
Abstract
Internet of Things (IoT) has practically facilitated the option of connecting devices that necessitates cooperation through the Internet. The IoT environment comprises of self-configuring and smart objects that have the possibility of interacting with one another using the infrastructure of a global network. Clustering is the predominant approach that potentially works on the improvement of network lifetime. In this paper, a new clustering scheme using Differential Evolution-Improved Dragonfly Algorithm-based Optimal Radius Determination Strategy (DE-IDAORDS) is proposed for achieving prolonged lifetime in IoT. DE-IDAORDS facilitates the selection of Cluster Head (CH) based on the hybridized merits of DE and IDA for balancing the trade-off between exploration and exploitation to achieve effective clustering that attributes toward excellent energy stability and network lifetime. It adopts fitness function evaluation using parameters like cluster radius, distance and energy during CH selection. The results of the proposed DE-IDAORDS confirm better results in terms of energy, cost function, and number of alive nodes in contrast to the benchmarked schemes taken for investigation. The results also demonstrate that the proposed DE-IDAORDS scheme is capable of adequately enhancing the convergence rate and energy conservation in a minuscule period.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Internet of Things (IoT)
- Differential Evolution (DE)
- Improved Dragonfly Algorithm (IDA)
- Cluster Head (CH) selection
- Optimal radius determination
1 Introduction
In the recent past, Internet of Things (IoT) has developed tremendously owing to its wide use across the world. It is a technological gift that is developed to overcome the challenges of non-ubiquitous sensing and non-pervasive computing enabled using Wireless Sensor Network (WSN) technologies [1,2,3]. It includes a collection of assorted devices that are openly connected to the Internet. IoT links the devices directly to the network through universal infrastructure, where the communication amid devices is through smart and self-configuring devices. The smart association of devices involving network resources plays a dominant role in IoT. The data accumulated from diverse devices are analyzed to disseminate the valuable data through applications built to deal with the demands [4]. The devices are capable of dealing with the breach amid physical and digital worlds, facilitating fresh kind of services. Though IoT is used in diverse applications, it involves many challenges which include incorporation of numerous technologies and standards that focus on sensing, computational competences, storage, and connectivity [5, 6]. The nodes are resource constrained with restricted energy, memory, computation, and communication abilities. The nodes may also act as gateways to distant users. Owing to insufficient supply of energy to nodes, energy preservation is predominant in attaining extended network lifetime. Clustering is effective as it improves scalability of network by dropping channel contention and packet collision, and enhancing throughput. Proficient Cluster Head (CH) selection increases the load efficiency on CHs as energy may be conserved and network lifetime may be improved [7].
In this paper, a new clustering scheme using Differential Evolution (DE)-Improved Dragonfly Algorithm-based Optimal Radius Determination Strategy (DE-IDAORDS) is proposed for achieving prolonged lifetime in IoT. It integrates the exploration capabilities of DE with the exploitation potentialities of improved DFA to establish balanced deviation between the local and global search process. It includes the parameters of cluster radius, distance and energy during CH selection to evaluate the fitness function under optimization. The simulation experiments of the proposed DE-IDAORDS are conducted using the evaluation metrics such as throughput, normalized energy, time incurred for CH selection, cost function and number of alive nodes for varying number of rounds and iterations in contrast to the benchmarked schemes taken for investigation.
2 Related Work
In this section, the work done by various authors related to CH selection are discussed. Feng et al. [8] have propounded an enhanced K-means algorithm to cluster nodes and perform weighted assessment to enhance cluster construction. The cluster is divided or broken based on the assessment outcomes to get non-uniform clustering. The authors have focused on increased transmission delay due to data fusion and have built a delay-enhanced fusion tree. Parent nodes are chosen based on distance and energy. Time slot distribution is enhanced by building a fusion tree, and the delay involved in transmission is reduced. Halder et al. [9] have dealt with improving the network lifespan by balancing energy depletion amid CHs. The radius at every level plays a dominant role in improving network lifetime. Lifetime Maximizing optimal Clustering Algorithm (LiMCA) is propounded for energy stringent IoT devices. Mainly, LiMCA involves a stochastic positioning mechanism for nodes in the network. A protocol is designed to train nodes about coarse-grain positions. Reddy and Babu [10] have adopted a hybrid model using Moth Flame Optimization (MFO) and Ant Lion Optimization (ALO) to increase the performance of CH selection amid devices. The distance and delay are maintained, and the temperature and load are balanced for achieving ideal CH selection. The mechanism focuses on convergence, maintaining alive nodes, controlling of energy, load and temperature. Reddy and Babu [11] have designed a Self-Adaptive Whale Optimization Algorithm (SAWOA) for ensuring energy-based selection of CH and clustering in Wireless Sensor Network (WSN)-based IoT. The propounded schemes offer better network lifetime. Dhumane and Prasad [12] have propounded Multi-Objective Fractional Gravitational Search Algorithm (MOFGSA) for finding optimal CHs that support energy effective routing in an IoT network. The CHs are assessed based on a fitness function in terms of distance, lifespan, delay, and energy.
