
Abstract
The automatic identification of language from voice clips is known as automatic language identification. It is very important for a multi lingual country like India where people use more than a single language while talking making speech recognition challenging. An automatic language identifier can help to invoke the language specific speech recognizers making voice interactive systems more user friendly and simplifying their implementation. Phonemes are unique atomic sounds which are combined to constitute the words of a language. In this paper, the performance of different classifiers is presented for the task of phoneme recognition to aid in automatic language identification as well as speech recognition. We have used Mel Frequency Cepstral Coefficient (MFCC) based features to characterize Bangla Swarabarna phonemes and obtained an accuracy of 98.17% on a database of 3710 utterances by 53 speakers.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Speech recognition based applications have developed significantly over the years facilitating the lives of the commoners. Though devices and applications have become more user friendly, residents of different multi-lingual countries like India have not been fully able to take advantage of them. They often use multiple languages while talking (which is perhaps one of the reasons for the limited success of speech recognizers) in addition to the complexity of the Indic languages. A system which can determine the spoken language from voice signals can help in recognizing multilingual speech by helping to invoke language specific recognizers; this task of automatically determining the language from voice signals is termed as automatic language identification.
Every language has atomic and unique sounds known as phonemes; these phonemes are used in different combinations for constituting the words of that language. Identification of phonemes from voice signals can aid in language identification as presented in [1, 3]. Vowel phonemes are an important aspect of a language playing a major role in the constitution of most of the words in it. Distinguishing phonemes of a single language is a crucial task prior to applying it in a multilingual scenario; it can also help in recognizing words and phrases from audio.
Hasanat et al. [5] distinguished Bangla phonemes with 13 reflection coefficients and autocorrelations; they used an Euclidean distance based technique for the classification of unknown phonemes obtaining an accuracy of 80%. Hybrid features were used by Kotwal et al. [7] for the classification of Bangla phonemes; they used a HMM based approach and obtained an accuracy of 58.53% when using train and test sets of 3000 and 1000 sentences, respectively. Hossain et al. [9] obtained accuracies of 93.66%, 93.33% and 92% with the help of Euclidean distance, hamming distance and artificial neural network, respectively, for classifying 10 phonemes out of which 6 were vowels and 4 were consonants. They used MFCC features in their experiments and tested their system on a database of 300 phonemes.
Zissman et al. [1] used a different approaches for language identification including a phoneme based approach and n-gram modelling. They experimented with the OGI multiple language telephonic speech corpus [2] and obtained an accuracy of 79.2% for 10 languages. They also carried out different experiments with 2 language closed sets like English-Japanese, Japanese-Spanish and English-Spanish which are detailed in [1]. Furthermore, Zissman [3] attempted at language identification with the help of phoneme recognition coupled with phonotactic language modelling obtaining accuracies of 89% and 98% for 11 languages and two language sets, respectively, from the OGI multi lingual telephonic speech corpus. Mohanty [6] used manner and place features coupled with a SVM based classifier for the task of language identification; experiments were performed for 4 different languages namely Hindi, Bangla, Oriya and Telugu on 500 words/language corpora producing an average word level accuracy of 89.75%.
Lamel et al. [8] performed different cross lingual experiments involving phone recognition; they obtained accuracies of 99% for language identification on clips of 2 s and 100% for sex as well as speaker identification. They had also obtained accuracies of 98.2% and 99.1% for speaker identification on the TIMIT and BREF datasets respectively with a single utterance per speaker. Koolagudi et al. [10] distinguished 15 different Indic languages with MFCC features and Gaussian Mixture Model; they used 300, 90 and 2 s of data per language for training, testing and validation respectively and obtained an accuracy of 88%. Berkling et al. [11] and Muthusamy et al. [12] have also employed and discussed different aspects of phoneme based techniques for language identification.
