
Abstract
Biometrics are vital in security. Facial recognition, fingerprints, and iris recognition are all examples of computer vision biometrics. Unique authentication based on iris structure is one of the finest approaches for iris identification. This research provides an iris-based biometric identification system combining CNN and Softmax classifier. The system consists of picture augmentation by histogram equalization, image reduction by discrete wavelet transformation (DWT), segmentation by circular Hough transform and canny edge detector, and normalizing by Daugman's rubber-sheet model. Each picture is adjusted before being fed into the DenseNet201 model. The Softmax classifier then sorts the 224 IITD iris classes into 249 CASIA-Iris-Interval classes, 241 UBIRIS.v1 iris classes, and 898 CASIA-Iris-Thousand classes. The performance of our suggested system is determined by the setting of its deep networks and optimizers. In terms of accuracy, it exceeds existing approaches by 99%.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Deep learning
- DenseNet201
- Convolutional neural network (CNN)
- Softmax classifiers
- Discrete wavelet transformation (DWT)
1 Introduction
For example, biometrics includes fingerprints and retina scans. Biometric systems have the best track record for person authentication. Because biometrics is difficult to steal, it may be used instead of passwords and smart cards. Behavioral traits are often paired with physical traits to create biometric IDs. Physiological qualities of the body include fingerprints, palm veins, DNA, face recognition, iris, and so on [1].
Other categories included speaking voice, walking motion, etc. Biometrics helps safeguard people's health in two ways: physically and behaviorally. Biometrics has entered our everyday lives. Although iris is certified for precise biometric systems. Many people believe that biometrics is the proper technique to identify someone. The iris is the annular eye area between the white sclera and the black pupil [2].
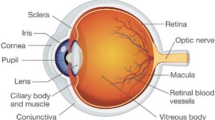
Iris texture is very random and distinct, making it unlikely to be unique across two iris patterns or two eyes. Circular, ridged, crypts, freckles, furrows, and zigzag patterns are among the most common iris texture traits. Its reputation for dependability helps in distinguishing individuals. Until his death, the iris pattern remained unchanged. Because recognition techniques are not susceptible to spoofing assaults, they are regarded safer. Again, altering its patterns requires more risk than altering fingerprints, which are simpler to manipulate. Eyelashes, reflections, and eyelids may all interfere with iris-based identification systems. For example, Aadhar card access, banks, and current apps employ iris-based identification [3] (Fig. 1).

The outer structure of human iris
This study encompasses the following: Sect. 2, the study of related Studies. In Sect. 3, there is the proposed iris recognition system, and in Sect. 4, there are the experimental results and analysis. Finally, the study's future evolution is summarized in the last section.
2 Review of Related Studies
S. Arora and M. S. Bhatia an iris scan may be used to verify a person's identification using deep learning. The circular Hough transform and CNN is used to locate an iris. Then, using a Softmax classifier, the dataset is classified into one of 224 classifications. The accuracy of their proposed system relies on the choice of hyper-parameters and optimization methods.
To discover the iris border in the eye picture, Reddy [4] used Daugman’s rubber-sheet model, followed by a circular Hough transform and edge detection. The recommended system is then trained using a CNN to identify iris characteristics. This classifier uses Softmax to classify 224 iris datasets and 108 CASIA V1 Iris datasets. Thus, the system's overall performance and deep-learning training and optimizations. We met our targets with 98% success and 95.4% accuracy.
Alaslni and Elrefaei [5] suggested CNNs (VGG-16s) for iris recognition model training. They used a pre-trained VGG-16 to successfully train on the IITD and CASIA Iris datasets. However, the suggested solution does not work with other publicly available datasets or solve other biometric issues.
CNN's iris recognition system was developed by Kien Nguyen et al. They tested DenseNet on two datasets, LG2200 and CASIA-Iris-Thousand, and found that it outperformed AlexNet, VGG, Google Inception, and ResNet. The authors did not explain why the AlexNet model was less accurate.
Shervin Minaee et Deep CNN features for iris recognition: a conceptual study They developed a system using VGG Net characteristics and got decent results. They studied data from CASIA-Iris-1000 and IIT Delhi using two well-known databases. This study uses a modified object recognition framework. Their findings would have been more accurate if they had used an architecture optimized for iris detection.
Aziz Nazri Ali and Sue Chin Yow His idea was to use deep learning to develop an iris scanner. In addition to SVM, Bayesian optimization, and data augmentation, this study uses CNN and data augmentation. The study's dataset is CASIA V1. The results are noteworthy; however, the approaches are not suited for other publicly accessible datasets.
3 The Proposed Iris Recognition System
In Fig. 2, the proposed iris recognition system uses a denseness for feature extraction and classification. The iris recognition technology will be developed in three areas: It includes both picture capture and preprocessing.