Srinidhi et al. [13] have propounded Hybrid Energy Efficient and QoS Aware (HEEQA) scheme, an amalgam of Quantum Particle Swarm Optimization (QPSO), and enhanced Non-dominated Sorting Genetic Algorithm (NSGA) to attain energy balance amid devices. The parameters in MAC layer are altered to decrease energy consumption of devices. NSGA focuses on multi-objective optimization, while the QPSO algorithm supports in finding the optimum cooperative grouping. Govindaraj and Deepa [14] have dealt with the optimization of IoT in WSNs that focuses on handling energy and accuracy involved in complex clustering mechanisms. Capsule Neural Network (CNN)-based learning model that manages network energy at an optimal level is propounded. This architecture supports efficient routing and optimization, wherein activation is done during the forward pass. Sennan et al. [15] have propounded Type-2 Fuzzy Logic-based Particle Swarm Optimization (T2FL-PSO) algorithm to choose the optimum CH to prolong the lifespan of a network. This scheme is useful in offering precise solution in indeterminate network surroundings. Residual energy along with the distances amid the nodes and the Base Station (BS) are used to find the fitness. Virtual clusters are built depending on the distance amid nodes and the CH or the BS. Dev et al. [16] have propounded a scheme wherein the CH is chosen by the Over taker Assisted Wolf Update (OA-WU) that is a combination of the conceptions of Gray Wolf Optimization (GWO) algorithm and Rider Optimization Algorithm (ROA). This scheme is based on distance, radius and energy of the cluster. Energy is conserved, and convergence rate is improved in a short duration.
3 Proposed DE-IDAORDS Scheme
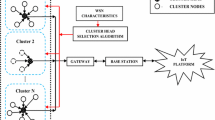
The network model considered during the implementation of the proposed DE-IDAORDS scheme consists of a single BS and finite number of static sensor nodes. The communication in the network always occurs within the range facilitated by the given radio. The network is assumed to face challenges related to energy consumption, data sensing, sensor allocation, radio communication and topology characteristics. The sensor nodes in the network are localized in the application areas either manually or randomly. However, extending network lifetime is a herculean task in WSNs enabled IoT. In this context, clustering is indispensable for partitioning the sensor nodes to construct clusters. Moreover, the transmission of data from one node to another is a challenging task in WSN-enabled IoT. This challenge of data transmission needs to be overcome based on the determination of optimal shortest paths. In this context, several works focusing on the establishment of different system models that aid in attaining the distribution of data packets among the cluster members and BS using the merits of routing protocols are contributed to the literature. However, energy and location of sensor nodes are identified as prime factors for performing CH selection in hierarchical routing. In this paper, the proposed DE-IDAORDS scheme is presented as a potential CH selection strategy using the optimizing factors of cluster radius, energy, and distance for achieving energy stability and prolonged network lifetime.
3.1 Cluster Radius Estimation
The factor of cluster radius needs to be estimated for enhancing the network lifespan in the clustering architecture. This cluster radius \(\left( {C_{{\text{R}}} } \right)\) is estimated by dividing the complete network area of radius \(\left( {R_{N} } \right)\) into ‘\(k\)’ ring sectors based on the angle of disk sector \(\left( \varphi \right)\). In the network model, the sensor nodes are independent of the size of the network and transmit data to the neighboring CHs within a fixed radius. In specific, each node possesses a particular sensing and communication radius to estimate its network coverage. But communication radius depending on the number of neighboring nodes needs to be essentially computed for reliable data transmission. To achieve the estimation, potential optimization strategy becomes essential, and thus, DE-IDA mechanism is employed for selecting the optimal cluster radius depending on the fitness function 1 as specified in Eq. (1).
where ‘\({\text{SN}}_{{R - {\text{UC}}\left( i \right)}}\)’ and ‘\({\text{SN}}_{{{\text{Total}}}}\)’ represent the number of sensor nodes that are not covered by the radius and the total number of nodes existing in the network.
