
Abstract
Under-determined Independent Component Analysis arises in a variety of signal processing applications, including speech processing. In this paper, we proposed a new approach focusing on the estimation of the number of columns and their values of the mixing matrix. The method is based on the observation that the observed vectors must be clustered along the direction of the column vectors of the mixing matrix. A new clustering measure and cluster direction finding are introduced. The propose algorithms are tested with real speech signals and compared with both AICA method and Information Index Removal, Perturbed Mean Shift Algorithm. Our result gives the correct number of columns with higher accuracy under the performance measure of algebraic matrix distance index.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

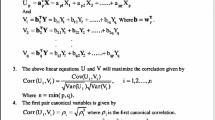
Keywords
- Independent component analysis
- Under-determined ICA
- Blind source separation
- Linear transformation
- Sparse representation
1 Introduction
Knowledge of Independent Component Analysis (ICA) has a great importance for potential speech signal processing, brain signal processing, feature extraction, and acoustic processing. Defined ICA is very closely related to the method called Blind Source Separation (BSS). ICA problem arises in many application domains, such as speech separation, array antenna processing, multi-sensor biomedical records and financial data analysis [1]. Blind Source Separation was using a two stage sparse representation approach and presented an algorithm for estimating the mixing matrix [2]. The over-complete were introduced that the source separation problem consist of estimating the original sources, the observed signals, then were introduced the over-complete source separation case where there are the mixture less than source signals [3]. A novel BSS algorithm for de-mixing under-determined presented anechoic mixtures [4].
In this paper, we proposed a new method to find the number of columns in the mixing matrix and estimated the value of each element. The remainder of this paper has the following structure. Section 2 describes the problem with constraints. Section 3 focuses on the main idea and the detail of the proposed algorithms. The experimental result is presented in Sect. 4. Section 5 concludes the paper.
2 Problem Statement
Under-determined ICA is considered in this paper. Let \( {\mathbf{S = [s}}_{{\mathbf{1}}} ,s_{2} , \ldots ,s_{N} {\mathbf{]}}^{T} \in R^{m \times T} \) and \( {\mathbf{X}} = \left[ {x_{1} ,x_{2} , \ldots ,x_{M} } \right]^{T} \in {\mathbf{R}}^{n \times M} \) be the source signals of n dimensions and observed signals of m dimensions, respectively. Each observed signal xi is computed by using a mixing matrix \( {\mathbf{A}} = \left[ {a_{1} ,a_{2} , \ldots ,a_{m} } \right] \in {\mathbf{R}}^{n \times m} \) for n < m as follows.
The source signals are based on the sparseness assumption [5]. The problem of how to recover the source signals after estimating the mixing matrix will not be considered here. However, we adopted the recovering method from [6].
3 Main Concept and Algorithms
Our method to find the columns of mixing matrix A is based on this simple observation. Let X = [xi,1, xi,2,…,x i,3]T be an observed signal i for 1 <= i <= n in a p-dimensional space. The mixing matrix A maps each incoming signal si to a new location considered as an observed signal xi in lower dimensions. An observed signal can be viewed as a vector. These observed vectors are clustered along each new independent basis represented by each column vector of mixing matrix A. Therefore, to compute each column vector of A, a new similarity measure for all observed vectors clustered at any column must be introduced. Our method consists of the following main steps.
-
1.
Computing the direction of each observed vector \( x_{i} \) in terms of radian degrees.
-
2.
Grouping all observed vectors based on their directions computed from Step 1.
-
3.
Finding the direction of each group and use it as a column vector of the mixing matrix A.
In this paper, we consider only the case where the observed vectors are in two dimensions. Hence, Xi = [xi,1, xi,2]T. The detail of the first two steps is given in the following Algorithm.
3.1 Grouping Observed Vectors Algorithm

Variable group in the algorithm is for counting the total number of groups. After grouping the observed vectors according to their radian degrees, the actual direction of each group will be derived and used as the column vector in mixing matrix A. Not every group generated by Grouping Observed Vectors Algorithm is feasible enough to derive a column vector in mixing matrix A. Only the group with high density of clustering will be selected. The detail of how to find the actual column of mixing matrix A is the following.
3.2 Finding Actual Column Algorithm

Steps 4 and 5 are used to measure the density of clustering of each group. The eigenvectors extracted from steps 10 in Finding Actual Column Algorithm above are used as column vectors in mixing matrix A. Figure 1 shows an example as the result of the above algorithms. Figure 1a is the observed vectors. After being grouped by Grouping Observed Vectors Algorithm, Fig. 1b is obtained. The actual column vectors of the mixing matrix are shown in Fig. 1c.

