
Abstract
Recently, recommender systems have been popularly used to handle massive data collected from applications such as movies, music, news, books, and research articles in a very efficient way. In practice, users generally prefer to take other people’s opinions before buying or using any product. A rating is a numerical ranking of items based on a parallel estimation of their quality, standards, and performance. Ratings do not elaborate many things about the product. On the contrary, reviews are formal text evaluation of products where reviewers freely mention pros and cons. Reviews are more important as they provide insight and help in making informed decisions. Today the internet works as an exceptional originator of consumer reviews. The amount of opinionated data is increasing speedily, which is making it impractical for users to read all reviews to come to a conclusion. The proposed approach uses opinion mining which analyzes reviews and extracts different products features. Every user does not have the same preference for every feature. Some users prefer one feature, while some go for other features of the product. The proposed approach finds users’ inclination toward different features of products and based on that analysis it recommends products to users.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In today’s data rich era, new information is added at faster speed compared to the rate at which that data is being used by users to gain some valuable information. The difference between these speeds can be fixed by recommender systems (RS). RS mainly suggest items to an individual based on his past actions like, ratings given to different items, search history and similar users’ activities [1].
Most common RS techniques are content-based filtering and collaborative filtering [2]. Content-based filtering, also known as cognitive filtering, works by comparing the content descriptions of items with the user profiles. User profiles have information about users and their taste. The technology behind Netflix and Pandora is content-based filtering [2]. On the other hand, the process of refining or evaluating products using the judgement of other people is known as collaborative filtering (CF). In recommender systems, collaborative filtering ages not more than a decade, but its basics are very old, have been used socially, i.e., sharing opinions. Last.fm recommendation engine uses collaborative filtering [3].
Before emergence of World Wide Web, we generally used to ask our neighbors, friends or specialists to be sure about any product before purchasing it [4]. Now in modern era, whenever a user wants to ask anything he asks cyber world. In today’s world market, users have great choice among different products to consume, according to needs and interests. Reviews and ratings, available on Internet, are best way to come across other’s opinion [5]. Using people’s opinions about different items, RS helps target user to make mindset about different merchandises.
Ratings are always a numerical value defined in some certain fixed bounds. Usually lower ratings imply that product is not good enough but it doesn’t mean that there is nothing good in that product, and it is not possible to mention this via ratings. Ratings supply a generalized summary about product. Reviews are texted opinions, having all positives and negatives about products. Reviews provide constructive criticism about products which helps consumers as well as manufacturers.
Generally, reviews are about different aspects or features of products [6]. Aspects are characteristics of the product. Few aspects are more promising than others and have great projection on decision making. It is perplexing to find aspects that are better in a particular product from reviews. The user opinionated data present on Internet are increasing massively. Users often have no choice, but to browse massive texts to find interesting information. Browsing them requires a lot of time and energy. However, investing that much time and efforts does not guarantee that one can get correct knowledge about products [7].
An automated system is required to address this problem so that knowledge can be withdrawn from that data. This paper presents an approach to manage this problem. The proposed approach recommends items based on features user is interested in, by combining collaborative filtering, opinion mining and SentiWordNet. The proposed method not only finds different features of products but also features in which user is interested, based on his past reviews. The proposed approach uses aspect-based opinion mining to find primary features of an item and then predicts score of those features from product reviews. Natural language processing is used to extract features using Part-Of-Speech (POS) tagging. This approach calculates score of these features using a lexical resource, i.e., SentiWordNet. These calculated scores along with information of similar users and features target user has liked are then used to recommend most probable items.
The remaining paper is structured as follows: Sect. 2 describes background knowledge and related work. Our approach, flow diagram and its details are described in Sect. 3. The practical implementation of proposed approach is defined in Sect. 4. Finally, Sect. 5 concludes the paper.
2 Background Knowledge and Related Work
2.1 Opinion Mining
Web 2.0 has given opportunity to people to write their experiences about various products, services and other things in the form of reviews at e-commerce sites, forums, blogs, etc. [8]. Now Web is full of opinionated text. However, this large amount of text has made it very challenging to extract useful data easily. Surveying these many reviews will confuse users about product as well as wastes their time. This requires a technique which can analyze these reviews and provide fruitful knowledge to users. The technique used is opinion mining.
