
Abstract
The excess accumulation of visceral adipose tissue (VAT) and subcutaneous adipose tissue (SAT) in the abdomen that causes obesity needs to be measured precisely for clinical evaluation of obesity. The availability of accurate and reliable imaging tools is needed to segment and quantify adipose tissues that cause serious chronic conditions. Computed tomography (CT) and magnetic resonance imaging (MRI) are the most commonly used imaging modalities to distinguish and quantify VAT and SAT. However, CT is subjected to ionizing radiation, and so, MRI is highly preferred. In this work, a fully automated deep learning model has been developed to segmentation VAT and SAT from MRI images of the abdomen. First, a fully convolutional network (FCN)-based U-Net architecture was used to separate SAT. In the second step, the K-means clustering algorithm was used to separate the adipose and non-adipose tissues, thereby extracting the VAT content. The proposed FCN-based method produced a Pearson correlation coefficient of 0.99 and 0.99 for VAT and SAT content. The results show that the new FCN method is highly accurate and reliable.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
- Obesity
- Computed tomography
- Magnetic resonance imaging
- Segmentation
- Deep learning
- Fully convolutional network
1 Introduction
In humans, body fat is disseminated into two areas—visceral adipose tissue (VAT) and subcutaneous adipose tissue (SAT) [1]. Visceral adipose tissue borders the internal organs in the abdominal cavity, whereas subcutaneous tissue is seen under the skin. An excess distribution of VAT in the abdominal region is known as central obesity or abdominal obesity, closely related to many health risks like type 2 diabetes, cardiovascular diseases, cancer, musculoskeletal disorders, and high cholesterol [2, 3]. Many methods exist to determine the distribution of body fat. In the past years, anthropometric measurements like body mass index (BMI), umbilicus circumference, waist circumference (WC), and waist-to-hip ratio (WHR) were considered as easy techniques to estimate the distribution of body fat [4, 5]. But the results were inconsistent due to the change of body position during measurement. Also, these methods do not differentiate SAT and VAT [6]. Therefore, there is a necessity for the advancement of accurate, specific, and reliable tools for the measurement of SAT and VAT.
Many imaging techniques like bioelectrical impedance, dual-energy X-ray absorptiometry, ultrasound, CT, and MRI have been proposed to measure abdominal fat distribution [7]. Among these, various research attempts have shown that MRI is a valuable and reliable tool to investigate and evaluate abdominal fat distribution. Several approaches for the segmentation of VAT and SAT have been proposed in the literature that includes manual, semi-automated, and fully automated techniques. Manual segmentation is the best choice, but it requires trained medical experts and long time span which is subjected to human errors. As VAT is irregular in shape and extensively distributed in the abdominal cavity, it is very difficult to segment VAT manually. To solve this problem, some semi-automated approaches were developed which consumes less time, but the results are based on the operator. Recently, various researchers have proposed several fully automated methods to segregate VAT and SAT and produced good results. The automated segmentation methods includes explicit models [8], random forests [9], multi-atlas segmentation model [10], and deep learning [11]. There exists various studies that demonstrates the accuracy of automated segmentation and quantification of adipose tissues using deep learning. In this work, it is proposed to improve adipose tissue segmentation by using a fully automated method that combines FCN-based U-Net and clustering method. The core of this fully automated segmentation method is the clustering in the peritoneal cavity avoids the misinterpretation of adipose and non-adipose tissues. U-Net is designed in the form of layers that performs pixelwise predictions of the whole image in a short duration of time. This provides rapid segmentation of adipose tissues for medical applications. Experimental results show that this automated method produces high segmentation accuracy with a Pearson correlation coefficient of 0.99 for VAT and SAT which is greater than existing deep learning-based approaches. An illustration of the segmentation of adipose tissues is shown in Fig. 1.

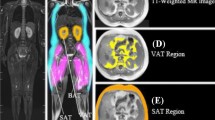
Illustration of delineation of adipose tissues. A and B Original T1-weighted MRI slices of the abdomen C and D Separation of adipose and non-adipose tissues—yellow-coloured area indicates VAT and orange-coloured area indicates SAT
The main objective of this work is the development of an automated adipose tissue segmentation system using U-Net and K-means clustering algorithm to predict chronic diseases earlier. The U-Net architecture separates SAT in the abdominal region from MRI images. The adipose tissues are separated from the background, and thereby, the VAT content is isolated using K-means clustering algorithm.
