
Abstract
This contribution is a sequel of the report (Bompard et al. in http://hal.inria.fr/inria-00526558/en/, 2010). In PDE-constrained global optimization (e.g., Jones (in J. Global Optim. 21(4):345–383, 2001)), iterative algorithms are commonly efficiently accelerated by techniques relying on approximate evaluations of the functional to be minimized by an economical but lower-fidelity model (“meta-model”), in a so-called “Design of Experiment” (DoE) (Sacks et al. in Stat. Sci. 4(4):409–435, 1989). Various types of meta-models exist (interpolation polynomials, neural networks, Kriging models, etc.). Such meta-models are constructed by pre-calculation of a database of functional values by the costly high-fidelity model. In adjoint-based numerical methods, derivatives of the functional are also available at the same cost, although usually with poorer accuracy. Thus, a question arises: should the derivative information, available but known to be less accurate, be used to construct the meta-model or be ignored? As the first step to investigate this issue, we consider the case of the Hermitian interpolation of a function of a single variable, when the function values are known exactly, and the derivatives only approximately, assuming a uniform upper bound ϵ on this approximation is known. The classical notion of best approximation is revisited in this context, and a criterion is introduced to define the best set of interpolation points. This set is identified by either analytical or numerical means. If n+1 is the number of interpolation points, it is advantageous to account for the derivative information when ϵ≤ϵ 0, where ϵ 0 decreases with n, and this is in favor of piecewise, low-degree Hermitian interpolants. In all our numerical tests, we have found that the distribution of Chebyshev points is always close to optimal, and provides bounded approximants with close-to-least sensitivity to the uncertainties.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

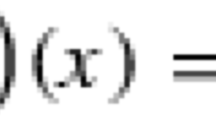
Keywords
- Interpolation Point
- Interpolation Error
- Optimal Distribution
- Hermitian Interpolation
- Interpolation Condition
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction: The Classical Notion of Best Approximation
In this section, we review certain classical notions on polynomial interpolation, in particular the concept of “best approximation” or “Chebyshev economization”. The literature contains numerous elementary and advanced texts on this fundamental issue, and we refer to [2, 4, 5].
Let n be an integer and x 0,x 1,…,x n be n+1 distinct points of the normalized interval [−1,1]. Let π(x) be the following polynomial of degree n+1:
and consider the following n+1 polynomials of degree n:
Clearly
where δ stands for Krönecker’s symbol. Application of L’Hospital’s rule yields the following compact formula:
Let f:[−1,1]→ℝ be a smooth function of the real variable x. The polynomial
is of degree at most equal to n, and it clearly satisfies the following interpolation conditions:
One such interpolant is unique among all polynomials of degree ≤n. Thus, P n (x) is the Lagrange interpolation polynomial of f at the points {x i }0≤i≤n .
It is well known that if f∈C n+1([−1,1]), for any given x∈[a,b], the interpolation error is given by
for some ξ∈[−1,1].
Proof
Let x∈[−1,1] be given. If x=x i for some i, the result is trivially satisfied. Otherwise, π(x)≠0; then let
so that
and define the function
The function ϕ(t) is of class C n+1([−1,1]) and it admits a nonempty set of roots in the interval [−1,1] that includes X={x 0,x 1,…,x n ,x}. The n+2 elements of X are distinct and can be arranged as the elements of a strictly increasing sequence \(\{ x_{i}^{0} \}_{0 \leq i \leq n+1}\) whose precise definition depends on the position of x w.r.t. the interpolation points {x i }0≤i≤n . By application of Rolle’s theorem to ϕ(t)=ϕ (0)(t) over the subinterval \([ x_{i}^{0},x_{i+1}^{0}]\), i=0,1,…,n, it follows that ϕ′(t) admits a root \(x_{i}^{1}\) in the open interval \(]x_{i}^{0},x_{i+1}^{0}[\), and this, for each i. In this way we identify a strictly-increasing sequence of n+1 roots of ϕ′(t), \(\{ x_{i}^{1} \}_{0 \leq i \leq n}\). Then Rolle’s theorem can be applied in a similar way, this time to ϕ′(t), and so on to the successive derivatives of ϕ(t). We conclude that in general ϕ (k)(t) admits at least n+2−k distinct roots in [−1,1], \(\{ x_{i}^{k} \}_{0 \leq i \leq n+1-k}\), 0≤k≤n+1. In particular, for k=n+1, ϕ (n+1)(t) admits at least one root, \(x_{0}^{n+1}\), hereafter denoted ξ for simplicity. But since \(P_{n}^{(n+1)} (\xi)=0\) and π (n+1)(ξ)=(n+1)!, one gets
and the conclusion follows. □
Hence, if
we have
Therefore, a natural way to optimize the choice of interpolation points a priori, that is, independently of f, is to solve the following classical min-max problem:
In view of this, the problem is to find among all polynomials π(x) whose highest-degree term is precisely x n+1, and that admit n+1 distinct roots in the interval [−1,1], an element, unique or not, that minimizes the sup-norm over [−1,1].
