
Abstract
One of the most deadly diseases in humans is brain tumor. For clinicians, MRI scan plays a key role in diagnosing and treating tumor. For brain tumor diagnosis, surgical approaches are usually suggested. But the radiologist's analysis of the medical image is time-consuming and also accuracy totally relies upon their skill. Now, Deep learning-based models have gained considerable interest in the diagnosis and treatment of diseases in medical field. As the medical images are limited, so it is a daunting task to train CNN from start and to implement deep learning. In this paper, we develop an automatic brain tumor detection method based on the pre-trained convolutional neural network architectures such as VGG-16, VGG-19, InceptionV3, ResNet50, ResNet101 and EfficientNetB1. The test accuracy achieved with VGG16 and ResNet101 gives highest performance accuracy among all other pretrained network.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
26.1 Introduction
Brain tumor is a mass (i.e. benign or malignant) which is produced by tissue besieging the brain or skull within the brain which impacts person's life explicitly. These tumors cultivate irregularly in the brain and put pressure around them [1]. Due to this pressure, different brain disorders are induced in human body. Side effects in patients due to these disorders are dizziness, headache, fainting attacks, paralysis, etc. As stated by WHO, tumor in brain accounts for less than 2% of human cancers in the cancer report; however, extreme bleakness and problems are registered [2]. The Cancer Research Corporation of UK estimated that almost 5200 causalities are recorded per year in UK due to brain disorders and skull tumors [3].
Deep learning (DL) has recently been used mainly in medical imaging. Conventional machine learning involves a great deal of domain expertise, human interaction to retrieve the hand-engineered features, i.e. used by classifiers for classification and detection of image patterns. Specialist manual annotation takes a lot of time. DL algorithms, however, maps unprocessed data, i.e. pixel for images directly into outputs, i.e. image classes. With the introduction of AlexNet [4] in 2012, the popularity of DL improved with ImageNet competition, which includes over 1 million images with 1000 different object categories. AlexNet has shown better results in this challenge, as in comparison to other state-of-the-art results obtained from the group of computer vision. DL has advanced fast, thus further significant work has regularly appeared in the area of medical imaging. Different researchers have researched DL in medical imaging [5,6,7,8,9], although some have surveyed individual imaging, i.e. magnetic resonance (MR) imaging, i.e. MRI [10,11,12], ultrasound (US) [13] and electroencephalogram (EEG) [14]. Convolutional neural networks (CNNs) are the most useful between many DL techniques that were used to actually solve problems in different applications, including detection, segmentation and classification, etc. MRI is a type of medical image modality that is measured by its non-invasiveness as a safe technique and has a reasonable soft-tissue contrast. As attempted by ionizing radiation-based methods, this does not alter the construction, properties and characteristics of particles. The MRI setting does however, offer potential hazards due to 3 magnetic fields that are robust static magnetic fields, gradient-based magnetic fields and pulsed radiofrequency fields that are used to generate 3D images [14]. Eventually, MRI can provide useful information on tissue structures, i.e. shape, size and location. MRI is being categorized as structural and functional imaging. Examples of structural imaging are T1-W MRI, T2-W MRI, Diffusion Tensor Imaging (DTI) and functional imaging is resting-state functional MRI (rs-fMRI) [10]. Nazir et al. [15] categorized brain MRI images into two classes, i.e. benign and malignant. They utilized filter methodology to remove the noise in the MR images as a pre-processing stage for the dataset. Using the normal color moment of every image, they then extracted features. They labeled extracted features by the artificial neural network (ANN). The prediction accuracy obtained was 91.8% in their method. Shree et al. [16] categorized brain MRI images into two classes, i.e. benign and malignant. They extracted features using discrete wavelet transform (DWT) and gray-level co-occurrence matrix (GLCM) preceded by morphological process. The probabilistic neural network was used as a classifier to detect location of tumor in brain MR images. Kanmani et al. [17] categorized brain MR images into two classes, i.e. normal and abnormal. To improve the efficacy of classification accuracy, they utilized the threshold-based region optimization technique along with segmentation. Ahmed et al. [18] also categorized brain MRI images into two classes, i.e. normal and abnormal. For this, they introduced a combination of Artificial neural network technique and a gray wolf optimization technique. Five distinct CNN models have been used by Abiwinanda et al. [19] and their one of the model attained the maximum accuracy. El-Dahshan et al. [20] also categorized brain MR images into two classes, i.e. normal and abnormal using the Discrete Wavelet Transform (DWT) technique for the extraction of features and the Principal component analysis method to reduce the features. Then, they used two classifiers (i.e. feedorward ANN and the k-Nearest neighbor for the identification of images.
In this paper, we diagnose the brain tumor in MR images by extracting features using DL based transfer learning technique. For this, we use six pre-trained models, i.e. VGG16, VGG19, InceptionV3, ResNet50, ResNet101, EfficientNetB1. This framework makes it a lot easier for radiologists to intervene, helps them solve the problem of classification of brain tumors, i.e. whether the tumor is present or not, and helps to develop an appropriate treatment.
Further, we organized the paper into different sections as follows: Sect. 26.2 depicts the information about material and different models used. Section 26.3 illustrates the experimental results and discussion. Finally, in Sect. 26.4, conclusion and future scope are specified, respectively.
26.2 Material and Models
26.2.1 Dataset
The data set used in this paper consists of freely accessible 646 T1 weighted MRI images of brain labeled as non-tumored and tumored attained from The Cancer Imaging Archive (TCIA) Publicly Accessible repository [21]. The images were obtained from 20 patients who identified with glioblastoma. The dataset has 548 samples of tumored images and 98 samples of non-tumored images. The images are in JPG/JPEG format. Figure 26.1. displays few images of Non-Tumored and Tumored classes used in the dataset.

