
Abstract
Sensor nodes are deployed over specific critical area for gathering environmental data. These sensor nodes are constrained with low battery energy without any external power supply feasibility, minimal computational ability, and narrow communication bandwidth. However, in wireless sensor networks (WSN), the cluster (group)-oriented route mechanisms are applied to decrease extra power usages and hence extend the live period (lifetime) of the network. Here, in this research article, we suggest a routing method, namely energy-efficient dual alternate cluster head-based approach (DACH) where we consider two nodes in a single cluster to perform the cluster head role to balance the data gathering and network transmission load. Again, to access the effectiveness of the proposed approach, we show the analyzed result through simulation and mathematical studies.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
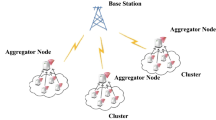
The microsensors are nowadays inexpensive due to the technological advancement, and hence, it could be deployed over a large area where the periodic maintenance is almost impossible. These sensors are low power and low communication range, so it is very much necessary to deploy the sensors with moderate or high density so that they connect with each other (low connectivity range) to set up and maintain the network infrastructure among themselves [1]. The small and large number of nodes, with limited battery capacity [2], gather the target facts and forward the same toward the base station (BS) (refer Fig. 1). The BS processes data and directs it to other networks, e.g., Internet for further analysis and study.

Typical wireless sensor network environment
This article is structured as mentioned here. Section 2 shows the review of the radio models and the related works. We debate our proposed routing approach in Sect. 3. We present mathematical analysis of cluster-based routing protocol and our DACH-based routing approach in Sect. 4. In Sect. 5, the simulation study is presented. And we conclude our work in conclusion section.
2 Existing Related WSN Routing Protocols and Issues
There are four major components in the wireless sensor nodes [3], e.g., sensor, processing, communication, and power. To work these components appropriately, there is a power unit which supplies the power to all other units. The radio model in [4] evaluates the power consumed in both sending and receiving a message of k-bits through a d-unit of distance. Below equations provide the sender’s power consumption and the power consumption of receiver node.
- \( \in_{\text{te}} \) :
-
power consumption in transmitter circuitry
- \( \in_{\text{r}} \) :
-
power consumption in receiver circuitry
- \( \in_{\text{ta}} \) :
-
power required for amplifier in transmitter unit
2.1 Low-Energy Adaptive Clustering Hierarchy (LEACH)
Low-energy adaptive clustering hierarchy (LEACH) [4] is built on the clustering hierarchy design model. The whole set of WSNs are organized and form number of groups called clusters. There is a head node in each group which is chosen by cluster members. This head node accepts the data from group members, fuses it, and then forwards to the next device (nodes) in the path toward the base station. There is a cluster network setup and election process to elect the new cluster head periodically.
2.2 Power-Efficient Gathering in Sensor Information Systems (PEGASIS)
This protocol [5] is based on a chain mechanism and does not form cluster like LEACH protocol. The sensor node communicates with its nearest nodes. The nearest nodes which receive the information again transfer the message to their nearest nodes and so on.
2.3 LEACH and PEGASIS Issues
LEACH is having a better performance over the flooding-based protocols [6], and the few limitations are as follows.
-
a.
Unbalanced energy load: Single cluster head per cluster.
-
b.
More transmission distance: send to CH instead of nearest neighbor.
PEGASIS is a well-balanced protocol and has better performance with respect to flooding-based protocols, and some of the limitations [5] are as follows.
-
a.
Unawareness of energy status: no awareness of nearest node’s energy level.
-
b.
More transmission distance: nearest neighbor chain, no specific route.
3 Our Proposed Dual Alternate Cluster Head Approach
As we see in above section, the devices in group (cluster)-based protocols transfer the gathered information to head node, and cluster head now collects the information from all its cluster member devices and transfers it to BS to complete the data transmission. In multi-hop transmission, the cluster head (CH) forwards the data to BS through intermediate device(s) and their corresponding cluster head(s) (shown in Fig. 2). In our proposed energy-efficient dual alternate cluster head routing (DACH) approach, an additional cluster head within the cluster, which would be a device located in the BS path, shares the data gathering and transmission load of cluster head.

