
Abstract
The discrimination for overcurrent relays has been considered as an optimization problem with complex constraints. Various meta-heuristic algorithms are presented to response with this drawback for over past few decades. This paper presented a study which compare two different meta-heuristic optimization approaches inspired by bio-nature. The approaches are tested to resolve the drawbacks of the overcurrent relays discrimination problem. With regards to this goal, two new optimization approaches called Ant Lion Optimizer and Grey Wolf Optimizer have been considered. The performances of these algorithms have been implemented on two different sizes of IEEE networks. The same initial condition and constraints’ boundaries have been executing for each algorithm for fair comparison purposes. The generated results with optimal value is then identified as the best method to resolve the coordination of the overcurrent relays problem.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Pick-up current
- Ant lion optimizer
- Grey wolf optimizer
- Overcurrent relays coordination
- Time dial setting
1 Introduction
In modern distribution network, relays configuration supposedly to be arranged properly to ensure the reliability of the system’s designed. Good configuration will remove the affected portion whereas keep the supply to the healthy portion during fault occurrences. Every equipment will be protected by two layer of relays which known as main relay and secondary relay. Main relays will react to the abnormal current flow within permitted time. If the main relay is fails to function well, secondary relays should take over the operation. Nevertheless, once the backup relay has taken over on behalf of the primary relay, the unnecessary power outages to a bigger portion of the system will occurs. This is why well-coordinated of the overcurrent relays is essential.
The optimization of the overcurrent relays (OCR) discrimination is establishing by two parameters that know as Plug Setting (PS) and Time Multiplier Setting (TMS). The OCR coordination is formulated as inequality constraints. In 1980s, The experimental of Trial and Error algorithm [1] has been wisely implemented to perform the OCR discrimination work. However, this approach only suitable for small distribution scale network. In early late 1980s researches has moved to topological analysis method which uses the graph theory approach to determine break points [2]. Whereas, in late 1990s, Linear Programming (LP) approach was presented in the frame of optimization method [3,4,5,6]. However, the slow convergence rate is the main drawback for the conventional methods especially for the system with large iteration no.
In early 2000, Genetic Algorithm (GA) [7,8,9,10] has pioneered the optimization method to resolve the OCR issue. GA known as the most popular method during that days. Then modification has been made to the original GA to improve the computational time of the method that called Continuous Genetic Algorithm (CGA) [11]. The evolutionary of the nature inspired approach is then continued with Particle Swarm Optimization [12,13,14] method which demonstrated to offer promising result rather than original GA and modified GA. The modernization of the technique is resumed by Cuckoo Search Algorithm [15]. In addition, hybrid method has been introduced in [16,17,18,19] to enhance the capabilities of the approaches. In overall, the approaches are established to explore the optimal OCR setting.
The No Lunch Free (NFL) theorem [20] highlighted that none of the method are able to solve all the problems. Since there are no limits in approaching for a new algorithm, this paper is proposing two new algorithms that known as Ant Lion Optimizer (ALO) and Grey Wolf Optimizer (GWO). Both algorithms are new for the OCR coordination field. The algorithm will be applied to search for the optimize value of the parameters TDS and Ip. The optimized parameters’ value will have determined the minimize value of the objective function. From this comparative study, the best method shall be established with regards to solve the OCR coordination issue.
This research is constructed as follows; Firstly, problem formulation explained at Sect. 2. Next section explained on the background of GWO and ALO. The paper is resumed with Sect. 4 which analyzed the simulation results. The conclusion of the work is in Sect. 5.
2 Problem Formulation
In order to ensure that the total operating time of the main relays are minimized whereas sustaining the selectivity in between main and secondary relays value with regards to the position of the DG insertion. Meanwhile, the aim is to optimize the plug setting (PS) and time multiplier setting (TMS) parameters.
2.1 Objective Function
It could be expressed as below:
where j is the main relays that need to be coordinated in total. T is the functioning time for the relays at the near end fault.
2.2 Characteristic Curve
Normal inverse characteristic (IDMT) will be applied where b = 0.02 and k = 0.14 as accordance to IEC standard. This is formulated as below.
PSa is the PS, TMSa is the setting for time multiplier, The current which may be detected by the respective relay as a fault is If.
2.3 Constraints
TMS will determine the time delay that bound in between 0.1 and 1.1 s whereas PS will determine the current delay which bound in between 1.5 and 5 s.
The time interval (DTI) to discriminate main and secondary relays must be fulfilled to ensure that relays are operating in sequence.
Tise is the operating time for secondary relay, Tima is the operating time for main relay and DTI is in between 0.2 and 0.5 s.
