
Abstract
Concomitant with the rapid advancements in information technology, the issue of secure data transmission through the Internet has become increasingly important. Hiding data in images is an important technique in digital media; it facilitates confidential data transfer to receivers and renders the data virtually undetectable by third parties. In this paper, a novel reversible data hiding scheme based on vector quantization (VQ) is proposed. First, codebook sorting is employed to enhance the correlation of neighbor indices and then a prediction error technique is used to generate a high peak histogram. The secret data are then embedded via histogram shifting of prediction errors. Our proposed scheme utilizes only one codebook, unlike other similar methods, and the stego carrier (index table after embedding) can be decompressed without secret data extraction to avoid detection by third parties. Experimental results indicate that the proposed scheme has better visual image quality and greater embedding capacity than recently proposed schemes of a similar nature.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
The rapid improvement of broadband networks has resulted in people easily sharing information via networks and data security becoming a critical research issue. Cryptography and steganography are the techniques currently utilized to deal with the issue of data transmission security [14]. Cryptography uses encryption algorithms to transform data into meaningless code. However, its “promiscuous” feature can easily attract the attention of third parties who, even though they may not be able to quickly decrypt the codes, can sabotage the integrity and availability of the data, and thus make it difficult for receivers to obtain accurate information. Steganography, also called data hiding, is another solution that facilitates data transmission with high security. In steganography, the secret data is embedded into the cover carrier, generating a stego carrier that is received and decoded at the receiving side. Because the cover and stego carriers are similar, the secret data are virtually undetectable by third parties. A data hiding scheme is categorized as either reversible or irreversible, depending on whether the scheme accurately reverses the stego carrier to its original state after the secret data have been extracted. Data hiding can be classified on the basis of the operational domain into spatial domain [1, 3, 16, 17, 20, 22], frequency domain [9, 11, 12, 15, 25, 27, 28], or compression domain [18, 19, 26, 30]. If both efficiency and security of data transmission over the Internet are being considered, data hiding in the compression domain adequately satisfies the demand. VQ compression utilizes the tolerance of the human visual system and compresses the image while simultaneously raising the compression ratio.
Many researchers are currently researching reversible data hiding technology based on VQ. The schemes being researched can be divided into two types based on output formats: codestream and index. Codestream schemes output a combination of indices and another compression scheme [4–6], such as LAS, and uses reserved space to embed secret data. Compression rate and embedding capacity are two important measures of these kinds of schemes. The output of index schemes can further be divided into index table output and image output schemes. The index table output scheme divides the indices of the codebook into several clusters and swaps the index with the corresponding cluster for data embedding [7, 29]. In all of these methods, however, the stego carrier cannot be decompressed directly before the secret data extraction step is conducted. They also result in the decompressed image being substantially different from the original, or potentially failing the decompression process.
The stego carrier can actually be directly VQ decompressed without an extraction step, as demonstrated by Tsai [21], who proposed a reversible data hiding technology based on the histogram of VQ compression. The proposed method uses the histogram data hiding technology proposed by Ni et al. [16], which uses the indices to replace Ni’s pixel values. Because the histogram indices of a natural image undergoing VQ compression are discretely dispersed, the concept of prediction is introduced. Based on this concept, the image blocks outside the first row and first column are complemented with Side Match Vector Quantization (SMVQ) [10] codes so that most of the indices approach zero to make a histogram with a peak point, which is conducive to data hiding. However, despite the advantage of concentrated indices, SMVQ requires a separate state codebook in each image block, which increases computation cost because of the complex calculations involved.
In general, a data hiding scheme should be considered in terms of its imperceptibility, robustness, and capacity. However, there is a trade-off between these three properties [2]. Of the three types of output schemes above, the image output scheme provides the lowest capacity. However, the stego carrier of the codestream and index table schemes cannot generate the normal VQ image after VQ decompression; the result obtained is singular and an easy target for eavesdroppers because these schemes have difficulty satisfying the imperceptibility requirement. In some essential scenarios, such as military intelligence transmission, the issue of security is the highest priority. In such cases, where imperceptibility is more important than the other properties, the image output scheme is the most suitable scheme.