Flow diagram of the system employed in this study
3.1 Image Acquisition
After capturing a picture of the iris, it may be preprocessed to improve clarity. CASIA-Iris-1000 [6], interval 12 [7], Delhi 10 [8], and the UBIRIS Database [9] were used in this investigation. The table has not been preprocessed Table 1.
3.2 Preprocessing
The four methods depicted in Fig. 3 are used before processing iris images. Because collected pictures are packed with noise, they must be processed before being fed to segmentation. Because brightness is not uniform and noise must be reduced, a histogram equalization is used to enhance the picture. Use unsharp mask to sharpen your picture to bring out textures and characteristics.

The process involved in iris systems
3.2.1 Histogram Equalization
Equalization of histograms: A histogram equation is applied to increase the contrast and brightness of images. A linear and equal distribution of colors is obtained by examining the color distribution in the image and choosing a conversion function to modify the light values. The number of repetitions for each color is calculated, and then, the number of repetitions for each color is calculated and done. According to Fig. 4, the values are divided by the sum of the colors in the image to yield new color values.

The histogram equation color distribution
3.2.2 Unsharp Mask Filter
To highlight the image's texture and detail, the unsharp mask is applied. By improving the resolution of the image at a tiny scale, it can substantially increase the look of detail. It removes an image that has been smoothed out of the original image. You first generate a copy of the original image that is very fuzzy and then you remove the blurry copy from the original image, leaving only the clearer image behind. The remaining difference is known as a mask. Next, you apply the mask to the original image. Completing the original image with the mask, rather than masking the original, leaves behind a clearer end result.
3.2.3 Reducing Image Dimensions and Preserving Important Features
We can help with preprocessing, a method for reducing picture size and speeding up the matching process. Our first DWT was run on the normalized iris picture. The DWT transformation, shown in Fig. 5, adds four sub-band frequencies to the iris image: LL, LH, HL, and HH. The iris low-frequency coefficients are encoded in the LL sub-band [10], which is used for iris segmentation.

Iris template using one-level DWT
Wavelet discretization: A wavelet transformation reduces noise by decomposing data or images into wavelet coefficients [11]. The inverse discrete wavelet transformations are utilized to reconstruct the picture [12]. Figure 5 shows the resultant frequency sub-bands (LL, LH, HL, and HH). Iris features may be characterized using low-frequency coefficients, LL sub-band, allowing us to employ LL frequency sub-band for feature reduction [10].
3.2.4 Iris Segmentation
The next step in iris identification is iris segmentation, which involves processing a digital eye picture to determine the iris area. Figure 1 illustrates two concentric circles as an iris area approximation. The inner-circle depicts iris/sclera; the outer circle represents iris/pupil. The Hough transformation circular iris area.
The Hough transformation computes geometric parameters (lines and circles) in an image. The Hough transform may be used to identify the iris and pupil center coordinates and radius. Commonly used to identify object shapes based on class names. An edge map is created by calculating the gradients (first derivatives of intensity values) in an eye picture. To obtain the greatest values for circle parameters, neighboring areas on the circle at various radii are evaluated, and votes are cast [13]. This equation computes the center’s coordinates and radius:
The circle’s radius (r) is the biggest number, and the circle's center coordinates (XC, YC) are determined using Hough space edge points. Vertical derivatives (gradients) are used to identify the iris-sclera border. To remove the eyelids' effect from the Hough transform, only vertical gradients may be employed. Some of the circle's boundary pixels are unnecessary. Less edge points to vote on improve accuracy and efficiency [13] (Fig. 6).

Segmentation using Hough transformation
3.2.5 Normalization
After successfully segmenting the iris area from an eye picture, the following step is to transform it into a fixed-size rectangular block. Normalization creates an iris with regular proportions. These measures are consistent; therefore, photographs of the same iris will have comparable properties [14]. This work uses Daugman's rubber-sheet model to normalize the iris image.
Rubber-sheet model: As the name implies, the rubber-sheet model transforms the iris into a rectangular block in non-concentric polar coordinates, which is the most prevalent kind [15]. To calculate the comparable location on the polar axis (r), Daugman created a rubber-sheet model. The angular resolution is calculated by dividing the number of radial lines by the number of data points. The radial resolution is the number of data points. Using Eq. 2,
(x, y) is the iris position, and (r) is the Cartesian and normalized polar coordinates. rranges from Rp to Rl, while varies from 0 to 2. The boundary points are utilized to calculate x(r) and y(r).
The array’s horizontal and vertical dimensions correspond to angular and radial resolution, respectively (Fig. 7).

