
Abstract
We discuss a temporal text mining task on finding evolutionary patterns of topics from a collection of article revisions. To reveal the evolution of topics, we propose a novel method for finding key phrases that are bursty and significant in terms of revision histories. Then we show a time series clustering method to group phrases that have similar burst histories, where additions and deletions are separately considered, and time series is abstracted by burst detection. In clustering, we use dynamic time warping to measure the distance between time sequences of phrase frequencies. Experimental results show that our method clusters phrases into groups that actually share similar bursts which can be explained by real-world events.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Over the past decade, numerous online collaboration systems have appeared and thrived on the Internet. Prime examples include Wikipedia, Yahoo! Answers, Mechanical Turkbased systems [3]. They enlist a large number of people to supply information and solve problems. Users become the main strength of contributors. Wikipedia is an open, multilingual Internet encyclopedia written collaboratively by volunteers around the world [11], and end users can also edit articles. Each edit revision is saved and all the revisions are available to the public. We can utilize the revision history to discover trends of topics.
In this paper, we particularly focus on how representative phrases change their frequencies in revisions, to find whether bursty edits occur phrases. We further present a method for clustering phrases by similarity on bursty time series, where we expect that topics in one cluster share similar temporal patterns in edit history. One cluster may contain multiple real-world events which are related each other. Such fine-grained temporal relationship is difficult to be found on topic models over a static corpus or a temporal series of corpora.
Unlike traditional text clustering works, we solve the problem by focusing on the changes of phrase frequencies in revisions. We also discuss extraction of candidate phrases that have significant temporal features, where additions and deletions of a phrase are separately evaluated.
In Wikipedia edit history, articles of events or persons are edited over years, and edits of articles can be bursty or gentle, and the peak time can be shifted. Therefore we need to adopt a flexible function to measure temporal similarities between phrases. Major contributions of this paper are summarized below:
-
We define a number of scoring functions to find candidate phrases that are having significant temporal features, and define the cumulative phrase frequency, which is effective to obtain time series of edit activities of a phrase in articles.
-
We apply burst detection on the time series of each phrase to reduce minor details and simply the time series. Then we apply k-means to cluster phrases, where similarity is defined by burst patterns, and dynamic time warping (DTW) [2] is utilized.
2 Related Work
Kalogeratos et al. [5] proposed an algorithm to improving text clustering algorithm by term coburstiness. The algorithm first constructs a bursty term correlation graph, then applying graph partitioning technique to find clusters based on bursts and inter-burst relationships. The fundamental problem in [5] is that it is irrespective of bursts of edits. Kleinberg [6] proposed a burst model where a burst is defined as a rapid increase of a term’s frequency of occurrences. If the term frequency is encountered at an unusual high rate, then the term is labeled as ‘bursty’. The work is used to identify bursts in text stream and produce state labels of bursts. Tran et al. [10] engaged in temporal text mining domain and proposed to represent an event by entities, which is instructive for event representation during burst event detection in Wikipedia. However, though a number of research activities on burst, it is difficult to compare methods because of a lack of common procedures today. Subašic [9] build up an evaluation system for temporal text mining methods, which makes it possible to measure the effectiveness of temporal text mining for news.
3 Selecting Historically Significant Phrases
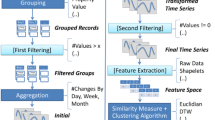
To find evolution of topics in a Wikipedia category, we need to monitor a relatively long period of edit history. We utilize key phrases to represent candidate topics. We discuss how to detect phrases that have bursty surge of edits in an article and a collection of articles. Wikipedia articles are edited repeatedly to reflect a chain of new events. Phrases occurring in such burst edits shall be detected as bursty phrases. We discuss selecting phrases that are semantically representative and having significant edit activities in their history.