In this paper, a reversible data hiding scheme based on VQ indices with image output is proposed. We use only one codebook to improve the complex computation of SMVQ. Furthermore, it is combined with the least difference sorting algorithm and prediction error histogram to increase its embedding capacity. In addition, the output stego carrier can be decompressed directly without secret data extraction. Experimental results indicate that the proposed scheme can provide better image quality and higher data hiding capacity than conventional schemes.
The remainder of this paper is organized as follows. Section 2 gives an overview of related work. Section 3 outlines the research method used in our study. Section 4 discusses the experimental results obtained, and Section 5 concludes this paper.
2 Related work
2.1 Reversible data hiding technology with histogram shifting of prediction error
Prediction error (PE) is the difference between the original pixel value and the predicted pixel value produced by a predictor. Because PE significantly approaches zero, its statistics histogram can produce higher peak point volumes. Compared with conventional histogram shifting, PE based histogram shifting offers obvious higher data hiding capacity. The following steps in a procedure proposed by Hong et al. [8], in which a median edge detection (MED) predictor is applied to the histogram shifting of PE, illustrates the technique:
-
Step 1
Generate an empty prediction vector (PI) of the same size as the cover image (I), and copy the cover image’s pixel values in the first row and first column to the prediction vector.
-
Step 2
Replace the values in the prediction vector (PI), starting from PI 2,2 , on the raster scanning sequence, with the predicted pixel values (x) generated by MED; the predicted pixel value is calculated as follows:

-
Step 3
Calculate the PE e = I − PI
-
Step 4
If e = 0 or −1, then go to Step 5 for data hiding; otherwise, go to Step 6 for pixel value shifting.
-
Step 5
w represents one bit of the information to be hidden by the following rule:
-
if e = 0, do right-shift embedding, e ' = e + w
-
if e = −1, do left-shift embedding, e ' = e − w
-
-
Step 6
If e > 0, then e ' = e + 1; if e < −1, then e ' = e − 1.
-
Step 7
Generate stego image I ' = PI + e '
Because the PE based histogram has a vast number of zeroes, its resulting steep distribution can be complemented with multiple peak points for secrecy embedding. It is obvious that this approach has a higher data hiding capacity than the one proposed by Ni et al. [16].

2.2 Histogram-based reversible data hiding for VQ image compression
VQ was proposed by Gray [13] in 1980. To encode an image, it divides the image into many equal-size non-overlapping blocks, and then chooses appropriate indices from a codebook to represent the image blocks and to complete the data compression. The decoding process replaces each index used with corresponding codewords to get the compression image. Tsai [21] applied the histogram-based reversible data hiding technique to the VQ compression image, which outputs an index table that is used to generate the histogram for the secret data embedding. In addition, the SMVQ concept is also applied. SMVQ uses the similar-quality characteristic of adjacent pixels, and thus produces, by prediction, a state codebook other than the original codebook that is suitable for the predictive image block (residual block). This approach generates a state codebook for each residual block, which in turn uses its own state codebook to generate its corresponding index table. Because every state codebook is made to fit its corresponding image block, the indices approach zero to form a histogram with the peak point also approaching zero. Further, because the histogram-based reversible data hiding technology uses the peak point for embedding, the SMVQ index is more suitable than the conventional VQ index in this application. The embedding algorithm is as follows:
2.2.1 Embedding procedure
-
Input: Original image, secret data
-
Output: Stego image, peak point, zero point, intermediate point
-
Step 1
Perform SMVQ encoding.
-
Step 2
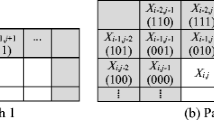
The image blocks in the first row and first column area are called the basic blocks (as shown in Fig. 1). These are the blocks used in VQ encoding (non-hiding data), while the remainder, called residual blocks, are used in SMVQ encoding.
Fig. 1 
SMVQ image blocks
-
Step 3
Use the index table resulting from the SMVQ encoding to generate a histogram.
-
Step 4
Determine the peak, intermediate, and zero points.
