
Abstract
In this contribution we consider the problem of active learning in the regression setting. That is, choosing an optimal sampling scheme for the regression problem simultaneously with that of model selection. We consider a batch type approach and an on-line approach adapting algorithms developed for the classification problem. Our main tools are concentration-type inequalities which allow us to bound the supreme of the deviations of the sampling scheme corrected by an appropriate weight function.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others
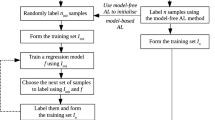

1 Introduction
Consider the following regression model
where the observation noise ε i are i.i.d. realizations of a random variable ε.
The problem we consider in this chapter is that of estimating the real-valued function x 0 based on t 1, …, t n and a subsample of size N < n of the observations y 1, …, y n measured at a well-chosen subsample of t 1, …, t n. This is relevant when, for example, obtaining the values of y i for each sample point t i is expensive or time consuming.
In this work we propose a statistical regularization approach for selecting a good subsample of the data in this regression setting by introducing a weighted sampling scheme (importance weighting) and an appropriate penalty function over the sampling choices.
We begin by establishing basic results for a fixed model, and then the problem of model selection and choosing a good sampling set simultaneously. This is what is known as active learning. We will develop two approaches. The first, a batch approach (see, for example, [7]), assumes the sampling set is chosen all at once, based on the minimization of a certain penalized loss function for the weighted sampling scheme. The second, an iterative approach [1], considers a two-step iterative method choosing alternatively the best new point to be sampled and the best model given the set of points.
The weighted sampling scheme requires each data point t
i to be sampled with a certain probability p(t
i) which is assumed to be inferiorly bounded by a certain constant p
min. This constant plays an important role because it controls the expected sample size  . However, it also is inversely proportional to the obtained error terms in the batch procedure (see Theorems 2.1 and 2.2), so choosing p
min too small will lead to poor bounds. Thus essentially, the batch procedure aims at selecting the best subset of data points (points with high probability) for the user chosen error bound. In the iterative procedure this problem is addressed by considering a sequence of sampling probabilities {p
j} where at each step j
p
j(t
i) is chosen to be as big as the greatest fluctuation for this data point over the hypothesis model for this step.
. However, it also is inversely proportional to the obtained error terms in the batch procedure (see Theorems 2.1 and 2.2), so choosing p
min too small will lead to poor bounds. Thus essentially, the batch procedure aims at selecting the best subset of data points (points with high probability) for the user chosen error bound. In the iterative procedure this problem is addressed by considering a sequence of sampling probabilities {p
j} where at each step j
p
j(t
i) is chosen to be as big as the greatest fluctuation for this data point over the hypothesis model for this step.
Following the active learning literature for the regression problem based on ordinary least squares (OLS) and weighted least squares learning (WLS) (see, for example [5,6,7] and the references therein) in this chapter we deal mainly with a linear regression setting and a quadratic loss function. This will be done by fixing a spanning family \(\{\phi _{j}\}_{j=1}^m\) and considering the best L 2 approximation x m of x 0 over this family. However, our approach is based on empirical error minimization techniques and can be readily extended to consider other models whenever bounds in probability are available for the error term.
Our results are based on concentration-type inequalities. Although variance minimization techniques for choosing appropriate subsamples are a well-known tool, giving adequate bounds in probability allowing for optimal non-asymptotic rates has been much less studied in the regression setting.
This is also true for the iterative procedure, where our results generalize previous ones obtained only in the classification setting for finite model spaces.
This chapter is organized as follows. In Sect. 2 we formulate the basic problem and study the batch approach for simultaneous sample and model selection. In Sect. 3 we study the iterative approach to sample selection and we discuss effective sample size reduction. All the proofs are available in the extended arXiv version [3].