3.1 POS Tagging and Filtering
In order to cluster shifty topics, we first detect key phrases that could represent topics in one article. In this step, POS (part of speech) Tagger and Chunker provided by Apache openNLP [4] is used to apply POS tagging and chunking function upon the revisions of Wikipedia articles, to produce various POS labels to each chunk.
3.2 Decay Phrase Frequency
Next we introduce a number of temporal features to refine candidate phrases. Revisions of one article are created over time, where various phrases are added or deleted, and phrase frequencies, namely the times one phrase occur in one revision, dynamically change over time. Traditional TF-IDF does not capture such temporal factors of document revisions.
In order to give weights to phrases through the whole edit history, one way is to compute the term frequency with a decay factor, like Aji [1]. However, their model ignores revision quality, and decay factor is applied based on revision counts, instead of time interval. We should give a higher weight to phrases appearing in long-lived revisions because that long-lived revisions are accepted by editors as trustworthy and high-quality. Let t(r) denote the time point of revision r and f(p, r i ) denote the frequency of phrase p in i th revision. We propose our timespan-weighted phrase frequency over history as:
Here, ρ > 0 is a decay factor, and r i is the i th revision of the article, i = 1,..,n.
We evaluate how widely a term occurs in the considered article set as below:
Here, N is the total number of articles in the corpus D, \( \left| {r \in D:p \in r} \right| \) is the number of revisions in which phrase p occurs. In case p is not in the corpus, we add one to the numerator to avoid division by zero.
3.3 Survival Rate
We define the survival rate of a phrase p in an article a as:
Here, \( \left| R \right| \) is the number of revisions of article a, scale (p) is the number of revisions of article a in the period between p appears first and p appears last, and contain(p) is the number of revisions of article a containing p. The first part measures how many revisions the phrase survived over the history, and the second part measures how long the phrase appears without interruptions during its lifespan. The survival rate is independent from text length. Phrases having long and non-interrupting lifespans are highly scored by the survival rate.
Combining the features we proposed so far, we define the following weight function for selecting historically-significant phrases:
4 Abstracting Time Series of Bursty Phrases
4.1 Time Series Modeling
Let S = [s 1 , …, s n ] be a corpus, which is a sequence of target articles \( s_{1} , \ldots ,s_{n} \). The corpus can be chosen based on certain topics, such as from a Wikipedia category.
The revision frequency of a phrase is the times the phrase occurs in one revision. As new revisions are created over time, certain phrases increase their revision frequency, while others keep stable, or decrease, and sometimes fluctuate. To detect edit activities, we should focus only on changes of revision frequency, which is caused by additions and deletions of a phrase. Let r i and r i-1 be two adjacent revisions of an identical article. The frequency difference of phrase p between revision r i and r i-1 is given by:
Here pf is the revision frequency of phrase p in the article. When \( \delta \left( {p,r_{i} } \right) > 0 \) holds, additions of p are more than deletions of p in creating revision r i from r i-1 .
Usually, the length of one articles grows over time, and the frequency of a phrase increases as well. On the other hand, deleting a phrase p can happen when p is overwritten by new contents, due to obsoleteness, error corrections, new facts, new concepts, etc. Also, edit fights between editors can cause deletions of a phrase. Furthermore, a real-world event can trigger a rush of edits, causing fluctuations of phrase frequencies. Thus additions and deletions of a phrase indicate distinct phenomena, so that we should introduce a burst detection which treats additions and deletions separately. We define the adding effect af of phrase p from revision ri to revision rj as:
We also define the deleting effect df of phrase p from revision r i to revision r j as:
Here, we assume that additions and deletions of preceding revisions i are affecting revision j with an exponential decay, based on revision number difference j−i, with the decay parameters λ 1 > 0 and λ 2 > 0. By having these separate decay parameters, we can control relative weighting between adding and deleting revisions over a phrase.
Finally, we define cumulative phrase frequency Pf(p, r j ) below, which sums up adding and deleting effects of revisions before j.