3.2 Energy Consumption
Adequate amount of energy is essential for data transmission. This energy is essential for carrying out the functions of sensing, aggregation, transmission and reception. The cumulative energy \(\left( {E_{{{\text{SN}}}}^{{{\text{Initial}}}} } \right)\) necessary for communication is the aggregate sum of the energy spent for idle state \(\left( {E_{{{\text{SN}}}}^{{{\text{IS}}}} { }} \right)\), data reception \(\left( {E_{{{\text{SN}}}}^{{{\text{DR}}}} } \right)\), electronic energy \(\left( {E_{{{\text{SN}}}}^{{{\text{EE}}}} } \right)\), and data transmission \(\left( {E_{{{\text{SN}}}}^{{{\text{DT}}}} } \right)\) as specified in Eq. (2).
The above-mentioned energy consumption is the second factor (fitness function 2) to be optimized during the CH selection process.
3.3 Distance Estimation
In the process of clustering, CH is responsible for generating and forwarding an advertisement message to the complete set of nodes existing in the network to inform their role during the communication process. Whenever a sensor node receives an advertisement message from a CH, it commences to estimate the distance between itself and the CH. Moreover, the construction of clusters within the network is facilitated by the sensor nodes that possess the least distance with the CH. This distance measure is determined and represented as a matrix as shown in Eqs. (3) and (4).
The complete objective of the proposed DE-IDAORDS-based IoT clustering model is defined in Eq. (5).
where ‘\(F_{1}\)’, ‘\(F_{2}\)’, and ‘\(F_{3}\)’ represent the fitness function parameters considered for optimization with cluster radius set in the range from 0 to 50.
3.4 Dragonfly Algorithm (DFA)
Primitive DFA algorithm is proposed based on the inspiration derived from the dragonflies’ social behavior with respect to the hunting and migration for food [17]. In specific, the dragonflies’ hunting phenomenon mimics the random movement in the local search space as it corresponds to the exploitation potentialities of the algorithm. On the other hand, migration of dragonflies is like the exploration capability that investigates the solution in the entire problem domain. In this context, the feasible solution in the problem domain with respect to optimal radius-based CH selection (population matrix) is shown in Eq. (6).
where ‘\(S_{i}^{D}\)’ represents the position of the search agent (dragonfly) with ‘\(D\)’ and ‘\(\hat{N}\)’ as the dimensional search space and search agents’ count respectively. The searching process of the DFA algorithm comprises of the parameter of separation, cohesion and alignment determined for ‘\(\hat{N}\)’ individual neighbors. In specific, the parameter separation and cohesion with respect to DFA are computed based on Eqs. (7) and (8).
On the other hand, the factor of alignment is determined based on Eq. (9).
where ‘i’ and ‘j’ represent the current and neighboring individual solutions considered from the search space for exploration and exploitation. Moreover, ‘\(V_{j}\)’ highlights the velocity associated with the \(j{\text{th}}\) neighboring individual solution.
Further, the degree of attraction \(\left( {A_{R(i)} } \right)\) and distraction \(\left( {D_{R\left( i \right)} { }} \right)\) of the search agents toward the determination of optimal solution are computed as shown in Eqs. (10) and (11).
where ‘\(S\)’ represents the current position of search agent from which the required solution is closer \(\left( {S^{ + } } \right)\) and farther \(\left( {S^{ - } } \right)\) depending on the position toward solution determination.
At this juncture, the step vector ‘\(\Delta S_{{P\left( {t + 1} \right)}}\)’ is updated based on Eq. (12).
where ‘\(\alpha\)’, ‘\(\beta\)’, ‘\(\gamma\)’, ‘\(\delta\)’, and ‘\(\mu\)’ represent the factors of separation, cohesion, alignment, attraction and distraction for achieving better exploration and exploitation with ‘\(W_{{{\text{Inertial}}}}\)’ as the inertial weight. Moreover, the position of the search agent is revised based on Eq. (13).
In addition, the search agents’ position (dragonfly) using the merits of Levy fight function is updated using Eq. (14).
