
Abstract
High-entropy alloys (HEAs) possess vast compositional space making them a suitable type of metallic alloy material that can be customized for a wide range of engineering applications ranging from structural, catalytic, functional, hydrogen storage and metamaterials. Predicting the phase of an HEA for a given composition in a certain molar ratio is a daunting task, and hitherto, trial-and-error approaches are employed. With the emergence of data-driven machine learning (ML) technique newer avenues have emerged to reduce the complexity in this task. In this work, we provide a canon of research in this area and used a testbed study by deploying random forest classifier (RFC) to predict distinct phases of HEAs, such as intermetallic (IM), BCC solid-solution (BCC_SS), FCC solid-solution (FCC_SS), and mixed (FCC + BCC) phase. With an average accuracy of 86%, a ROC_AUC score of 0.965, and tenfold cross-validation ROC_AUC score of 0.903, the random forest model showed great ability and prospects in future discovery of novel phases of HEAs. Based on this analysis, the input parameters such as the mixing enthalpy (ΔHmix) and valence electron concentration (VEC) were identified most influential in governing the stable phase of an HEA.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Conventional alloys made from iron, aluminium, titanium, magnesium, and many others are prepared by mixing one or sometimes two principal elements with some secondary alloying elements in small proportions. Cantor alloys also recognized now as high-entropy alloys shows a unique characteristic that by mixing at least five metallic elements such that when the mixing percentage vary from 5 to 35% in an equimolar composition produces a single solid-solution phase which is crystalline in nature [1]. By virtue of this, HEAs offer high specific strength [2, 3], excellent stability at high temperatures, exceptional ductility [4], and high corrosion resistance and others [5]. Unlike conventional alloys, HEAs possess a trend of ‘stronger being more ductile’ [6, 7].
Cantor suggests that as many as ~ 108 varieties of HEAs can be developed using 44–64 elements from the chemical periodic table [8]. Many of these HEAs are yet to be synthesized in the lab and Yeh [9] suggests that “still a lot more treasure exist in non-equimolar HEAs”. In developing an alloy, a considerable number of input parameters such as its composition, synthesis route, processing window, temperature, heating/cooling rate are required to obtain its crystallographic information and mechanical, electrical and functional properties of interest. Thus, relying on traditional laboratory experiments for novel material discovery can be very time-intensive.
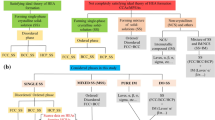
Machine learning (ML) has emerged as a sophisticated and reliable technique in replacing repetitive laboratory experiments and computational simulations such as Density Functional Theory (DFT) and Molecular Dynamics (MD) [10]. DFT method predicts material properties using quantum mechanics and can at times be erroneous [11]. MD on the other hand analyse atoms by numerically solving Newton’s equations of motion [12]. MD continues to suffer from the drawback on having reliable interatomic potential functions. Thus, ML provides a robust alternative tool based on the reliance of historical data and a mathematic way by pattern recognition technique. This in turn enhances our ability to extract salient features from within the data which are otherwise not readily visible even to an experienced researcher. A summary of various ML algorithms currently being used is shown in Fig. 1a which formed the core of this paper.

1.1 ML Algorithms
ML algorithms are broadly classified into three categories based on their type of learning, namely supervised, unsupervised, and reinforcement learning shown in Fig. 1b [13, 14].
1.1.1 Supervised Learning
As the name suggests, supervised ML algorithms are taught by providing a labelled dataset that includes input and output variables. The objective of supervised learning is to map input (x) and output (y), using a linear or nonlinear function, for instance, y = f(x) [14].
1.1.2 Unsupervised Learning
In unsupervised ML algorithms, unlabelled dataset is used to train an algorithm, where inputs are not labelled with the correct outputs. The goal is to model the underlying structure or to discover the patterns in the data. The unlabelled data in the unsupervised learning is used to train algorithms for clustering and association problems.
1.1.3 Reinforcement Learning
Reinforcement learning is based on reward or punishment methods, where an agent learns to perceive and interpret its complex environment; it takes actions and learns through the trial-and-error method. It is devised to reward the desired behaviour by assigning a positive value to encourage the agent and punishing the undesirable behaviour by assigning negative values to penalize the agent. An agent either gets an award or a penalty based on the actions it performs, and the ultimate goal is to maximize the total reward. Over time, the agent learns to avoid the negative and seek the positive, thus learns the ideal behaviour to optimize its performance.
Current study focuses on a supervised ML algorithm, as the labelled data is employed for phase prediction of HEAs. A detailed description of all supervised ML algorithms has been discussed in Table 1.
1.2 Literature Review
Recently, there has been a surge in the number of publications on phase prediction of HEAs using various ML techniques. Islam et al. [15], Huang et al. [16] and Nassar et al. [17] employed neural networks in their study for phase prediction of HEAs and observed an average accuracy of 83%, 74.3%, and 90%, respectively, by using a relatively smaller number of datasets. These models considered five physical parameters namely mixing entropy (∆Smix), valence electron concentration (VEC), atomic size difference (δ), mixing enthalpy (∆Hmix), and electronegativity difference (∆χ). Choudhury et al. [18], used a random forest regression algorithm for the classification of different phases and crystal structures and obtained an accuracy of 91.66% for the classification of phases and 93.10% for the classification of different crystal structures, respectively.
To significantly improve the phase prediction accuracy, Risal et al. [19], compared Support Vector Machine (SVM), K-Nearest Neighbour (KNN), Random Forest (RF) classifier, and Multi-layer perceptron (MLP). KNN and RF Classifiers performed most effectively and obtained the test accuracy of 92.31% and 91.21%, respectively, whilst SVM and MLP provided satisfactory performance with accuracies greater than 90%. Several similar studies have recently reported about the phase prediction and various mechanical properties which are summarized briefly in Table 2.
From the aforementioned literature, the random forest algorithm was observed to be the most prominently used algorithm in phase prediction studies, due to its high predictive performance. Therefore, the present study used random forest algorithm with the motive of correctly classifying each phase of HEAs for an imbalanced dataset. Scarce studies on the interpretation of the inner-working of an algorithm have been found in the literature. Thus, an additional attempt to decipher the black-box nature of the employed random forest algorithm has also been made using SHapely Additive exPlanation (SHAP) technique.
1.3 Data Source
A dataset of 1360 HEA samples was used to classify different phases of HEAs [30]. This dataset was observed to be highly imbalanced, as it contained 463 Intermetallic (IM), 441 BCC solid-solution (BCC_SS), 354 FCC solid-solution (FCC_SS), and 102 mixed (FCC + BCC) phase. Five crucial features such as valence electron concentration (VEC), electronegativity difference (∆χ), atomic size difference (δ), mixing enthalpy (dHmix), and mixing entropy (∆Smix) calculated by Miedema’s model were used as input parameters in the dataset. The ML modelling framework for the classification of four different phases of HEAs are demonstrated in Fig. 2, where data preprocessing is performed to detect outliers and missing values, and then feature scaling was performed to scale down the data into a finite range. The data was then divided into training and test sets (80:20) for the training (1088 HEA samples) and testing (272 HEA samples) purpose of the model. Random forest classifier (RFC) was employed using the scikit-learn library in Python, and further training and testing was performed to evaluate the performance of the RFC model.

ML modelling framework for phase classification of high-entropy alloys (HEAs)
1.4 RFC Model Performance
RF is an ensemble of various decision trees (tree-like structures) based on various subsets of the given dataset. For a classification task, it takes votes from various decision trees and makes a final prediction on the basis of majority votes. It is more accurate compared to a single decision tree algorithm, as a large number of trees improve its performance and makes the prediction more stable. The performance of RFC model has been evaluated using a confusion matrix and classification report. Confusion matrix provides the number of correctly predicted and incorrectly predicted classes for each phase [35]. Classification report on the other hand provides precision, recall, f1-score, average classification accuracy, and weighted average accuracy. Out of 272 HEA samples from the test data, 93 samples belong to class 0, i.e. IM phase, 88 samples belong to class 1, i.e. BCC phase, 71 samples belong to class 2, i.e. FCC phase, 20 samples belong to class 3, i.e. FCC + BCC mixed phase, as shown in classification report in Fig. 3a. The confusion matrix in Fig. 3b demonstrates the correctly and incorrectly classified phases, for example out of a total of 93 samples of IM phase, only 72 samples were correctly classified as IM phase, remaining 13 samples were misclassified as BCC phase, 5 samples were misclassified as FCC phase and 2 samples were misclassified as FCC + BCC phase. Similarly, the classification of each phase can be observed. Apart from an average classification accuracy of 86%, the precision, recall, and f1-score for all four phases were investigated in the classification report.

