
Abstract
A reversible data hiding scheme makes it possible to extract secret data and recover the cover image without any distortion. This paper presents a novel reversible data hiding scheme based on side-match vector quantization (SMVQ). If the original SMVQ index value of an image block is larger than a threshold, a technique called state-codebook sorting (SCS) is used to create two state-codebooks to re-encode the block with a smaller index. In this way, more indices are distributed around zero, so the embedding scheme only needs a few bits to encode the indices, which produces more extra space for hiding secret data. The experimental results indicate that the proposed scheme is superior to some previous schemes in embedding performance while maintaining the same visual quality as that of VQ compression.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


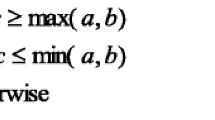
Keywords
1 Introduction
With the rapid development of multimedia and communication technologies, massive amounts of multimedia data are transmitted over the Internet, which is convenient for people to exchange and share information without time or space constraints. However, such easy access to the Internet makes illegal distribution of multimedia easier and poses key challenges on security protection of confidential data. To solve this security problem, many researchers have proposed various data protection approaches, including encryption and data hiding techniques. An encryption method just encrypts the secret data into a meaningless form using cryptographic algorithms. The unrecognizable form may raise the suspicion of malicious attackers. On the contrary, data hiding is used to embed the secret data imperceptibly in meaningful cover media. In this way, attackers will not be suspicious of the media that carries the secret data.
Generally, data hiding techniques can be classified into three domains, i.e., the spatial domain [1,2,3,4,5,6], the transform domain [7, 8] and the compression domain [9,10,11,12,13,14,15,16,17]. In the spatial domain, the cover image is modified directly and undetectably to conceal the secret data. In the transform domain, the secret data is embedded by altering the frequency coefficients of the cover image. However, due to the bandwidth limitation, many image compression schemes, such as vector quantization (VQ) [9], block truncation coding (BTC) [10, 11] and JPEG [12] have been introduced into the compression domain to save storage and bandwidth space. VQ is a widely used image compression technique with properties of simple implementation and high compression rate. In this work, we mainly focus on the data hiding in VQ-related [13,14,15,16,17] image compressed codes. This hiding technique aims to provide a way for low bandwidth transmission, as well as a means of covert communication.
In 2009, Chang et al. [13] proposed a reversible information embedding method for VQ-compressed image using the joint neighboring coding (JNC) technique. Their method only uses the left or upper neighboring indices to embed secret data and obtains a low hiding capacity. In 2011, Yang et al. [14] proposed an MFCVQ-based reversible data hiding scheme, which use the Huffman-code strategy and 0-centered classification to reduce the bit rate of the output code stream, however the hiding capacity is still low. In the same year, Chang et al. [15] designed a locally adaptive coding scheme in the VQ compression domain. This scheme achieves both good reconstructed image visual quality and a high embedding rate. In 2013, Wang et al. [16] proposed a new VQ-based scheme for reversible data hiding. In this scheme, a technique called adjoining state-codebook mapping (ASCM) is used to improve the side- match vector quantization (SMVQ)-based scheme. Therefore, it can reduce the size of the output code stream by 13% on average when 16,129 bits are embedded in each test image. In 2015, Lin et al. [17] proposed a new reversible data hiding scheme for VQ-compressed images. The search-order coding (SOC) and state-codebook mapping (SCM) are used in the proposed scheme for reducing the size of the VQ index table and for hiding a scalable amount of data. However, the scheme does not work effectively when images have low correlation among neighboring indices.
One of the common characteristics of VQ-based data hiding schemes mentioned above is that the secret data are embedded in the compressed code stream. This type of data hiding algorithm focuses on providing larger embedding capacity with lower compressed bit rate. Therefore, considering how to make room to enlarge hiding capacity and how to reduce the index values to further suppress the bit rate are significant subjects of our proposed scheme. Generally, we employ SMVQ to improve the distribution of VQ index table, and adopt a state-codebook sorting (SCS) technique to further reduce the index values of SMVQ index table. So the proposed embedding scheme only needs few bits to encode the indices, thus yielding more space for secret data hiding. Compared with related existing schemes, our proposed method has higher embedding capacity and lower bit rate.
