
Abstract
The aim of this study was to identify the spatial variability of various metal elements in soils and to compare the variability of the outputs of different geostatistical methods using the concentration of heavy metals in the ground of the waste disposal site at Rajbandh, Khulna, Bangladesh, to find the best-fitted prediction model. In this study, sixty soil samples were collected from the waste disposal site at a depth of 0–30 cm from the existing ground surface. The concentration of metal components like Al, As, Ba, Ca, Cd, Cr, Co, Cu, Fe, Hg, K, Mn, Na, Ni, Pb, Sb, Sc, Sr, Ti, V, and Zn in soils were measured through standard technique. ArcGIS 10.5 was used to prepare the spatial distribution of these metals to determine their extents in the soil. Four geostatistical methods named inverse distance weighting (IDW), universal kriging (UK), ordinary kriging (OK), and empirical Bayesian kriging (EBK) were performed to generate the spatial distribution of these elements in the soil. The interpolation technique was used in this regard to reduce the possibility of error prediction of results. Prediction maps prepared using interpolation techniques showed that most of the contaminated spots were near the dumping point. There was seen a significant amount of low concentration of metals in some spots. Moreover, cross-validation was conducted to determine the best-fitted model. The results indicated that EBK was a better method with more accurate predictions based on MAPE, RMSPE, and SRMSPE values than that of other counterparts.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Today, thousands of processes are constantly contaminating soils on a daily basis. Accumulation of heavy metals and metalloids due to pollution from rapidly developing industrial areas, mine littering, disposal of high metal wastes, excess of lead in gasoline and paints, application of compost to grounds, animal compost, sewage sludge, pesticides, wastewater irrigation, leftovers from coal combustion, petrochemicals spilling and atmospheric deposition, etc., can be some of the major examples [1]. Heavy metals comprise some ill-defined groups of inorganic chemical hazards in the contaminated sites. The most hazardous and toxic heavy metals found in these groups are lead (Pb), chromium (Cr), arsenic (As), zinc (Zn), cadmium (Cd), copper (Cu), mercury (Hg), nickel (Ni), etc. In the soil, the concentration of these metals holds for a very long time and puts on a substantial threat to human health and the ecological system. Soil samples are taken from various points of the site to determine the concentration of heavy metals in a contaminated site, and several geostatistical approaches can provide precise predictions at the unsampled locations.
Spatial prediction, usually referred to as spatial interpolation, is a widely used analytical technique for estimating an unknown spatial value using known values observed at a range of sample locations [2]. The techniques of interpolation are based on the principles of spatial autocorrelation, which assumes that the points closer to each other are more similar than the farther ones [3]. There are several space interpolation methods, each according to different estimation criteria that are considered to produce a good prediction. This research focuses on four of the most commonly used methods for spatial interpolation: inverse distance weighting (IDW), ordinary kriging (OK), universal kriging (UK), and empirical Bayesian kriging (EBK). Such methods approximate values at unsampled locations with certain allocated weights for each measurement based on the measurements at surrounding locations. Till now, there have been many comparisons made by many researchers between the results found from these methods.
Shiode and Shiode [2] reported ordinary kriging to be providing more accurate results than the other methods of interpolation for street-level spatial interpolation. In a study of soil texture, variance structure and soil-chemical properties ordinary kriging showed more accurate results than the other counterparts [4]. Again, IDW interpolation showed the best result while mapping organic matter contents for several fields [5]. According to Luo et al. [6], for offshore estimations, where site investigation is expensive, ordinary kriging is not suitable as this method requires a large number of in the interested area. Bayesian kriging method in this case can tackle the scarcity of data in the site of interest by making use of prior information from similar sites. Besides, some researchers found the results to be mixed between the kriging methods [7, 8].
This research focuses mainly on the evaluation and comparison of the results coming up relatively from inverse distance weighting (IDW), ordinary kriging (OK), universal kriging (UK), and empirical Bayesian kriging (EBK) and to come up with some map quality of soil contamination indicators in Rajbandh Waste Disposal Site, Khulna.