a Confusion matrix, b classification report for RFC model in classification of IM, BCC, FCC, and FCC + BCC phase
Training accuracy, test accuracy, ROC_AUC_Score, and tenfold cross-validation ROC_AUC_Score were evaluated and shown in Table 3. The Receiver Operating Characteristic_Area under Curve (ROC_AUC) score ensures better performance of model in predicting different classes of HEAs. tenfold cross-validation was performed to avoid overfitting, where the complete dataset is divided into ten equal folds. Each time, the model was trained with 9 of those folds and the remaining onefold was used for the testing purpose, and the procedure was repeated ten times, by reserving a different tenth fold each time for testing the model. This measure ensured the effectiveness of the model and that the RFC model was not overfitting. The reported training accuracy of 90.9% and testing accuracy of 85.23%, suggested that the model was successfully classifying different phases of HEAs. The difference in the training and test accuracy indicated that the data used to train and test the RFC model was slightly different, which means that the RFC model is capable of predicting phases successfully, even for the unseen data points that have not been used in the present study.
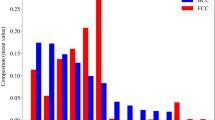
Furthermore, the interpretation of RFC model was performed using SHAP technique, to understand which physical features were influential in governing phases of HEAs. SHapely Additive exPlanation (SHAP) technique has emerged as breakthrough in the field of ML for easy interpretation and explanation of a complex model’s prediction; published by Lundberg and Lee in 2017 [36]. SHAP value aims to explain the prediction of an instance by considering the contribution of each feature in making a certain prediction at global as well as local levels. From this analysis, VEC was found to play most crucial role in determining FCC, BCC, and mixed FCC + BCC solid-solution phases whilst mixing enthalpy (dHmix) was found important in determining the formation of solid-solution or an intermetallic phase, as shown in Fig. 4. Tables 4 and 5 show the RFC model performance and cross-validation score in each fold of tenfold cross-validation respectively.

Feature importance plot for RFC model using SHAP
2 Conclusions
The RFC model developed in this study had successfully and reliably predicted BCC, FCC, intermetallic, and FCC + BCC phases in high-entropy alloys. RFC model performance was evaluated using various evaluation metrics such as average classification accuracy, precision, recall, f1-score, ROC_AUC score, and tenfold cross validation ROC_AUC score.
The RFC model showed that the two input parameters, namely valence electron concentration (VEC) and mixing enthalpies were most influential in determining the resulting phase of a given HEA composition. VEC contributed the most in predicting the crystal structure of solid solution phases (BCC, FCC, and FCC + BCC) whilst mixing enthalpy (ΔHmix) played important role in determining formation of solid-solution or intermetallic. Thus, this present study leveraged the reliability of applying ML techniques in material science without any requirement of performing expensive experiments.