2 Preliminaries
2.1 Basic Assumptions
We assume that the observations noise ε i in (1) are i.i.d. realizations of a random variable ε satisfying the moment condition
- MC:
-
Assume the r.v. ε satisfies \(\mathbb {E} \varepsilon =0,\) \(\mathbb {E} (|\varepsilon |{ }^r/\sigma ^r) \le r ! /2\) for all r > 2 and \(\mathbb {E} (\varepsilon ^2)=\sigma ^2\).
It is important to stress that the observations depend on a fixed design t 1, …, t n. For this, we need some notation concerning this design. For any vectors u, v r, we define the normalized norm and the normalized scalar product by
We drop the letter r from the notation when r = 1. With a slight abuse of notation, we will use the same notation when u, v, or r are functions by identifying each function (e.g. u) with the vector of values evaluates as t i (e.g. (u(t 1), …, u(t n)). We also require the empirical max-norm ∥u∥∞ =maxi|u i|.
2.2 Discretization Scheme
To start with we will consider the approximation of function x 0 over a finite-dimensional subspace S m. This subspace will be assumed to be linearly spanned by the set \(\{\phi _{j}\}_{j\in \mathcal {I}_m}\subset \{\phi _{j}\}_{j\ge 1} \), with \(\mathcal {I}_m\) a certain index set. Moreover, we shall, in general, be interested only in the vector \((x_0(t_i))_{i=1}^{n}\) which we shall typically denote just by x 0 stretching notation slightly.
We will assume the following properties hold:
- AB:
-
There exists an increasing sequence c m such that ∥ϕ j∥∞≤ c m for j ≤ m.
- AQ:
-
There exist a certain density q and a positive constant Q such that q(t i) ≤ Q, i = 1, …, n and
$$\displaystyle \begin{aligned}\int \phi_{l}(t)\phi_{k}(t)q(t)\, dt=\delta_{k,l},\end{aligned}$$where δ is the Kronecker delta.
We will also require the following discrete approximation assumption. Let G m = [ϕ j(t i)]i,j be the associated empirical n × m Gram matrix. We assume that \(G_{m}^{t}D_{q}G_{m}\) is invertible and moreover that \(\frac {1}{n}G_{m}^{t}D_{q}G_{m}\to I_{m}\), where D q is the diagonal matrix with entries q(t i), for i = 1, …, n and I m the identity matrix of size m. More precisely, we will assume
- AS:
-
There exist positive constants α and c, such that
$$\displaystyle \begin{aligned} \|I_m-\frac{1}{n}G_{m}^{t}D_{q}G_{m} \| \le c n^{-1-\alpha}.\end{aligned}$$
Given [AQ], assumption [AS] is a numerical approximation condition which is satisfied under certain regularity assumptions over q and {ϕ j}. To illustrate this condition we include the following example.
Example 2.1
Haar Wavelets: let ϕ(t) = 1 [0,1](t), ψ(t) = ϕ(2t) − ϕ(2t − 1) (see, for example, [4]), with q(t) = 1 [0,1](t). Define
For all m ≥ 0, S m denotes the linear space spanned by the functions \((\phi _{m,k}, k \in \mathbb {Z})\). In this case c m ≤ 2m∕2 and condition [AS] is satisfied for the discrete sample t i = i∕2m, i = 0, ⋯ , 2m−1.
We will denote by \(\hat {x}_{m} \in S_{m}\) the function that minimizes the weighted norm \(\|x-y\|{ }^2_{n,q}\) over S m evaluated at points t 1, …, t n. This is,
with \(R_{m}=G_{m}(G_{m}^{t}D_{q}G_{m})^{-1}G_{m}^{t}D_{q}\) the orthogonal projector over S m in the q-empirical norm ∥⋅∥n,q.
Let x m := R mx 0 be the projection of x 0 over S m in the q-empirical norm ∥⋅∥n,q, evaluated at points t 1, …, t n. Our goal is to choose a good subsample of the data collection such that the estimator of the unobservable vector x 0 in the finite-dimensional subspace S m, based on this subsample, attains near optimal error bounds. For this we must introduce the notion of subsampling scheme and importance weighted approaches (see [1, 7]), which we discuss below.
