
Abstract
This paper investigates the self-organized task allocation behaviors in swarm systems by means of evolutionary game theory. A group of E-puck robots are employed to study the potential factors influencing the strategy choices of tasks that require different costs. Endowing the cooperation and defection strategy to robots, we find possible approaches to promote cooperation among selfish robots without explicit communication or cooperation mechanisms. Irrespective of the global information and centralized control, the proposed method is related with the strategy evolution adopted by the robots performing the tasks. Results are presented for a system of physical robots capable of moving and collectively form a specified spatial pattern. The contribution is that evolutionary game theory offers a new approach to environment-specific task modelling in collective robots.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The study on task allocation behaviors realized by self-organization receives much attention nowadays, which has a wide range of applications in artificial intelligence and engineering areas. Division of labor, where thousands of individuals in nature perform specific tasks can be seen as the hallmark of insect societies [1,2,3]. Daily experience tells us that the division of labor is a common phenomenon, in which different sub-tasks may require different effort or cost with others [4, 5]. Group behaviors achieved by self-organization, can be seen as a result from local interactions without central control or global information exchange.
Most mechanisms for promoting effective task allocation results have been proposed. Among these mechanisms, an often-used approach is based on thresholds of tasks, where the switching of the agents’ strategy choices are related with the threshold value [6, 7]. This consideration is closely related with the hints provided by the observation from animal societies. The settings of threshold is on the strength of feeling a stimulus which describes the “degree of urgency” of a task to be performed [7]. It is thus understandable that larger stimulus of a task will attract more agents to engage in the task performing. Besides, many works have made their contributions in the study of division of labor. The study in [8] focuses on a foraging task including two sub-tasks, called harvest and store. Robinson [9] investigate the potential ways for effective task allocation, by setting a scenario where the employed robots collect the randomly distributed objects to accumulate them in a cluster. Michael J.B. Krieger et al. use robots to simulate agents to conduct a foraging task by employing the method based on the thresholds [10], where the strategy switching occurs when a given parameter in the surroundings reaches a threshold. The works by Sendova-Franks and Franks [11] provide an equation which is helpful for calculating the instantaneous rate of energy, which is fundamental to the strategy choices of foraging robots in their study.
In the collective systems, collaboration dilemmas usually describe the scenario where the conflicts between the best decision of an individual and that of the group arise [12]. Rational agents, who attempt to maximize their own benefits, may thus attempt to free-ride on the others—benefiting from the contributions of others without offering their own to the group. In investigating this problem the often-used tool for modelling the dilemma is evolutionary game theory [13,14,15]. In other words, cost and benefits are the key factors for tasks, which will influence individual’s choice. From the perspective of game theory and benefits-maximizing pursuit of rational agents, division of labor, can be seen as a particular or further developed form of cooperation. The effective distribution of sub-tasks execution will result a better performance of the system, though different group members may bear unequal costs for the sub-tasks [16, 17].
By feat of game theory, we study the collective behaviors in the form of tasks by a swarm of robots whose personalities are described by their strategies. Then, assumptions made on the robotic platform make these results rather interesting from a theoretical perspective. A single robot is equivalent to an individual in the game theory. The robot task selection can be seen as a game situation. The task assignment of multi-robot system is to select the most effective task by each robot according to the certain goal in a game state. In this paper, we will study the relationship between agents’ payoff and agents’ cooperative level in different state and try to find some rules which are useful for agents to execute task effectively.
The paper is organized as follows. Section 2 describes the experimental platform design. Sections 3 and 4 is contributed to introduce experimental setup. Section 5 displays the experimental results. Finally in the last section concluding comments are given.
2 Experimental Platform Design
The experiment platform includes two parts: hardware platform and software platform. The hardware platform consists of a host computer, two USB cameras, 4 E-puck robots and an experiment Table (240 cm*240 cm). The host computer is responsible for image processing, running game and path planning algorithm. The USB camera can catch the real-time position information of the robots (Fig. 1).

Left the used E-puck robot; right settings of the experiment platform
The software platform includes three modules: target location and recognition module, communication module, and algorithm module. The target recognition and recognition module is mainly responsible for robots’ localization. It uses openCV [2], a visual library, to implement the recognition of color marks on robots, which contains position information of robots. The communication module is based on the Bluetooth communication. The algorithm module is divided into two parts: game algorithm, path planning and obstacle avoidance algorithm. Game algorithm is mainly responsible for robots’ decision-making and payoff calculation. Path planning [1] and obstacle avoidance algorithm refers to leading robots to run from the current location to the target location, and meanwhile avoid collision with obstacles in the planned route.
3 Experimental Setup
Here 4 E-puck robots are employed for performing the collective task, whose maneuverability and intelligence improves their applicability. It has a pair of driving wheels and their real-time position and angle are available. The experiment settings are: (1) initial position: 4 robots are randomly scattered at the experimental table. (2) initially target site: to increase the conflicts between the robots, robots’ initial target site is randomly selected. (3) objects: to move towards the 4 target sites which can form some spatial pattern, such as the square shown in Fig. 2. (4) conflicts: the conflicts for selecting the same site is adjusted by the evolutionary game theory, where strategy choices are endowed with the robots.