2 Materials and Methodology Adopted
2.1 Study Area
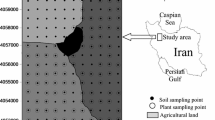
Khulna, which lies in the so-called transition area of the southwest tidal flood plain of the Ganges–Brahmaputra Delta, is the third-largest city in Bangladesh after Dhaka and Chittagong. This district occupies an area of 4394.96 km2. Khulna is situated to the east of Satkhira, west of Bagerhat, south of Jessore and Narail, and north of the Bay of Bengal. Khulna’s bounding coordinates are 22°47´16´´ to 22°52´0´´ north latitude and 89°31´36´´ to 89°34´35´´ east longitude. In 2020, the metropolitan area of Khulna had a projected population of 1.7 million roughly. The only official dumping site in the Khulna region is the Rajbandh waste disposal site (Fig. 1). The disposal site is situated 10 km west of the city. A total of 420–520 tons of MSW/day waste that is generated daily in Khulna City is disposed of directly at this 25-acre waste disposal site. A total of 60 soil samples from the various points at a depth of 0–30 cm of the disposal site are collected, and the locations of the sampling points were recorded using GPS (Fig. 1). The concentrations of the 21 metal elements like Al, As, Ba, Ca, Cd, Cr, Co, Cu, Fe, Hg, K, Mn, Na, Ni, Pb, Sb, Sc, Sr, Ti, V, and Zn in soils of the contaminated site were measured in the laboratory for further study using normal laboratory procedure.

Map of the study area with soil sampling locations
2.2 Laboratory Investigations
In the laboratory, the concentrations of metal elements in soil were measured through standard procedure. The acid digestion and atomic absorption spectrophotometer (AAS) analysis are described in the following articles.
2.2.1 Acid Digestion
To measure the concentration of metal elements in soil, laboratory work was done through the standard test method. In laboratory investigation, at first, 10 g of each soil sample was taken into a 100 ml conical flask. Already, the flask had been washed with deionized water prepared by adding 6 mL HNO3/HClO4 acid in ratio 2:1 and left overnight. Each sample was kept at 150 °C temperature for about 90 min. Later, the temperature was raised to 230 °C for 30 min. Subsequently, HCl solution was added in ratio 1:1 to the digested sample and re-digested again for another 30 min. The digested sample was washed into a 100 ml volumetric flask, and the mixture obtained was cooled down to room temperature.
2.2.2 Analysis of Metal Elements with AAS
After performing the digestion procedure, metal elements in this digested solution were determined using AAS in the laboratory, and the amount of each metal element was deduced from the calibration graph. The relevant concentrations of Al, Fe, Mn, Cr, Cu, Pb, Zn, Ni, Cd, As, Co, Sb, Sc, and Hg in mg/kg were measured.
2.3 Inverse Distance Weighting
Inverse distance weighting (IDW) is a sort of deterministic approach with a defined scattered set of points for multivariate interpolation. It is a localized and precise method that approximates an unknown spatial value at a target location using observed values at the neighboring sampling points in a straight line distance and applies a weight inversely proportional to the straight line distance from the corresponding sampling point [2]. The idea that points closer one to another have more similarities and correlations than ones farther away was used to establish all the interpolation approaches. Also in IDW, the rate of similarities and correlations between the neighboring sampling points is considerably assumed to be proportionate to the space between the points [9]. The accuracy of the IDW interpolations is greatly influenced by power parameters p. In this study, IDW on the heavy metals was performed for power 1–5 using the following Eq. (1).
-
Z0 = estimated value of z variable in point I
-
Zi = sample value in point I
-
di = distance between the sample point and estimated point
-
N = a weigh coefficient based on distance
-
n = prediction number per validation case.
2.4 Ordinary Kriging
Among all, ordinary kriging (OK) is the most commonly known and used kriging technique. This geostatistical technique uses data from the neighboring sampling points to predict the value of the desired sampling points that have defined variograms. Ordinary kriging is the most versatile kriging method since it acts on the assumption that the mean u is an unknown constant, and thus, random errors are unknown at data locations. Ordinary kriging is most suitable for data with a spatial trend and, besides that, this process can easily be adapted to limit (average) approximation from point estimation. The approximation of weighted average approximation provided by the ordinary kriging estimator at an unsampled location Z(s0) is represented by the following Eq. (2).
Here, λ is the weight of each sample observed.
2.5 Universal Kriging
Universal kriging (UK) is an ordinary kriging (OK)-type kriging technique. This technique working with either semivariograms or covariances is kriging with a local trend. This local trend is a previously defined deterministic function of coordinates which is an incessant and gradually varying trend surface on top of which the interpolated variation is imposed. With each output pixel, the local trend is recalculated. At an unsampled location u0, the universal kriging estimator can be expressed by the following Eq. (3).
Here, A is a constant shift parameter and the λK(uk)’s are the kriging weights assigned to the n surrounding z(us) sample data.
2.6 Empirical Bayesian Kriging
The empirical Bayesian kriging (EBK) technique is an incredibly simple, effective, and reliable solution, both for automated and collaborative data interpolation. It can be used to interpolate large data sets of up to hundreds of millions of data points [10]. EBK comprises of two models of geostatistics: a linear mixed model and an intrinsic random kriging model. Both models have been set in a single computational model represented by the following Eq. (4) [11].
-
zi = measured value at observed location
-
si = observed location
-
y(s) = studied Gaussian process
-
ϵi = measurement error
-
K = number of measurements
In general, traditional kriging methods in the geostatistical analyst require manual adjustment of parameters, but empirical Bayesian technique automatically allows the adjustments through subsets and simulations [12]. Thus, the most challenging part of the construction of a valid kriging model is automated by this method. This approach differs from classical kriging techniques for the error made of the semivariogram model calculation. The data is first used for the semivariogram estimation. A new data set is considered using a semivariogram, and then, the proper values are obtained through continuous simulation at the input locations.
2.7 Assigning of Search Neighborhood
It is very important in a GIS analysis to assign the neighborhood criteria appropriately. When the measured points of data sets are situated at greater distances from the location of prediction, they are less autocorrelated to one another spatially. In this study, the measurement spheroid was divided into four sectors in which the minimum and maximum neighbor numbers were limited to 1 and 10, respectively, for all the methods. For inverse distance weighting, ordinary kriging, and universal kriging, the neighborhood type was “Standard.” In the universal kriging method, “Gaussian” was used as the kernel function. For the empirical Bayesian kriging method, “Standard Circular” was selected as the neighborhood type.
2.8 Cross-Validation
The predictive accuracy of a linear regression equation is often evaluated by a cross-validation method. This is one of many common approaches for determining whether a statistical analysis is extended in an independent data set. In practice, it is primarily used when the goal is to determine the exactness in the action of a predictive model [13]. Initially, the points are split randomly into two data sets, one for the training phase and one for validation. Each element must validate in successive rounds with training and validation sets to minimize variability [14]. The precision of the interpolation methods was determined by estimating mean average prediction error (MAPE), root mean square prediction error (RMSPE), and standardized root mean square prediction error (SRMSPE). Yasrebi et al. [9] stated, in the case of MAPE, the lower its value, the lower the error of the method. According to them, a successful model should calculate MAPE values near zero to prove predictions are accurate or centered on the locations measured. The RMSPE and SRMSPE are also two methods to check the properness of a model. Jakubek and Forsythe [15] mentioned that low RMSPE and SRMSPE values indicate that predictions of a method are close to their original values. In this study, all the methods were assessed for MAPE values at first. Then, the best-fitted model was determined based on the accuracy of RMSPE values first and then SRMSPE.
3 Results and Discussions
3.1 Distribution of Metal Elements in Soils
Spatial distribution of metal concentrations is a helpful tool for visually classifying metal production sources as well as exposure hotspots with high metal content. The map created from different techniques of interpolation of metal elements provides a clear idea of on-the-ground pollution measures of the soil by metal elements in the disposal site. In this study, predicted distribution maps were created for all metal elements (Al, As, Ba, Ca, Cd, Cr, Co, Cu, Fe, Hg, K, Mn, Na, Ni, Pb, Sb, Sc, Sr, Ti, V, and Zn) using four types of interpolation methods (IDW, OK, UK, and EBK). As all the metals were showing almost same type of distribution across the site, among these, the distribution maps for iron (Fe) and cadmium (Cd) are represented in Fig. 2. The findings showed that the pattern of distribution of the metals were both zonal and concentrated. The maximum concentrations of all metals were between the disposal site's center and the southwest region where almost all the waste products were dumped initially. The concentration of the metals gradually decreased from the southeast to the northeast zone of the disposal site where the cultivated lands were situated away from the dumping point.

Spatial distribution of Fe and Cd using inverse distance weighting, ordinary kriging, universal kriging, and empirical Bayesian kriging
3.2 Interpolation and Cross-Validation of Results
IDW, OK, UK, and EBK techniques were used to interpolate the spatial variation of heavy metals and to find out the best model to predict the variability of them in the soil. In terms of MAPE results, Table 1 shows that the geostatistical kriging methods were performing better and providing less error in prediction than the deterministic IDW methods. In the analysis of almost all the metals, the geostatistical kriging methods were showing lesser MAPE values than the deterministic IDW methods conducted from power 1 to 5.
Again, the RMSPE values for all the geostatistical methods are given in Table 2. OK’s summary result showed the lowest RMSPE values of 38.91, 2.13, 450.57, 5.43, 1.54, and 10.11, respectively, for Ca, Cu, Fe, Mn, Sb, and V. UK showed the lowest RMSPE values for Al (114.03), As (1.28), Cd (1.17), Hg (1.49), Ni (1.16), and Zn (7.55). EBK showed the smallest RMSPE results for Ba (12.43), Co (1.14), K (75.71), Sc (2.15), Sr (5.31), and Ti (247.65).
Table 3 represents the SRMSPE values for the three types of kriging methods. Performed results show that these values were ranging around 0.89–0.95 for EBK, 1.09–5.68 for UK, and 0.75–1.16 for OK. So, though ordinary kriging sometimes shows better performance, in terms of cross-validation results, empirical Bayesian kriging is the interpolation method with the best performance here.
3.3 Evaluation of Semivariogram Parameters
Table 4 shortens the parameters from the semivariogram models of the metal elements. The data from the semivariograms indicated the reality of different spatial dependence for the collected field soil properties. The nugget-to-sill ratio states the spatial autocorrelation. In Fig. 3, the semivariogram diagrams of barium, iron, and lead found from ordinary kriging are shown. The C0/(C + C0) value measured for arsenic and copper was 12% and 6% indicating that the metals were distributed strongly spatially. The metals barium, sodium, antimony, scandium, and strontium were distributed at moderate levels as for C0/(C + C0) values of 42%, 44%, 54%, 42%, and 57%, respectively. C0/(C + C0) value equaling 81% depicted lead was weakly distributed in the study zone. Contrarily, calcium, cadmium, chromium, cobalt, iron, mercury, potassium, nickel, titanium, vanadium, and zinc were non-spatially correlated as their C0/(C + C0) values were zero.

Semivariogram models of (a) Ba, (b) Fe, and (c) Pb
4 Conclusions
This study was conducted to find out the appropriate geostatistical approach to generate a proper spatial distribution map for metal elements in the soil. It was inferred from the prediction maps that all types of metal elements were showing the highest concentration in soil from the nearest point of the selected waste disposal site. The most surprising finding along these lines was that the three kriging methods like ordinary kriging, universal kriging, and empirical Bayesian kriging consistently and significantly outperformed the inverse distance weighting approach over all other factors. Again, among all three kriging methods, the empirical Bayesian kriging method was superior to the other two approaches (like ordinary kriging and universal kriging). From the study, it can be concluded that the EBK method was the best to generate the prediction maps and generate spatial variability of metal elements in the soil.
