
Abstract
In this paper, we discussed the disassembly line balancing problem (DLBP) in the presence of uncertain cycle time. A multi-objective mathematical optimization model was established to minimize workstation equilibrium index and demand index. And Genetic Algorithm (GA) was developed to solve this model. Some works were done as follows: firstly, generating initialized populations combining heuristic with stochastic methods; Secondly, developing a unique principle for gene decoding, which leads to efficient disassembly line balancing; Additionally, converting iteration process to matrix operators based on precedence matrix, which makes it quickly to find the optimal solutions. Finally, given a simulation experiment to get the optimal solutions in Matlab 7 and verify the efficiency of this proposed algorithm.
Supported by: The National Natural Science Foundation of China (No. 70971022; No. 71271054); The Scientific Research and Innovative Plan Program for Postgraduate in University of Jiangsu Province (No. CXLX_0157); The Scientific Research Foundation of the Education Department of Anhui Province (No. 2011sk123).
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
51.1 Introduction
Disassembly operations can be completed not only in a single disassembling workstation, but also in a disassembling unit or disassembling lines (Wiendahl and Burkner 1999; Wiendahl et al. 1998; Gungor and Gupta 1999). In the face of the large-scale product disassembly, disassembly line being organized in flow shop began to gain attention and application so that improve the efficiency of product disassembly and promote disassembly industrialization. It is defined as the disassembly process which consists of a series of disassembly operations elements, each operating elements corresponding to constant operating time, and there exist precedence among some of the operating elements. The disassembly line with various returned cores is often in highly non-equilibrium state, how to maintain its balance and maximize the disassembly efficiency is a very important and urgent problem which should be solved.
The assembly line balance problem research, mainly concentrated in the complete removal. Gungor et al. (2001) and Gungor and Gupta (2001) first proposed the disassembly line balancing problem and developed an algorithm for solving the DLBP in the presence of failures with the goal of assigning tasks to workstations in a probability to minimize the cost of defective parts. (McGovern et al. 2003; McGovern and Gupta 2003) first proposed applying combinatorial optimization techniques to the DLBP. McGovern and Gupta (2004a, b, c, 2007a, b, 2006) later compared various combinatorial optimization techniques for use with DLBP. Koc et al. (2009) used two accurate calculation formulas, i.e. dynamic programming (DP) and integer programming (IP) and adopt AND/OR GRAPH (AOG) shows the priority of tasks in the model to research DLBP, but the exact algorithm can only solve the small scale problems. A recent book by Filip (2011) is helpful in understanding the general area of disassembly.
These literatures consider only single objective in constructing optimization model and assuming constant cycle time in solving this problem, but in these single targets they often affect or even conflict with each other. Therefore, it’s more realistic to consider integrated multiple targets in arranging the disassembly path. This paper presents a multi-objective model considering both equilibrium index and demand index in the presence of uncertain cycle time. In view of the superiority and effectiveness of GA in solving combinatorial optimization problems, we design GA for DLBP and simplify the difficulty in solving problem and set a unique chromosome decoding rule in the determination of cycle time which improves the disassembly line balance efficiency greatly. In operator designing, we design a GA operator based on precedence matrix which can convert iterative procedure to matrix operation and has a good adaptability to target function. So this algorithm has faster convergence speed, and can quickly obtain the optimal solution. The simulation experiment results show the effectiveness of the algorithm.
51.2 Multi-Objective Optimization Model for DLBP
For ease of modeling, some assumptions are given as follows:
-
Each product is disassembled completely.
-
All parts are no defect when being disassembled.
-
Disassembly time of each component is deterministic, constant and integer.
-
Each task is assigned to exactly one workstation.
-
There are no parallel workstations, namely the workstation is linear arrangement.
-
The sum of the part disassembly time of all parts assigned to a workstation must not exceed CT.
-
Part precedence relationships must be enforced.