3 Meta-heuristic Approaches
This section explains on background of the GWO in the first subsection and in the next subsection, an overview to the ALO would be presented. Both algorithms have been introduced by Mirjalili et al. Details on the GWO and ALO can be found in [21] and [22] respectively
3.1 Grey Wolf Optimizer (GWO)
Grey Wolf Optimization method is inspired by the leadership pyramid of grey wolf initiated by Mirjalili et al. [21]. The group has average members of not more than 12 wolves. The top ranking is a leader known as alpha (α) which liable for decisions making and dominating the group. The leader is nominated due to their competency to control the members of the group.
The second ranking role as an assistance to impose instruction by the leader that called beta (β). The β is either male or female with good discipline. The last tier called Delta (δ) is once used to be α and β. The function of δ as nanny to the little members and eldest. The called not so important members are Omega (ω). The ω existence is to equalize the bio-chain of the group. There are three phases during hunting activity which are:
-
Tracking: track the spot of the target.
-
Encircling: surround the target in a loop.
-
Attacking: repositioning to or from the target according to the terms.
The α will be placed as the best solution, secondly by β and lastly by δ. The ω will update the positioning referred to three best solutions.
Base on bio-nature capabilities, the first three best wolves are expected to have knowledge on the prey’s position for mathematical modelling purposes. The formulas as below are obtained [21].
During hunting activity, the first step is encircling the prey. This could be modelled by the following equations [21]:
C and A are vectors’ coefficient, \( \overrightarrow {X} \) is the wolf positioning vector, \( \overrightarrow {X}_{p} \) is the prey’s location and t is the iteration for present situation. The vector’s coefficient of C and A are as following equation [21].
\( \overrightarrow {a} \) is deducted linearly from 2 to 0 at each iterations, \( \overrightarrow {{r_{1} }} \),\( \overrightarrow {{r_{2} }} \) are random vectors within (0,1). According to wolf behaviors of hunting, the re-positioning of the present location is accordance to prey’s location. The updated location will be depends on \( \overrightarrow {A} \) and \( \overrightarrow {C} \) with respect to the present location of the wolf. The wolf could be placed to new places by adjusting the \( \overrightarrow {A} \) and \( \overrightarrow {C} \). Agents are allowed to shift to a random location circling the prey accordance to \( \overrightarrow {{r_{1} }} \) and \( \overrightarrow {{r_{2} }} \) as Eqs. (8) and (9).
In a wide search area, the optimum location of the prey is a toughest exercise to be performed. α, β and δ will assume the prey’s location by the nature capabilities and could be modelled as the following [21].
The final position of the search agents is according to α, β and δ. The position would be within the search area. The ω will re-new their location in random accordance to the location of the target which have been estimated by α, β and δ.
Only when the prey stop moving, the wolves will attack and it stop the hunting process. As the wolves are forthcoming the prey, the value of \( \overrightarrow {a} \) is decreased. The decreasing of value \( \overrightarrow {a} \) will give impact to value of \( \overrightarrow {A} \) between (−2a, 2a). The wolves are attacking the target if \( \left| A \right| < 1 \) and back-off when \( \left| A \right| > 1 \). For the next iteration, the process will be repeated until it is terminated by the satisfied criterion.
3.2 Ant Lion Optimization (ALO)
The method of ALO is based on the relation in between ants and antlions during hunting [22]. In nature, ants move randomly over the search area when searching for food. It could be mathematically described as below
t and T indicate the iteration (random pace) and maximum iteration numbers respectively. cumsum computes the sum of cumulative, r(t) indicates the function expressed like the following
r indicates a random number within [0, 1]. The ants’ locations are saved in matrix form as below [22]:
where MAnt shows the position matrix for each ant. Respectively, parameters n is ants’ quantity and d is dimension number. Ai,j means the j-th variable value of i-th agent. During optimization, a target function is used to evaluate the qualification of every ant and the values are arrange as below [22].
where MQA represent the arrangement of fitness of every ant. f indicates the objective function, n indicates the ants’ number whereas d indicates the variables and Ai,j indicates j-th arrangements of i-th ant. In addition, antlions are also hiding in traps within the area which the locations and qualifications values can be saved in the matrices as following:
where MAntlion shows the position arrangement for each antlion. n shows the antlions and d is the rrangement. Ai,j denotes the j-th variable of i-th antlion.
MQAL demonstrates the arrangement for saving the qualification of every antlion. Variables n and d indicate the number of antlions and dimension, respectively. Ai,j signifies the j-th of i-th antlion and f represents objective function. Furthermore, ants will update their positions during each optimization. The random walk of agents within the boundary is modelled as as follows [22].
ai represents the least pace of variable i. Parameters ci is minimum variables and di is maximum variables for i-th agents. On the other hand, variables \( c_{i}^{t} \) is minimum and \( d_{i}^{t} \) is maximum variable at the iteration t.