2 Proposed Scheme
2.1 State-Codebook Sorting
The goals of SMVQ-based data hiding scheme are to embed large amount of secret data and achieve a low compressed bit rate. The main factor in achieving good embedding performance is the distribution of SMVQ index table, which is determined by the state-codebook used for encoding an image block. In the final analysis, the state-codebook is the critical element for SMVQ-based data hiding method. Therefore we propose an SCS method to improve the distribution of SMVQ index table.
As is well-known, correlation among neighboring blocks of a natural image is very strong, which is the key feature exploited in SMVQ, so we can use the border pixels of neighboring blocks to predict the current block. However, when the image block is complex, the prediction result becomes worse, which indicates the state-codebook used for encoding is not appropriate. In order to solve this problem, we adopt a strategy that the block whose index value is larger than threshold T needs to be re-encoded using new generated state-codebook. The threshold is chosen on the basis of empirical value. The statistics distribution of indices in Fig. 1 shows that most of the high-frequency SMVQ indices of the eight representative images range from 0 to 7, i.e., most of the indices are smaller than 8 (the integer power of 2). With the higher frequency of used indices, better embedding capacity can be achieved while maintaining low bit rate and the good visual quality of the reconstructed image. Therefore we take 8 as the threshold T to determine whether an SMVQ encoded image block needs to be re-encoded using the new state-codebooks generated by our sorting method. The detailed processes of the state-codebook sorting method are introduced as follows.

High-frequency histogram of state-codebook sorted indices.
To encode a block of an image (except the first row and first column blocks that are encoded by VQ), the scheme first compresses it by the conventional SMVQ algorithm, then compares the index value v with T, if it is smaller than T, the index value is reserved, otherwise our scheme sorts the state-codebook by each codeword’s mean value in both ascending and descending order to create two state-codebooks, which are used again to encode the block to get new index values v 1 and v 2, then compares them with T. If only one of v 1 and v 2 is smaller than T, the scheme replaces v with that one, or if v 1 and v 2 are both smaller than T, replaces v with the smaller one of v 1 and v 2, and otherwise leaves the original index v unchanged. In this way, more indices are distributed around zero.
According to the abovementioned SMVQ scheme, a 2-bit indicator is required to distinguish four cases of block encoding results. If a block is encoded using the original SMVQ index value which is smaller than T, the indicator is set as “00”, or if a block is re-encoded by the state-codebook sorted in ascending order, the indicator is set as “01”, or the indicator is set as “10” for the case that the state-codebook is sorted in descending order, or else the indicator is set as “11” to denote that a block’s original index value is larger than T and the state-codebook sorting method cannot effectively reduce the index. In other words, the first three cases obtain the index value that is smaller than T, while only for the fourth case, the index value is equal to or larger than T.
Subsequently, the reverse processes of the SCS- based SMVQ are described below. When decoding an SMVQ index v, firstly judge its 2-bit indicator ind, if it is “00” or “11”, which means v is the index value of original state-codebook, so the image block can easily be recovered by table lookup method in original state-codebook. However, if the indicator is “01” or “10”, we need to sort the state-codebook in ascending order or descending order to produce the sorted state-codebook, in which the corresponding image block is found by table lookup. Then these image blocks compose the recovered image.
2.2 Data Embedding Process
In the data embedding process, the secret bits can be easily embedded into the index table IT. Similar to the scheme proposed by Wang et al. [16], our scheme uses a flag of two bits to identify the index encoding types, and embeds secret data in the index whose value is smaller than T. In order to enlarge the embedding capacity while maintaining a low output bit rate, 4 bits secret data is embedded in each embeddable index and another threshold T a is applied to further divide the index, whose indicator is “11”, into two parts, i.e., \( P_{1} \, \in \left[ {T,T_{a} - 1} \right] \) and \( P_{2} \, \in \left[ {T_{a} ,M - 1} \right] \). Since index values are divided into three groups using threshold T and T a , the index smaller than T (T = 8) can be encoded by 3 bits, and the index with indicator “11” (i.e., P 1 and P 2) needs another 1-bit indicator to identify which group the index belongs to, so P 1 is encoded as \( 1\left\| {\left( {P_{1} - T} \right)_{2} } \right. \) and P 2 is encoded as 0||(P 2)2, where “||” denotes the concatenation operation and (x)2 means the binary representation of x. It is worth noting that the length of P 1 should be power of 2, i.e., \( T_{a} = \, 2^{i} + T\left( {i = 1,2, \ldots ,log_{2} M - 1} \right) \) into the secret data. Though additional 1-bit flag is required, we can effectively reduce the bit rate of final code stream. Because, on the one hand, more indices are smaller than T, on the other hand, the code length of P 1 is much smaller than the bit size if P 1 and P 2 are encoded as one group.