-
Step 5
Calculate the data hiding capacity.
-
Step 6
If the data hiding capacity is greater than the message length, go to Step 7; otherwise, return to Step 4 and look for another peak point.
-
Step 7
Based on the secret message, modify the indices of the peak, intermediate, and zero points.
-
Step 7.1
Replace the intermediate point index with the zero point index.
-
Step 7.2
Use the peak point index to hide the secret message. When the secret message is 1, the peak point index is modified such that it becomes the intermediate point index; otherwise, the peak point index remains as is.
-
Step 7.1
-
Step 8
Record the positions of the peak, intermediate, and zero points (called extra information), and send them to the receiving side.
-
Step 1

2.2.2 Extraction and restoration procedure
-
Step 1
Receive the data hiding index table and extra information.
-
Step 2
Compare the index table from left to right and from top to bottom.
-
Step 2.1
If the index matches the peak point value, extract secret message zero, and leave the index unchanged.
-
Step 2.2
If the index matches the intermediate point value, extract secret message one, and then restore the index back to the peak point value.
-
Step 2.3
If the index matches the zero point, restore the index back to the intermediate point.
-
Step 2.1
3 The proposed scheme
Because the VQ image-based data hiding technology uses the post-encoding index table to hide the secret message, the relationship of the block indices directly affects the data hiding capacity and image quality. Adjustment of the index is closely related to the codebook and, as a result, codebook sorting is a key factor in this scheme. The approach proposed by Tsai [21] is an application of SMVQ encoding, which re-sorts the codebook of every residual block to form a state codebook. Consequently, most of the image blocks have their post-encoding indices approaching zero, which is conducive to data hiding. This approach, however, requires recalculation of the corresponding codewords in the codebook of every residual block in order to generate the same number of state codebooks as number of residual blocks, which requires massive amounts of computation. For example, assume that the natural image’s size is 512 × 512 pixels, the codebook size is 256, and the image is cut into 4 × 4 blocks, then there will be 28903168 (127 × 127 × 256 × 7) calculations for a total of 16130 (1 + 127 × 127) codebooks. To rectify this situation, this paper proposes using only one VQ image-based codebook, which simplifies the calculation. Further, the data hiding capacity and image quality are also considered by applying the reversible data hiding technique. This process is illustrated in Fig. 2, which is roughly divided into the preprocessing and embedding/extraction procedures described below.

Flowchart of our proposed scheme
3.1 The preprocessing procedure
The preprocessing procedure comprises two major steps: generation of a sorted codebook, and generation of an index table. First, a sorted codebook suitable for all the image blocks of the cover image is generated and used to conduct VQ compression encoding on a natural image to produce an index table. The purpose of the sorted codebook is to make the indices of the adjacent blocks highly relevant, such that the index table can be applied to the MED predictor to generate a histogram with a large proportion of PEs that are zero. As a result, the histogram shifting PE approach can subsequently be used to embed secret data.
The LBG [13] algorithm is first used to obtain a phase codebook, from which a set of codewords with the smallest average value is taken as the first codeword set (index 0). To make the indices of adjacent blocks highly relevant to each other so that better image quality can be obtained after embedding secret data, one of the remaining codeword sets with the smallest sum of squared errors from codewords with index 0 is chosen and taken as the next codeword set (i.e., index 1), which is then used to generate a subsequent codeword index to complete the codebook sorting. The sorted codebook (SCB) is used for conventional VQ compression to produce an index table (IT). The algorithm is as follows:
-
Input: A natural image (size: M × N pixels)
-
Output: Index table IT
-
Step 1
Divide the natural image into m × n blocks, where \( {\scriptscriptstyle \raisebox{1ex}{$M$}\!\left/ \!\raisebox{-1ex}{$m$}\right.} \) and \( {\scriptscriptstyle \raisebox{1ex}{$N$}\!\left/ \!\raisebox{-1ex}{$n$}\right.} \) are integers.
-
Step 2
Use the LBG algorithm to generate a phase codebook, CB, with dimension N d and size N c .
-
Step 3
Create an empty vector, SCB, of size N c × N d .