References
Katiyar N, Goel G, Goel S (2021) Emergence of machine learning in the development of high entropy alloy and their prospects in advanced engineering applications. Emergent Mater 4(6):1635–1648. https://doi.org/10.1007/s42247-021-00249-8
Senkova ON, Senkova SV, Woodward C, Miracle DB (2013) Low-density, refractory multi-principal element alloys of the Cr–Nb–Ti–V–Zr system: Microstructure and phase analysis. Acta Mater 61(5):1545–1557. https://doi.org/10.1016/j.actamat.2012.11.032
Stepanov N, Shaysultanov D, Salishchev G, Tikhonovsky M (2015) Structure and mechanical properties of a light-weight AlNbTiV high entropy alloy. Mater Lett 142:153–155. https://doi.org/10.1016/j.matlet.2014.11.162
Deng Y, Tasan C, Pradeep K, Springer H, Kostka A, Raabe D (2015) Design of a twinning-induced plasticity high entropy alloy. Acta Mater 94:124–133. https://doi.org/10.1016/j.actamat.2015.04.014
Zhang Y, Li R (2020) New advances in high-entropy alloys. Entropy 22(10):1158. https://doi.org/10.3390/e22101158
Tsai M, Yeh J (2014) High-entropy alloys: a critical review. Mater Res Lett 2(3):107–123. https://doi.org/10.1080/21663831.2014.912690
Youssef K, Zaddach A, Niu C, Irving D, Koch C (2014) A novel low-density, high-hardness, high-entropy alloy with close-packed single-phase nanocrystalline structures. Mater Res Lett 3(2):95–99. https://doi.org/10.1080/21663831.2014.985855
Cantor B (2021) Multicomponent high-entropy Cantor alloys. Prog Mater Sci 120:100754. https://doi.org/10.1016/j.pmatsci.2020.100754
Yeh J (2006) Recent progress in high-entropy alloys. Annales De Chimie Science Des Matériaux 31(6):633–648. https://doi.org/10.3166/acsm.31.633-648
Kremer K, Grest G (1990) Molecular dynamics (MD) simulations for polymers. J Phys Condens Matter 2(S):SA295-SA298. https://doi.org/10.1088/0953-8984/2/s/045
Neugebauer J, Hickel T (2013) Density functional theory in materials science. Wiley Interdiscip Rev: Comput Mol Sci 3(5):438–448. https://doi.org/10.1002/wcms.1125
Goel S, Knaggs M, Goel G, Zhou X, Upadhyaya H, Thakur V et al (2020) Horizons of modern molecular dynamics simulation in digitalized solid freeform fabrication with advanced materials. Mater Today Chem 18:100356. https://doi.org/10.1016/j.mtchem.2020.100356
Osisanwo FY, Akinsola JE, Awodele O, Hinmikaiye JO, Olakanmi O, Akinjobi J (2017) Supervised machine learning algorithms: classification and comparison. Int J Comput Trends Technol 48(3):128–138. https://doi.org/10.14445/22312803/ijctt-v48p126
Nasteski V (2017) An overview of the supervised machine learning methods. HORIZONS B 4:51–62. https://doi.org/10.20544/horizons.b.04.1.17.p05
Islam N, Huang W, Zhuang H (2018) Machine learning for phase selection in multi-principal element alloys. Comput Mater Sci 150:230–235. https://doi.org/10.1016/j.commatsci.2018.04.003
Huang W, Martin P, Zhuang H (2019) Machine-learning phase prediction of high-entropy alloys. Acta Mater 169:225–236. https://doi.org/10.1016/j.actamat.2019.03.012
Nassar A, Mullis A (2021) Rapid screening of high-entropy alloys using neural networks and constituent elements. Comput Mater Sci 199:110755. https://doi.org/10.1016/j.commatsci.2021.110755
Choudhury A, Konnur T, Chattopadhyay P, Pal S (2019) Structure prediction of multi-principal element alloys using ensemble learning. Eng Comput 37(3):1003–1022. https://doi.org/10.1108/ec-04-2019-0151
Risal S, Zhu W, Guillen P, Sun L (2021) Improving phase prediction accuracy for high entropy alloys with machine learning. Comput Mater Sci 192:110389. https://doi.org/10.1016/j.commatsci.2021.110389
Tancret F, Toda-Caraballo I, Menou E, Rivera Díaz-Del-Castillo P (2017) Designing high entropy alloys employing thermodynamics and Gaussian process statistical analysis. Mater Des 115:486–497. https://doi.org/10.1016/j.matdes.2016.11.049
Li Y, Guo W (2019) Machine-learning model for predicting phase formations of high-entropy alloys. Phys Rev Mater 3(9). https://doi.org/10.1103/physrevmaterials.3.095005