a Non-tumored images, b Tumored images
26.2.2 Data Pre-processing and Augmentation
Data pre-processing can be referred as the transformation of raw data into a form that is more easy to interpret and renders the images more appropriate for any further processing. Figure 26.2 specifies the various steps involved in Data Pre-processing.

Steps involved in data pre-processing
The MRI data set contains 253 images, which are divided into 193 training images, 50 validation images and 10 test images. After data splitting the images are cropped to obtain only the portion of brain by using the technique given in Ref. [22]. This method is used for assessing the extreme points within contour lines. Figure 26.3. shows the cropped image after finding extreme points in contour.

Cropped image after finding extreme points in contour
However, acquisition processes of MR image are normally costly and complex, the size of MR image dataset is limited in several applications. If a large dataset is present, DL will perform much better. As the dataset used in this work is small, we use data augmentation for artificially increasing the size of training data. For this, the images from original dataset are artificially varied to generate modified images so that the size of training data increase. Due to this, the learning capability of model increase and it became more generalized for unseen data. Then on the other hand, it becomes less susceptible to overfitting. Figure 26.4. shows some samples of images after data augmentation.

Images samples after augmentation
26.2.3 Pre-trained CNNs Architectures
DL became prominent with the increasing availability of various datasets and fast gaming graphical processing units (GPUs) nearly a decade ago. DL technique includes numerous layers which learn enormous features from input image and these are used for analyses of various images by providing huge dataset of unlabeled or labeled images [23].
Convolutional neural network (CNN) is frequently utilized DL system architecture in analysis of medical imaging [24]. CNN architectures were built for learning the spatial hierarchies of different features through multiple blocks which includes convolution layers, non-linear layer, pooling layers and fully connected layers. Fully connected layers choose the most effective features and move them to the classification layer. Different pretrained CNN architectures are used in our study. Table 26.1 provides different parameter values used in the different CNN architecture.
In reality, it is unlikely that a person can train a full CNN model from scratch as datasets with adequate sample data are usually not feasible. Persistently, pre-training a CNN on large datasets, e.g. ImageNet seems to have become a common practice. Transfer learning (TL) [25, 26] can be seen as better learning in a novel problem by extracting features obtained from a comparable problem that exists. TL is a method in which features obtained from one data set can be used for other datasets.
VGG16 and VGG19 models [27]—The impact of CNN depth on its performance in computer vision was analysed by Simonyan K. and Zisserman A. Using very small convolution filters, they drive the depth from 11 to 19 weight layers of established VGGNet network. The variations that has 16 and 19 weight layers, referred as VGG16 and VGG19 and they do well. With the increase in depth, the classification error reduces and saturates when the depth exceeds 19 layers. In visual representations, authors affirm the value of depth.
InceptionV3 model [28]—It is a Google Brain Team 48-layer CNN that is trained on the ImageNet database and categorizes objects into 1,000 classes. In comparison to the other inception models and process, it trained much quicker.
ResNet model [29]—Microsoft developed deep residual learning platform, i.e. ResNet, which uses residual learning for simplification of deeper network training and decrease errors through increase in depth. This architecture suggested several structures such as 18-layers, 34-layers, 50-layers and 101-layers framework. This structure is less complexity and more deep in comparison to VGG network.
EfficientNetB1 model [30]—Google Brain Team developed a CNN model named as EfficientNet. These researchers studied the model scaling and identified that carefully balancing the depth, width and resolution of the network can lead to better performance. In order to develop a new model, they scaled neural network to generate more deep learning models, that achieve significantly improved efficacy and accuracy in comparison to prior used CNN.
26.2.4 Proposed Methodology
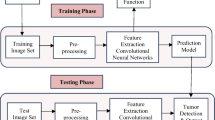
This proposed diagnosis method aims to improve the accuracy of the detection of brain MRI images by using DL models and TL method. The flow diagram of the suggested work performed is shown in Fig. 26.5.