The science of analyzing and extracting valuable information from text data is known as opinion mining. Opinion mining is a mixture of information retrieval and computational linguistics which is bothered not with the title of text, but with the opinions it conveys [9]. Generally, to perform opinion mining it is required to design automated systems using machine learning, artificial intelligence, data mining and natural language processing techniques [10]. These systems can collect and classify opinions about product available in opinionated data.
Sometimes opinion mining also referred as sentiment analysis, but sentiment analysis is different. Sentiment is defined as an attitude, thought or judgment prompted by feeling [11], whereas opinion is defined as a view, judgment formed in the mind about a particular matter [8]. The definitions indicate that an opinion is more of a person’s view about something, whereas a sentiment is more of a feeling. However, in most cases opinions imply positive or negative sentiments. Sentiment analysis and opinion mining are almost same thing; however, there is minor difference between them that is opinion mining extracts and analyzes people’s opinion about an entity, while sentiment analysis searches for the sentiment words/expression in a text and then analyzes it [12].
Opinion mining is useful in multiple ways for consumers as well as manufacturers [13]. Customers can make up their mind about a product that whether they should buy it or not. They get to know about pros and cons of product. Similarly, manufacturers evaluate their products using opinion mining of public reviews. Features which require modifications or improvements can easily be identified by makers using opinion mining. This helps in deciding features, products and services which are liked or disliked in a particular region. It helps businesses finding reasons behind low sales and possible solutions based on people’s views [10]. Companies can anticipate market trends by tracking consumer views.
According to Pang and Lee [10], there are three major areas of opinion mining which are identification of sentiment polarity, detection of subjectivity and joint topic-sentiment analysis. Similarly, Liu [13] in his book narrates three different mining assignments. Later, he expands his grouping in his handbook [14] as sentiment and subjectivity classification, aspect-based opinion mining, sentiment analysis of comparative sentences, opinion search and retrieval and spam opinion discovery. Lastly, in his latest book [9] he specifies three generic categories of opinionated text mining as document-level, sentence-level, and phrase-level opinion mining.
In [5], authors have found semantic orientation of reviews to classify them using pointwise mutual information between bigrams and seed words. In [15], author’s approach uses Naïve Bayes classification method to classify customer reviews. Limitation of this work is having incomplete training dataset and attribute independence.
2.2 Aspect-Based Opinion Mining
In some cases, document-level opinion mining or sentence-level opinion mining are fruitful, but when it is used in conclusive process, then these levels of information are not enough [8]. For example, a positive review of a product does not denote that reviewer is delighted with each and every aspect of the product. In the same way, a negative review does not say that reviewer has objection for every aspect. Typically, the reviewer mentions both positive and negative sides of item, still his broader viewpoint may be positive or negative. Indeed, document-level and sentence-level mining cannot produce detailed decisive data. So, it is required to grind opinions in-depth. In-depth excavating of reviews is aspect-based opinion mining [9]. Phrase-level mining aids in uncovering numerous features of various product from reviews.
Two main aims are there in the problem of aspect-based opinion mining: first is aspect extraction and other one is rating prediction. Bing Liu in his book [9] divided aspect extraction method into four categories: finding frequent nouns and noun phrases, using opinion and target relations, using supervised learning and using topic models. In [11] aspect-based opinion mining, approaches have been categorized into frequency-based, relation-based, and model-based types.
Most frequent aspects of product which have been discussed by many people in their reviews are recognized in frequency-based methods. Popescu and Etzioni [16] has designed an unsupervised knowledge extraction system called OPINE which mines reviews to select substantial product features. It counts the frequency of each noun and keeps only them which have value greater than the threshold. All these noun phrases now judged by calculating the pointwise mutual information between the phrase and associated discriminators. Hu and Liu [17] extracted frequent features from reviews using part-of-speech tagging. Scanffidi et al. [18] in their work compares the repetition of derived words with occurrence rate of these words.