The state-of-the-art segmentation methods are reviewed in detail in Sect. 2. The proposed U-Net based segmentation methodology is presented in Sect. 3. Experimental results and discussion is described in Sect. 4. Finally, the work is concluded in Sect. 5.
2 Related Work
Deep learning with convolutional neural networks (CNNs) has become popular in recent years in areas such as image identification, classification, and segmentation. SAT and VAT regions were separated by Wang et al. [12] based on clustering method using water–fat separation MRI. First, adipose tissues were separated from the non-adipose tissues using K-means clustering algorithm. A deformable model initiated by a uniquely generated deformation field that points to the inner SAT boundary was used to differentiate SAT and VAT. The advantage of this method is the increased level of automation and objectivity, as well as less bias among different operators. However, testing was done only on a specific number of people with dyslipidaemia. Hui et al. [13] proposed a method using spoke template for separating SAT and VAT. Midpoint circle algorithm and Bresenham’s line algorithm were used to develop the spoke template which is round in shape. When the specified condition is met, VAT and SAT were isolated automatically. This method does not require any user intervention to produce the segmented output, but a portion of the VAT is left in the SAT results when the connecting area between SAT and VAT is thick. Langner et al. [14] introduced two fully convolutional network architectures U-Net and V-Net which were trained for the segmentation and quantification of SAT and VAT on MR images. The segmentation output produced by U-Net is highly reliable and accurate for the quantification of abdominal adipose tissues. The V-Net is less robust and results in oversegmentation of random patterns. Park et al. [15] performed abdominal muscle and fat segmentation using deep learning concept. A training dataset consisting of 467 subjects and 883 CT scans was used to develop a fully convolutional network (FCN) model. The network model resulted in high performance and accuracy, and external validation was carried out using data from a small number of subjects FCN generated accurate segmentation results, but in a few cases, the results were erroneous in the validated dataset related to SAT and muscle fat segmentation.
A graph theoretic segmentation algorithm was introduced by Sadananthan et al. [16] to segment VAT, deep (DSAT), and superficial (SSAT) from abdominal MRI images. The segmentation process is carried out in two steps. In the first step, graph cut method is used to separate SAT and VAT, and in the second step, a modified level set method is used to distinguish DSAT and SSAT. The segmentation algorithms produced the results rapidly, and precise segmentation was done. The major drawback is that accurate segmentation of VAT and SAT compartments is difficult in lean subjects. The data was obtained from 44 normal and 38 overweight population for the segmentation. For the quantification of SAT and VAT from MRI, Ning Shen et al. [17] proposed a machine learning technique using IDEAL-IQ sequences. A deep neural network was trained first to obtain the SAT patterns. Then, VAT clustering is done using the AFK-MC2 algorithm. Although this method is highly reliable, a considerable amount of training time is required for the successful completion of the segmentation process. Kim et al. [17] used a separation mask method to separate SAT and VAT from CT images. The unwanted space between a closed path and muscle area is reduced by the separation mask region. The shortest closed path was estimated by the Convex Hull algorithm. Although this method is accurate and reliable, there is a gap in SAT segmentation because the muscular fat near SAT is included as part of VAT. A 3D convolutional neural network (DCNet) was presented by Kustner et al. [18] for separating SAT and VAT on MRI images. Training and testing of DCNet on whole-body MRI data is done from the epidemiological patient databases of various multi-centres. It provides a robust architecture and can be generalized to different sequence of images. The network was not trained to differentiate bone marrow and other tissues, resulting in misclassifications. The accuracy produced is estimated as 98.4%. Estrada et al. [19] proposed a deep learning pipeline for the segmentation of VAT and SAT using DIXON MRI images. In this three step process, first, the localization of the abdominal area is done, next, the adipose tissue segmentation is done, and finally, aggregation of the previously generated label maps are done. In this method, the number of training parameters is less which is an added advantage. When the input images are of poor quality, segmentation reliability decreases. Samira Masoudi et al. [20] introduced a segmentation method for the separation of adipose tissues on MR images of the abdomen using cross modality adaptation and deep learning algorithms. In order to make the separation of adipose tissues easier, a cycle generative adversarial network (C-GAN) is used. C-GAN converts the MR images into CT format, and then, two U-Net models separate VAT and SAT. The basic limitation of this method is the loss of many features during the transformation of MR images to CT images.
