
Abstract
Wireless sensor network (WSN), in recent times, has been exhibiting potential in variety of applications like military surveillance, disaster management, and wildlife monitoring. In these applications, humans cannot access the place either to deploy the sensors or to monitor the sensors as the environment is inhospitable. Therefore, the sensors are expected to be remotely deployed and to operate in an autonomous mode. To support scalability, sensor nodes are formed or organized into clusters and the clusters formed are without overlap and disjoint. In this paper, classification of clustering attributes is presented from the various published clustering algorithms of WSN. The clustering schemes are compared based on the metrics such as sensor mobility, overlap of clusters, position awareness, efficient energy-based, uniform clustering, and stability of cluster.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Recent advances in wireless sensor network (WSN) have led to the increase in the limited-power, low-cost, tiny-sized, multi-functional sensors that are capable of communicating over short distance range. Sensors are embedded with microprocessor, radio receiver, and power components to enable sensing, data processing, and communication [1]. Sensors are battery-operated devices; hence, decrease in the energy consumption to prolong the lifetime of the network is a major challenge in the field of wireless sensor network (WSN).
In the sensing field, the sensors are deployed randomly along with the base station (BS). The function of the sensor is to sense the physical conditions of the environment like temperature, humidity, pressure, light, and disaster and send these data to the BS. The BS may be placed far away from the sensor nodes. Each and every sensor must report its sensed information to the BS either directly in single step or through multi-hop fashion. The sensors that are near to the BS consume less energy when compared with the sensors that are placed far away from the BS. So, more the energy consumption of the sensors less will be its battery life as the sensors have limited power.
Wireless sensor network have variety of applications like military surveillance, disaster management, health monitoring, air pollution monitoring, and area monitoring. In some applications like disaster management, humans cannot directly interact to deploy the sensors or to monitor the sensors as the environment is so harsh. These applications require thousands of nodes to be deployed. So, the sensors need to be deployed in a remote manner and these are operated autonomously [2]. The WSN must have the feature of scalability to manage the thousands of sensors. To support scalability and to reduce the energy consumption of the sensor nodes, clustering technique is used. A detailed description of clustering is being presented in the next section of the paper.
2 Clustering
Clustering is a technique in which the sensors are organized into different number of clusters. In each cluster, one node acts as a cluster head (CH) and the remaining nodes form the members of the cluster. The member nodes of the cluster sense their physical surroundings and transmit the data to the CH. The CH is responsible for aggregating the data that are received and reporting the data to the sink or BS. The cluster members send the data to the CH usually in a single-hop fashion. And it is termed as intra-cluster topology [3].
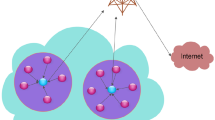
The main advantage of clustering is that it supports network scalability [2]. The CH can be randomly picked from the set of deployed sensors, or it can also be decided by the network. If the CH is pre-assigned, then it can be provided in advance with more resources [2]. In this, the clusters formed are stable throughout the network as the cluster head is fixed. If the CH is selected randomly, then the clusters are not stable and they change dynamically. When compared with the cluster members, CHs must be provided with more energy and they must always be in active state (Fig. 1).

Clustering technique in WSN
3 Critical Analysis of Clustering Protocols
A brief description of the published clustering protocols is provided, and the protocols are compared against the metrics sensor mobility, overlap of clusters, position awareness, efficient energy-based, uniform clustering, and stability of cluster.
The timeline chart in Fig. 2 shows the important protocols used for the clustering from year 2002 to 2016.

Timeline chart of protocols
3.1 Improved EADUC Protocol
In [4], the nodes are randomly deployed and are energy heterogeneous. Base station (BS) is located far from the sensor field. This protocol operates in rounds. After the nodes are deployed, BS broadcasts a signal to all the nodes. The nodes then approximate its distance to the BS based on the received signal strength. Every round comprises of two stages: cluster setup stage and steady-state stage. Setup phase consist of three sub-phases. The first sub-phase is the neighbor node information collection. In the second sub-stage, selection of cluster heads takes place. In the last sub-stage, the cluster formation starts. Once the network is divided into clusters, the steady-state stage begins in which the transmission of data takes place. The steady-state phase consists of number of major slots. After one major slot, the cluster head rotation takes place. An extension of EADUC protocol is proposed in order to reduce the cluster overhead and also to balance the energy.