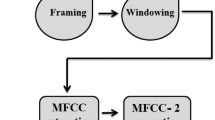
Bangla is not only one of the official languages of our country - India but also of our state - West Bengal. Moreover, based on the number of speakers, it is also among the top 3 and top 6 in India and the world respectively [4]. These factors inspired us to work with the same. In this paper, the performance of different classifiers for the task of Bangla vowel/swarabarna phonemes identification is presented. The adopted methodology is presented in Fig. 1. The clips were first pre processed and then subjected to feature extraction. The feature sets were then reduced using PCA. Both the reduced and non reduced feature sets were individually fed to different classifiers for performance analysis. The details of these steps is presented in the subsequent paragraphs. The remainder of the paper is organized as follows: Sect. 2 describes the datasets while Sect. 3 describes proposed methodology; the results are presented in Sect. 4 and the conclusion in Sect. 5.

Methodology of the proposed work.
2 Dataset
The quality of data is vital in an experiment. It needs to be ensured that inconsistencies are avoided during the data collection phase. We collected a dataset of Bangla swarabarna/vowel phonemes from 53 volunteers aged between 20–30 of whom 32 were male and 21 were female as we could not find any standard Bangla phoneme dataset available freely for research. The speakers uttered the 7 vowel phonemes (shown in Table 1) in one take; each of the volunteers repeated this 10 times. The 7 phonemes were recorded in a single take from the speakers in every iteration in order to get real life data as in terms of gushes of breath on the microphone, linked utterances, etc. The collected database of 3710 (10*7*53) phonemes were then segregated with a semi-supervised amplitude based technique.
Different local microphones were used for recording, including Frontech JIL-3442, to get variations as the microphones have disparate sensitivities helping to uphold real world characteristics; with the same purpose, the distance and angle of the microphones from the speakers were also varied in addition to different ambiences. The data was recorded in stereo mode with Audacity [13] in .wav format at a bitrate of 1411 kbps. Figure 2 present the waveform representation of a single channel clip of the 7 phonemes.

Single channel waveform representation of the 7 phonemes.
3 Methodology
In the following sub-sections, the signal pre-processing (framing and windowing) and feature extraction are presented along with an introduction of the classification algorithms used.
3.1 Pre-processing
Framing. The spectral characteristics of an audio clip tend to show a lot of deviation through the entire length which complicates the task of analysis. In order to cope up with this, a clip is broken down into smaller parts termed as frames which ensures that the spectral characteristics are quasi stationary within each of such frames. As presented in Eq. (1), a clip having T samples can be subdivided into M frames, each of size G having O overlapping points.
In the present experiments, the frame size was chosen to be of 256 points and the overlap factor to be of 100 sample points in accordance with [14].
Windowing. The sample points at the start and end of a frame might not be aligned thereby disrupting the intra-frame continuity. These jitters interfere with the Fourier transformation for the spectrum based analysis in the form of spectral leakage. To tackle this problem, every frame is windowed. In our experiment, the hamming window was chosen in accordance with [14]. The hamming window A(n) is mathematically illustrated in Eq. (2) where, n ranges from start to end of a frame of size N.
3.2 Feature Extraction
Due to its utility as presented in [15], 19 standard MFCC features per frame were extracted for each clip. Since the phoneme recordings were of disparate lengths, different number of frames were obtained producing features of different dimensions. In order to make the feature dimension constant, the global highest and lowest of the MFCC values were used to define 18 equally spaced classes; the number of classes was set to 18 in accordance with [14]. Next, the occurrence of energy values in each of such classes was recorded; this was repeated for each of the 19 bands producing a dataset where each example is represented by 342 features.
In addition to this, the MFCC bands were also ordered in a descending manner using the band wise energy content and this sequence was added to the feature vector, producing a feature vector of 361 values. It was also observed that there were some classes (feature values) which did not have any energy value distributions; such feature values were identified to have similar values for all phoneme instances and were removed, ultimately producing a feature vector of 147 dimensions.
In order to observe the recognition performance using reduced features, the final feature vector was subjected to principal component analysis (PCA) following the work presented in [16]. This procedure produced a feature vector of 95 dimensions. The visual representation of the features for 7 phoneme classes for pre- and post-PCA reduction are presented in Figs. 3 and 4, respectively.

Non reduced features for the 7 phonemes.

PCA reduced features for the 7 phonemes.
3.3 Classification
Both the PCA reduced and non reduced feature sets were fed into various popular classifiers in pattern recognition problems. They were: Support Vector Machine (SVM), Random Forest (RF), Multi Layer Perceptron (MLP), BayesNet (BN) and Simple Logistic (SL). These algorithms are briefly outlined below.