-
Step 4
Generate the first SCB codeword set (index 0).
-
Step 4.1
From the phase codebook, identify the codeword set with the smallest average and use it as the first SCB codeword set (index 0).
-
Step 4.2
Remove this codeword set from CB.
-
Step 4.1
-
Step 5
Generate the rth SCB codeword set (r = 2 − N c ), to complete the SCB sorting.
-
Step 5.1
Square the errors of the CB codeword sets against the non-empty codewords of the last SCB row, identify the codeword set with the smallest squared error value, and use it as the rth SCB codeword set.
-
Step 5.2
Remove this codeword set from CB. Repeat Steps 5.1 and 5.2 until r = N c , which then completes the SCB sorting.
-
Step 5.1
-
Step 6
Use the sorted SCB for VQ compression of the natural image to generate index table IT.
-
Step 1
The proposed sorting scheme continually searches for the smallest codewords difference error to be the next index of the codebook. The sorting algorithm used is the selection sort algorithm and the time complexity is described in Big-O notation: O(N c 2).
3.2 The embedding procedure
The embedding procedure proposed in this paper is based on histogram shifting of PE, as illustrated in Fig. 3, where I is the primitive index, P the predictive index, E the predictive error, and I’ the post-embedding index.

Structural diagram of the error shifting method
The error shifting method first needs to define the initial position of the peak point. Assume that the right-shift peak point starts at R, the left-shift peak point starts at L, w is the secret message, and E’ is the PE after embedding. Following the embedding, the calculations are as follows:
The post-embedding index is I ' = E ' + P, and the indices after embedding are shown as follows:
The embedding steps are as follows:
-
Input: Secret message stream s (secret message bit w), index table (IT), counter (cnt_e), and initial location map (with size a \( {\scriptscriptstyle \raisebox{1ex}{$M$}\!\left/ \!\raisebox{-1ex}{$m$}\right.} \) × \( {\scriptscriptstyle \raisebox{1ex}{$N$}\!\left/ \!\raisebox{-1ex}{$n$}\right.} \) zero vector).
-
Output: Post data hiding index table (IT_stego) and extra information (peak point starting position, peak-point pairs, and location map)
-
Step 1
Calculate the PE E, and then draw the histogram of PEs:
-
First, create an empty error matrix (ET) with the same size as the index table (IT). Because blocks of the first row and first column of the error matrix (ET) are not used for data hiding, they are given the value NaN. The remaining blocks starting from ET 2,2 are fed by the raster scanning sequence to the MED predictor to produce the index P = x, and then calculate error E = I - P. Finally, finish the error matrix (ET) and draw a corresponding histogram of PEs.
-
-
Step 2
Select the peak point starting positions at R and L:
-
The peak point selection depends on the distribution of PEs on the histogram. When the quantity of PE = +1 is greater than the quantity of PE = −1, the selected peak point starting position is (0, 1), where zero is the peak point starting position of the left-shift embedding L, and one is the peak point starting position of the right-shift embedding R. When the quantity of PE = −1 is greater than the quantity of PE = +1, the selected peak point starting position is (−1, 0), where −1 is the peak point starting position of the left-shift embedding L, and zero is the peak point starting position of the right-shift embedding R.
-
-
Step 3
Determine the number of peak-point pairs, pn:
-
Adjust the number of peak-point pairs, pn, based on the data hiding capacity.
-
-
Step 4
Calculate the data hiding capacity:
-
The data hiding capacity, cap, is the sum of the peak point values.
-
-
Step 5
Compare the data hiding capacity, cap, against the secret message volume s:
-
If cap ≥ s: pn = pn, go to Step 6;
-
Otherwise: pn = pn + 1, return to Step 3.
-
-
Step 6
Embed the secret message.
-
Step 6.1
Define the areas:
-
Embedding areas:
-
right-shift, EM R : R ≤ E < R + pn; left-shift, EM L : L ≥ E > L − pn
-
-
Overlapping areas:
-
right-shift, OV R : R + pn ≤ E < R + 2pn; left-shift, OV L : L − pn ≥ E > L − 2pn
-
-
Non-embedding areas:
-
right-shift, NEM R : E ≥ R + 2pn; left-shift, NEM L : E ≤ L − 2pn ∘
-
-
-
Step 6.2
PE E falls in the non-embedding areas, and its index remains unchanged.