Finally, the fitness function presented in Eq. (5) is evaluated based on the determined position vector until the termination condition is satisfied.
3.5 Differential Evolution
Differential evolution is proposed as a potential optimization algorithm that facilitates significant results over different linear objective functions which are like objective functions formulated for CH selection [18]. It offers better convergence rate and aids in attaining better global optimal solution during searching. In this proposed DE-IDAORDS scheme, DE is specifically utilized for handling the computation intensive cost functions with minimized number of convergence properties and control variables. It also adopts random mutation that inherits the weighted difference estimated between two vectors. It inherits trial factor for employing mutation and crossover over the target vector using mutant vector specified in Eq. (15).
where ‘\(r_{1}\)’, ‘\(r_{2}\)’, and ‘\(r_{3}\)’ represent the randomly selected values that highlight the individuals in ‘N’ dimensions. Moreover, ‘\(M_{F}\)’ represents the component of crossover introduced for refining the algorithmic diversity.
Further, the vectors of ‘\(m_{v}^{i}\)’ and ‘\(S_{P}^{i}\)’ are built using crossover for constructing the trial vector based on Eq. (16).
where ‘\(C_{F}\)’ and ‘\(R_{{{\text{CF}}}}\)’ represent the crossover factor and dimension considered for searching in the range of 0 and 1. Moreover, \(R_{{{\text{CF}}}}^{{{\text{Rnd}}}} \in \left[ {1,D} \right]\) highlights the randomly selected individual index value. In addition, the fitness value of the objective function (specified in Eq. (5)) is utilized for selecting the optimal solution from the target and trial vector.
3.6 Hybridization of DE and DFA
The primitive aim of hybrid optimization is to establish superior balance between exploration and exploitation that attributes toward the mitigation of limitations possessed in the parent optimization method for attaining enhanced optimal solution. The traditional DFA algorithm possesses exploration potential based on the randomness of the initially generated population depending on the significance of Levy fight search to achieve solution diversity. However, DFA does not inherit any mechanism for storing the best solution. It also discards the local best values during implementation when it exceeds the global best solution. It is also considered to be slow and suffers from the problem of premature convergence. This limitation completely fails in tracking the comprehensive set of solutions that introduces the possibility of converging the solution to a global optimum. Thus, the hybridization of DE and DFA concentrates on the performance improvement by (i) including individual particle memory that stores the global best solution along with the local best solution for attaining the global optimal point, (ii) integrating iteratively with DE to execute the set of solutions determined by DFA in a predominant manner, and (iii) hybridizing improved learning-based mutation of DE into DFA for achieving population diversity. It also introduces the evaluation of convergence power using local and global best solutions that control the span of convergence. In addition, it utilizes the convergence power to generate a new set of population when it exceeds the specific threshold. In this process of hybridization, mutation inherent in DE is carried out using the local and global best solutions for identifying the predominant solutions in the search space. This mutation process adopts an enhanced learning strategy to include the local and best solutions that improve the population diversity. Then, the vector of target associated with DE is improved with the iterative best solution identified from DFA depending on Eq. (17).
where ‘\(S_{{{\text{Old}}}}^{{\left( {i, k} \right)}}\)’, ‘\(S_{{{\text{LBest}}}}^{{\left( {i, k} \right)}}\)’, and ‘\(s_{{{\text{Leader}}}}\)’ represent the positions of the individual solution and global worst particle in the preceding iteration. In this case, ‘\({\text{rnd}}_{i}\)’ represents the random number that lies between 0 and 1 which obeys the characteristics of normal distribution ‘\(N\left( {0,1} \right)\)’. Moreover, the values of ‘\(M_{F}^{1}\)’ and ‘\(M_{F}^{2}\)’ are determined based on Eqs. (18) and (19).
At this juncture, the value of ‘\(M_{F}\)’ representing the mutation factor is computed based on Eq. (20).
where ‘\({\text{Iter}}_{{{\text{Curr}}}}\)’ and ‘\({\text{Iter}}_{{{\text{Max}}}}\)’ represent the current iteration and maximum number of iterations considered during the implementation of DE-IDAORDS.
Finally, the proposed DE-IDAORDS-based IoT clustering optimization model is adopted for clustering to improve the network lifetime and energy stability.