Deep learning models require less pre-processing steps and depend on the availability of large-scale dataset. For the past few years CNNs have influenced the area of adipose tissue segmentation. In this work, a new method is proposed to identify and segment SAT and VAT. For the extraction of SAT pattern, a FCN-based U-Net architecture was used, followed by K-means clustering for classifying the abdominal region into adipose tissue and non-adipose tissue and then obtain the VAT pattern.
3 Proposed Methodology
This section covers in detail the structure and technique of the proposed U-Net-based VAT and SAT separation system and the benefits of using it. The suggested method consists of two critical modules: image pre-processing and the development of a skip connection-based U-Net model for SAT and VAT segmentation.
3.1 Abdominal MR Images Pre-Processing
Although deep learning approaches do not require pre-processing in MR image segmentation, image enhancement is required to minimise computing costs, eliminate false positives caused by MR image bias fields, and get a better result with limited training data. This proposed abdominal VAT segmentation method uniform sizing, Gaussian normalization and data augmentation methods are used for MR image pre-processing.
Uniform sizing
A change in the size and quality of the MR images can be observed when different configurations of MRI scanners are used for different clinical investigations. Consequently, when the size of the MR images is high, it takes a significant amount of time and computer power to construct a model. In this proposed study, the image is resized to a resolution of 256 × 256 pixels before being trained and tested with the U-Net model.
Gaussian normalization
Due to variations in the MRI scanner, the brightness and contrast of the images are not uniform in all MR images. Furthermore, MRI scans are frequently obtained using a variety of collection techniques or methods. This has a significant impact on the deep learning model’s VAT segmentation efficiency. In this study, Gaussian normalisation was utilised to reduce segmentation error by uniformizing the MR images’ luminance and brightness used for the U-Net model’s training and validation. Gaussian normalisation is accomplished through the use of the following formula.
where I represents the pixel intensity values in MR images, and \(\left( {x,y,z} \right)\) denotes the pixel dimensions. \(\mu\) and \(\sigma\) represent the mean and standard deviation of all pixel dimensions, respectively.
MR image augmentation
The primary goal of image augmentation in deep learning models is to produce a more accurate segmentation or classification model with fewer training images. In this study, abdomen MR images are rotated artificially in a variety of directions, including horizontally, 180 degrees, 360 degrees, and vertically. Image augmentation multiplies the amount of training images by 400%.
3.2 Skip Connection Based U-Net Architecture for SAT and VAT Segmentation
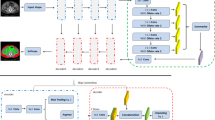
FCN architecture is universally utilised in clinical image processing to perform semantic segmentation. A FCN encodes image pixels into image classes using a convolutional neural network. FCNs are composed of convolutional, pooling, and upsampling layers. Images of varying sizes can be handled by FCNs, which is a notable feature of the technique. The convolution and pooling layers represent the objects in the image, whereas the up sampling layer indicates the area where the object is detected. A skip connection is employed in order to maintain the smooth representation of spatial data that has been lost during the pooling levels of the network. The U-Net architecture is believed to be the most effective FCN for doing end-to-end segmentation. The U-Net, which is formed from FCNs, has evolved into a fundamental network structure for biomedical image segmentation. Figure 1 depicts the complete flow diagram for the automated segmentation of SAT and VAT. Figure 1 depicts the overall flow diagram for automated SAT and VAT segmentation, including pre-processing, training, and testing. The proposed skip connection-based U-Net architecture is divided into three modules: encoding, decoding and bridge. The encoding layer receives pre-processed and augmented images as input. The encoding block is made up of four blocks, each of which has down convolutional layers, a non-linear activation function, and a max pooling layer. This encoding block’s primary job is to extract high-level and low-level texture features from the input abdominal MR images. Then, high-level and low-level features with positive values are chosen and fed into the bridge layer. The bridge module connects the encoding and decoding modules. The bridge module has two normalisation units, two ReLU units, two convolutional units and a concatenation unit. Finally, the textural properties of the MRI fat region are extracted by the decoding unit.

The proposed U-Net-based system for automatic VAT and SAT segmentation, includes pre-processing, training and testing
A novel skip connection-based U-Net model is proposed to separate the SAT and VAT from abdominal MR images in this study. This improved U-Net architecture establishes skip connectivity between both the up convolution and down convolution parts to enhance convergence rate and VAT and SAT segmentation efficiency. It carries out convolution and cropping operations. The yellow arrow on the figure indicates this. The outputs of the down convolution (1st, 2nd, 3rd and 4th blocks) are connected to the input component of the up convolutional layer (7th, 8th, 9th and 10th block) in this architecture. The skip connection method can be calculated as follows:
In Eq. 2, X represents the input, W represents the FCN’s network weight, and f denotes the non-linear activation function (ReLU). The gradient descent (GD) algorithm is commonly used to train the FCN model. When using GD to train the FCN model, the gradient vanishing problem emerges. The proposed skip connection model more effectively addresses the gradient vanishing problem. As a result, the proposed U-Net model’s training efficiency has substantially increased.
Adam optimizer is used for training the input images and the related feature maps [21] for segmentation. Soft-max [22] over the final feature map and Dice loss function are combined to update the weighing values. Soft-max is defined as,
where mk(L) indicates the activation at the pixel position L in feature channel k. Sk(L) is the maximum-function approximation. The Dice loss function is given by:
where p(L) represents the pixel label, and θ represents the feature map. The weighing values are calculated as:
Here, t represents the time period, st and ut represent the first and second moment vectors. The rate of exponential decay of the first and second estimation of moments are α1 = 0.9 and α2 = 0.99, respectively. The entire process flow of the proposed method is described in algorithm 1.

3.3 Clustering of VAT Based on K-means Algorithm
The automatic segmentation of VAT and the segregation of adipose and non-adipose tissues are carried out using K-means (K = 2) clustering method based on the intensity of images. Some observations without labels can be clustered using the K-means clustering algorithm [23,24,25]; however, the total number of categories must be clearly represented, such as a total of K categories. It is necessary to find centre of clusters for each category which is the core of the algorithm. A rough seed point is needed to induce the algorithm. But it seems to be complex to get an adequate output when random seed algorithm is used. Better clustering results are obtained using AFK-MC2 algorithm without the distribution of data. It enhances the creation of initial seed point, and its clustering speed is also high. The VAT clustering is done in the peritoneal cavity to avoid misinterpretation of VAT. Several clusters are generated with varying signal intensity. The cluster whose average intensity was high are considered as VAT.
4 Experimental Results
This study includes 65 non-contrast MRI datasets that is collected at random from the prospective EISNER trial obtained at NIMS Medical Institute. The study cohort included people without any previous record of coronary heart disease but with diabetes and hypercholesterolemia. The population is represented in Table 1. An average of 55 transverse slices were used per scan, and each axial slice has a dimension of 512 × 512 pixels of 0.684 mm × 0.684 mm. For the implementation of this proposed work, a workstation with Dual Intel Xeon Processor E5-2630 v2 (Six-Core HT, 2.6 GHz Turbo, 15 MB), 4 GB NVIDIA Quadro K5000, 1 × 8 GB DDR3, 1 TB 7200RPM SATA, and Windows 10 Pro workstation is used as a platform. Python 3.7 and open-source machine learning libraries such as Keras 2.2.4, TensorFlow 1.13.1, and Scikit-learn 0.20.3 have been used for the development of working model.
In this method, the SAT results produced by the automated method are represented as orange-coloured area, and the VAT results are shown in yellow colour as represented in Fig. 3. In Table 2, the proposed method was compared with the existing literatures, and it is observed that the proposed method provides a high correlation coefficient (SAT—0.99 and VAT—00.99).

Column1 represents the original image, column2 and column3 indicate the result of segmentation of SAT and VAT, respectively
The suggested VAT and SAT segmentation model’s overall performance is determined by its total accuracy, which is calculated using Eq. 3.
This study used the FCN-based U-Net architecture and clustering method to automatically quantify VAT and SAT accurately. In VAT clustering, at certain times, the non-VAT areas in the peritoneal cavity shows a signal intensity similar to VAT. In this case, there is a chance for over estimation of VAT content, and so VAT clustering is carried out in the peritoneal cavity contour. To avoid misinterpretation of VAT, the fat images was mapped to the water images depicted by U-Net peritoneal contour to obtain the same position.
5 Conclusion
Even though various approaches for VAT and SAT segmentation have been proposed, this deep learning and clustering-based segmentation method improves the efficiency and accuracy of segmentation. The experimental results shows that there is a good correlation between the proposed and manual method. The automated segmentation of adipose tissue volumes are considered to be beneficial for the creation of new biomarkers of various disorders. This work helps the clinicians to access central obesity and the risks associated with it by segmenting VAT and SAT. Overall, the proposed deep learning-based approach could save the excess time that doctors spend on the segmentation of visceral adipose tissue.