-
Step 6.3
PE E falls in the overlapped areas, its index remains unchanged, and the location map is marked as one at this address.
-
Step 6.4
PE E falls in the embedding areas, the right-shift embedding index is adjusted as I ' = I + E − R + w, and the left-shift embedding index is adjusted as I ' = I + E − L − w. If overflow occurs, restore the original index and mark the location map as one at this address. After the embedding is done, increment counter cnt_e by one.
-
Step 6.1
-
Step 7
Use an arithmetic encoding method to compress the location map (LM).
-
Step 1
3.3 The extraction and restoration procedures
In the embedding process, the indices of the first row and first column of index table IT are excluded; therefore, the values of the first row and first column of the post-embedding index table IT_stego remain unchanged, while its indices starting from IT_stego 2,2 undergo MED prediction in the order of the raster scanning sequence. Because the adjacent pixels used by the MED predictor are restored, the predictive index P obtained is identical to the one obtained from the embedding calculation. The PE after the data hiding is E ' = I ' − P. The value domains of the PE that falls in the “embedding areas,” before and after the secret message is embedded, are shown in Table 1. The secret message bit w can be obtained from Eq. (1). The two scenarios are combined to form Eq. (3) below:
The primitive index I is calculated as
and for right-shift embedding, E can be obtained from Eq. (1):
Then, substituting (E ' − E) in Eqs. (4) with (5), we get
For right-shift embedding, based on Eqs. (4) and (6), the primitive index I can be calculated as
Similarly, for left-shift embedding, E can be obtained from Eq. (1):
Then, substituting (E ' − E) in Eqs. (4) into (8), we get
On the basis of Eqs. (4) and (9), the primitive index I of the left-shift embedding can be calculated as
The extraction and restoration procedure is as follows:
-
Input: Index table IT_stego after data hiding and extra information.
-
Output: Secret message s and index table IT.
-
Step 1
Use an arithmetic encoding algorithm to decompress LM.
-
Step 2
If LM i,j = 0, then IT_stego i,j remains unchanged; if LM i,j = 1, then go to Step 3.
-
Step 3
If IT_stego i,j = I ', then use the MED predictor to generate the predictive index P, and then calculate the PE E’.
-
Step 4
Extract the secret message and restore the index table.
-
Step 4.1
Define areas:
-
Embedding areas:
-
right-shift, EMD R ; R ≤ E ' < R + 2pn; left-shift, EMD L : L ≥ E ' > L − 2pn
-
-
Non-embedding areas:
-
right-shift, NEMD R : E ' ≥ R + 2pn; left-shift, NEMD L : E ' ≤ L − 2pn ∘.
-
-
-
Step 4.2
PE E’ falls in the “non- embedding” areas, thus the index remains unchanged.
-
Step 4.3
PE E’ falls in the “embedding areas,” so the index is right-shifted to the embedding areas and can be restored to its primitive value using Eq. (7), \( I=I\hbox{'}-\left\lceil \frac{E\hbox{'}-R}{2}\right\rceil \), and the secret message can be extracted using Eq. (3), w = mod(E ' + R, 2). The index left-shifted to the embedding area can be restored to its primitive value using Eq. (10), \( I=I\hbox{'}-\left\lfloor \frac{E\hbox{'}-L}{2}\right\rfloor \), and the secret message can be extracted using Eq. (3), w = mod(E ' + L, 2).
