
Abstract
Urban air quality has degraded at an alarming rate due to rapid urbanisation and industrialization in megacities. Therefore, there is an urgent need to assess air quality and suggest risk mitigation measures. In this paper, air quality of Chennai city was evaluated using different Fuzzy Synthetic Evaluation (FSE) techniques i.e. Fuzzy similarity method (FSM) and Simple fuzzy classification (SFC) and the results are compared with the National air quality index (NAQI). In the case of SFC weights for different pollutants were computed using Shannon’s information entropy. Seasonal analysis of the criteria pollutants shows highest concentration during the winter season followed by pre-monsoon and summer season. The lowest concentration was observed during Monsoon in most cases. The FSE results are optimistic as compared to the NAQI due to aggregation of pollutant concentration as opposed to maximising function in NAQI which reconfirms the findings of earlier researchers. FSE can be used as a decision making tool to communicate the overall air quality to policy makers/end users (Public) in a simplified qualitative form.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

1 Introduction
Urban air quality has degraded at an alarming rate in the recent decades [1]. Chennai being one of the major metropolitan and industrial area has shared the same fate. Chennai regarded as the “Detroit of India” due to its large Automobile industry has been under constant scrutiny of Central pollution control board (CPCB) and Tamilnadu pollution control board (TNPCB) [2]. Chennai city has been classified as a non-attainment area for PM10 due to the number of exceedances [3]. This leads to the challenge of informing the residents and policy makers about the air quality of region effectively and in time.
Air quality information dissemination is an integral part of any air quality management system. Air quality index plays a vital role in this purpose. Many air quality indices have been developed in the past few decades [4, 5] to serve the purpose of providing current air quality status for resident’s health and safety at the time of exceedances and informed decision making for air quality management strategies of the area.
National Air quality index (NAQI) based on a linear scale working with maximum operator has the problem of eclipsing that is showing lower concentration as compared to the observed concentration and ambiguity showing higher concentration as compared to the observed concentration at or near the class boundaries. These problems occur due to a strict boundary between air quality classes which don’t give enough information about the uncertainty and imprecision in air quality data.
The following paper is divided into 7 parts. Followed by the introduction, study area is explained with the location details and types of monitoring location. Conventional air quality indexing techniques are explained in Sect. 3. In the next section the philosophy of fuzzy logic is elaborated with the explanation of Fuzzy similarity method and distance metrics employed in the development of the model. The air quality of the study area is evaluated in the results and discussion section. The paper ends with conclusion describing the main attributes of the model and analysis and future scope of the work.
2 Study Area
Chennai city is located on the south-eastern coast of peninsular India [2]. It has a flat coastal terrain with the average elevation of 6.7 m. It stretches along a length of 25.6 km with an area of 176 Km2. Chennai is considered as the Indian capital of automobile manufacturing with a share of 30% of automobiles and 40% of auto-parts manufactured in India.
According to Indian meteorological department (IMD) the weather in Chennai is sub-tropical (hot and humid) with 4 seasons i.e. winter, summer, pre-monsoon and monsoon [6]. The season of winter occurs between January to February with an average temperature of 25.6 °C, Summer from March to May with an average temperature of 30.5 °C, Pre-monsoon or southwest monsoon occurs from June to September with an average temperature of 29.7 °C, while Post-monsoon or northeast monsoon occurs from October to December with an average temperature of 26.7 °C. 60% of rainfall occurs during the season of post monsoon or northeast monsoon.
Daily average concentration of Sulphur dioxide (SO2), Nitrogen dioxide (NO2) and Respirable suspended particulate matter (RSPM) for 2009–2013 was collected from Tamilnadu pollution control board (TNPCB). TNPCB monitors Air quality data twice a week at 6 locations as depicted in Fig. 1 and Table 1.