Relation-based techniques find the correlation between the words and sentiments to identify aspects. In this type of methods, generally part-of-speech tagging is used to find aspects. Liu et al. [19] presented “opinion observer,” for the visual comparison of customer reviews. It is used only for short comments. A supervised algorithm is used for feature extraction. Initially a training dataset is tagged using a POS tagger. Now actual aspects are manually identified in training dataset and replaced by a specific tag. Afterward, association rule is used to find POS patterns which are probable features. All of the derived patterns are not valuable, and some constraints are used to discard less important phrases.
In model-based methods, models are designed to pull out features. Hidden Markov model (HMM) and conditional random field (CRF) are most frequently used mathematical models based on supervised learning, and unsupervised topic modeling methodologies are probabilistic latent semantic indexing (PLSI) and latent Dirichlet allocation (LDA) [10]. Jin et al. [20] presented the model “Opinion Miner” based on HMM to find features, opinions and their polarities. The EnsembleTextHMM, a new supervised sentiment analysis using an ensemble of text-based hidden Markov models, method has been presented in [21].
An ontology-based sentiment classification method to detect features concerning financial news has been given in [22]. In [23], a text summarization technique has been proposed to determine the top-k most informative sentences about hotel from online reviews by calculating sentence importance. Authors in [24] have combined similarity and sentiment of reviews and proposed a recommendation ranking strategy to suggest items similar but superior to a query product. Techniques used for opinion mining and some simple assumptions are their limitations.
2.3 SentiWordNet
SentiWordNet is a publicly available lexical resource absolutely designed to support sentiment classification and opinion mining. It is the outcome of self-annotation of all the synsets of WordNet on the basis of “positivity,” “negativity” and “neutrality.” Three different mathematical values Pos(s), Neg(s) and Obj(s), correlated with every synsets, decide the positivity, negativity and objectivity of all the terms present in synset. Different meanings of same term may have different sentiment score. For each synset, sum of all three scores is always 1.0 and all three values lie in interval [0.0, 1.0]. It implies that a synset can have nonzero value for all three classes. This signifies that terms present in synset contain all three, opinion polarity up to a certain degree. SentiWordNet is generated in two steps: first one is semi-supervised learning step, and second one is random-walk step [25].
3 Proposed Approach
The proposed approach can be viewed as a two-phase process which is as follows:
3.1 Data Preprocessing and Opining Mining
In the first phase, customer reviews are mined and features are extracted. Major steps during this phase are as follows:
-
1.
Perform preprocessing of reviews, which involves removal of meaningless, unwanted symbols and stop words.
-
2.
Perform part-of-speech tagging on preprocessed reviews using POS tagger.
-
3.
Based on these POS tags, perform feature extraction by finding bi-word phrases in which mostly features are represented by noun tags and corresponding adjective words are opinion about these features.
-
4.
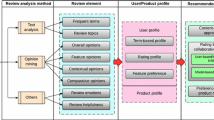
Store user’s opinion about features, obtained in previous step, in the database. Schematic diagram of this phase is shown in Fig. 1.
Fig. 1 
Schematic diagram of the first phase

3.2 Score Calculation and Recommendation
The second phase generates personalized product recommendations for the target user, based on opinions of other similar users and features in which target user is interested. The major steps of this phase are as follows:
-
1.
Now consider those extracted features which have frequency greater than some threshold value, specified by domain expert, across all items.
-
2.
Calculate average sentiment score of each feature of every product using SentiWordNet.
-
3.
Similarly, calculate average sentiment score of each feature for every user and store it in database.
-
4.
Calculate cosine-based similarity of every user with other users based on average sentiment score values for different features using Eq. (1).
where UA and UB are feature vectors of user A and B. Similarly, i is the number of commonly scored features between user A and B.
-
5.
Select those products that have not been reviewed by the target user but have been reviewed by its similar users.
-
6.
Find the occurrence frequency of each feature, discussed by the target user in his past reviews and arrange features in decreasing order of their frequency.