Conventional single cluster head-based data transmission
The nodes which are located close to the additional (alternate) group head transmit the information to additional cluster head in place of transmitting data to primary head node, as displayed in Fig. 3. The main idea of introducing an additional head node (group or cluster head) is to balance the data gathering and transmission load and to elongate the live period of the network.

DACH routing-based data transmission
The proposed approach is being initially applied in a restricted environment where all individual devices in the group are assumed to sense different information of the environment, i.e., the data collected by different nodes present in the cluster are mutually exclusive. The considerations of the data, collected by sensor nodes, which are not mutually exclusive, are left for our future research work. The goal of DACH approach is to reduce the power absorption in information communication period.
Also, it avoids a frequent cluster head selection to some extent, as the additional cluster head can carry forward the data transmission for some more periods. As shown in Fig. 4, the remaining power (often denoted as residual energy, i.e., RE) of the primary cluster head \( ( {E_{\text{r}}^{{c_{1} }} } ) \) is compared with the threshold (edge) energy (ξ).

DACH approach—a typical process flow
The ξ is the minimum energy required to actively play the role of cluster head. If the head node is not able to play the role of a cluster head, then the RE of the additional head node is compared with the edge energy (ξ). Here, the additional cluster head can transmit the data for more time before the network proceeds for network setup phase, where all nodes exchange the information for the cluster head selection.
In general, it is true that out of the two cluster heads (primary and alternate), one will fall in one’s routing path to base station, as all devices in a group send their information to base station through the group head. In our approach, we have taken a use case (scenario 1) of keeping the alternate cluster head as an intermediate node in routing path of primary group head to BS. In similar fashion, the other case (scenario 2), i.e., keeping primary cluster head as an intermediate node in the alternate cluster head’s routing path, could also be shown. In this paper, we have considered scenario 1 for the mathematical analysis and network simulation.
The proposed approach has an alternate cluster head along with a group head in each group (cluster). This approach is different than two cluster (group) heads in two clusters in the following ways.
-
1.
Alternate cluster head is a backup or secondary cluster head in the same cluster whereas all earlier approach has a single cluster head in a cluster.
-
2.
DACH avoids frequent complex network setup phases. In DACH approach, the secondary cluster will become the primary cluster and select another alternate group head within the group, and the network continues to work till both CHs (primary and alternate) die.
-
3.
Multiple granular clusters (small-sized and many clusters) have network complexity and maintenance of routing tables which reduced in this DACH approach.
-
4.
Target object property sensing (data capture) and data integration within a cluster by alternate CH and primary CH become easy than two different CHs in two different clusters (two different object visibilities).
Lemma 1
For two mutually exclusive property message sets, the combined property message size is equal to the sum of the individual property message size.
Proof
Let the two property message sets be
As \( M_{1} \) and \( M_{2} \) are mutually exclusive, so \( M_{2} \cap M_{2} = \oslash \), and hence, \( \left| {M_{2} \cap M_{2} } \right| = 0 \).
So, the combined message size is given by
Lemma 2
If the additional cluster head \( ( {c_{2} } ) \) is located on the path to base station from the cluster head (c), then the distance \( ( {d_{{c_{2} ,b}} } ) \) between \( c_{2} \) and BS is less than or equal to the distance \( ( {d_{c,b} } ) \) between the cluster head and base station, i.e., \( d_{{c_{2} ,b}} \le d_{c,b} . \)
Proof
As the additional cluster head is on the path to BS from CH, so
-
Case I
-
if \( c = c_{2} \), then \( d_{{c,c_{2} }} = 0 \). So \( d_{c,b} = d_{{c_{2} ,b}} . \)
-
-
Case II
-
if \( c \ne c_{2} \), then \( d_{{c,c_{2} }} > 0 \). So \( d_{{c_{2} ,b}} < d_{c,b} . \)
-
So, combining Case I and Case II, we conclude \( d_{{c_{2} ,b}} \le d_{c,b} . \)
The sensor nodes, which perform the role of CH and the additional CH, execute the algorithm 1 (executeDACHForCH). The cluster heads receive the gathered information from the devices, combine the information, and transfer to BS. If the node plays the role of primary cluster head, then it sends the combined information to the additional CH \( c_{2} \), and \( c_{2} \) finally sends information to BS. However, in every iteration of data transmission, the residual power of the CH is compared with the threshold (ξ) value, and then, setup phase is called, if required.