The antlions’ effect on random walk of ants is mathematically formulated as below [22].
\( Antliont_{j}^{t} \) represents the location of the certain j-th antlion. Parameters \( c^{t} \) and \( d^{t} \) indicate the maximum and minimum of t-th iteration’s variables respectively. Moreover, vectors d and c defined that ants are moving around designated antlion as hyper sphere.
In ALO, ants are captured by selected single antlion. Thus, ALO approach implemented roulette wheel operator to select the antlions upon their ability the process of optimization. This process can be mathematically described as follows where the radius of hyper sphere is decreased adaptively [22].
where I, the percentage. \( I = 10^{W} \frac{t}{T} \). T and t are the maximum and present iteration, correspondingly. Constant w defined the exploitation level accuracy.
Finally, the prey becomes fitter than its respective predator when the ant is being caught by antlion in the trap. The antlion will consequently re-new its location to where the hunted ant located to improve the possibility to get new prey. The formula described as follows [22].
\( Ant_{i}^{t} \) and \( Ant_{j}^{t} \) represent the location at t-th iteration for designated i-th and j-th ant, respectively. In addition, at t-th iteration \( Antlion_{j}^{t} \) denotes the location of the designated j-th antlion.
Elitism is a vital behaviour that helps ALO algorithm to maintain the best results attained for each optimization process. The fittest antlion is known as the elite. The movements of the ants are effected by the elite. Hence, all the ants walk randomly within the designated antlion [22].
At t-th iteration, \( R_{A}^{t} \) and \( R_{E}^{t} \) are the walk randomly within the selected antlion by the roulette wheel and the elite, respectively. Besides, at t-th iteration, \( Ant_{j}^{t} \) is the location of the i-th ant.
The flow chart of OCR coordination using GWO and ALO as in Fig. 1

OCR coordination flow chart using GWO and ALO
4 Simulation Results
The implementation of the GWO and ALO algorithms have been implemented on i5-6200U core intel CPU, 8 GB 2.3 GHz RAM using MATLAB software. The algorithms have been verified on different IEEE 3-bus and IEEE 8-bus systems to identify the optimal objective function. Normal inverse characteristic curve is implemented to both test cases where with k = 0.14 and α = 0.02. The values of constant are accordance to standard of IEC [23].
4.1 Case I
The system is supplied by three generators and consists of three busbar (B1, B2 and B3), six overcurrent relay (R1, R2, … R6) and three ring lines with 69 kV. The test case details could be retrieved in [5]. The Ip parameter varies from 1.5 to 5 [24] and TDS parameter varies from 0.1 to 1.1 s [18, 24] and. The 0.3 s of CTI value of is implemented. The results are exhibited with discrete Ip and continuous TDS models. The no. of iteration used is 1000 with 30 search agents.
The optimized results of GWO and ALO are presented as Table 1. It could be highlighted that the GWO accomplishes better results with 0.0036 s better than ALO. This shows that GWO presents better than ALO to accomplish optimal value of TDS and Ip.
4.2 Case II
The system connect six busbars (B1, B2 … B6) and 14 overcurrent relays (R1, R2,… R14), that consists of seven ring lines as in Fig. 2. The Ip parameter bound in between 1.5 and 5 whereas TDS parameter bounds in between 0.1 and 1.1 s. The system can be retrieved from [14]. The results of GWO and ALO as in Table 2.

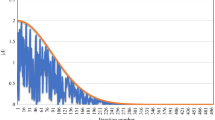
ALO versus GWO results for 1000 iteration
The simulation results obtained shows that GWO has decreases the relays’ operational time for about around 0.5104 s as compared to ALO algorithm (Fig. 3).

IEEE 8 bus system [14]
5 Conclusion
This paper simulates the performances of two metaheuristic approaches known as GWO and ALO to solve the OCR coordination problem. Both approaches have been executed with similar initial condition, characteristic curve and parameter model to two systems with different sizes. It could be highlighted that GWO approach generates the minimized relays’s operating time. As the conclusion, GWO is considered the best approach to solve the OCR coordination problem.