-
7.
Now recommend products obtained from step-5 in the order of scores for features in the same sequence as obtained in step-6. Schematic diagram of this phase is shown in Fig. 2.
Fig. 2 
Schematic diagram of the second phase

4 Practical Implementation
Every review goes through preprocessing and POS tagging activity. In this work, Stanford Core NLP tagger has been used. For example, the output of the review “Shoes are nice and good looking.”, after performing preprocessing and POS tagging activity is shown in Fig. 3.

Output after preprocessing and POS tagging
The Stanford tagger uses some standard tags to define part-of-speech of each word, such as NN and JJ. Some useful tags have been shown in (Table 1).
Based on these POS tags, features are extracted from all reviews. In this work, fifteen features which are most frequent in all reviews have been considered. After performing all steps described in proposed approach, the system recommends products, for example, let us say there are total 10 users and 10 products. After performing feature extraction, 15 features are found, but only those features are considered whose frequencies are higher and these are f1, f2, f3, f4, f5 and f6. Suppose the target user is u1 and his similar users are u3, u5, u8, u9, and u7, products obtained from step-5 of second phase of recommendation for target user are i8, i1, i2, i6, and i10. Scores of different features of these products are shown in Table 2.
The frequency of features obtained from step-6 of second phase of recommendation for the target user u1 is shown in Table 3.
So using step-6 of phase-two, the sequence obtained is f2, f3, f4, f5, f1, f6. Now step-7 checks the scores of features in items obtained from step-5. So, accordingly first of all it is checked that which product has highest score for feature f2, that product is recommended first, next checked for feature f3 and so on. Therefore, final recommendation order of products is i6, i1, i10, i8, i2.
5 Conclusion
Now almost every user is writing their experiences about different products in the form of reviews. Opinion mining handles this huge user generated opinionated data. A comparatively recent sub-area of opinion mining is aspect-based opinion mining, and it extracts products features and users’ opinion about those features from reviews. In this paper, a novel approach has been proposed to recommend products to users on the basis of features on which they have shown interest in their past reviews by arranging products in the order of score of features. The proposed approach extracts features and opinions from reviews using part-of-speech tagging and then calculates their score using a publicly available lexical resource SentiWordNet. Afterward, it recommends product to the target user with the collaboration of other similar users. In future, this work can be expanded by refining feature extraction and selection method so that only those features will be considered which affect the decision making most. As in review “The hotel is expensive,” the reviewer is talking about the price of hotel but the word price is mentioned nowhere in text. As a future enhancement to this work, all such problems in aspect extraction have to be addressed.
References
Aggarwal, C.C.: Recommender Systems: The Textbook. 1st edn. Springer International Publishing, USA (2016)
Ricci, F., Rokach, L., Shapira, B.: Recommender Systems Handbook, 1st edn. Springer, USA (2011)
Schafer, J.B., Frankowski, D., Herlocker, J., Sen, S.: The Adaptive Web: Methods and Strategies of Web Personalization, 1st edn. Springer, Heidelberg (2007)
Hasan, K.A., Sabuj, M.S., Afrin, Z.: Opinion mining using Naive Bayes. In: IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE) 2015, pp. 511–514. IEEE, Bangladesh (2015)
Nakade, S.M., Deshmukh, S.N.: Observing performance measurements of unsupervised PMI algorithm. Int. J. Eng. Sci. 7563–7568 (2016)
Zhang, Y.: Incorporating phrase-level sentiment analysis on textual reviews for personalized recommendation. In: Proceedings of the Eighth ACM International Conference on Web Search and Data Mining, pp. 435–440. ACM, Shanghai (2015)