One thing to note is that the indices in the first row and the first column of IT are the seed area, where the index values will be directly transformed into binary form of log2 N bits without embedding any secret data. The residual indices of IT will be processed in order from left-to-right and top-to-bottom by the proposed embedding algorithm which is described in detail as follows:
-
Input: Grayscale cover image I, N-sized super codebook C, threshold T and T a , secret data stream B.
-
Output: Code stream CS in binary form.
-
Step 1:
Encode image I using SCS-based SMVQ technique to obtain the index table IT and the block encoding indicator table indT.
-
Step 2:
Read index v which is not in the seed area from the index table IT.
-
Step 3:
Read index v’s corresponding indicator ind from encoding indicator table indT.
-
Step 3.1:
if ind is “11”, this means that v is equal to or larger than T, and no secret data will be embedded in this index.
-
Step 3.1.1:
If v < T a , v is encoded by q = 11||1||(v − T)2, where the size of (v − T)2 is log2(T a − T).
-
Step 3.1.2:
If \( v\, \ge \,T_{a} \), v is encoded by q = 11||0||(v)2, where the size of (v)2 is log2 M.
-
Step 3.1.1:
-
Step 3.2:
Otherwise, i.e., the ind is “00”, “01” or “10”, which means the index v is smaller than T.
-
Step 3.2.1:
If B is not empty, fetch 4 bits secret data as s and remove them from B, v is encoded by q = ind||(v)2||s, where the size of(v)2 is 3.
-
Step 3.2.2:
If B is empty, v is encoded by q = ind||(v)2, where the size of (v)2 is 3.
-
Step 3.2.1:
-
Step 3.1:
-
Step 4:
Send q to the code stream CS.
-
Step 5:
Repeat Step 2 to Step 4 until all indices in the index table IT are processed.
-
Step 6:
Output the code stream CS.
-
Step 1:
After the above steps are processed completely, each index of IT can be encoded to form the code stream CS. The sender then distributes the encoded binary stream CS to the receiver.
2.3 Data Extracting Process
At the receiving side, with the received code stream CS and the size of state-codebook M, the decoder can extract the embedded secret message and reconstruct the original SMVQ indices simultaneously, and after that the cover image can be restored by decoding SMVQ indices with N-sized super codebook C. Initially, the indices in the seed area are recovered directly by converting every log2 N bits codes, which are read from CS, to decimal value. The residual indices in non-seed area and secret data are reconstructed easily through distinguishing four cases with the help of indicators. The detailed processes for extracting secret data and restoring the indices in the non-seed area are described as follows:
-
Input: The binary code stream CS, N-sized super codebook C, the size of state-codebook M, threshold T and T a , the number of unrecovered secret data N x .
-
Output: The secret data stream B and the original SMVQ-compressed index table IT.
-
Step 1:
Set the secret bit stream B empty.
-
Step 2:
Read 2 bits indicator from the binary code stream CS as ind.
-
Step 3:
if ind is “11”, this means the index value is equal to or larger than T and no secret data is embedded in the index. Then read the next one bit from CS as lab.
-
Step 3.1:
If lab is “1”, which means \( T\, \le \,v^{{\prime }} < T_{a} \), then read next log2(T a −T) bits from CS as q, \( v^{{\prime }} \) is reconstructed by converting q to decimal value then adding with T.
-
Step3.2:
If lab is “0”, which means \( v^{{\prime }} \, \ge \, T_{a} \), then \( v^{{\prime }} \) is reconstructed by reading next log2 M bits from CS and converting them to decimal value.
-
Step 3.1:
-
Step 4:
Otherwise, i.e., the ind is “00”, “01” or “10”, which means the index value \( v^{{\prime }} \) is smaller than T. And \( v^{{\prime }} \) is reconstructed by reading next 3 bits from CS and converting them to decimal value.
