
Abstract
The amounts of multimedia data on the Web have increased in recent times and there are very few approaches for video recommendations. There is a need for a semantically driven video recommendation system as the current structure of the Web is progressing into a rational Semantic Web. The increase in the number of videos has also enhanced the annotations and the metadata associated with the video recommendation system. Due to the luxury of the availability of an increase in the amounts of metadata on the Web specifically for the video contents, an annotations-based video retrieval scheme by aggregating the meta information of the video is a mandated requirement as it can reduce the computational complexity in video recommendation than the traditional content-based video recommendation systems. In this paper, an OntoVidRec framework which aggregated video-related meta information from the query, user profiles, and the dataset has been proposed. The approach builds formal ontologies from the individual sources and encompasses a strategic model for Ontology Matching to yield the most appropriate Query relevant Ontological Entities that are semantically matched with the video annotations and are recommended based on the semantic similarity and the Kullback-Leibler divergence measure. An overall F-Measure of 95.37% has been achieved by the OntoVidRec which is the best in class performance for such systems.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Video Recommendation from the World Wide Web in the era of Semantic Web is required owing to the exponential increase in the multimedia contents on the Web. The Video contents tend to increase the complexity than any other multimedia content owing to their large frame size and incorporation of audio into them. Video Analysis is computationally expensive, and the recommendation of videos based on the video descriptions and annotations can reduce the complexity of the recommendation and yield satisfactory results. Most of the existing video recommendation systems are either content-based video recommendation systems with a very high computational complexity or consider only the titles of the video or the annotations of the video or descriptions. The latter which are text-driven do not perform well and usually end up being polysemous or have a low coverage without addressing the issues of ambiguity. The Learning-Based Approaches which select text features alone do not tackle the problem of ambiguity and still have a low coverage rate. The Hybrid Learning Approaches which consider the textual and the content features also lag in their performance owing to the fact that the video contents are a collection of frames that are in constant motion and learning from them does not yield results that are correct or satisfactory. Due to all these reasons a text-driven video recommendation approach but that considers every possibility of the text sources as indicator or clue terms is the solution. The best in class solution is to build an ontology from various sources to capture the relevance of recommendation from different perspectives. A Query Sourced Ontology, a user information ontology, and the source data-driven ontology can be modeled and recommendations can be done using some semantic strategies which will transform the problem of Video Recommendation into a paradigm of Ontology-Driven Semantic Search for the Videos which ensures it as an inferential scheme over a learning-driven paradigm.
Motivation: Video Recommendation has emerged to be necessitated in the current times where the multimedia contents of the Web is exponentially expanding. With several video recommendation platforms competing against each other, a computationally less expensive and yet a full cover video recommendation framework which tackles the problems of polysemy, cold start, and ambiguity is the need. Due to the complexity involved in the content-based video recommendation techniques and their lag in performing effectively, an annotation-based video recommendation approach that takes into consideration, the textual contents from several sources and perspectives is required, such that the recommendations are non-ambiguous with a contextual semantic search and performs efficiently.
Contribution: A strategic approach for an annotations-based video retrieval, the OntoVidRec has been proposed. OntoVidRec is a full cover search that tackles the problem of ambiguity, polysemy, cold -start and serendipity in semantic search. The approach makes use of the Query and formulates an ontology by aggregating Lexical and Auxiliary Knowledge to yield a Query Sourced Ontology. Similarly, a User Profile-based Ontology and the Dataset-Derived Ontology is formalized. The approach encompasses the SemantoSim measure and the Kullback-Leibler Divergence for Ontology Matching of the Query Sourced Ontology with the other ontologies in a systematic manner to yield the most recommendable tags which are used for recommending the videos to the user. An F-Measure of 95.18% has been achieved with a coverage of 0.98 which makes it a full cover search.
Organization: This paper is organized as follows. Section 2 provides an overview of the related research work. Section 3 presents the Proposed System Architecture. Implementation is discussed in Sect. 4. Performance Evaluation and Results is discussed in Sect. 5. This paper is concluded in Sect. 6.