Algorithm 2 describes the network setup process to elect cluster head and select alternate cluster head for our proposed DACH approach.

4 Mathematical Analysis
Let us consider we have a multiple group formed in a sensor node network which is deployed arbitrarily. The following are some of the mathematical symbols used in our analysis.
- \( d_{cj} \) :
-
remoteness (distance) between CH and jth node.
- \( d_{{c^{\prime } j}} \) :
-
remoteness between jth device and the next hop cluster head \( c^{\prime } \).
- n :
-
device counts in the group (cluster).
- \( \in_{\text{te}} , \in_{\text{ta}} \) :
-
device’s radio transmitter power and transmitter amplifier energy.
- \( \in_{\text{r}} \) :
-
device’s radio receiver power.
- \( p_{d} ,p_{cd} ,p_{{cd^{\prime } }} \) :
-
size of data (information) packets for single, \( ( {n - 1} ) \), and \( ( {n - 2} ) \) aggregated data packet, respectively.
- \( \Psi _{f}^{t} ,\Psi _{f}^{r} ,\Psi _{f} \) :
-
transmitting energy, receiving energy, and combined energy for flooding-based routing.
- \( \Psi _{d,c}^{t} ,\Psi _{d,c}^{r} ,\Psi _{d,c} \) :
-
energy dissipated for transmitting, receiving, and total energy for DACH approach with cluster head as c.
As per the Dijkstra’s algorithm, the minimum path is
For \( p_{d} \)-sized data packet to send, energy consumption in cluster head is given by
Similarly, energy required for \( ( {n - 1} ) \) number of receiving packets with \( p_{d} \) size and again for forwarding combined \( p_{cd} \)-sized packets to base station is given by
Again, in case of multi-hop communication
So, in the mth cluster, the overall energy consumed by all nodes is
where \( \in_{d}^{\prime } = \left[ {\left( {n - 1} \right)\left( { \in_{\text{te}} + \in_{\text{r}} } \right) + \in_{\text{ta}} \sum d_{cj}^{2} } \right] \) and \( \in_{cd}^{\prime } = \left[ { \in_{\text{te}} + \in_{\text{ta}} d_{cb}^{2} } \right]. \)
Now, in a proposed DACH approach, let \( ( {m - 1} ) \) count of devices are close to the CH \( c_{1} \) and \( ( {l - 1} ) \) count of devices are close to the CH \( c_{2} \), i.e., now, the energy dissipated by all \( ( {m - 1} ) \) number of nodes is given by
So, the total energy consumed by the \( ( {m - 1} ) \) number of devices with primary CH \( c_{1} \) is
Similarly, the energy equation for the \( ( {l - 1} ) \) number of devices which are close to the additional CH \( c_{2} \) is given by
and
So, the total energy consumed by the \( ( {l - 1} ) \) number of devices with additional CH \( c_{2} \) is
Hence, the energy consumed by the \( ( {m + l} ) \) number of devices with primary CH \( c_{1} \) and additional CH \( c_{2} \) is given by
where
So, if we compare the above expression, we have \( {\Psi}_{f} > {\Psi}_{d} \); as from Theorem 3, we have \( p_{{c_{1} d}} d_{{c_{1} b}}^{2} + p_{{c_{2} d}} d_{{c_{2} b}}^{2} \le p_{cd} d_{cb}^{2} \) and from Theorem 4 we have
Hence, we mathematically found that the energy dissipated by a single cluster head is more than the energy dissipated in the DACH approach.