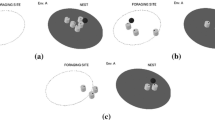
The illustration about the evolving process of the multi-robots. Initially, robots randomly select the target site. Conflicts results for one site depend on the strategy choices of robots
4 The Individual Behavior of Robots
Searching state: Robots randomly select a target site in the initial state. When the robot approaches the target site within a certain range, she will check whether the target site has been occupied. If not, robot continues to move to the chosen target. Otherwise, robot must determine whether to give up the target (already has been occupied by others) or not. Insisting on this site will face potential conflicts with the robots who have already been in the site. The results of conflicts depend on the strategy choice (cooperation or defection) of the involved robots. Whereas giving up the target, means the robot run to another site instead. The above process until it stops at a target position.
Occupation state: Robot that has stopped at the target point is on the Occupation state. The robot on the occupation state checks if any other robot is approaching to the target site occupied by itself. When other robots are coming to fight for the target point, the robot will determine whether to leave. If robot gives up the occupied site, it turns to search state.
Robot’s payoffs and cost: The collected payoff is related to the task choice and the completion of the chosen tasks. If the robots can finally form the specified spatial pattern, the collective task succeeds. Successful task will bring robots a payoff denoted by b. Failed task will bring nothing to the group members. To perform the task, the consumed energy of E-puck robots is related to time and distance. Besides, the time and distance needed to achieve a steady state in performing the tasks are noteworthy indicators. And, they can help us to measure how the employed method influences the collaboration behaviors. Therefore, the robots’ payoffs are described by,
Here b = 100 for successful task, and b = 0 for failed one. t is the time that robot spends on the task. d is the distance that robot runs for the task. α and β are scale factors.
For a robot suiting on the chosen target, she faces two choices when another robot gets close to her site: cooperation or defection. Here, we employ \( \varvec{P}_{{\varvec{sea}}} \) to describe the probability that robot chooses to be a cooperator who will leave the current site and choose a new target. \( \varvec{P}_{{\varvec{occ}}} \) describes the probability that the focal robot chooses to be a defector who will stay in her current target.
5 Experiment Results
In collecting the experiment results, our focus is put on three main parameters: the success rate of the tasks, the performance index and the payoffs of robots. The success rate is fraction of successfully-performed tasks in the whole experiments. The performance index is the number of appointed sites which are occupied by robots in experiments. If all the sites are occupied by the robots, i.e. they finally self-organize into the specified shape, the value of the performance index will be 4. If only two robots steadily situate in the specified sites, while other two sites are empty, the value of the performance index will be 2. The payoffs are collected and calculated by the \( \varvec{R} = \varvec{b} -\varvec{\omega}_{{\mathbf{1}}} \varvec{e}^{{\varvec{t}/\varvec{\alpha}}} +\varvec{\omega}_{{\mathbf{2}}} \varvec{e}^{{\varvec{d}/\varvec{\beta}}} \).
Figure 3 clearly shows that the success rate reaches the highest for the settings: \( \varvec{P}_{{\varvec{sea}}} = {\mathbf{1}} \) and \( \varvec{P}_{{\varvec{occ}}} = {\mathbf{0}} \) or \( \varvec{P}_{{\varvec{sea}}} = {\mathbf{0}} \) and \( \varvec{P}_{{\varvec{occ}}} = {\mathbf{1}} \). It means that, if the robots in the searching state will leave the already occupied site and choose a new target (i.e. to be a cooperator), meanwhile the robots who occupied this site will stay (i.e. to be a defector), what will benefit the success performing of the specified tasks. In the same way, if the robots in the searching state will insist in occupying the already occupied site, meanwhile the occupants leave this site which causes conflicts, this will promote the successful performance of the tasks. The reason lies on the fact that, the cooperation-cooperation will make it be easier for the appearance of vacant sites. While the defection-defection will lead the system to evolve into a state of an infinite loop where the two robots conflict with one site.

The success rate of the robotics in performing tasks as a combination function of \( P_{sea} \) and \( P_{occ} \). When conflicts for one site occur, \( P_{sea} \) is the probability that robot chooses to be a cooperator who will leave the current site and choose a new target. Similarly, \( P _{occ} \) describes the probability that the focal robot chooses to be a defector who will stay in her current target, when conflicts for one site occur. Here, it is clear that the success rate reaches the highest for the settings: \( P_{sea} = 1 \) and \( P_{occ} = 0 \) or \( P_{sea} = 0 \) and \( P_{occ} = 1 \)
Figure 4 suggests that the number of completions reaches a higher level for the settings of larger \( \varvec{P}_{{\varvec{sea}}} \) or larger \( \varvec{P}_{{\varvec{occ}}} \). It means that, larger cooperation probability of the robots will help more specified sites to be occupied by robots. Notably, it is irrespective of the state of robots, either in the searching state or occupation state. Thus, the performance of tasks is closely related with the strategy choice of the robots. However, the successful performance of tasks depends on more limited conditions. To facilitate the understanding, Fig. 5 provides the general view of the gaming process.