2 Related Work
Yashar et al. [1] have put forth a strategy for recommending videos focusing on the stylistic features from the video. This approach not only facilitates content-based extraction of videos from full-length videos, but the approach is capable to extract features from an abstractive form of videos like the trailer of the full video. Diaz et al. [2] have proposed a cognitive approach for video recommendations based on the emotional reactions of the viewer. Shang et al. [3] have devised an approach that recommends a micro-video based on inferences made from Big Data using parallel computing as a scheme. The parallel computing is achieved using Hadoop and MapReduce frameworks and based on the inferences made from the analysis of the big data, the videos are recommended. Checkley et al. [4] have devised a scheme where videos are recommended in a dynamic environment involving video sharing by extracting the keywords from the title of the video and compares with the words in the target video by computing its similarity score and ranking it. Gao et al. [5] have proposed a dynamic RNN model to capture the changing user interests over time and yield a personalized video recommendation framework. Liu et al. [6] have proposed the multi-info-based fusion model for video recommendation based on the integration of the user rating and the textual data of the video names the description and the genre. The approach uses the Jaccard Similarity Measure for comparing the similarity between the items. Zhou et al. [7] have improvised the performance of video recommendations by encompassing the usage of social interactions of the user. Cai et al. [8] have proposed a multi-view learning framework for the recommendation of videos that focuses on class label querying. The approach proposes an MVAL algorithm for cutting down the annotation cost, and also encompass informative scenarios into the approach. Wei et al. [9] have proposed a mixed model for a collaborative filtering-driven video recommendation system by making use of user information and similarity, K-means clustering, video genetic structure for yielding style and regional preferences. Yongxia et al. [10] have proposed a relative algorithm for recommending videos which integrates a user-based collaborative filtering, item-based collaborative filtering, and a model-based collaborative filtering for an efficient recommendation of videos. Nitin et al. [11] have proposed a mechanism of concept-based recommendation of videos by combining a technique comprising of ranked intersection filtering and a foreground-based concept co-occurrence matrix which is a content-based video recommendation system that uses deep CNNs. Liu et al. [12] have devised an approach that recommends videos based on tags that are enhanced using a graph-based neural network for ranking of tags. The approach also assimilates a neighbor similarity scheme for loss estimation which facilitates encoding the varied user preferences into possible representations of nodes. In [13,14,15,16,17,18] Ontologies have played a vital role in semantic enrichment of tags or vocabularies and ontology focused mechanisms have incorporated intelligence into the approach to yield the best in class recommendations in various scenarios.
3 Proposed System Architecture
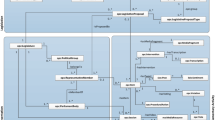
The architecture of the proposed Semantic Aware Video Recommendation Framework is depicted in Fig. 1. The proposed framework is a composition of Ontology Modeling from three main sources namely the Query Sourced Ontology, User-Driven Ontology, and the Dataset-Derived Ontology. The approach looks quite significant, but this is the first of its kind which matches a single source Ontologies with Ontologies from two different sources for facilitating semantic search. The Query Sourced Ontology is obtained from the User Query which is input into the system. The user query undergoes simple pre-processing namely the Tokenization, Lemmatization, and the stop word removal. The pre-processed user query is formulated as a query word set. The query word set is subject to Named Entity Recognition for predicting the context of the user query, and then the query word set is subject to synonymizing using the WordNet 3.1.

Proposed system architecture
Further to overcome the polysemy problem and if the query word is polysemous, then its equivalent Hypernyms, Hyponyms, and Meronyms are loaded based on the context of the query word. Further, the synonymized query word with hypernym, hyponym, and meronym aggregation based on the context is linked to the Wikidata through the SPARQL Endpoint to aggregate real-world knowledge based on the query words which have been synonymized to yield a taxonomy of Query Words. The Query Word Taxonomy is further Reasoned using the Pellet Reasoner and is formalized into a Query Sourced Ontology.
