
Abstract
We will begin by a quick but thorough look at the effects of fault s, error s and failure s, caused by terrestrial neutron s originating from cosmic rays , on the terrestrial electronic systems in the variety of industries. Mitigation measures, taken at various levels of design hierarchy from physical to systems level against neutron-induced adverse effects, are then introduced. Challenges for retaining robustness under future technology development are also discussed. Such challenges in mitigation approaches are featured for SRAMs (Static Random Access Memories), FFs (Flip-Flops), FPGAs (Field Programmable Gate Arrays) and computer systems as exemplified in the following articles: (i) Layout aware neutron-induced soft-error simulation and fault tolerant design techniques are introduced for 6T SRAMs. The PNP layout instead of conventional NPN layout is proposed and its robustness is demonstrated by using the MONTE CARLO simulator PHITS. (ii) RHBD (Radiation-Hardened By Design) FFs hardened by using specially designed redundant techniques are extensively evaluated. BCDMR (Bistable Cross-Coupled Dual Modular Redundancy) FFs is proposed in order to avoid MCU (Multi-Cell Upset) impacts on FF reliability. Its robustness is demonstrated thorough a set of neutron irradiation tests. (iii) CGRA (Coarse-Grained Reconfigurable Architecture) is proposed for an FPGA-chip-level tolerance. Prototype CGRA-FPGA chips are manufactured and their robustness is demonstrated under alpha particle/neutron irradiation tests. (iv) Simulation techniques for failures in heterogeneous computer system with memory hierarchy consisting of a register file, an L1 cache, an L2 cache and a main memory are also proposed in conjunction with masking effects of faults/errors.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Terrestrial neutron
- Soft-error
- Simulation
- SRAM
- BCDMR
- Flip-Flop
- ALU
- CGRA
- Heterogeneous computer system
- Register file
- Cache
- Mitigation measures
1 Fundamentals and Highlights in Radiation-Induced Soft-Errors
Eishi H. Ibe, Exapalette, LLC
1.1 Hierarchy of Faulty Conditions of an Electronic System
Reliability is gaining monumental spotlights as the foremost property that is indispensable for the overall worth of electronic products, in particular, with respect to radiation hardness at the ground [1,2,3]. Once failures take place in electronic systems in the market, the news is spread over the world immediately though the internet and massmedia and the products or even the vender companies may, in the worst case, lose their business chance for a long period of time.
It is believed that the failures should have some sequential steps of symptoms to result in failures in almost all the troubles. In the most electronic systems, the symptom starts with a simple fault in the substrate of a circuit board in the system. Before the fault would grow the fatal failure, there should be many kinds of symptoms towards failures in a variety of situations. In many cases, a substantial part of faults may be disappeared or eliminated during propagation by a certain logical/timing masking effects as illustrated in Fig. 3.1, but some may be captured and fixed in memory elements such as SRAM, DRAM, flash memory, flip-flops, and so on. Once these faults are fixed in the memory elements, they have a lot more chance to cause the system failed.

Hierarchy of faulty conditions: fault-error-failure
It is important, therefore, to detect the faults, error s, and onsets of the failure, and eliminate them at the early stage to prevent fatal failure.
In the present chapter, we will show the basic understandings and examples of countermeasures against evolving threat of soft-error in electronic systems induced by terrestrial neutron s in VLSI devices and systems.
1.2 Sources of Neutrons in the Field and Fundamentals of Terrestrial Neutrons
In space applications, primary cosmic-ray (electrons, protons, and heavy ions)-induced soft-errors and hard-error s (permanent errors by which the device is mechanically destructed) are major concerns in reliability, which may cause failures and eventually determine the life of a space craft [4].
Meanwhile, when energetic cosmic ray protons enter into the atmosphere (troposphere and stratosphere) of the Earth, some protons undergo nuclear spallation reaction with nuclei (mainly nitrogen and oxygen nuclei) in the atmosphere to produce a number of light particles or secondary cosmic rays including neutrinos, photons, electrons, muons, pions, protons, and neutrons. As the cosmic rays are deflected by Heliomagnetic field or the Sun’s activity whose intensity has about 11-year cycle, strength of neutrons at the ground has also about 11-year cycle [5]. The neutron flux at the ground is the lowest, during the solar maximum (states when the Sun is the most active), while it is the highest at the solar minimum (states when the Sun is the least active).
Since a secondary neutron causes a cascade of spallation reactions in the atmosphere, it produces a shower of secondary particles and radiations that reaches the ground of the Earth. As the thick air layer over the ground can shield neutrons, strength (both of flux and energy) of neutrons depends upon altitude with slight dependency on atmospheric pressure [6]. Compared to neutron flux at the avionics altitude (about 10,000 m), therefore, the neutron flux at terrestrial altitude is much lower by a factor of 100–300.
The cumulative flux, which is the sum of total flux from the minimum neutron energy determined by some practical reason (in some standards like JESD89A [7] as below, for example) to the maximum neutron energy, is summarized in Fig. 3.2 with respect to of the terrestrial neutron flux estimated at the NYC sea level [1]. Figure 3.2a can be used for evaluation of the effects of thermal (about 25 meV) or low-energy (<1 MeV) neutrons, and Fig. 3.2b can be used for evaluation of the effects of high-energy (>1 MeV) neutrons. The total flux beyond 10 meV can be estimated 13 n/cm2/h from Fig. 3.2b, which is consistent with JESD89A setting [7]. It is noteworthy that the energy of terrestrial neutrons ranges widely from thermal (25 meV) to high-energy (>1 GeV) and its total flux is about 50 n/cm2/h at the ground including NYC sea level.

Cumulative neutron flux at the NYC sea level. a Low-energy (<1 MeV) neutrons, b high-energy (>1 MeV) neutrons (2015©IEEE [1])
Neutrons themselves are not charged particles, thus do not interact directly with matters except for very limited cases such as nuclear reactions and as summarized in Table 3.1. Only some charged particles, which can be produced as a consequence of nuclear reaction depending on the type of reaction, may cause SEEs . Since the natural abundances of the target nuclei in (i) nuclear fission reaction (235U/238U) are negligibly low, the reactions (ii) neutron capture reaction and (iii) spallation nuclear reaction only matter in the terrestrial fields.
In particular, the reaction mechanism (iii) has major roles in SEEs in the terrestrial fields, and therefore, the neutron reaction (iii) is focused in the present chapter. Only when 10B is contained in the matter, reaction mechanism (ii) may be of concern as explained in Sect. 3.1.6(iv).
Energetic charged particles including secondary particles from the nuclear reactions above interact with matters via Coulomb interaction mechanism.
Namely, while an energetic charged particle passes through the material, an orbital electron (conduction-band electron in solid) is stripped from its orbit by Coulombic interaction with the impinging ion, leaving electron-hole pairs (deposited energy of 3.6 eV is required to produce one-pair of electron-hole pair in Si) along with the trajectory of the impinging ion as illustrated in Fig. 3.3a. This process is called “direct ionization” or “charge deposition”.

Basic physical phenomena in matters by an energetic charged particle. a Charge deposition (direct ionization), b charge collection
The original sum of charges of electrons or holes is called “deposited charge”.
Some or most parts of electrons and holes recombine to disappear in particular in metals and dielectrics because mobility of the carrier is very high (electrons in metals) or low (holes in dielectrics). Some part of electrons and holes can survive from recombination in semiconductor materials under a certain level of potential gradient. (This can take place even in dielectrics under very high potential field.)
Some part of the deposited charges generated in the semiconductor materials can be collected by applying a certain level of potential gradient as illustrated in Fig. 3.3b. This process is called “charge collection” (to the electrode).
1.3 Generation of Faults: Origin of Errors and Failure
There are number of sources of faults in electronic devices and circuits such as SET (SNT and MNT) , power disturbances [3], and EMI [3] as summarized in Table 3.2 and they play very crucial roles in reliability in the electronic systems for the ground applications.
SET is a single transient due to charge collected to a diffusion region in the chip by an energetic particle impingement. Pulse width is below a few nano-second, and can long more than two clock pulses, which may require special and additional design consideration [8].
When SETs take place in multiple diffusion regions, the phenomenon is called MNT (Multiple Node Transient) that may corrupt the protective functions in the redundant circuitries [9].
Cross talk is noise propagation between close wires via parasitic capacitance [10]. Disturbance in power supply [3], and EMI [3, 11] are very important fault sources in electronic systems.
The most important characteristics of faults caused by a single event effect compared to other fault sources mentioned above is that they are initially only localized in a single well or substrate. In other words, it can be said that SET has an internal origin in the transistor structure while other sources have external origins outside transistors. Keeping this difference in mind, we will focus only on faults caused by a single event effect in this book. Please have a look at [3] for details of the last two mechanisms, power disturbance and EMI.
1.4 Transformation of Faults to Errors and Failures
As an SET is a single rapid (pico- to nano- second order) pulse noise in the substrate or well so that it is very difficult, in general, to detect and locate it in the device. Suppression of them to low enough level is also very difficult, but they do not always transform to “error”. Three important concepts of faulty conditions of a system are explained in [1].
An error is an incorrect state in a digital circuit node that could be caused by a data flip in a memory element like an SRAM (Static Random Access Memory) [12], a DRAM (Dynamic Random Access Memory) [13], a flash memory [14], and an FF (Flip-Flop) [15] or an extra delay in a circuit [16]. When an error is caused by ionizing radiation, it is called SEU (Single Event Upset ) or SE (Soft-Error) [7]. When an SEU causes randomly distributed multiple errors, it is also called an MCU (Multi-Cell Upset) [7]. Failure is a malfunction or dysfunction of a system. It is to be noted that a fault may or may not give rise to an error and an error may or may not result in a failure; A fault may or may not be strong enough to cause a memory bit to flip; An errors in a circuit may or may not reflect in the arithmetic results on a system. Furthermore, it is possible to reduce the probability of escalation of faulty conditions. It is therefore very important to characterize the nature of faulty conditions and their behavior in escalation from lower levels to higher levels of hierarchy.
Whether an error causes a failure or not depends on its location and the particular function that the system happens to be performing. Only when an error(s) propagates to the final output and cause malfunction of the system, we call this consequence as “ failure ”. An error does not always cause a system failure, because it may disappear or may be masked during propagation in the chip or board by some masking effects. The real failure rate of a system, therefore, cannot be estimated from the total sum of memory SEUs or SERs (SE Rates) in the system. In order to estimate realistic failure rate of a computer system can be obtained through computer simulation and extended in Sect. 3.5. Some mitigation techniques like parity [17], ECC (Error Correction Code ) [18], and interleaving techniques [19] may be applied to reduce SER. In the parity technique, one extra bit is added to a word (a set of bits) that expresses a character like numbers and alphabets. The data in the extra bit is set according to whether the number of “1” in the word is odd or even. When an SBU takes place in the word, the datum in the extra bit and the word become inconsistent and thus the SBU can be detected. In the ECC, more extra bits are added to a word to correct the error(s) in the word. To reduce speed, area and power penalties, the simplest scheme, Hamming code [18], where an SBU can be corrected based on the coding theory, is commonly applied. Two or more errors in the same word, which is called an MBU (Multi-Bit Upset) cannot be corrected by the Hamming code. Interleaving technique, by which the intervals between the bit in the same word are made wide enough compared to the penetrating ion range, is applied to reduce MBUs.
Failures include shut-down, abnormal operation of the system. Incorrect calculation by using supercomputers can also be categorized into failure. Failure is not recovered by system itself without physical or economic damages.
1.5 Fundamentals of CMOS Semiconductor Devices
In order in primary importance to understand the physical aspects of soft errors in relation to real MOSFET structure. A brief look at the structsure of CMOS (Complementary Metal Oxide Semiconductor) devices [20], which are commonly recognized as the most vulnerable semiconductor structure to neutron-induced soft-error, such as SRAMs, FFs and most logic circuits is given here. CMOS circuits are basically built on the identical striped structure of p and n- dual wells as illustrated in Fig. 3.4a for one bit of an SRAM or one OR gate. Unlike dual well structure (this structure is often called “bulk”) as illustrated in Fig. 3.4b, triple-well structure has an additional deep n-well to isolate Si-body from electrical disturbance in the substrate. It is recognized that the triple-well structure have some benefit for soft-error resilience because the volume of charge collection is limited and reduced above the deep n-well.

Basic layouts of CMOSFET devices on a the striped structure of p- and n-wells and b cross sections of triple and dual wells
In SOI (Silicon On Insulator ) devices [20], BOXs (Buried-OXides) [21] are made under the dual wells to isolate the Si-body vertically and completely from the substrate. Isolation oxides such as Shallow Trench Isolation (STI) oxides are also made to isolate each node in lateral direction for such a structure. The SOI structure, therefore, has more advantages in soft-error resilience than triple-well structure does.
Further challenges have been made on the SOI structure: When the thickness of the SOI layer is thinner than the depth of depletion region in the SD (Source-Drain) channel, the structure is called FD (Fully Depleted) SOI [22]. Meanwhile, when the thickness of the SOI layer is thicker than the depletion region, the structure is called as PD (Partially Depleted) SOI [23]. Since the upper surface of BOX in FDSOI is covered fully with the depletion region, parasitic capacitance can be largely reduced compared to bulk/PDSOI devices, resulting in steep sub-threshold characteristics, reduction in latency, and power consumption.
Sugii et al. develop Silicon on Thin BOX (SOTB) [24] structure by which backgate bias can be applied in Silicon substrate below the bottom of thin (about 10 nm thickness) BOX in order to control Vth [24] (see Sect. 3.3 for more details). This structure is also called as double-gate structure because the Si-body is sandwiched by the conventional gate and the backgate.
The structure of Si-body has been changed continuously year by year as mentioned above, and will also be changed even drastically in the future. The challenges to enhance the resilience of CMOS devices, however, have to be started continuously and simply with Si-body structure because it is the initial condition of the failures regardless of the memory or logical origins.
1.6 Effects of Ionizing Radiation on Semiconductor Circuits
-
(i)
Soft-Error
As first found in alpha particle-induced soft-error mechanism [25], a high-energy single charged particle that hits a semiconductor generates a number of electron-hole pairs along its trajectory as illustrated in Fig. 3.5a, which is similar to Fig. 3.2a used for general material. When a charged particle penetrates into a depletion region at the bottom of the storage node of semiconductor memory cell (diffusion region), electrons flow into the off-state storage node (with “high (1)” potential for an n+ node, for example) in accordance with electromagnetic field there as illustrated in Fig. 3.5a. The mechanism shown in Fig. 3.5b is again called charge collection mechanism. The potential in the node is eventually lowered down by charge collection below the threshold potential between “1” and “0”, resulting in an SEU or a soft-error to flip the data from “1” to “0”. The flipped state can be recovered without any physical damages in the semiconductor device simply by rewriting data. This is why the phenomenon is called “soft”-error. In addition, charge collection is intensified by funneling effect [26], in which electrostatic field in the depletion region is elongated beneath the original depletion region by flowing electrons themselves and more electrons than initially contained in the depletion region are collected. Charge collection may cause SEU in both DRAM and SRAM [12] when the collected charge exceeds the critical charge Qcrit, which can be estimated by

