
Abstract
A novel method for automatic classification of magnetic resonance image (MRI) under categories of normal and Parkinson’s disease (PD) is then classified according to the severity of the medical specialty drawbacks. In recent years, with the advancement in all fields, human suffers from numerous specialty disorders like brain disorder, epilepsy, Alzheimer, Parkinson, etc. Parkinson’s involves the malfunction and death of significant nerve cells within the brain, known as neurons. As metal progresses, the quantity of Dopastat made within the brain decreases, defeat someone, and make them unable to manage movements commonly. In the planned system, T2 (spin-spin relaxation time)—weighted MR images are obtained from the potential PD subjects. For categorizing the MRI knowledge, bar graph options and gray level co-occurrence matrix (GLCM) options are extracted. The options obtained are given as input to the SVM classifier that classifies the information into traditional or PD classes. The system shows a satisfactory performance of quite 87 %.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Electroencephalogram (EEG)
- Parkinson’s disease (PD)
- Gray-level co-occurrence matrix (GLCM)
- Support vector machine (SVM)
1 Introduction
Parkinson’s disorder (PD) is the second most typical neurodegenerative illness moving several individuals worldwide. A calculable 7 to 10 million individuals worldwide reside with paralysis agitans. Incidence of Parkinson’s will increase with age, however, associate in nursing calculable 4 % of individuals with palladium square measure diagnosed before the age of fifty. The MR image is used to identify spatial map and properties associated with a specific nuclei or proton present in the region being analyzed. The hydrogen proton is the most common form of nuclei used in MRI. These properties are the spin–lattice relaxation time T1, spin-spin relaxation time T2, and the spin density p. To detect PD, various signals (EEG, speech, etc.) and images (MRI, C.T, etc.) have been undertaken [1].
In [2], of this paper, the authors have proposed a novel technique for automated segmentation of brain structures that are related to PD from low resolution sonographic images. The authors have performed averaging of adjusted spatially varying TCS image as preprocessing step to avoid noise in the image. The segmentation is performed by a tailored shape-based active contour segmentation algorithm.
A novel region of interest (ROI)-based CAD technique using T1-weighted magnetic resonance imaging (MRI) was used to discriminate PD patients from healthy subjects. Features are constructed from gray matter (GM), white matter (WM), and cerebrospinal fluid (CSF) values of voxel from these regions. A decision model is built with the help of support vector machine classifier. The results demonstrate that the proposed method has an accuracy of 86.67 % in identifying PD patients from health subjects [3].
In an expert system proposed in [4], a supervised machine learning approach for identifying sensitive medical image biomarkers which enables automatic diagnosis of individual subjects. Morphological T1-weighted magnetic resonance images (MRIs) of PD patients and PSP patients were analyzed using principal component analysis as feature extraction technique and support vector machine is used for classification.
2 Feature Extraction
2.1 Histogram Processing
The histogram of a digital image with intensity levels in the range [0, L − 1] is a discrete function
where r k is the kth gray level, n k is the number of pixels in the image with that intensity level, n is the number of pixels in the MRI with k = 0, 1, 2, …, L − 1. In short, s(r k ) gives an estimate of the probability of occurrence of intensity level r k [5].
2.2 Histogram Feature Extraction
Histogram equalization is an image enhancement method which uses a monotonically increasing transformation function [6]. The original intensity values r i are transformed using the function T(r) into new intensity values of the output image as follows:
where S r(r i ) is the probability-based histogram of the input image that is transformed into the output image with the histogram S s(s i ). The histogram of the input image is stretched using the transformation function T(r 1) in Eq. (2) in such a way that the intensity values in the output image occurs with equal probability of occurrence.
This method achieves uniform distribution by redistributing the intensity values of an image. This methodology could cause saturation in some regions of the image leading to loss of details and high-frequency data which will be necessary for interpretation.
2.3 Texture Feature
The GLCM is created from a grayscale image and hence the values that are checked for co-occurrence are pixels with gray level (grayscale intensity) [7].
