
Abstract
Clustering is a well-known machine learning algorithm which enables the determination of underlying groups in datasets. In electric power systems it has been traditionally utilized for different purposes like defining consumer individual profiles, tariff designs and improving load forecasting. A new age in power systems structure such as smart grids determined the wide investigations of applications and benefits of clustering methods for smart meter data analysis. This paper presents an improvement of energy consumption forecasting methods by performing cluster analysis. For clustering the centroid based method K-means with K-means centroids was used. Various forecasting methods were applied to find the most effective ones with clustering procedure application. Used smart meter data have an hourly measurements of energy consumption time series of russian central region customers. In our computer modeling investigations we have obtained significant improvement due to carrying out the cluster analysis for consumption forecasting.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The development of intelligent networks in manufacturing, finance, and services creates new opportunities for the development and application of effective methods of machine learning and data analysis. The installation of smart meters is usually considered as the starting point in the implementation of smart grids. Smart meters employ advanced metering, control, data storage, and communication technologies to offer a range of functions. The deployment of smart meters provides benefits to the end consumers (domestic and non-domestic), energy suppliers, and network operators by providing near real-time consumption information to the consumers that will help them to manage their energy use, save money, and reduce greenhouse gas emissions. At the same time, smart meters will benefit distribution network planning and operation, and demand management. In this regard, the smart metering data will enable more accurate demand forecasts, allow improved asset utilisation in distribution networks, locate outages and shorten supply restoration times, and reduce the operational and maintenance costs of the networks. Smart technologies for collecting, recording and monitoring data on energy consumption create a huge amount of data of different nature for the energy suppliers and network operators to exploit. The data volume will vary according to the number of installed smart meters, the number of received smart meter messages, the message size (in bytes per message), and the frequency of recording the measurements – e.g., every 15 or 30 min. These data can be used for optimal network management, improving the accuracy of the forecasting load, detection of abnormal effects of power supply (peak load conditions), the formation of flexible price tariffs for different groups of consumers [1,2,3].
One of the most important issues in this area is to predict the power load consumption as accurately as possible. Consumption, as a rule, have a rather complicated stochastic structure, which are difficult for modeling and prediction for individual consumers. Therefore, the consumption data is aggregated (summed). Statistical, engineering and time-series methods [4,5,6] have been reported to analyse and extract the required information from the load profiles of customers. Additionally, statistical time-series and artificial intelligence (AI) methods have been applied to estimate and forecast the load in power networks. However, these methods can be costly and complex to implement and validate when large volumes of consumption measurements become available. Nevertheless, when different methods of aggregation are applied to the group of consumers having similar statistical characteristics of time series of power consumption, it is possible to count on considerable progress in the solution of objectives. One efficient approach to extract the necessary information from smart meter measurements is the employment of data mining techniques. Cluster analysis is one type of these techniques [7, 8]. Clustering is the grouping of load profiles into a number of clusters such that profiles within the same cluster are similar to each other.
The main goal of this paper is to investigate the practical issues and possible benefits of combining clustering procedures with forecasting methods in order to improve their accuracy. We have used several known approaches to present time series and different forecasting methods such as Holt-Winters, ARIMA model, Support Vector Regression and some others. The results of cluster analysis can also be beneficial for finding the patterns in data [3, 4] for classification of new customers. The paper is organized as follows: Sect. 2 contains some models for energy time series presentations that we used for clustering and forecasting. In Sect. 3 we described our clustering algorithm for classification and forecasting. Section 4 contains the review of our computer experiments and Sect. 5 presents conclusions.