Physical phenomena in basic nMOSFET structure with deep n-well induced by a high-energy particle. a Charged (secondary) particle penetrates through an \( n^{ + } \) diffusion region (storage node) and charge deposition. b Charge collection to the diffusion region
where,
- C s :
-
storage node capacitance;
- V cc :
-
supply voltage.
The principal metric that stands for the vulnerability of semiconductors is SER (Soft Error Rate), which is calculated by
The unit of SER is FIT (Failure In Time : number of events/109 h). Another unit, FIT/Mbit (of memories), is commonly used referring to the SER per memory bit capacity.
-
(ii)
Error modes other than soft-error
Unlike soft-error, there are other error modes that cannot be recovered by rewriting.
SEFI (Single Event Functional Interrupt) is an error mode in logic circuits by data flips in FFs contained in the logic circuits [27]. State in an FF can be flipped in two ways by an ion hit. One is capture of an SET from the input of an FF. The other is data flip by direct hit into an FF storage node by ionizing radiation. An SEFI may be related to the FF behavior but is not understood fully. It is said that it cannot be recovered by rewriting of memory data, but can be recovered by resetting FF data to default values [1].
SEL (Single Event Latchup) is a phenomenon in which a pnpn switch is turned on resulting in an Idd current increase accompanying a number of circuit errors [28]. SEL cannot be recovered by re-writing but can be recovered by power-cycling (power off and then power-on) [7]. SEB (Single Event Burnout) and SEGR (Single Event Gate Rupture) are permanent destructive modes of radiation effects in power devices [29,30,31].
-
(iii)
The influence of scaling on radiation-induced faults or SER
Scaling (shrinking) the feature size (linewidth and spacing) has been the key to reduce power consumption, increase density and performance of LSIs, and, therefore intensely pursued for many decades [32]. From a viewpoint of SEE, however, there are some conflicting impacts by scaling
-
(1)
The smaller a memory size becomes, the lower the probability to be hit by an energetic particle, resulting in reduction of SER.
-
(2)
In addition, volume for charge collection become smaller, the amount of collected charge gets smaller compared to Qcrit, resulting in reduction of SER.
-
(3)
Capacitance of a storage node Cs is, in principle, in proportion to the area of a storage node. Scaling of memory cell, therefore in general causes decrease in the capacitance and worsens susceptibility of a memory cell due to decrease in Qcrit (∝CsVcc).
-
(4)
The distance between adjacent storage nodes is shortened by scaling, which causes “charge-sharing” [33] between multiple nodes. This causes an increase in MCU ratio to total SEUs.
-
(5)
The distance between pn-junctions is also shortened, which causes increase in susceptibility to bipolar effects including latchup. Such bipolar effects are becoming dominant in CMOSFET (CMOS Field Effect Transistor) circuits as a result of scaling (see Sect. 3.1.7 for more details).
The impacts (1) and (2) are beneficial for SER reduction. The impacts (3)–(5) are adverse effects. They are in a trade-off relation and, therefore, SER may increase or decrease depending on which mechanism is dominant.
Next we will discuss how SER at which errors occur in a device, is estimated. When a single particle penetrates into a device(s), it can cause multiple transients or multiple errors. By definition, physical consequence due to one single particle including neutron is called an SEE . When an SEE causes an error(s), we call this phenomenon SEU. Therefore, SEU can consist of multiple errors. Important thing is that SER is defined by the number of SEUs, not by the number of errors.
Another important quantity used in this chapter is SEU cross section σseu that is defined by
where,
- N seu :
-
the number of SEUs (not errors!)/count;
- Φp:
-
fluence of particles (neutrons)/(n/cm2).
Fluence means the total number of particle passed through a unit area.
σseu can be measured in experiments using radio-isotopes or accelerators [1] and one can calculate SER by using the σseu as follows:
where,
- <σseu>:
-
is an average of σseu over particle energies to adjust for actual field (or packaging) environment;
- ϕp:
-
flux of the particle/(count h−1 cm−2);
- FIT:
-
Failure In Time, SER in 109 h.
Flux means the number of particles that pass through a unit area per unit time.
1.7 Bipolar Action: A Newly Found Mode of Radiation-Induced Faults
As explained in Sect. 3.1.5, electron-hole pairs are produced along the trajectory of a high-energy particle when it passes through a semiconductor device. If the particle passes through the depletion region of the pn-junction under an off-state n-diffusion at the potential Vcc, electrons in the depletion region are collected to the n-diffusion region to cause a single event fault or a SEU and holes are repulsed out of the depletion region.
Ibe et al. pointed out that, in addition to the charge collection described so far, there is a novel soft-error mechanism, which they called Multi-Coupled Bipolar Interaction (MCBI) [34]. When a high-energy charged particle passes through the pn-junctions, not below the diffusion region, for example, in the side wall of the p-well in the triple-well CMOS structure as shown in Fig. 3.6a, direct ionization or charge deposition, by which electron-hole pairs are produced along with the track, similarly to Fig. 3.5a. Then, as illustrated in Fig. 3.6b electrons produced in the well flow out of the well by the same funneling mechanism as the conventional soft-error mechanism, leaving the holes in the well. These holes can make the well potential high enough to turn the parasitic npn transistor in the well “on” as illustrated in Fig. 3.6c. As a substantial number of nodes are contained and flipped in a single common well, the “high” nodes in the MCBI region can be flipped simultaneously to cause MNT or MCU.

Physical phenomena in basic nMOSFET structure induced by a high-energy charged particle. a Charged particle penetrates through pn-junctions on the side wall of the p-well and generate electron-hole pairs. b Electrons flow out of the p-well and holes remain in the p-well. c Holes elevate the potential in the p-well, resulting in turning the parasitic transistor on to cause soft-error
1.8 A Perspective of Progresses in Research and Engineering of Radiation-Induced Soft Errors
In this subsection, a historical review will be given regarding how technology challenges were encountered in the issue of radiation-induced soft-errors in LSIs and how engineering have solved them. Ever since alpha particle soft error was first discovered in DRAMs in 1979, a few distinctive paradigm shifts have been experienced.
-
(i)
First paradigm (1979–1990s) where SRAM design rule and density are >250 nm and <64 kbits, respectively: It is well known that alpha particle-induced soft error in DRAM was discovered by May et al. in 1979 [25]. In the same year, the possibility of soft-error due to terrestrial neutron is pointed out by Ziegler and Lanford [35]. As the impact of alpha particles on DRAMs appeared to be most devastating at that time, engineering attention was focused on alpha particles. By the early 1990s, alpha particle soft error in DRAMs was overcome by several effective countermeasures such as stacked or trench capacitors to enhance storage capacitance [36], triple-well structure, usage of purified low-alpha materials, and shielding by package materials [37,38,39]. Thus, soft errors in LSIs for terrestrial applications did not get much attention until the late 1990s.
-
(ii)
Second paradigm (late 1990s–2000) was experienced when SRAM design rule and density were around 130 nm and 128 k–4 Mbits, respectively: The terrestrial neutron-induced SER of SRAM was found to have become much higher than DRAMs [40]. It is understood that SER in DRAMs, which have embedded capacitors to keep high Qcrit, naturally has decreased thanks to the beneficial effects of scaling as mentioned previously in Sect. 3.1.3 (iii) (1) and (2). Meanwhile, SRAMs do not implement any artificial capacitor, and, therefore, SER in SRAMs has drastically increased by the adverse effect mentioned in Sect. 3.1.3 (iii)(3).
-
(iii)
Third paradigm (2000–2005) was experienced when SRAM design rule and density were around 90 nm and 8 Mbits, respectively: Filing neutron irradiation data report to users was mandatory for memory venders, and this triggered discussions on neutron standard testing methods worldwide. As a consequence, JESD89 [41] for neutron, proton and α-ray SER testing method were issued as the de facto soft-error testing standard in 2001. In the third paradigm shift, concerns on neutron soft-error further spread over two directions from around 2004. One direction was concerns about MCU that emerged from about 130 nm process due to bipolar effects [42] and charge-sharing effects [43]. When a MCU takes place in more than two bits in the same word of SRAM, it cannot be recovered by using EDAC (Error Detection and Correction) or ECC (Error Checking and Correction) to result in system crash. EDAC or ECC can detect two-bit errors and correct one-bit error, but cannot correct two-bit errors in the same word (MBUs). It was found that almost all MCUs had taken place in one single MOSFET well and been aligned along with the only two adjacent bit lines. Based on this finding, newly found problem of neutron-induced MCUs in SRAMs was basically overcome by applying both ECC and interleaving with a small interval [34]. Another direction was to address concerns about single event transient (noise) in sequential and combinational logic devices. SERs (Soft-Error Rates) in flip-flops were predicted to be close to that in SRAM beyond 90 nm design rule [44], but there had been no effective detection and correction methods in logic devices except for redundancy techniques. Moreover, obvious threats of common-node failures or those due to MNT had been found in most space redundancy techniques, like TMR [45] and DICE (Dual-Interlocked storage Cell) [46]. If an MNT happens in two modules of TMR or two input nodes of DICE, recovery mechanism fails and may result in SDC (Silent Data Corruption) that cause unrecognizable system failure [47]. Uemura et al. [48] and Lee et al. [49] proposed ideas to harden DICE-like flip-flops by changing layout of nodes independently in 2010.
In addition to the two distinct directions described above, Baumann et al. pointed out soft-error caused by thermal neutron caption reaction by 10B that has natural abundance of 19.9% in Boron contained in the BPSG (Boron Phosphor Silicate Glass) used for the planarization of wafer surface [50]. When a thermal neutron, mostly of cosmic origins, which has a typical energy of 25 meV in equilibrium with atmospheric molecules, is captured by a 10B nucleus, a He ion (1.47 MeV) and a 7Li ion (0.84 MeV) are released to cause soft-errors by ionization. This type of soft-error seemed to have been overcome by changing the planarization process from BPSG to CMP (Chemical Mechanical Polishing), which does not use Boron.
-
(iv)
Fourth paradigm (2006–2009) was experienced where SRAM design rule and density were around 65 nm and 16 Mbits, respectively: Discussions on revision of JESD89 was started in 2003 because the original JESD89 had a number of limitations: the only testing facility assigned as the standard facility was the spallation neutron source in Los Alamos National Laboratory, for example. The new version JESD89A [7] was issued in 2006 with more practicable and reliable testing and analysis methods including quasi-monoenergetic neutron test method. Differential spectrum of terrestrial neutron was revised and a certain number of neutron irradiation facilities were added as the standard facilities. IEC60749-38 standard that is consistent with JESD89A was issued in 2008 as the de jure standard [51].
-
(v)
Fifth paradigm (2010) was experienced when SRAM design rule and density were <40 nm and >32 Mbits, respectively: the impact of soft-errors spread over large electronic systems. For big data-centers [52] or exa-scale supercomputers [53], power reduction had been one of the most important design issues. The space redundancy techniques that require large areas and power overheads would not be therefore applied to such big systems, in principle. Real-time (safety critical) systems like avionics or micro-control units in automobiles are also becoming under serious concerns and in-depth studies were widely undertaken [54, 55]. AEC Q100 G [56] and ISO26262 [57] for automobiles were also issued in 2008 and 2011, respectively.
With a common recognition that soft-error-induced system failure cannot be suppressed to satisfactory level by applying mitigation techniques only to a single design stack layer (device, circuit, chip, board, firmware, OS, middleware, and so on), communications between and combined mitigation techniques among stack layers have been encouraged as unavoidable direction [58,59,60,61]. In reality, such collaboration has turned out to be very difficult since the basic engineering skills in each stack layer are essentially and significantly different. Most engineers/researcher cannot expand their specialties beyond their own stack layers. Novel strategies to overcome this situation are needed to be explored and being proposed. Built-in communication scheme among the stack layers has been proposed by Ibe et al. in their LABIR (inter-Layer Built-In Reliability) concept [62, 63]. Evans et al. have proposed the RIIF (Reliability Information Interchange Format) as common format or protocol to be used in system design among stack layers [64].
In the possible sixth paradigm shift, other terrestrial particles, like muons, low-energy neutrons, protons, are being pointed out as a possible SER threat at the ground [65]. Alpha particle with VLA (Very Low-Alpha)-level package can again cause soft-errors in SRAMs [66]. Sub-100 nm SRAMs have a substantial susceptibility for soft-error due to terrestrial muons [67]. Low (thermal) energy neutron causes soft-error due to neutron capture reaction of 10B in device without BPSG processes [68, 69]. Concerns on electrons (beta rays) and gamma rays have been boosted after the severe accident in Fukushima-1 nuclear power plants [70, 71].
1.9 Spreading Concerns on Failures in Industries
Table 3.3 summarizes recent concerns in various fields of industry related to single event effects with applications, possible root causes, and observable failure symptoms [72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88].
In avionics, TMR is applied to critical components to avoid fatal failures and faults can be found through error flags from TMRs [72]. IGBTs (Insulated Gate Bipolar Transistors) are used in trains [73], automobiles [29,30,31] and avionics for inverters. They are subject to destructive SEE mode, SEB, due to electron avalanche by a charged particle penetration in pnp structures. SEEs in servers [74, 75] and routers [76] have been main concerns in networks because they use a tremendous number of memories, in particular, SRAMs. Power supplies for network systems like DC–DC converters are also vulnerable to terrestrial radiation in the destructive mode [77].
In large-scale supercomputers like TITAN in ORNL (Oak Ridge National Laboratory) , it has been reported that about 10 errors take place in a day [78]. In particular, SDC s by which wrong results are obtained without any error evidences after extremely massive and costly calculations [79, 80], is one of the most serious concern in resilience. DUEs (Detected Unrecoverable Errors) are also major concern in microprocessors, in particular, for the systems that are not allowed to stop. It is said that the rate of DUEs is higher than that of SDC in cache memory [81]. Capture and recovery of SDCs and DUEs impacts is top-priority issue in real time, safety critical systems.
Concerns about automobile systems reliability are spreading rapidly and widely, on the brake by wire [82], power steering [83], engine control [84], communication protocol in a car like CAN (Controller Area Network) [85] and LIN (Local Interconnect Network) [86]. GPUs (Graphic Processing Units) or GPGPUs (General-Purpose GPU) are being widely used for many purposes including nodes for supercomputers thank to its high ability in parallel computing. Rech et al. made a neutron beam testing at ISIS for 40 nm GeForce GTX480 and showed high susceptibility of GPUs to terrestrial neutrons [87]. Pedestrian detection at night is one of the most important safety requirements (“Five star” in Euro NCAP rating) where GPUs are used in future.
Even portable digital applications, like smartphones and tablet PCs, have been tested under neutron irradiation [88]. Obviously, no electronic equipment is free from threat due to SEE by terrestrial radiations, these days.
There are a number of fault/error/failure modes that reflect their root-cause mechanisms. Prediction and estimation techniques of faulty conditions and their rates of occurrence have a primary importance in designing devices, circuits and electronic systems. Detection techniques of faulty conditions must be advanced to know the nature of the faults/errors/failures based on their underlying physical mechanisms and to validate the prediction and estimation techniques. Cost-effective resilient techniques may be assigned according to each nature of the failure and application. The following sections introduce some examples of prediction/estimation, detection and classification techniques of fault/error/failures.
1.10 Conventional and Advanced Mitigation Techniques
As explained in Sects. 3.1.5 and 3.1.6, an SET takes places only in well/substrate region. Therefore, strategies to mitigate soft-errors in devices or failures in electronic systems boil down to simple strategies as summarized in Table 3.4 with some typical examples [1, 24, 89,90,91,92,93,94,95,96,97,98]:
-
Restriction of production of faults in wells or acceleration of recombination of electron-hole pairs.
Implantation of catalyst element like Au in wells is possible choice.
-
Restriction of production or collection of charges in the relevant volume. Triple-well structure is among such techniques. Volume of the triple well and depth of STI (Shallow Trench Isolation) can be important factor to reduce charge production and collection. Layout of pMOS and nMOS is also one of key design points in order to reduce MCUs in memory cells (see Sect. 3.2).
-
Recovery of errors in memory elements. ECC for memories and DICE, BISER (Built-In Soft Error Resilience), BCDMR (Bistable Cross-Coupled Dual Modular Redundancy) for FFs are among such techniques (see Sect. 3.3 for more details).
Failures take place when an error propagates to the final output of an electronic system. Therefore mitigation techniques for failures are
-
Enhancing masking effect to prevent propagation of errors in the circuitry.
-
Space redundancy techniques to cancel out errors. TMR (see Sects. 3.3 and 3.4) and DMR (see Sect. 3.3) are typical methods. DCC (Duplication + Comparison + Checkpointing) [98] is an extended version of DMR. Lock-step operation of dual processors is mainly applied to automobile MCUs (Micro-Control Units).
Power consumption is one of major metrics that determine the mitigation techniques to be applied in large-scale systems like data-centers and supercomputers [53, 58, 59, 79, 80]. “Dark silicon” refers such constraints on performance and reliability due to power consumption [52]. Space redundancy techniques such as TMR and DMR may not be applied to such large big data systems in order to avoid large power consumption.
MCU may cause deactivation of space redundancy technique by simultaneous errors in redundant nodes. Layout design of redundant node must be carefully conducted (see Sect. 3.3).
-
Time-redundancy techniques to cancel out errors. RAZOR [99] is one of simple solutions for FFs. RCC (Replication + Comparison + Checkpointing) is a typical time redundancy technique for an extra-large electronic systems from the viewpoint of suppressing power consumption, but concerns are addressed on even such time-redundancy techniques because error rate may exceed checkpointing frequency [79].
-
FPGA (Field Programmable Gate Array) s are being widely used in a variety of applications due to their versatility and adjustability in programming [100]. Programs for operation of electronic systems are initially written and fixed in CRAM (Configuration RAM). Errors in CRAM may cause fatal failure due to malfunction of operation. Prompt detection of errors in CRAM and reconfiguration of CRAM are key techniques for reliability in FPGA (refer to Sect. 3.4).
Shimbo et al. have recently developed non-stop recovery CRAM system by using an embedded controller into FPGA array [101]. This kind of approaches seems to be promising in future.
-
Reliability for the entire computer system is far more difficult to achieve and challenging because of its complexity and dependence on applications (refer to Sect. 3.5).
1.11 Symptom-Driven System Resilient Techniques
Ibe et al. [63, 64] proposed the LABIR approach that is a recovery method driven by a hardware error symptom . Symptom-driven techniques originally meant that predetermined optimization process for isolation of faulty conditions in electronic systems were initiated upon capturing any pretabulated “symptoms” of faulty conditions in OS [102, 103]. This approach utilizes the so-called fuzzy/intelligent expert systems. Unlike this approach, Ibe’s proposal is specific only to SEEs which evolve in a well as a detectable symptom. In this scheme, the recovery process is triggered by detecting the symptom before it grows to error/failure and the system is recovered in CPU or application level by means of time-redundancy techniques such as checkpointing and rollback [104]. It can avoid large area, power overheads because it does not apply space redundancy techniques such as TMR. In general, since time-redundancy techniques always apply the same procedure twice and make comparison, speed penalty is inevitable. Since terrestrial neutron-induced soft-errors and resulting symptoms do not take place so often (one per hour even for the largest super computers [105]), this approach can be adopted with a very small speed penalty. Software symptom based approaches are also proposed on the basis that only errors that affect execution of instructions have to be taken care of, while other errors can be left “don’t care” In this section, possible examples for such approaches are introduced.
-
(i)
Hardware symptom
LABIR proposes interactive or communicative mitigation techniques in which a recovery action such as rollback to the checkpoint is triggered when a layer finds any error symptom, not necessarily error or fault itself.
As illustrated in Fig. 3.7, immediately after capturing such a symptom, errors or failures can be removed by a rollback-and-replicate operation in CPU level of the chip. In the case of the example in Fig. 3.7, sense amplifiers are applied to detect slight potential differences between adjacent two p-wells, so that other source of noises like EMI and noise in power supply line [105] propagate in wider area than soft-error over many wells so that they can be eliminated as well by the differential method between adjacent wells. BIST (Built—In Self-Test) [106], Built-In Current (Pulse) Sensor (BICS [90, 107], BIPS)), SAW (Surface Acoustic Wave)-based symptom detector [81], on-chip monitor [108] can be used for such kind of technique. By using BIPS, a pulse propagated from a zone penetrated by a charged particle in p-well can be detected in Idd line by using an embedded current or pulse sensor. In the SAW-based symptom detector, the surface acoustic wave generated by a hazardous event at any location in the semiconductor device is captured by micro-cantilever type detectors. The location of charged particle penetration is calculated by the capture time difference among the detectors. In the on-chip monitor approach, multiple micro-pulse monitors are embedded in the peripheral area of a chip to monitor noises in selected locations.

An example of LABIR (inter-LAyer Built-In Reliability)
-
(ii)
Software symptom
Li et al. has proposed a software–hardware co-designed resilient super-scalar system where failure symptom is detected mainly by software and recovery and diagnosis (software bug/permanent error/transient) are made during rollback from checkpoint [109]. Reconfiguration is made in fine grains based on the diagnosis. Fault injection is applied to Solaris-9 OS with the UltraSparc-III ISA. Application and OS crashes and hang-ups are monitored and classified by injected component. These authors have reported that a large fraction of the faults results in OS failures so that and that recovery methods for OSs must be developed.
Hari et al. proposed a symptom detector to detect fault including SDC in software behavior [110].
Wang et al. has proposed SBRM (Symptom Based Redundant Multithreading) where symptom of failure is monitored on software like deadlock, exception handling, miss-instruction in control flow, and error in the cache/translation look-aside buffer [97]. Instructions are executed simultaneously in two threads. Symptom monitoring is applied only to the redundant thread and results in two threads are compared. If the results do not match, an error signal is delivered and restore process is initiated. Checkpointing supported with input replication, symptom detector, and control logic for pipeline flush is used for restore process. Fault injection in the RTL model of Alpha microprocessor is made while SPEC2000 Integer benchmarks operated. By choosing deadlock and exception handling as symptoms, it has been demonstrated that 75% of errors can be recovered with a speed loss of only 2%.
1.12 Challenges in the Near Future
Table 3.5 shows future trends, conventional approaches against failures, challenges, and global standards being worked out relevant to the fault/error/failure modes actually encountered in various industry sectors.
In safety critical system or real-time system like avionics and automobiles, weight saving in structural materials is one of major trends to reduce fuel and power consumption. Usage of GPUs will be extended to much wider areas [87]. Millisecond recovery is one of the most challenging themes in real-time systems. In railway systems, further computerization will proceed to realize cost effective, connected, and resilient railway systems [111]. In exa-scale supercomputer system, paradigm shifts in dependability techniques including HW and SW must be realized to avoid failures due to very frequent errors including SDC and DUE (Detected Unrecoverable Error) [112].
In network system as well as supercomputer system, large power consumption will be a serious bottleneck for selection of mitigation techniques.
PDA (Personal Digital Assistance) s or smartphones are being increasingly utilized to control in-house digital appliances remotely. Noise disturbances and malicious attacks must be considered as possible causes of serious accidents [113].
Best combination of mitigation techniques as in LABIR/Cross layer reliability should vary by industry and need to be extensively pursued as well as development of novel key technologies. A list of global standards with their objects and category types such as IEC61508, ISO26262, JESD89A, and so on are listed in Table 3.5.
In addition, it is predicted by SRAM soft-error simulation that further scaling may have significant impacts of processor/computer system design [112]. Namely,
-
As scaling proceeds, Qcrit will decrease below 1 fC or even below 0.1 fC. This causes an extensive increase in area affected by an SEE: For 130 nm design rule, 100 bit × 100 bit SRAM memory matrix can be affected by an SEE, while 1000 bit × 1000 bit SRAM memory matrix would be affected by an SEE beyond 22 nm design rule. When the SRAM has six transistors, the area containing 6M transistors would be affected by an SEE for 22 nm design rule, resulting in unprecedented difficulty in reliability design of processor/computer systems. New breakthrough technologies are obviously required.
2 Soft-Error Tolerant SRAM Cell Layout
Shusuke Yoshimoto, Kobe University
Masahiko Yoshimoto, Kobe University
Hiroshi Kawaguchi, Kobe University
2.1 Introduction
Nano-scaled integrated circuits are susceptible to particle-induced single event effect (SEE) because of their low signal charge and noise margins [31, 65, 113, 114]. Particularly the effect of multi-cell upsets (MCUs), in which a single event results in simultaneous errors in more than one memory cells, have been closely investigated. MCUs are caused by collection of charges produced by secondary ions in neutron-induced nuclear reaction [1]. The ratio of MCUs to single event upsets (SEUs) is predicted to increase drastically in nano-scaled SRAM s [2, 33, 43, 114].
Figure 3.8 shows a schematic and a layout of a general 6T SRAM cell with a typical 65-nm CMOS logic design rule. In the design, the sizes of the transistors are relaxed to suppress threshold voltage variation so that the cell area is about twice as large as a commercial 65-nm 6T cell [115]. The 6T cell consists of PMOS load transistors (PL0, PL1), NMOS driver transistors (ND0, ND1) and access transistors (NA0, NA1). A wordline (WL) and two bitlines (BL, BLN) are horizontally and vertically connected among cells, respectively. In the layout of the general 6T cell, the PMOS transistors are centered in the memory cell; this structure is called an NMOS-PMOS-NMOS (NPN) layout hereafter.

a Schematic and b NMOS-PMOS-NMOS (NPN) layout of a general 6T SRAM cell
Figure 3.9 shows sensitive nodes in the general 6T cell layout: a low-state (“L”) PMOS diffusion and a high-state (“H”) NMOS diffusion. We have observed that the NMOS has a four-times larger SEU cross section than a PMOS for a wide range of supply voltages (see Fig. 3.10) [116]. The simulation results come from an iRoC TFIT soft-error simulator [117] with a database of a generic 65-nm bulk CMOS process [118].

Sensitive nodes in a general NPN 6T SRAM cell

In this subsection, we present a neutron-induced soft-error rate simulation tool and two types of soft-error tolerant SRAM cell layouts. Results show that the proposed memory cell layouts favorably affects their reliability; they enhance the effectiveness of single error correcting-double error detecting ECC (SEC-DED ECC).
2.2 Neutron-Induced Soft-Error Rate Simulator
Figure 3.11 illustrates a flow chart of our neutron-induced soft error simulator [116] using PHITS, the Particle and Heavy Ion Transport Code System [119]. The input data for PHITS are neutron spectrum data, device structure data, and nucleus reaction models. The cosmic-ray neutron spectrum is calculated using an Excel-based Program for calculating Atmospheric Cosmic-ray Spectrum (EXPACS) [120], as shown in Fig. 3.12. The device structure is constructed as presented in Fig. 3.13.


Cosmic-ray neutron flux normalized to ground level in New York City. Flux is calculated with EXPACS [120]

Device structure based on a 65-nm general 6T SRAM cell layout (logic rule basis) [120]
The device structure includes the cell property (width, height, and position of sensitive nodes), a cell-to-cell pitch in a cell array, and data patterns. The cell height, width, and position of the sensitive nodes are modeled as presented in the figure. The diffusion area is derived from the transistor width and the cell height. The clearances between diffusion edges are all equal.
The PHITS can export secondary particle dump files presented in Fig. 3.14. In our simulation, the dump files are generated in respect to NMOS and PMOS sensitive volumes in an SRAM cell. The dump file includes nucleus reaction IDs (event numbers), atomic weight, geometry points (X, Y, Z), velocity vectors (dX, dY, dZ), and energy in the point (E). The deposit energy (Edeposit) is calculated with the dump files in the respective sensitive nodes. The deposit charge (Qdeposit) is calculated using the following equation, in which e is the elementary charge:

Product-dump and cross-dump data related to secondary ions: a crossing the sensitive area, b entering the area, c leaving the area, and d remaining in the area
When a secondary particle deposits more charge than the critical charge (Qcrit) to at least one memory cell, that particle is classified as a single event upset (SEU) particle. Finally, single-bit-upset and multi-cell-upset soft-error rates (SBU and MCU SERs) are calculated at every SEU particle event.
2.3 PMOS-NMOS-PMOS (PNP) 6T Cell Layout
The proposed 6T cell is designed as a PMOS-NMOS-PMOS (PNP) layout in Fig. 3.15. The NMOS-centered 6T layout has the same transistors as the general one. The WLs and the BLs are assigned in horizontal and vertical directions, respectively.

Layout of a proposed PMOS-NMOS-PMOS (PNP) 6T cell
Figure 3.16a shows an SRAM cell array using the general NPN 6T layout. In the conventional 6T SRAM, the sensitive NMOS nodes are in the same P-well in the horizontal direction; horizontal upsets can be easily incurred. In contrast, the proposed PNP 6T cell can lower a horizontal MCU rate because the NMOS-centered layout can separate the horizontally adjacent NMOS sensitive nodes with the N-well as shown in Fig. 3.16b.

SRAM cell arrays using a general NPN 6T cell layout and b proposed PNP cell layout
The proposed layout has the same schematics and the cell area on the 65-nm logic rule basis, so that the proposed design can be implemented only by replacing its cell layout. Note that shared contacts, which are commonly used in an industrial SRAM rule, cannot be applied to the proposed 6T cell layout. This drawback incurs a certain area overhead in the SRAM rule basis design.
We designed and fabricated 1-Mb SRAM test chips consisting of 256-Kb macros of four types (NPN layout with twin well, PNP layout with twin well, NPN layout with triple well, and PNP layout with triple well). Figure 3.17 presents an experimental setup for a neutron-accelerated test. The neutron irradiation experiment was conducted at The Research Center for Nuclear Physics (RCNP), Osaka University. Spallation neutron beam generated by the 400-MeV proton beam irradiates a board under test (BUT) 7892-mm far from a tungsten target, on which three sample chips are placed in a BUT, for 30 h. The neutron flux is normalized to 13 cph/cm2 above 10 MeV at ground level in New York City [7], which incorporates scattering effect [121], attenuation effect [44], and board screening effect [122].

Setup for neutron-accelerated test
As presented in Fig. 3.18, an MCU SER in the vertical direction is called MCUBL=1 in this paper, and an MCU SER in the horizontal direction is called MCUBL>1. The MCUBL>1 is more important for designers to adopt the interleaving and/or ECC strategy.

Multiple-cell-upset patterns: a MCUBL=1 and b MCUBL>1 are defined respectively by vertical fail bits in a same column and by horizontal fail bits in two or more columns
Figure 3.19a–d illustrate measured MCU SER in the four data patterns at the supply voltage of 1.2 V. When using the CHB (checkerboard), CS (column stripe), and RS (raw stripe) patterns, the MCUBL>1 in the PNP 6T SRAM can be suppressed by 86–98% compared to the general NPN layout. The proposed PNP layout separates NMOSs from adjacent ones in the horizontal direction, which reduces the MCUBL>1 SER. In the ALL0 (all zero) pattern, the MCUBL>1 even in the general NPN cells is low in nature because the sensitive nodes are not horizontally adjacent in a single bitline. As a result, only 67% improvement is observed in the MCU SER. The proposed PNP layout with the dual-well structure achieves MCUBL>1 SERs of 5.78, 4.58, 9.48, and 4.70 FIT/Mb in the CHB, ALL0, CS and RS patterns and the PNP layout with the triple-well structure achieves MCUBL>1 SERs of 5.78, 4.58, 18.96, and 3.13 FIT/Mb.

Data patterns: a checkerboard (CHB), b all zero (ALL0), c column stripe (CS), and d row stripe (RS)
2.4 N-P Reversed 6T Cell Layout
To scale CMOS transistors down to a 45-nm process or less, it is important to use compressive and tensile strain engineering for PMOS and NMOS, respectively, thereby increasing the drain current. Particularly, for a PMOS, embedded SiGe (eSiGe) in a source and drain boosts its saturation current (Isatp). The strain engineering is thereby more effective for PMOS (Isatp) than for NMOS (Isatn). Current enhancement using eSiGe strain for the PMOS increases more effective with the process scaling: +30% and +45% in 45-nm and 22-nm processes [123, 124]. Figure 3.20 shows the trend of the saturation current ratio of an NMOS to a PMOS (=Isatn/Isatp) along with a process node [125, 126]. The ratio approaches becomes unity when Isatp is comparable to Isatn at a 22-nm node. As previously described, the SEU cross section of the PMOS is 1/4 of that of the NMOS. Therefore, the conventional 6T cell suffers from the shortcomings of the soft-error vulnerability in the NMOS driver transistors. To cope with this NMOS problems and to leverage the PMOS benefit, we propose using PMOS access and driver transistors instead: an N-P (NMOS-PMOS) reversed structure. Soft-error tolerance is enhanced in the proposed N-P reversed 6T SRAM cell in future 22-nm node or advanced ones.