4 Results and Discussion
The performance evaluation of the proposed DE-IDAORDS-based IoT clustering model and the benchmarked approaches is conducted using MATLAB R2018a. The data acquisition associated with the implemented IoT environment is considered from the data science community of Kaggle. This experimental investigation is carried out based on the time taken for CH selection, cost function, normalized energy, alive nodes and throughput.
The network area considered for implementation is 100 × 100 square meters in which 100 sensor nodes are deployed randomly throughout the entire region. The initial energy of sensor nodes is set to 0.5 J with simulation rounds of 2000 and packet size of 4500 bits. Initially, Figs. 1 and 2 demonstrate the throughput and normalized energy realized in the network during the implementation of the proposed DE-IDAORDS and the benchmarked T2FL-PSO, HEEQA, and SAWOA approaches for varying number of rounds. The results evidently prove that the proposed DE-IDAORDS scheme is potent in estimating the optimal cluster radius to a more accurate level and confirm better throughput by propagating the packets from the source to the destination nodes. On the other hand, the normalized energy sustained in the network is maximized by the proposed DE-IDAORDS by adopting the potentialities of trial and target vector during local and global searches. Hence, the normalized energy used by the proposed DE-IDAORDS for varying number of rounds is comparatively improved by 13.29%, 15.64% and 17.46% when compared to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches. Moreover, the proposed DE-IDAORDS for varying number of rounds reduces the normalized energy by 12.98%, 14.82% and 16.71% in contrast to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches.

Throughput for Varying Number of Rounds

Normalized Energy for Varying Number of Rounds
Further, Figs. 3 and 4 depict the cost function and the time incurred for CH selection by the proposed DE-IDAORDS and the benchmarked T2FL-PSO, HEEQA, and SAWOA approaches for varying number of iterations. The results confirm that the proposed DE-IDAORDS scheme is capable of minimizing the cost function as it integrates the merits of DE and DFA toward optimal CH selection process. The time incurred for CH selection as attained by the proposed DE-IDAORDS is comparatively minimized since it adopts the adjustment of migration factor of DFA into the mutation factor of DE toward better exploration and exploitation. Thus, the cost function attained by the proposed DE-IDAORDS for varying number of iterations is comparatively reduced by 17.21%, 19.86% and 21.94% when compared to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches.

Cost Function for Varying Number of Rounds

Time incurred for CH Selection for Varying Number of Rounds
Moreover, the proposed DE-IDAORDS for varying number of iterations minimizes the time incurred for CH selection by 14.29%, 16.84% and 19.23% when compared to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches. In addition, Fig. 5 depicts the number of alive nodes in the network as attained by the proposed DE-IDAORDS and the benchmarked T2FL-PSO, HEEQA and SAWOA approaches for varying number of rounds. The number of alive nodes sustained in the network is improved due to the inclusion of DE that adaptively helps the DFA in exploring the search space during the optimal CH selection process. The proposed DE-IDAORDS for varying number of rounds maximizes the number of alive nodes by 12.98%, 14.76% and 16.21% when compared to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches.

Number of Alive Nodes for varying Number of Rounds
5 Conclusion
In this paper, the proposed DE-IDAORDS scheme is a significant scheme for selecting optimal CHs through the exploration and exploitation benefits of DE and DFA algorithms. It chooses optimal CH using the optimization factors of cluster radius, energy model and distance measures. It facilitates optimal tuning of the process of determining the cluster radius. The simulation results confirm that the cost function attained by the proposed DE-IDAORDS for varying number of iterations is comparatively reduced by 17.21%, 19.86% and 21.94% when compared to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches. Further, the proposed DE-IDAORDS for varying number of iterations minimizes the time incurred for CH selection by 14.29%, 16.84% and 19.23% when compared to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches. In addition, the results evidently prove that the proposed DE-IDAORDS for varying number of rounds maximizes the number of alive nodes by 12.98%, 14.76% and 16.21% in contrast to the benchmarked T2FL-PSO, HEEQA and SAWOA approaches. As a part of the future plan, it is decided to formulate a Mayfly-based optimal CH selection to improve the network lifetime in IoT on par with the proposed DE-IDAORDS scheme.
References
Behera TM, Mohapatra SK, Samal UC, Khan MS, Daneshmand M, Gandomi AH (2019) Residual energy-based cluster-head selection in WSNs for IoT application. IEEE Internet Things J 6(3):5132–5139
Balamurugan A, Priya M, Janakiraman S, Malar A (2021) Hybrid stochastic ranking and opposite differential evolution-based enhanced firefly optimization algorithm for extending network lifetime through efficient clustering in WSNs. J Netw Sys Manag 29(3):1–31
Balamurugan A, Janakiraman S, Priya DM (2022) Modified African buffalo and group teaching optimization algorithm-based clustering scheme for sustaining energy stability and network lifetime in wireless sensor networks. Trans Emerg Telecommun Technol 33(1)
Alazab M, Lakshmanna K, Reddy T, Pham QV, Maddikunta PKR (2021) Multi-objective cluster head selection using fitness averaged rider optimization algorithm for IoT networks in smart cities. Sustain Energy Technol Assess 43:100973
Janakiraman S, Priya DM (2020) An energy-proficient clustering-inspired routing protocol using improved Bkd-tree for enhanced node stability and network lifetime in wireless sensor networks. Int J Commun Sys 33(16):e4575
Janakiraman S, Priya M, Devi SS, Sandhya G, Nivedhitha G, Padmavathi S (2021) A Markov process-based opportunistic trust factor estimation mechanism for efficient cluster head selection and extending the lifetime of wireless sensor networks. EAI Endorsed Trans Energy Web e9
Rajarajeswari PL, Karthikeyan NK, Priya MD (2015) EC-STCRA: Energy Conserved-Supervised Termite Colony based Role Assignment scheme for Wireless Sensor Networks. Procedia Comp Sci 57:830–841
Feng X, Zhang J, Ren C, Guan T (2018) An unequal clustering algorithm concerned with time-delay for internet of things. IEEE access 6:33895–33909
Halder S, Ghosal A, Conti M (2019) LiMCA: an optimal clustering algorithm for lifetime maximization of internet of things. Wireless Netw 25(8):4459–4477
Reddy MPK, Babu MR (2019) A hybrid cluster head selection model for internet of things. Clust Comput 22(6):13095–13107
Reddy MPK, Babu MR (2019) Implementing self-adaptiveness in whale optimization for cluster head section in internet of things. Clust Comput 22(1):1361–1372
Dhumane AV, Prasad RS (2019) Multi-objective fractional gravitational search algorithm for energy efficient routing in IoT. Wireless Netw 25(1):399–413
Srinidhi NN, Lakshmi J, Kumar SD (2019) Hybrid energy efficient and QoS aware algorithm to prolong IoT network lifetime. In: International conference on ubiquitous communications and network computing, pp 80–95. Springer, Cham
Govindaraj S, Deepa SN (2020) network energy optimization of IOTs in wireless sensor networks using capsule neural network learning model. Wireless Pers Commun 115(3):2415–2436
Sennan S, Ramasubbareddy S, Balasubramaniyam S, Nayyar A, Abouhawwash M, Hikal NA (2021) T2FL-PSO: type-2 fuzzy logic-based particle swarm optimization algorithm used to maximize the lifetime of internet of things. IEEE Access 9:63966–63979
Dev K, Poluru RK, Kumar RL, Maddikunta PKR, Khowaja SA (2021) Optimal radius for enhanced lifetime in IoT using hybridization of rider and grey wolf optimization. IEEE Trans Green Commun Netw 5(2):635–644
Mirjalili S (2016) Dragonfly algorithm: a new meta-heuristic optimization technique for solving single-objective, discrete, and multi-objective problems. Neural Comput Appl 27(4):1053–1073
Storn R, Price K (1997) Differential evolution–a simple and efficient heuristic for global optimization over continuous spaces. J Global Optim 11(4):341–359
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Sengathir, J., Deva Priya, M., Christy Jeba Malar, A., Sandhya, G. (2022). Differential Evolution-Improved Dragonfly Algorithm-Based Optimal Radius Determination Technique for Achieving Enhanced Lifetime in IoT. In: Udgata, S.K., Sethi, S., Gao, XZ. (eds) Intelligent Systems. Lecture Notes in Networks and Systems, vol 431. Springer, Singapore. https://doi.org/10.1007/978-981-19-0901-6_53
Download citation
DOI: https://doi.org/10.1007/978-981-19-0901-6_53
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-0900-9
Online ISBN: 978-981-19-0901-6
eBook Packages: EngineeringEngineering (R0)