The User Profile Information is elicited, analyzed to understand the user preferences, and uncover the details concerning the categories and the nature of video that the user wishes to watch. The Web Usage Data from the user profile and the channel subscription information from the user profile is extracted, pre-processed based on Tokenization, Lemmatization, and stop word removal. The frequent terms from the Web Usage Data and the subscription are extracted and further synonymized. The terms are prioritized based on the frequent terms and are further subject to synonymization. The SPARQL Endpoint for Wikidata is used for Knowledge Leveraging and Aggregation. Furthermore, the terms are reasoned out and formalized to yield a User-Driven Ontology. The dataset is first pre-processed based on the Title of the video, Video Description, and the Video Metadata to yield descriptor and indicator terms. Among all the contents in the dataset, the focus is mainly on the Video Title, Annotations of the video, and the Metadata description of the video content. The pre-processed dataset yields video descriptor and indicator terms which are passed onto the reasoner for correlations among the contents. Further to this the term descriptor and indicators are linked with the Wikidata API to leverage real-world knowledge. Further to this the terms are reasoned out and formalized into an ontology termed as the Dataset-Derived Ontology. The ontological terms are populated based on leveraging of the knowledge contents from the standard real-world knowledge base which is the Wikidata.
Once the Query Sourced Ontology, User-Driven Ontology, and the Dataset-Derived Ontology are formulated from the Query, User Profile Information, and the Dataset, Ontology Matching is performed by encompassing two constraints, namely the Kullback-Leibler (K-L) Divergence and the SemantoSim Similarity Measure. The Query Sourced Ontology is used as a source Ontology or the key for Matching. Ontology Matching is achieved in two stages namely where the SemantoSim measure is computed with a threshold of 0.5 among the concepts of the Query Sourced Ontology and the User-Driven Ontology; the matching concepts along with it two immediate neighbors with a direct link are alone retained in the ontology. Now the K-L Divergence [19] is computed between the Query Sourced Ontology and the new ontology with matching nodes and their neighbors with a 50% threshold. The Matching modes from the User Profile Ontology are now Merged with the Query Sourced Ontology. Furthermore, based on the Merged Ontology as the node, a similar procedure is followed to retain the nodes in the Dataset Ontology and the retained nodes are matched with the newly Merged Query Sourced Ontology. The videos with data descriptors that are semantically similar to the newly Merged Query Sourced Ontology are recommended based on the increasing order of the semantic similarity.
The SemantoSim [20, 21] Measure is depicted in Eq. (1) which is proposed which depicts the semantics based on the probability of individual occurrence and the probability of co-occurrence of the terms in the web corpus or the text corpus. Equation (2) depicts the K-L Divergence as the information divergence which is a probabilistic distance model that represents the distance between a pair of probabilistic distributions [22].
4 Implementation
The experimentations were conducted on the YouTube-8M dataset with added descriptions of the videos based on the annotations in the Multilabel dataset. Apart from the annotations, textual descriptions based on the Categorizations in the dataset were used to add descriptions to the video using customized JAVA crawlers. To get user profile and subscription information of the user, 427 users were given the annotations, labels, and the video information in the dataset and were asked to browse, binge watch videos based on their choices but restricted to their topics for 120 days in a separately created YouTube profile. Further, they were asked to subscribe to the channels they were interested in and that they thought belonged to the domain without deviance. At the end of 120 days, the user profile information which comprised of the Web Usage Data of the user and the channel subscription information were extracted and were used for the experimentations. The Terms were formulated into Taxonomy and then Ontological Structures using the OntoCollab [23, 24] framework as it supports dynamism and has the facilitation to link itself to the Wikidata API through an intrinsic SPARQL Agent. The formulations and steps in the proposed OntoVidRec algorithm are represented as Algorithm 1.

5 Results and Performance Evaluation
The YouTube-8 M dataset was used as a base dataset but it has been enriched based on the addition of descriptions and incorporation of user information to it, and the experimentations were conducted on the newly resultant dataset. The performance of the OntoVidRec was evaluated using Precision, Recall, Accuracy, F-Measure, and False Discovery Rate as the suitable metrics. The OntoVidRec has served as a full cover search as it takes into consideration the query details, user details and also is driven by the data in the dataset which makes it quite efficient and solves the serendipity and the polysemy problems that are prevalent in web search. The experimentations were conducted for 1748 queries which were given to the users who participated in the user profile information collection and top-10 relevant items for recommendation were recorded for ground truth collection. Each of the query results was correlated with the ground truth for relevance where the true positives and the false positives were estimated for each of the query results and the overall average performance was evaluated.