3.2 Cluster Head Rotation Mechanism
In [5], for a random period of time the sensor node goes into idle mode. Node self-elects and declares itself as a cluster head and broadcasts an advertisement message to all the nodes within the range. After receiving the response from the neighboring nodes, it decides whether to continue as a cluster head or to join as a member node in any of the existing clusters. For cluster head rotation, it uses a scheme in which the initial cluster head nominates the successor cluster head based on the information collected by the initial cluster head. This information contains the identification of member nodes sorted as per received signal strength indicator (RSSI) reading and sorted in a packet called NODE packet. This packet contains net location field with the ID of the successor cluster head. The initial cluster head communicates this packet to the successor cluster head. In this way, the cluster heads are rotated.
3.3 DUCF Protocol
In [6], initially all the sensors are randomly deployed. RSSI is used to calculate the distance between the sensor nodes. Three metrics are considered for selecting the node as a cluster head namely residual energy of the node, degree of the node, and distance from the node to BS. Similarly two output variables are also used namely chance and size. This protocol operates in two stages: cluster formation stage and data collection stage. In the cluster formation stage, cluster heads are selected using fuzzy logic. In the data collection phase, a TDMA schedule is generated by each cluster head and the nodes should send the information to the cluster head within that schedule.
3.4 Hierarchal Clustering Algorithm with Cluster Head Selection
Generally, a hierarchical protocol works in two layers. The first layer is used for selection of cluster heads, and the second layer is used for routing of the data. The clustering algorithm mechanism mentioned in [7] is used for cluster head selection. In this, cluster head selection is the key point which aims for decreased energy consumption and decrease in delay. Here, three parameters are used namely, remaining energy of the node, distance from the BS, and degree of the node (surrounding nodes). In every round, the weight of each node is calculated using the above-mentioned three parameters. The node with the maximum weight will be elected as cluster head for that cluster.
3.5 Mobile Sink-Based Approach
In [8], sensors are randomly deployed and are static. But the sink is mobile. In order to reduce the overhead on the single mobile sink, two mobile sinks are used and they are moved in the counterclockwise direction for every half of the round. LEACH protocol is used for the cluster formation and cluster head selection. The sensing field is equally divided into regions and each region contains clusters which are of unequal size. Initially, the node which is at the center of the region is selected as a cluster head. At the end of each round, the node that is closer to the center point and the node that is having higher residual energy are selected as a cluster head. As the sink is mobile, nodes must set up the route to deliver the data corresponding to the new location of the sink. Only one cluster head is responsible for maintaining the new route information of the mobile sinks.
3.6 SECC Protocol
In [9], the protocol consists of two phases. In the first phase, the energy of an individual node and the distance between its adjacent sensor nodes is calculated. Sensor nodes with nearly same average distance range are grouped into same cluster. In the next phase, energy-aware clusters are formed based on the threshold value. The nodes whose energy value is less than threshold is disabled and do not participate in the sensor operations.
3.7 P-LEACH Protocol
In [10], P-LEACH algorithm uses the combination of both PEGASIS and LEACH protocols. From PEGASIS, chain formation implementation is considered and from LEACH, data forwarding through the cluster head is considered. The nodes are divided into clusters based on the sensing range of the REQ message sent by the BS. Then, all the nodes of each cluster send their location and the energy information to the BS. Now for cluster head selection, the BS selects a node with higher remaining energy as a cluster head for each cluster. After the election of the cluster heads, the cluster head with minimum distance to the BS and with maximum energy is elected as a leader.
3.8 H-LEACH Protocol
H-LEACH proposed in [11] is the combination of HEED and LEACH protocols. When the setup phase is started, initially the average energy of all the nodes is calculated by using the required parameters. Then, the threshold value is calculated. Now, a random number is picked by the node in the range of 0 and 1. If the random number is less than the threshold and the sensor is having the energy greater than the average energy, then the corresponding node is elected as a cluster head. The energy required for data transmission is deducted from the energy of the node.
