
Abstract
Medicinal plants are the backbone of the system of medicines; they are the richest bioresource of drugs of traditional systems of medicine, modern medicines, nutraceuticals, food supplements, folk medicines, pharmaceutical intermediates, and chemical entities for synthetic drugs. These plants are classified according to their medicinal values. Classification of medicinal plants is acknowledged as a significant activity in the production of medicines along with the knowledge of its use in the medicinal industry. Medicinal plant classification based on parts such as leaves has shown significant results. An automated system for the identification of medicinal plants from leaves using Image processing and Machine Learning techniques has been presented. This paper provides knowledge of the process of identification of medicinal plants from features extracted from the images of leaves and different preprocessing techniques used for feature extraction from a leaf. Many features were extracted from each leaf such as its length, width, perimeter, area, color, rectangularity, and circularity. It is expected that for the automatic identification of medicinal plants, a web-based or mobile computer system will help the community people to develop their knowledge on medicinal plants, help taxonomists to develop more efficient species identification techniques and also participate significantly in the pharmaceutical drug manufacturing.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Medicinal plants have long been utilized in traditional medicine. Identification of medicinal plants is a very challenging task without external resources or assistance. Identification of the right medicinal plants that are used for the preparation of medicines is important in the medicinal industry. In various countries, there is a trend toward using traditional plant-based medicines alongside pharmaceutical drugs. Therefore, there seems to be immense potential in this field. Various kinds of algorithms are integrated into the application software. Image analysis is one important method that helps segment image into objects and background [1]. One of the key steps in image analysis is feature detection. Transforming the input data into the set of features is called feature extraction. The image processing nowadays have become the key technique for the diagnosis of various features of the plant [1].
The non-automatic method is based on morphological characteristics. Thus, classification here is based on the core knowledge of botanists. However, this non-automatic identification is tedious. Hence many researchers support this automated classification system and identification. There are a few systems developed so far where most of the processes are the same.
Following are the steps involved:
-
Step 1: Preparing the dataset.
-
Step 2: Preprocessing.
-
Step 3: Once the preprocessing is done, attributes have to be identified.
-
Step 4: Training.
-
Step 5: Classification of the leaves.
-
Step 6: Result evaluation (Fig. 1).
Fig. 1 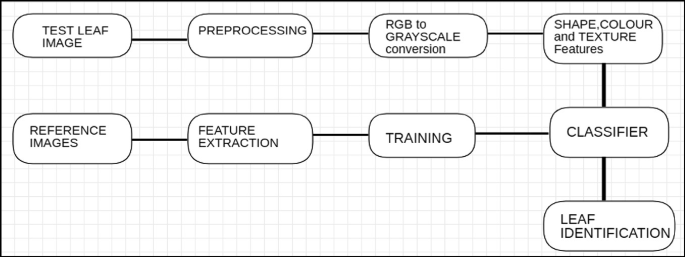
Design of the proposed solution

This is an effective and efficient automated system (Fig. 1) that can be used by any student, pharmacist, or anyone from the non-botanical background. Motivation to undertake this project was given to us by an incident that happened with the head of the ‘National Social Service’ cell. He was trying to figure out a way to identify the medicinal plants correctly so that the villagers could make use of them for their pharmaceutical purposes. Seeing his difficulty gave us an idea of building this system.
2 Literature Review
See Table 1.
3 Methodology
The system will work in four stages:
-
A.
Obtaining dataset.
-
B.
Image segmentation/preprocessing.
-
C.
Feature extraction.
-
D.
Classification algorithm (Fig. 2).
Fig. 2 
Methodology overview

A. Obtaining dataset
Leaves are a feasible means to identify plants [5]. The image dataset used in this paper is Flavia leaves dataset which is obtained from http://flavia.sourceforge.net/. This image dataset consists of approximately 1900 image instances of leaves of 32 different species of plants. Sample images from one class are shown (Fig. 3).

Image dataset
For training and testing the model, a dataset was created using the extracted features of the leaf. The dataset was divided into two sets namely Train set (70%) and Test set (30%).
B. Image segmentation/preprocessing
Pixel values play a very important role in image analysis. They can be used to segment distinct objects. If there’s a significant difference in the contrast values of the object and the image’s background, then the pixel values will also differ. In this case, a threshold value can be set. Accordingly, an object or the background can be classified on the basis of the pixel values being less than or greater than a threshold value. This method is also known as Threshold Segmentation. It converts original image (Fig. 4) to grayscale (Fig. 5). If the image has to be divided into two regions, i.e., object and background, a single threshold value is defined. This is known as the global threshold (Fig. 6). If there are multiple objects along with the background, multiple thresholds need to be calculated. These thresholds are collectively known as the local threshold. This technique is preferred when there is a high contrast between object and background.

Original leaf image

Grayscale image
Two adjacent regions with different grayscale values are always differentiated based on the edge present between them. The discontinuous local features of an image can be considered as the edges. This discontinuity may prove to be helpful in defining a boundary of the object. This helps in discovering multiple objects present in an image along with their shapes. Filter and Convolutions are used in Edge detection. Edge detection is fit for images having better contrast between objects. When there are too many edges in the image and if there is less contrast between objects, it should not be used.
Digital image processing techniques are used for the classification of medicinal plants in the Plant Leaf Identification system. Firstly, all the images are preprocessed, for removing background area [6]. Then their features based on color, texture, and shape [7] are extracted from the processed image. The subsequent steps were followed for preprocessing the image.
-
(1)
In this technique, we convert RGB to a grayscale image.
-
(2)
After conversion, we smoothen the image using a Gaussian filter.
-
(3)
Then Otsu’s thresholding method is used for adaptive image thresholding (Fig. 7).
-
(4)
Morphological Transformation is used for the closing of the holes.
-
(5)
The last step for preprocessing is that the boundary extraction is done using contours.
Fig. 6 
Global threshold
Fig. 7 
Adaptive mean threshold