The solution of this problem is given by the n+1 roots of the Chebyshev polynomial of degree n+1. Before recalling the proof of this, let us establish some useful auxiliary results. Let k be an arbitrary integer and T k (x) denote the Chebyshev polynomial of degree k. Recall that for x∈[−1,1]
so that, for k≥1 and x∈[−1,1],
where one has let
Thus, if the leading term in T k (x) is say a k x k, the following recursion applies:
and, since a 0=a 1=1, it follows that
Therefore, an admissible candidate solution for the min-max problem, (11.2), is the polynomial
It remains to establish that π ⋆(x) is the best choice among all admissible polynomials, and its roots the best possible interpolation points. To arrive at this, we claim the following lemma:
Lemma 11.1
For all admissible polynomial q(x) one has
where ∥ ∥ is the sup-norm over [−1,1].
Proof
Assume otherwise that an admissible polynomial q(x) of a strictly smaller sup-norm over [−1,1] exists:
Let r(x)=π ⋆(x)−q(x). Since the admissible polynomials π ⋆(x) and q(x) have the same leading term, x n+1, the polynomial r(x) is of degree at most n. Let us examine the sign of this polynomial at the n+2 points
at which π ⋆(x) as well as T n+1(x) achieve a local extremum. At such a point,
and r(η i ) is nonzero and has the sign of the strictly dominant term \(\pi^{\star}(\eta_{i})=\frac{1}{2^{n}} \, T_{n+1}(\eta_{i})=\frac{(-1)^{i}}{2^{n}}\). Therefore, r(x) admits at least n+1 sign alternations and as many distinct roots. But this is in contradiction with the degree of this polynomial. The contradiction is removed by rejecting the assumption made on ∥q∥. □
Consequently, in (11.2), the min-max is achieved by the roots of T n+1(x):
and the value of the min-max is \(\frac{1}{2^{n}}\).
2 Best Hermitian Approximation
Now assume that the points {x i }0≤i≤n are used as a support to interpolate the function values {y i =f(x i )}0≤i≤n , but also the derivatives \(\{ y_{i}'=f'(x_{i}) \}_{0 \leq i \leq n}\), that is a set of 2(n+1) data. Thus, we anticipate that the polynomial of least degree complying with these interpolation conditions, say H 2n+1(x), is of degree at most equal to 2n+1. One such polynomial is necessarily of the form
where the quotient Q(x) should be adjusted to comply with the interpolation conditions on the derivatives. These conditions are
where
and since π(x i )=0. Thus Q(x) is solely constrained by the following n+1 interpolation conditions:
Therefore, the solution of least degree is obtained when Q(x) is the Lagrange interpolation polynomial associated with the above function values:
The corresponding solution is thus unique, and we will refer to it as the global Hermitian interpolant.