-
Step 4.1
-
Step 1
4 Results and discussion
To verify the efficacy of the method proposed in this paper, we conducted experiments using six 8-bit grayscale images, 512 × 512 pixels in size. The images were labeled Lena, Baboon, Tiffany, Pepper, Airplane, and Boat. We first divided each of the images into blocks of size m × n = 4 × 4 pixels (codebook dimension, N d = 16), and then used the LBG algorithm to generate a primitive codebook of size N c = 256. The codebook then underwent the smallest squaring error sorting to get the sorted codebook (hereafter referred to as codebook) to be used in the experiment. The codebook then underwent VQ encoding of its corresponding image to get the cover image and its index table. The cover images are shown in Table 2, and the index table’s histogram of the PE of Lena is shown in Fig. 4. The same random number seed was subsequently used to generate random bit streaming to simulate secret messages and subsequent embedding, extraction, and restoration operations. The experiment comprised several categories: data hiding capacity, image visual quality, size of extra information, and optimization. They are described below.

Index table’s histogram of PE after VQ encoding of the Lena image
Because the histogram of PEs has a peak in the middle and steep drops on both sides (see Fig. 4), we took the peak point starting from error value zero, and stretched to both sides based on the data hiding capacity. The more pairs of peak-points there are, the greater the data hiding space. However, any increase in the peak-point pairs also increases the number of index shifts and accompanying overflows, causing deterioration of the image quality. The steep dropping of the two sides of the histogram generates overflows that make data hiding impossible. We used peak-point pairs ranging from one to 10 and obtained the experimental results shown in Table 3(a), along with the corresponding graph shown in Fig. 5. As a result, when the number of peak-point pairs increases, the growth in the data hiding capacity slows and becomes flat.

Incremental curves of data hiding capacity
The quality of an embedded image is subjectively judged by human eyes; however, it should also be scientifically and objectively assessed via digitized Peak-Signal-to-Noise-Ratio (PSNR) measures according to Eq. (11), and structural similarity (SSIM) [23, 24] according to Eq. (12). The PSNR and SSIM values are the calculated discrepancies between the cover image and the stego image:
The mean square error (MSE) is defined as \( MSE=\left(\frac{1}{M\times N}\right){{\displaystyle \sum_{i=1}^M{\displaystyle \sum_{j=1}^N\left({x}_{i,j}-x{\hbox{'}}_{i,j}\right)}}}^2 \), where M and N represent the length and width of the image in terms of pixels, x i,j is the pixel value at coordinate (i, j) of the cover image, and x ' i,j is the pixel value at coordinate (i, j) of the stego image. In the SSIM equation, the two patches, x and y, correspond to the same spatial window of images X and Y, respectively. Further, μ x denotes the mean of x, σ x denotes the standard deviation of x, σ xy is the covariance of x and y, and C 1 and C 2 are small positive constants.
Table 4 shows the stego images generated from the corresponding cover images that underwent the VQ encoding process proposed in this paper. The PSNR and SSIM values are shown in Table 3(b), and the stego images’ visual quality and peak point curves are shown in Fig. 6.

Curves of visual image qualities of the stego images
The method proposed in this paper has the PE E falling in the “overlapping” zone and the indices to the embedded secret messages overflowing. To rectify this situation, the LM is used to record the locations of the indices, which are then compressed via arithmetic encoding to produce extra information. The extra information is sent to the receiver via a different path for security reasons, and is used by the receiving side to extract the secret messages from the stego image and restore the cover image. The sizes of the extra information are shown in Table 3(c).
The method proposed in this paper considers the impact of data hiding capacity, visual image quality, and the size of extra information on overall performance. A compromise is made between the data hiding capacity and the visual image quality, while the size of the extra information fluctuates irregularly depending on the number of peak-point pairs and overflows. The ultimate goal for the overall performance is to achieve the largest data hiding capacity (C), high visual image quality (Q), and small extra information size (E). To this end, we used C x Q / E to calculate the performance of the proposed scheme, with the largest value calculated indicating the most appropriate number of peak-point pairs. The result is shown in Table 3(d).
Table 3(d) reveals that, on average, five pairs of peak-points can produce the best performance in our scenario. This result can be verified using Table 3(b), where the six stego images have their respective five peak-point pairs with PSNR values greater than 30 dB, and the average data hiding capacity of the images shown in Table 3(a) at a maximum of 8,900 bits, and an average embedding bit rate of 0.54 bit/index.