-
Step 4.1:
If N x > 0, 4 subsequent bits are extracted from CS as secret data \( s^{{\prime }} \), then concatenate \( s^{{\prime }} \) into the secret data stream \( B\left( {i.e.\,B = B\left\| {s^{{\prime }} } \right.} \right) \) and let N x = N x − 4.
-
Step 4.2:
If N x = 0, there is no secret data need to be extracted.
-
Step 4.1:
-
Step 5:
Put \( v^{{\prime }} \) in the recovered index table IT.
-
Step 6:
Repeat Step2 to Step5 until all the bits of code stream CS are processed.
-
Step 1:
According to the restored SMVQ index table IT and the super codebook C, we can reconstruct the original image by the reverse process of SCS-based SMVQ. In this way, the whole decoding process is realized.
3 Experimental Results and Analysis
In this section, the experimental results are presented to demonstrate the performance of the proposed scheme. Figure 2 shows eight test images of size 512 × 512, each image is divided into 16384 non-overlapping 4 × 4 blocks in the codebook encoding procedure. The super codebook of sizes 512 with codewords of 16 dimensions were trained by the LBG algorithm. The secret data in the experiment is in binary format, 0 and 1, which are generated by a pseudo-random number generator, and four bits are embedded in each embeddable index. If a high level of security is required, secret data can be encrypted prior to embedding using well-known cryptographic methods as DES or RSA.

Eight grayscale test images of size 512 × 512.
In these experiments, four criteria are employed to evaluate the performance of our proposed scheme, i.e., visual quality, compressed bit rate, embedding rate and embedding efficiency. The peak signal-to-noise (PSNR) ratio is used to estimate the degree of distortion between the original cover image and the stego-image. The compressed bit rate R b is used to evaluate the compression performance of an encoding algorithm, which is defined as \( R_{b} = \, \left| {\left| {CS} \right|} \right|/(H \times W) \), where ||CS|| represents the total length of the output code stream, H and W is the height and width of the cover image. The embedding rate R e , which describes how many secret bits can be embedded into one index of the SMVQ index table, is defined as \( R_{e} = \, \left| {\left| S \right|} \right|/N_{IDX} \), where ||S|| is the number of confidential bits embedded into the SMVQ index table, namely C p , and N IDX is the number of indices in the index table generated by SMVQ. The last criterion is the embedding efficiency E e , which describes the ratio of the size of secret data to the length of output code stream, is defined as \( E_{e} = \, \left| {\left| S \right|} \right|/\left| {\left| {CS} \right|} \right| \).
3.1 Performance of SCS
The motivation for the SCS technique is to increase the probability of getting small indices. Experimental results in Table 1 illustrate the feasibility of reducing the index value by using SCS method. M is the size of state-codebook used to generate SMVQ index table. When M = 512, it means the image quality of SMVQ is as same as that of VQ, and the index value is reduced by 7.18% on average. On the other hand, a smaller size of state-codebook (M = 32) can obviously achieve an average of 64.42% reduction of the index value.
3.2 Parameters Choosing
In order to maintain the same image quality as VQ, we make the size of state-codebook equal to that of super codebook, i.e., M = N = 512. Table 2 is a comparison between our scheme and Wang et al.’s scheme [16]. Evidently, the visual quality of our proposed scheme is same to that of Wang et al.’s scheme and VQ compression. Since there are no distortions in the index encoding and data hiding process and all distortions only occur in the SMVQ-index table generating process, the PSNR value of the stego-image is exactly equal to that of the SMVQ compressed cover images.
The threshold T a is another important parameter which affects the compressed bit rate of the output code stream, therefore we also test which threshold can lead to a better result of our proposed scheme. The bit rate results with different T a are shown in Table 3, where no secret data is embedded in the test images. The bit rate values are in the range of 0.338–0.506 and the best one for each test images is shown in bold. We can easily find that, with the increase of T a the bit rate decreased first then increased, therefore the better value for T a would be 40 since more than half of the test images have better compressed bit rate when T a is 40. The following experiments are done under these conditions.