References
Wuana RA, Okieimen FE (2011) Heavy metals in contaminated soils: a review of sources, chemistry, risks and best available strategies for remediation. ISRN Ecol 2011:1–20. https://doi.org/10.5402/2011/402647
Shiode N, Shiode S (2011) Street-level spatial interpolation using network-based IDW and ordinary kriging. Trans GIS 15:457–477. https://doi.org/10.1111/j.1467-9671.2011.01278.x
Arun PV (2013) A comparative analysis of different DEM interpolation methods. Egypt J Remote Sens Sp Sci 16:133–139. https://doi.org/10.1016/j.ejrs.2013.09.001
Yasrebi J, Saffari M, Fathi H, Karimian N, Emadi M, Baghernejad M (2008) Spatial variability of soil fertility properties for precision agriculture in Southern Iran. J Appl Sci 8:1642–1650
Gotway CA, Ferguson RB, Hergert GW, Peterson TA (1996) Comparison of kriging and inverse-distance methods for mapping soil parameters. Soil Sci Soc Am J 60:1237–1247. https://doi.org/10.2136/sssaj1996.03615995006000040040x
Luo W, Xuan T, Li J (2017) Estimating anisotropic soil properties using Bayesian Kriging. Geotech Spec Publ 370–381. https://doi.org/10.1061/9780784480717.035
Lapen DR, Hayhoe HN (2003) Spatial analysis of seasonal and annual temperature and precipitation normals in Southern Ontario, Canada. J Great Lakes Res 29:529–544. https://doi.org/10.1016/S0380-1330(03)70457-2
Schloeder CA, Zimmerman NE, Jacobs MJ (2001) Division S-8 - nutrient management & soil & plant analysis: comparison of methods for interpolating soil properties using limited data. Soil Sci Soc Am J 65:470–479. https://doi.org/10.2136/sssaj2001.652470x
Yasrebi J, Saffari M, Fathi H, Karimian N (2009) Evaluation and comparison of ordinary Kriging and IDW methods. Res J Biol Sci 4:93–102
Gribov A, Krivoruchko K (2020) Empirical Bayesian kriging implementation and usage. Sci Total Environ 722:137290. https://doi.org/10.1016/j.scitotenv.2020.137290
Krivoruchko K, Gribov A (2019) Evaluation of empirical Bayesian kriging. Spat Stat 32:100368 https://doi.org/10.1016/j.spasta.2019.100368
Sağir Ç, Kurtuluş B (2017) Hydraulic head and groundwater 111cd content interpolations using empirical Bayesian kriging (Ebk) and geo-adaptive neuro-fuzzy inference system (geo-ANFIS). Water SA 43:509–519. https://doi.org/10.4314/wsa.v43i3.16
Mosier CI (1951) The need and means of cross validation. I. Problems and designs of cross-validation. Educ Psychol Meas 11:5–11. https://doi.org/10.1177/001316445101100101
Bhunia GS, Shit PK, Maiti R (2018) Comparison of GIS-based interpolation methods for spatial distribution of soil organic carbon (SOC). J Saudi Soc Agric Sci 17:114–126. https://doi.org/10.1016/j.jssas.2016.02.001
Jakubek DJ, Forsythe KW (2004) A GIS-based kriging approach for assessing Lake Ontario sediment contamination. Gt Lakes Geogr 11:1–14
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Nath, H., Rafizul, I.M. (2022). Spatial Variability of Metal Elements in Soils of a Waste Disposal Site in Khulna: A Geostatistical Study. In: Arthur, S., Saitoh, M., Pal, S.K. (eds) Advances in Civil Engineering. Lecture Notes in Civil Engineering, vol 184. Springer, Singapore. https://doi.org/10.1007/978-981-16-5547-0_3
Download citation
DOI: https://doi.org/10.1007/978-981-16-5547-0_3
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-5546-3
Online ISBN: 978-981-16-5547-0
eBook Packages: EngineeringEngineering (R0)