
Abstract
Speaker identification and verification is an important research area that finds applications in forensics voice verification, mobile banking and security authentication for access control. Various techniques for feature extraction are available in the literature. In this work, a speech feature fusion extraction technique based on fusion of time domain, frequency domain and cepstral domain features has been proposed. Supervised machine learning classification algorithms are used for speaker feature classification. Performance of proposed technique has been evaluated on two open-source speech datasets. Performance metrics of training time and accuracy (validation and test) are measured with the help of confusion matrix. The results indicate that even with smaller training datasets, the average accuracy achieved is 2.97 and 8.97% better and training time 1.95 and 2.03 s less as compared to MFCC and (MFCC + delta + delta delta) MFCC + Δ + Δ2, respectively.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others

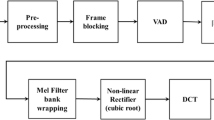
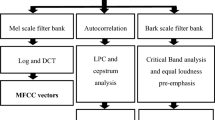
References
H. Garg, R.K. Bansal, S. Bansal, Improved speech compression using LPC and DWT approach. Int. J. Electron. Commun. Instrum. Eng. Res. Dev. (IJECIERD) 4(2), 155–162 (2014)
Z. Zhang, Mechanics of human voice production and control. J. Acoust. Soc. Am. 140, 2614–2635 (2016). https://doi.org/10.1121/1.4964509
R.M. Hanifa, K. Isa, S. Mohamad, A review on speaker recognition: technology and challenges. Comput. Electr. Eng. 90, 107005 (2021). https://doi.org/10.1016/j.compeleceng.2021.107005
Z. Bai, X.-L. Zhang, Speaker recognition based on deep learning: an overview. Neural Netw. 140, 65–99 (2021). https://doi.org/10.1016/j.neunet.2021.03.004
G. Sharma, K. Umapathy, S. Krishnan, Trends in audio signal feature extraction methods. Appl. Acoust. 158, 107020 (2020). https://doi.org/10.1016/j.apacoust.2019.107020
F. Alías, J.C. Socoró, X. Sevillano, A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 6(5), 143 (2016). https://doi.org/10.3390/app6050143
K.S.R. Murty, B. Yegnanarayana, Combining evidence from residual phase and MFCC features for speaker recognition. IEEE Signal Process. Lett. 13(1), 52–55 (2006). https://doi.org/10.1109/LSP.2005.860538
S. Fong, K. Lan, R. Wong, Classifying human voices by using hybrid SFX time-series preprocessing and ensemble feature selection. BioMed Res. Int. 2013(720834) (2013). https://doi.org/10.1155/2013/720834
H. Ali, S.N. Tran, E. Benetos et al., Speaker recognition with hybrid features from a deep belief network. Neural Comput. Appl. 29, 13–19 (2018). https://doi.org/10.1007/s00521-016-2501-7
M. Soleymanpour, H. Marvi, Text-independent speaker identification based on selection of the most similar feature vectors. Int. J. Speech Technol. 20, 99–108 (2017). https://doi.org/10.1007/s10772-016-9385-x
S. Selva Nidhyananthan, R. Shantha Selva Kumari, T. Senthur Selvi, Noise robust speaker identification using RASTA–MFCC feature with quadrilateral filter bank structure. Wireless Pers. Commun. 91, 1321–1333 (2016). https://doi.org/10.1007/s11277-016-3530-3
M. Mohammadi, H.R. Sadegh Mohammadi, Robust features fusion for text independent speaker verification enhancement in noisy environments, in 2017 Iranian Conference on Electrical Engineering (ICEE) (2017), pp. 1863–1868. https://doi.org/10.1109/IranianCEE.2017.7985357
R. Jahangir et al., Text-independent speaker identification through feature fusion and deep neural network. IEEE Access 8, 32187–32202 (2020). https://doi.org/10.1109/ACCESS.2020.2973541
S. Bansal, R.K. Bansal, Y. Sharma, ANN based efficient feature fusion technique for speaker recognition, in International Conference on Emerging Technologies: AI, IoT and CPS for Science & Technology Applications (2021). http://ceur-ws.org/Vol-3058/Paper-063.pdf
M.A. Hossan, S. Memon, M.A. Gregory, A novel approach for MFCC feature extraction, in 2010 4th International Conference on Signal Processing and Communication Systems (2010), pp. 1–5. https://doi.org/10.1109/ICSPCS.2010.5709752
E. Alexandre-Cortizo, M. Rosa-Zurera, F. Lopez-Ferreras, Application of Fisher linear discriminant analysis to speech/music classification, in EUROCON 2005—The International Conference on “Computer as a Tool” (2005), pp. 1666–1669. https://doi.org/10.1109/EURCON.2005.1630291
S. Sun, C. Zhang, Subspace ensembles for classification. Physica A 385(1), 199–207 (2007). https://doi.org/10.1016/j.physa.2007.05.010
G. Pirker, M. Wohlmayr, S. Petrik, F. Pernkopf, A pitch tracking corpus with evaluation on multipitch tracking scenario. Interspeech, 1509–1512 (2011). Available Online https://www2.spsc.tugraz.at/databases/PTDB-TUG/
ST-AEDS-20180100_1, Free ST American English Corpus. Available Online https://www.openslr.org/45/
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Bansal, S., Bansal, R.K., Sharma, Y. (2022). An Efficient Feature Fusion Technique for Text-Independent Speaker Identification and Verification. In: Verma, P., Charan, C., Fernando, X., Ganesan, S. (eds) Advances in Data Computing, Communication and Security. Lecture Notes on Data Engineering and Communications Technologies, vol 106. Springer, Singapore. https://doi.org/10.1007/978-981-16-8403-6_56
Download citation
DOI: https://doi.org/10.1007/978-981-16-8403-6_56
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-8402-9
Online ISBN: 978-981-16-8403-6
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)