The disassembly line balancing problem seeks a sequence which: is feasible, minimizes workstations, and ensures similar idle times, as well as other end of life specific concerns. This paper seeks to fulfill four objectives including cost, profit, equilibrium index and demand index. The mathematic model is described as:
Some notations in the model are described as follows:
- \( CT \) :
-
Cycle time
- \( n \) :
-
Serial Number of workstation
- \( ST_{n} \) :
-
Operating time of workstation \( n \)
- \( N \) :
-
Numbers of workstation
- \( M \) :
-
Numbers of operation elements
- \( m \) :
-
The \( m \)th operation element
- \( d_{m} \) :
-
Demand for parts \( m \)
- \( t_{m} \) :
-
Disassembling time of the mth operation element
- \( x_{mn} \) :
-
Binary value; 1 if task m is assigned to the nth workstation, else 0
- \( S_{n} \) :
-
Operation elements which are assigned to the \( n \)th workstation
- \( Q_{n} \) :
-
Numbers of operation elements in \( S_{n} . \)
51.3 Disassembly Precedence Relation Matrix
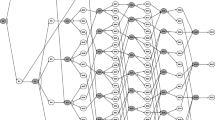
In this paper, we take a certain type mobile phone as research object; its parts are shown in Fig. 51.1.

Mobile phone parts
We obtain precedence relation matrix which is more suitable for processing by computer through quantifying Fig. 51.2. We denote \( y_{ij} \) as a binary value; 1 if task i must be completed before task j, else 0.

Disassembly precedence relations
For a product including n operating elements, the precedence constraints among its operation elements can be mapped into a 0–1 matrix as follows.
51.4 Genetic Algorithm Design for DLBP
GA is a general-purpose optimization algorithm. It can handle any form of objective functions and constraints without knowing the intrinsic nature of the solution during searching and also find out the global optimal solutions in greater probability during searching. Therefore, in view of the advantages of GA, we solve the model using it.
51.4.1 Chromosome Encoding
Coding should be solved firstly in the application and is also one of the key steps in designing it. This paper codes part numbers by real coding directly and then scheduling operation elements in a row according to the order in the assigned workstation and each corresponds to a gene location. Disassembly information for the mobile phone is shown in Table 51.1. Parts disassembly time means the average time of workers’ operating, and demand is the average value for the latest week.
Assuming WS equals to 4. Figure 51.3 is the result of a chromosome coding. This chromosome describes the operation element assigned in the order.

A chromosome being coded
51.4.2 Initial Population
The initialization of the first population is usually generated by random. But taking into account precedence constraints, we combine a heuristic random search method and hybrid method to generate initial population based on the priority relationship among the operations.
Assuming \( a\left( i \right) \) as the feasible operation set after finishing operation \( i \). According to the precedence relation, the condition of operation \( j \) can enter the feasible operation set \( a\left( i \right) \) is that all operations should be completed before it and also it is uncompleted. Therefore, the specific steps of generating feasible operation sequence are as follows:
-
Step 1
Selecting those tasks with no precedence operations to format feasible operation set \( a\left( i \right) \);
-
Step 2
Judging the termination condition, if the optional set \( a\left( i \right) \) is empty, then stop; else go to step 3;
-
Step 3
Selecting a task randomly from the feasible operation set and enrolling it to gene location;
-
Step 4
Updating \( a\left( i \right) \), deleting operations selected and adding new operations in accord with the rules, then go to step 2;
-
Step 5
If all operations are assigned, then stop; else go to step 2.
51.4.3 Chromosome Decoding
Decoding means assigning operation elements to workstations according to priority relationship constraints with \( ST_{k} \le CT\left( {WS} \right) \). On the determination of \( CT\left( {WS} \right) \), for an existing allocation scheme, the increment of \( CT\left( {WS} \right) \) is not a consecutive integer, \( CT\left( {WS} \right) \)’s increase or decrease in the quantity for each adjustment is time value of an operating element. We design a new decoding method based on this idea as follows.
Step 1 Initial CT: \( CT' = {{\sum\limits_{m = 1}^{M} {t_{m} } } \mathord{\left/ {\vphantom {{\sum\limits_{m = 1}^{M} {t_{m} } } {WS = {{45} \mathord{\left/ {\vphantom {{45} 4}} \right. \kern-0pt} 4} = 12}}} \right. \kern-0pt} {WS = {{45} \mathord{\left/ {\vphantom {{45} 4}} \right. \kern-0pt} 4} = 12}} \)
Step 2 Allocating \( M \) operating elements to \( WS \) workstations in accordance with the order of genes in the chromosome (operating elements’ allocation sequence) with \( CT' \). Each workstation time is \( ST_{1} ,ST_{2} , \ldots ,ST_{k} , \ldots ,ST_{WS} \), respectively. If \( ST_{k} \le CT' \), then \( CT' \) is the minimal cycle time under this assignment and stop. Else go to step 3.