References
Damborg MJ et al (1984) Computer aided transmission protection system design part I: alcorithms. IEEE Trans Power Apparatus Syst PAS-103(1):51–59
Mansour MM, Mekhamer SF, El-Kharbawe N (2007) A modified particle swarm optimizer for the coordination of directional overcurrent relays. IEEE Trans Power Deliv 22(3):1400–1410
Urdaneta AJ et al (1996) Coordination of directional overcurrent relay timing using linear programming. IEEE Trans Power Deliv 11(1):122–129
Abdelaziz AY et al (2002) An adaptive protection scheme for optimal coordination of overcurrent relays. Electr Power Syst Res 61(1):1–9
Urdaneta AJ, Nadira R, Perez Jimenez LG (1988) Optimal coordination of directional overcurrent relays in interconnected power systems. IEEE Trans Power Deliv 3(3):903–911
Birla D, Maheshwari RP, Gupta HO (2006) A new nonlinear directional overcurrent relay coordination technique, and banes and boons of near-end faults based approach. IEEE Trans Power Deliv 21(3):1176–1182
Cheng-Hung L, Chao-Rong C (2007) Using genetic algorithm for overcurrent relay coordination in industrial power system. In: International conference on intelligent systems applications to power systems, 2007. ISAP 2007
So CW et al (1997) Application of genetic algorithm for overcurrent relay coordination. In: Sixth international conference on developments in power system protection (Conf. Publ. No. 434)
So CW et al (1997) Application of genetic algorithm to overcurrent relay grading coordination. in Advances in Power System Control, Operation and Management, 1997. APSCOM-97. In: Fourth international conference on (Conf. Publ. No. 450)
Razavi F et al (2008) A new comprehensive genetic algorithm method for optimal overcurrent relays coordination. Electr Power Syst Res 78(4):713–720
Bedekar PP, Bhide SR (2011) Optimum coordination of overcurrent relay timing using continuous genetic algorithm. Expert Syst Appl 38(9):11286–11292
Bansal JC, Deep K (2008) Optimization of directional overcurrent relay times by particle swarm optimization. In: Swarm intelligence symposium, 2008. SIS 2008. IEEE
Moravej Z, Jazaeri M, Gholamzadeh M (2012) Optimal coordination of distance and over-current relays in series compensated systems based on MAPSO. Energy Convers Manag 56:140–151
Zeineldin HH, El-Saadany EF, Salama MMA (2006) Optimal coordination of overcurrent relays using a modified particle swarm optimization. Electr Power Syst Res 76(11):988–995
Ahmarinejad A et al (2016) Optimal overcurrent relays coordination in microgrid using cuckoo algorithm. Energy Procedia 100:280–286
Sueiro JA et al (2012) Coordination of directional overcurrent relay using evolutionary algorithm and linear programming. Int J Electr Power Energy Syst 42(1):299–305
Papaspiliotopoulos VA, Kurashvili TA, Korres GN (2014) Optimal coordination of directional overcurrent relays in distribution systems with distributed generation based on a hybrid PSO-LP algorithm. In: MedPower 2014
Noghabi AS, Sadeh J, Mashhadi HR (2009) Considering different network topologies in optimal overcurrent relay coordination using a hybrid GA. IEEE Trans Power Delivery 24(4):1857–1863
Chunlin X et al (2008) Optimal coordination of protection relays using new hybrid evolutionary algorithm. in Evolutionary Computation, 2008. CEC 2008. (IEEE World Congress on Computational Intelligence). IEEE Congress on. 2008
Wolpert DH, Macready WG (1997) No free lunch theorems for optimization. IEEE Trans Evol Comput 1(1):67–82
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey Wolf optimizer. Adv Eng Softw 69:46–61
Mirjalili S (2015) The Ant Lion Optimizer. Adv Eng Softw 83:80–98
IEC (1976) Single input energizing measuring relays with dependent specified time In: IEC standard 60255–4. IEC publication
Amraee T (2012) Coordination of directional overcurrent relays using seeker algorithm. IEEE Trans Power Delivery 27(3):1415–1422
Funding
This research is supported under grant RDU1703284 by Universiti Malaysia Pahang (UMP).
Conflict of Interest
The authors declared, they have no conflict with the others research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Jamal, N.Z., Sulaiman, M.H., Nasir, A. (2020). Metaheuristic Optimization Approaches for Overcurrent Relays Discrimination: A Comparative Study. In: Mohd Razman, M., Mat Jizat, J., Mat Yahya, N., Myung, H., Zainal Abidin, A., Abdul Karim, M. (eds) Embracing Industry 4.0. Lecture Notes in Electrical Engineering, vol 678. Springer, Singapore. https://doi.org/10.1007/978-981-15-6025-5_14
Download citation
DOI: https://doi.org/10.1007/978-981-15-6025-5_14
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-6024-8
Online ISBN: 978-981-15-6025-5
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)