References
Al-Radaideh, A., Tayyem, R., Al-Fayomi, K., Nimer, N., Malkawi, A., Al-Zu’bi, R., Agraib, L., Athamneh, I., Hijjawi, N.: Assessment of abdominal fat using high-field magnetic resonance imaging and anthropometric and biochemical parameters. Am. J. Med. Sci. 352, 593–602 (2016). https://doi.org/10.1016/j.amjms.2016.09.009
Hussein, S., Bagci, U., Green, A., Watane, A., Reiter, D., Chen, X., Papadakis, G.Z., Wood, B., Cypess, A., Osman, M.: Automatic segmentation and quantification of white and brown adipose tissues from PET/CT scans. IEEE Trans. Med. Imaging. 36, 734–744 (2017). https://doi.org/10.1109/TMI.2016.2636188
Grainger, A.T., Krishnaraj, A., Quinones, M.H., Tustison, N.J., Epstein, S., Fuller, D., Jha, A., Allman, K.L., Shi, W.: Deep learning-based quantification of abdominal subcutaneous and visceral fat volume on CT images. Acad. Radiol. S1076633220304268 (2020). https://doi.org/10.1016/j.acra.2020.07.010
Srikumar, T., Siegel, E.M., Gu, Y., Balagurunathan, Y., Garcia, A.L., Chen, Y.A., Zhou, J.-M., Zhao, X., Gillies, R., Clark, W., Gamenthaler, A., Choi, J., Shibata, D.: Semiautomated measure of abdominal adiposity using computed tomography scan analysis. J. Surg. Res. 237, 12–21 (2019). https://doi.org/10.1016/j.jss.2018.11.027
Kucybała, I., Tabor, Z., Ciuk, S., Chrzan, R., Urbanik, A., Wojciechowski, W.: A fast graph-based algorithm for automated segmentation of subcutaneous and visceral adipose tissue in 3D abdominal computed tomography images. Biocybernetics Biomed. Eng. 40, 729–739 (2020). https://doi.org/10.1016/j.bbe.2020.02.009
Wald, D., Teucher, B., Dinkel, J., Kaaks, R., Delorme, S., Boeing, H., Seidensaal, K., Meinzer, H., Heimann, T.: Automatic quantification of subcutaneous and visceral adipose tissue from whole-body magnetic resonance images suitable for large cohort studies. J. Magn. Reson. Imaging. 36, 1421–1434 (2012). https://doi.org/10.1002/jmri.23775
Mattsson, S., Thomas, B.J.: Development of methods for body composition studies. Phys. Med. Biol. 51, R203–R228 (2006). https://doi.org/10.1088/0031-9155/51/13/R13
Heimann, T., Meinzer, H.-P.: Statistical shape models for 3D medical image segmentation: a review. Med. Image Anal. 13, 543–563 (2009). https://doi.org/10.1016/j.media.2009.05.004
Criminisi, A.: Decision forests: a unified framework for classification, regression, density estimation, manifold learning and semi-supervised learning. FNT in Comput. Graph. Vision. 7, 81–227 (2011). https://doi.org/10.1561/0600000035
Decazes, P., Rouquette, A., Chetrit, A., Vera, P., Gardin, I.: Automatic measurement of the total visceral adipose tissue from computed tomography images by using a multi-atlas segmentation method. J. Comput. Assisted Tomography. 42, 139–145 (2018). https://doi.org/10.1097/RCT.0000000000000652
Shen, D., Wu, G., Suk, H.-I.: Deep learning in medical image analysis. 28 (2017)
Wang, D., Shi, L., Chu, W.C.W., Hu, M., Tomlinson, B., Huang, W.-H., Wang, T., Heng, P.A., Yeung, D.K.W., Ahuja, A.T.: Fully automatic and nonparametric quantification of adipose tissue in fat–water separation MR imaging. Med. Biol. Eng. Comput. 53, 1247–1254 (2015). https://doi.org/10.1007/s11517-015-1347-y
Hui, S.C.N., Zhang, T., Shi, L., Wang, D., Ip, C.-B., Chu, W.C.W.: Automated segmentation of abdominal subcutaneous adipose tissue and visceral adipose tissue in obese adolescent in MRI. Magn. Reson. Imaging 45, 97–104 (2018). https://doi.org/10.1016/j.mri.2017.09.016
Langner, T., Hedström, A., Mörwald, K., Weghuber, D., Forslund, A., Bergsten, P., Ahlström, H., Kullberg, J.: Fully convolutional networks for automated segmentation of abdominal adipose tissue depots in multicenter water–fat MRI. Magn. Reson. Med. 81, 2736–2745 (2019). https://doi.org/10.1002/mrm.27550