C. Feature extraction
The major problem in image analysis arises due to the number of variables involved. These variables require a large amount of memory and computation. If the dataset is used as it is, it becomes less instructive and more redundant for doing analysis. When an algorithm has to process large datasets, then by applying this method, the dataset will be reduced to minimum dimensions. Extracting useful features from images in the dataset is the feature extraction process. Various types of leaf features were extracted (Fig. 8) from the preprocessed image which are listed as follows:
-
1.
Features related to shape:
-
Length.
-
Width.
-
Total area.
-
Perimeter.
-
Proportional relationship between width and length (aspect ratio).
-
Rectangularity.
-
Circularity.
-
-
2.
Features related to color:
-
The sum of channels divided by the number of channels of R, G, and B (mean).
-
Amount of variation of a set of values of R, G, and B channels (standard deviations).
-
-
3.
Features related to texture:
-
The difference between the textures (contrast).
-
The similarities between the textures (correlation).
-
Inverse difference.
-
Entropy.
Fig. 8 
Feature set of different leaf samples
-

D. Classifier algorithms
Four machine learning classifier algorithms were applied to the data, which are as follows:
-
1.
KNN (k-Nearest Neighbor) Algorithm.
-
2.
Logistic Regression.
-
3.
Naïve Bayes Algorithm.
-
4.
SVM (Support Vector Machine).
These classifier algorithms were applied to the preprocessed data. The results are shown in Table 2. The Logistic Regression classifier achieves the best performance with an accuracy of 83.04% (Table 2).
However, due to resource constraints, for finding the highest accuracy the important parameters of every classifier were varied. The k-Nearest Neighbor (KNN) classifier gave the best accuracy of 79.49% (Table 3).
Apart from the accuracy, the performance was also assessed on a class proportion of leaves, for each class, that was accurately chosen from the entire set [3]. Precision here is the proportion of precisely identified leaves out of the total leaves that are predicted to be a specific plant while F-measure here is considered as the average of these two values [3].
Table 4 shown gives useful knowledge which can be used to test the strong aspects of the system and address its weaknesses. Plants that have low precision and recall must be reassessed. For example, new features must be designed and extracted that give uniqueness in such leaves and are determinative of their species [3].
In Fig. 9, the confusion matrix is shown which is obtained when using the k-Nearest Neighbor (KNN) classifier with specified attributes in each iteration. The identification was successful which is indicated by the highest values in the diagonal line. Classes ranging from 0 to 31 represent the different 32 species of plants.

Confusion matrix for KNN classifier
4 Conclusion
The main aim of this paper is to identify the medicinal plant from a given sample of a leaf. For this, we proposed an automated system for the identification of species of plants from leaves on the basis of their Color, Shape, and Texture features by using image processing techniques. Accordingly, the features were extracted from the Flavia image dataset, which consists of a total of 1907 images, and machine learning algorithms like SVM, Logistic Regression, Naïve Bayes, and KNN were applied. Accuracies of 82.69%, 83.04%, 72.90%, and 82.99% were observed, respectively. After cross-validation of the extracted features, the accuracies changed to 78.74%, 78.85%, 71.23%, and 79.49%, respectively. As a result, an inference was deduced from the observed accuracies that KNN would be best suited to the proposed solution. This system takes less processing time with increased accuracy for identification.
References
Aitwadkar, P.P, Deshpande, S.C, Savant, A.V.: Identification of Indian medicinal plant by using artificial neural network. Int. Res. J. Eng. Technol (IRJET) 5(4), 1669–1671 (2018)
Jeon, W.-S., Rhee, S.-Y.: Plant leaf recognition using a convolution neural network. Int. J. Fuzzy Logic Intell. Syst. 17(1), 26–34 (2017)
Begue, A., Kowlessur, V., Mahomoodally, F., Singh, U., Pudaruth, S.: Automatic recognition of medicinal plants using machine learning techniques. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 8(4) (2017)
Nijalingappa, P., Madhumathi, V.J.: Plant identification system using its leaf features. In: International Conference on Applied and Theoretical Computing and Communication Technology (iCATccT) (2015)
Khmag, A., Al-Haddad, S.A.R., Kamarudin, N.: Recognition system for leaf images based on its leaf contour and centroid. In: IEEE 15th student conference on research and development (SCOReD) (2017)
Sabu, A., Sreekumar, K., Nair, R.R.: Recognition of ayurvedic medicinal plants from leaves: a computer vision approach. In: Fourth International Conference on Image Information Processing (ICIIP) (2017)
Venkataraman, D., Mangayarkarasi, N.: Computer vision based feature extraction of leaves for identification of medicinal values of plants. IEEE International Conference on Computational Intelligence and Computing Research (2016)
Acknowledgements
The authors would like to extend gratitude toward the faculty guide Dr. Anuradha Thakare and H.O.D Department of Computer Engineering Dr. K. Rajeswari for their constant support and guidance.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Gokhale, A., Babar, S., Gawade, S., Jadhav, S. (2020). Identification of Medicinal Plant Using Image Processing and Machine Learning. In: Iyer, B., Rajurkar, A., Gudivada, V. (eds) Applied Computer Vision and Image Processing. Advances in Intelligent Systems and Computing, vol 1155. Springer, Singapore. https://doi.org/10.1007/978-981-15-4029-5_27
Download citation
DOI: https://doi.org/10.1007/978-981-15-4029-5_27
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-4028-8
Online ISBN: 978-981-15-4029-5
eBook Packages: EngineeringEngineering (R0)