From Fig. 2 it can be inferred that the OntoVidRec yields an average precision of 93.89%, an average recall of 96.87%, an average accuracy of 94.33%, and an average F-Measure of 95.37%. From Fig. 3 it is evident that the proposed OntoVidRec yields a high Coverage of 0.98 and a low FDR of 0.07. The reason for high Precision, Recall, Accuracy, F-Measure, and Coverage is not just the fact that the proposed OntoVidRec is Tag driven or due to the reason that it is driven by text and not the video content but the main reason is that it is quite selective in integrating the text contents from several heterogeneous sources. Most importantly, the user query is transformed into an ontology which is staged by accumulating knowledge based on Synonymization, Hypernym–Hyponym extraction, Wikidata based Knowledge Aggregation to yield a Query Sourced Ontology. Furthermore, the Subscription Information and the Web Usage Data from the user profile information is formalized into a User-Driven Ontology by encompassing frequent term extraction, Synonymization, and Wikidata based Knowledge Aggregation. Also, an ontology is formalized from the Dataset by pre-processing, synonymization, and knowledge aggregation. The recommendation is based on a strategic scheme of Ontology Matching based on the SemantoSim measure and the K-L Divergence as objective functions. Ontology Matching enables the semantics between Ontologies from varied perspectives and vantage points rather than a specific single source. This not only improves the context of recommendation but also enhances the coverage of the semantic search. The provision of dynamic auxiliary knowledge from the Wikidata Knowledge Source helps in overcoming cold start problem, ambiguity problem, context irrelevance in web search and also provides a deep sense of understanding of the query words and the probable entities that are relevant to the query. This enhances the Precision, Recall, Accuracy, and F-Measure scores and is also a reason for a low FDR value.

Performance evaluation of the OntoVidRec

Coverage and FDR of OntoVidRec
The proposed OntoVidRec Framework is baselined with the state of art video recommendation frameworks namely the RABCF [10] approach, SC-CNN [11] approach, and the GNN [12]. The baseline methods were evaluated in the exact same environment of the proposed OntoVidRec for the same dataset and the exact same number of queries. It is seen that from Table 1 that RABDC yields an average precision of 83.64%, an average recall of 80.61%, an average accuracy of 82.04%, F-Measure of 82.09%, and an FDR of 0.17. The SC-CNN has yielded an average precision of 88.78%, an average recall of 90.89%, an average accuracy of 89.21%, an average F-Measure of 89.81, and an FDR of 0.12. The GNN has furnished an average precision of 91.48%, an average recall of 93.77%, an average accuracy of 92.18%, and an average F-Measure of 92.61 with an FDR of 0.09. However, the performance of OntoVidRec is higher than the baseline strategies with an average Precision of 93.89%, an average Recall of 96.87%, an average accuracy of 94.33%, and an average F-Measure of 95.37% with the low FDR of 0.07.
The RABCF is a collaborative filtering-based approach that infuses the user-based collaborative filtering, item-based collaborative filtering, and a model-based collaborative filtering algorithm. However, there is no auxiliary knowledge fed into the system, but it is driven by the profile of the users’ and the collective ratings of the items. The lack of structured knowledge makes it lag to a small extent. The SC-CNN integrates ranked intersection filtering with a foreground-based concept co-occurrence matrix which uses the deep CNNs. The SC-CNN model is a semantic concept-driven content-based model which employs the deep CNN which makes the approach computationally expensive and although semantics are imbibed into the methodology, the absence of background knowledge from standard knowledge bases is evident. The GNN is a tag-based scheme which uses a graph-based neural network for tag ranking and recommends the videos based on the tags ranked. Although this method is quite efficient, there is still a complexity in the usage of graphs with neural networks, and most importantly, the neighborhood similarity scheme makes it much more computationally expensive.