Trend in the n-to-p saturation current ratio, Isatn/Isatp, in 1999–2011
Figures 3.21a and 3.21b depict a schematic and a layout of the proposed NMOS-PMOS (N-P) reversed 6T SRAM cell, respectively. The 6T cell consists of NMOS load transistors (NL0 and NL1), PMOS driver transistors (PD0 and PD1), and PMOS access transistors (PA0 and PA1). The number of transistors and the poly-gate alignment are similar as the conventional one, although the N- and P-diffusions are swapped. The shared contacts are applicable to both 6T cells.

a Schematic, and b layout of the proposed N-P reversed 6T SRAM cell. Cell current (I cell) flows through PMOS load and NMOS access transistors in read operation
Therefore, the proposed cell has no area overhead over the conventional one. In a read operation, either bitline (BL or BLN in Fig. 3.21a) is pulled up by a cell current flowing through a PMOS access transistor. Generally, the read current of the proposed cell is degraded because Isatp is smaller than Isatn. However, as presented in Fig. 3.20, the saturation current ratio of Isatn to Isatp becomes smaller in the scaled process. Moreover, the random dopant fluctuation of the PMOS is less than that of the NMOS. Consequently, the cell current of the proposed cell will be larger than that of a conventional cell.
The device structure includes the cell property (width, height, and position of sensitive nodes), a cell-to-cell pitch in a cell array, and data patterns. The cell height, width, and position of the sensitive nodes are modeled as presented in Fig. 3.22. The ratio of the cell height to the cell width is set as 3.5. Each transistor width is doubled from the process node to suppress threshold voltage variation. The diffusion area is derived from the transistor width and the cell height. The clearances between diffusion edged are all equal. The parameters are presented in Table 3.6.

Models of SRAM cell width, height, and positions of sensitive nodes in 22-nm to 130-nm processes using parameters in Table 3.6
Figure 3.23a–d show neutron-induced soft-error simulation results obtained using CHB, ALL0, CS, and RS patterns. Although the critical charge is decreasing, the SBU SER is also decreasing with process scaling thanks to the smaller critical area. The MCU SER exhibits a similar tendency at the 65-nm and less nodes.

SBU and MCU SERs of conventional and proposed cells in the a CHB, b ALL0, c CS, and d RS patterns
The proposed N-P reversed cell has 50% smaller NMOS diffusion area in our definition. Therefore, its SBU and MCU SERs are reduced by 11–51% and 34–70%, respectively, at the 22-nm node. Particularly for the column stripe pattern, the MCU SER is improved by 70% (but the SBU SER is decreased by only 11%) because NMOS diffusions in the conventional cells share the same p-substrate in the vertical direction and vertical MCUs occur easily. However, in the row stripe pattern, the MCU SER improvement is the smallest, 34% (but the SBU SER improvement is the largest, 51%), because the distance from a sensitive NMOS node to another in the conventional cells is the longest among the four patterns.
3 Radiation-Hardened Flip-Flops
Kazutoshi Kobayashi, Kyoto Institute of Technology
Jun Furuta, Kyoto Institute of Technology
Radiation-hardened flip-flops (FFs) are used to mitigate unwanted flips by radiation strikes. Here we first deal with several redundant FFs and then move to non-redundant ones. Finally, we discuss device/process/circuit-level mitigation techniques for nano-scaled CMOS.
3.1 Approaches for Radiation-Hardened Flip-Flops
It is mandatory to prevent soft errors in storage circuits such as SRAMs, latches and flip-flops. Aggressive process scaling relieves soft errors rates per bit. But semiconductor chips are utilized in the fields demanding high reliabilities such as automotive, aerospace and medical devices. It is mandatory to reduce soft error rates as small as possible.
Redundant flip-flops mitigate soft errors to prepare extra circuit elements. Usually, three storage cells are prepared. It is possible to correct an error in a storage cell by majority voting. Since redundant flip-flops have large area, delay and power overhead, non-redundant flip-flops are used to reduce soft error rates by adding extra circuit elements with smaller penalties.
Device and process approaches are also effective to reduce soft error rates. Silicon-On-Insulator (SOI) is one promising candidate. Compared with conventional bulk technologies, SOI is strong against soft errors since Buried-Oxide (BOX) layers prevent charge collections.
Those mitigation techniques are introduced in this section.
3.2 Redundant-Structured Flip-Flops
3.2.1 Triple Modular Redundancy Flip-Flop
Triple Modular Redundancy Flip-Flop (TMR-FF ) mitigates soft errors by majority voting. Three storage elements are prepared. Even if one of them is flipped due to a radiation strike, it outputs the correct value by majority voting. Figure 3.24 depicts a typical TMR-FF which contains tripled latches and a majority voter. If one wishes to build a TMR-FF utilizing cells available out there, the majority voter can be constructed with combinations of conventional logic gates as shown in Fig. 3.25a, or using a PDK (Process Design Kit) that includes a special logic cell typically called MAJ as shown in Fig. 3.25b.

Triple-modular-redundancy flip-flop. Delay elements (τ) prevents to store incorrect data in three redundant latches from input

Majority voters implemented by logic gates (a) and MAJ logic cell (b)
TMR-FF is immune from Single Bit Upsets (SBUs) but can fail against Multi-Cell Upsets (MCUs). If two storage elements are flipped, it outputs an incorrect value. Due to the aggressive process scaling, the probability of MCUs is getting higher and higher [127]. It is caused by the fact that ranges of radiation particles are not scaled, while the sizes of storage elements are scaled. If a particle strikes a storage node, generated charge is shared with neighbors. Parasitic bipolar effects [128] also elevate well potential, which turn on parasitic bipolar transistors. To mitigate MCUs, layout-level techniques are effective.
Figure 3.26 shows an example which interleaves the storage elements in the TMR-FF that must not be flipped at the same time [129]. If two storage elements are flipped, it outputs an incorrect value. Due to the aggressive process scaling, the probability of MCUs is getting higher and higher [127]. It is caused by the fact that ranges of radiation particles are not scaled, while the sizes of storage elements are scaled. If a particle strikes a storage node, generated charge is shared with neighbors. Parasitic bipolar effects [128] also elevate well potential, which turn on parasitic bipolar transistors. To mitigate MCUs, layout-level techniques are effective.

Interleaving storage elements on the TMR-FF that must not be flipped at the same time. a w/o interleaving. b w/interleaving. SL0 and ML0 denote Master Latch 0 and Slave Latch 0 in Fig. 3.24
3.2.2 Dual-Interlocked Storage Cell (DICE) Flip-Flop
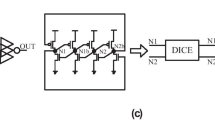
DICE stands for Dual-Interlocked storage cell. It is utilized in SoCs for High-Performance Computers (HPCs) [46, 130, 131].
The DICE structure as shown in Fig. 3.27a mitigates soft errors by duplicating latches implemented by the half C-elements and the clocked half C-elements as shown in Fig. 3.27b. The input and output signals of these half C-elements have cross-coupled connections to be automatically recovered from a flip on a single node. On the other hand, redundant FFs such as TMR, BISER [132] and BCDMR [133] mitigates soft errors by majority voting among three storage cells, in which a flipped node is left until the next clock signal is injected to supply an unflipped new value.

DICE FF schematic. DICE has four cross-coupled half C-elements. If a C-element is flipped, other three restore the original stored value
Compared with these majority-voter-based structures, the DICE structure is area-efficient since latches are not triplicated but duplicated.
3.2.3 Dual-Modulared-Redundancy Flip-Flop
Several dual-modulared-Redundancy (DMR) FFs are developed to achieve equivalent SEU tolerance to the TMR-FF. The DMR FFs explained here have two latches, a cross-coupled inverter called a keeper and C-elements. Compared with the TMR-FF with triplicated latches and voters, the DMR FFs has less area/power/delay penalties. Built-In Soft Error Resilience (BISER ) FF [132] is developed by Intel and Stanford Univ. It consists of dual-modulated latches, C-elements and weak keepers as shown in Fig. 3.28a. As shown in Fig. 3.28b, the C-element and the weak keeper keep the previous value even when one of duplicated latches is flipped. Therefore, BISER FF eliminates an unexpected flip caused by an SBU.

BISER schematic
Bistable Cross-Coupled Dual Modular Redundancy (BCDMR ) FF [133] is a modified version of the BISER FF with the functionality which was developed at Kyoto Univ. and Kyoto Inst. of Tech. It has duplicated C-elements with cross-coupled connection as shown in Fig. 3.29, which protects the slave latches from simultaneous flips caused by an SET in the C-element. In the BISER structure, duplicated slave latches are simultaneously flipped when a particle hits on the C-element and an SET pulse is transferred to the slave latches. The probability to capture the SET pulse is increased according to the clock frequencies. On the other hand, in the duplicated C-elements of the BCDMR structure, the SET pulse is only captured by one of the slave latches. Table 3.7 compares area, delay and power of BISER and BCDMR normalized by a conventional DFF. BCDMR FF has the same area with BISER. At 0.5 V, the delay of BISER FF becomes much slower than BCDMR.

BCDMR schematic
In neutron-accelerated tests, BCDMR FF showed over 100× more error resilience than non-redundant FF at clock frequencies up to 100 MHz thanks to the stability given by the cross-coupled dual C-elements [129], while BISER FF became more susceptible to SET at higher clock frequencies [129].
3.3 Non-redundant-Structured Flip-Flops
In this subsection, several non-redundant-structured FFs which pay less area/power/delay penalties but with less robustness against SEUs compared with redundant ones will be introduced.
3.3.1 Reinforcing Charge Collection Flip-Flop
The Reinforcing Charge Collection (RCC) FF [134] was proposed by Intel with dummy transistors to increase critical charge. Figure 3.30 shows an RCC latch schematic. There are two pairs of dummy CMOS transistors between n1 and n2. They are laid out to minimize victim-to-reinforcing diffusion separation as depicted in Fig. 3.31. The OFF device’s diffusion, referred as victim diffusion, collects charge that can flip the stored value. On the other hand, the ON devices diffusion, reffered as reinforcing diffusion, collects charge that can reinforce the stored value. In RCC, those diffusions are laid out besides the dummy gates DN1 and DN2.

RCC schematic

RCC layout for N diffusions
3.3.2 Hysteresis Flip-Flop
Hysteresis Flip-Flop (HY-FF) was developed by Broadcom and Vanderbilt Univ. It is a non-redundant FF with additional weak keepers that restricts unwanted flips by radiation strikes [135]. Figure 3.32 shows a schematic diagram of HY-FF. It is non-redundant but its area penalty is relatively large. It is reported in [136] that its radiation hardness is 5× compared with a non-redundant FF and the area of the pulsed hysteresis latch is 108% of a non-redundant FF.

Hysteresis Flip-Flop schematic
3.4 Device/Process/Circuit-Level Mitigation Techniques for Nano-Scaled CMOS
For nano-scaled CMOS technologies, MCUs, or multiple upsets of signal nodes in close vicinity caused by a single strike of energetic particles, have become more and more pronounced since ranges of radiation particles such as neutrons or alpha particles are not scaled while signal nodes are becoming closer to each other. MCUs may cancel out mitigation effect by redundancy; If two storage elements out of the two among the three in TMR are flipped, it becomes a fault. In nano-scaled CMOS down to 45 or 28 nm, device or process level mitigation techniques are therefore getting increasing attention. Fully Depleted Silicon-On-Insulator (FD-SOI) is one of promising candidates to supplant conventional bulk technologies to cope with. We introduce two FD-SOI processes which have thin BOX (Buried OXide) layers named 65-nm Silicon On Thin BOX (SOTB) and 28-nm Ultra-Thin Body and BOX (UTBB). We also introduce a non-redundant mitigation technique adequate for an anti-soft-error process such as FD-SOI.
3.4.1 Thin BOX FD-SOI Technologies
FD-SOI suppresses the short-channel effect (SCE) and process variations. Two semiconductor companies in Japan and in France are developing similar FD-SOI technologies with thin BOX layers. Sugii et al. from LEAP (Low-Power Electronics Association & Project), an industry consortium in Japan, have developed a 65 nm Thin BOX FD-SOI technology called SOTB [137, 138].
Figure 3.33 shows a cross section of an SOTB transistor. The thickness of the BOX layer is only 10 nm thick so it is possible to control the threshold voltages through backgate biases. Kamohara et al. developed an SoC integrating a 32 bit microprocessor and SRAMs for Internet of Things (IoTs) [139]. ST Microelectronics is also developing another 28 nm Thin BOX FD-SOI technology named UTBB [140]. The thickness of the BOX layers is 25 nm, which is 2.5× thicker than SOTB’s, and has less controllability of threshold voltages than SOTB. Jaquet et al. have implemented a dual-core ARM A9 processor with 2.66 GHz enabled by forward body biases in the UTBB process [141].

Cross section of a Silicon on Thin BOX Transistor
FD-SOI technologies have a distinct advantage in soft error immunity, because the bulk Si substrate is separated from the active SOI (Silicon-On-Insulator) regions. Charges generated in the substrate do not penetrate the BOX oxide. SOI The results obtained by the author’s group in spallation neutron irradiation experiment have shown that a conventional TGFF (Transmission Gate FF) on SOTB has the 16× lower SER than a similar TGFF built-in bulk Si [142]. In addition to that, it has been found out that redundant FFs such as DICE, BCDMR and TMR built-in SOTB have no errors during the neutron irradiation [142].
3.4.2 Mitigation Technique Without Redundancy
In the low-SER technologies such as FD-SOIs, non-redundant circuits are enough to suppress SERs. Thus, redundant circuits may not be required. In such technologies, slight difference in critical charge (Qcrit) makes a lot of difference in threshold energy of particles as qualitatively shown in Fig. 3.34. Thus, layout or circuit-level techniques to increase Qcrit without redundancy are good candidates. Figure 3.35 is a non-redundant FF called Tristate-Inverter FF (TIFF) that replaces the transmission gate between master and slave latches on TGFF with a tristate inverter. The area of TIFF is only 5% larger than a Transfer-Gate FF (TGFF), but the critical charge of TIFF is larger than that of TGFF. TIFF has better SERs than TGFF. We fabricated a test chip by 65 nm bulk and FD-SOI processes. Table 3.8 shows the error probabilities by alpha irradiation of TIFF and TGFF. In bulk, the error probabilities are almost equivalent, while in FD-SOI the probability of TIFF is 0.6× of that of TGFF.

Relationship between particle energy and Critical charge

Tristate-Inverter FF
4 Soft-Error-Tolerant Reconfigurable Architecture
Yukio Mitsuyama, Kochi University of Technology
Masanori Hashimoto, Osaka University
Takao Onoye, Osaka University
Hiroyuki Kanbara, Advanced Science, Technology & Management Research Institute of KYOTO
Hiroyuki Ochi, Ritsumeikan University
Kazutoshi Wakabayashi, NEC
Hidetoshi Onodera, Kyoto University
4.1 Soft Errors on Reconfigurable Architecture
Recently, the reliability of reconfigurable devices is drawing attentions, since implementing mission-critical applications with high reliability on reconfigurable devices is highly demanded for saving NRE (Non-Recurring Engineering ) costs. Especially, soft errors are one of serious concerns threatening reliability of mission-critical applications. In reconfigurable devices, the reliability of the configuration memory is often considered to be more critical than that of the computed data in data/pipeline registers, since an SEU in the configuration memory damages the functionality until the configuration data is reloaded again; we will refer to this as a permanent error. In the majority of terrestrial applications, on the other hand, requirements for radiation hardness may not be as stringent as in space applications but can vary to such an extent that a single processor architecture would be hard to accommodate.
Coarse-grained reconfigurable architecture s (CGRA) have been studied to fill the performance gap between FPGA and ASIC by reasonably limiting application domains and programmability. From reliability point of view, CGRA is inherently superior in soft error immunity to FPGA, since the amount of configuration bits is by orders of magnitude smaller than that of FPGA. Several groups have so far reported on CGRAs with reliability consideration [143,144,145].
Thus far, while CGRAs have been extensively discussed (e.g., [146,147,148]), their adoption for commercial use has been limited compared to FPGAs. FPGAs have dominated wide areas of applications that are rather popular despite of their large power dissipation and chip area for two major reasons. For one thing, CGRA is basically composed of an array of ALUs (Arithmetic Logical Units) handling multi-bit operands, and is therefore suitable for data-path implementation but not for efficiently implementing one-bit operations that are often used in flag computation, conditional branching and state machines. RTL (Register Transfer Level ) designers and existing behavioral synthesis tools for ASIC and FPGA commonly synthesize data-path circuits that are controlled by state machines. The incompatibility with state machine implementation is, therefore, a significant problem that has prevented CGRA from being widely used. Another reason is that no CGRAs have been provided so far with the full benefit of IP reuse or the standard ANSI C/C++ source codes available for designs. To overcome this issue, several CGRA architectures compatible with state machine implementation have been proposed [149,150,151]. To expand the application domains of CGRAs, an architecture having high compatibility with design automation tools and high flexibility that allows trade-offs between reliability, performance and cost has been highly demanded.
4.2 Proposed Reconfigurable Architecture
4.2.1 Design Concept
The concept of our reconfigurable architecture, which we call Flexible Reliability Reconfigurable Array (FRRA), is based on the above-mentioned recognition of the requirements for flexible reliability in architecture design and compatibility with behavioral synthesis .
-
(1)
Flexible reliability in architecture design
Reliability requirements depend on the application and operating environment, and hence, there is a growing demand for design scheme that would allow flexible choice of countermeasures to prevent reliability degradation. A reconfigurable device is suitable for a spatial redundancy based soft-error-tolerant design , which is applied in mission-critical applications with area costs. In order to achieve the desired level of reliability in a reconfigurable device, it is useful to be able to subject all its basic elements to trade-off between the sensitivity to soft errors and the chip area.
According to the reliability classifications against soft errors, each basic element of our reconfigurable architecture supports several operation modes. When an application is implemented on our reconfigurable device, the operation modes of each basic element are defined by our design tools, which can consider the trade-off between soft-error resilience and hardware cost.
-
(2)
Compatibility with behavioral synthesis
Compatibility with behavioral synthesis requires architectural supports that help provide a trade-off between latency and resource usage (area). Figure 3.36 demonstrates how a C program can be implemented in one cycle and in two cycles. Our architecture supports not only one-cycle implementation of Fig. 3.36a but also multi-cycle implementation. In the two-cycle implementation of Fig. 3.36b, one coarse-grained processing element including two multiplexers and a register, and fine-grained elements for implementing a state machine are necessary. Dynamic reconfiguration of the processing element is controlled by the state machine, which has two states, S0 and S1. In order to show a simple example of two types of implementations, Fig. 3.36 uses a small C program, and may not have been able to show an obvious trade-off between latency and area. In case of a practical C program, a large trade-off could be obtained. Such a trade-off between latency and area obtained by various implementations enables various types of desirable specifications.