2.3.1 Derivation of Texture Features from a Co-occurrence Matrix
In the simplest form, the GLCM s(a, b) is the distribution of the number of occurrences for a pair of gray values a and b separated by a distance vector d = [dx; dy].
We used 22 textural features in our study. The following equations define these features. Let s(a, b) be the (a, bj)th entry in a normalized GLCM [8]. we define also
and µ x , µ y , σ x , and σ y as the means and standard deviations of S x and S y , respectively. We used the [9] and [10] Haralick texture features with their equations (1–22) in Table 1.
3 Modeling Technique for SVM
Support vector machine (SVM) relies on the principle of structural risk decrease [11]. SVM learns associate degree best separating hyper plane from a given set of positive and negative examples. SVM are often used for pattern classification. For linearly severable knowledge, SVM finds a separating hyperplane that separates the information with the biggest margin. For linearly indivisible knowledge, it translates the information within the input area into a high-dimension area
with kernel operate Φ(x), to find out the separating hyperplane. SVMs area unit evaluated as well-liked tools for learning from the given knowledge [12, 14]. The explanation is that, SVMs area unit is simpler than the normal pattern recognition approaches that supported the mix of a feature choice procedure and a standard classifier.
SVM is generally applied to linear margins. If a linear boundary is out of place, the SVM will map the input vector into a high dimensional feature area. Nonlinear mapping is selected by the SVM constructs to associate the best separating hyperplace in the higher dimensional area. A kernel function K is defined for generating the inner products to construct machines with different kinds of nonlinear decision surfaces within the input area.
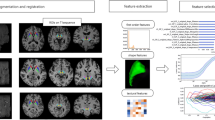
4 Experimental Results
4.1 Dataset
We evaluated the accuracy of our technique by acting experiments on information obtained as a part of the Parkinson’s progression markers initiative (PPMI) (https://www.ida.loni.usc.edu/services/Menu/IdaData.jsp?page=DATA&subPage=AVAILABLE_DATA&project=PPMI). An outline of demographic and psychology details of subjects utilized in our study is bestowed in Table 2.
The database consists of 595 different data groups are available, which 32 are normal and 78 are PD.
4.2 Image Acquisition and Preprocessing
The structural T2-weighted magnetization ready fast gradient echo images were nonheritable on a 1.5-T Vision scanner during an imaging period. From the original image knowledge, the region of interest is fixed to a size of 95 × 95. The ROI is fixed such that it provides enough information for feature selection. Image parameters: TR = 9.7 ms, TE = 4.0 ms, Flip angle = 10, TI = 20 ms, TD = 200 unit of time., 128 mesial 1.25 mm slices while not gaps and pixels resolution of 512 × 512.
4.3 Feature Extraction
The features are extracted using Histogram and GLCM. Histogram is an image enhancement technique which normalizes gray level in the image. There are 8 histogram features and 22 GLCM features extracted from the image data which are combined to form a 30-dimensional feature vector. The cropped image is of size 95 × 95. From the 120 MR images within the dataset, we have used 80 images for training and 40 pictures for testing. The training image set consists of 48 control images and 32 abnormal MR images. Within the training phase, the images are applied to the SVM which creates models numbered zero and one, 0 belong to Normal, 1 belong to PD. In the testing phase, the images are applied to the SVM which extracts the features from the images and creates models, these models are compared with the existing models to classify the image.
4.4 Modeling Using SVM
We use a nonlinear support vector machine modeling that is employed to classify the image. The 30 features that are extracted within the previous section are provided to SVM for model generation. The model generated by the SVM classifies the image information into traditional and Parkinson’s sickness. The character of the dataset, total range of dataset used per class, and also the classification are accuracy is bestowed in Table 3 (Figs. 1 and 2).