Step 3 Defining \( \Updelta_{k} \) as the operating time of the first operating element in the \( \left( {k + 1} \right) \)th workstation and calculating \( \Updelta_{1} ,\Updelta_{2} , \ldots ,\Updelta_{k} , \ldots ,\Updelta_{WS - 1} \) which are the increment of \( CT\left( {WS} \right) \), where \( k = 1,2, \ldots ,\left( {WS - 1} \right) \).
The searching results are shown in Table 51.2 when \( CT' = 12 \).
During the first searching, we obtain
Obviously, \( CT' < CT \).
Therefore, reassigning operating elements to each workstation with \( CT' = 13 \). The assignment results are shown as Table 51.3.
Step 4 Denoting \( CT = \mathop {\hbox{max} }\limits_{1 \le k \le WS} \left\{ {ST_{k} } \right\},CT' = \mathop {\hbox{min} }\limits_{1 \le k \le WS} \left\{ {ST_{k} + \Updelta_{k} } \right\}, \) if \( CT \le CT' \), then \( CT \) is the minimal cycle time under this assignment and stop; Else go to step 2.
During the first searching, \( CT = \mathop {\hbox{max} }\limits_{1 \le k \le WS} \left\{ {ST_{k} } \right\} = 13,CT' = \mathop {\hbox{min} }\limits_{1 \le k \le WS} \left\{ {ST_{k} + \Updelta_{k} } \right\} = 15. \) Obviously, \( CT' > CT \), stop. The results of decoding are shown in Table 51.3 and \( CT = 13 \).
51.4.4 Fitness Function
The fitness function is maximum, but the objective function is minimum, in order to convert target function to seek maximum problem, we introduce a transition function \( C \) (\( C \) is constant and \( C \ge \sum\limits_{n = 1}^{N} {\left( {CT - ST_{n} } \right)}^{2} + \sum\limits_{m = 1}^{M} {m \cdot d_{m} } \)). Calculating the fitness of each individual as follows:
51.4.5 Select Operator
We apply the famous roulette wheel selection method to select excellent quality unit and generate new populations. The main idea of this method is that the next generation inherit some excellent quality unites which are selected based on the fitness value of unites in the population in certain rules and methods, namely individual choice probability is proportional to the fitness value, and the probability that strong adaptability individuals being selected is high.
51.4.6 Crossover Operator
This paper applies two-point crossover method which generates two cross points randomly:
-
(1)
For a chromosome including \( M \) genes, the first cross point is \( position1 \) which is a stochastic integer between \( 1 \) and \( M - 1 \).
-
(2)
Another stochastic integer between \( position1 \) and \( M \) is the second cross point.
Therefore the two points divide the chromosome into three parts, i.e. Head, Body and Tail. The chromosomes’ crossbar transition occurs in Body which is between them. The gene segment Bodyl in the first chromosome’s Body is found in the second one. They are arranged in the second chromosome’s numerical order and form a new gene segment Bodyl_new. Having removed the gene segment body and inserted gene segment Bodyl_new, the first chromosome constitutes a new one. A second new chromosome is generated in the same way.
In order to speed up the convergence, law of competition is applied in this paper. Namely compared with the fitness value of progeny chromosome and paternal chromosome, a chromosome which has higher value enters into a new population.
51.4.7 Mutation Operator
Mutation is a genetic operator that alters one or more gene values in a chromosome from its initial state under certain mutation probability \( P_{m} \) and then generating a new one. Law of competition is applied in this paper. In the precedence relation table, the gene segment lying in the front of the mutation point is removed, and then a feasible gene segment is formed according to the method of generating the initial solution. Combining both of them, a new chromosome was generated.
51.5 Simulation Results
Some parameters are set as follows:
\( pop\_size \) is 40, crossover probability \( P_{c} \) is 0.8, mutation probability \( P_{m} \) is 0.2, \( Generation\_no \) is 100. Getting the optimal workstation equilibrium index and demand index optimization scheme by compiling genetic algorithm program in MATLAB 7 as shown in Table 51.4, evolutionary convergence curve of GA are shown in Fig. 51.4.