Rubber-sheet model of Daugman
3.2.6 Deep Learning for Iris Recognition
After preprocessing, we use a Softmax classifier to extract and classify CNN features. The DenseNet201 model is used in this work to simulate the CNN architecture. This is the top categorization layer; it is linked. The Softmax classifier then gets the fully connected layer's output and computes the probability distribution across N classes. This section also discusses the efficient recognition of the training process, network architecture, and input picture size. Keeping over fitness at bay throughout training is vital.
3.2.6.1 Training Methodology
The database is used to build the training, validation, and testing sets. 80% of the database is for training, and 20% is for testing. The validation set also contains parameters with a low validation error. The Softmax classifier divides the training set into mini-batches and calculates the training errors for each. The validation set is used after each epoch to test the present architecture's validity. The present architecture's cost value and validation error are then determined. This study's beginning learning rate is 0.001. The dropout approach [16] avoids overfitting. Each node and its connection are ignored in each training iteration by 0.2. After the training phase, the best model is chosen based on performance recognition.
3.2.6.2 Network Architecture
DenseNet is a CNN model created by Huang et al. and won the ILSVRC-2016 competition in 2017. An already trained and configured convolutional neural network model called DenseNet201 is utilized for the iris recognition [17] in this method. Each of the four dense blocks and three transition layers in DenseNet201 is shown in Fig. 8. To enhance the capabilities of the DenseNet201 bottleneck output features, a flattening layer and a dense layer are applied, and then, a Softmax layer is applied on top.

