Trans Signal Process 59(12):6197–6205
Patil UG, Shirbahadurkar SD, Paithane AN (2019) Linear collaborative discriminant regression and Cepstra features for Hindi speech recognition. J Eng Res 7(4)
Adithya V, Vinod PR, Gopalakrishnan U (2013) Artificial neural network based method for Indian sign language recognition. IEEE Conf Inf Commun Technol 1080–1085
Sharma V, Kumar V, Masaguppi SC, Suma MN, Ambika DR (2013) Virtual talk for deaf, mute, blind and normal humans. Tex Inst India Educators’ Conf 316–320
Preetham C, Ramakrishnan G, Kumar S, Tamse A, Krishnapura N (2013) Hand talk-implementation of a gesture recognizing glove. Tex Inst India Educators Conf 328–331
Lu Z, Chen X, Li Q, Zhang X, Zhou P (2014) A hand gesture recognition framework and wearable gesture-based interaction prototype for mobile devices. IEEE Trans Hum-Mach Syst 44(2):293–299
Rossol N, Cheng I, Basu A (2015) A multisensor technique for gesture recognition through intelligent skeletal pose analysis. IEEE Trans Hum-Mach Syst 46(3):350–359
Mohandes M, Deriche M, Liu J (2014) Image-based and sensor-based approaches to Arabic sign language recognition. IEEE Trans Hum-Mach Syst 44(4):551–557
Kanwal K, Abdullah S, Ahmed YB, Saher Y, Jafri AR (2014) Assistive glove for Pakistani sign language translation. In: 17th IEEE international multi topic conference, pp 173–176
Saini GK, Kaur R (2015) Designing real-time virtual instrumentation system for differently abled using LabVIEW. Int J Biomed Eng Technol 18(1):86–101
Guo J, Li N, Guo S, Gao J (2017) A LabVIEW-based human-computer interaction system for the exoskeleton hand rehabilitation robot. IEEE Int Conf Mechatron Autom (ICMA) 571–576
Latif S, Javed J, Ghafoor M, Moazzam M, Khan AA (2019) Design and development of muscle and flex sensor controlled robotic hand for disabled persons. Int Conf Appl Eng Math (ICAEM) 1–6
Vishwanathraddi, Chakravarthi K (2017) Arduino-based wireless mobot. Asian J Pharm Clin Res Spec 61–65
Chaparro-Rico BDM, Cafolla D, Castillo-Castaneda E, Ceccarelli M (2020) Design of arm exercises for rehabilitation assistance. J Eng Res 8(3)
Srinivas V (2020) LFBNN: robust and hybrid training algorithm to neural network for hybrid features-enabled speaker recognition system. J Eng Res 8(2)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Harish, M.N., Poonguzhali, S. (2023). Gesture Recognition Glove for Speech and Hearing Impaired People. In: Khosla, A., Kolhe, M. (eds) Renewable Energy Optimization, Planning and Control. Studies in Infrastructure and Control. Springer, Singapore. https://doi.org/10.1007/978-981-19-8963-6_8
Download citation
DOI: https://doi.org/10.1007/978-981-19-8963-6_8
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-8962-9
Online ISBN: 978-981-19-8963-6
eBook Packages: EnergyEnergy (R0)