Ganu, G., Elhadad, N., Marian, A.: Beyond the stars: improving rating predictions using review text content. In: 12th International Workshop on the Web and Databases, pp. 1–6. USA (2009)
Tewari, A.S., Barman, A.G.: Collaborative recommendation system using dynamic content based filtering, association rule mining and opinion mining. Int. J. Intell. Eng. Syst. 10(5), 57–66 (2017)
Liu, B.: Sentiment analysis and opinion mining. Synth. Lect. Human Lang. Technol. 5(1), 1–167 (2012)
Pang, B., Lee, L.: Opinion mining and sentiment analysis. Foundat. Trends Informat. Retrieval 2(1–2), 1–135 (2008)
Kreuz, R.J., Glucksberg, S.: How to be sarcastic: the echoic reminder theory of verbal irony. J. Exp. Psychol. Gen. 118(4), 374–386 (1989)
Pang, B., Lee, L.: A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In: Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics 2004, pp. 271–278. Association for Computational Linguistics, Barcelona (2004)
Liu, B.: Web Data Mining: Exploring Hyperlinks, Contents, and Usage Data, 1st edn. Springer Science & Business Media, Heidelberg (2007)
Liu, B.: Handbook of Natural Language Processing, 2nd edn. Taylor & Francis, Boca Raton (2010)
Pisote, A., Bhuyar, V.: Review article on opinion mining using Naïve Bayes classifier. Advanc. Comput. Res. 7(1), 259–261 (2015)
Popescu, A.M., Etzioni, O.: Extracting product features and opinions from reviews. In: Kao, A., Poteet, S.R. (eds.) Natural Language Processing and Text Mining 2007, pp. 9–28. Springer, London (2007)
Hu, M., Liu, B.: Mining and summarizing customer reviews. In: Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2004, pp. 168–177. ACM, Seattle (2004)
Scaffidi, C., Bierhoff, K., Chang, E., Felker, M., Ng, H., Jin, C.: Red opal: product-feature scoring from reviews. In: Proceedings of the 8th ACM Conference on Electronic Commerce 2007, pp. 182–191. ACM, San Diego (2007)
Liu, B., Hu, M., Cheng. J.: Opinion observer: analyzing and comparing opinions on the web. In: Proceedings of the 14th International Conference on World Wide Web 2005, pp. 342–351. ACM, Chiba (2005)
Jin, W., Ho, H.H., Srihari, R.K.: OpinionMiner: a novel machine learning system for web opinion mining and extraction. In: Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining 2009, pp. 1195–1204. ACM, Paris (2009)
Kang, M., Ahn, J., Lee, K.: Opinion mining using ensemble text hidden Markov models for text classification. Exp. Syst. Appl. 94(2018), 218–227 (2018)
Salas-Zárate, M.D.P., Valencia-García, R., Ruiz-Martínez, A., Colomo-Palacios, R.: Feature-based opinion mining in financial news: an ontology-driven approach. J. Informat. Sci. 43(4), 458–479 (2017)
Hu, Y.H., Chen, Y.L., Chou, H.L.: Opinion mining from online hotel reviews—a text summarization approach. Inf. Process. Manag. 53(2), 436–449 (2017)
Dong, R., O’Mahony, M.P., Schaal, M., McCarthy, K., Smyth, B.: Combining similarity and sentiment in opinion mining for product recommendation. J. Intell. Informat. Syst. 46(2), 285–312 (2016)
Baccianella, S., Esuli, A., Sebastiani, F.: Sentiwordnet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining. In: Calzolari, N., Choukri, K. (eds.) Proceedings of the Seventh conference on International Language Resources and Evaluation, 2010, LREC, vol. 10, pp. 2200–2204. ELRA Malta (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Tewari, A.S., Jain, R., Singh, J.P., Barman, A.G. (2019). Personalized Product Recommendation Using Aspect-Based Opinion Mining of Reviews. In: Chakraborty, M., Chakrabarti, S., Balas, V., Mandal, J. (eds) Proceedings of International Ethical Hacking Conference 2018. Advances in Intelligent Systems and Computing, vol 811. Springer, Singapore. https://doi.org/10.1007/978-981-13-1544-2_36
Download citation
DOI: https://doi.org/10.1007/978-981-13-1544-2_36
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-13-1543-5
Online ISBN: 978-981-13-1544-2
eBook Packages: EngineeringEngineering (R0)