The proposed OntoVidRec framework suffices all the lacunae in the baseline systems and ensures that sufficient auxiliary knowledge is imbibed into the system in the form of Synonyms and background information from Wikidata Knowledge Base for the formalization of the Query Sourced Ontology, User-Driven Ontology, and the Dataset-Derived Ontology. Moreover, the Query Sourced Ontology has strategically matched with the User-Driven Ontology and the Dataset-Derived Ontology using SemantoSim measure and the K-L Divergence. Ontology Matching is computationally less expensive when compared to the graph-based neural network scheme and the content-based video recommendation which incorporates CNN. Moreover, the OntoVidRec framework amalgamates Query Information, User Profile Information consisting of the Subscription Information and the Web Usage Data, and an ontology from the data in the Dataset. Apart from this synonym from WordNet 3.1, Homonyms, Hypernyms, and background knowledge from Wikidata make OntoVidRec quite rich in its knowledge density which enhances the coverage and the performance in terms of Precision, Recall, Accuracy, and F-Measure.
6 Conclusions
A novel framework for an ontology focused video recommendation, the OntoVidRec has been proposed. The OntoVidRec serves as a multifaceted versatile video recommendation approach by formalizing ontologies from varied perspectives namely the Query Sourced Ontology, the ontology formulated from the user profiles, and the Dataset-Derived Ontology. The approach matches Ontologies based on the SemantoSim measure and the K-L Divergence to yield the best in class videos based on the video annotations or tags. The strategy involves NER, Synonymization, hypernym-hyponym identification, and Wikidata is used for knowledge aggregation which ensures that the approach is free from context irrelevance and ambiguity problems. The proposed OntoVidRec yields an average accuracy of 94.33% with a very low FDR of 0.06 which ensures that OntoVidRec is the best in class approach for annotations-based video recommendation.
References
Y. Deldjoo, M. Elahi, P. Cremonesi, F. Garzotto, P. Piazzolla, M. Quadrana, Content-based video recommendation system based on stylistic visual features. J. on Data Semant. 5(2), 99–113 (2016)
Y. Diaz, C.O. Alm, I. Nwogu, R. Bailey, Towards an affective video recommendation system, in 2018 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops) (IEEE, 2018), pp. 137–142
S. Shang, M. Shi, W. Shang, Z. Hong A micro-video recommendation system based on big data, in 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS). (IEEE, 2016), pp. 1–5
G. Checkley, L.L.C. Google, Video recommendation based on video titles. U.S. Patent 10,387,431 (2019)
J. Gao, T. Zhang, C. Xu, A unified personalized video recommendation via dynamic recurrent neural networks (2017)
Y. Liu, G. Zhang, X. Jin, H. Yuan Multi-info fusion based video recommendation system. J. Phys. Conf. Ser. 1229(1), 012010 (2019) (IOP Publishing)
X. Zhou, L. Chen, Y. Zhang, D. Qin, L. Cao, G. Huang, C. Wang, Enhancing online video recommendation using social user interactions. VLDB J. 26(5), 637–656 (2017)
J.J. Cai, J. Tang, Q.G. Chen, Y. Hu, X. Wang, S.J. Huang, Multi-view active learning for video recommendation. IJCAI, 2053–2059 (2019)
W. Zhang, Y. Wang, H. Chen, X. Wei, An efficient personalized video recommendation algorithm based on mixed mode, in 2019 IEEE International Conferences on Ubiquitous Computing & Communications (IUCC) and Data Science and Computational Intelligence (DSCI) and Smart Computing, Networking and Services (SmartCNS) (IEEE, 2019), pp. 367–373
Y. Zhao, B. Zhang, Research on recommendation algorithms based on collaborative filtering. J. Phys. Conf. Ser. 1237(2), 022094 (2019). IOP Publishing
N. Janwe, K. Bhoyar, Semantic concept-based video retrieval using convolutional neural network. SN Applied Sciences 2(1), 80 (2020)