3.9 Clustering Using Fuzzy Logic
In [12], the algorithm operates in two phases. Residual energy and the required energy are the two linguistic input variables used in the fuzzy logic system. In the first phase, each sensor node calculates the energy required to transmit ‘k’ number of bits to the BS based on the received signal strength of the message sent by the BS. Nodes set its timer value inversely proportional to the output variable of the fuzzy logic system called as ‘chance’. The higher the value of chance, the more will be the probability of the node to become a cluster head. Each sensor node sets the countdown, and if it reaches zero, the node advertises itself as a CH and clusters are formed based on the distance between the sensors. In the second phase, TDMA schedule is used by the cluster head and sends it to the cluster members.
3.10 Area Coverage-Aware Clustering Protocol (ACACP)
In [13], the setup stage consists of information update, sensor activation, CH election, and relay node selection phases for the formation of clusters. Steady-state stage consists of data communication phase in which the active sensor node collects the data from time to time and sends this information to the CH nodes. Then, CHs aggregate the data and transmit these data to the BS through the relay node.
3.11 Virtual Grid Margin Optimization and Energy Balancing Scheme (VGMEB)
In [14], the network is organized in the form of grids in order to achieve uniform clustering. Here, each grid of the network uses cluster evaluation model to select the cluster head. The cluster evaluation model is the probability of selecting the cluster head which is located at the center of the grid so that the consumption of energy can be reduced. The weight factor of the node is calculated to find the probability of selection of a cluster head. The selected CH is responsible for forwarding the data to the sink by performing data fusion. As the sink is mobile, it is responsible for informing its location to all the cluster heads when moving from one grid to another.
3.12 Hybrid Backtracking Search Optimization Algorithm (BSA)
The protocol in [15] is a hybrid of genetic algorithm and k-means. Selection, crossover, and mutation operations are performed. This algorithm has two selection stages in order to update population ‘P’ with final trial population ‘T’ individuals, if they have better fitness value than ‘P’. Next, k-means algorithm is run to find the centroids for the clusters. These centroids are mapped to the nearest sensor nodes to obtain new cluster heads and again new clusters are formed.
Table 1 shows the summary of all the clustering protocols with their attributes.
4 Conclusion
In this paper, some published clustering techniques have been studied and these algorithms are categorized based on the classification of clustering attributes. Further, the clustering algorithms are compared based on the metrics such as sensor mobility, overlap of clusters, and position awareness. It can be concluded that clustering technique greatly reduces the energy consumed by the nodes and thus extends the stability of the network. Each of the illustrated technique can be treated as a milestone in the domain, a unique solution or a significant improvement over an existing method. By this fastidious review, we try to lend a beneficial resource for researchers and practitioners in the field of wireless sensor networks.
References
Singh, S.K., Singh, M.P., Singh, D.K.: A survey of energy-efficient hierarchical cluster-based routing in wireless sensor networks. Int. J. Adv. Netw. Appl. 2(2), 570–580 (2010)
Abbasi, A.A., Younis, M.: A survey on clustering algorithms for wireless sensor networks. Comput. Commun. 30(14–15), 2826–2841 (2007)
Singla, S., Kaur, K.: Comparative analysis of homogeneous N heterogeneous protocols in WSN. Int. J. Sci. Res. 5(6), 1300–1305 (2016)
Vrinda, G., Rajoo, P.: An improved energy aware distributed unequal clustering protocol for heterogeneous wireless sensor networks. Eng. Sci. Technol. Int. J. 19(2), 1050–1058 (2016)
Pradhan, S., Sharma, K.: Cluster head rotation in wireless sensor network: a simplified approach. Int. J. Sens. Appl. Control Syst. 4(1), 1–10 (2016)