3.3 Comparison Results with Related Schemes
We firstly considered only the scheme of Wang et al. [16] for performance comparisons of bit rate and embedding efficiency by embedding various sizes of secret data into the SMVQ index table. The bit rate comparison results of the two schemes are shown in Table 4. It is observed that, with the increase of embedding capacity, the encoding length for each index becomes longer, therefore the bit rates of the two schemes become gradually increased. In addition, under the same embedding capacity, our scheme achieves a lower bit rate than that of Wang et al.’s scheme for each test image. And the reduction of bit rate can be 1.7% to 9.1%, the average improvement of bit rate for our scheme is nearly 6.2%. The reason for achieving a lower bit rate is that in our proposed scheme the indices belonging to \( P_{1} \, \in \,\left[ {T,T_{a} - 1} \right] \), which embeds no secret data, can be encoded using few bits. On the other hand, the number of indices whose values are smaller than T is increased by SCS method, accordingly the number of indices that cannot be used for data embedding is decreased, hence the length of code stream is reduced.
Table 5 presents the corresponding embedding efficiency for the comparison experiment. The results show that, the embedding efficiencies are respectively higher than that of Wang et al.’s scheme, therefore a better performance can be achieved by using our SCS-based SMVQ technique. The increased percentage of embedding efficiency ranges from 1.5% to 10.0%, on average 6.3%, which indicates if the sizes of output code stream produced by the two schemes are same, the number of secret bits that can be embedded in our scheme will increase by 6.3% on average compared with Wang et al.’s scheme.
We have conducted another experiment to evaluate the performance of the proposed scheme by embedding the maximum numbers of secret bits into the index table. The results in Table 6 show that, the smooth image can get better results, such as image “Tiffany”, which has the highest hiding capacity and embedding efficiency. While the results of complex image become worse to some extent, the embedding rate of image “Baboon” is only 2.00 bpi, which is the lowest one of the test images. However, the embedding rate of proposed scheme is about 2.85 bpi on average, which means almost 2.85 bits secret data can be embedded in one index. Additionally, the average bit rate is 0.560 bpp, and the average embedding efficiency is 31.4%.
To demonstrate the superiority of the proposed scheme, three related schemes, i.e., Chang et al.’s scheme [13], Wang et al.’s scheme [16] and Lin et al.’s scheme [17] were finally compared with the proposed scheme. The sizes of codebooks adopted in all schemes are 512 and the suggested optimal settings are used as given in their corresponding algorithms. Table 7 shows the comparison results for embedding 16,129 bits in different test images. For most test images, the proposed scheme achieves the optimal result compared with other schemes.
In terms of bit rate, we can see that the proposed scheme generally produces the smallest one. Although Lin et al.’s scheme gets lower bit rate for simple images such as “Airplane” and “Tiffany”, the average bit rate is 1.5% higher than that of the proposed scheme, because the proposed scheme can greatly reduce the bit rate of complex images. Compared with Wang et al.’ scheme and Chang et al.’s scheme, the reduction of bit rate is 6.4% and 18.8% respectively.
On the other hand, the embedding efficiency of our scheme has been increased in comparison with other schemes. Since under the same embedding capacity, the embedding efficiency is only determined by the total length of the output code stream, therefore, a data hiding scheme with low bit rate will achieve a high embedding efficiency. In our scheme, the average embedding efficiency for embedding 16,129 bits is nearly 13.7%, which outperforms all the other schemes: Chang et al.’s scheme (11.1%), Wang et al.’s scheme (12.8%), and Lin et al.’s scheme (13.5%).
In short, the above experiments demonstrate that the proposed algorithm has a better performance in both embedding capacity and bit rate. Additionally, in certain test images or especially in complex images, our scheme achieves a lower bit rate than other schemes because large amount of index values are smaller than T due to the SCS-based SMVQ technique.
4 Conclusion
We propose a new reversible data hiding method for SMVQ compressed images. By employing the SCS-based SMVQ technique, our scheme achieves a higher embedding capacity with lower bit rate than related schemes. Since the SCS method is used to further reduce the index values of SMVQ index table, the proposed embedding scheme only needs few bits to encode the indices, thus yielding more space for secret data hiding. Though a 2-bit flag is required to distinguish the types of indices, we can effectively reduce the bit rate of the final code stream because large amounts of index values are smaller than T, and the indices belonging to [T, T a − 1] are used to reduce the code length, with no secret data embedded. Several experiments were conducted with 512 codewords to evaluate the performance of proposed scheme. The comparison results show that the proposed scheme outperforms other schemes both in compression rate and embedding efficiency. Especially, for the complex images “Baboon” and “Boat”, the embedding efficiency is improved by 1.8% and 5.2% compared with Lin et al.’s scheme [17]. Moreover, the proposed scheme maintains the same visual quality as that of VQ compression.