Examples of implementations with different latency
In order to achieve this trade-off, the following elements are required: fine-grained elements to implement state machines, coarse-grained elements to perform various types of data processing with dynamic reconfiguration depending on the state signal, register files to save temporal data, and large memories to store large bulk data. Here, although an embedded CPU could be used to control the state of coarse-grained elements, we took the option of using the fine-grained elements built in the chip for pursuing low-latency state control. With these elements, behavioral synthesis allows designers to explore the solution space and select an implementation that satisfies the requirements of the design.
4.2.2 Architecture Design Overview
The proposed architecture is composed of coarse-grained elements as ALU clusters, fine-grained elements as LUT (Look-Up Table ) clusters, register blocks called as REG clusters, and memory blocks called as MEM clusters, where the basic element is noted as cluster. Figure 3.37 shows an example of cluster array, in which an LUT block is composed of a number of LUT clusters. When an application is mapped on the proposed architecture, data-paths are assigned to ALU clusters. Meanwhile, state machines and one-bit operations are assigned to LUT clusters. The temporal intermediate data across the different states could be stored in REG clusters.

Example of heterogeneous cluster array based on the proposed architecture
The proposed reconfigurable array architecture has two global signals: context signal and state signal. Both of these global signals are generated by designated LUT clusters. The inter-cluster connections are changed according to the context signal, which switches the mapped application or algorithm. An ALU cluster changes its functionality and data-path/flag operands according to the broadcast state signals, while the inter-cluster interconnection is unchanged. All the inter-cluster routings to provide data to clusters are fixed for all the states, and each ALU cluster selects a few data as operands, depending on the state, from all the data delivered to the ALU cluster. Also, a REG cluster selects input data and changes write address depending on the state signal, since the store of intermediate data depends on the state. On the other hand, the functionalities of LUT and MEM clusters are unchanged by the state signal.
ALU, LUT and REG clusters all have an inner structure with three cells as illustrated in Fig. 3.38, while the execution modules (EM) in the cells are specific to each of them. The EMs for ALU, LUT and REG clusters are ALU, LUT and register file, respectively. On the other hand, an MEM cluster includes a single SRAM macro, and hence the structure inside the cluster is different. Several LUT clusters are organized in a two-dimensional array forming a LUT block. ALU, REG, and MEM clusters and LUT blocks are placed in a two-dimensional array. The details of each cluster are explained in Sect. 3.4.2.3.

The inner structure of ALU, LUT and REG clusters. Cluster-to-cluster interconnection is shown as well
4.2.3 Details of Reconfigurable Architecture
As shown in Fig. 3.38, an ALU cluster consists of a reconfigurable cell unit for processing various types of operations, a redundancy control unit (RDU) for flexible reliability, a comparing and voting unit, switches and wires. An RCU is composed of a configuration memory switching matrix (ConfSM) and three cells, each of which contains an execution module (EM), register files for storing configuration bits, and voters. In EM, arithmetic operations including multiplication, logic operation, and shift operation are performed.
The cluster interconnection has three tracks (Track 0–2), and each cell inside a cluster is placed on one of them. Thus, each cell in a cluster can be connected to the cells in adjacent clusters on the same track. The interconnection also has a diagonal track, connecting cells within one cluster. Switches to control these interconnections are implemented by multiplexers.
The cell architecture of ALU cluster is illustrated in Fig. 3.39. In order to implement dynamic reconfiguration with a small area overhead, configuration bits are divided and stored in three types of register files: instruction register file (InstRF), interconnection register file (InterRF), and constants register file (ConstRF). As mentioned earlier, instructions for ALU are locally stored in the cluster, where an instruction for ALU represents a set of ALU configuration bits for a single state. On the other hand, the configuration bits for inter-cluster connection stored in InterRF are fixed for all the states in each context. In this paper, InterRF is implemented so that it can store three contexts. ConstRF is used to store up to four constants that are required in the application, and one of the four constants is selected by the 2-bit signal from InstRF. This implementation has been selected for area reduction because not all instructions need constants in most applications.

Architecture of cell in ALU cluster
In this architecture, as pointed out earlier, an InstRF consisting of a larger number of words can accommodate a larger state machine, which enables trade-offs between the area and latency. However, as the number of ALU instructions stored in InstRF becomes larger, the silicon area of ALU cluster increases, and the area overhead originating from the unused words of InstRF tends to be significant. The detail of this trade-off is described in [152].
To attain soft error immunity, InterRF and ConstRF are protected with an error correction code (ECC). The selected code is single error correction/double error detection (SEC/DED) Hamming code. For every read of InterRF and ConstRF, the error corrected bits are regularly restored in InterRF and ConstRF to prevent error accumulation. In addition, three contexts of InterRF and four constants of ConstRF are restored by re-writing the data itself through another SEC/DED encoder/decoder in rotation. On the other hand, three InstRFs is implemented with bitwise triple modular redundancy, since the path from the state signal to the register file output includes only a voter and its delay is small. This small delay is important, since this delay is necessarily included in the critical path. Three InstRFs can also be used as three contexts of configuration memory for dynamic reconfiguration without any soft error immunity. This is the reason why ECC, which would require an ECC decoder having large delays, was not selected for InstRF.
As summarized in Table 3.9, ALU cluster supports three operation modes: triple modular redundancy (TMR), single modular with single context (SMS), and single modular with multi-context (SMM). These operation modes also offer different capabilities of dynamic reconfigurability (number of contexts) and throughput per cluster.
TMR, in which both InstRF in a cell and data-paths in three cells are triplicated as shown in Figs. 3.38 and 3.39, provides the highest soft-error immunity. Meanwhile, in SMS, only InstRF is triplicated but the data-path is singular. In both TMR and SMS, an SEU occurring in the InstRF will be repaired when the next configuration clock is given, since the voted value is rewritten to the register file in every configuration clock cycle. Here, the configuration clock signal is given to the InstRF separately from the system clock. This configuration data is stored with bitwise TMR, and therefore, multiple SEUs in different bits will also be corrected when the next configuration clock is given. On the other hand, in SMM, the voters are disabled, and three contexts are stored independently using three InstRFs, each of which is included in individual cells. With this implementation, users can flexibly choose the operation modes, depending on the importance of SEUs in InstRF and SEU/SET in EM.
The detailed architecture of LUT, REG, and MEM clusters are described in [152]. REG, LUT, and MEM clusters support reliable and regular modes. In each operation mode, register files for storing configuration bits and EMs, which are LUT, register file, and SRAM macro in LUT, REG, and MEM cluster respectively, can be adopted individual reliability level. In order to achieve different levels of reliability to soft-errors, each operation modes of each cluster are defined by our design tools [153, 154], which can consider the trade-off between soft error resilience and hardware cost. The overview of our design tools is presented in Sect. 3.4.3.
4.3 Design Tools for Our Reconfigurable Architecture
4.3.1 Reliability Programming by Selective TMR
A study on SEU mitigation for FPGAs revealed that there are configuration bits that should be protected with higher priority and proposed to adopt costly TMR selectively [155]. Similarly, it is expected that selective TMR is also effective to CGRAs, and thus we developed an architecture that has capability of applying either TMR or non-TMR modes for each cluster as explained in Sect. 3.4.2.
In order to implement a given circuit to the proposed architecture with highest possible reliability under limited reconfigurable fabric, it is important to find vulnerable operations that should be triplicated with higher priority without time-consuming fault simulation. For this purpose, we developed a method to determine the priority to be triplicated [153, 154].
In the method, we assume that vulnerability, v, of an operation in a given DFG (Data Flow Graph) is modeled by a linear equation v = w · a, where a is a vector of feature values of the operation (e.g., type of operation, distance to primary output), and w is a weight vector, in which each element corresponds to the element in the vector a. By analyzing some sample circuits in an application domain, we obtained examples of a vectors and corresponding v values, and from these a-v pairs, we found w that approximates model equation v = w · a using a generalized inverse matrix [153] or simulated annealing method [154]. Once w is found, we can obtain the priority for triplication of operations in a given DFG since we can estimate v of each operation.
Figure 3.40 shows the area-vulnerability trade-off of implementations of a 1024-point FFT [154]. The horizontal axis represents normalized circuit area, in other words, hardware cost. The entire TMR and non-TMR correspond to 3.0 and 1.0 respectively, and a partial TMR in between. The vertical axis represents mean absolute error (MAE) at the output data-stream induced by soft-errors. The definition of MAE is given by

Area-vulnerability trade-off of application implementations
where N is the number of words in the output data, xi and \( \tilde{x}_{i} \) are the i-th word of actual output and error-free output, respectively. The “Best” and “Worst” plots show the entire design space obtained by exhaustive search and fault simulation, and the “Estimated” plots show the obtained implementation using our method. When the all clusters adopt TMR mode, the amount of mean absolute errors should be zero. According to the obtained priority, a small portion of triplication effectively reduces the vulnerability.
4.3.2 Reliability-Oriented C-Based Design Flow
Figure 3.41 shows the reliability-oriented C-based design flow for the dependable VLSI platform, which consists of the reliable processor [156] and the reliable reconfigurable array. An application can be written in ANSI-C language. After partitioning the whole operation to the processor and the reconfigurable array, the C source code for the reconfigurable array is translated to an RTL description. This behavioral synthesis is performed by Cyber Work Bench [157, 158] whose algorithm is optimized for our CGRA. The RTL description is then mapped and place-and-routed on the reconfigurable array.

Reliability-oriented C-based design flow
4.4 Test Chip Implementation
A proof-of-concept array based on the proposed reconfigurable architecture was fabricated in 65 nm 12ML CMOS process. The die size is 4.2 × 4.2 mm. Figure 3.42 shows a layout of the test chip, which has 26 ALU clusters, 6 MEM clusters and 4 LUT blocks. REG clusters have not been included in the test chip because of a constraint of chip area. ALU, LUT and MEM clusters include 120 k, 4 k, and 99 k gates, respectively. Here, REG clusters are not included in the test chip since our preliminary evaluation before the test chip implementation shows that small image processing applications that can be implemented on the test chip demand more ALU clusters instead of REG clusters.

Chip layout of designed reconfigurable array
Thanks to dynamic reconfiguration using states generated by an FSM, area-efficient mapping becomes possible. Here, in this implementation, the number of instructions for ALU was set to 16 due to the limited silicon area, while a work done by our colleagues suggested that the number of instructions of more than 24 is desirable [152]. Nevertheless, it has been shown that, for example, an edge detection filter can be implemented with 25 ALU clusters only, while 62 ALU clusters would be necessary if it were not for dynamic reconfiguration (i.e., in a single state). The number of clusters is reduced by 60% in this particular example. Thus, the proposed architecture implemented on the test chip has demonstrated the possibility of exploiting latency-area exploration using the behavioral synthesis.
Figure 3.43 illustrates the mapping of an application on our reconfigurable array. With the help of the C-based design flow taking into account reliability specifications, it has been demonstrated that the use of the proposed mixed-grained reconfigurable array enable to manage both the trade-off between soft-error resiliency and hardware cost, and the trade-off between latency and hardware resource usage.

Application implementation flow on the mixed-grained reconfigurable array
4.5 Demonstration of a Video Application
In order to validate the functionality and reliability of the architecture, a demonstration using two mappings of SMM and SMS was performed on the evaluation board shown in Fig. 3.44. The chip receives a live data stream from a video camera, and sends it to a monitor demonstrating the processed stream. The mapping of black and white reversal filter was generated from a C source code. Here, the black and white reversal filter is a filter that performs tone reversal, and a subtraction is performed for each pixel.

Demonstration setup
A snapshot of the results is shown in Fig. 3.45. After positioning an Am-241 alpha foil whose flux [7] is 9 × 109 cm2 h−1 over the chip, it was observed that SMS mapping continued to output the processed video as expected. On the other hand, SMM mapping got destroyed in 2 s due to SEUs in configuration registers, and then video processing stopped within 10 s in all four trials. We also tested TMR mapping and confirmed the expected continuous functionality. The proposed architecture thus enables reliable operation, which includes application mapping, under harsh irradiation.