Theorem 3
For two mutually exclusive property messages with size \( p_{{c_{1} d}} \) and \( p_{{c_{2} d}} \), the sum of the cluster heads and base station distance square multiplied with the respective message size is less than the primary cluster head and base station distance square multiplied with the combined property message with size \( p_{cd} \), i.e., \( p_{{c_{1} d}} d_{{c_{1} b}}^{2} + p_{{c_{2} d}} d_{{c_{2} b}}^{2} \le p_{cd} d_{cb}^{2} . \)
Proof
As the CH (c) is assumed as the primary CH in our proposed DACH approach, so \( c = c_{1} \). Hence, \( d_{{c_{1} b}}^{2} = d_{cb}^{2} \), and from Lemma 2, we have \( d_{{c_{2} b}} < d_{cb} \).
So,
where from Lemma 1, we have \( p_{cd} = p_{{c_{1} d}} + p_{{c_{2} d}} . \)
Theorem 4
If \( d_{{c_{1} j}} \) and \( d_{{c_{2} j}} \) be the distances (remoteness) from the jth node to CH \( c_{1} \) and \( c_{2} \) , respectively, \( ( {{\text{m}} - 1} ) \) and \( ( {{\text{l}} - 1} ) \) are the number of nodes close to CHs \( c_{1} \) and \( c_{2} \) , and then,
where \( n = ( {m + l} ). \)
Proof
Let \( c = c^{\prime} \). So,
Now, if we consider \( c = c_{1} \) and \( c^{\prime } = c_{2} \) as the nodes which are nearer to additional cluster head, \( c_{2} \) transfers the data to CH \( c_{2} \) rather than sending to the primary cluster head \( c_{1} (d_{{c_{1} j}} \ge d_{{c_{2} j}} ) \), for all jth nodes those are in close proximity of the additional CH \( (c_{2} ) \). So
Hence, the inequality holds true.
5 Simulation
In the simulated environment study, the below limit values have been taken to replicate the flooding-based route protocol, LEACH, and PEGASIS route mechanism versus DACH route mechanism.
-
a.
Every device has initial residual energy 1 J.
-
b.
\( \in_{\text{r}} = 50\,{\text{nJ}}/{\text{bit}}\,{\text{i}}.{\text{e}}.\;50\;{\text{nJ }} \) amount of energy consumed by receiver circuitry for 1-bit data processing.
-
c.
\( \in_{\text{ta}} = 100\;{\text{pJ}}/{\text{bit}}/{\text{m}}^{2} \;{\text{i}}.{\text{e}}.\;100\;{\text{pJ }} \) amount of energy required to send/broadcast 1 bit of data in 1 m2 area by the transmit amplifier.
-
d.
\( \in_{\text{te}} = 100\;{\text{pJ}}/{\text{bit}}\;{\text{i}}.{\text{e}}.\;100\;{\text{pJ }} \) amount of energy required to receive 1 bit of data by the receiving amplifier.
-
e.
Base station location \( \left( {x,y} \right) = \left( {{\text{random}},{\text{random}}} \right). \)
-
f.
Size of the data packets \( p_{d} = 1000\,{\text{bits}} . \)
-
g.
Magnitude of the combined packet
-
i.
\( p_{cd} = {\text{random}} \le \left( {n - 1} \right).1000. \)
-
ii.
\( p_{cd} = {\text{random}} \le \left( {n - 2} \right).1000. \)
-
i.
-
h.
Network coverage area of each device = 7.25 m.
The sensor devices are deployed haphazardly as we have taken the random values for the sensor nodes’ coordinates. For cluster (group) formation, we have considered the network coverage and number of nodes present inside the wireless coverage area. To find the cluster head, we select the node which can communicate maximum number of nodes available inside its wireless coverage area. The RE of the devices vs the network live period is displayed below (refer Fig. 5a) (60 nodes deployed over 100 × 100 Sq. unit area) and Fig. 5b (150 nodes deployed over 120 × 120 Sq. unit area). We observed that our proposed DACH scheme is providing approximately 1.2–1.5 times more lifetime to the network in both scenarios.