Flow chart of proposed methodology
TL is the process of learning new models generated by new data using the features provided by a pre-trained framework. In order to learn low level features which are utilized to encode medical images, TL is used in which Deep Learning model is pre-trained on a huge data set of images from various medical image modalities or different domains. The use of pre-trained DL models allows to learn new tasks quickly. In this work, we first pre-process the MRI data to run the built model and test it. Then, we trained six different pretrained CNN models, i.e. VGG16, VGG19, InceptionV3, ResNet50, ResNet101 and EfficientNetB1 with brain MR Images and then, utilized them to classify tumored and non-tumored images using TL technique.
26.3 Experimental Results and Discussion
Each model has been trained for 50 epochs. Figures 26.6 and 26.7 were attained by training the models using brain MR image dataset for 50 epochs and represents the accuracy and loss curve for training and validation set for VGG16 and ResNet101 models. Table 26.2 displays performance of different model used in our study.

Accuracy and loss curve for training and validation set for VGG16 model

Accuracy and loss curve for training and validation set for ResNet101 model
Performance for the different technique was evaluated in terms of different measures such Accuracy, Precision, Recall, F1 score, Kappa and AUC. VGG16 and ResNet101 has highest test accuracy. Training accuracy of ResNet101 is 93%. But, F1 score of VGG16 is more as the precision and recall are more in this case. By analyzing the performance measures, we found that both ResNet101 and VGG16 has better performance as compared to other pretrained networks.
26.4 Conclusion
In this paper, a completely automatic system is used for diagnosing tumor in brain MRI images. For this, numerous DL-based pretrained CNN architectures are used. The suggested solution applied the theory of DL employing four pre-trained networks that use the TL approach to enhance diagnosis of brain tumor. The dataset used contains images of 2 classes, i.e. abnormal data which have tumor and normal data which don’t have tumor. Although the dataset is not huge, the image data augmentation was relatively good enough to produce excellent performance. As exhibited in Table, it is noticeable that TL through VGG16 and ResNet101 gives highest performance accuracy among all other pretrained network used in this paper. In future work, we will use our model for different medical imaging modalities from different fields and for larger dataset to improve the robustness. Substantial hyperparameter tuning as well as a better pre-processing approach can be conceived that can further improve efficiency of the model. In future work, we are also planning to further classify different types of tumors using larger dataset.
References
Grisold, W., Grisold, A.: Cancer around the brain. Neuro-Oncology Practice 1(1), 13–21 (2014)
Stewart B.W., Wild C.P.: World cancer report 2014, IARC. IARC Nonserial Publ, Lyon, France, p. 630 (2014)
Brain, other CNS and intracranial tumours statistics Cancer Research UK. (n.d.), 2020 from https://www.cancerresearchuk.org/health-professional/cancer-statistics/statistics-by-cancer-type/brain-other-cns-and-intracranial-tumours?_ga=2.245798211.613033350.1594394057-1698240228.1594394057 (Retrieved July 10, 2020)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: ImageNet classification with deep convolutional neural networks, In: Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q. (eds.) Advances in Neural Information Processing Systems, vol. 25, pp. 1097–1105 (2012)
Litjens, G., Kooi, T., Ehteshami, B.B.: A survey on deep learning in medical image analysis. Med. Image Anal. 42, 60–88 (2017)
Shen, D., Wu, G., Zhang, D.: Machine learning in medical imaging. Comput. Med. Imaging Graph 1–2 (2015)
Shen, D., Wu, G., Suk, H.-I.: Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 19, 221–48 (2017)