Q. Liu, R. Xie, L. Chen, S. Liu, K. Tu, P. Cui, B. Zhang, L. Lin, Graph neural network for tag ranking in tag-enhanced video recommendation, in Proceedings of the 29th ACM International Conference on Information & Knowledge Management (2020), pp. 2613–2620
G. Deepak, B.N. Shwetha, C.N. Pushpa, J. Thriveni, K.R. Venugopal, A hybridized semantic trust-based framework for personalized web page recommendation. Int. J. Comput. Appl. 42(8), 729–739 (2020)
G. Deepak, J.S. Priyadarshini, Personalized and Enhanced Hybridized Semantic Algorithm for web image retrieval incorporating ontology classification, strategic query expansion, and content-based analysis. Comput. Electr. Eng. 72, 14–25 (2018)
G. Deepak, D. Kasaraneni, OntoCommerce: an ontology focused semantic framework for personalised product recommendation for user targeted e-commerce. Int. J. Comput. Aided Eng. Technol. 11(4–5), 449–466 (2019)
C.N. Pushpa, G. Deepak, A. Kumar, J. Thriveni, K.R. Venugopal, OntoDisco: improving web service discovery by hybridization of ontology focused concept clustering and interface semantics, in 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT) (IEEE, 2020), pp. 1–5
A. Kumar, G. Deepak, A. Santhanavijayan, HeTOnto: a novel approach for conceptualization, modeling, visualization, and Formalization of domain centric ontologies for heat transfer, in 2020 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT) (IEEE, 2020), pp. 1–6
S. Mandal, V.E. Balas, R.N. Shaw, A. Ghosh, Prediction analysis of idiopathic pulmonary fibrosis progression from OSIC dataset, in 2020 IEEE International Conference on Computing, Power and Communication Technologies (GUCON), (2–4 Oct. 2020), pp. 861–865. https://doi.org/10.1109/GUCON48875.2020.9231239
S. Haribabu, P.S. Sai Kumar, S. Padhy, G. Deepak, A. Santhanavijayan, N.D. Kumar, A novel approach for ontology focused inter- domain personalized search based on semantic set expansion, in 2019 Fifteenth International Conference on Information Processing (ICINPRO) (Bengaluru, India, 2019), pp. 1–5, https://doi.org/10.1109/ICInPro47689.2019.9092155
M. Kumar, V.M. Shenbagaraman, R.N. Shaw, A. Ghosh, Predictive data analysis for energy management of a smart factory leading to sustainability, in Innovations in Electrical and Electronic Engineering. Lecture Notes in Electrical Engineering, vol. 661. ed. by M. Favorskaya, S. Mekhilef, R. Pandey, N. Singh (Springer, Singapore, 2021) https://doi.org/10.1007/978-981-15-4692-1_58
S. Kullback, R.A. Leibler, On information and sufficiency. Ann. Math. Stat. 22(1), 79–86 (1951). https://doi.org/10.1214/aoms/1177729694.JSTOR2236703.MR0039968
G.L. Giri, G. Deepak, S.H. Manjula, K.R. Venugopal, OntoYield: a semantic approach for context-based ontology recommendation based on structure preservation, in Proceedings of International Conference on Computational Intelligence and Data Engineering (Springer, Singapore, 2018), pp. 265–275
S. Mandal, S. Biswas, V.E. Balas, R.N. Shaw, A, Ghosh, Motion prediction for autonomous vehicles from lyft dataset using deep learning, in 2020 IEEE 5th International Conference on Computing Communication and Automation (ICCCA) (30–31 Oct. 2020), pp. 768 – 773. https://doi.org/10.1109/ICCCA49541.2020.9250790
C.N. Pushpa, G. Deepak, J. Thriveni, K.R. Venugopal. Onto collab: strategic review oriented collaborative knowledge modeling using ontologies, in 2015 Seventh International Conference on Advanced Computing (ICoAC). (IEEE, 2015), pp. 1–7
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Deepak, G., Santhanavijayan, A. (2021). OntoVidRec: A Staged Knowledge Aggregation Scheme for Annotations-Based Video Retrieval Using Ontology Matching. In: Mekhilef, S., Favorskaya, M., Pandey, R.K., Shaw, R.N. (eds) Innovations in Electrical and Electronic Engineering. Lecture Notes in Electrical Engineering, vol 756. Springer, Singapore. https://doi.org/10.1007/978-981-16-0749-3_73
Download citation
DOI: https://doi.org/10.1007/978-981-16-0749-3_73
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-0748-6
Online ISBN: 978-981-16-0749-3
eBook Packages: EnergyEnergy (R0)