Table 5(a) compares our proposed method with the SMVQ encoding proposed by Tsai [21]—an improvement over the original VQ encoding, which has a more discrete nature. In Tsai’s method, an image is divided into blocks that undergo SMVQ encoding and the resulting indices are largely concentrated at a lower value area, where histogram shifting is used to embed secret messages, so as to increase the data hiding capacity. When the number of peak-point pairs selected is one, two, or three the method proposed in this paper has better performance in terms of data hiding capacity and stego-image quality. Table 5(b) shows the result of Tsai’s method, in which smoother image blocks are selected for better image quality in data hiding. The figures show that the performance of our proposed scheme is better than that of Tsai [21].
5 Conclusion
In this paper, we proposed a reversible data hiding scheme for VQ indices that uses histogram shifting of PE to hide secret data in the PEs of the indices. The proposed method only requires a sorted codebook for simple, fast, and efficient VQ compression to generate PEs, which are then combined with a simple predictor to form a PE based histogram with peak points concentrated on both sides of error value zeroes. Then, a peak point is determined to create, through a complex calculation process, an SMVQ data hiding capacity that is greater than that of the traditional VQ capacity. Further, the data embedding algorithm proposed in this paper can produce stego images that are virtually identical to the cover image and thus highly visually acceptable as well. Imperceptible data hiding is thus achieved. However, this proposed method comes at the price of extra information overlaps from the histogram shifting and an accompanying overflow of addresses.
Our experimental results show that when the number of peak-point pairs is five, the visual image quality can still be greater than 30 dB. For example, a 512 × 512 grayscale image with a 256 × 16 codebook has an average data hiding capacity of 8,900 bits, with an average embedding bit rate of 0.54 bit/index. We also proved that our reversible data hiding scheme for VQ indices using histogram shifting of PE performs better than the method proposed by Tsai [21] in terms of data hiding capacity and visual image quality. Our empirical evidence proves that the VQ compression scheme proposed in this paper is a simple, fast, and efficient reversible data hiding technique.
References
Al-Qershi OM, Khoo BE (2011) High capacity data hiding schemes for medical images based on difference expansion. J Syst Softw 84(1):105–112
Bender W, Gruhl D, Morimoto N, Lu A (1996) Techniques for data hiding. IBM Syst J 35:313–336. doi:10.1147/sj.353.0313
Chan CK, Cheng LM (2004) Hiding data in images by simple LSB substitution. Pattern Recognit 37:469–474. doi:10.1016/j.patcog.2003.08.007
Chang YT, Huang CC-L, Huang CC-L, Wang S (2014) Data hiding of high compression ratio in VQ indices with neighboring correlations. Multimed Tools Appl 74:1645–1666. doi:10.1007/s11042-014-2019-x
Chang CC, Kieu TD, Chou YC (2009) Reversible information hiding for VQ indices based on locally adaptive coding. J Vis Commun Image Represent 20:57–64. doi:10.1016/j.jvcir.2008.08.005
Chang C-C, Nguyen TS, Lin C-C (2011) A reversible data hiding scheme for VQ indices using locally adaptive coding. J Vis Commun Image Represent 22:664–672. doi:10.1016/j.jvcir.2011.06.005
Chang CC, Wu WC, Hu YC (2007) Lossless recovery of a VQ index table with embedded secret data. J Vis Commun Image Represent 18:207–216. doi:10.1016/j.jvcir.2006.11.005
Hong W, Chen TS, Shiu CW (2009) Reversible data hiding for high quality images using modification of prediction errors. J Syst Softw 82:1833–1842. doi:10.1016/j.jss.2009.05.051
Hsu CT, Wu JL (1999) Hidden digital watermarks in images. IEEE Trans Image Process 8:58–68. doi:10.1109/83.736686