Results of image processing under irradiation
4.6 Directions of Future Work
In the present work, we developed a mixed-grained reconfigurable architecture, which consists of fine-grained and coarse-grained fabrics, each of which can be configured for different levels of reliability depending on the reliability requirement of target applications, e.g., mission-critical applications to consumer products. Thanks to the fine-grained fabrics, the architecture can accommodate implementing a state machine, which is indispensable for exploiting C-based behavioral synthesis to trade latency with resource usage through multi-step processing using dynamic reconfiguration. The demonstration of a video application using a proof-of-concept VLSI chip, which is fabricated in 65 nm process, will answer a broad range of reliability requirements from terrestrial to space applications with varied resilience against radiation-induced soft errors.
Further extension of this work is under way in a few important directions. One is to further advance the basic concepts borne in the present work of reconfigurable architecture to better accommodate real-world trade-offs among performance, reliability, and cost. Another is to demonstrate the feasibility of this architecture at the levels of integration required for practical applications.
5 Simulation and Design Techniques for Computer Systems
Makoto Sugihara, Kyusyu University
5.1 Simulation Technique
A single event upset (SEU) is a change of state, which is caused by a high-energy particle strike to a sensitive node in semiconductor memory devices. An SEU in an integrated circuit (IC) component often causes a faulty behavior of a computer system. A soft error rate (SER) of a memory device is the rate at which the memory device encounters or is predicted to encounter SEUs during a unit time. The SER is often utilized as a metric for vulnerability of an IC component. The SER for a memory module is a vulnerability baseline rather than one reflecting its actual and accurate behavior. SERs of memory modules become over-pessimistic when the modules are embedded into computer systems and the system vulnerability is estimated as the simple sum of all memory SERs in the system. More specifically, every SEU occurring in memory modules is regarded as a critical error when memory modules are under field or accelerated tests. This implicitly assumes that every SEU on memory cells of a memory module always make a computer system faulty. Since memory modules are used spatially and temporarily in computer systems, only some of SEUs on the memory modules make the computer system faulty and others not. Therefore, the soft errors in an entire computer system should be estimated in a different way from the simple summation of memory SERs in the system.
Accurate vulnerability estimation of an entire computer system is essential for building reliable computer systems. This subsection summarizes a simulation-based vulnerability estimation approach for a computer system, which has several memory hierarchies in order that one can accurately estimate the reliability of the computer system within reasonable computation time [159, 160]. We define a critical SEU as one which may cause faulty behavior of a computer system. We also define an SEU vulnerability factor for a job running on a computer system as the expected number of critical SEUs which occur during the job, unlike a classical vulnerability factor. The architectural-level soft-error model identifies the part of memory modules that are utilized temporarily and spatially, and SEUs which are critical to the program execution at cycle-accurate ISS (instruction set simulation) level in the computer system. Our architectural-level soft-error model is capable of estimating the reliability of a computer system that has several memory hierarchies and finding which memory module is vulnerable in the computer system. Reliability estimation helps one apply reliable design techniques to vulnerable part of their design.
Unlike memory components, the rate at which a computer system encounters SEU-induced errors varies every moment because the computer system uses memory modules spatially and temporarily. Since only active part of the memory modules affects reliability of the computer system, it is essential to identify the active part of memory modules for accurately estimating the number of soft errors occurring in the computer system. A universal soft error metric other than an SER is necessary to estimate reliability of computer systems because an SER is a reliability metric suitable for components of regular and monotonous structure like memory modules but not for computer systems. In this subsection, the number of soft errors which occur during execution of a program is utilized as a soft error metric for computer systems. In computer systems, a word is a basic element for computation in CPUs. A word is an instruction in an instruction memory while that is a data in a data memory. A collection of words is required to be processed in order to run a program. We consider the reliability to process all words as the reliability of a computer system. The total number of SEUs which are expected to occur on all the words is regarded as the number of SEUs of the computer system. This subsection discusses an estimation model for the number of soft errors on a word. A CPU-centric computer system typically has the hierarchical structure of memory modules, which includes a register file, cache memory modules, and main memory modules. The computer system at which we target has levels of memory modules, in order of accessibility from/to the CPU. In the hierarchical memory system, instructions are generally processed as follows.
-
Instructions are generated by a compiler and loaded into a main memory.
The birth time of an instruction is the time for the instruction to be loaded into the main memory, from the viewpoint of program execution.
-
When the CPU requires an instruction, it fetches the instruction from the memory module closest to it. The instruction is duplicated into all levels of memory modules which reside between the CPU and the source memory module.
Note that instructions are basically read-only. Duplication of instructions is uni-directionally made from a low level to a high level of a memory module.
Data items in data memory are processed as follows.
-
Some data are given as initial values of a program when the program is generated with a compiler. The birth time of such a data is the time for the program to be loaded into a main memory. The other data are generated during execution of the program by the CPU. The birth time of the data which is made online is the time for the data item to be made and saved to the register file.
-
When a data is requested by a CPU, the CPU fetches it from the memory module closest to the CPU. If the write allocate policy is adopted, the data is duplicated at all levels of memory modules which reside between the CPU and the master memory module, and otherwise it is not duplicated at the inter-adjacent memory modules.
Note that data are writable as well as readable. This means that data can be copied from a high level to a low level of a memory module, and vice versa.
In CPU-centric computer systems, data are utilized as constituent elements. The data vary in lifetime and the numbers of soft errors on the data vary from data to data.
Let us consider critical SEUs in a computer system whose memory hierarchy is shown in Fig. 3.46. The memory hierarchy of the computer system consists of a register file, an L1 cache, an L2 cache, and a main memory.

Memory hierarchy example
Figure 3.47 shows an example of critical SEUs in instruction memory.

Periods for critical SEUs in instruction memory
In this example, we ideally assume that an instruction is instantaneously transmitted between memory hierarchy levels. A rectangle indicates a period during which its corresponding memory hierarchy level stores a copy of the word. In the example, there are three fetch requests for the instruction which resides at a certain address. On the first instruction fetch, the target word item resides only in the main memory. It is assumed that a word is directly brought from the main memory to the register file while copies are made in the register file, L1 and L2 caches. SEUs which occur during the periods indicated by the red rectangles are regarded as critical with regard to the first instruction fetch. The same for the second instruction fetch. SEUs which occur during the periods indicated by the purple rectangles are regarded as critical. On the third instruction fetch, the target word resides at the L1 cache. SEUs which occur during the periods indicated by the pink rectangles are regarded as critical. The periods indicated by the white rectangles are finally found to be non-critical.
Figure 3.48 shows an example of critical SEUs in data memory on the assumption of the write-through policy. In this example, we ideally assume that a data is instantaneously transmitted between memory hierarchy levels. A rectangle indicates a period during which its corresponding memory hierarchy level stores the data. Initially, a word is stored in the register file. Then the first store writes the word through. A load instruction follows. On the load instruction, the highest memory hierarchy which has a copy of the target word is the L1 cache and a copy is made from the L1 cache to the register file. Then the CPU uses the copy of the word. The register read makes SEUs which occur during the periods indicated the red rectangles critical. Then another register write, the second store, an L1 overwrite, a load instruction and register read follow. On the second load instruction, the highest memory hierarchy which has a copy of the target word is the L2 cache and a copy is made from the L2 cache to the register file. Then the CPU uses the copy of the word. The second register read makes SEUs which occur during the periods indicated the purple rectangles critical. The periods indicated by the white rectangle are finally found to be non-critical.