Park, H.J., Shin, Y., Park, J., Kim, H., Lee, I.S., Seo, D.-W., Huh, J., Lee, T.Y., Park, T., Lee, J., Kim, K.W.: Development and validation of a deep learning system for segmentation of abdominal muscle and fat on computed tomography. Korean J Radiol. 21, 88 (2020). https://doi.org/10.3348/kjr.2019.0470
Sadananthan, S.A., Prakash, B., Leow, M.K.-S., Khoo, C.M., Chou, H., Venkataraman, K., Khoo, E.Y.H., Lee, Y.S., Gluckman, P.D., Tai, E.S., Velan, S.S.: Automated segmentation of visceral and subcutaneous (deep and superficial) adipose tissues in normal and overweight men: Automated Segmentation of Adipose Tissue. J. Magn. Reson. Imaging. 41, 924–934 (2015). https://doi.org/10.1002/jmri.24655
Kim, Y.J., Park, J.W., Kim, J.W., Park, C.-S., Gonzalez, J.P.S., Lee, S.H., Kim, K.G., Oh, J.H.: Computerized automated quantification of subcutaneous and visceral adipose tissue from computed tomography scans: development and validation study. JMIR Med Inform. 4, e2 (2016). https://doi.org/10.2196/medinform.4923
Küstner, T., Hepp, T., Fischer, M., Schwartz, M., Fritsche, A., Häring, H.-U., Nikolaou, K., Bamberg, F., Yang, B., Schick, F., Gatidis, S., Machann, J.: Fully automated and standardized segmentation of adipose tissue compartments by deep learning in three-dimensional whole-body mri of epidemiological cohort studies. 30 (2020)
Estrada, S., Lu, R., Conjeti, S., Orozco-Ruiz, X., Panos-Willuhn, J., Breteler, M.M.B., Reuter, M.: FatSegNet: a fully automated deep learning pipeline for adipose tissue segmentation on abdominal dixon MRI. Magn Reson Med. 83, 1471–1483 (2020). https://doi.org/10.1002/mrm.28022
Masoudi, S., Anwar, S.M., Harmon, S.A., Choyke, P.L., Turkbey, B., Bagci, U.: Adipose tissue segmentation in unlabeled abdomen mri using cross modality domain adaptation. In: 2020 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). pp. 1624–1628. IEEE, Montreal, QC, Canada (2020). https://doi.org/10.1109/EMBC44109.2020.9176009
Tripathi, M.: Analysis of convolutional neural network based image classification techniques. JIIP. 3, 100–117 (2021). https://doi.org/10.36548/jiip.2021.2.003
Dr. Manoharan, S., Sathish: Improved version of graph-cut algorithm for CT images of lung cancer with clinical property condition. JAICN. 2, 201–206 (2020). https://doi.org/10.36548/jaicn.2020.4.002
Balasubramaniam, V.: Artificial intelligence algorithm with SVM classification using dermascopic images for melanoma diagnosis. JAICN. 3, 34–42 (2021). https://doi.org/10.36548/jaicn.2021.1.003
Babiker Hamdan, P. K., Sathish, Y.: Early prediction of autism spectrum disorder by computational approaches to fMRI analysis with early learning technique. JAICN. 2, 207–216 (2020). https://doi.org/10.36548/jaicn.2020.4.003
Sungheetha, Dr. A., Sharma, R., Dr.R.: GTIKF-gabor-transform incorporated K-means and fuzzy C means clustering for edge detection in CT and MRI. JSCP. 2, 111–119 (2020). https://doi.org/10.36548/jscp.2020.2.004
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Devi, B.S., Misbha, D.S. (2022). Development of a Fully Convolutional Network for the Segmentation of Adipose Tissues on Abdominal MRI. In: Pandian, A.P., Fernando, X., Haoxiang, W. (eds) Computer Networks, Big Data and IoT. Lecture Notes on Data Engineering and Communications Technologies, vol 117. Springer, Singapore. https://doi.org/10.1007/978-981-19-0898-9_56
Download citation
DOI: https://doi.org/10.1007/978-981-19-0898-9_56
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-0897-2
Online ISBN: 978-981-19-0898-9
eBook Packages: EngineeringEngineering (R0)