Qi J, Cheung A, Poon S (2019) High entropy alloys mined from binary phase diagrams. Sci Rep 9(1). https://doi.org/10.1038/s41598-019-50015-4
Zhou X, Zhu J, Wu Y, Yang X, Lookman T, Wu H (2022) Machine learning assisted design of FeCoNiCrMn high-entropy alloys with ultra-low hydrogen diffusion coefficients. Acta Mater 224:117535. https://doi.org/10.1016/j.actamat.2021.117535
Agrawal A, Choudhary A (2016) Perspective: materials informatics and big data: realization of the “fourth paradigm” of science in materials science. APL Mater 4(5):053208. https://doi.org/10.1063/1.4946894
Abdoon Al-Shibaany Z, Alkhafaji N, Al-Obaidi Y, Atiyah A (2020) Deep learning-based phase prediction of high-entropy alloys. IOP Conf Ser: Mater Sci Eng 987(1):012025. https://doi.org/10.1088/1757-899x/987/1/012025
Dai D, Xu T, Wei X, Ding G, Xu Y, Zhang J, Zhang H (2020) Using machine learning and feature engineering to characterize limited material datasets of high-entropy alloys. Comput Mater Sci 175:109618. https://doi.org/10.1016/j.commatsci.2020.109618
Kaufmann K, Vecchio K (2020) Searching for high entropy alloys: a machine learning approach. Acta Mater 198:178–222. https://doi.org/10.1016/j.actamat.2020.07.065
Zhang L, Chen H, Tao X, Cai H, Liu J, Ouyang Y et al (2020) Machine learning reveals the importance of the formation enthalpy and atom-size difference in forming phases of high entropy alloys. Mater Des 193:108835. https://doi.org/10.1016/j.matdes.2020.108835
Buranich V, Rogoz V, Postolnyi B, Pogrebnjak A (2020) Predicting the properties of the refractory high-entropy alloys for additive manufacturing based fabrication and mechatronic applications. In: IEEE international conference on “nanomaterials: applications & properties” (NAP-2020) symposium on additive manufacturing and applications (SAMA-2020) Sumy, Ukraine, 9–13 Nov 2020
Machaka R (2021) Machine learning-based prediction of phases in high-entropy alloys. Comput Mater Sci 188:110244. https://doi.org/10.1016/j.commatsci.2020.110244
Bhandari U, Rafi M, Zhang C, Yang S (2021) Yield strength prediction of high-entropy alloys using machine learning. Mater Today Commun 26:101871. https://doi.org/10.1016/j.mtcomm.2020.101871
Lee S, Byeon S, Kim H, Jin H, Lee S (2021) Deep learning-based phase prediction of high-entropy alloys: optimization, generation, and explanation. Mater Des 197, 109260. https://doi.org/10.1016/j.matdes.2020.109260
Zeng Y, Man M, Bai K, Zhang Y (2021) Revealing high-fidelity phase selection rules for high entropy alloys: a combined CALPHAD and machine learning study. Mater Des 202, 109532. https://doi.org/10.1016/j.matdes.2021.109532
Krishna Y, Jaiswal U, Rahul R (2021) Machine learning approach to predict new multiphase high entropy alloys. Scripta Mater 197:113804. https://doi.org/10.1016/j.scriptamat.2021.113804
Markoulidakis I, Rallis I, Georgoulas I, Kopsiaftis G, Doulamis A, Doulamis N (2021) Multiclass confusion matrix reduction method and its application on net promoter score classification problem. Technologies 9(4):81. https://doi.org/10.3390/technologies9040081
Lewis F, Butler A, Gilbert L (2010) A unified approach to model selection using the likelihood ratio test. Methods Ecol Evol 2(2):155–162. https://doi.org/10.1111/j.2041-210x.2010.00063
Acknowledgements
Swati Singh greatly acknowledge the scholarship provided by the Ministry of Education, Government of India. Saurav Goel greatly acknowledge the support provided by the Royal Academy of Engineering via Grants No. IAPP18-19\295 and TSP1332.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Singh, S., Joshi, S.N., Goel, S. (2023). Summary of Efforts in Phase Prediction of High Entropy Alloys Using Machine Learning. In: Joshi, S.N., Dixit, U.S., Mittal, R.K., Bag, S. (eds) Low Cost Manufacturing Technologies. NERC 2022. Springer, Singapore. https://doi.org/10.1007/978-981-19-8452-5_4
Download citation
DOI: https://doi.org/10.1007/978-981-19-8452-5_4
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-8451-8
Online ISBN: 978-981-19-8452-5
eBook Packages: EngineeringEngineering (R0)