The interpolation error associated with the above global Hermitian interpolant H 2n+1(x) is given by the following result valid when f∈C 2n+2([−1,1]):
Proof
Let x∈[−1,1] be given. If x=x i for some i, the result is trivially satisfied. Otherwise, π(x)≠0; then let
so that
Let
The function ψ(t) is of class C 2n+2([−1,1]), and similarly to the former function ϕ(t), it admits a nonempty set of roots in the interval [−1,1] that includes \(X=\{x_{0},x_{1},\ldots,x_{n},x\} = \{ x_{i}^{0} \}_{0 \leq i \leq n+1}\). Hence, Rolle’s theorem implies that in the open interval ]x i ,x i+1[, 0≤i≤n, a root \(x'_{i}\) of ψ′(t) exists. But the interpolation points, at which the derivative also is fitted, are themselves n+1 other distinct roots of ψ′(t). Thus we get a total of at least 2n+2 roots for ψ′(t), and by induction, 2n+1 for ψ″(t), and so on, and finally one, say η, for ψ (2n+2)(t). Now, since \(H_{2n+1}^{(2n+2)}(\eta)=0\) because the interpolant is of degree 2n+1 at most, and since (π 2(t))(2n+2)(t)=(2n+2)!, one gets
which yields the final result. □
As a consequence of (11.8), the formulation of the best approximation problem for the global Hermitian interpolant is as follows:
But, if we define the following functions of ℝn+1→ℝ:
it is obvious that
Hence the functions P and p achieve their minimums for the same sequence of interpolation points, and
Therefore the best Hermitian interpolation is achieved for the same set of interpolation points as the best Lagrangian interpolation, that is, the roots, \(\{ x_{i}^{\star}\}_{0 \leq i \leq n}\) of (11.3), of the Chebyshev polynomial T n+1(x).
3 Best Inexact Hermitian Approximation
In PDE-constrained global optimization [3], it is often useful to model the functional criterion to be optimized by a function f(x) of the design variable x∈ℝn, whose values are computed through the discrete numerical integration of a PDE, and the derivative f′(x), or gradient vector, by means of an adjoint equation. A database of function values and derivatives is compiled by Design of Experiment, and the surrogate model, or meta-model is constructed from it. This meta-model is then used in some way in the numerical optimization algorithm with the objective of improving computational efficiency (see, for example, [3]). The success of such a strategy depends on the accuracy of the meta-model f(x) to represent the dependency on x of the actual functional criterion. If all the data were exact, and properly used, the accuracy would undoubtedly improve by the addition of the derivative information. However, in practice, since the PDE is solved discretely, the derivatives are almost inevitably computed with inferior accuracy. Therefore it is not clear that accounting for the derivatives is definitely advantageous if the corresponding accuracy of the data is poor. Should special precautions be taken to guarantee it?
In order to initiate a preliminary analysis of this problem, we examine the simple one-dimensional situation of a function f(x), when x is scalar (x∈ℝ), and consider the case of a Hermitian interpolation meta-model based on inexact information. Specifically, we assume that the function values {y i }0≤i≤n are known, whereas only approximations \(\{\bar{y}_{i}'\}_{0 \leq i \leq n}\) of the derivatives \(\{y_{i}'\}_{0 \leq i \leq n}\) are available, and we let:
Hence the computed interpolant is \(\overline{H}_{2n+1}(x)\) instead of H 2n+1(x), and in view of the definitions (11.4)–(11.7), we have
Now, suppose an upper bound ϵ on the errors ϵ i ’s is known:
The following questions arise:
-
1.
What is the corresponding upper bound on max x∈[−1,1]|δH 2n+1(x)|?
-
2.
Can we choose the sequence of interpolation points {x i }0≤i≤n to minimize this upper bound?
-
3.
Is the known sequence of the Chebyshev points a good approximation of the optimum sequence for this new problem?
