
Abstract
In this paper, we present an approach to forecasting the number of paintings that will be sold daily by Vivre Deco S.A. Vivre is an online retailer for Home and Lifestyle in Central and Eastern Europe. One of its concerns is related to the stocks that it needs to make at its own warehouse (considering its limited available space) to ensure a good product flow that would maximize both the company profit and the users’ satisfaction. Since stocks are directly connected to sales, the purpose is to predict the amount of sales from each category of products, given the selling history of these products. Thus, we have chosen a category of products (paintings) and used ARIMA for obtaining the predictions. We present different considerations regarding how we chose the model, along with the solver and the optimization method for fitting ARIMA. We also discuss the influence of the differencing on the obtained results, along with information about the runtime of different models.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Problem Description
Vivre is a leading online retailer for Home and Lifestyle in Central and Eastern Europe, currently activating in 8 countries from this area. They are offering their customers both limited-time discounts (“flash sales”) called “campaigns” in which are grouped products from similar fields (such as “entrance and bath mats”, “sun glasses” or “LEGO accessories”) and long-term available products, which are grouped in the “product catalog”.
Since 2012, when it was launched, Vivre accumulated an important quantity of historical data regarding sales, providers and customers, information that could be used to improve the company’s activity.
The problem described in this paper derived as an attempt to forecast the daily quantity from each product to be sold by Vivre. These numbers could be very valuable for the company, as they would help maintain in the warehouse only the right stock from each product, under the constraints imposed by the restricted storage area. Another benefit would be that of allowing faster products delivery towards clients, (as the products are readily available in the warehouse and thus one does not have to also wait for their arrival from the providers,) which can be translated in increasing the customer satisfaction and a better positioning of the brand on the market. Finally, good estimation of the daily sold quantities of each product could help improve the flow of the incoming and outcoming deliveries for the products, thus optimizing the usage of the warehouse and eliminating the time lost when trailers are available but there is no storage in the warehouse or there are not enough products to be shipped. This may finally translate in larger profit for the company.
However, even though these numbers are extremely important, it is not trivial to derive them even when enough historical data is available, due to several factors. First, there are over 1 million different product ids in the database, making the task of predicting the daily sales for all of them time and resource consuming, especially considering this a recurrent (daily) task. Secondly, at any moment there are not more than about 50–60.000 products available on the website and thus, predicting the sale of any of the other products would be meaningless, as they cannot be seen by the user (and therefore cannot be bought by them). Thirdly, among all the products, there are numerous that are/were available on the website only for a very limited amount of time (during a campaign, for less than 30 days for a history spreading for more than 6 years), thus not having enough information for predicting their sales. Fourthly, there are products that may be replaced one for the other (e.g. products having different colors or sizes, but serving to the same purpose) and thus their sales are tightly connected. Finally, the sale of a product is highly influenced by the seasonality, marketing budget, existing campaigns on the website, providers of the goods that are available for buying and many other factors, some of them being logged in the system, while for others not having any information at all.
Considering all the above problems, a design decision has been made with the purpose to alleviate some of the issues: instead of trying to forecast the daily quantity to be sold for each product from the database, first a grouping over the similar products was made and then the forecast of the daily quantity to be sold was generated for each such group (called “generic name”). This decision was intended to solve the first four issues, as it seriously reduced the number of (group of) products for which predictions should be provided (from over a million to around 27,000). Moreover, it solved the problem of products not being available on the website, since all the obtained groups had at least one representative on the site. Finally, since similar products were grouped in the same generic name, the problem with rarely available products and with the replaceable products was also solved as they were simply part of the same larger distribution. Another effect of this decision was to diminish the scarcity and variability in the data, which might lead in the end to better predictions. On the other hand, there was also a drawback since, by joining the information related to multiple products in the same generic name, after prediction, the obtained data should be disentangled to obtain the quantities for the initial products.
Thus, the task described in this paper is to forecast the daily quantity to be sold for each generic name that was identified starting from the product ids from the database. Considering the historical data that was aggregated for each such generic name, we used time series analysis (that is described in the next section) for obtaining the predictions. Section 3 presents a use case scenario for one of the generic names that was used, along with the problems and decisions that were made. The obtained results are presented in Sect. 4, while the paper concludes with our observation regarding the used methodology and with some proposed directions for extending this research.
2 Time Series Analysis and Some of Its Applications
A time series is “a set of well-defined data items collected at successive points at uniform time intervals” [1]. Time series analysis represents a class of methods for processing these items to determine the main patterns of the dataset, which then may help predicting future values based on the identified patterns. One of the simplest method from this class is called autoregressive (AR) model and “specifies that the output variable depends linearly on its own previous values” [2]. The notation AR(p) – autoregressive model of order p – means that the current value depends on the previous p values of the time series. The expression of AR(p) is given by (1), where γ1, γ2…, γp are the parameters of the model, c is a constant, and ε1, ε2, …, εt are white noise error terms.
In 1951, the AR model was extended by Whitle [3] into the autoregressive-moving-average (ARMA) model, which had two parts: an autoregressive (AR) part, consisting on the regression of the variable on its own past values, and a moving average (MA) part, modelling the error term as a linear combination of the current error term, along with some of the previous ones. The new model, depicted as ARMA(p, q) represents a model with p autoregressive terms and q moving-average terms, given by (2), where γ1, γ2, …, γp are the AR model parameters, θ1, θ2, …, θq are the MA model parameters, c is a constant, and ε1, ε2, …, εt are white noise error terms:
This new model was further improved by Box and Jenkins [4] to obtain the Autoregressive Integrated Moving Average (ARIMA) model. The difference between ARMA and ARIMA is that the latter’s first step is to convert a non-stationary data to a stationary one by replacing the actual data values with the difference between these values and previous ones (process called “differencing”, that may be performed multiple times). The ARIMA model has three parameters ARIMA(p, d, q), where p is the autoregressive order, d is the degree of differencing (the number of times the data have had past values subtracted) and q is the order of the moving-average model. Its formula is the same as in (2), with the only difference that instead of having the actual values Xi, we work with the difference between Xi and past values. One observation that should be made is that ARIMA(p, 0, q) represents in fact the ARMA(p, q) model, while ARIMA(p, 0, 0) represents the AR(p) model.
Being given the 3 parameters (p, d, q) and the actual data X, the ARIMA model uses the Box-Jenkins method [4] to find the best fit of a time-series model to past values of a time series. Later on, the parameters identified during fitting may be used to generate predictions on the future behavior of the time series. However, choosing the best values of p and q is not easy. Several options were proposed by the researchers. One option was proposed by Brockwell and Davis [5] who state that “our prime criterion for model selection will be the AICc”, which stands for the Akaike information criterion with correction [6]. Another option was given by Hyndman & Athanasopoulos [7] who suggest how to automatically determine both the values of p and q using ACF (autocorrelations function) and PACF (partial autocorrelations function) plots.
Since their inception, the ARIMA models were used to make predictions in various fields: from estimating the monthly catches of pilchard from Greek waters [8], to forecasting the Irish inflation [9], to predicting next-day electricity prices in Spain and Californian markets [10], to estimating the incidence of hemorrhagic fever with renal Syndrome (HFRS) in China during 1986–2009 [11], to foretelling the sugarcane production in India [12], and finally to prognosticate the energy consumption and greenhouse emission of a pig iron manufacturing organization [13]. However, many of the ARIMA uses were in the field of stock forecasting [14, 15], where they were trying to find the best parameters for estimating the stock prices of a particular stock.
In the following section, we will present a case study of applying different ARIMA models for predicting not the stock prices, but the quantities to be sold from different groups of products by Vivre. We could have tried to estimate the amount of sales, but since the product prices vary a lot in time, we decided to have a more stable estimation and opted out for the product quantities.
3 Case Study and Obtained Results
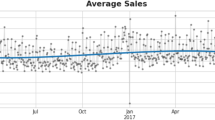
In this section, we will present the experiments that we undertook using the above-mentioned models with the purpose to predict the daily quantity to be sold for one of the generic names that were identified starting from the product ids from the database. Thus, we have chosen the “painting” generic name, having the distribution of daily quantities sold presented in Fig. 1. We chose this generic name because of two reasons: there was enough data available to enable predictions (only few days had zero-counts) and the distribution has some seasonality, but in the same time features some spikes that could be interpreted as outliers. Given this distribution, our task was to use the historical data from January 1st, 2014 to December 31st, 2017 (1461 training samples) for training the model, and the rest of the data (from January 1st to May 7th, 2018 – 127 samples) for testing the quality of the forecasting. The quality of the trained models was tested using 3 different values: RMS (root mean square error) for both the training and testing sets and MAPE (mean absolute percentage error).

The distribution of the daily quantity sold for the generic name “painting” by Vivre Deco. The values from Jan 2014 to Jan 2018 were used for training, while the ones from Jan 2018 to May 2018 were used for testing.
Therefore, we started building several ARIMA models, with different parameters, and tested the forecasting accuracy on each of them. To start with, we used AR with different orders (p) to generate some initial predictions. The values of p that were used in these tests were influenced by some basic assumptions regarding the data: we assumed that the current data might be influenced by the value from the previous day (AR(1)), by the ones from the previous week (AR(7)), month (AR(31)), or year (AR(365)). The next step was to use various differencing to see if the data seasonality improves the results or not. However, since the results of AR(365) were very poor, we stopped using it for tests. Thus, we tested monthly (differencing of 31), weekly (differencing of 7) and daily seasonality (differencing of 1) combined with the remaining AR orders. We should mention that in all our experiments, by differencing of d, we understand single differencing (not stacked differencing), with lags = d (instead of Xi − Xi−1, we used Xi − Xi−d). The obtained results are reported in Table 1.
Afterwards, we moved on to ARMA and tested models with different p (2–7) and q (1, 2, 3). To estimate the best values of p and q, we used the Hyndman & Athanasopoulos [7] methodology based on ACF and PACF (see Table 2). Since ARMA could use during training multiple solvers (lbfgs – limited memory Broyden-Fletcher-Goldfarb-Shanno; newton – Newton-Raphson; nn – Nelder-Mead; cg – conjugate gradient; ncg – non-conjugate gradient; and powell) along with 3 different methods (css – maximize the conditional sum of squares likelihood; mle – maximize the exact likelihood via the Kalman Filter; and css-mle – maximize the conditional sum of squares likelihood and then these values are used as starting values for the computation of the exact likelihood via the Kalman filter) for determining the model parameters, we used a grid search to find the best combination of the solver and the method for fitting the most promising ARMA model (ARMA(7, 0, 2)). The results are reported in Table 3.
Finally, we used the Augmented Dickey–Fuller test to verify if our time series was stationary, to find out if differencing could improve the results. Even though the test showed that the series was stationary, meaning that integration will not help, we still verified a couple of integrated models (with d = 1) to see the seasonality influence on the reference values that were used. The results are presented in Table 4. In most of these tests the differencing was made explicitly before running ARIMA, and thus the value of d = 0. However, we also made a test on a random combination of p and q (5, 1) to see if the implicit integration of ARIMA(5, 1, 1) would yield different results. These are reported in Table 2.
For each of the above models, we used the ARIMA method from the statsmodels.tsa.arima_model.ARIMA package from python. This package offered two types of predictions, and we used both in our experiments: forecast, that could predict the values for each day from the testing set in a single run based on the parameters that were obtained after training; and predict, that was predicting only the next value in the time series and was run iteratively for each day from the testing set, interleaved with re-fitting the model using the true value that was observed for the previous day. The iterative method always yielded better results than the 1-step forecasting, as it used more information. The results of the best model (ARIMA(7, 0, 2)) using powell solver and css-mle optimizing method are presented in Fig. 2.

The best results obtained by ARIMA(7, 0, 2). The triangles represent the original values, the circles depict the 1-step forecasting and the ‘x’-s show the iterative predictions.
Since some of the trained models did not converge (such as ARIMA(5, 0, 2)), we also report this fact, along with the phase when they failed to converge (during training or iterative testing). If the model did not converge during the iterative testing, it was unable to generate the predictions for all the 127 samples from the testing set and thus we also report the number of generated predictions.
Finally, as the computation that is done for this generic name (“painting”) should be done for all the generic names, it means that the whole process should be repeated a couple thousand times. Thus, another important element is the time needed to obtain the predictions and therefore, for the most promising runs, this information is also presented.
Besides the ARIMA models, we also tested the FBProphet [16], which is a tool “for producing high quality forecasts for time series data that has multiple seasonality with linear or non-linear growth”. Prophet may be run with or without daily seasonality. Both methods generated very similar predictions (RMS 1 step 33.18/33.21; MAPE 1 step 37.85/37.77; RMS iterative 32.26/32.25; MAPE iterative 41.29/41.35; runtime 1668 s/1380 s), which were poorer than the ones obtained using ARIMA(7, 0, 2). We also tried to model the time series spikes using a different distribution with the help of the holiday option from FBProphet, but the results didn’t improve much (RMS 1 step 33.04; MAPE 1 step 37.43), remaining worse than the ones of ARIMA.
4 Discussion and Conclusion
The AR results showed that the best model was the one involving the previous 7 days. They also revealed that, except for AR(1) with daily seasonality, including differencing according to different seasonality worsen the results.
The table presenting the ARMA scores shows that the methodology based on ACF and PACF does not work in our case, the model with p and q generated by the ACF and PACF being the only one that did not converge during training (ARIMA(5, 0, 2)). Moreover, all the models with p and q chosen this way did not converge during testing. Although ARIMA(5, 0, 2) seems to have the best results (MAPE 24.22), it should be noticed that the model managed to provide only 27 predictions out of 127 required. The best model was ARIMA(7, 0, 2) which converged during both training and testing.
The investigation of different solvers and optimization methods showed that they have a very small influence on the obtained results. However, since some of the methods did not converge, for further experiments was chosen the combination leading to the second-best result (powell solver, css-mle method). This combination also had a reduced running time, which counts when the process has to be repeated 27,000 times.
Finally, choosing different lags only worsen the results, showing that the best solution is to work directly with the data, without differencing.