References
Rudder, A., Kieu, T.D.: A lossless data hiding scheme for VQ indexes based on joint neighboring coding. KSII Trans. Internet Inform. Syst. 9(8), 2984–3004 (2015)
Li, X., Zhou, Q.: Histogram modification data hiding using chaotic sequence. In: Wang, W. (ed.) Mechatronics and Automatic Control Systems. LNEE, vol. 237, pp. 875–882. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-01273-5_98
Li, X.L., et al.: General framework to histogram-shifting-based reversible data hiding. IEEE Trans. Image Process. 22(6), 2181–2191 (2013)
Hong, W., Chen, T.S., Luo, C.W.: Data embedding using pixel value differencing and diamond encoding with multiple-base notational system. J. Syst. Softw. 85(5), 1166–1175 (2012)
Hong, W., Chen, T.S.: A novel data embedding method using adaptive pixel pair matching. IEEE Trans. Inf. Forensics Secur. 7(1), 176–184 (2012)
Hong, W.: Adaptive image data hiding in edges using patched reference table and pair-wise embedding technique. Inform. Sci. 221(1), 473–489 (2013)
Fang, H., Zhou, Q., Li, K.J.: Robust watermarking scheme for multispectral images using discrete wavelet transform and tucker decomposition. J. Comput. 8(11), 2844–2850 (2013)
Su, P.C., Chang, Y.C., Wu, C.Y.: Geometrically resilient digital image watermarking by using interest point extraction and extended pilot signals. IEEE Trans. Inf. Forensics Secur. 8(12), 1897–1908 (2013)
Wang, W.J., Huang, C.T., Wang, S.J.: VQ applications in steganographic data hiding upon multimedia images. IEEE Syst. J. 5(4), 528–537 (2011)
Guo, J.M., Liu, Y.F.: High capacity data hiding for error-diffused block truncation coding. IEEE Trans. Image Process. 21(12), 4808–4818 (2012)
Guo, J.M., Tsai, J.J.: Reversible data hiding in low complexity and high quality compression scheme. Digit. Signal Proc. 22(5), 776–785 (2012)
Mobasseri, B.G., et al.: Data embedding in JPEG bit stream by code mapping. IEEE Trans. Image Process. 19(4), 958–966 (2010)
Chang, C.C., Kieu, T.D., Wu, W.C.: A lossless data embedding technique by joint neighboring coding. Pattern Recogn. 42(7), 1597–1603 (2009)
Yang, C.H., et al.: Huffman-code strategies to improve MFCVQ-based reversible data hiding for VQ indexes. J. Syst. Softw. 84(3), 388–396 (2011)
Chang, C.C., Nguyen, T.S., Lin, C.C.: A reversible data hiding scheme for VQ indices using locally adaptive coding. J. Vis. Commun. Image Represent. 22(7), 664–672 (2011)
Wang, W.J., et al.: Data embedding for vector quantization image processing on the basis of adjoining state-codebook mapping. Inform. Sci. 246(14), 69–82 (2013)
Lin, C.C., Liu, X.L., Yuan, S.M.: Reversible data hiding for VQ-compressed images based on search-order coding and state-codebook mapping. Inform. Sci. 293, 314–326 (2015)
Acknowledgement
This work is supported by the National Natural Science Foundation of China (No. 61372175).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Liu, Jn., Zhou, Q., Hu, Yl., Wei, Jy. (2017). A New SMVQ-Based Reversible Data Hiding Scheme Using State-Codebook Sorting. In: Zhao, Y., Kong, X., Taubman, D. (eds) Image and Graphics. ICIG 2017. Lecture Notes in Computer Science(), vol 10668. Springer, Cham. https://doi.org/10.1007/978-3-319-71598-8_48
Download citation
DOI: https://doi.org/10.1007/978-3-319-71598-8_48
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71597-1
Online ISBN: 978-3-319-71598-8
eBook Packages: Computer ScienceComputer Science (R0)