Map showing monitoring locations for air quality monitoring
3 Air Quality Index
Air quality index has been developed for weighted and aggregated representation of complex environmental data in a simplified and intelligible form. It helps the common public in taking proper precautions in the case of exceedances and decision makers in developing new policies for reducing the harmful effects of air pollution and developing a sustainable society.
The most commonly used air quality index was developed by USEPA earlier named as Air pollution index (API) [7] and later renamed to USEPA AQI. In the above index the air quality is divided into 5 strict linear classes based on concentration breakpoints. A sub-index is calculated for each pollutant using the given Eq. (1)
- Ip:
-
index for pollutant p
- Cp:
-
Rounded concentration of pollutant p
- BPHI:
-
Breakpoint that is higher than or equal to Cp
- BPLO:
-
Breakpoint that is lower than or equal to Cp
- IHI:
-
AQI value corresponding to BPHI
- ILO:
-
AQI value corresponding to BPLO
4 Fuzzy Logic
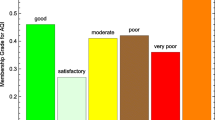
Fuzzy logic is a multi-valued logic formed by extending the binary logic into the realm of partial membership. It was first described by Lotfi A. Zadeh in a seminal paper published in 1965 [8]. Fuzzy logic uses overlapping membership functions to model the uncertainty and ambiguity pertaining in a real world complex system like urban air quality. Fuzzy logic helps in classification using linguistic parameters developed by employing the expert knowledge-base derived by responses from a fuzzy questionnaire.
Fuzzy logic has been applied in a number of papers for the assessment of air quality and development of air quality management tools [9,10,11,12]. In assessment of a complex system like air quality fuzzy logic based techniques are able to trap and model the uncertainty arising in data due to error during monitoring, and analysis.
The membership functions were determined by employing expert’s perception using fuzzy questionnaire duly filled by different air quality experts. The mean of the membership functions developed were used as the final set of membership functions.
The membership functions help in determining the AQI by integrating the health and ecological effects of different pollutants obtained through the expert’s experience in the field of air quality into the Fuzzy based model (Fig. 2).

Fuzzy membership functions for SO2, NO2 and RSPM
5 Fuzzy Synthetic Evaluation
In Fuzzy synthetic evaluation (FSE) the air quality standards for different pollutants were used to develop linguistic classes which were represented in matrix form with the columns as pollutant and rows as classes [13]. The pollutant concentration value was compared with the standards using the min max approach.
FSE constitutes Fuzzy similarity method (FSM) and simple fuzzy classification (SFC) [14]. In the case of FSM an evaluation matrix R as shown in Eq. (2) is derived from the mean value of each trapezoidal membership function with rows representing the pollutants and columns representing the air quality class and another matrix R’ represents the membership value of each pollutant for different air quality class at a given instance [15]. The 2 matrices are compared using the similarity function in Eq. (3) and the maximum value of the similarity function was used to represent the final air quality class for the given case.
- rij:
-
membership value for pollutant i and class j
- i:
-
pollutant 1, …, 3, 1 = SO2, 2 = NO2 and 3 = RSPM
- j:
-
class 1, …, 5, 1 = very low, 2 = low, 3 = medium, 4 = high, 5 = very high
In case of SFC, weight for each pollutant was derived using Shannon’s information entropy function [16]. Information entropy signifies the amount of information contained in a given set of data and represented by the negative log of normalised data [17].
Concentration for jth reading of the ith pollutant was normalised using Eq. (4) from the evaluation matrix. The normalised value rij is divided by the sum of all the normalised values using Eq. (5) and the final value is used to calculate the Shannon’s entropy for each pollutant in Eq. (6). Weight of a pollutant is calculated using Eq. (7)
Distance metric for each case was calculated from the Eq. (8) utilising the membership value from the evaluation matrix (R) and weight derived using Shannon entropy. The maximum value of the distance metric for each case determines the final air quality category
- \(\lambda_{ij}\) :
-
Membership value for jth value of ith pollutant
- k(j):
-
distance metric for jth value
- w i :
-
entropy weight for pollutant I
- k(f) :
-
air quality category of the value
6 Results and Discussion
The AQI procedure was applied to air pollutant concentration values obtained from the 6 urban air quality monitoring stations in Chennai. The fuzzy AQI was calculated using FSM and SFC and compared with the conventional National air quality index (NAQI). The results for Kathivakkam and Manali industrial area for 2013 are shown in Tables 2 and 3 respectively.
The FSE results are optimistic compared to the NAQI as they show that the air quality is better than air quality determined by the NAQI. This happens because the concentration of all the pollutants are integrated for calculation of index in case of FSE techniques while in the case of NAQI the index is determined only by the concentration of the pollutant with the maximum sub index which causes the NAQI to be less sensitive to the health effect of other pollutants. The FSE techniques give a clearer picture about the air quality as the effect of all the individual pollutants are integrated in the final AQI. The use of membership functions, expert’s perception and predetermined Shannon’s entropy based weights make the FSE based methods more sensitive to changes in concentration of air pollutants.
The AQI in the winter months of January and February are poor as compared the other months of the year. The best air quality was observed during the Northeast monsoon period of November and December.
Seasonal variation for the 6 monitoring locations for 2009–2012 are shown in Figs. 3, 4, 5 for SO2, NO2 and RSPM respectively. No exceedances were observed for SO2 and NO2.

Seasonal variation of SO2 at TNPCB monitoring locations

Seasonal variation of NO2 at TNPCB monitoring locations

Seasonal variation of RSPM at TNPCB monitoring locations
In case of all pollutants highest concentration was observed during the winter season due to stable atmospheric conditions which restricts the vertical mixing of air mass and dispersion of pollutants.
In the case of RSPM concentration, exceedances were observed during the years 2009–2011 for some of the industrial locations. All the exceedances were observed during the winter season (Fig. 4).
7 Conclusion
FSE methods integrates multiple pollutant’s concentration and expert’s knowledge into the AQI as opposed to conventional NAQI in which a single pollutant with maximum subindex is considered to define the air quality. Urban air quality is not easy to assess and comprehend because of its multi-pollutant characteristics. Contribution of each pollutant can be measured and assessed in the case of FSE.
The given methods are easy to model, less data intensive and the results are comprehensible for local public and decision makers. FSE techniques show more optimistic results as compared to the conventional AQI which can reduce the burden of money and effort on air quality management. The methods overcome the uncertainty of air quality classification near the class boundaries by implying fuzziness in the class boundaries using the overlapping Fuzzy classes and produce an air quality index with higher sensitivity. The above techniques can be used to develop an effective air quality management plan for the urban area of Chennai city.
References
J. Fenger, Air pollution in the last 50 years—from local to global. Atmos. Environ. 43(1), 13–22 (2009)
R. Krishnamurthy, K.C. Desouza, Chennai, India. Cities 42, 118–129 (2015)
CPCB, Air quality monitoring, emission inventory and source apportionment study for Chennai (2011)
D. Shooter, P. Brimblecombe, Air quality indexing. Int. J. Environ. Pollut. 1–24 (2005)
A. Plaia, M. Ruggieri, Air quality indices: a review. Rev. Environ. Sci. Bio/Technol. 10(2), 165–179 (2010)
B. Srimuruganandam, S.M. Shiva Nagendra, Application of positive matrix factorization in characterization of PM (10) and PM (2.5) emission sources at urban roadside. Chemosphere 88(1), 120–30 (2012)
W.-L. Cheng, Y.-S. Chen, J. Zhang, T.J. Lyons, J.-L. Pai, S.-H. Chang, Comparison of the revised air quality index with the PSI and AQI indices. Sci. Total Environ. 382(2–3), 191–198 (2007)
L.A. Zadeh, Fuzzy sets. Inf. Control, 338–353 (1965)
B.E.A. Fisher, Fuzzy approaches to environmental decisions: application to air quality. Environ. Sci. Policy 9, 22–31 (2006)
D. Dunea, A.A. Pohoat, E. Lungu, Fuzzy inference systems for estimation of air quality index. ROMAI J. 7(2), 63–70 (2011)
M.H. Sowlat, H. Gharibi, M. Yunesian, M. Tayefeh Mahmoudi, S. Lotfi, A novel, fuzzy-based air quality index (FAQI) for air quality assessment. Atmos. Environ. 45(12), 2050–2059 (2011)
X. Zhao, Q. Qi, R. Li, The establishment and application of fuzzy comprehensive model with weight based on entropy technology for air quality assessment. Procedia Eng. 7, 217–222 (2010)
N.B. Chang, H.W. Chen, S.K. Ning, Identification of river water quality using the fuzzy synthetic evaluation approach. J. Environ. Manage. 63, 293–305 (2001)
G. Onkal-Engin, I. Demir, H. Hiz, Assessment of urban air quality in Istanbul using fuzzy synthetic evaluation. Atmos. Environ. 38(23), 3809–3815 (2004)
L. Abdullah, N.D. Khalid, Classification of air quality using fuzzy synthetic multiplication. Environ. Monit. Assess. 184, 6957–6965 (2012)
Z. Zhi-hong, Entropy method for determination of weight of evaluating indicators in fuzzy synthetic evaluation. J. Environ. Sci. 18(5), 1020–1023 (2006)
S. Al-sharhan, F. Karray, W. Gueaieb, O. Basir, Fuzzy entropy: a brief survey, in 10th IEEE International Conference on Fuzzy Systems (Cat. No.01CH37297), vol. 3 (2001), pp. 1135–1139
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this chapter

Cite this chapter
Gautam, H.C., Shiva Nagendra, S.M. (2018). Comparison of Fuzzy Synthetic Evaluation Techniques for Evaluation of Air Quality: A Case Study. In: Zadeh, L., Yager, R., Shahbazova, S., Reformat, M., Kreinovich, V. (eds) Recent Developments and the New Direction in Soft-Computing Foundations and Applications. Studies in Fuzziness and Soft Computing, vol 361. Springer, Cham. https://doi.org/10.1007/978-3-319-75408-6_47
Download citation
DOI: https://doi.org/10.1007/978-3-319-75408-6_47
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-75407-9
Online ISBN: 978-3-319-75408-6
eBook Packages: EngineeringEngineering (R0)