Control versus parkinson using SVM

Performance of classification for different combination of feature
5 Conclusions
In this paper, a system for classifying MRI image is described. ROI is manually calculated by cropping the MRI image. Histogram and GLCM features are extracted from the cropped image. 30 features are extracted from the ROI image. The features are given as input to the SVM for classification as Normal and PD. The experimental results show that the classification by SVM can produce a performance of accuracy, sensitivity, and specificity for the classifier (SVM). Measures could only be viewed on testing multiple images.
References
Pezard, L., Jech, R., Ruezlicika, E.: Investigation of non-linear properties of multichannel EEG in the early stages of Parkinson’s disease. Clini Neurophysiol 122, 38–45 (2001)
Sakalauskas, A., Lukosevicius, A., Lauckaite, K., Jegelevicius, D., Rutkauskas, S.: Automated segmentation of transcranial sonographic images in the diagnostics of parkinson’s disease. Elsevier—Ultasonics, 53(1), 111–121 (2013)
Rana, B., Juneja, A., Saxena, M., Gudwani, S., Senthil Kumaran, S., Agrawal, R.K., Behari, M.: Regions-of-interest based automated diagnosis of Parkinson’s disease using T1-weighted MRI. Elsevier—Expert Syst. Appl. 42(9), 4506–4516 (2015)
Salvatore, C., Cerasa, A., Castigilioni, I., Gallivanone, F., Augimeri, A., Lopez, M., Arabia, G., Morelli, M., Gilard, M.C., Quattrone, A.: Machine learning on brain MRI data for differential diagnodid of Parkinson’s disease and progressive supranuclear palsy. Elsevier—J. Neurosci. Methods 222, 230–237, 30 Jan 2014
Gonzalez, R.C., Woods, R.E.: Digital Image Processing, 3rd edn. Prentice Hall, Upper Saddle River (2008)
Freeborough, P.A., Fox, N.C.: MR image texture analysis applied to the diagnosis and tracking of Alzheimer’s disease. IEEE Trans. Med. Imaging 17(3), June 1998
Haralick, R.M., Shanmugam, K.: Textural features for image classification. IEEE Trans. Syst. Man Cybern. SMC-3(6), Nov 1973
Soh, L.-K., Tsatsoulis, C.: Texture analysis of SAR sea ice imagery using gray level co-occurrence matrices. IEEE Trans. Geosci. Remote Sens. 37(2), March 1999
Clausi, D.A.: An analysis of co-occurrence texture statistics using gray level co-occurrence matrices. Can. J. Remote Sens./J. Can. de Teledetect. 28(1), 45–62 (2002)
Sarage, G.N., Sagar Jambhorkar, S.: Enhancement of mammography images for breast cancer detection using histogram processing techniques. IJCST 2(4), 2011
Dhanalakshmi, P., Palanivel, S., Ramalingam, V.: Classification of audio signals using SVM and RBFNN. Elsevier, pp. 6069–6075 (2009)
Jing, H., Bai, J., Zhang, S., Xu, B.: SVM-based audio scene classification. In: Proceeding of IEEE, pp. 131–136 (2005)
Yegnanarayana, B., Kishore, S.P.: AANN: an alternative to GMM for pattern recognition. Neural Netw. 15, 459–469 (2002)
Dhanlakshmi. P.: Classification of audio for retrieval applications. Ph.D. Thesis, Annamalai University (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer India
About this paper
Cite this paper
Pazhanirajan, S., Dhanalakshmi, P. (2016). MRI Classification of Parkinson’s Disease Using SVM and Texture Features. In: Satapathy, S., Raju, K., Mandal, J., Bhateja, V. (eds) Proceedings of the Second International Conference on Computer and Communication Technologies. Advances in Intelligent Systems and Computing, vol 380. Springer, New Delhi. https://doi.org/10.1007/978-81-322-2523-2_34
Download citation
DOI: https://doi.org/10.1007/978-81-322-2523-2_34
Published:
Publisher Name: Springer, New Delhi
Print ISBN: 978-81-322-2522-5
Online ISBN: 978-81-322-2523-2
eBook Packages: EngineeringEngineering (R0)