An example of the result from the proposed algorithm. a The given synthetic observed vectors. b The result after grouping. c The computed eigenvectors which are used as column vectors in the mixing matrix
4 The Experimental Results
The algorithms are tested with a real speech as shown in Fig. 2a. There are three sources of signals and two observed signals. The source signals are mixed by using the following mixing matrix.

The tested data. a Three given source signals. b Two observed signals. c The distribution plot of observed vectors
The wave form of each observed signal is shown in Fig. 2b. The distribution of both observed vectors are plotted as shown in Fig. 2c. After applying Grouping Observed Vectors Algorithm to all observed vectors, three groups are obtained as shown in Fig. 3a. The direction of each eigenvector in each group is computed and illustrated in Fig. 3b. Our result was compared with the results produced by AICA method [7] and the Information Index Removal and Perturbed Mean Shift Algorithm [8]. To measure the accuracy of the estimated mixing matrix, Algebraic Matrix-Distance Index (AMDI) [7] was used. The following matrix is the result from our algorithms. Table 1 summarizes the accuracy of each method.

The result from our algorithm. a Groups of observed vectors in the experiment obtained after applying Grouping Observed Vectors Algorithm. b The direction of each eigenvector in each group
5 Conclusions
This paper presents a new approach for de-mixing mixtures under-determined Independent Component Analysis. This technique is based on the observation that the observed vectors usually clustered along the direction of column vectors in the mixing matrix. Our algorithms can find the correct number of column vectors in the mixing matrix with the lowest AMDI value. However, a further modification must be studied to scope with higher dimensional signals.
References
Chinnasarn, K., Lursinsap, C., Palade, V.: Blind separation of mixed kurtosis signed signals using partial observations and low complexity activation functions. Int. J. Comput. Intell. Appl. 4, 207–223 (2004)
Yuanqing, L., Amari, S., Cichocki, A., Daniel, W.C.H., Shengli, X.: Under-determined blind source separation based on sparse representation. IEEE Trans. Signal Process. 54, 423–437 (2006)
Mitianoudis, N., Stathaki, T.: Over-complete source separation using laplacian mixture models. IEEE Signal Process. Lett. 12, 277–280 (2005)
Rayan, S., Yilmaz, O., Martin, J.M., Rafeef, A.: Blind separation of anechoic under-determined speech mixtures using multiple sensors. In: IEEE International Symposium on Signal Processing and Information Technology (2006)
Paul, D.O., Barak, A.P.: The LOST algorithm: finding lines and separating speech mixtures. EURASIP J. Adv. Signal Process. 2008,784296 Hindawi Publishing Corporation (2008)
Steven, V.V., Ignacio, S.: A spectral clustering approach to under-determine postnonlinear blind source separation of sparse sources. IEEE Trans. Neural Netw. 17, 811–814 (2006)
Khurram, W., Fathi, M.S.: Algebraic independent component analysis: an approach for separation of over-complete speech mixtures. In: IEEE-INNS Joint International Conference on Neural Networks (2003)
Panyangam, B., Chinnasarn, K., Lursinsap, C.: Estimating columns of under-determined mixing matrix by information index removal and perturbed mean shift algorithm. In: IEEE Third International Conference on Natural Computation (2007)
Acknowledgments
The Commission on Higher Education, Thailand for supporting by grant fund under the program Strategic Scholarships for Frontier Research.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2012 Springer Science+Business Media Dordrecht
About this paper
Cite this paper
Saengpratch, C., Lursinsap, C. (2012). Estimating Number of Columns in Mixing Matrix for Under-Determined ICA Using Observed Signal Clustering and Exponential Filtering. In: Yeo, SS., Pan, Y., Lee, Y., Chang, H. (eds) Computer Science and its Applications. Lecture Notes in Electrical Engineering, vol 203. Springer, Dordrecht. https://doi.org/10.1007/978-94-007-5699-1_26
Download citation
DOI: https://doi.org/10.1007/978-94-007-5699-1_26
Published:
Publisher Name: Springer, Dordrecht
Print ISBN: 978-94-007-5698-4
Online ISBN: 978-94-007-5699-1
eBook Packages: Computer ScienceComputer Science (R0)