2 Modeling of the Energy Consumption Time Series
The problems of application of clustering methods to the time series of electricity consumption are mainly in high dimension and high noise level of the data, which can be solved as mentioned above with the use of machine learning methods. Papers dealing with aggregating of consumers usually use clustering primarily for mainly one purpose: immediate forecasts of time series [6, 7]. These works, however, put a little focus on application of forecasting methods and methods for time series data mining. Shahzadeh et al. [6] explore the clustering of consumers for feature extraction from time series and its impact on the accuracy of forecast of energy consumption. K-means was used for clustering and neural network for forecasting. They used three different representation of time series: estimated regression coefficients, extractions of the averages of electricity consumption and the whole time series. The best results were achieved by the clustering with regression coefficients, which showed significant improvements in the accuracy of forecast with the help of clustering. Rodrigues [7] presented a hierarchical clustering method with optimization criterion of forecast error of ARIMA model. This method was compared against simple aggregation consumption forecast. Experiments showed that the positive impact of consumers’ aggregation on forecast accuracy of certain methods (linear regression, multi-layer perceptron and support vector regression) depends not only on the number of clusters, but also on the size of the customer base. To evaluate this hypothesis, Monte-Carlo grouping of consumers and also forecasting methods Random Walk and Holt-Winters exponential smoothing were used [12]. McLoughlin et al. [4] presented dynamic clustering of consumers. With clustering approach, a large amount of mean daily profiles was created and then deeply analyzed. To link domestic load profiles with household characteristics, SOM clustering and multi-nominal logistic regression were used to perform analysis of dwelling, occupant and appliance characteristics [10].
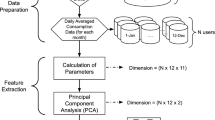
In this paper we have focused our attention on the influence of clustering of consumers on accuracy of different forecasting methods and on the representations of time series, which are suitable for seasonal times series of electricity load. Based on investigated approaches we made the comparative analysis of two approaches of classification of consumers: with clustering application and without it (aggregation). Our methodology has four steps:
(1) to normalize the data and calculate the energy consumption model for each consumer. In the future, the study uses four different models based on the representation of time series, which serve as inputs to the clustering method.
(2) The second stage consists of calculating the optimal number of clusters for the given time series representation and the selected data learning window.
(3) The third stage is clustering and aggregation of consumption within clusters. For each cluster, the forecast model is trained and the forecast for the next period is run.
(4) The forecasts are aggregated and compared with the real consumption data. Next, we construct a forecast for day-ahead for the received representations of the clusters using the above-described prediction methods.
The process (1)–(4) is iteratively repeated as measurements from a next day become available. The training window of data is changed so that the new day is added to the training window and the oldest one is removed. The standard approach without clustering is just a summation of all measurements together.
2.1 Energy Consumption Time Series Modeling
The time series X is an ordered sequence of n real variables
The main reason for time series presentation using is a significant decrease in the dimension of the analyzed data, respectively, reducing the required memory and the computational complexity. In our approach next four model-based representation methods were chosen: (a) Robust Linear Model (RLM), (b) Generalized Additive Model (GAM), (c) Holt-Winters Exponential Smoothing, and (d) Median Filter.
The first presentation is based on a robust linear model (RLM). Like other regression methods, it is aimed at modeling the dependent variable by independent variables
where \(i=1,..,n,\) \(u_i\) - is energy consumption, \(\beta _1,...,\beta _s\) are the regression coefficients. Let’s define the frequency of one season as s. \(u_{i1},..,u_{is}\) are independent binary variables, \(u_{ij}\), \(j=1,2,...,s,\) variable \(\varepsilon _i\) is a white noise with the normal distribution \(N\left( 0,\sigma ^2\right) \). Obtaining an estimate of the vector \(\beta _1,...,\beta _s\) is calculated by using reiterated weighted least squares (IRLS). Extensions for RLM are generalized additive models (GAM) [9, 11].
where \(f_1\) is B-spline [17], \(u_1=\left( 1,2,...,s,1,...,s,...\right) \) is a vector \(\left( day_j\right) _{j=1}^d\), \(day=\left( 1,...,s\right) ,\) d is a number of days. Model parameters (3) can be evaluated by the weighted least squares (IRLS) iterative method [5].
Holt-Winters exponential smoothing (HW) was used as another method of representations based on the model. It is a method that is used mainly to forecast the seasonal time series and to smoothing time series from the noise [12]. Components of this model (with trend and seasonality) are:
where L is smoothing component, b is trend component, r is seasonal component, \(\alpha ,\beta ,\gamma \) are smoothing factors. Smoothing factors have been selected automatically, where the factors were optimized according to the average square error of the one-stepwise forecast. As HW representation (4)–(6) we have taken seasonal coefficients \((r_{n-s+1},...,r_n)\). Last presentation for time series model is a median filter as following
where \(k=(1,...,s),\) and \(d-\) time series dimension. An example of application of presentation (7) is shown on Fig. 1.

Weekly median filter for energy consumption time series with absolute deviation.