This article attempts to bring some answers to these questions. Presently, we try to identify how the interpolation points should be defined to minimize or reduce the effect on the meta-model accuracy of uncertainties on the derivatives only. It follows from (11.10) that
which by virtue of (11.1) simplifies as follows:
Thus if (11.11) holds, we have
where
These considerations have led us to analyze the min-max problem applied to the new criterion Δ(x) in place of π 2(x). In summary, the solution of the min-max problem associated with the criterion Δ(x) minimizes the effect of uncertainties in the derivatives on the identification of the global Hermitian interpolant. In the subsequent sections, this solution is identified formally, or numerically, and compared with the Chebyshev distribution of points, which is optimal w.r.t. the interpolation error. Lastly, the corresponding interpolants are compared by numerical experiment.
4 Formal or Numerical Treatment of the Min-Max-Δ Problem
We wish to compare three particular relevant distributions of interpolation points in terms of performance w.r.t. the criterion Δ(x). These three distributions are symmetrical w.r.t. 0, and recall that the total number of interpolation points is n+1. Thus, we let
and when n is odd (α=0; n=2m−1≥1),
where
and m≥1. Otherwise, when n is even (α=1; n=2m≥0), we adjoin to the list ξ 0=0 (once). We consider specifically:
-
1.
The uniform distribution:
- n=2m::
-
\(\xi_{0}^{u}=0\) associated with the interpolation point x 0=ξ 0=0, and \(\xi_{k}^{u} = \frac{k}{m}\), 1≤k≤m, associated with 2 interpolation points \(\pm\xi_{k}^{u}\).
- n=2m−1::
-
\(\xi_{k}^{u}=\frac{2k-1}{n}\), 1≤k≤m.
-
2.
The Chebyshev distribution:
$$\xi_k^{\star}= x_{m-k}^{\star}= \cos \biggl( \frac{2(m-k)+1}{n+1} \, \frac{\pi}{2} \biggr), \quad1 \leq k \leq m. $$ -
3.
The optimal distribution:
$$\bar{\xi}= \operatorname {arg\,min}_{\xi} \max_{x \in[0,1]} \varDelta (x;\xi), $$where ξ=(ξ 1,ξ 2,…,ξ m ) denotes the vector of adjustable parameters defining, along with ξ 0=0 if n is even, the distribution of interpolation points, and the dependence of the criterion Δ on ξ is here indicated explicitly for clarity. (Note that due to symmetry, the interval for x has been reduced to [0,1] without incidence on the result.)
To these three distributions are associated the corresponding values of the maximum of Δ(x;ξ) over x∈[0,1]; these maximums are denoted Δ u, Δ ⋆ and \(\bar{\varDelta }\), respectively.
As a result of these definitions, the polynomial π(x) is expressed as follows:
and for x>0, the criterion Δ(x) becomes
Then, given x, let j be the index for which
so that
As a result,
Calculation of the derivatives \(\boldsymbol{\pi}^{\boldsymbol{\prime}}_{\boldsymbol{k}}\)
First, for α=0, π(x) is an even polynomial, and \(\pi'_{0}=0\). Otherwise, for α=1,
Regardless α, for k≥1
so that:
4.1 Expression of δ 0 Applicable Whenever n+1 is Even (α=0; n+1=2m)
Suppose that 0<x<ξ 1. Then j=1 and (11.12) reduces to
But,
so that
All the terms in this sum are composed of three factors: a positive constant and two positive factors that are monotone decreasing as x varies from 0 to ξ 1. Hence Δ(x) is monotone decreasing and

4.2 Expression of δ 1 Applicable Whenever ξ m <1
Suppose that ξ m <x<1. Then j=m+1 and (11.12) reduces to

All the terms in Δ(x) are products of positive factors that are monotone-increasing with x. Consequently, the maximum is achieved at x=1. But
This gives
4.3 Special Cases
For n=0,1,2, the formal treatment is given in [1].
For n=3, the four interpolation points form a symmetrical set {±ξ,±η}. Hence the optimization is made over two parameters ξ and η. Thus, the function
is defined discretely. The iso-value contours of this function are indicated in Fig. 11.1, which permits after refinement to identify the optimum ξ≈0.351 and η≈0.926.

Contour plot of function z(ξ,η) of (11.16) for n+1=4: the plot is symmetrical w.r.t. the bisecting line η=ξ, and one location of the minimum is ξ=0.351, η=0.926
For n=4, the five interpolation points form a symmetrical set 0,{±ξ,±η}. Hence the optimization is again made over two parameters ξ and η. Thus, the function z(η,η) is again defined by (11.16) and evaluated discretely. The iso-value contours of this function are indicated in Fig. 11.2, which permits after refinement to identify the optimum ξ≈0.571 and η≈0.948.

Contour plot of function z(ξ,η) of (11.16) for n+1=5: the plot is symmetrical w.r.t. the bisecting line η=ξ, and one location of the minimum is ξ=0.571, η=0.948
4.4 General Results (n>4)
The min-max-Δ problem has been solved by either analytical or numerical means for values of n in the range from 0 to 40. The results are collected in Table 11.1 in which the first column indicates the number of interpolation points n+1, the second gives the definition of the Chebyshev points ξ ⋆ (n≤4), the third provides the definition of the optimal distribution \(\bar{\xi}\), and the fourth a comparison of performance by giving, when available, the values of
-
1.
\(\bar{\varDelta }= \max_{x} \varDelta ( x, \bar{\xi})\), the upper bound on Δ(x) corresponding to the optimal distribution \(\xi=\bar{\xi}\) of interpolation points;
-
2.
Δ ⋆=max x Δ(x,ξ ⋆), the upper bound on Δ(x) corresponding to the approximately optimal distribution ξ=ξ ⋆ of interpolation points (the Chebyshev distribution);
-
3.
Δ u=max x Δ(x,ξ u), the upper bound on Δ(x) corresponding to the uniform distribution ξ=ξ u of interpolation points.
The analytical results are related to the cases for which n≤4, and have been outlined in a previous subsection.
For n+1≥10, the distribution \(\bar{\xi}\) (not given here) has been identified by a numerical minimization realized by a particle-swarm (PSO) algorithm. The table indicates the corresponding values of \(\bar{\varDelta }\).
From these results, one observes that the upper bound \(\bar{\varDelta }\) achieved when the distribution of interpolation points is optimized, is not only bounded, but it even diminishes with increasing n. The Chebyshev distribution has an almost equivalent performance. Inversely, the uniform distribution yields a value of the upper bound Δ u that is unbounded with n. In conclusion, using the Chebyshev distribution, which is known explicitly, is highly recommended in practice.
5 Generalized Hermitian Interpolation
In this section, we generalize the notions introduced in the first three to the situation where one wishes to construct a(the) low(est)-degree polynomial interpolant of the values, as well as the derivatives up to order, say p (p∈ℕ), of a given smooth function f(x) over [−1,1]. The interpolation points are again denoted {x i } i=0,1,…,n , and we use the notation
The interpolation polynomial is denoted H n,p (x) and it is now constrained to the following (p+1)(n+1) interpolation conditions:
We associate such kind of interpolation with the expression “generalized Hermitian interpolation”.
5.1 Existence and Uniqueness
We first establish existence and uniqueness by the following:
Theorem 11.1
There exists a unique polynomial H n,p (x) of degree at most equal to (p+1)(n+1)−1 satisfying the generalized interpolation conditions (11.17).