SVM. It is a supervised learner which is used for classification as well as regression analysis. It generates an optimal hyperplane from a set of labelled instances provided at training time; for a 2D space, it finds a line which differentiates the instances based on their associated labels.
Random Forest. It is an ensemble learning based classifier which works with decision trees during training. It classifies an instance using the mode of the output of the individual decision trees.
MLP. It is a neural network based classifier which tries to mimic the human nervous system. It maps an input set to an output set and consists of nodes that are joined by means of links having different weights. It is one of the most popular classifiers in pattern recognition problems.
BayesNet. It is a bayesian classifier which uses a Bayes Network for learning by employing different quality parameters and search algorithms. Data structures consisting of conditional probability distributions, structure of network, etc. are provided by the base class.
Simple Logistic. It is used to build linear logistic regression models. The classifier uses LogitBoost as base learner and the number of iterations is further cross validated helping to select the attributes automatically.
4 Result and Discussion
For the experiments, Weka [16], which is considered to be an extremely popular open source classification tool, was used in applying the mentioned classifiers with their default parameters. For the evaluation, a 5 fold cross-validation procedure was chosen.
4.1 Results
The obtained results are tabulated in Table 2. It is seen that the accuracy for the non reduced features is higher in comparison to PCA for all classifiers. In the case of the non reduced sets the best performance was obtained with Random Forest while the worst was obtained using BayesNet; MLP, simple logistic and SVM obtained 2\(^{nd}\), 3\(^{rd}\) and 4\(^{th}\) ranks respectively. The ranks of the classifiers varied in the case of the PCA reduced set; similar to the non reduced set, BayesNet performed the worst; however, MLP generated the best result followed by Random Forest, SVM and simple logistic.
Since Random Forest produced the overall highest result using the non reduced feature set, we further fined tuned this algorithm’s parameters.
First different number of cross validation folds were tested. The results are shown in Table 3 and it is seen that the highest accuracy was attained for both 15 as well as 20 cross-validation folds.
The number of training iterations using the default number of cross validation folds (5 in our experiment) was also tested, ranging from 100 to 500 iterations. The results are tabulated in Table 4 and it is observed that the highest accuracy (97.87%) was attained for 300 iterations.
Finally, for 15 folds of cross validation (chosen to be the best, even though the 20 folds also produced the same highest accuracy), a varying number of iterations was also tested. The obtained results are shown in Table 5 where it can be seen that an accuracy of 98.17% (highest) was attained for 400 training iterations, which is also the highest value obtained from all the experiments.
For this highest performing configuration, the confusion percentage among different phoneme pairs are presented in Table 6.
The ‘u-o’ phoneme pair created a total confusion of 9.05% (3.58 + 5.47), which is the highest in our experiment. One of the primary reasons for this result is that these 2 phonemes sound very close when pronounced separately and even closer when pronounced at a stretch. The same issue was observed during the data collection phase as well. The phoneme pair
 produced the next highest confusion with a value of 2.26%. It was observed that different speakers had extremely close pronunciations for these two phonemes which led to this confusion.
produced the next highest confusion with a value of 2.26%. It was observed that different speakers had extremely close pronunciations for these two phonemes which led to this confusion.
4.2 Statistical Significance Test
The non parametric Friedman test [17] was carried out on the non reduced dataset for checking the statistical significance. We divided the dataset into 5 parts (N) and used all the 5 classifiers (k) in the test. The obtained ranks and accuracies is presented in Table 7.
The Friedman statistic (\(\chi ^2_F\)) [17] was calculated using these results with the help of Eq. (3), where \(R_j\) is the mean rank of the \(j^{th}\) classifier.
The critical values at significance levels of 0.05 and 0.10 for the mentioned setup were found to be 9.448 and 7.779; we obtained a value of 11.96 for (\(\chi ^2_F\)) thereby rejecting the Null hypothesis, and demonstrating statistical significance.
5 Conclusion
The performance of different classifiers in the task of Bangla swarabarna phoneme identification is presented here; this can aid in language identification as well as speech recognition. Among different classifiers, the highest accuracy was obtained using Random Forest which demonstrated an average precision of 0.982.