Kim T (1992) Side match and overlap match vector quantizers for images. IEEE Trans Image Process 1:170–185. doi:10.1109/83.136594
Langelaar GC, Lagendijk RL (2001) Optimal differential energy watermarking of DCT encoded images and video. IEEE Trans Image Process 10:148–158. doi:10.1109/83.892451
Lin Y-K (2012) High capacity reversible data hiding scheme based upon discrete cosine transformation. J Syst Softw 85:2395–2404. doi:10.1016/j.jss.2012.05.032
Linde Y, Buzo A, Gray R (1980) An algorithm for vector quantizer design. IEEE Trans Commun 28:84–95. doi:10.1109/TCOM.1980.1094577
Lou DC, Liu JL (2002) Steganographic method for secure communications. Comput Secur 21:449–460. doi:10.1016/S0167-4048(02)00515-1
Mallat SG (1989) A theory for multiresolution signal decomposition: the wavelet representation. IEEE Trans Pattern Anal Mach Intell 11:674–693. doi:10.1109/34.192463
Ni ZNZ, Shi Y-QSY-Q, Ansari N, Su WSW (2006) Reversible data hiding. IEEE Trans Circuits Syst Video Technol 16:354–362. doi:10.1109/TCSVT.2006.869964
Qin C, Chang C-C, Huang Y-H, Liao L-T (2013) An inpainting-assisted reversible steganographic scheme using a histogram shifting mechanism. IEEE Trans Circuits Syst Video Technol 23:1109–1118. doi:10.1109/TCSVT.2012.2224052
Qin C, Chang CC, Chen YC (2013) Efficient reversible data hiding for VQ-compressed images based on index mapping mechanism. Signal Process 93:2687–2695. doi:10.1016/j.sigpro.2013.03.036
Qin C, Chang CC, Chiu YP (2014) A novel joint data-hiding and compression scheme based on SMVQ and image inpainting. IEEE Trans Image Process 23:969–978. doi:10.1109/TIP.2013.2260760
Tian J (2003) Reversible data embedding using a difference expansion. IEEE Trans Circuits Syst 13:890–896. doi:10.1109/TCSVT.2003.815962
Tsai P (2009) Histogram-based reversible data hiding for vector quantisation-compressed images. IET Image Process 3:100–114. doi:10.1049/iet-ipr.2007.0220
Tsai CL, Chiang HF, Fan KC, Chung CD (2005) Reversible data hiding and lossless reconstruction of binary images using pair-wise logical computation mechanism. Pattern Recognit 38:1993–2006. doi:10.1016/j.patcog.2005.03.001
Wang Z, Bovik A (2002) A universal image quality index. IEEE Signal Process Lett 9:81–84. doi:10.1109/97.995823
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13:600–612. doi:10.1109/TIP.2003.819861
Wang Y, Doherty JF, Van Dyck RE (2002) A wavelet-based watermarking algorithm for ownership verification of digital images. IEEE Trans Image Process 11:77–88. doi:10.1109/83.982816
Wang WJ, Huang CT, Wang SJ (2011) VQ applications in steganographic data hiding upon multimedia images. IEEE Syst J 5:528–537. doi:10.1109/JSYST.2011.2165603
Xuan GXG, Shi YQ, Ni ZC (2004) High capacity lossless data hiding based on integer wavelet transform. 2004 I.E. Int Symp Circuits Syst (IEEE Cat No04CH37512). doi:10.1109/ISCAS.2004.1329200
Xuan G, Zhu J, Chen J et al (2002) Distortionless data hiding based on integer wavelet transform. Electron Lett 38:1646. doi:10.1049/el:20021131
Yang CH, Lin YC (2009) Reversible data hiding of a VQ index table based on referred counts. J Vis Commun Image Represent 20:399–407. doi:10.1016/j.jvcir.2009.04.001
Yang CH, Lin YC (2010) Fractal curves to improve the reversible data embedding for VQ-indexes based on locally adaptive coding. J Vis Commun Image Represent 21:334–342. doi:10.1016/j.jvcir.2010.02.008
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflicts of interest to disclose.
Rights and permissions
About this article

Cite this article
Cheng, PH., Chang, KC. & Liu, CL. A reversible data hiding scheme for VQ indices using histogram shifting of prediction errors. Multimed Tools Appl 76, 6031–6050 (2017). https://doi.org/10.1007/s11042-015-3142-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-015-3142-z