2.3 Sampling Scheme and Importance Weighting
In order to sample the data set we will introduce a sampling probability p(t) and a sequence of Bernoulli(p(t i)) random variables w i, i = 1, …, n independent of ε i with \(p(t_{i})>p_{\min }\). Let D w,q,p be the diagonal matrix with entries q(t i)w i∕p(t i). So that E (D w,q,p) = D q. Sometimes it will be more convenient to rewrite \(w_i={\mathbf {1}}_{u_i<p(t_i)}\) for {u i}i an i.i.d. sample of uniform random variables, independent of {ε i}i in order to stress the dependence on p of the random variables w i.
The next step is to construct an estimator for x m = R mx 0, based on the observation vector y and the sampling scheme p. For this, we consider a modified version of the estimator \(\hat {x}_m\).
Consider a uniform random sample u 1, …, u n and let \(w_i=w_i(p)={\mathbf {1}}_{u_i<p(t_i)}\) for a given p. For the given realization of u 1, …, u n, D w,q,p will be strictly positive for those w i = 1. Moreover, as follows from the singular value decomposition, the matrix \((G_{m}^{t}D_{w,q,p}G_{m})\) is invertible as long as at least one w i≠0. Set \(R_{m,p}=G_{m}(G_{m}^{t}D_{w,q,p}G_{m})^{-1}G_{m}^{t}D_{w,q,p}\). Then R m,p is the orthogonal projector over S m in the wq∕p-empirical norm ∥⋅∥n,wq∕p and it is well defined if at least one w i≠0. If all w i = 0, the projection is defined to be 0.
As the approximation of x m, we then consider (for a fixed m, p and (u 1, …, u n)) the random quantity

Note that
This estimator depends on y i only if w i = 1. However, as stated above, this depends on p(t i) for the given probability p.
2.4 Choosing a Good Sampling Scheme
To begin with, given n, we will assume that S m is fixed with dimension \(|\mathcal {I}_m|=d_m\) and d m = o(n). Remark that the bias \(\|x_{0}-x_{m}\|{ }^2_{n,q}\) is independent of p so for our purposes it is only necessary to study the approximation error \(\|x_{m}-\hat {x}_{m,p}\|{ }^2_{n,q}\) which does depend on how p is chosen.
Let \(\mathcal {P}:=\{p_{k}, k\ge 1 \}\) be a numerable collection of [0, 1] valued functions over {t 1, …, t n}. Set p k,min =minip k(t i). We will assume that \(\min _{k}p_{k,min}>p_{\min }\). The way the candidate probabilities are ordered is not a major issue, although in practice it is sometimes convenient to incorporate prior knowledge (certain sample points are known to be needed in the sample, for example) letting favourite candidates appear first in the order. To get the idea of what a sampling scheme may be, consider the following toy example:
Example 2.2
Let Π = {0.1, 0.4, 0.6, 0.9} and set \(\mathcal {P} = \{ p, p(t_i)=\pi _j \in \varPi , i=1,\ldots ,n \}\) which is a set of |Π|n functions. In this example, any given p will tend to favour the appearance of points t i with p(t i) = 0.9 and disfavour the appearance of those t i with p(t i) = 0.1.
A good sampling scheme p, based on the data, should be the minimizer over \(\mathcal {P}\) of the non-observable quantity \( \| x_m-\hat {x}_{m,p}\|{ }^2_{n,q}.\) In order to find a reasonable observable equivalent we start by writing,

Consider first the deterministic term E (R m,p) [x 0 − x m] in (3). We have the next lemma which is proved in the extended arXiv version.