In the future, we will experiment with other features in order to reduce the confusion between different phoneme pairs. We also plan to use other machine learning techniques like deep learning based approaches to obtain better results. Experiments will not only be performed on a larger Bangla phoneme dataset but also the same will be extended to other languages. The same will also be carried out by incorporating artificial noise in the datasets to make the system more robust. Experiments will also be done by integrating the phoneme identifier with a speech recognizer to observe both speech as well as language identification in real time.
References
Zissman, M.A., Singer, E.: Automatic language identification of telephone speech messages using phoneme recognition and n-gram modeling. In: Proceedings of ICASSP-94., vol. 1, p. I-305. IEEE (1994)
Muthusamy, Y.K., Cole, R.A., Oshika, B.T.: The OGI multi-language telephone speech corpus. In: Proceedings of ICSLP-92, pp. 895–898 (1992)
Zissman, M.A.: Language identification using phoneme recognition and phonotactic language modeling. In: Proceedings of ICASSP-95., vol. 5, pp. 3503–3506. IEEE (1995)
https://www.ethnologue.com/. Accessed 25 Mar 2018
Hasanat, A., Karim, M.R., Rahman, M.S., Iqbal, M.Z.: Recognition of spoken letters in Bangla. In: Proceedings of ICCIT (2002)
Mohanty, S.: Phonotactic model for spoken language identification in indian language perspective. Int. J. Comput. Appl. 19(9), 18–24 (2011)
Kotwal, M.R.A., Hossain, Md.S., Hassan, F., Muhammad, G., Huda, M.N., Rahman, C.M.: Bangla phoneme recognition using hybrid features. In: Proceedings of ICECE (2010)
Lamel, L.F., Gauvain, J.L.: Cross-lingual experiments with phone recognition. In: Proceedings of ICASSP-93., vol. 2, pp. 507–510. IEEE (1993)
Hossain, K.K., Hossain, Md.J., Ferdousi, A., Khan, Md.F.: Comparative study of recognition tools as back-ends for Bangla phoneme recognition. Int. J. Res. Comput. Appl. Robot. 2(12), 36–40 (2014)
Koolagudi, S.G., Rastogi, D., Rao, K.S.: Identification of language using mel-frequency cepstral coefficients (MFCC). Procedia Eng. 38, 3391–3398 (2012)
Berkling, K.M., Arai, T., Barnard, E.: Analysis of phoneme-based features for language identification. In: Proceedings of ICASSP-94., vol. 1, p. I-289. IEEE (1994)
Muthusamy, Y., Berkling, K., Arai, T., Cole, R., Barnard, E.: A comparison of approaches to automatic language identification using telephone speech. In: Proceedings of Eurospeech-93, pp. 1317–1310 (1993)
http://www.audacityteam.org/. Accessed 25 Mar 2018
Mukherjee, H., Dhar, A., Phadikar, S., Roy, K.: RECAL-A language identification system. In: Proceedings of ICSPC, pp. 300–304. IEEE (2017)
Mukherjee, H., Obaidullah, S.M., Phadikar, S., Roy, K.: SMIL - a musical instrument identification system. In: Mandal, J.K., Dutta, P., Mukhopadhyay, S. (eds.) CICBA 2017. CCIS, vol. 775, pp. 129–140. Springer, Singapore (2017). https://doi.org/10.1007/978-981-10-6427-2_11
Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.H.: The WEKA data mining software: an update. ACM SIGKDD Explor. Newsl. 11(1), 10–18 (2009)
Dems̆ar, J.: Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 7, 1–30 (2006)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Mukherjee, H. et al. (2019). Performance of Classifiers on MFCC-Based Phoneme Recognition for Language Identification. In: Mandal, J., Mukhopadhyay, S., Dutta, P., Dasgupta, K. (eds) Computational Intelligence, Communications, and Business Analytics. CICBA 2018. Communications in Computer and Information Science, vol 1030. Springer, Singapore. https://doi.org/10.1007/978-981-13-8578-0_2
Download citation
DOI: https://doi.org/10.1007/978-981-13-8578-0_2
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-8577-3
Online ISBN: 978-981-13-8578-0
eBook Packages: Computer ScienceComputer Science (R0)