The fraction of number of completions (i.e. performance index) as a function of \( P_{sea} \) and \( P_{occ} \). The number of completions describes the number of robots who stay at a target position when task ends. It is clear that high number of completions means the close to success. As the figure above depicted, the number of completions is low when \( P_{sea} \) and \( P_{occ} \) are at a low level. It reaches the highest when \( P_{sea} = 1 \), \( P_{occ} = 0 \) or \( P_{sea} = 0 \), \( P_{occ} = 1 \). The number of completions is low when \( P _{sea} \) and \( P _{occ} \) are at a low level. The number of completions is high when \( P _{sea} \) and \( P _{occ} \) are at a high level

The process for performing the aggregation task in the robotic swarm. 1 Robots settings at the initial state. 2 Robots are moving to the chosen targets. 3 The conflicts for a site. 4 The steady state where no one changes her choice
6 Conclusions
Conflicts of interest and self-adjustment are pivotal elements in studying the problem of task allocation or division of labor in a swarm of agents. Different from the traditional approach, we employ the evolutionary game theory to study the self-organization of individual behaviors among E-puck robots. Experiment results show that robots can gain the highest payoffs under the following conditions: robots cooperate when being in the searching state and defect in the occupied state, robots defect in the searching state and cooperate in the occupied state. The coordination driven by strategy choice can help us get more hints about the solutions for the effective division of labor among selfish agents. The successful performance of the collective task can be better realized by the agents with rationality and selfishness.
References
Agassounon W, Martinoli A, Goodman R (2001) A scalable, distributed algorithm for allocating workers in embedded systems. IEEE international conference on systems 5(2):3367–3373
Brutschy A, Pini G, Pinciroli C, Birattari M, Dorigo M (2014) Self-organized task allocation to sequentially interdependent tasks in swarm robotics. Auton Agent Multi-Agent Syst 28(1):101–125
Campo A, Dorigo, M (2007) Efficient multi-foraging in swarm robotics. European conference on advances in artificial life, vol 4648 LNAI. Springer, Berlin, pp 696–705
Duarte A, Weissing FJ, Pen I, Keller L (2011) An evolutionary perspective on self-organized division of labor in social insects. Annu Rev Ecol Evol Syst 42(1):91–110
Gerdes J, Becker MHG, Key G, Cattoretti G, Sanders HW, Smith AG et al (1992) Letters to the editor. J Pathol 168(1):85–87
Karsai I, Wenzel JW (1998) Productivity, individual-level and colony-level flexibility, and organization of work as consequences of colony size. Proc Natl Acad Sci U S A 95(15):8665–8669
Kreiger M, Billeter J (2000) The call of duty: self-organized task allocation in a population of up to twelve mobile robots. Robot Auton Syst 30(1):65–84
Wilson EO (1978) Caste and ecology in the social insects. Monogr Popul Biol 12(3):1
Robinson GE (1992) Regulation of division of labor in insect societies. Annu Rev Entomol 37(1):637
Seeley TD (1989) The honey bee colony as a superorganism. Am Sci 77(6):546–553
Sendova-Franks A, Franks NR (1993) Task allocation in ant colonies within variable environments (a study of temporal polyethism: experimental). Bull Math Biol 55(1):75–96
Stewart AJ, Plotkin JB (2016) Small groups and long memories promote cooperation. Sci Rep 6(s 1–3): 26889
Stivala A, Kashima Y, Kirley M (2016) Culture and cooperation in a spatial public goods game. Phys Rev E 94(3–1):032303
Van den Berg P, Molleman L, Weissing FJ (2015) Focus on the success of others leads to selfish behavior. Proc Nat Acad Sci U S A 112(9):2912–2917
Xu Z, Zhang J, Zhang C, Chen Z (2016) Fixation of strategies driven by switching probabilities in evolutionary games. Europhys Lett 116(5):58002
Zhang J, Chen Z (2016) Contact-based model for strategy updating and evolution of cooperation. Physa D Nonlinear Phenom 323–324(2):27–34
Zhang J, Zhang C, Cao M, Weissing FJ (2015) Crucial role of strategy updating for coexistence of strategies in interaction networks. Phys Rev E Stat Nonlin Soft Matter Phys 91(4):042101
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper
Cite this paper
Li, Q., Yang, X., Zhu, Y., Zhang, J. (2018). Self-organized Task Allocation in a Swarm of E-puck Robots. In: Deng, Z. (eds) Proceedings of 2017 Chinese Intelligent Automation Conference. CIAC 2017. Lecture Notes in Electrical Engineering, vol 458. Springer, Singapore. https://doi.org/10.1007/978-981-10-6445-6_17
Download citation
DOI: https://doi.org/10.1007/978-981-10-6445-6_17
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-6444-9
Online ISBN: 978-981-10-6445-6
eBook Packages: EngineeringEngineering (R0)