Here, r mn is the n th revision of the m th article in corpus S. We take the sum of cumulative phrase frequencies for every article containing p and for every revision in a time unit of one week, into one element Pf(p, r ij ), and construct the time series PF(p, S) for temporal clustering.
4.2 Burst Detection and Time Series Abstraction
Cumulative phrase frequency captures trends of edit activities, but its time series PF(p, S) still contains noises and spikes, which makes difficult to cluster similar edit histories. To overcome this problem, we apply Kleinberg’s burst detection algorithm [6], to convert the cumulative phrase frequencies into burst levels. The burst detection algorithm finds a state sequence where each symbol b i corresponds to a burst level of non-negative integers. After burst detection, we obtain a time series TS p = [(s 1 , x 1 ), …, (s n , x n )] on phase p, where s i is the burst level at time point x i . After this time series abstraction, we can easily detect bursts co-occurring in phrases.
4.3 Temporal Clustering by Dynamic Time Warping Measure
In order to uncover the temporal dynamics of key phrases in Wikipedia, we apply the temporal clustering method dynamic time warping (DTW) [1] to the abstracted time series of edit histories. Since the time sequences on phrases have sparse and random bursts, and their durations are diverse, time shift on peaks of frequencies is necessary. The classical Euclidean distance metric which compares at exact time points is not suitable in this situation.
For a pair of phrases p and q, let TS 1 and TS 2 be their time sequences of cumulative phrase frequencies. We define the distance d(i, j) between the i th component (s 1i , x 1i ) of TS 1 and the j th component (s 2j , x 2j ) of TS 2 as d(i, j) = \( \surd \)((s 1i − s 2j )2 + (x 1i − x 2j )2). Based on the local cost matrix by d(i, j), dynamic time warping paths are calculated by dynamic programming, which yield DTW distances. We carry out k-means clustering [12], to cluster phrases having similar burst patterns. Since burst positions and durations are varying, in k-means clustering we adopt the DTW metric, instead of the Euclidean metric.
5 Experiments
To confirm the effect of cumulative phrase frequency, we present in Fig. 1 the result on phrase “airstrikes,” which is in the candidate phrases selected by the weighting function in Sect. 3, from article “American-led intervention in Syria.”

Detected bursts of “airstrikes” with both effects in “American-led intervention in Syria” (Color figure online)
The red curve in Fig. 1 shows burst levels detected on cumulative phrase frequencies, where additions and deletions are evaluated separately with decay parameters, while the blue curve shows burst levels detected on changes of raw phrase frequencies. We can find that the red curve has more detailed burst levels and burst intervals, responding to sudden changes of phrase frequencies. On the other hand, although the blue curve has reduced noises, a number of bursts are not detected. Note that we can control the burst sensitivity by changing the decay parameters of additions and deletions.
In order to evaluate our proposing method, we select ten different categories in Wikipedia. In each category, articles are filtered by the following criteria: English language, having more than 200 revisions.
After filtering, we manually review the articles and remove articles with repeated contents or irrelevant contents. Finally, in each category 10 articles are filtered as datasets. A subset is shown in Table 1. Then we retrieved all the revisions of each article.
We selected historically significant phrases by the method described in Sect. 3, and produced time sequences by their cumulative phrase frequencies. After simplifying the time sequences by burst detection, temporal clustering was carried out.
Figure 2 and Table 2 show a part of phrases in each cluster of the temporal clustering, where phrases having similar burst patters are grouped into the same cluster.

Temporal patterns of evolutionary topics
We choose a week as a unit of time series, which gives us reasonable revision counts per unit time. Temporal clustering is applied over revisions created in the 167 weeks from Aug. 1st, 2012 to Oct. 6th, 2015. We tried several times and four clusters were observed. The burst detection step realizes removal of most of spikes and noises, so that only notable bursts are observed. In cluster 1, the patterns can be linked to real-world events. For example, in November 2012, