
Abstract
The prominent role of facilities in influencing ‘why crime happens where it does’ has been widely recognized and vigorously researched. Criminological theories which focus on opportunity such as routine activity theory and crime pattern theory have provided the basis for such inquiries. Some of these investigations have targeted the role of facilities in fueling higher crime levels at places. They have usually developed facility-focused measures that quantify each facility’s influence based on the crime experienced by the places located near it. Measures are calculated only at the locations with facilities present. However, improvements in data sources and software have allowed researchers to examine the population of small units of geography rather than focusing on only those with a facility present. Thus it is now possible to quantify the cumulative effect of nearby facilities on the crime rates of geographies of such street blocks and addresses. This chapter begins by discussing the traditional methods for exploring the relationship between facilities and crime. Next, the theoretical case for more sophisticated distance and activity-level based measures is made. The critical role of geoprocessing models in automating complex analysis processes is explained and a model developed to create three different exposure measures. Data describing the locations of drinking places and street block level crime are used to illustrate how measures produced by the model can be used to explore the relationships between exposure to facilities and an outcome such as crime. The output measures from the model are evaluated using descriptive statistics and then used as independent variables in an ordinary least squares regression. Local variation in the measures is examined using a bivariate LISA to highlight areas of negative and positive spatial autocorrelation between exposure to bars and crime. The chapter concludes with a discussion of the implications of the findings and probable next steps.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
Since the 1970s, the characteristics of small areas and specific places in influencing crime patterns have received increasing attention. Some of this attention has been facilitated by theoretical advances that drew attention to the role of place in producing observed crime patterns. Theories under the rubric of environmental criminology hold that the context of crime events is critical to understanding crime patterns (Brantingham and Brantingham 1984, 1991a; Clarke and Cornish 1985; Cohen and Felson 1979). They focus on the convergence of individuals who are criminally inclined (i.e., motivated offenders) with people or things who are suitable targets, in situations where someone likely to intervene (i.e., capable guardian) is not present. How the three elements necessary for a crime to occur end up at the same place and time is primarily a function of the routine activities of each person. The characteristics of the place at which convergence occurs determine why the individuals who use the place are present and the behaviors they perceive to be norms for the place. In other words, different places facilitate differing levels of convergence involving differing types of individuals. Further, opportunity theories recognize that places do not exist in a vacuum but rather are situated in the context of their neighbors.
Empirical testing of these theories would not have been possible without the development of geographic information systems (GIS) software and the increased availability of data describing places. It was the combination of new technology and data describing places that facilitated empirical work relating the census characteristics of various census geographies, such as census tracts, census block groups, and census blocks to the types of crime which occurred there (see Weisburd et al. 2009 for a comprehensive history). In recent years, the focus of inquiry has shifted to smaller geographies and led to the discovery that significant variability exists in crime across smaller units of analysis such as addresses (Eck et al. 2000; Sherman et al. 1989) and street blocks (Groff et al. 2009; Taylor 1997; Weisburd et al. 2004). As Taylor (2010, p. 467) notes “different types of processes are likely to be involved at different spatial scales” and “more insight can probably be gained by examining impacts of smaller-scale contexts like streetblocks.”
One aspect of places that is especially important is the number and type of facilities present since facilities draw people to the places (Brantingham and Brantingham 1995). Except for residents, people must travel to get to particular facilities they want to patronize. While there, they tend to also patronize other establishments nearby. This means places along frequently used routes of travel and near, but not necessarily at a facility, also have increased potential for convergence just by virtue of their proximity. Thus any an accurate description of the impact of facilities on the places near them must capture the probability of spatial interaction. The cumulative influence of surrounding facilities on a place can be thought of as that place’s exposure to facilities. Exposure can be quantified for one type of facility, for example bars or schools, or multiple types of similar facilities, for example retail outlets or recreational facilities.
A major challenge to calculating an exposure measure lies in the considerable effort involved. Tools to automate the identification of polygon feature (i.e., area) neighbors are part of the functionality of GIS software and relatively easy to calculate using a three step process. This is not the case for measuring micro-level spatial interaction along street networks which requires almost twenty steps to compute. Manually completing each of those steps is both tedious and time-consuming. This chapter presents a geoprocessing model that automates the calculation of micro-level exposure measures. The chapter begins by exploring questions related to appropriately quantifying spatial interaction and establishing its geographic extent. The etiology of spatial interaction across places is explained. Three incrementally more complex measures of facility influence on nearby places are suggested and implemented in a geoprocessing model. An illustration of how the output of the model might be used to conduct further research is offered through an examination of drinking place influence on street blocks in Seattle, Washington.
2 Theoretical Background
Geographers have long known that nearby things tend to be related and the closer they are to one another the stronger the relationship (Tobler 1970). This observation suggests it is important to measure and analyze relations among near places (Miller 2004). Facilities shape human activity because they attract people to particular places. At the same time, individuals make choices about which facilities to patronize based on distance and preferences. Distance is essentially a proxy for the time/effort and cost of traveling to a particular facility and is weighed against the attractiveness of the facility. The important role of distance in human decision-making has been widely recognized. Zip’s (1950) principle of least effort states people will try to minimize effort and cost, often equated with distance or time, when choosing destinations for shopping, recreation, seeing a movie etc. The distance decay function holds that the likelihood of interaction decreases with increasing distance (Brantingham and Brantingham 1984; Harries 1990, 1999; Katzman 1981; Rossmo and Rombouts 2008). Thus travel decisions have much to do with proximity and distance influences interaction through the spatial choices of individuals. Since the location of human activity is largely shaped by distance and opportunities in the built environment, it makes sense that near things tend to be related.
More broadly, individuals have programs of daily behavior that constitute their routine activity spaces (Carlstein et al. 1978; Hägerstrand 1970, 1973; Horton and Reynolds 1971; Pred 1967, 1969). These spaces encompass the places that are visited, termed nodes, and the routes taken among those places, referred to as paths. Often, activity spaces are expanded to incorporate newly discovered places of interest such as a restaurant. In addition, individuals tend to become familiar with the areas on the way to and from their nodes as well as places around their nodes. Because of this, the boundaries of activity spaces are fuzzy and tend to change over time.
Environmental criminologists recognize the applicability of spatial choice and human activity spaces to the study of crime patterns. Both crime pattern theory (Brantingham and Brantingham 1991a, b) and routine activity theory (Cohen and Felson 1979; Felson 1986; Felson and Clarke 1998) identify the convergence of motivated offenders and suitable targets at the same place and time as necessary elements for a crime to occur. The presence or absence of individuals who could potentially intervene is another necessary element (Cohen and Felson 1979; Eck 1995; Felson 1995). One type of capable guardian especially important in the context of facilities is place managers (Eck 1995; Felson 1995). Store employees, bartenders, parking lot attendants and other individuals who work at facilities are all place managers. In addition, crime pattern theory emphasizes the role of places characteristics and the urban backcloth in setting the stage for crime events.
In sum, the configuration of facilities within general areas of land use types shapes the routine activities of individuals which in turn influence the number of convergences which occur at places. This chapter demonstrates how geoprocessing models can be used to operationalize three different types of exposure measures. The output values can then be used in multivariate statistical models to represent exposure to facilities in a more nuanced fashion.
2.1 Quantifying Exposure
Exposure of areal units such as census blocks, block groups and tracts can be been easily measured using first-order (adjacent) or second-order (neighbors of adjacent units) neighbors. For example, first-order exposure is the total number of facilities in the set of adjacent areas and second-order exposure is the number of facilities in the neighbors of adjacent areas. Bernasco and Block (2011) recently undertook just such an analysis in Chicago using census blocks. They examined the effect of a variety of facilities on robbery using census blocks and their adjacent neighbors. However, using a finer spatial scale opens the door to new ways of more accurately quantifying potential spatial influence.
Past studies using micro-spatial scales have quantified the exposure of street blocks to facilities nearby using a simple count of the number of facilities within a distance threshold. Two of these studies used a questionnaire approach asking a sample of neighborhood residents whether certain facilities were located within three blocks of their home (Miethe and McDowall 1993; Wilcox et al. 2004).Footnote 1 The responses were aggregated to neighborhoods for the analysis. Another study examined every street block in a city and used a threshold distance of a quarter mile (just over three blocks) (Weisburd et al. 2011, 2012). This method had the advantages of: (1) being relative easy to compute using current GIS software and (2) producing an understandable outcome measure (e.g., two facilities within quarter-mile of a place).
However, there are three issues with the straight-line-distance, simple-count operationalization of place (in this case street blocks) exposure to facilities. Most importantly, it fails to account for the diminishing influence of facilities as distance increases. All facilities count equally regardless of whether they are on the same block or three blocks away. Second, it overestimates the geographic extent of a threshold distance because travel is limited by the transportation network. Third, it does not incorporate differences in facility influence. The influence of a facility may be tied to its physical size, the number of patrons, the amount of sales, the types of people who frequent it, and the times it is open for business just to name a few. These characteristics of facilities play a role in the amount and type of influence they have over crime at street blocks nearby. Recognizing these issues a recent study examined the places near bars using both Euclidean and street distance measures across a range of threshold distances and found street distance was a stronger measure of the relationship between facilities and crime (Groff 2011).
Building on the earlier work, this effort develops three new measures of facility influence that represent increasingly more sophisticated operationalizations of exposure to facilities. All three measure distance along a street network and thus address the concern that human activity patterns are not represented in a tradition count threshold measure of influence using Euclidean distance (i.e., ‘as the crow flies’) (Groff 2011).Footnote 2 The simplest measure, Count, is a count of the facilities within a threshold.Footnote 3 Each facility within the specified threshold distance counts as one, in this way the amount of influence attributed to each drinking place within a threshold is constant.
-
Measure 1:
-
Count i = S(Number of facility locations)
-
where the number of facilities within the threshold distance i from the place is counted.
To deal with the issue of distance from the place to the facility, inverse distance weighting (IDW) is used to ‘discount’ the potential influence of a place. A facility at a place counts as ‘1’ while those farther away count less than one. Distances are once again measured along a street network. The outcome measure, IDW Count, represents the cumulative influence of facilities on a place discounted for distance, the larger the number, the greater the influence.
-
Measure 2:
-
IDW Count i = S(1/Sqr(d ij ))
-
where d ij = distance from the place i to each facility j within the threshold bandwidth
The final measure, Distance Weighted Activity (DWA), operationalizes ‘exposure’ as reduced by distance but increased by potential activity at a place. The DWA takes into account both the distance a facility is from a street block and the activity at that location and thus provides a more nuanced view of the relationship between exposure and crime. Measuring activity could be done in a variety of ways and will vary based on the type of facility. For example, total square footage, total sales, seating capacity, ticket sales, number of bar stools, or enrollment are a few possibilities. For drinking establishments, annual sales, number of bar stools, seating capacity, and square footage are all possibilities. Annual sales has the advantage of capturing actual dollars spent rather than the potential for people to patronize the facility as is the case with characteristics such as bar stools, seating capacity and square footage.
-
Measure 3:
-
Distance Weighted Activity i = S((1/Sqr(d ij )) * a j )
-
where dij = distance from the place i to each facility j within the bandwidth and a j = total activity
2.2 Role of Geoprocessing Models
The three operationalizations of exposure measures can be created using the out-of-the-box software tools which exist in ArcGIS® but doing so requires a complicated series of roughly twenty individual actions on the part of the user. A way to automate the process is needed.
Geoprocessing models offer an attractive alternative to writing computer programs to achieve automation. Geoprocessing models are visual-based representations of processes. They allow nonprogrammers to automate tasks by dragging and dropping geoprocessing tools onto a canvas. Models can be easily passed from one user to another. Finally, they can be exported to a python script and then used as the basis for a more complex custom programming effort.
Automation of manual processes has many benefits including: (1) improved efficiency because tasks can be done more quickly and in less time (Kitchens 2006; Moudry 2012); (2) greater accuracy because there is reduced chance of human error (Fan 1998; Kitchens 2006; Moudry 2012); (3) greater consistency because the same steps are repeated without change from one analysis to the next (Fan 1998; Kitchens 2006; Moudry 2012); and (4) the creation of a record of steps taken which, in turn, enables exact replication of analyses (Moudry 2012; Thoma 1991). In addition, automation that involves computer programs or geoprocessing models can be easily shared and the analysis reproduced using different data.
Using geoprocessing models holds in common many of the same benefits familiar to users of syntax or log files. Models document what operations were conducted to produce the analysis and in this way they facilitate communication between analysts. This is extremely helpful when the same analysis has to be redone with new data or when someone else wants to conduct the same analysis using different data. In this way, models facilitate easy replication of research. Models also allow parameters to be easily and systematically changed to aid in sensitivity analysis. Finally, geoprocessing model provide flexibility because they run without human intervention or even presence.
3 Generating Measures of Facility Influence on Places
This chapter illustrates how a geoprocessing model can be used to operationalize and automate the collection of measures related to the exposure of places to facilities nearby. In keeping with recent research, the current study used street distance to measure spatial influence (Groff 2011) and examined very short threshold distances (Groff 2011; Ratcliffe 2011, 2012). Because the results are included for illustration purposes, this chapter discusses the results for only four threshold distances, one block (400 ft), two blocks (800 ft), three blocks (1,200 ft), and 2,800 ft (about 6 blocks or just over one half a mile).
A geographic information system (GIS) was used to generate the three measures quantifying place exposure to facilities. GIS are designed to facilitate spatial data creation, manipulation, storage, analysis, and visualization (Worboys and Duckham 2004). GIS have always had the ability to measure distances but recent versions have expanded the range of tools and made them more accessible. Most important to this research was the ability to measure distances along street networks from a set of origins to a set of destinations.
The Origin and Destination Matrix tool in Network Analyst (ArcGIS 9.3) was used for all the measurements. This tool is designed to measure the distance between an origin place or set of origins and a destination place or set of destinations. Here it was used to develop the three measures of exposure. Street block midpoints were used as the origins and the drinking places were the destinations. The software measured from each origin outward in all directions along the street network. If a destination was located within the threshold, a record was written to the matrix. The record contained the distance between the origin and the destination pair as well as information identifying the pair of locations involved.
At this point, the formulas for IDW Count and DWA were applied to the distance measures for each pair. In the case of IDW Count, each facility was inverse distance weighted by its distance from the street block (the closer the facility the greater the potential influence and thus the higher the score). The DWA measure multiplied the weighted score for each place-facility pair by total annual sales for that facility. The values for each measure were then summed for each street block to produce measures of the cumulative influence of facilities within a particular distance threshold.
The most challenging aspect of computing exposure measures is the large number of steps involved. As mentioned before, one reason gaps in our knowledge about the effect of facilities on the streets near them have remained is the time consuming nature of the inquiry. Computation of the final three measures from the output table required that fields be added, joins done, values calculated, and data summarized for each and then the entire process repeated for each distance threshold investigated. This is where the geoprocessing model was especially important to facilitating the multistep process required and ensuring consistent computation of measures (see Appendix for details of the model).
4 Using the Geoprocessing Model to Quantify Exposure to Drinking Places
To illustrate the value of facility exposure measures, an example analysis was conducted using drinking places in Seattle, WA and crime. Drinking places are ideally suited for a test case because there is a well-documented and positive relationship between bars and crime (Bernasco and Block 2011; Brantingham and Brantingham 1982; Frisbie et al. 1978; Groff 2011; Loukaitou-Sideris 1999; McCord and Ratcliffe 2007; Ratcliffe 2011, 2012; Rengert et al. 2005; Rice and Smith 2002; Roncek and Bell 1981). Accordingly, a positive relationship between bars and crime was hypothesized and the focus was on the ability of each measure of exposure to quantify the relationship.
4.1 Data
The street centerline file for Seattle, WA was provided by Seattle GIS. The locations of drinking places in 2004 (n = 157) were obtained from a private vendor.Footnote 4 Crime incident data for 2004 were provided by the Seattle Police Department and geocoded.Footnote 5 The number of crimes per street segment ranged from 0 to 515. The average street had 3.89 crimes (sd = 13.43). In Seattle, crime incident reports were generated by police officers or detectives after an initial response to a request for police service. Thus, they represent only those events which were both reported to the police and deemed to be worthy of a crime report by the responding officer. In this way, incident reports provided a measure of ‘true’ crime, at least the crime that was reported to the police. Specifically, we included all crime events for which a report was taken except those which: (1) occurred at an intersection,Footnote 6 (2) had an address of a police precinct or police headquarters; and (3) occurred on the University of Washington campus.Footnote 7
4.2 Exposure Measures Produced
The values for the exposure measures vary based on two dimensions, the threshold distance and the operationalization (simple count vs. IDW vs. DWA). Looking first at the threshold distances, all the measures increase steadily as the distance threshold increases (see Table 12.1). This is expected since as the threshold size increases more drinking places are included in the measure. The finding provides additional confidence that the model is correctly specified.
The operationalization of the measures is consistent with the hypothesized relationships. As expected, the values for the Simple Count were consistently higher than the values for the inverse distance weighted count (IDW count) across all threshold distances (see Table 12.1). The average street in Seattle had .1 drinking places within about a block. The subset of only those street blocks with at least one drinking place within 800 ft averaged just over one drinking place (Table 12.2). The inverse distance weighted (IDW) counts were lower because they took into account the distance between the street and the drinking places within the threshold so they averaged .09 and 1.07 respectively. In contrast, the values of the DWA measure were much larger than either of the other two because it weights the sales of each drinking place (in thousands of dollars) by the distance between the street block and the facility. The average street block was exposed to approximately $46,670 distance weighted sales dollars within one block but among places with at least one drinking place within 800 ft the exposure was $566, 513.
Overall, the descriptive statistics reveal differences in the exposure values generated within measures as the threshold increases. There are also differences in the values from one operationalization of exposure to the next (i.e., between Count, IDW and DWA). All the observed differences are consistent with the way the measures were calculated. The next question is which combination of threshold size and operationalization most closely relates exposure to drinking places and crime at the street block.
4.3 Examining the Relationship Between Exposure to Drinking Places and Crime
To get an indication regarding which exposure measures were most strongly related to crime, a simple OLS regression was calculated using only the exposure measure and a spatial lag of total crime. The Corrected Akaike Information Criterion (AICc) was used to compare the different models and get preliminary feedback on model fit. Models with lower AICc scores fit the observed data better. The model adjusted R-squared was also used to explore whether different conceptualizations of exposure explained a greater percentage of crime controlling for the amount of crime on nearby street blocks.
There were only minor differences between exposure measures at specific thresholds (Table 12.3). The IDW measure produced better fitting models with slightly higher adjusted R-squared values at every distance threshold. Simple Count and DWA measures, respectively, had slightly lower explanatory power and poorer fit regardless of distance threshold. Consistent with previous research, the relationship between drinking places and crime was highest at shorter distances. At about six blocks (2800 ft), only the IDW exposure measure explained a significant amount of the variation in crime.
Overall, these measures more exactly quantify the local situation of each street block in Seattle and thus provide better inputs to multivariate models of exposure to drinking places. But the differences among the measures in explaining crime are relatively small, especially between Count and IDW. One explanation for the lack of large differences between the measures may be in the type and extent of local variation. If there is a good deal of local, micro-spatial variation it may be masked by using a global statistic such as OLS regression (even with a spatial lag).
To examine local rather than global relationships, a bivariate local indicator of spatial association (LISA) was used. The bivariate LISA allows investigation of whether the measure used to operationalize exposure to drinking places affects the relationship between drinking places and total crime (Anselin 1995, 2003). The statistic classifies the relationship between each place and its neighbors as one of four types and provides an assessment of statistical significance for each.
There are two general types of spatial autocorrelation, positive and negative. Positive spatial autocorrelation can take the form of places with a high exposure to drinking places being associated with high crime (High-High) or places with low exposure scores being associated low crime (Low-Low). Places exhibiting positive spatial autocorrelation are where the hypothesis regarding the relationship between bar influence and crime was supported. Negative spatial autocorrelation occurs where places with a high level of exposure were associated with low crime (High-Low) or places with low exposure scores were associated high crime (Low-High). Instances of the former relationship represent places that run counter to the general assumption that drinking places exposure is positively related to crime. These places are especially good candidates for further investigation. For this preliminary investigation, all four types of spatial autocorrelation are examined.
Comparing the three measures reveals a remarkable level of consistency between the Simple Count, IDW Count, and DWA measures of exposure (Table 12.4). The number of places that change classification from one measure to the other is relative small. The DWA is very different from the other two indicating the inclusion of sales in the calculation of exposure significantly changes the bivariate relationship between drinking places and crime. These differences are consistent as distance thresholds get larger. However, using larger thresholds spreads the influence of facilities over larger distances and increases the number of street blocks with exposure to drinking places. Not surprisingly, the number of significant relationships also increases. Of particular interest to understanding the influence of drinking places, the number of significant high exposure-high crime and high exposure-low crime places increase.
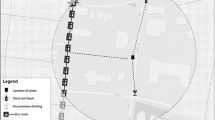
Bivariate LISA classifications for one part of Seattle are mapped to examine the patterns at the 800 ft and 1,200 ft thresholds for each of the exposure measures (Figs. 12.1 and 12.2). The color of the street indicates the type of spatial autocorrelation that exists between a street block and its neighbors. Only significant relationships are shown (p < .01). Streets which have a high score on their exposure measure and are located near streets with high numbers of crime events are red. These are the streets where exposure is positively correlated with crime. Lighter colors on the map represent places with negative spatial autocorrelation. Streets scoring high on exposure to drinking places which are near streets with low crime appear pink. At these places, the presence of bars nearby is associated with low crime counts. Streets classified as low on exposure and surrounded by high crime places are light blue. These places are high crime but are not near a bar and thus are less interesting to the questions posed here. Finally, if a street is low on exposure and surrounded by low crime places, it is dark blue. These are the least interesting places in terms of exposure to facilities and crime because neither condition of interest is present.

(a) Simple count (b) Inverse distance weighted count (c) Distance weighted activity. Bivariate LISA Results for 800 Foot Threshold (Note: The black square near the top of all three maps highlights one area where change occurred across all three measures. There is no drinking place within 1200 ft to the north of the area shown)

Bivariate LISA Results for 1200 Foot Threshold
The advantage to examining the results on a map is the ability to visualize where the relationships are located in Seattle. Consequently, locations where different measures classified the same place differently are evident. However, it is very hard to distinguish micro level patterns when mapping an entire city. Instead, one portion of the city is mapped as an illustration. Turning first to the relationships revealed at the 800 ft threshold by the simple count measure of exposure (Fig. 12.1a), there a few street blocks near drinking places (symbolized as yellow triangles) with high exposure and low crime (pink). In this area, streets adjacent to drinking places are most often classified as high exposure to drinking places associated with low crime. Given the relatively low number of drinking places, there are also many street blocks with low exposure and low crime (dark blue). Notice also the preponderance of thicker light grey streets across the city where there was low exposure to bars but still high crime. A few drinking places are surrounded by grey streets, in these places there was no significant relationship between the level of exposure and the amount of crime in their vicinity.
Figure 12.1b reveals the IDW measure of exposure has a pattern almost identical to the one produced by exposure as measured by a Simple Count. There was very little visual difference in the spatial autocorrelation of exposure measure when operationalized as a simple count or as a distance discounted count (IDW).
Incorporating the annual sales of the drinking places into a measure that represented the distance discounted presence of drinking places changed the spatial pattern quite a bit (Fig. 12.1c). Several areas that had significant associations between count-based measures of exposure and crime are no longer significant. At the same time, in some formerly non-significant (lightest) places near drinking places (areas not shown), there were now significant relationships to crime. A major difficulty in explaining these patterns lies in the complex nature of environment-crime relationships but some possible explanations for this finding are explored in the discussion section.Footnote 8
As indicated by the tabular results, increasing the threshold to 1200 ft results in more street blocks with significant local relationships (between drinking place exposure and crime) (Fig. 12.2). Across the measures, once again Simple Count (Fig. 12.2a) and IDW (Fig. 12.2b) produce consistent patterns but DWA (Fig. 12.2c) is very different overall. The black square is again provided to highlight one area with differences visible across all three measures. In the area within the black square, Simple Count found more streets with significant High-Low relationships than IDW while DWA found none.
5 Discussion
This chapter demonstrates how geoprocessing models can aid research in two ways. One, by allowing the operationalization of new, geographically-based measures of exposure and two, by automating complex processes allowing the examination of measure performance across multiple thresholds. The ability to more precisely model spatial influence has increased due to greater availability of micro level data and new software functionality. Visual tools such as geoprocessing models provide the capability to automate processes within GIS. This automation is what makes it feasible to create more sophisticated distance-based measures of spatial interaction. Here a geoprocessing model was built to create three different measures of exposure to facilities. The model was then applied to the test case of quantifying the exposure of street blocks to drinking places in Seattle Washington.
The geoprocessing model provided the ability to easily create three different conceptualizations of exposure to drinking places and then test them under three different thresholds. Just computing the four different distance thresholds generated here would have involved over 240 manual steps and countless hours. Instead using the geoprocessing model running the model could be done in a few minutes and only involved setting the input data, threshold distance, and output data.
Analysis of model output found it was consistent with expectations. Exposure values were lowest for inverse-distance-weighted (IDW) because it weighted the presence of a facility by the distance from the street block. Exposure values were highest for distance-weighted-activity (DWA) because it represented inverse distance weighted by total sales volume. Simple-Count values fell in the middle.
Globally, there was little difference among the three measures at short distances. As distance increased, IDW emerged as producing the best fitting model for the illustrative example of drinking places and crime. The outcomes of a bivariate LISA analysis to examine local variation in the relationships of exposure and total crime revealed Simple Count and IDW were surprisingly similar but some local differences in the spatial patterns were evident in the maps. The results from the DWA measure were significantly different than the distance-only measures. Close inspection of the places that were classified as high DWA exposure and were significantly related to their neighbors reveals those street blocks were near either a single very high volume drinking place or near several low to moderate sales volume drinking places on adjacent streets.
In addition, the amount of activity at a facility is only one aspect of its potential influence. Perhaps equally important are the type of people and the place managers present at the facility. Madensen and Eck (2008) have proposed a model of bar-related violence that identifies bar ‘theme’, physical characteristics of the bar, and marketing strategies employed as critical factors to consider. Unfortunately, no data were available to represent of those facility attributes for all the drinking places in Seattle. Future research should include these aspects to get a more precise idea of what facility characteristics and place management characteristics interact.
One plausible explanation for the similarity in Simple Count and IDW has to do with the low number of drinking places in Seattle. The more facilities within a buffer the greater the difference will be between the Simple Count and IDW Count measures. With relatively few drinking places within each threshold there were fewer opportunities to weight the influence of facilities and thus the two measures were very similar. The short distance thresholds used, although empirically and theoretically justified, made it even more difficult to find multiple drinking places within a threshold. Greater differences among measures at short distances might be found in cities such as Philadelphia, PA, Washington DC, or Boston MA which have many more drinking places.
The measures created here tell only part of the story and do not control for how other features of the built and social environment might be interacting with the presence of a bar to determine the crime rate. Regardless of the type of facility being examined, in order to fully understand the differences observed, future research should test the measures in a multivariate model which could control for the differences observed at the local level. A multivariate model that incorporates the different measures of exposure as predictors would take into account those other factors and better evaluate the unique contribution of each measure to explaining variations in crime at street blocks. In addition, the differences in the pattern of bivariate correlations suggest the use of geographically weighted regression to examine the relationship in terms of multivariate predictors may be more illuminating than standard spatial regression models.
Finally, the model currently implements one of several possible weighting schemes such as exponential or inverse distance-weighted squared which would weight closer facilities much higher and the ones father away much lower. And of course, the current model needs to be applied to many different types of facilities in a variety of cities.
This chapter demonstrated the capability of geoprocessing models to provide a documented and replicable record of the analysis steps performed in GIS. Modeling exposure in different geographies or using different facilities in the same geography are straightforward and simply involve ‘pointing’ the model to look for different input data. The model can be easily shared with other researchers or practitioners interested in using the measures with their own data or those who want to build on the model to develop additional operationalizations of facility exposure. In sum, this research provides a theoretically sound spatial platform for achieving greater specificity in quantifying the influence of facilities.
Notes
- 1.
Kurtz et al. (1998) examined the percent of the street block that was retail storefronts but did not consider adjacent areas.
- 2.
Earlier work by Groff and colleagues has suggested that street distance buffers offer a more parsimonious representation of the spatial interaction occurring at specific distances than do Euclidean buffers (Groff 2011; Groff and Thomas 1998). Euclidean buffers often include events/facilities that cannot be reached using available travel routes.
- 3.
Threshold distances are measured from the midpoint of the street segment along the street network in all directions to the threshold distance specified. A street segment is included only if its midpoint falls within the threshold.
- 4.
Drinking places were identified using the NAICS code 7224 which defines them as follows: “This industry comprises establishments known as bars, taverns, nightclubs, or drinking places primarily engaged in preparing and serving alcoholic beverages for immediate consumption. These establishments may also provide limited food services.” U.S. Census Bureau (2010) NAICS 7224: Drinking Places (Alcoholic Beverages) Retrieved 2/11/2010, from U.S. Census Bureau: http://www.census.gov/epcd/ec97/def/7224.HTM. InfoUSA provided the physical locations of the drinking places as well as their annual sales in thousands of dollars.
- 5.
All geocoding was done in ArcGIS 9.1 using a geocoding locator service with an alias file of common place names to improve the hit rate. The geocoding locater used the following parameters: spelling sensitivity = 80, minimum candidate score = 30, minimum match score = 85, side offset = 0, end offset = 3 percent, and Match if candidates tie = no. Manual geocoding was done on unmatched records in ArcGIS 9.1 and then in ArcView 3.2 using the ‘MatchAddressToPoint’ tool (which allowed the operator to click on the map to indicate where an address was located) to improve the overall match rate. Research has suggested hit rates above 85% are reliable Ratcliffe (2004). Geocoding Crime and a First Estimate of a Minimum Acceptable Hit Rate. International Journal Geographical Information Science, 18(1), 61–72. Our final geocoding percentage for crime incidents was 97.3 %.
- 6.
Intersection crimes are excluded because incident reports at intersections differed dramatically from those at street segments. For example, traffic-related incidents accounted for only 3.77 % of reports at street segments, but for 45.3 % of reports at intersections. After excluding intersections, records that lacked a specific address, and records that could not be geocoded, there were 186,958 incident reports in 2004.
- 7.
Data on crime from the University of Washington campus were not provided to the Seattle Police Department after 2001. Efforts to obtain geocodable data directly from the University of Washington were unsuccessful.
- 8.
To save space only the results from the 800 and 1200 ft threshold are shown. Maps of additional thresholds are available from the author.
References
Anselin L (1995) Local indicators of spatial association. Geogr Anal 27:93–115
Anselin L (2003) GeoDa 0.9 User’s guide. Spatial analysis laboratory, University of Illinois, Urbana-Champaign
Bernasco W, Block R (2011) Robberies in Chicago: a block-level analysis of the influence of crime generators, crime attractors, and offender anchor points. J Res Crime Delinq 48(1):33–57
Brantingham PL, Brantingham PJ (1982) Mobility, notoriety, and crime: a study of crime patterns in urban nodal points. J Environ Syst 11(1):89–99
Brantingham PJ, Brantingham PL (1984) Patterns in crime. Macmillan, New York
Brantingham PJ, Brantingham PL (1991a) Introduction to the 1991 reissue: notes on environmental criminology. In: Brantingham P, Brantingham P (eds) Environmental criminology. Waveland Press Inc, Prospect Heights, pp 1–6
Brantingham PJ, Brantingham PL (1991b) Notes on the geometry of crime. In: Brantingham P, Brantingham P (eds) Environmental criminology. Waveland Press, Inc, Prospect Heights, pp 27–54
Brantingham PL, Brantingham PJ (1995) Criminality of place: crime generators and crime attractors. Eur J Crim Policy Res 3(3):5–26
Carlstein T, Parkes D, Thrift NJ (1978) Human activity and time geography. Halsted, New York
Clarke RV, Cornish DB (1985) Modeling offender’s decisions: a framework for research and policy. In: Tonry M, Morris N (eds) Crime and justice: an annual review of research, vol 6. University of Chicago Press, Chicago, pp 23–42
Cohen LE, Felson M (1979) Social change and crime rate trends: a routine activity approach. Am Sociol Rev 44:588–608
Eck JE (1995) A general model of the geography of illicit retail marketplaces. In: Eck JE, Weisburd D (eds) Crime and place. Willow Tree Press, Monsey, pp 67–93
Eck JE, Gersh JS, Taylor C (2000) Finding crime hot spots through repeat address mapping. In: Goldsmith V, McGuire P, Mollenkopf GJH, Ross TA (eds) Analyzing crime patterns: frontiers of practice. Sage Publications, Thousand Oaks, pp 49–64)
Esri (2012) ArcGIS 10.0 help. Esri, Redlands, California.
Fan Y-H (1998) Effective defect detection and classification methodology based on integrated laser scanning inspection and automatic defect classification. Paper presented at the 1998 IEEE/Semi advanced semiconductor manufacturing conference and workshop, Boston, MA
Felson M (1986) Predicting crime potential at any point on the city map. In: Figlio RM, Hakim S, Rengert GF (eds) Metropolitan crime patterns. Criminal Justice Press, Monsey, pp 127–136
Felson M (1995) Those who discourage crime. In: Eck JE, Weisburd D (eds) Crime and place. Willow Tree Press, Monsey, pp 53–66
Frisbie DW, Fishbine G, Hintz R, Joelson M, Nutter JB (1978) Crime in minneapolis: proposals for prevention. Minnesota Crime Prevention Center, Minneapolis
Groff ER (2011) Exploring ‘Near’: characterizing the spatial extent of drinking place influence on crime. Aust N Z J Criminol 44:156–179
Groff, ER, and Thomas D (1998) Characterizing crime ‘Within a distance of’: a comparison of radius vs. street distance. In: ESRI Mid-Atlantic Users Group Meeting. Philadelphia, PA
Groff ER, Weisburd D, Morris N (2009) Where the action is at places: examining spatio-temporal patterns of juvenile crime at places using trajectory analysis and GIS. In: Weisburd D, Bernasco W, Bruinsma G (eds) Putting crime in its place: units of analysis in spatial crime research. Springer, New York, pp 60–86
Hägerstrand T (1970) What about people in regional science? Pap Reg Sci Assoc 24:7–21
Hägerstrand T (1973) The domain of human geography. In: Chorley RJ (ed) Directions in geography. Methuen, London, pp 67–87
Harries KD (1990) Geographic factors in policing. Police Executive Research Forum, Washington, DC
Harries KD (1999) Mapping crime: principle and practice. U.S. National Institute of Justice, Washington, DC
Horton FE, Reynolds DR (1971) Action space differentials in cities. In: McConnell H, Yaseen D (eds) Perspectives in geography: models of spatial interaction. Northern Illinois University Press, Dekab, pp 83–102
Katzman MT (1981) The supply of criminals: a geo-economic examination. In: Hakim S, Rengert GF (eds) Crime spillover. Sage, Beverly Hills, pp 119–134
Kitchens T (2006) Automating software development processes. Developer.* Retrieved from 05 Mar 2012 . http://www.developerdotstar.com/mag/articles/automate_software_process.html
Loukaitou-Sideris A (1999) Hot spots of bus stop crime: The importance of environmental attributes. J Am Plan Assoc 65(4):395–411
Madensen TD, Eck JE (2008) Violence in bars: exploring the impact of place manage decision-making. Crime Prev Commun Saf 10:111–125
McCord ES, Ratcliffe JH (2007) A micro-spatial analysis of the demographic and criminogenic environment of drug markets in Philadelphia. Aust N Z J Criminol 40(1):43–63
Miethe TD, McDowall D (1993) Contextual effects in models of criminal victimization. Social Force 71:741–759
Miller H (2004) Tobler’s first law and spatial analysis. Ann Assoc Am Geogr 94(2):284–289
Moudry JA (2012) Real benefits of automated processes. Retrieved from 5 March 2012. http://www.nextgenpinews.com/files/Real%20Benefits%20of%20Automated%20Processes.pdf
Pred A (1967) Behavior and location: foundations for a geographic and dynamic location theory, part I. Gleerup, Lund
Pred A (1969) Behavior and location: foundations for a geographic and dynamic location theory, part II. Gleerup, Lund
Ratcliffe JH (2011) How near is near? Quantifying the spatial influence of crime attractors and generators. In: Andresen M, Kinney JB (eds) Patterns, prevention, and geometry of crime. Routledge, London
Ratcliffe JH (2012) The spatial extent of criminogenic places on the surrounding environment: a change-point regression of violence around bars. Geogr Anal 44(4):302–320
Rengert GF, Ratcliffe JH, Chakravorty S (2005) Policing illegal drug markets: geographic approaches to crime reduction. Criminal Justice Press, Monsey
Rice KJ, Smith WR (2002) Sociological models of automotive theft: integrating routine activity and social disorganization approaches. J Res Crime Delinq 39(3):304–336
Roncek DW, Bell R (1981) Bars, blocks and crimes. J Environ Syst 11:35–47
Rossmo DK, Rombouts S (2008) Geographic profiling. In: Wortley R, Mazerolle L (eds) Environmental criminology and crime analysis. Willan Publishing, Portland, pp 78–93
Sherman LW, Gartin P, Buerger ME (1989) Hot spots of predatory crime: routine activities and the criminology of place. Criminology 27(1):27–55
Taylor RB (1997) Social order and disorder of street blocks and neighborhoods: ecology, microecology, and the systemic model of social disorganization. J Res Crime Delinq 34(1):113–155
Taylor RB (2010) Communities, crime, and reactions to crime multilevel models: accomplishments and meta-challenges. J Quant Criminol 26(4):455–466
Thoma RS (1991) Automated phenylthiocarbamyl amino acid analysis of carboxypeptidase/aminopeptidase digests and acid hydrolysates. J Chromatogr 537:153
Tobler W (1970) A computer model simulation of urban growth in the detroit region. Econ Geogr 46(2):234–240
Weisburd D, Bushway S, Lum C, Yang S-M (2004) Trajectories of crime at places: a longitudinal study of street segments in the city of seattle. Criminology 42(2):283–321
Weisburd D, Bruinsma G, Bernasco W (2009) Units of analysis in geographic criminology: historical development, critical issues and open questions. In: Weisburd D, Bernasco W, Bruinsma G (eds) Putting crime in its place: units of analysis in spatial crime research. Springer, New York, pp 3–31
Weisburd D, Groff E, Yang S-M (2011) Understanding developmental crime trajectories at places: social disorganization and opportunity perspectives at micro units of geography. Office of Justice Programs, National Institute of Justice, Washington, DC
Weisburd D, Groff E, Yang S-M (2012) The criminology of place: street segments and our understanding of the crime problem. Oxford University Press, Oxford
Wilcox P, Quisenberry N, Cabrera DT, Jones S (2004) Busy places and broken windows? Toward defining the role of physical structure and process in community crime models. Sociol Q 45(2):185–207
Worboys M, Duckham M (2004) GIS: a computing perspective. CRC Press, Boca Raton
Zipf G (1950) Principle of least effort. Addison Wesley, Reading
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Documentation of Geoprocessing Model for Calculating Exposure to Facilities
Appendix: Documentation of Geoprocessing Model for Calculating Exposure to Facilities
A geoprocessing model was used to develop the cumulative measures of exposure to facilities. There are three main inputs to the model: (1) a network data set; (2) a feature class of point locations representing origins; and 3) a feature class of point locations representing destinations. The remainder of the Appendix provides a step-by-step description of the model. A snapshot of the section of the model appears first followed by a description of that step.

Step 1:
Make an OD Cost Matrix Layer – This tool makes an origin–destination (OD) matrix. The user sets the analysis properties for the matrix. This type of analysis is especially helpful when the goal is to specify the “costs of going from a set of origin locations to a set of destination locations” (Esri help 2011). This is where the user sets the impedance attribute and the threshold distance cutoff. The impedance attribute is the field is used to measure the distance or time between each origin and destination pair.
Output: OD Cost Matrix -

Step 2:
Add Locations – This tool adds locations which are network analysis objects to the network analysis layer. In this model, the first locations added are the origin locations which consist of the points representing the mid-points of street blocks (which by definition include both sides of the street between two intersections).

Step 3:
Add Locations – This tool adds locations which are network analysis objects to the network analysis layer. In this model, this second instance of Add Locations tool is adding the destination locations which consist of the points representing the type of facility (here it is drinking places).
Output: OD Cost Matrix (3)

Step 4:
Solve tool – Uses OD Cost Matrix (3) and the properties identified earlier to measure the distances between origin and destination points.
Output: Network Analyst Layer – exists in virtual memory

Step 5:
Select Data tool – Selects the Lines data element developed by the Solve tool which exists in the Network Analyst Layer stored in a geodatabase.
Output: Lines data

Step 6:
Copy Features (2) tool – Copies the features from the input feature class into a new layer in the geodatabase for further manipulation. Resides under work/scratch.gdb.
Output: outputodmatrix
The output matrix looks like this:

Notice the ‘Name’ field has the origin node number followed by a dash and then the destination node number. In order to work with these, we need to get them into two separate fields. The field to contain the origin data is called ‘UofA’ and the field to contain the destination data is called ‘DP’. The next several steps are to add the fields and then calculate their contents using the contents of the ‘Name’ field.

Step 7:
Add Field tool – Adds a field to the specified the input feature class (in this case outputodmatrix) in the geodatabase for further manipulation. The feature class resides under work/scratch.gdb/outputmatrix. The field added is called UofA (field type = double). The purpose of this field is to hold the five digit unique unit of analysis number.
Output: outputodmatrix (2)

Step 8:
Add Field (2) tool – Adds a field to the specified the input feature class (in this case outputodmatrix (2)) in the geodatabase for further manipulation. The feature class resides under work/scratch.gdb/outputmatrix. The field added is called DP (field type = double). The purpose of this field is to hold the X digit unique unit of analysis number.
Output: outputodmatrix (3)

Step 9:
Calculate Field tool – Calculates the values in a field according to an expression supplied by the user. In this case, the expression (theValue) is created from a block of Visual Basic (VB) code which calculates the left side of the ‘Name’ equal to the ‘UofA’ field added in Step 7.
theVal
theName = [Name]
theLoc = Instr(theName,”-”)
theValue = Left(theName,theLoc −2)
The first of code creates and sets a variable called ‘theName’ to be equal to the field called ‘[Name]’. The second line of code finds the position number of the dash in the contents of the ‘theName’ field. The third line subtracts 2 from the variable ‘theLoc’ (this was the position of the dash in the string). Output: outputodmatrix (4) Output: OD Cost Matrix (2)

Step 10:
Calculate Field (2) tool – Calculates the values in a field according to an expression supplied by the user. In this case, the expression (‘theValue’) is created from a block of Visual Basic (VB) code which calculates the right side of the ‘Name’ equal to the ‘DP’ field added in Step 8.
theVal
theName = [Name]
theSize = Len(theName)
theLoc = Instr(theName,“-”)
theValue = Right(theName,theSize – theLoc)
Similar to the code in Step 9, the purpose of this code is to extract the numbers representing the destination point’s unique id. The first line of code creates and sets a variable called ‘theName’ to be equal to the field called ‘[Name]’. The second line of code creates and sets a variable called ‘theSize’ equal to the total length of ‘theName’ variable. For the first record in the sample below, ‘theSize’ = 4. The third line creates and sets ‘theLoc’ variable to the position of the dash in the string (first line below ‘theLoc’ = 6). The fourth line creates and sets a variable called ‘theValue’ to be the rightmost part of the string in ‘theName’ variable equal to the difference between ‘theSize’ and ‘theLoc’ (same example , 4−6 = −2). The Expression box tells the computer to set the value of ‘UofA’ equal to ‘theValue’.
Output: Lines (5)
After this step output matrix looks like this:

Step 11:
Make Feature Layer tool – Creates a feature layer from the lines representing the distances from each origin to each destination. This layer is temporary and will not persist after the session ends.
Output: Output Data Layer consisting of outputodmatrix_Layer

Step 12:
Add Join tool – Joins a layer or table view to another layer or table view based on a common field. In this case, the join is from the drinking places shape file to the Output Layer using the DP field. This allows the attributes attached to each drinking place to be used in the calculation of a measure.
Output: Lines (6) a composite of outputodmatrix_Layer

Step 13:
Copy Features tool – Copies the features of the input layer (in this case Lines (6)) to a new layer or feature class. The new feature class is stored in work\scratch.gdb\lines
Output: Lines (7) a composite of outputodmatrix_Layer

Step 14:
Add Field (3) tool – Adds a field to a table. In the model, this is adding the field ‘i_Exp04’ to hold the exposure values for inverse distance weighted count of drinking places in 2004. A value is calculated for each origin–destination pair within the threshold distance. In this case the influence of the drinking place is reduced from 1 based on the distance away from the origin. The farther the distance, the lower the resulting value attached to the drinking place.
Output: Lines (8) store in … work\scratch.gdb\lines

Step 15: Calculate Field (3) tool – Calculates the field ‘i_Exp04’ equal to the formula in the Expression box. In the model, the expression is 1- Sqr (( [Total_Length] /5280)) which is the formula for inverse distance weighting (IDW) of each drinking place.
Output: Lines (9) store in … work\scratch.gdb\lines

Step 16:
Add Field (4) tool – Adds a field to a table. In the model, this is adding the field ‘i_ExpSal04’ to hold the exposure values for inverse distance weighted annual sales a of drinking place in 2004. A value is calculated for each origin–destination pair within the threshold distance.
Output: Lines (10) store in … work\scratch.gdb\lines

Step 17:
Calculate Field (4) tool – Calculates a value for the field ‘i_ExpSal04’ using the expression: (1- Sqr ( [Total_Length] /5280))* [drinking_places04_num_sales]. This field holds the exposure values for inverse distance weighted annual sales of each drinking place within the threshold distance of each street block. A separate value is calculated for each origin–destination pair within the threshold distance.
Output: Lines (11) store in … work\scratch.gdb\lines


Step 18:
Summary Statistics tool – Calculates summary statistics for each field in a table. For each street block (UofA field is used as unique identifier), all the values of the ‘i_Exp04’ and the ‘i_ExpSal04’ are summed. This produces a table with one record for each street block and fields containing the cumulative values for length, ‘i_Exp04’ and ‘i_ExpSal04’.
Output: Lines Sum – a new table that is written out and stored in … work\scratch.gdb\lines_Sum
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media Dordrecht
About this chapter
Cite this chapter
Groff, E. (2013). Measuring a Place’s Exposure to Facilities Using Geoprocessing Models: An Illustration Using Drinking Places and Crime. In: Leitner, M. (eds) Crime Modeling and Mapping Using Geospatial Technologies. Geotechnologies and the Environment, vol 8. Springer, Dordrecht. https://doi.org/10.1007/978-94-007-4997-9_12
Download citation
DOI: https://doi.org/10.1007/978-94-007-4997-9_12
Published:
Publisher Name: Springer, Dordrecht
Print ISBN: 978-94-007-4996-2
Online ISBN: 978-94-007-4997-9
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)