Evolutionary convergence curve of workstation equilibrium index and demand index solved by GA
51.6 Conclusions
This paper studies DLBP under uncertain cycle time, presents a multi-objective mathematic model aiming to minimize equilibrium index and demand index and resolved by GA. We design a unique chromosome decoding rule to determine cycle time of disassembly line. On the determination of \( CT\left( {WS} \right) \), we present a new decoding method and improve the disassembly line balancing efficiency more; in operator designing, we design a GA operator based on precedence matrix which can convert iterative procedure to matrix operation and has a good adaptability to target function. So this algorithm has faster convergence speed, and can quickly obtain the optimal solution. The simulation experiment results show the effectiveness of the algorithm.
References
Filip FG (2011) The disassembly line: balancing and modeling. Int J Comput Commun Control (3):581–582
Gungor A, Gupta SM (1999) Disassembly line balancing. In: Proceedings of the 1999 annual meeting of the Northeast decision sciences institute, Newport, Rhode Island, 24–26 March, pp 193–195
Gungor A, Gupta SM (2001) A solution approach to the disassembly line problem in the presence of task failures. Int J Prod Res 39(7):1427–1467
Gungor A, Gupta SM, Pochampally K, Kamarthi SV (2001) Complications in disassembly line balancing. In: Proceedings of SPIE, vol 4193. SPIE, Bellingham, Washington, USA, pp 289–298
Koc Ali, Sabuncuoglu Ihsan, Erel Erdal (2009) Two exact formulations for disassembly line balancing problems with task precedence diagram construction using an AND/OR graph. IIE Trans 41:866–881
McGovern SM, Gupta SM (2003) Greedy algorithm for disassembly line scheduling. Syst Man Cybern, IEEE Xplore 2:1737–1744
McGovern SM, Gupta SM (2004a) Combinatorial optimization methods for disassembly line balancing. In: Proceedings of the 2004 SPIE international conference on environmentally conscious manufacturing IV, Philadelphia, Pennsylvania, 25–28 October, pp 53–66
McGovern SM, Gupta SM (2004b) 2-Opt heuristic for the disassembly Line balancing problem. In: Proceedings of SPIE, SPIE, vol 5262. SPIE, Bellingham, Washington, USA, pp 71–84
McGovern SM, Gupta SM (2004c). Combinatorial optimization methods for disassembly line balancing. In: Proceedings of SPIE, vol 5583. SPIE, Bellingham, Washington, USA, pp 53–66
McGovern SM, Gupta SM (2006) Ant colony optimization for disassembly sequencing with multiple objectives. Int J Adv Manuf Technol 30:481–496
McGovern SM, Gupta SM (2007a) A balancing method and genetic algorithm for disassembly line balancing. Eur J Oper Res 179:692–708
McGovern SM, Gupta SM (2007b) Combinatorial optimization analysis of the unary NP-complete disassembly line balancing problem. Int J Prod Res 45:4485–4511
McGovern SM, Gupta SM, Kamarthi SV (2003) Solving disassembly sequence planning problems using combinatorial optimization. In: Proceedings of Northeast decision sciences institute 32nd annual meeting, pp 178–180
Wiendahl H-P, Burkner S (1999) Planning and control in disassembly: the key to an increased profitability. In: Proceeding of the second international working seminar on re-use, Eindhoven, The Netherlands, vol 3, pp 247–256
Wiendahl H-P, Lorenz B, Burkner S (1998) The necessity for flexible and modular structure in hybrid disassembly processes. Prod Eng Res Devel 5:71–76
Acknowledgments
This research was supported in part by the National Natural Science Foundation of China under Grant Numbers (70971022;71271054); and The Scientific Research and Innovative Plan Program for postgraduate in University of Jiangsu Province (CXLX_0157); and the Scientific Research Foundation of the Education Department of Anhui Province (2011sk123).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Liu, By., Chen, Wd., Huang, S. (2013). Research on Disassembly Line Balancing Problem in the Presence of Uncertain Cycle Time. In: Qi, E., Shen, J., Dou, R. (eds) International Asia Conference on Industrial Engineering and Management Innovation (IEMI2012) Proceedings. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-38445-5_51
Download citation
DOI: https://doi.org/10.1007/978-3-642-38445-5_51
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-38444-8
Online ISBN: 978-3-642-38445-5
eBook Packages: EngineeringEngineering (R0)