a RE versus life period of network for DACH versus LEACH and flood based for 60 devices on 100 × 100 Sq. area. b RE versus life period of network for DACH versus LEACH and flood based for 150 devices on 120 × 120 Sq. unit area
Similarly, in case of PEGASIS, we have 120 nodes installed on 80 × 80 unit square area (Fig. 6a) and 200 nodes installed on 150 × 150 square unit area (Fig. 6b). In both the scenarios, PEGASIS has a significant more lifetime over the flooding-based approach and our proposed DACH approach is adding approximately 0.28–0.38 times more network lifetime over PEGASIS. Though PEGASIS is a chain-based protocol, its nearest neighbor broadcast mechanism consumes more energy. In DACH, devices transmit the information packets to the group heads (primary or alternate) instead of broadcast the data packet, and DACH shares the load between primary and alternate cluster heads. The simulation depicts that though LEACH and PEGASIS have more network lifetime over the flooding-based routing approach, DACH approach is giving an improved performance in conserving the residual energy.

a RE versus life period of network for DACH versus PEGASIS and flood based for 120 devices on 80 × 80 unit Sq. area b RE versus life period of network for DACH versus PEGASIS and flood based for 200 devices on 150 × 150 unit Sq. area
6 Conclusion
Different routing techniques, e.g., flooding, LEACH, PEGASIS, are evolved to minimize the energy consumption. However, there is an energy loss in transmitting the data to a CH which is in a more distance than the alternate cluster head in the same group. The DACH mechanism is an attempt to decrease the transmission energy and to share and balance the information gathering and data transmission load with the primary cluster head. Our mathematical observation shows that DACH approach is conserving more power than the cluster-based routing approach. The simulation results show the effectiveness of the proposed DACH protocol’s performance for the energy conservation. This approach could now be applied and integrated into other clustering-based routing protocol to manage the sensor device power effectively and to extend the sensor network lifetime. The more relevant mechanism, e.g., neural network in primary cluster head and alternate cluster head selection process, is our future scope of work.
References
Kamila, N.K., Dhal, S.,: Overview of WSN Infrastructure Models, Design & Management, In: International Journal on Recent and Innovation Trends in Computing and Communication (IJRITCC), vol 3, Issue 3, pp. 9–13 (2016).
Kamila, N.K., Dhal, S., Samantaray, A.K.,: A Survey of Neural Network Energy Efficiency Management in Wireless Sensor Networks, In: International Journal of Applied Engineering Research (IJAER), vol 10, Number 21, pp. 42023–42036 (2015).
Muruganat, S.D.,: A Centralized Energy-E_client Routing Protocol for Wireless Sensor Networks, In: IEEE Radio Communications, vol 43, pp. 8–13 (2005).
Heinzelman, W.R., Chandrakasan, A., Balakrishnan, H.: Energy-Efficient Communication Protocol for Wireless Microsensor Networks, In: Proceedings of the 33rd Hawaii International Conference on System Sciences, pp. 1–10 (2000).
Lindsey, S., Raghavendra C.S.,: PEGASIS: Power-Efficient Gathering in Sensor Information Systems, In: IEEE Aerospace Conference Proceeding (2002).
Intanagonwiwat, C., Govindan, R., Estrin, D.,: Directed diffusion: a scalable and robust communication paradigm for sensor networks, In: Proceedings of ACM MobiCom (Boston, MA), pp. 56–67 (2000).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper
Cite this paper
Kamila, N.K., Dhal, S. (2018). An Energy-Efficient Dual Alternate Cluster Head-Based Routing Mechanism in Wireless Sensor Network. In: Mishra, D., Azar, A., Joshi, A. (eds) Information and Communication Technology . Advances in Intelligent Systems and Computing, vol 625. Springer, Singapore. https://doi.org/10.1007/978-981-10-5508-9_5
Download citation
DOI: https://doi.org/10.1007/978-981-10-5508-9_5
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-5507-2
Online ISBN: 978-981-10-5508-9
eBook Packages: EngineeringEngineering (R0)