Lemma 2.1
Under condition [AS] if m = o(n), then

From Lemma 2.1, we can derive that the deterministic term is small with respect to the other terms. Thus, it is sufficient for a good sampling scheme to take into account the second and third terms in (3). We propose to use an upper bound with high probability of those two last terms as in a penalized estimation scheme and to base our choice on this bound.
Define
with
The second square root appearing in the definition of \(\widetilde {\beta }_{m,k}\) is included in order to give uniform bounds over the numerable collection \(\mathcal {P}\).
In the following, the expression tr(A) stands for the trace of the matrix A. Set \(T_{m,p_{k}}=\mbox{tr}((R_{m,p_{k}}D_q^{1/2})^t R_{m,p_{k}}D_q^{1/2})\) and define
with r > 1 and d = d(r) < 1 a positive constant that depends on r. The sequence θ k ≥ 0 is such that \(\sum _{k}e^{-\sqrt {dr \theta _{k}(d_m+1) }} < 1\) holds.
It is thus reasonable to consider the best p as the minimizer
where, for a given 0 < γ < 1,
The different roles of \(\widetilde {B}_1\) and \(\widetilde {B}_2\) appear in the following lemmas:
Lemma 2.2
Assume that the conditions [AB], [AS], and [AQ] are satisfied and that there is a constant p min > 0 such that for all i = 1, …, n, \(p (t_i) > p_{k,\min }>p_{\min }\) . Assume \(\widetilde {B}_1\) to be selected according to (4). Then for all δ > 0 we have

Lemma 2.3
Assume the observation noise in Eq.(1) is an i.i.d. collection of random variables satisfying the moment condition [MC]. Assume that the condition [AQ] is satisfied and assume that there is a constant p min > 0 such that p(t i) > p minfor all i = 1, …, n. Assume \(\widetilde {B}_2\) to be selected according to (6) with r > 1, d = d(r) and θ k ≥ 0, such that the following Kraft inequality \(\sum _{k}e^{-\sqrt {d r \theta _{k}(m+1) }} < 1\) holds. Then,
Those two lemmas together with Lemma 2.1 assure that the proposed estimation procedure, based on the minimization of \(\widetilde {B}\), is consistent establishing non-asymptotic rates in probability.
We may now state the main result of this section, namely, non-asymptotic consistency rates in probability of the proposed estimation procedure. The proof follows from Lemmas 2.2 and 2.3 and is given in the extended arXiv version along with the proof of the lemmas.
Theorem 2.1
Assume that the conditions [AB], [AS], and [AQ] are satisfied. Assume \(\hat {p}\) to be selected according to (7). Then the following inequality holds with probability greater than 1 − δ

Remark 2.1
In the minimization scheme given above it is not necessary to know the term \(\|x_0-x_m\|{ }^2_{n,q}\) in \(\widetilde {B}_1\) as this term is constant with regard to the sampling scheme p. Including this term in the definition of \(\widetilde {B}_1\), however, is important because it leads to optimal bounds in the sense that it balances p min with the mean variation, over the sample points, of the best possible solution x m over the hypothesis model set S m. This idea shall be pursued in depth in Sect. 3.
Moreover, minimizing \(\widetilde {B}_1\) essentially just requires selecting k such that \(p_{k,\min }\) is largest and doesn’t intervene at all if \(p_{k,\min }=p_{min}\) for all k. Minimization based on p k(t i) for all sample points is given by the trace \(T_{m,p_{k}}\) which depends on the initial random sample u independent of {(t i, y i), i = 1, …, n}. A reasonable strategy in practice, although we do not have theoretical results for it, is to consider several realizations of u and select sample points which appear more often in the selected sampling scheme \(\hat {p}\).
