
Abstract
In recent years remaining useful life of rolling bearings is paid much more attention. In this paper, the remaining useful life prediction based on fault diagnosis is proposed. Based on the real-time fault diagnosis results of the bearing, the remaining life is predicted and a set of bearing life expectancy prediction system is established by obtaining the vibration signal. In order to solve the problem that the whole life fault data is difficult to obtain, make full use of the bearing information contained in unlabeled data and take into account the advantages of each algorithm, the remaining useful life prediction of bearing is studied based on a semi supervised co-training method. The effectiveness and prediction accuracy of this method are demonstrated by a case study.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Bearings are important component of mechanical, which works in severe conditions and its life is often much less than the expected and desired life. The bearing fault is one of the foremost causes on mechanical breakdowns. And such fault will result in costly downtime and life safety are under serious threat [1]. Therefore, it is vitally important to diagnose the faults and predict the remaining useful life (RUL).
In recent years, scholars have made some achievements in the study of mechanical remaining useful life prediction methods. The mechanism model of running state is designed based on the model with the crack growth law [2], however, the residual life prediction method based on mechanism has a higher requirement on the professional research. Zio [3] has studied the similarity degree of the equipment characteristics, but the prediction accuracy will be affected even if the similar products are used to predict the remaining life. In addition, artificial intelligence and hybrid algorithm are the research directions of remaining useful life prediction.
Traditional data-driven prognostics often requires amount of fault data for the offline training in order to achieve better accuracy of the online prediction. In many experiments, it is hard to get enough fault data. So it becomes essentially critical to utilize unlabeled data which may carry rich information regarding the degradation trend and help achieve more accurate RUL prediction [4, 5]. Unlabeled data (UL) refer to the condition monitoring data acquired from the beginning of an engineered system’s lifetime till planned inspection or maintenance when the system is broken down. Disagreement-based semi-supervised learning is used in the RUL prediction, which uses multiple learning algorithms to make use of unlabeled data, and the “disagreement” among the algorithms is crucial.
The rest of this paper is organized as follows. The problem statement is introduced in Sect. 2. Remaining life prediction of bearing based on fault diagnosis in this paper is primarily focused in Sect. 3. Section 4 has shown a case study of this method. Finally, some conclusions and prospects are given in Sect. 5.
2 Problem Statement
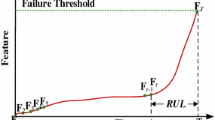
The change of the operating environment leads to a difficult RUL predict of a normal railway bearing. When the bearing fault occurs, the available life of the bearing is shortened and it is more meaningful to predict the RUL. There is a close relationship between the RUL estimation and the fault type of the bearing. The deteriorative curves for different fault types are shown in Fig. 1 [6], different faults have different prediction models. Hence predicting the RUL of the bearing accurately, it is important to identify fault type first.

Health status deteriorative curves for different fault model
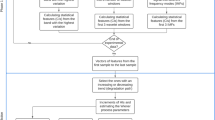
In this paper, the RUL prediction of the bearing based on fault diagnosis is considered. Data processing as a preparation for diagnosis and RUL prediction in the first place. The RUL prediction issue based on semi-supervised co-training method is considered. The frame of the whole process is shown in Fig. 2. In Fig. 2 the back propagation (BP), principal component analysis (PCA) are used.

The progress of residual life prediction based on fault diagnosis
The working principle of fault diagnosis is as follows: Put the bearing signal into the fault diagnosis system, determine the time and degree of failure. At the same time, put the original data into the processor system to extraction the feature, then separate the different type of fault. And the fault time, fault degree and fault type are used as the output of the fault diagnosis device.
The principle of RUL prediction: The extracted feature values are fused and PSO-BP and SVR are used to perform semi supervised training for different fault data. The fault type of the fault diagnosis system is used as the input of the RUL prediction system, according to this value, management and maintenance decision for the parts with current faults can make timely and accurately.
There are a lot of researches on fault diagnosis, and the semi supervised cooperative residual life prediction algorithm is introduced in detail in this paper.
3 Semi Supervised Co-training
This section focuses on the RUL prediction based on the fault diagnosis. The semi-supervised co-training-based approach is used for bearing RUL prediction, as a promising research aiming to exploit simultaneously the benefits from labeled and unlabeled data. And two prediction algorithms are used for algorithms integration, which can combine with different algorithms models, different forecasting process and different prediction results. The simple process of semi supervised co-training is shown in Fig. 3, and the fake code of main process is shown in Table 1, which is taking the two characteristic values as an example. After the training process, the optimal algorithm is obtained. Then loading the testing data, the RUL will be exported. And method 1 and method 2 are RUL prediction method.