Proof
By recurrence on p. For p=0, the generalized Hermitian interpolation reduces to the classical Lagrange interpolation, whose solution is indeed unique among polynomials of degree at most equal to (p+1)(n+1)−1=n:
For p≥1, assume H n,p−1(x) exists and is unique among polynomials of degree at most equal to p(n+1)−1. This polynomial, by assumption, satisfies the following interpolation conditions:
Hence, by seeking H n,p (x) in the form
one finds that R(x) should be of degree at most equal to (p+1)(n+1)−1 and satisfy
and
Now, (11.19) is equivalent to saying that R(x) is of the form
for some quotient Q(x). Then, the derivative of order p of R(x) at x=x i is calculated by the Leibniz formula applied to the product u(x)v(x) where
This gives
But, u (k)(x i )=0 for all k except k=p yielding
Thus, all the interpolation conditions are satisfied iff the polynomial Q(x) fits the following interpolation conditions:
Therefore, solutions exist, and the lowest-degree solution is uniquely obtained when Q(x) is the Lagrange interpolation polynomial associated with the above function values. This polynomial is of degree at most equal to n. Hence, R(x) and H n,p (x) are of degree at most equal to p(n+1)+n=(p+1)(n+1)−1. □
5.2 Interpolation Error and Best Approximation
We have the following:
Theorem 11.2
(Interpolation Error Associated with the Generalized Hermitian Interpolant)
Assuming that f∈C (p+1)(n+1)([−1,1]), we have
Proof
Let x∈[−1,1] be fixed. If x=x i for some i∈{0,1,…,n}, f(x)=H n,p (x) and π(x)=0, and the statement is trivial. Hence, assume now otherwise that x≠x i for any i∈{0,1,…,n}. Then, define the constant
so that
Now using the symbol t for the independent variable, one considers the function
By virtue of the interpolation conditions satisfied by the polynomial H n,p (t),
but, additionally, by the choice of the constant γ, we also have
This makes n+2 distinct zeroes for θ(x):x 0,x 1,…,x n and x. Thus, by application of Rolle’s theorem in each of the n+1 consecutive intervals that these n+2 points once arranged in an increasing order define, a zero of θ′(t) exists, yielding n+1 distinct zeroes for θ′(t), to which (11.21) adds n+1 distinct and different ones, for a total of 2(n+1)=2n+2 zeroes. Strictly between these, one finds 2(n+1)−1 zeroes of θ″(t) to which (11.21) adds n+1 distinct and different ones, for a total of 3(n+1)−1=3n+2 zeroes. Thus, for every new derivative, we find one less zero in every subinterval, but n+1 more by virtue of (11.21), for a total of n more, and this as long as (11.21) applies. Hence we get that θ (p)(t) admits at least (p+1)n+2 distinct zeroes. For derivatives of higher order, the number of zeroes is one less for every new one; hence, (p+1)n+1 for θ (p+1)(t), and so on. We finally get that θ ([p+(p+1)n+1])(t)=θ ([(p+1)(n+1)])(t) admits at least one zero ξ, that is
because H ([(p+1)(n+1)])(ξ)=0 since the degree of H n,p (t) is at most equal to (p+1)(n+1)−1, and the conclusion follows. □
As a consequence of this result, it is clear that the best generalized Hermitian approximation is achieved by the Chebyshev distribution of interpolation points again.
5.3 Best Inexact Generalized Hermitian Interpolation
Now suppose that all the data on f and its successive derivatives are exact, except for the derivatives of the highest order, \(\{y_{i}^{(p)}\}\) that are subject to uncertainties {ϵ i } i=0,1,…,n . Then, the uncertainties on the values {Q i } i=0,1,…,n of the quotient Q(x) are the following:
on the quotient itself the following:
and, finally, the uncertainty on the generalized Hermitian interpolant H n,p (x) the following:
In conclusion, for situations in which the uncertainties {ϵ i } i=0,1,…,n are bounded by the same number ϵ, the criterion that one should consider to conduct the min-max optimization of the interpolation points {x i } i=0,1,…,n is now the following one to replace the former Δ(x):
or, equivalently,
We note that this expression is a homogeneous function of π(x) of degree 0.
We conjecture that the variations of the above criterion, as p→∞, are dominated by those of the factor |π(x)|. Hence, in this limit, the optimal distribution of interpolation points should approach the Chebyshev distribution.
5.4 Overall Bound on the Approximation Error
The quantity ϵΔ (p)(x) is an absolute bound on the error committed in the computation of the generalized Hermitian interpolant based on function and derivative values in presence of uncertainties on the derivatives of the highest order, p, only, when these are uniformly bounded by ϵ:
where \(\bar{\mathsf{H}}_{n,p}(x)\) represents the actually computed approximation.