Remark 2.2
Albeit the appearance of weight terms which depend on k both in the definition of \(\widetilde {B}_1\) and \(\widetilde {B}_2\), actually the ordering of \(\mathcal {P}\) does not play a major role. The weights are given in order to assure convergence over the numerable collection \(\mathcal {P}\). Thus in the definition of \(\widetilde {\beta }_{m,k}\) any sequence of weights \(\theta ^{\prime }_k\) (instead of [k(k + 1)]−1) assuring that the series \(\sum _k \theta ^{\prime }_k<\infty \) is valid. Of course, in practice \(\mathcal {P}\) is finite. Hence for \(M=|\mathcal {P}|\) a more reasonable bound is just to consider uniform weights \(\theta ^{\prime }_k=1/M\) instead.
Remark 2.3
Setting \(H_{m,p_{k}}:=(G_{m}^{t}D_{w,q,p_{k}}G_{m})^{-1}G_{m}^{t}D_{w,q,p_{k}}\) we may write \(T_{m,p_{k}}=\mbox{tr}(G_m^tD_qG_m H_{m,p_{k}}H_{m,p_{k}}^t) \) in the definition of \(\widetilde {B}_2\). Thus our convergence rates are as in Lemma 1, [5]. Our approach, however, provides non-asymptotic bounds in probability as opposed to asymptotic bounds for the quadratic estimation error.
Remark 2.4
As mentioned at the beginning of this section, the expected “best” sample size given u is \(\hat {N}=\sum _i \hat {p}(t_i)\), where u is the initial random sample independent of {(t
i, y
i), i = 1, …, n}. Of course, a uniform inferior bound for this expected sample size is  , so that the expected size is inversely proportional to the user chosen estimation error. In practice, considering several realizations of the initial random sample provides an empirical estimator of the non-conditional “best” expected sample size.
, so that the expected size is inversely proportional to the user chosen estimation error. In practice, considering several realizations of the initial random sample provides an empirical estimator of the non-conditional “best” expected sample size.
2.5 Model Selection and Active Learning
Given a model and n observations (t 1, y 1), …, (t n, y n) we know how to estimate the best sampling scheme \(\hat {p}\) and to obtain the estimator \(\hat {x}_{m,\hat {p}}\). The problem is that the model m might not be a good one. Instead of just looking at fixed m we would like to consider simultaneous model selection as in [7]. For this we shall pursue a more global approach based on loss functions.
We start by introducing some notation. Set l(u, v) = (u − v)2 the squared loss and let \(L_n(x,y,p)=\frac {1}{n}\sum _{i=1}^n q(t_i) \frac {w_i}{p(t_i)}l(x(t_i),y_i)\) be the empirical loss function for the quadratic difference with the given sampling distribution. Set L(x) := E (L n(x, y, p)) with the expectation taken over all the random variables involved. Let L n(x, p) := Eε (L n(x, y, p)) where Eε () stands for the conditional expectation given the initial random sample u, that is the expectation with respect to the random noise ε. It is not hard to see that

and

Recall that \(\hat {x}_{m,p}=R_{m,p}y\) is the minimizer of L n(x, y, p) over each S m for given p and that x m = R mx 0 is the minimizer of L(x) over S m. Our problem is then to find the best approximation of the target x 0 over the function space \(S_0:=\bigcup _{m\in \mathcal {I}} S_m\). In the notation of Sect. 2.2 we assume for each m that S m is a bounded subset of the linearly spanned space of the collection \(\{\phi _j\}_{j\in I_m}\) with \(|\mathcal {I}_m|=d_m\).
Unlike the fixed m setting, model selection requires controlling not only the variance term \(\|x_m-\hat {x}_{m,p}\|{ }_{n,q}\) but also the unobservable bias term \(\|x_0-x_m\|{ }^2_{n,q}\) for each possible model S m. If all samples were available this would be possible just by looking at L n(x, y, p) for all S m and p, but in the active learning setting labels are expensive.
Set e m := ∥x 0 − x m∥∞. In what follows we will assume that there exists a positive constant C such that supme m ≤ C. Remark this implies supm∥x 0 − x m∥n,q ≤ QC, with Q defined in [AQ].