Process of co-training semi-supervised algorithm
BP neural network is one of the algorithms, which can fit any finite input–outputs mapping with a sufficient number of neurons in the hidden layer. The exact parameters and function selection and more information about BP will be introduced in the [7] another algorithms is support vector regression (SVR). It is improved on the basis of support vector machine (SVM) by introducing the loss function \( \varepsilon \) into the SVM. It can be approximated any nonlinear function by control the precision and the generalization ability. And SVR has a good global optimum ability and stability [8].
4 Case Analysis
4.1 Data Sources
To validate the efficiency of this method, data from the bearing experimental platform of the NSFI/UCR intelligent maintenance center in the United States are used. Four Rexnord ZA-2115 double row bearings are installed on one shaft. The parameters of the bearing are shown in Table 2.
There are three groups of this experiment, each group has 4 bearings to test, and the data sampling rate is 20 kHz. RUL prediction results for different unlabeled number are compared to show the relation between unlabeled number and prediction accuracy. The data settings are shown in Table 3.
There are 12 input vectors, composed by the normalized age value of bearing and PCA features at the current and previous points, and RUL as the output. In BP network algorithm, the number of hidden layer neurons is 8, the output layer function is linear, trainlm as training function and sigmoid as hidden layer transfer function, the network is trained for 1000 times and the expected error value of this net is 10e-5. The other algorithm is SVR, the center function is RBF, the parameter of C is 0.503, and is 0.016. The weight of each network is 0.5.
The RUL prediction result compared with other methods are shown in Fig. 4, which UL is mean the semi supervised co-training method when the unlabeled sets are 8. All of the results has shown a typical recession characteristic of rotating machinery. The prediction curve is gentle in the early stage. When the fault occurs, the curve shows a decreasing trend, and the slope is much larger than the initial stage. It can be seen that the result of semi-supervised cooperative algorithm are better than BP and SVR in the whole forecasting process.

Different number of unlabeled data for RUL prediction
To verify the effect of the unlabeled data to the prediction accuracy of the algorithm, four error indexes are calculated, which are the root mean square error, the mean absolute error, the hill coefficient of the inequality and the average relative change, respectively.
The RUL prediction result compared with different number of unlabeled data is shown in Fig. 5. Take 2, 5 and 8 as example. The trend of the prediction curve is the same, the recession curve is stable at the early stage, and the curve decreases when the fault occurred and the slope increases. The error values of different unlabeled data method are calculated as Table 4. With the increase of the number of unlabeled data, the accuracy of the model is generally improved, indicating that the increase of the number of unlabeled data can improve the prediction accuracy of the algorithm.

Different number of unlabeled data for RUL prediction
Considering the situation that RUL is predicted when fault occurs, Fig. 6 shows the RUL prediction from 118 to 164 h, which is in fault stage. When the unlabeled data is 8, the curve is closer to the actual value than others. And the error values are calculated for this period either, the error values are listed in Table 5. All error values reach the minimum when unlabeled data is 8.

Different number of unlabeled data for RUL prediction
5 Conclusions
This paper presents a RUL prediction method based on fault diagnosis and fault isolation at the early stage. For early fault diagnosis, spectral correlation density combination slice method is used, which fully considers the cycle characteristics of the rotating machine. VPMCD can verify the bearing’s fault type even though the integrated fault. And semi supervised co-training-based approach combines the two models, and the unlabeled data is fully used in this method. The case study has proved the effectiveness of the method convincingly. A further study and application of the prediction method for practical mechanical systems would be our future work.
References
Jianwei Y (2015) Fault diagnosis of railway bearing based on FIR-wavelet packet and LVQ neural network. Open Autom Control Syst J 7:303–313
Oppenheimer CH, Loparo KA (2002) Physically based diagnosis and prognosis of cracked rotor shafts. In Aerosense international society for optics and photonics
Zio E, Maio FD (2010) A data-driven fuzzy approach for predicting the remaining useful life in dynamic failure scenarios of a nuclear system. Reliab Eng Syst Safety 95(1):49–57
Hu C (2015) A co-training-based approach for prediction of remaining useful life utilizing both fault and suspension data. Mech Syst Signal Process 62–63:75–90
Zhou Z (2013) Disagreement-based semi-supervised learning. Acta Automatica Sinica 39(11)
Sikorska JZ, Hodkiewicz M, Ma L (2011) Prognostic modelling options for remaining useful life estimation by industry. Mech Syst Signal Process 25:1803–1836
Chen Yuhao (2010) Review of neural network BP algorithm. Comput Knowl Technol 6(36):10364–10365
Dvaid M, Alexnader F (2004) Active set support vector regression. IEEE Trans Neural Netw 15(2)
Acknowledgements
This work is also partly supported by State Key Lab of Rail Traffic Control & Safety (Contract No. RCS2016ZT006). This work is also partly supported by National Key R&D Program of China (Contract No. 2017YFB1201201).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Yan, D., Wei, X. (2018). RUL Prediction for Bearings Based on Fault Diagnosis. In: Jia, L., Qin, Y., Suo, J., Feng, J., Diao, L., An, M. (eds) Proceedings of the 3rd International Conference on Electrical and Information Technologies for Rail Transportation (EITRT) 2017. EITRT 2017. Lecture Notes in Electrical Engineering, vol 482. Springer, Singapore. https://doi.org/10.1007/978-981-10-7986-3_102
Download citation
DOI: https://doi.org/10.1007/978-981-10-7986-3_102
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7985-6
Online ISBN: 978-981-10-7986-3
eBook Packages: EnergyEnergy (R0)