On the other hand, the interpolation error is the difference between the actual function value, f(x), and the “true” interpolant, H n,p (x), that could be computed if all function and derivative information was known. The interpolation error satisfies
where one has let
Consequently, we have
Now, examining the precise expression for Δ (p)(x), that is (11.22), we see that the ratio of the second term to the first on the right of the above inequality is equal to
For given n and p, this expression is unbounded in x. Thus, (the bound on) the error is inevitably degraded in the order of magnitude due to presence of uncertainties.
However, the actual dilemma of interest is somewhat different. It is the following: given the values \(\{y_{i},y_{i}',\ldots,y_{i}^{(p-1)}\}\), 0≤i≤n, and correspondingly, approximations of the higher derivative \(\{ y_{i}^{(p)} \}\), which of the following two interpolants is (guaranteed to be) more accurate:
-
1.
the Hermitian interpolant of the sole exact values: \(\{y_{i},y_{i}',\ldots,y_{i}^{(p-1)} \}\), 0≤i≤n, or
-
2.
the Hermitian interpolant of the entire data set?
The first interpolant differs from f(x) by the sole interpolation error, μ n,p−1|π(x)|p. The second interpolant is associated with the higher-order interpolation error, μ n,p |π(x)|p+1, but is subject to the uncertainty term ϵΔ (p)(x), which is dominant, as we have just seen. Thus, the decision of whether to include derivatives or not should be guided by the ratio of the uncertainty term, ϵΔ (p)(x), to the lower interpolation error, μ n,p−1|π(x)|p. This ratio is equal to
and it admits the bound
where the bound
exists since, in the above, the function over which the max applies is piecewise polynomial for fixed n and p.
Hermitian interpolation is definitely preferable whenever the expression in (11.24) is less than 1. This criterion permits us to identify trends as ϵ, n and p vary, but is not very practical in general since the factors ϵ and μ n,p−1 are problem-dependent and out of control. The variation with n of the bound B n,p has been plotted in Fig. 11.3 for p=1, 2 and 3. Visibly, the bound B n,p can be large unless p and n are small. Therefore, unsurprisingly, unless n and p, as well as the uncertainty level ϵ, are small enough, the criterion in (11.24) is larger than 1, and the interpolant of the sole exactly known values is likely to be the more accurate one.

Coefficient B n,p as a function of n for p=1,2 and 3
To appreciate this in a practical case, we have considered the case of the interpolation of the function
over the interval [−1,1] for p=0 (Lagrange interpolation) and p=1 (Hermitian interpolation). This smooth function is bounded by 1, and its maximum derivative increases with λ. For λ=64/27, this maximum is equal to 1. For λ=256/27, this maximum is equal to 2.
In the first experiment (Figs. 11.4 and 11.5), λ=64/27 and n=5. The Lagrange interpolant is fairly inaccurate, mostly near the endpoints. Thus the error distribution indicates that the approximate Hermitian interpolant is preferable even for a fairly high level of uncertainty on the derivatives (20 % is acceptable).

Case λ=64/27 (\(\max_{x} \vert f_{\lambda}(x) \vert = \max_{x} \vert f_{\lambda}'(x) \vert =1\)); function f λ (x) and various interpolation polynomials (n=5)

Case λ=64/27 (\(\max_{x} \vert f_{\lambda}(x) \vert = \max_{x} \vert f_{\lambda}'(x) \vert =1\)); error distribution associated with the various interpolation polynomials (n=5)
In the second experiment (Figs. 11.6 and 11.7), the interpolated function is the same, but the number n is doubled (n=10). Consequently, the Lagrange interpolant of the sole exact function values is very accurate. The approximate Hermitian interpolant can only surpass it if the level of uncertainty on the derivatives is small (less than 5 %).