As above \(p_{k}\in \mathcal {P}\) stands for the set of candidate sampling probabilities and \(p_{k,\min }=\min _i(p_{k}(t_i))\).
Define
with
and finally setting \(T_{p_k,m}=\mbox{tr}((R_{m,p_k}D_q^{1/2})^t R_{m,p_k}D_q^{1/2})\), define
where θ m,k ≥ 0 is a sequence such that \(\sum _{m,k}e^{-\sqrt {dr \theta _{m,k}(d_m + 1) }}<1\) holds.
We remark that the change from δ to δ∕(d m(d m + 1)) in pen 0 and pen 1 is required in order to account for the supremum over the collection of possible model spaces S m.
Also, we remark that introducing simultaneous model and sample selection results in the inclusion of term \(pen_0\sim C^2/ p_{k,\min } \sqrt {1/n}\) which includes an L ∞ type bound instead of an L 2 type norm which may yield non-optimal bounds. Dealing more efficiently with this term would require knowing the (unobservable) bias term ∥x 0 − x m∥n,q. A reasonable strategy is selecting p k,min = p k,min(m) ≥∥x 0 − x m∥n,q whenever this information is available.
In practice, p k,min can be estimated for each model m using a previously estimated empirical error over a subsample if this is possible. However this yields a conservative choice of the bound. One way to avoid this inconvenience is to consider iterative procedures, which update on the unobservable bias term. This course of action shall be pursued in Sect. 3.
With these definitions, for a given 0 < γ < 1 set
and define
The appropriate choice of an optimal sampling scheme simultaneously with that of model selection is a difficult problem. We would like to choose simultaneously m and p, based on the data in such a way that optimal rates are maintained. We propose for this a penalized version of \(\hat {x}_{m,\hat {p}}\), defined as follows.
We start by choosing, for each m, the best sampling scheme
computable before observing the output values \(\{y_i\}_{i=1}^n\), and then calculate the estimator \(\hat {x}_{m,\hat {p}(m)}=R_{m,\hat {p}(m)}y\) which was defined in (2).
Finally, choose the best model as
The penalized estimator is then \(\hat {x}_{\hat {m}}:=\hat {x}_{\hat {m},\hat {p}(\hat {m})}\). It is important to remark that for each model m, \(\hat {p}(m)\) is independent of y and hence of the random observation error structure. The following result assures the consistency of the proposed estimation procedure, although the obtained rates are not optimal as observed at the beginning of this section.
Theorem 2.2
With probability greater than 1 − δ, we have
Remark 2.5
In practice, a reasonable alternative to the proposed minimization procedure is estimating the overall error by cross-validation or leave one out techniques and then choose m minimizing the error for successive essays of probability \(\hat {p}\). Recall that in the original procedure of Sect. 2.5, labels are not required to obtain \(\hat {p}\) for a fixed model. Cross-validation or empirical error minimization techniques do, however, require a stock of “extra” labels, which might not be affordable in the active learning setting. Empirical error minimization is specially useful for applications where what is required is a subset of very informative sample points, as for example when deciding what points get extra labels (new laboratory runs, for example) given a first set of complete labels is available. Applications suggest that \(\hat {p}\) obtained with this methodology (or a threshold version of \(\hat {p}\) which eliminates points with sampling probability \(\hat {p}_i\le \eta \) a certain small constant) is very accurate in finding “good” or informative subsets, over which model selection may be performed.
3 Iterative Procedure: Updating the Sampling Probabilities
A major drawback of the batch procedure is the appearance of \(p_{\min }\) in the denominator of error bounds, since typically \(p_{\min }\) must be small in order for the estimation procedure to be effective. Indeed, since the expected number of effective samples is given by E (N) := E (∑ip(t i)), small values of p(t i) are required in order to gain in sample efficiency.