Baranidharan, B., Santhi, B.: DUCF: distributed load balancing unequal clustering in wireless sensor networks using fuzzy approach. Appl. Soft Comput. 40, 495–506 (2016)
Chaubey, N.K., Patel, D.H.: Energy efficient clustering algorithm for decreasing energy consumption and delay in wireless sensor networks (WSN). Int. J. Innov. Res. Comput. Commun. Eng. 4(5), 8652–8656 (2016)
Nagamalar, T., Rangaswamy, T.R.: Energy efficient cluster based approach for data collection in wireless sensor networks with multiple mobile sink. In: 2015 International Conference on Industrial Instrumentation and Control (ICIC) 348–353 (Pune, 2015)
Bala Krishna, M., Doja, M.N.: Self-organized energy conscious clustering protocol for wireless sensor networks. In: 2012 14th International Conference on Advanced Communication Technology (ICACT) 521–526 (PyeongChang, 2012)
Razaque, A., Abdulgader, M., Joshi, C., Amsaad, F., Chauhan, M.: P-LEACH: energy efficient routing protocol for wireless sensor networks. In: 2016 IEEE Long Island Systems, Applications and Technology Conference (LISAT) 1–5 (Farmingdale, NY, 2016)
Razaque, A., Mudigulam, S., Gavini, K., Amsaad, F., Abdulgader, M., Krishna, G.S.: H-LEACH: hybrid-low energy adaptive clustering hierarchy for wireless sensor networks. In: 2016 IEEE Long Island Systems, Applications and Technology Conference (LISAT) 1–4 (Farmingdale, NY, 2016)
Singh, M., Soni, G.S., Kumar, V.: Clustering using fuzzy logic in wireless sensor networks. In: 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom) 1669–1674 (New Delhi, 2016)
Nguyen, T.G., So-In, C., Nguyen, N., Phoemphon, S.: A novel energy-efficient clustering protocol with area coverage awareness for wireless sensor networks. Peer-to-Peer Netw. Appl. 10, 1–18 (2016)
Tang, C., Yang, N.: Virtual grid margin optimization and energy balancing scheme for mobile sinks in wireless sensor networks. Multimed. Tools Appl. 76, 1–20 (2016)
Latiff, N.M.A., Malik, N.N.N.A., Idoumghar, L.: Hybrid backtracking search optimization algorithm and K-means for clustering in wireless sensor networks. In: 2016 IEEE 14th International Conference on Dependable, Autonomic and Secure Computing, 14th International Conference on Pervasive Intelligence and Computing, 2nd International Conference on Big Data Intelligence and Computing and Cyber Science and Technology Congress (DASC/PiCom/DataCom/CyberSciTech) 558–564 (2016)
Heinzelman, W.B., Chandrakasan, A.P., Balakrishnan, H.: An application-specific protocol architecture for wireless microsensor networks. IEEE Trans. Wirel. Commun. 1(4), 660–670 (2002)
Coyle, E.J., Bandyopadhyay, S.: An energy efficient hierarchical clustering algorithm for wireless sensor networks. In: IEEE INFOCOM 2003. Twenty-second Annual Joint Conference of the IEEE Computer and Communications Societies (IEEE Cat. No. 03CH37428), vol. 3, pp. 1713–1723 (2003)
Fahmy, S., Younis, O.: HEED: a hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Trans. Mobile Comput. 3(4), 366–379 (2004)
Yulin, S., Xiangning, F.: Improvement on LEACH protocol of wireless sensor network. In: 2007 International Conference on Sensor Technologies and Applications (SENSORCOMM 2007) 260–264 (Valencia, 2007)
Kim, J.M., Park, S.H., Han, Y.J., Chung, T.M.: CHEF: cluster head election mechanism using fuzzy logic in wireless sensor networks. In: 2008 10th International Conference on Advanced Communication Technology 654–659 (Gangwon-Do, 2008)
Chen, G., Li, C., Ye, M., Jie, W.: An unequal cluster-based routing protocol in wireless sensor networks. Wirel. Netw. 15(2), 193–207 (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Kalla, N., Parwekar, P. (2018). A Study of Clustering Techniques for Wireless Sensor Networks. In: Satapathy, S., Bhateja, V., Das, S. (eds) Smart Computing and Informatics . Smart Innovation, Systems and Technologies, vol 77. Springer, Singapore. https://doi.org/10.1007/978-981-10-5544-7_46
Download citation
DOI: https://doi.org/10.1007/978-981-10-5544-7_46
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-5543-0
Online ISBN: 978-981-10-5544-7
eBook Packages: EngineeringEngineering (R0)