Even though the obtained results are promising, some of them being even better than FBProphet’s ones, we believe that there are still ways to improve them. They were obtained using only historical information about the daily sold quantities of a single generic names. Still, similar information is available for the other generic names, and could be used to improve the predictions, as the sale of some products also influence the sale of others. However, to use this additional information, the ARIMA model must be changed for one that allows multi-variate dependencies. If such a change happens, other additional information may also be used: marketing budget, sales events, number and type of products on sale in each sale event, number of page views, products availability, etc. In the future, we intend to advance the work presented here by inspecting several such models (logistic regression, random forest, neural nets and deep learning) and including some of the supplementary information. Another possibility to improve the results is by creating an ensemble from different models, built using the above-mentioned techniques, and thus to benefit from the fact that they generate the predictions in different ways, which might help eliminating some of the prediction errors.
References
Mondal, P., Shit, L., Goswami, S.: Study of effectiveness of time series modeling (ARIMA) in forecasting stock prices. Int. J. Comput. Sci. Eng. Appl. 4(2), 13 (2014)
Parthiban, K.T., Sekar, I., Umarani, R., Kanna, S.U., Durairasu, P., Rajendran, P.: Industrial Agroforestry Perspectives and Prospectives. Scientific Publishers, Jodhpur (2014)
Whitle, P.: Hypothesis Testing in Time Series Analysis, vol. 4. Almqvist & Wiksells, Uppsala (1951)
Box, G., Jenkins, G.: Time Series Analysis: Forecasting and Control. Holden-Day, San Francisco (1970)
Brockwell, P.J., Davis, R.A.: Time Series: Theory and Methods, p. 273. Springer, New York (1991). https://doi.org/10.1007/978-1-4419-0320-4
Akaike, H.: A new look at the statistical model identification. IEEE Trans. Autom. Control 19(6), 716–723 (1974). https://doi.org/10.1109/tac.1974.1100705
Hyndman, R.J., Athanasopoulos, G.: Forecasting: principles and practice, OTexts. https://www.otexts.org/fpp/8/5. Accessed 20 May 2018
Stergiou, K.I.: Modeling and forecasting the fishery for pilchard (Sardina pilchardus) in Greek waters using ARIMA time-series models. ICES J. Mar. Sci. 46(1), 16–23 (1989)
Meyler, A., Kenny, G., Quinn, T.: Forecasting Irish inflation using ARIMA models. Central Bank and Financial Services Authority of Ireland Technical Paper Series, vol. 1998, no. 3/RT/98, pp. 1–48, December 1998
Contreras, J., Espinola, R., Nogales, F.J., Conejo, A.J.: ARIMA models to predict nextday electricity prices. IEEE Trans. Power Syst. 18(3), 1014–1020 (2003)
Li, Q., Guo, N.N., Han, Z.Y., Zhang, Y.B., Qi, S.X., Xu, Y.G., Wei, Y.M., Han, X., Liu, Y.Y.: Application of an autoregressive integrated moving average model for predicting the incidence of hemorrhagic fever with renal syndrome. Am. J. Trop. Med. Hyg. 87(2), 364–370 (2012)
Kumar, M., Anand, M.: An application of time series ARIMA forecasting model for predicting sugarcane production in India. Stud. Bus. Econ. 9(1), 81–94 (2014)
Sen, P., Roy, M., Pal, P.: Application of ARIMA for forecasting energy consumption and GHG emission: a case study of an Indian pig iron manufacturing organization. Energy 116, 1031–1038 (2016)
Jarrett, J.E., Kyper, E.: ARIMA modeling with intervention to forecast and analyze chinese stock prices. Int. J. Eng. Bus. Manag. 3(3), 53–58 (2011)
Devi, B.U., Sundar, D., Alli, P.: An effective time series analysis for stock trend prediction using ARIMA model for nifty midcap-50. Int. J. Data Min. Knowl. Manag. Process 3(1), 65 (2013)
Taylor, S.J., Letham, B.: Forecasting at scale. PeerJ Preprints 5:e3190v2 (2017). https://doi.org/10.7287/peerj.preprints.3190v2
Acknowledgement
This work was partly supported through the GEX contract 20/25.09.2017 funded by the University Politehnica of Bucharest. We would also like to thank Vivre Deco for providing us the data that made this study possible.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Chiru, CG., Posea, VV. (2018). Time Series Analysis for Sales Prediction. In: Agre, G., van Genabith, J., Declerck, T. (eds) Artificial Intelligence: Methodology, Systems, and Applications. AIMSA 2018. Lecture Notes in Computer Science(), vol 11089. Springer, Cham. https://doi.org/10.1007/978-3-319-99344-7_15
Download citation
DOI: https://doi.org/10.1007/978-3-319-99344-7_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-99343-0
Online ISBN: 978-3-319-99344-7
eBook Packages: Computer ScienceComputer Science (R0)