2.2 Applications of Cluster Analysis for Smart Grids
As a common thing, utilities usually divided their customers in industrial, commercial and residential sectors based on some fixed information like voltage level, nominal demand etc. Based on this approach a set of customer class load profiles were defined and each user was assigned to one of these classes. However, this is still a fundamental problem, and the procedures for dealing with customers segmentation need to be revised greatly. Firstly, the consumption data of customers, those who have installed smart meters, are now accessible. Secondly, the time period of measurement is not restricted and usage information for some successive years is available. These two factors affect the dimensionality of data which is not comparable with previously used data sets. Finally, as the data is continuously recorded, it can have possible applications for real-time operation and management of power systems. All of these factors emphasize the use of new clustering methods for electricity consumption characterization. For classification consumers into groups (clusters), we used the centroid based clustering method K-means [9]. K-means is a method based on the mutual distances of objects, measured by Euclidean distance. The advantage over conventional K-means is based on carefully seeding of initial centroids, which improves the speed and accuracy of clustering. Before applying the K-means algorithm the optimal number of clusters k must be determined. For each representation of a data set, we have determined the optimal number of clusters to k using the internal validation rate Davies-Bouldin index [10]. The optimal number of clusters as been shown in our computer experiments ranged from 7 to 18. The results of this algorithm applied to energy consumption data [16] may be seen on Fig. 2. Computer code in R programming language, realized K-means algorithm, in Sect. 5 is reported.
Our algorithm works as follows. Let \(d\left( x\right) \) denote the shortest Euclidean distance from a data point x to the closest centroid we have already chosen.
Step1. Choose an initial centroid \(K_1\) randomly with uniform probability from set X.
Step 2. Choose the next center \(K_i={\widehat{x}}\) \(\in T\), selecting with some probability \(P=\frac{d\left( {\widehat{x}}\right) ^2}{\sum _{x\in X}d\left( x\right) ^2}\).
Step 3. Repeat previous step until we have chosen all K centers. Each object from data set is connected with a centroid that is closest to it. New centroids are then calculated.
Step 4. Last two steps are repeated until classification to clusters no longer changes. Euclidian distance measure is one of the best measures for comparison of time series of electricity load because of its stronger dependence on time. In each iteration of a batch processing, we have automatically determined the optimal number of clusters to K using the internal validation rate Davies-Bouldin index.
Computer code in R programming language, realized Euclidian function distance, is reported in Sect. 5 of this paper.
2.3 Energy Consumption Time Series Forecasting
We used mostly effective methods to improve forecasting energy consumption time series:
-
(1)
Support Vector Regression (SVR), a method that works like simple linear regression but it tries to find a real regression function that best approximates output vector. SVR technique relies on kernel functions to construct the model. The commonly used kernel functions are: (a) Linear, (b) Polynomial, (c) Sigmoid and (d) Radial Basis. The selection of kernel function is a tricky and requires optimization techniques for the best selection. In the constructed SVR model, we used automated kernel selection. In our computer experiments the best forecasting results were shown by Radius Basis Function (RBF) kernel [8]
$$\begin{aligned} K\left( x_i,x_j\right) =exp\left( -\frac{\left( x_i-x_j\right) ^2}{2\sigma ^2}\right) , \end{aligned}$$(8)where \(x_i,\;x_j\) are energy consumption time series, \(\sigma ^2\) is variance.
-
(2)
Seasonal decomposition of time series based on loses regression (STL) is a method, which decomposes seasonal time series into three parts: trend, seasonal component and remainder (noise) [11]. The seasonal component is found by loess (local regression) smoothing of the seasonal series, whereby smoothing can be effectively replaced by taking the mean. The seasonal values are removed, and the remainder is smoothed to find the trend. The overall level is removed from the seasonal component and added to the trend component. For the final three time series any of the forecast methods is used separately, in our case either Holt-Winters exponential smoothing or ARIMA model.
-
(3)
Random Forest (RF). First the Random Forests concept was proposed by Ho [4]. The method constructs the large number of decision trees at training time. Its output is the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees.
-
(4)
Gradient Boosting Machine (GBM) is an efficient and scalable implementation of gradient boosting framework by Friedman [4]. The principle approach is to combine iteratively several simple models, called “weak learners”, to obtain a “strong learner” with improved prediction accuracy. Paper [6] introduced a statistical point of view of boosting, connecting the boosting algorithm to the concepts of loss functions. It could extended the boosting to the regression by introducing the gradient boosting machines method (GBM). The GBM method can be seen as a numerical optimization algorithm that aims at finding an additive model that minimizes the loss function. Thus, the GBM algorithm iteratively adds at each step a new decision tree (i.e., “weak learner”) that best reduces the loss function. More precisely, in regression, the algorithm starts by initializing the model by a first guess, which is usually a decision tree that maximally reduces the loss function (which is for regression the mean squared error), then at each step a new decision tree is fitted to the current residual and added to the previous model to update the residual. The algorithm continues to iterate until a maximum number of iterations, provided by the user, is reached. This process is so-called stage wise, meaning that at each new step the decision trees added to the model at prior steps are not modified. By fitting decision trees to the residuals the model is improved in the regions where it does not perform well. We consider 4 seasonal variables to RF and GBM models for half-hourly and weekly periods in sinus and cosinus functions form \(\frac{\left( \sin \left( 2\pi {\displaystyle \frac{day}{s}}\right) +1\right) }{2}\) and \(\frac{\left( \cos \left( 2\pi {\displaystyle \frac{day}{s}}\right) +1\right) }{2}\) respectively, s is a period. For weekly periods week is a vector \(\left( s\;times\;week_j\right) _{j=1}^d\), \(\frac{\left( \sin \left( 2\pi {\displaystyle \frac{week}{7}}\right) +1\right) }{2}\) and \(\frac{\left( \cos \left( 2\pi {\displaystyle \frac{week}{7}}\right) +1\right) }{2}\), \(week_j=\left( 1,2,...,7,1,..\right) .\)
-
(5)
Bagging (Bagg) predictors generate multiple versions of predictors and use them for determination an aggregated predictor. The aggregation is an average of all predictors. The bagging method gives substantial gains in accuracy, but the vital element is the instability of the prediction method. In the case that perturbing the learning set has significant influence on the constructed predictor, the bagging can improve accuracy.
-
(6)
Regression Trees (R-Tree) are regression methods that consist of partitioning the input parameters space into distinct and non-overlapping regions following a set of if-then rules. The splitting rules identify regions that have the most homogeneous response to the predictor, and within each region a simple model, such as a constant, is fitted. The use of decision trees as a regression technique has several advantages, one of which is that the splitting rules represent an intuitive and very interpretable way to visualize the results. In addition, by their design, they can handle simultaneously numerical and categorical input parameters. They are robust to outliers and can efficiently deal with missing data in the input parameters space. The decision tree’s hierarchical structure automatically models the interaction between the input parameters and naturally performs variable selection, e.g., if an input parameter is never used during the splitting procedure, then the prediction does not depend on this input parameter. Finally, decision trees algorithms are simple to implement and computationally efficient with a large amount of data [18].
The accuracy of the forecast of electricity consumption was measured by MAPE (Mean Absolute Percentage Error). MAPE is defined as follows:
where \(x_t\) is actual consumption, \(\overline{x}\) - load forecast, n - length of time series.
3 Computer Experiments for Customer Energy Consumption
We performed the computer experiments to evaluate the profit of using clustering procedures on four time series representation methods for one day ahead forecast. Our testing data set contains measurements from customers of Central Russia Region [16]. Table 1 shows average daily MAPE forecast errors of 6 forecasting methods. Each forecasting method was evaluated on 5 datasets; 4 datasets are clustered with different representation methods (Median, HW, GAM, RLM) and aggregated electric load consumption (Sum). The following conclusions can be derived from Table 1. Optimized clustering of consumers significantly improves accuracy of forecast with forecasting methods SVR, Bagging, GBM. Despite this, clustering with STL+ARIMA, RF, R-Tree does not really improves accuracy of forecast. Three robust representation methods of time series Median, GAM and RLM performed best among all representations, while HW was the worst in most of the cases, because robust representations are stable and less fluctuate. The best result of all cases achieved by GBM with optimized clustering using GAM representation which mean daily MAPE error under 3,17% [14].

Results of clustering of energy consumers: clusters and centroids.