Case λ=64/27 (\(\max_{x} \vert f_{\lambda}(x) \vert = \max_{x} \vert f_{\lambda}'(x) \vert =1\)); function f λ (x) and various interpolation polynomials (n=10)

Case λ=64/27 (\(\max_{x} \vert f_{\lambda}(x) \vert = \max_{x} \vert f_{\lambda}'(x) \vert =1\)); error distribution associated with the various interpolation polynomials (n=10)
Lastly, with the same number of interpolation points (n=10), we have considered the case of a function with larger derivatives (λ=256/27). As a result (see Figs. 11.8 and 11.9), the accuracy of the Lagrange interpolation has been severely degraded. Then again, the approximate Hermitian interpolation is found superior for higher levels of uncertainty in the derivatives (the switch is between 20 % and 50 %).

Case λ=256/27 (max x |f λ (x)|=1; \(\max_{x} \vert f_{\lambda}'(x) \vert =2\)); function f λ (x) and various interpolation polynomials (n=10)

Case λ=256/27 (max x |f λ (x)|=1; \(\max_{x} \vert f_{\lambda}'(x) \vert =2\)); error distribution associated with the various interpolation polynomials (n=10)
6 Conclusions
Recalling that the Chebyshev distribution of interpolation points is optimal w.r.t. the minimization of the (known bound on the) interpolation error, we have proposed an alternate criterion to be subject to the min-max optimization. The new criterion to be minimized aims at reducing the sensitivity of the Hermitian interpolant of function values and derivatives, to uncertainties assumed to be present in the derivatives only. We have found by analytical developments and numerical experiments that the Chebyshev distribution is close to be optimum w.r.t. this new criterion also, thus giving the stability of the corresponding approximation a somewhat larger sense.
We have also considered the generalized Hermitian interpolation problem in which the derivatives up to some order p (p>1) are fitted. For this problem we have derived the existence and uniqueness result, as well as the expression of the interpolation error, and also the definition that one could use for the criterion to be subject to the min-max optimization to reduce the sensitivity of the interpolant to uncertainties in the derivatives of the highest order. We conjectured from the derived expression that the corresponding optimal distribution of interpolation points converges to the Chebyshev distribution as p→∞.
Lastly, we have made actual interpolation experiments in cases of a function bounded by 1, whose derivative is either bounded by 1 or 2. These experiments have confirmed that the approximate Hermitian interpolant was superior to the Lagrange interpolant of the sole exact function values, when the uncertainty on the derivatives is below a certain critical value which decreases when n is increased.
In perspective, we intend to examine a much more complicated case in which the meta-model depends nonlinearly on the adjustable parameters, by means of semi-formal or numerical analysis tools.
References
Bompard M, Désidéri J-A, Peter J (2010) Best Hermitian interpolation in presence of uncertainties. INRIA Research Report RR-7422, Oct. http://hal.inria.fr/inria-00526558/en/
Conte SD, de Boor C (1972) Elementary numerical analysis: an algorithmic approach, 2nd edn. McGraw-Hill, New York
Jones D (2001) A taxonomy of global optimization methods based on response surfaces. J Glob Optim 21(4):345–383
Pearson CE (ed) (1990) Handbook of applied mathematics: selected results and methods, 2nd edn. Van Nostrand Reinhold, New York
Quarteroni A, Sacco R, Saleri F (2007) Numerical mathematics, 2nd edn. Texts in applied mathematics, vol 37. Springer, Berlin
Sacks J, Welch W, Mitchell T, Wynn H (1989) Design and analysis of computer experiments. Stat Sci 4(4):409–435
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media Dordrecht
About this chapter
Cite this chapter
Désidéri, JA., Bompard, M., Peter, J. (2013). Hermitian Interpolation Subject to Uncertainties. In: Repin, S., Tiihonen, T., Tuovinen, T. (eds) Numerical Methods for Differential Equations, Optimization, and Technological Problems. Computational Methods in Applied Sciences, vol 27. Springer, Dordrecht. https://doi.org/10.1007/978-94-007-5288-7_11
Download citation
DOI: https://doi.org/10.1007/978-94-007-5288-7_11
Publisher Name: Springer, Dordrecht
Print ISBN: 978-94-007-5287-0
Online ISBN: 978-94-007-5288-7
eBook Packages: EngineeringEngineering (R0)