Shows DenseNet architecture
3.2.6.3 Input Image Size
The size of the input image influences the speed and accuracy of the network. To test the system's performance, three input image sizes (128 × 128 pixels, 64 × 64 pixels, and 32 × 32 pixels) are employed. Normalization and histogram equalization followed by three layers of DWT are used to create these photos. As the iris size is lowered, the iris patterns will become completely undetectable; nevertheless, for the larger size, larger memory requirements and the higher level of complexity computations could pose a challenge.
4 Experimental Results and Analysis
It is tested with four iris datasets: IITD Iris Databases [8], UBIRIS.v1 [9], CASIA-Iris-Thousand [6], and CASIA-Iris-Interval [7]. This set of iris photographs uses pupil dilation, eyelid/lash occlusion, a tiny eyelid shadow, and specular reflection. Table 2 lists the dataset's specifications.
A laptop with a Core i7 CPU operating at 2.8 GHz runs the system and its stages, which are implemented using Python 3.8.
Initially, the investigations used the iris image before preprocessing. In this case, we use DenseNet to simulate the eye's iris in its normal size.
In the second case, the iris image is normalized. The normalizing step sets the radial and angular resolutions to 224. The normalized picture is 224 pixels wide and 224 pixels height, perfect for dense network input.
Case 3: Use the iris picture after DWT and normalization. The picture size changes from DWT 128-by-128 to 64-by-64 to 32-by-32.
There will be a random split of each picture set into training and test data. Images make roughly 80% of training data and 20% of testing data.
This is followed by feature extraction and classification using a pre-trained CNN model. DenseNet was pre-trained to identify 1000 classes [17]. We used the following database types to test the system on all participants in the dataset:
With the same dataset as the class dataset, we pre-trained a DenseNet, using a tuning approach that modifies outputs in the final fully connected layer (FC) based on the class count.
Our study used DenseNet2016 pre-trained with varied epoch counts. The complete training set traversed by the training process is one epoch [18]. The initial learning cycle's learning rate is 0.001. The mini-batch option has a batch size of 32. In computing the gradient of the loss function and adjusting weights, the words mini-batch and subset are interchangeable. Gradient descent iteratively modifies network parameters (weights and biases) [19, 20] (Table 3).
These are the database accuracy and training time before and after segmentation of the ocular image, as well as after utilizing the first level of DWT. Because DWT reduces the picture size while maintaining important features, it reduces training time and increases accuracy. So our method improves accuracy without adding training time.
5 Conclusions
A pre-trained CNN was utilized to build an effective iris recognition system (DenseNet201). Then, an iris image is segmented using a circular Hough transform and normalized using Daugman's rubber-sheet model. The normalized picture is loaded into the pre-trained CNN (DenseNet201). The approach works well on public datasets. We will evaluate the suggested system's performance on other iris datasets and other biometric recognition tasks in the future.
References
Thomas T, George A, Devi KI (2016) Effective iris recognition system. Proc Technol 25:464–472
Al-Waisy AS, Qahwaji R, Ipson S, Al-Fahdawi S, Nagem TA (2018) A multi-biometric iris recognition system based on a deep learning approach. Pattern Anal Appl 21(3):783–802
Liu M, Zhou Z, Shang P, Xu D (2019) Fuzzified image enhancement for deep learning in iris recognition. IEEE Trans Fuzzy Syst 28(1):92–99
Sujana S, Reddy VSK (2021) An effective CNN based feature extraction approach for iris recognition system. Turkish J Comput Math Educ (TURCOMAT) 12(6):4595–4604
Alaslani MG, Elrefaei LA (2019) Transfer lerning with convolutional neural networks for iris recognition. Int J Artif Intell Appl 10(5):47–64
CASIA Iris Image Database Version 4.0 (CASIA-Iris-Thousand). Available from: http://biometrics.idealtest.org/dbDetailForUser.do?id=4
CASIA Iris Image Database Version 4.0 (CASIA-Iris-Interval). Available from: http://biometrics.idealtest.org/dbDetailForUser.do?id=4
IIT Delhi Database. Available from: http://www4.comp.polyu.edu.hk/~csajaykr/IITD/Database_Iris.htm
UBIRIS Image Database Version 1.0. Available from: http://iris.di.ubi.pt/ubiris1.html
Sharma VP, Mishra SK, Dubey D (2013) Improved iris recognition system using wavelet transforma and ant colony optimization. In: 5th International conference on computational intelligence and communication networks (CICN). IEEE, New York, pp 243–246
Jyoti P, Parvati B, Sandeep KG, Shubh Lakshmi A (2016) New improved feature extraction approach of iris recognition. Int J Comput Syst 3:1–3
Ma L, Tan T, Wang Y, Zhang D (2004) Efficient iris recognition by characterizing key local variation. IEEE Trans Image Process 13:739–750
Verma P, Dubey M, Basu S, Verma P (2012) Hough transform method for iris recognition-a biometric approach. Int J Eng Innov Technol (IJEIT) p 1
Verma P, Dubey M, Verma P, Basu S (2012) “daughman”s algorithm method for iris Recognition-a biometric approach. Int J Emerg Technol Adv Eng p 2
Daugman JG (1993) High condence visual recognition of persons by a test of statistical independence. IEEE Trans Pattern Anal Mach Intell 15:1148–1161
Srivastava N, Hinton GE, Krizhevsky A, Sutskever I, Salakhutdinov R (2014) Dropout: a simple way to prevent neural networks from overftting. J Mach Learn Res 15:1929–1958. ISSN: 1532-4435
Huang G, Liu Z, van der Maaten L, Weinberger KQ (2017) Densely connected convolutional networks. In: IEEE Conference on computer vision and pattern recognition (CVPR). Honolulu, pp 2261–2269
Al-Waisy AS et al (2017) A multi-biometric iris recognition system based on a deep learning approach. Pattern Anal Appl pp 1–20
Syafeeza A et al (2015) Convolutional neural networks with fused layers applied to face recognition. Int J Comput Intell Appl 14(03):1550014
Abdulreda A, Obaid A (2022) A landscape view of deepfake techniques and detection methods. Int J Nonlinear Anal Appl 13(1):745–755. https://doi.org/10.22075/ijnaa.2022.5580
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Arnoos, S.M., Sahan, A.M., Ansaf, A.H.O., Al-Itbi, A.S. (2023). An Intelligent Iris Recognition Technique. In: Kumar, R., Pattnaik, P.K., R. S. Tavares, J.M. (eds) Next Generation of Internet of Things. Lecture Notes in Networks and Systems, vol 445. Springer, Singapore. https://doi.org/10.1007/978-981-19-1412-6_17
Download citation
DOI: https://doi.org/10.1007/978-981-19-1412-6_17
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-1411-9
Online ISBN: 978-981-19-1412-6
eBook Packages: EngineeringEngineering (R0)