4 Conclusions
Improving the accuracy of forecasts of electricity consumption is a key area in the development of intelligent energy grids. To implement this problem, we used machine learning methods, namely cluster analysis. The main purpose of this paper is to show that the application of the clustering procedure of consumers to the representation of time series of energy consumption can improve the accuracy of their forecasts for energy consumption. Robust linear model, generalized additive model, exponential smoothing and median linear filter were used as such representations. In this paper we applied a modified K-means algorithm to more accurately select centroids and the Davis-Boldin index to evaluate clustering results. Numerical experiments have shown that the methods of forecasting such as \(STL+ARIMA, SVR, RF, Bagging\) considered in the paper are more effective for improving forecast accuracy if used together with clustering. Prediction methods performed the best reliable representations of RLM, GAM, and median filter. The most accurate prediction result is obtained by GBM with the GAM presentation time series. Among the perspective applications of clustering for smart grids are benefits for tariff design, compilation smart demand response programs, improvement of load forecast, classifying new or non-metered customers and other tasks.
5 Program Code
R code for K-means algorithm

R code for Euclidian distance between cluster centroids

R code for modeling example of application K-means algorithm

R code for GAM time series model presentation

References
Haben, S., Singleton, C., Grindrod, P.: Analysis and clustering of residential customers energy behavioral demand using smart meter data. IEEE Trans. Smart Grid 99, 1–9 (2015)
Chicco, G., Napoli, R., Piglione, F.: Comparisons among clustering techniques for electricity customer classification. IEEE Trans. Power Sys. 21, 933–940 (2013)
Gelling, C.W.: The Smart Grid: Enabling Energy Efficiency and Demand Response. The Fairmont Press Inc. (2009)
McLoughlin, F., Duffy, A., Conlon, M.: A clustering approach to domestic electricity load profile characterisation using smart metering data. Appl. Energy 141, 190–199 (2015)
Aghabozorgi, S., Shirkhorshidi, A.: Time-series clustering: a decade review. Inf. Sys. 53, 16–38 (2015)
Shahzadeh A., Khosravi A., Nahavandi S.: Improving load forecast accuracy by clustering consumers using smart meter data. In: International Joint Conference on Neural Networks (IJCNN), pp. 1–7 (2015)
Rodrigues, P., Gama, J., Pedroso, J.: Hierarchical clustering of time-series data streams. IEEE Trans. Knowl. Data Eng. 20(5), 615–627 (2008)
Hsu, D.: Comparison of integrated clustering methods for accurate and stable prediction of building energy consumption data. Appl. Energy 160, 153–163 (2015)
Andersen A.: Modern Methods for Robust Regression. SAGE Publications, Inc. (2008)
Wijaya T.K., Vasirani M., et al.: Cluster-based aggregate forecasting for residential electricity demand using smart meter data. In: 2015 IEEE International Conference on Big Data. IEEE Press, pp. 879–887 (2001)
Wood, S.: Generalized Additive Models: An Introduction with R. Chapman and Hall/CRC (2006)
Hyndman, R.J., Koehler, A.B., Snyder, R.D., Grose, S.: A state space framework for automatic forecasting using exponential smoothing methods. Int. J. Forecast. 18(3), 439–454 (2002)
Arthur D., Vassilvitskii S.: K-means++: the advantages of careful seeding. In: SODA 07 Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, pp. 1027–1035 (2007)
Hong, W.C.: Intelligent Energy Demand Forecasting. Springer, London (2013). https://doi.org/10.1007/978-1-4471-4968-2
Taylor, J.W.: Short-term electricity demand forecasting using double seasonal exponential smoothing. J. Oper. Res. Soc. 54, 799–805 (2003)
Lyubin, P., Shchetinin, E.: Fast two-dimensional smoothing with discrete cosine transform. In: Vishnevskiy, V.M., Samouylov, K.E., Kozyrev, D.V. (eds.) DCCN 2016. CCIS, vol. 678, pp. 646–656. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-51917-3_55
Liaw A.: Breiman and Cutler’s Random Forests for Classification and Regression. CRAN (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Shchetinin, E.Y. (2018). Cluster-Based Energy Consumption Forecasting in Smart Grids. In: Vishnevskiy, V., Kozyrev, D. (eds) Distributed Computer and Communication Networks. DCCN 2018. Communications in Computer and Information Science, vol 919. Springer, Cham. https://doi.org/10.1007/978-3-319-99447-5_38
Download citation
DOI: https://doi.org/10.1007/978-3-319-99447-5_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-99446-8
Online ISBN: 978-3-319-99447-5
eBook Packages: Computer ScienceComputer Science (R0)