Periods for critical SEUs in write-through data memory
Counting the periods for critical SEUs in instruction set simulation calculates the number of fault bits which are inputted to the CPU, that is an SEU vulnerability factor.
5.2 Design Techniques
Design for reliability (DFR) is one of the themes of urgent concern. Based on the simulation-based vulnerability estimation technique [142, 143], several DFR techniques were proposed.
In [144, 145], a reliable cache architecture was presented which offered performance and reliability modes. More cache memory is used in the performance mode while less cache memory is used in the reliability mode to avoid SEUs. Task scheduling approach was also presented in [161, 162]. All tasks are statistically scheduled under real-time and reliability constraints. The demerit of the approach is that switching operation modes causes performance and area overheads and might be unacceptable to high-performance or general-purpose microprocessors.
In [163, 164], a task scheduling approach was presented which minimized SEU vulnerability of a heterogeneous multiprocessor under real-time constraints. Architectural heterogeneity among CPU cores offers a variety of reliability for a task. A task scheduling problem was presented which minimized SEU vulnerability of an entire system under a real-time constraint. The demerit of the approach is that the fixed heterogeneous architecture loses general-purpose programmability.
In [165, 166], a heterogeneous multiprocessor synthesis approach was presented which minimizes chip area under SEU vulnerability and execution time constraints.
To the best of our knowledge, this is the first study to synthesize a heterogeneous multiprocessor system with a soft error issue taken into account. In this section we use the SEU vulnerability factor as a vulnerability factor. The other vulnerability factors, however, are applicable to our system synthesis methodology as far as they are capable to estimating task-wise vulnerability on a processor. If a single event transient (SET) is a dominant factor to fail a system, a vulnerability factor which can treat SETs should be used in our heterogeneous multiprocessor synthesis methodology. Our methodology assumes that a set of tasks are given and that several variants of processors are given as building blocks. It also assumes that real-time and vulnerability constraints are given by system designers. Simulation with every combination of a processor model and a task characterizes performance and reliability. Our system synthesis methodology uses the values of the chip area of every building block, the characterized runtime and vulnerability, and the given real-time and vulnerability constraints in order to synthesize a heterogeneous multiprocessor system whose chip area is minimal under the constraints.
References
E. Ibe, Terrestrial Radiation Effects in ULSI Devices and Electronic Systems (IEEE Press and Wiley, 2015)
E. Ibe, H. Taniguchi, Y. Yahagi, K. Shimbo, T. Toba, Impact of scaling on neutron-induced soft error in SRAMs from a 250 nm to a 22 nm design rule. Trans. Electron Devices 57(7), 1527–1538 (2010)
N. Kanekawa, E. Ibe, T. Suga, Y. Uematsu, Dependability in Electronic Systems-Mitigation of Hardware Failures, Soft Errors, and Electro-Magnetic Disturbances (Springer, New York, 2010)
S. Kuboyama, K. Sugimoto, S. Shugyo, S. Matsuda, T. Hirao, Single-event burnout of epitaxial bipolar transistors. Trans. Nucl. Sci. 45(6), 2527–2533 (1998)
http://helios.izmiran.rssi.ru/cosray/main.htm#top. Accessed 14 Feb 2013
T. Nakamura, M. Baba, E. Ibe, Y. Yahagi, H. Kameyama, Terrestrial Neutron-Induced Soft-Errors in Advanced Memory Devices (World Scientific, New Jersey, 2008)
JEDEC, Measurement and reporting of alpha particle and terrestrial COSMIC ray induced soft errors in semiconductor devices. in JEDEC Standard JESD89A, pp. 1–93 (2006)
T. Inoue, H. Henmi, Y. Yoshikawa, H. Ichihara, High-level synthesis for multi-cycle transient fault tolerant data paths. in 17th IEEE International On-line Testing Symposium, vol. 1.3, Athens, Greece, 13–15 July 2011, pp. 13–18
https://repository.exst.jaxa.jp/dspace/bitstream/a-is/19254/1/61889032.pdf
C.S. Walker, Capacitance, Inductance and Crosstalk Analysis (Artech House Antennas and Propagation Library, Altech House Publisher)
http://www.bostonscientific.com/lifebeat-online/electromagnetic-interference.html
K. Ishibashi, K. Osada (eds.), Low Power and Reliable SRAM Memory Cell and Array Design (Springer, 2011)
G. Cellere, A. Paccagnella, A. Visconti, M. Bonanomi, S. Beltrami, Single event effects in NAND flash memory arrays. IEEE Trans. Nucl. Sci. 53(4), 1813–1818 (2006)
M. Nicolaidis (ed.), Soft Errors in Modern Electronic Systems (Springer, 2011) pp. 1–239
S. Sayil, N.B. Patel, Soft error and soft delay mitigation using dynamic threshold technique. IEEE Trans. Nucl. Sci. 57(6), 3553–3559 (2010)
D.M. Fleetwood, R.D. Schrimpf (eds.), Radiation effects and soft errors in integrated circuits and electronic devices World Sci. 1–324 (2004)
C. Slayman, M. Ma, S. Lindley, Impact of error correction code and dynamic memory reconfiguration on high-reliability/low-cost server memory. in IEEE International Integrated Reliability Workshop Final Report, pp. 190–193 (2006)
P. Andrei, S. Manoj (eds.), CMOS SRAM Circuit Design and Parametric Test in Nano-Scaled Technologies (Springer, 2008) pp. 1–192
http://www.csl.cornell.edu/courses/ece5745/handouts/ece5745-T02-cmos-devices.pdf
B. Nikolić1, M. Blagojević, O. Thomas, P. Flatresse, A. Vladimirescu, Circuit design in nanoscale FDSOI technologies. in Proceedings of 29th International Conference on Microelectronics (MIEL 2014), Belgrade, Servia 12–14 May 2014, pp. 3–6
O. Kononchuk, B.-Y. Nguyen (eds.), Silicon-On-Insulator (SOI) Technology: Manufacture and Applications (Elsevier, 2014)
N. Sugii, R. Tsuchiya, T. Ishigaki, Y. Morita, H. Yoshimoto, K. Torii, S. Kimura, Comprehensive study on Vth variability in silicon on thin BOX (SOTB) CMOS with small random-dopant fluctuation: finding a way to further reduce variation, in IEEE International Devices Meeting, San Francisco, 15–17 Dec 2008, pp. 249–253
T.C. May, M.H. Woods, Alpha-Particle-induced soft errors in dynamic memories. IEEE Trans. Elect. Device ED-26(1), 2–9
C. Hu, Alpha-particle-induced field and enhanced collection of carriers. IEEE Elect. Device Lett. EDL-3(2), 31–34 (1982)
https://www.jedec.org/standards-documents/dictionary/terms/single-event-functional-interrupt-sefi
J. Barak, E. Adler, B. Fischer, M. Schlogl, S. Metzger, Micro-beam mapping of single event Latchups and single event upsets in CMOS SRAMs. IEEE Trans. Nucl. Sci. Seattle 45(3), 1595–1602 (1998)
H. Asai, K. Sugimoto, I. Nashiyama, Y. Iide, K. Shiba, M. Matsuda, Y. Miyazaki, Terrestrial neutron-induced single-event burnout in SiC power diodes, in The Conference on Radiation Effects on Components and Systems, vol. (PC-3), Sevilla, Spain, 19–23 Sept. 2011
T. Shoji, S. Nishida, T. Ohnishi, T. Fujikawa, N. Nose, M. Ishiko, K. Hamada, Neutron induced single-event burnout of IGBT, in The 2010 International Power Electronics Conference, Sapporo, Hokkaido, 21–24 June 2010, pp. 142–148
S. Nishida, T. Shoji, T. Ohnishi, T. Fujikawa, N. Nose, M. Ishiko, K. Hamada, Cosmic ray ruggedness of IGBTs for hybrid vehicles, in The 22nd International Symposium on Power Semiconductor Devices & ICs, Hiroshima, 6–10 June 2010, pp. 129–132
ITRS Report 2010. http://www.itrs.net/
N. Seifert, B. Gill, M. Zhang, V. Zia, V. Ambrose, On the scalability of redundancy based SER mitigation schemes, in International Conference on IC Design and Technology, Austin, Texas 18–20 May, vol. G2, pp. 197–205
E. Ibe, S. Chung, S. Wen, H. Yamaguchi, Y. Yahagi, H. Kameyama, S. Yamamoto, T. Akioka, Spreading diversity in multi-cell neutron-induced upsets with device scaling, in The 2006 IEEE Custom Integrated Circuits Conference, San Jose, CA, 10–13 Sept 2006, pp. 437–444
J.F. Ziegler, W.A. Lanford, Effect of cosmic rays on computer memories. Science 206, 776–788 (1979)
M. Gutsche, et al., Capacitance enhancement techniques for sub-100 nm trench DRAMs, in International Electron Device Meeting, Washington, DC, 3–6 Dec 2001, pp. 18.6.1–18.6.4
K. Takeuchi, K. Shimohigashi, E. Takeda, E. Yamasaki, Experimental characterization of α-induced charge collection mechanism for megabit DRAM cells, in IEEE International Solid-State Circuits Conference, N.Y., 10 Feb 1987, pp. 99–100
G.A. Sai-Halasz, M.R. Wordeman, R.H. Dennard, Alpha-particle-induced soft error rate in VLSI circuits. IEEE Trans. Elect. Devices ED-29(4), 725–731 (1982)
C.E. Thompson, J.M. Meese, Reduction of α-particle sensitivity in dynamic semiconductor memories (16 k d-RAMs) by neutron irradiation. IEEE Trans. Nucl. Sci. NS-28(6), 3987–3993 (1981)
E. Ibe, Current and future trend on cosmic-ray-neutron induced single event upset at the ground down to 0.1-micron-device, in The Svedberg Laboratory Workshop on Applied Physics, Uppsala, 3 May (1)
JEDEC, Measurement and reporting of alpha particle and terrestrial cosmic ray induced soft errors in semiconductor devices. JEDEC Standard JESD89, pp. 1–63 (2001)
E. Ibe, H. Kameyama, Y. Yahagi, K. Nishimoto, Y. Takahashi, Distinctive asymmetry in neutron-induced multiple error patterns of 0.13 umocess SRAM, in The 6th International Workshop on Radiation Effects on Semiconductor Devices for Space Application, Tsukuba, 6–8 Oct 2004, pp. 19–23 (2004)
N. Seifert, V. Zia, Assessing the impact of scaling on the efficacy of spatial redundancy based mitigation schemes for terrestrial applications, in 2007 IEEE Workshop on Silicon Errors in Logic—System Effects, Austin, Texas, April 3, 4 (2007)
P. Shivakumar, M. Kistler, S.W. Keckler, D. Burger, L. Alvisi, Modeling the effect of technology trends on the soft error rate of combinational logic, in International Conference on Dependable Systems and Networks, pp. 389–398 (2002)
H. Quinn, K. Morgan, P. Graham, J. Krone, M. Caffrey, K. Lundgren, Static proton and heavy ion testing of the Xilinx Virtex-5 device, in Radiation Effects Data Workshop, No. W-31, Honolulu, Hawaii, 23–27 July, pp. 177–184 (2007)
T. Calin, M. Nicolaidis, R. Velazco, Upset hardened memory design for submicron CMOS technology. IEEE Trans. Nucl. Sci. 43(6), 2874–2878 (1996)
H. Quinn, J. Tripp, T. Fairbanks, A. Manuzzato, Improving microprocessor reliability through software mitigation, in 2011 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinoi, 29–30 Mar 2011, pp. 16–21
T. Uemura, Y. Tosaka, H. Matsuyama, K. Shono, SEILA: soft error immune latch for mitigating multi-node-SEU and local-clock-SET, in IEEE International Reliability Physics Symposium 2010, Anaheim, CA, USA, 2–6 May 2010, pp. 218–223
H.-H. Lee, K. Lilja, S. Mitra, Design of a sequential logic cell using LEAP: layout design through error aware placement, in 2010 IEEE Workshop on Silicon Errors in Logic—System Effects, Stanford University, 23–24 Mar 2010
R.C. Baumann, E.B. Smith, Neutron-induced boron fission as a major source of soft errors in deep submicron SRAM devices, in 2000 IEEE International Reliability Physics (2000)
IEC (2008) Part 38: soft error test method for semiconductor devices with memory. Semiconductor devices. Mechanical and climatic test methods, in Symposium Proceedings IEC60749-38, San Jose, CA, 10–13 Apr 2008 pp. 152–157
B. Falsafi, Reliability in the dark silicon era, in International On-Line Testing Symposium 2011, Athens, Greece, 13–15 July 2011, p. xvi
J. Loncaric, DOE’s exascale initiative and resilience, in 2011 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, 29–30 Mar 2011
J.F. Abella, J. Cazorlal, D. Gizopoulos, E. Quinones, A. Grasset, S. Yehia, P. Bonnot, R. Mariani, G. Bernat, Towards improved survivability in safety-critical systems, in 17th IEEE International On-Line Testing Symposium, Athens, Greece, 13–15 July 2011 (S3), pp. 242–247
D. Baumeister, S.G.H. Anderson, Evaluation of chip-level irradiation effects in a 32-bit safety microcontroller for automotive braking applications, in 2012 IEEE Workshop on Silicon Errors in Logic—System Effects, vol. 2.2, Urbana-Champaign, Illinois, 27–28 Mar 2012
Automotive Electronics Council, Failure mechanism based stress test quantification for integrated circuits, in AEC-Q100 Revolution G, pp. 1–35 (2007)
ISO, International Standard ISO26262 Road vehicles-Functional safety (2011)
H. Quinn, Study on cross-layer reliability, in 2011 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, March 29–30
N. Carter, Cross-layer reliability, in 2010 IEEE Workshop on Silicon Errors in Logic—System Effects, Stanford University, March 23, 24 (2010)
C. Slayman, Eliminating the threat of soft errors—a system vendor perspective, in IRPS SER Panel Discussion, Eliminating the Threat of Soft Error, vol. 6 Dallas, Texas, April 2, 2003
E. Ibe, H. Kameyama, Y. Yahagi, H. Yamaguchi, Single event effects as a reliability issue of IT infrastructure, in 3rd International Conference on Information Technology and Applications, July 3–7, 2005, Sydney, vol. I, pp. 555–560
E. Ibe, K. Shimbo, T. Toba, H. Taniguchi, Y. Taniguchi, LABIR: Inter-LAyer built-in reliability for electronic components and systems, in Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, USA, March 27–28 2011
E. Ibe, K. Shimbo, T. Toba, H. Taniguchi, Y. Taniguchi, Quantification and mitigation strategies of neutron induced soft-errors in CMOS devices and components-the past and future, in 2011 IEEE International Reliability Physics Symposium, Monterey, California, April 12–14 (3C2)
A. Evans, M. Nicolaidis, S.-J. Wen, D. Alexandrescu, E. Costenaro, RIIF—Reliability Information Interchange Format, in IEEE International On-Line Testing Symposium, Sitges, Spain, June 27–29, 2012 (6.2)
E. Ibe, T. Toba, K. Shimbo, H. Taniguchi, Fault-Based reliable design on-upper-bound of electronic systems for terrestrial radiation including muons, electrons, protons and low energy neutrons, in IEEE International On-Line Testing Symposium, Sitges, Spain, June 27–29, 2012 (3.2)
H. Kobayashi, N. Kawamoto, J. Kase, K. Shiraishi, Alpha particle and neutron-induced soft error rates and sling trends in SRAM, in IEEE International Reliability Physics Symposium 2009, Montreal, Quebec, Canada, April 28–30 (2H4), pp. 206–211
B.D. Sierawski, M.H. Mendenhall, R.A. Reed, M.A. Clemens, R.A. Welle, R.D. Schrimp, E.W. Blackmore, M. Trinczek, B. Hitti, J.A. Pellish, R.C. Baumann, S.-J. Wen, R. Wong, N. Tam, Muon-Induced single event upsets in deep-submicron technology. Trans. Nucl. Sci. 57(6), 3273–3278 (2010)
S. Wen, R. Wong, M. Romain, N. Tam, Thermal neutron soft error rate for SRAMs in the 90 nm–45 nm technology range, in 2010 IEEE International Reliability Physics Symposium, Anaheim, CA, 2–6 May 2010 (SE5.1), pp. 1036–1039
S. Wen, S.Y. Pai, R. Wong, M. Romain, M., N. Tam, B10 Findings and correlation to thermal neutron soft error rate sensitivity for SRAMs, in the sub-micron technology, in IEEE International Integrated Reliability Workshop, Stanford Sierra, CA, Oct. 17–21 2010, pp. 31–33
R.C. Baumann, Determining the impact of alpha-particle-emitting contamination from the Fukushima Daiichi disaster on Japanese manufacturing sites, in The 12th European Conference on Radiation and Its Effects on Component and Systems, Sevilla, Spain, Sept. 19–23 2010, pp. 784–787
http://semicon.jeita.or.jp/hp/srg/docs/JEITA-SERPG-View_en.pdf
D.C. Matthews, M.J. Dion, NSE impact on commercial avionics, in 2009 IEEE International Reliability Physics Symposium, Montreal, QC, April 26–30 2009, pp. 181–193
E. Normand, J. Wert, D. Oberg, P. Majewski, P. Voss, S.A. Wender, Neutron-induced single event burnout in high voltage electronics. Trans. Nucl. Sci. 44, 2358–2368 (1997)
C. Slayman, Cache and memory error detection, correction, and reduction techniques for terrestrial servers and workstations. IEEE Trans. Device Mater. Reliab. 5(3), 397–404 (2005)
G. Schindlbeck, C. Slayman, Neutron-induced logic soft errors in dram technology and their impact on reliable server memory, in IEEE Workshop on Silicon Errors in Logic—System Effects, Austin Texas, April 3–4 2007, p. 3
K. Shimbo, T. Toba, K. Nishii, E. Ibe, Y. Taniguchi, Y. Yahagi, Quantification & mitigation techniques of soft-error rates in routers validated in accelerated neutron irradiation test and field test, in 2011 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, 29–30 Mar 2011, pp. 11–15
C. Rivetta, B. Allongue, G. Berger, F. Faccio, W. Hajdas, Single event burnout in DC-DC converters for the LHC experiments, in The 6th European Conference on Radiation and Its Effects on Components and Systems, Grenoble, France, 10–14 Sept 2001, pp. 315–322
P. Rech, L. Carro, Experimental evaluation of neutron-induced effects in graphic processing units, in The 9th Workshop on Silicon Errors in Logic—System Effects, Palo Alto, California, USA, 26–27 Mar, vol. 5.3
A. Geist, Exascale monster in the closest, in 2012 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, 27–28 Mar, vol 5.1 (2012)
J.T. Daly, Emerging challenges in high performance computing: resilience and the science of embracing failure, in The 9th Workshop on Silicon Errors in Logic—System Effects, Palo Alto, California, USA, 26–27 Mar (Keynote III) (2013)
G. Upasani, X. Vera, A. Gonzalez, Achieving zero DUE for L1 data caches by adapting acoustic wave detectors for error detection, in 19th IEEE International On-Line Testing Symposium, Chania, Crete, 8–10 July, vol. 5.2 (2013)
D. Skarin, J. Sanfridson, Impact of soft errors in a brake-by-wire system, in IEEE Workshop on Silicon Errors in Logic—System Effects 3, Austin, Texas, 3–4 Apr (2007)
B. Nemeth, P. Gaspar, Z. Szabo, J. Bokor, O. Sename, L. Dugard, Design of fault-tolerant control for trajectory tracking, in 13th Mini Conference on Vehicle System Dynamics, Identification and Anomalies, Budapest, Hungary, 5–7 Nov 2012 (2012)
Y. Nakata, Y. Ito, Y. Sugure, S. Oho, Y. Takeuchi, S. Okumura, H. Kawaguchi, M. Yoshimoto, Model-based fault injection for failure effect analysis—evaluation of dependable SRAM for vehicle control units, in The 5th Workshop on Dependable and Secure Nanocomputing, Hong Kong, China, 27 July 2011
C. Lopez-Ongil, M. Portela-Garcia, M. Garcia-Valderas, A. Vaskova, J. Rivas-Abalo, L. Entrena, A. Martinortega, J. Martinez-Oter, S. Rodriguez-Bustabad, I. Arruego, SEU sensitivity of robust communication protocols, in IEEE International On-Line Testing Symposium, Sitges, Spain, 27–29 June 2012, vol. 9.4 (2012), pp. 188–193