Proofs in Sect. 2.5 depend heavily on bounding expressions such as
or
where x and x′ belong to a given model family S m. Thus, it seems like a reasonable alternative to consider iterative procedures for which at time j, \(p_j(t_i)\sim \max _{x,x'\in S_j}|x(t_i)-x'(t_i)|\) with S j the current hypothesis space. In what follows we develop this strategy, adapting the results of [1] from the classification to the regression problem. Although we continue to work in the setting of model selection over bounded subsets of linearly spanned spaces, results can be readily extended to other frameworks such as additive models or kernel models. Once again, we will require certain additional restrictions associated to the uniform approximation of x 0 over the target model space.
More precisely, we start with an initial model set \(S(=S_{m_0})\) and set x ∗ to be the overall minimizer of the loss function L(x) over S. Assume additionally
- AU:
-
\(\sup _{x\in S}\max _{t \in \{t_1,\ldots ,t_n\}}|x_0(t )-x(t )|\le B\)
Let L n(x) = L n(x, y, p) and L(x) be as in Sect. 2.5. For the iterative procedure introduce the notation
with n j = n 0 + j for j = 0, …, n − n 0.
In the setting of Sect. 2 for each 0 ≤ j ≤ n, S j will be the linear space spanned by the collection \(\{\phi _\ell \}_{\ell \in \mathcal {I}_j}\) with \(|\mathcal {I}_j|=d_j\), d j = o(n).
In order to bound the fluctuations of the initial step in the iterative procedure we consider the quantities defined in Eqs. (4) and (6) for r = γ = 2. That is,
with
As discussed in Sect. 2.4, Δ 0 requires some initial guess of \(\|x_0-x_{m_0}\|{ }^2_{n,q}\). Since this is not available, we consider the upper bound B 2. Of course this will possibly slow down the initial convergence as Δ 0 might be too big, but will not affect the overall algorithm. Also remark we do not consider the weighting sequence θ k of Eq. (6) because the sampling probability is assumed fixed.
Next set \(B_j=\sup _{x, x'\in S_{j-1}}\max _{t \in \{t_1,\ldots ,t_n\}}|x(t )-x'(t )|\) and define
The iterative procedure is stated as follows:
-
1.
For j = 0:
-
Choose (randomly) an initial sample of size n 0, \(M_0=\{t_{k_{1}},\ldots , t_{k_{n_0}}\}\).
-
Let \(\hat {x}_0\) be the chosen solution by minimization of L 0(x) (or possibly a weighted version of this loss function).
-
Set \(S_0\subset \{x\in S: L_0(x)<L_0(\hat {x}_0)+\varDelta _0\}\)
-
-
2.
At step j:
-
Select (randomly) a sample candidate point t j, t j∉M j−1.
Set M j = M j−1 ∪{t j}
-
Set \(p(t_j)=(\max _{x,x'\in S_{j-1}}|x(t_j)-x'(t_j)|\wedge 1)\) and generate w j ∼ Ber(p(t j)).
If w j = 0, set j = j + 1 and go to (2) to choose a new sample candidate.
If w j = 1 sample y j and continue.
-
Let \(\hat {x}_j=\mbox{arg}\min _{x\in S_{j-1}}L_j(x)+ \varDelta _{j-1}(x)\)
-
Set \(S_j\subset \{x\in S_{j-1}:L_j(x)< L_j(\hat {x}_j)+\varDelta _j\}\)
-
Set j = j + 1 and go to (2) to choose a new sample candidate.
-
Remark that, such as it is stated, the procedure can continue only up until time n (when there are no more points to sample). If the process is stopped at time T < n, the term \(\log (n(n+1))\) can be replaced by \(\log (T(T+1))\). We have the following result, which generalizes Theorem 2 in [1] to the regression case.