Suzuki, K.: Survey of deep learning applications to medical image analysis. Med Imaging Technol. 35, 212–226 (2017)
Ker, J., Wang, L., Rao, J., Lim, T.: Deep learning applications in medical image analysis. IEEE Access 6, 9375–9389 (2018)
Liu, J., et al.: Applications of deep learning to mri images: a survey. Big Data Min. Anal. 1(1), 1–18 (2018)
Datta, P., Rohilla, R.: An introduction to deep learning applications. In: MRI Images, 2019 2nd International Conference on Power Energy, Environment and Intelligent Control (PEEIC), Greater Noida, India, pp. 458–465 (2019)
Lundervold, A.S., Lundervold, A.: An overview of deep learning in medical imaging focusing on MRI. Z. Med. Phys. 29, 102–127 (2019)
Liu, S., Wang, Y., Yang, X., Lei, B., Liu, L., Li, S., Ni, D., Wang, T.: Deep learning in medical ultrasound analysis: a review. Engineering, 261–275 (2019)
Movahedi, F., Coyle, J.L., Sejdic, E.: Deep belief networks for electroencephalography: A review of recent contributions and future outlooks. IEEE J. Biomed. Health Inform. 22(03), 642–652 (2018)
Nazir, M., Wahid, F., Khan, S.A.: A simple and intelligent approach for brain MRI classification. J. Intell. Fuzzy Syst. 28, 1127–1135 (2015)
Shree, N.V., Kumar, T.N.R.: Identification and classification of brain tumor MRI images with feature extraction using DWT and probabilistic neural network. Brain Inf. 5, 23–30 (2018)
Kanmani, P., Marikkannu, P.: MRI brain images classification: a multi-level threshold based region optimization technique. J. Med. Syst. 42, 1–12 (2018)
Ahmed, H.M., Youssef, B.A.B., Elkorany, A.S., Saleeb, A.A., El-Samie, F.A.: Hybrid gray wolf optimizer–artificial neural network classification approach for magnetic resonance brain images. Appl. Opt. 57, B25–B31 (2018)
Abiwinanda, N., Hanif, M., Hesaputra, S.T., Handayani, A., Mengko, T.R.: Brain tumor classification using convolutional neural network. In: Lhotska L., Sukupova L., Lacković I., Ibbott G. (eds) World Congress on Medical Physics and Biomedical Engineering 2018. IFMBE Proceedings, vol 68/1, Springer, Singapore (2019)
El-Dahshan, E.S.A., Hosny, T., Salem, A.B.M.: Hybrid intelligent techniques for MRI brain images classification. Digit. Signal Process. 20(2), 433–441 (2010)
Clark, K., Vendt, B., Smith, K., Freymann, J., Kirby, J., Koppel, P., Moore, S., Phillips, S., Maffitt, D., Pringle, M., Tarbox, L., Prior, F.: The cancer imaging archive (TCIA): maintaining and operating a public information repository. J. Digit. Imaging 26(6), 1045–1057 (2013)
Rosebrock, A.: Finding Extreme Points in Contours with OpenCV.PyImageSearch, 11, https://www.pyimagesearch.com/2016/04/11/findingextreme-points-in-contours-with-opencv/ (2016)
Schmidhuber, J.: Deep learning in neural networks: an overview. Neural Netw. 6, 85–117 (2015)
LeCun, Y., Kavukcuoglu, K., Farabet, C.: Convolutional networks and applications in vision. In: IEEE International Symposium on Circuits and Systems, pp. 253–256 (2010)
Pan, S.J., Yang, Q.: A survey on transfer learning. IEEE Trans Knowl Data Eng. 22, 1345–1359 (2010)
Weiss, K., Khoshgoftaar, T.M., Wang, D.: A survey of transfer learning. J Big Data 3, 9 (2016)
Simonyan, K., Andrew, Z.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the Inception Architecture for Computer Vision. arXiv:1512.00567 [cs] (2015)
He K., Zhang X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, pp. 770–778 (2016)
Tan, M., Le, Q.V.: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv:1905.11946 (2019)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Datta, P., Rohilla, R. (2022). Transfer Learning-Based Brain Tumor Detection Using MR Images. In: Rao, V.V., Kumaraswamy, A., Kalra, S., Saxena, A. (eds) Computational and Experimental Methods in Mechanical Engineering. Smart Innovation, Systems and Technologies, vol 239. Springer, Singapore. https://doi.org/10.1007/978-981-16-2857-3_29
Download citation
DOI: https://doi.org/10.1007/978-981-16-2857-3_29
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-2856-6
Online ISBN: 978-981-16-2857-3
eBook Packages: EngineeringEngineering (R0)