A. Vaskova, M. Portela-Garcia, M. Garcia-Valderas, M. SonzaReorda, C. Lopez-Ongil, Hardening of serial communication protocols for potentially critical systems in automotive applications: LIN Bus, in 19th IEEE International On-Line Testing Symposium, Chania, Crete, 8–10 July, vol. 1.3 (2013), pp. 13–18
P. Rech, C. Aguiar, R. Ferreira, C. Frost, L. Carro, Neutrons radiation test of graphic processing units, in IEEE International On-Line Testing Symposium, Sitges, Spain, 27–29 June 2012, vol. 3.3 (2012)
Y. Chen, Cosmic ray effects on cellphone and laptop applications, in The 9th Workshop on Silicon Errors in Logic—System Effects, Palo Alto, California, USA, 26–27 Mar, vol. 5.4 (2013)
G. Upasani, X. Vera, A. González, Avoiding core’s DUE & SDC via acoustic wave detectors and tailored error containment and recovery, in 2014 ACM/IEEE 41st International Symposium on Computer Architecture (ISCA) 14–18 June 2014, Minneapolis, Minnesota, pp. 37–48
E.H. Neto, F.L. Kastensmidt, G.I. Wirth, A Built-In current sensor for high speed soft errors detection robust to process and temperature variations, in Proceedings of the 20th Annual Symposium on Integrated Circuits and System Design, Rio de Janeiro, Brazil, September 2007, pp. 190–195
P. Oldiges, K. Bernstein, D. Heidel, B. Klaasen, E. Cannon, R. Dennard, H. Tang, M. Ieong, H.-S.P. Wong, Soft error rate scaling for emerging SOI technology options, in VLSI Technology, 2002. Digest of Technical Papers. 2002 Symposium on 11–13 June 2002 Honolulu, Hawaii, USA, pp. 46–47
N. Seifert, B. Gill, S. Jahinuzzaman, J. Basile, V. Ambrose, Q. Shi, R. Allmon, A. Bramnik, Soft error susceptibilities of 22 nm tri-gate devices, in IEEE Transactions on Nucear. Science, vol. 59, No. 6, pp. 2666–2673
P. Roche, Technology downscaling worsening radiation effects in bulk: SOI to the rescue, in 2013 IEEE International Electron Devices Meeting, 9–11 Dec. 2013, pp. 31.1.1–31.1.4
H. Sato, T. Wada, S. Ohbayashi, K. Kozaru, Y. Okamoto, Y. Higashide, T. Shimizu, Y. Maki, R. Morimot, H. Otoi, T. Koga, H. Honda, M. Taniguchi, Y. Arita, T. Shiomi, A 500-MHz pipelined burst SRAM with improved SER immunity. IEEE J. Solid State Circ. 34(11), 1571–1579 (1999)
L.W. Massengill, SEU-hardened resistive-load static RAMs. IEEE Trans. Nucl. Sci. 38(6), 1478–1485 (1991)
T. Ohsawa, S. Ikeda, T. Hanyu, H. Ohno, T. Endoh, A 1-Mb STT-MRAM with zero-array standby power and 1.5-ns quick wake-up by 8-b fine-grained power gating, in 2013 5th IEEE International Memory Workshop, Monterey, California, 26–29 May 2013, pp. 80–83
N. Wang, S.J. Patel, Symptom based redundant multithreading, in The Second Workshop on System Effects of Logic Soft Errors, Urbana-Champaign, Illinois, 11–12 Apr 2006
K. Shimbo, T. Toba, T. Uezono, E. Ibe, Rapid recovery technique from soft error of FPGAs in information and communication apparatus. The Institute of Electronics, Information Technical Report 115(58), 37–42 (2015)
D. Ernst, S. Das, S. Lee, D. Blaauw, T. Austin, T. Mudge, N. Kim, K. Flautner, Razor: circuit-level correction of timing errors for low-power operation. Micro 24(6), 10–20 (2004)
http://www.nextplatform.com/2016/03/14/intel-marrying-fpga-beefy-broadwell-open-compute-future/
J.J. Chen, R. Tsai, H. Tzeng, A symptom-driven fuzzy system for isolating faults, in IEEE International Conference on Systems, Man and Cybernetics, Chicago, Illinois, vol. 2, pp. 1589–1592 (1992)
T. Marques, A symptom-driven expert system for isolating and correcting network faults. IEEE Commun. Mag. 26(3), 6–13 (1988)
M. Lee, A. Krishnakumar, P. Krishnan, N. Singh, S. Yajnik, Hypervisor-assisted application checkpointing in virtualized environments, in DSN2011, 28–30 June 2011, Hong Kong, China
Y. Sazeides, A. Geist, S. Adve, R. Iyer, T. Wenisch, Panel discussion: reliability requirements of large scale data centers, in 2012 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, 27–28 Mar 2012, vol. 4.1 (2012)
A. Sanyal, S. Alam, S. Kundu, A built-in self-test scheme for soft error rate characterization, in International On-Line Testing Symposium 2008, 6–9 July 2008, Greece, vol. 3.3, p. 65
S. Siskos, A new built-in current sensor for low supply voltage analog and mixed-signal circuits testing, in International On-Line Testing Symposium, 5–7 July 2010, Corfu Island, Greece
K. Yoshikawa, T. Hashida, M. Nagata, An on-chip waveform capturer for diagnosing off-chip power delivery, in International Conference on IC Design and Technology, 2–4 May 2011 Kaohsiung, Taiwan
M.-L. Li, P. Ramachandran, Towards a software-hardware co-designed resilient system, in IEEE Workshop on Silicon Errors in Logic—System Effects, 3–4 Apr 2007, vol. 3, Austin Texas
S.K.S. Hari, H. Naeimi, P. Ramachandran, S.V. Adve, Relyzer: application resiliency analyzer for transient faults, in 2011 IEEE Workshop on Silicon Errors in Logic—System Effects, Urbana-Champaign, Illinois, March 29–30, pp. 22–26
http://www.hitachi.com/rev/archive/2001/_icsFiles/afieldfile/2004/06/08/r2001_04_101.pdf. Accessed 22 Nov 2013
http://hes-standards.org/sc25_wg1_introduction.pdf. Accessed 22 Nov 2013
A. Dixit, A. Wood, The impact of new technology on soft error rates, in IEEE International Reliability Physics Symposium (IRPS), Monterey, California, pp. 486–492 (2011)
J. Maiz, S. Hareland, K. Zhang, P. Armstrong, Characterization of multi-bit soft error events in advanced SRAMs, in IEEE International Electron Devices Meeting (IEDM), (Washington, DC, 2003) pp. 519–522
S. Ohbayashi, M. Yabuuchi, K. Nii, Y. Tsukamoto, S. Imaoka, Y. Oda, T. Yoshihara, M. Igarashi, M. Takeuchi, H. Kawashima, Y. Yamaguchi, K. Tsukamoto, M. Inuishi, H. Makino., K. Ishibashi, H. Shinohara, A 65-nm SoC embedded 6T-SRAM designed for manufacturability with read and write operation stabilizing circuits, in IEEE Symposium on VLSl Circuits Digest of Technical Papers, Kyoto, Japan, pp. 820–829 (2007)
S. Yoshimoto, T. Amashita, D. Kozuwa, T. Takata, M. Yoshimura, Y. Matsunaga, H. Yasuura, H. Kawaguchi, M. Yoshimoto, Multiple-bit-upset and single-bit-upset resilient 8T SRAM bitcell layout with divided wordline structure, in IEEE International On-Line Testing Symposium (IOLTS), (Athens, Greece, 2011) pp. 151–156
iRoC TFIT Simulator, Transistor Level Soft Error Analysis. http://www.iroctech.com
G. Gasiot, D. Giot, P. Roche, Multiple cell upsets as the key contribution to the total ser of 65 nm cmos srams and its dependence on well engineering. IEEE Trans. Nucl. Sci. 54(6), 2468–2473 (2007)
H. Iwase, K. Nitta, T. Nakamura, Development of general-purpose particle and heavy ion transport Monte Carlo code, in IEEE Transactions on Nuclear Science, vol. 39, pp. 1142–1151 (2002). http://phits.jaea.go.jp/
T. Sato, H. Yasuda, K. Niita, A. Endo, L. Sihverd, Development of PARMA: PHITS-based analytical radiation model in the atmosphere, in Rad. Res. 170, 244–259, 2008; EXPACS ver. 2.21, 2011, http://phits.jaea.go.jp/expacs/index.html
P. Hazucha, C. Svensson, Impact of CMOS technology scaling on the atmospheric neutron soft error rate. IEEE Trans. Nucl. Sci. 47(6), 2586–2594 (2000)
C. Robert, Radiation-induced soft errors in advanced semiconductor technologies. IEEE Trans. Nucl. Sci. 5(3), 305–316 (2005)
C. Auth, A. Cappellani, J.S. Chun, A. Dalis, A. Davis, T. Ghani, G. Glass, T. Glassman, M. Harper, M. Hattendorf, P. Hentges, S. Jaloviar, S. Joshi, J. Klaus, K. Kuhn, D. Lavric, M. Lu, H. Mariappan, K. Mistry, B. No.rris, N. Rahhal-orabi, P. Ranade, J. Sandford, L. Shifren, V. Souw, K. Tone, F. Tambwe, A. Thompson, D. Towner, T. Troeger, P. Vandervoorn, C. Wallace, J. Wiedemer, C. Wiegand, 45 nm High-k + Metal Gate Strain-Enhanced Transistors, in IEEE Symposium on VLSI Technology, Honolulu, Hawaii, pp. 128–129 (2008)
H.J. Cho, K.I. Seo, W.C. Jeong, Y.H. Kim, Y.D. Lim, W.W. Jang, J.G. Hong, S.D. Suk, M. Li, C. Ryou, H.S. Rhee, J.G. Lee, H.S. Kang, Y.S. Son, C.L. Cheng, S.H. Hong, W.S. Yang, S.W. Nam, J.H. Ahn, D.H. Lee, S. Park, M. Sadaaki, D.H. Cha, D.W. Kim, S.P. Sim, S. Hyun, C.G. Koh, B.C. Lee, S.G. Lee, M.C. Kim, Y.K. Bae, B. Yoon, S.B. Kang, J.S. Hong, S. Choi, D.K. Sohn, J.S. Yoon, C. Chung, Bulk planar 20 nm high-K/metal gate CMOS technology platform for low power and high performance applications, in IEEE International Electron Devices Meeting (IEDM) (Washington, DC, 2011), pp. 350–353
C.C. Wu, Y.K. Leung, C.S. Chang, M.H. Tsai, H.T. Huang, D.W. Lin, Y. M. Sheu, C.H. Hsieh, W.J. Liang, L.K. Han, W.M. Chen, S.Z. Chang, S.Y. Wu, S.S. Lin, H. C. Lin, C. H. Wang, P.W. Wang, T.L. Lee, C.Y. Fu, C. W. Chang, S.C. Chen, S.M. Jang, S.L. Shue, H.T. Lin, Y.C. See, Y.J. Mii, C. H. Diaz, B. J. Lin, M. S. Liang, Y.C. Sun, A 90-nm CMOS device technology with high-speed, general-purpose, and low-leakage transistors for system on chip applications, in IEEE International Electron Devices Meeting (IEDM), San Francisco, California, pp. 65–68 (2002)
C. Shin, N. Damrongplasit, X. Sun, Y. Tsukamoto, B. Nikoli, T.J.K. Liu, Performance and yield benefits of Quasi-Planar bulk CMOS technology for 6-T SRAM at the 22-nm node. IEEE Trans. Elect. Devices 58(7), 1846–1854 (2011)
J. Furuta, K. Kobayashi, H. Onodera, Impact of cell distance and well-contact density on neutron-induced multiple cell upsets, in Proceedings of International Reliability Physical Symposium, Monterey, California, Apr 2013, pp. 6C.3.1–6C.3.4
K. Zhang, K. Kobayashi, Contributions of charge sharing and bipolar effects to cause or suppress MCUs on redundant latches, in Proceedings of International Reliability Physical Symposium, Monterey, Calirofonia, Apr 2013, pp. SE.5.1–SE.5.4
R. Yamamoto, C. Hamanaka, J. Furuta, K. Kobayashi, H. Onodera, An area-efficient 65 nm radiation-hard dual-modular flip-flop to avoid multiple cell upsets. IEEE Trans. Nucl. Sci. 58(6), 3053–3059 (2011)
D. Krueger, E. Francom, J. Langsdorf, Circuit design for voltage scaling and SER immunity on a quad-core itanium processor, in ISSCC, Feb 2008, San Francisco, California, pp. 94–95
R. Kan, T. Tanaka, G. Sugizaki, K. Ishizaka, R. Nishiyama, S. Sakabayashi, Y. Koyanagi, R. Iwatsuki, K. Hayasaka, T. Uemura, G. Ito, Y. Ozeki, H. Adachi, K. Furuya, T. Motokurumada, The 10th generation 16-core SPARC64TM; processor for mission critical UNIX server. IEEE J. Solid State Circ. 49(1), 32–40 (2014)
M. Zhang, S. Mitra, T.M. Mak, N. Seifert, N.J. Wang, Q. Shi, K.S. Kim, N.R. Shanbhag, S.J. Patel, Sequential element design with built-in soft error resilience. IEEE Trans. VLSI Syst. 14(12), 1368–1378 (2006)
J. Furuta, C. Hamanaka, K. Kobayashi, H. Onodera, A 65 nm bistable cross-coupled dual modular redundancy flip-flop capable of protecting soft errors on the C-element, in VLSI Circuit Symposium, June 2010, Honolulu, Hawaii, pp. 123–124
N. Seifert, V. Ambrose, B. Gill, Q. Shi, R. Allmon, C. Recchia, S. Mukherjee, N. Nassif, J. Krause, J. Pickholtz, A. Balasubramanian, On the radiation-induced soft error performance of hardened sequential elements in advanced bulk CMOS technologies, in Proceedings of International Relational Physics Symposium, May 2010, Anaheim, California, pp. 188–197
B. Narasimham, K. Chandrasekharan, Z. Liu, J. Wang, G. Djaja, N. Gaspard, J. Kauppila, B. Bhuva, A hysteresis-based d-flip-flop design in 28 nm CMOS for improved SER hardness at low performance overhead. IEEE Trans. Nucl. Sci. 59(6), 2847–2851 (2012)
N. Gaspard, S. Jagannathan, Z. Diggins, N. Mahatme, T. Loveless, B. Bhuva, L. Massengill, W. Holman, B. Narasimham, A. Oates, P. Marcoux, N. Tam, M. Vilchis, S.-J. Wen, R. Wong, Y. Xu, Soft error rate comparison of various hardened and non-hardened flip-flops at 28-nm node, in Proceedings of International Reliability Physical Symposium Waikoloa, Hawaii, June 2014, pp. SE.5.1–SE.5.5
R. Tsuchiya, M. Horiuchi, S. Kimura, M. Yamaoka, T. Kawahara, S. Maegawa, T. Ipposhi, Y. Ohji, H. Matsuoka, Silicon on thin BOX: a new paradigm of the CMOSFET for low-power high-performance application featuring wide-range back-bias control, in IEDM, San Francisco, California, Dec 2004, pp. 631–634
N. Sugii, R. Tsuchiya, T. Ishigaki, Y. Morita, H. Yoshimoto, S. Kimura, Local Vth variability and scalability in Silicon on-Thin-BOX (SOTB) CMOS with small random-dopant fluctuation. IEEE Trans. Elect. Dev. 57(4), 835–845 (2010)
S. Kamohara, N. Sugii, Y. Yoshiki, H. Makiyama, T. Yamashita, T. Hasegawa, S. Okanishi, H. Yanagita, M. Kadoshima, K. Maekawa, M. Hiroshi, Y. Yamagata, H. Oda, Y. Yamaguchi, K. Ishibashi, A. Hideharu, K. Usami, K. Kobayashi, T. Mizutani, T. Hiramoto, Ultra low-voltage design and technology of silicon on-thin-buried-oxide (SOTB) CMOS for highly energy efficient electronics in iot era, in VLSI Technology Symposium (Honolulu, Hawaii, 2014)
P. Roche, J.-L. Autran, G. Gasiot, D. Munteanu, Technology downscaling worsening radiation effects in bulk: SOI to the rescue, in IEDM, Washington, DC, Dec 2013, pp. 31.1.1–31.1.4
D. Jacquet, G. Cesana, P. Flatresse, F. Arnaud, P. Menut, F. Hasbani, T. Di Gilio, C. Lecocq, T. Roy, A. Chhabra, C. Grover, O. Minez, J. Uginet, G. Durieu, F. Nyer, C. Adobati, R. Wilson, D. Casalotto, 2.6 GHz ultra-wide voltage range energy efficient dual A9 in 28 nm UTBB FD-SOI, in VLSI Technical Symposium, Kyoto, Japan, 2013, pp. C44–C45.8
K. Kobayashi, K. Kubota, M. Masuda, Y. Manzawa, J. Furuta, S. Kanda, H. Onodera, A low-power and area-efficient radiation-hard redundant flip-flop, DICE ACFF in a 65 nm thin-box FD-SOI, in IEEE Tranactions on Nuclear Science vol. 61, no. 4, June 2014
S.M.A.H. Jafri, et al., Design of a fault-tolerant coarse-grained reconfigurable architecture: a case study, in Proceedings of International Symposium on Quality Electronic Design (ISQED), Mar 2010, San Jose, California, pp. 845–852
M.M. Azeem, et al., Error recovery technique for coarse-grained reconfigurable architectures, in Proceedings of IEEE Symposium on Design and Diagnostics of Electronic Circuits and Systems (DDECS), Apr 2011, Cottbus, Germany, pp. 441–446
T. Schweizer, et al., Low-cost TMR for fault-tolerance on coarse-grained reconfigurable architectures, in Proceedings of International Conference on Reconfigurable Computing and FPGAs (ReConFig), Dec 2011, Cancun, Mexico, pp. 135–140
S.C. Goldstein et al., PipeRench: a reconfigurable architecture and compiler. IEEE Trans. Comput. 33(4), 70–77 (2000)
C. Ebeling, et al., RaPiD—reconfigurable pipelined data-path, in Proceedings of International Conference on Field Programmable Logic and Applications (FPL), Sept 1996, Darmstadt, Germany, pp. 126–135
Y. Mitsuyama, et al., Area-efficient reconfigurable architecture for media processing, IEICE Transactions in Fundamentals of Electronics, Communications and Computer Sciences, Dec 2008, vol. E91-A, no. 12, pp. 3651–3662
T. Toi, et al., High-level synthesis challenges and solutions for a dynamically reconfigurable processor, in Proceedings of International Conference on Computer-Aided Design (ICCAD), Nov. 2006, San Jose, California, pp. 702–708
T. Sugawara et al., Dynamically reconfigurable processor implementation with IPFlex’s DAPDNA technology. IEICE Trans. Informat. Syst. E87-D(8), 1997–2003 (2004)
V. Baumgarte et al., PACT XPP—a self-reconfigurable data processing architecture. J. Supercomput. 26(2), 167–184 (2003)
H. Konoura, et al., Reliability-configurable mixed-grained reconfigurable array supporting C-based design and its irradiation testing, in IEICE Transactions on Fundamentals of Electronics, Communications and Computer Sciences, to appear, Dec. 2014
T. Imagawa, et al., A cost-effective selective TMR for heterogeneous coarse-grained Reconfigurable architectures based on DFG-level vulnerability analysis, in Proceedings of Design, Automation & Test in Europe (DATE), Mar 2013, Grenoble, France, pp. 701–706
T. Imagawa, H. Tsutsui, H. Ochi, T. Sato, A cost-effective selective TMR for coarse-grained reconfigurable architectures based on DFG-level vulnerability analysis, in IEICE Transactions on Electronics, vol. E96-C, no. 4, Apr. 2013
B. Pratt, M. Caffrey, P. Graham, K. Morgan, M. Wirthlin, Improving FPGA design robustness with partial TMR, in Proceedings of International Reliability Physics Symposium (IRPS), San Jose, California, Mar. 2006, pp. 226–232,
J. Yao et al., DARA: a low-cost reliable architecture based on unhardened devices and its case study of radiation stress test. IEEE Trans. Nucl. Sci. 59(6), 2852–2858 (2012)
K. Wakabayashi, T. Okamoto, C-based SoC design flow and EDA tools: an ASIC and system vendor perspective, in IEEE Transactions Computer-Aided Design of Integrated Circuits and Systems, vol. 19, no. 12, Dec 2000, pp. 1507–1522
CyberWorkbench, http://www.nec.com/en/global/prod/cwb/
M. Sugihara, T. Ishihara, M. Muroyama, K. Hashimoto, A simulation-based soft error estimation methodology for computer system, in Proceedings of International Symposium on Quality Electronic Design (ISQED), Mar 2006, San Jose, California, pp. 196–203
M. Sugihara, T. Ishihara, and K. Murakami, Architectural-level soft-error modelling for estimating reliability of computer systems, IEICE Trans. Electron. E90-C(10), 1983–1991 (2007)
M. Sugihara, T. Ishihara, K. Murakami, Task scheduling for reliable cache architectures of multiprocessor systems, in Proceedings of Design, Automation and Test in Europe (DATE), Nice Acropolis, France, Apr 2007, pp. 1490–1495
M. Sugihara, T. Ishihara, K. Murakami, Reliable cache architectures and task scheduling for multiprocessor systems. IEICE Trans. Electron. E91-C(4), 410–417 (2008)
M. Sugihara, SEU vulnerability of multiprocessor systems and task scheduling of heterogeneous multiprocessor systems, in Proceedings of EUROMICRO Conference on Digital System Design (DSD), Patras, Greece, Aug 2009 pp. 333–340
M. Sugihara, Reliability inherent in heterogeneous multiprocessor systems and task scheduling for ameliorating their reliability. IEICE Trans. Fundament. Electron. Commun. Comput. Sci. E92-A(4), 1121–1128 (2009)
M. Sugihara, Heterogeneous multiprocessor synthesis under performance and reliability constraints, in Proceedings of EUROMICRO Conference on Digital System Design (DSD), Patras, Greece, Sept 2009, pp. 232–239
M. Sugihara, On synthesizing a reliable multiprocessor for embedded systems. IEICE Trans. Fundament. Electron. Commun. Comput. Sci. E93-A(12), 2560–2569 (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Japan KK, part of Springer Nature
About this chapter

Cite this chapter
Ibe, E.H. et al. (2019). Radiation-Induced Soft Errors. In: Asai, S. (eds) VLSI Design and Test for Systems Dependability. Springer, Tokyo. https://doi.org/10.1007/978-4-431-56594-9_3
Download citation
DOI: https://doi.org/10.1007/978-4-431-56594-9_3
Published:
Publisher Name: Springer, Tokyo
Print ISBN: 978-4-431-56592-5
Online ISBN: 978-4-431-56594-9
eBook Packages: EngineeringEngineering (R0)