Theorem 3.1
Let x ∗ = argminx ∈ SL(x). Set δ > 0. Then, with probability at least 1 − δ for any j ≤ n
-
|L(x) − L(x′)|≤ 2Δ j−1, for all x, x′∈ S j
-
\(L(\hat {x}_j)\le [L(x^*)+2\varDelta _{j-1}]\)
Remark 3.1
An important issue is related to the initial choice of m 0 and n 0. As the overall precision of the algorithm is determined by L(x ∗), it is important to select a sufficiently complex initial model collection. However, if \(d_{m_0}>>n_0\), then Δ 0 can be big and p j ∼ 1 for the first samples, which leads to a more inefficient sampling scheme.
3.1 Effective Sample Size
For any sampling scheme the expected number of effective samples is, as already mentioned, E (∑ip(t i)). Whenever the sampling policy is fixed, this sum is not random and effective reduction of the sample size will depend on how small sampling probabilities are. However, this will increase the error bounds as a consequence of the factor \(1/p_{\min }\). The iterative procedure allows a closer control of both aspects and under suitable conditions will be of order \(\sum _j\sqrt {L(x^*)+ \varDelta _j} \). Recall from the definition of the iterative procedure we have \(p_j(t_i)\sim \max _{x,x'\in S_j}|x(t_i)-x'(t_i)|\), whence the expected number of effective samples is of the order of \(\sum _j \max _{x,x'\in S_j}|x(t_i)-x'(t_i)|\). It is then necessary to control \(\sup _{x,x'\in S_{j-1}}|x(t_i)-x'(t_i)|\) in terms of the (quadratic) empirical loss function L j. For this we must introduce some notation and results relating the supremum and L 2 norms [2].
Let S ⊂ L 2 ∩ L ∞ be a linear subspace of dimension d, with basis Φ := {ϕ j, j ∈ m S}, |m S| = d. Set \(\overline {r}:=\inf _\varLambda r_\varLambda \), where Λ stands for any orthonormal basis of S.
We have the following result
Lemma 3.1
Let
\(\hat {x}_j\)
be the sequence of iterative approximations to x
∗and p
j(t) be the sampling probabilities in each step of the iteration, j = 1, …, T. Then, the effective number of samples, that is, the expectation of the required samples
 is bounded by
is bounded by
References
Beygelzimer, A., Dasgupta, S., & Langford, J. (2009). Importance weighted active learning. In Proceedings of the 26th Annual International Conference on Machine Learning (pp. 49–56). New York: ACM.
Birgé, L., & Massart, P. (1998). Minimum contrast estimators on sieves: Exponential bounds and rates of convergence. Bernoulli, 4, 329–395.
Fermin, A. K., & Ludeña, C. (2018). Probability bounds for active learning in the regression problem. arXiv: 1212.4457
Härdle, W., Kerkyacharian, G., Picard, D., & Tsybakov, A. (1998). Wavelets, approximation and statistical applications: Vol. 129. Lecture notes in statistics. New York: Springer.
Sugiyama, M. (2006). Active learning in approximately linear regression based on conditional expectation generalization error with model selection. Journal of Machine Learning Research, 7, 141–166.
Sugiyama, M., Krauledat, M., & Müller, K. R. (2007). Covariate shift adaptation by importance weighted cross validation. Journal of Machine Learning Research, 8, 985–1005.
Sugiyama, M., & Rubens, N. (2008). A batch ensemble approach to active learning with model selection. Neural Networks, 21(9), 1278–1286.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Fermin, AK., Ludeña, C. (2018). Probability Bounds for Active Learning in the Regression Problem. In: Bertail, P., Blanke, D., Cornillon, PA., Matzner-Løber, E. (eds) Nonparametric Statistics. ISNPS 2016. Springer Proceedings in Mathematics & Statistics, vol 250. Springer, Cham. https://doi.org/10.1007/978-3-319-96941-1_14
Download citation
DOI: https://doi.org/10.1007/978-3-319-96941-1_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-96940-4
Online ISBN: 978-3-319-96941-1
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)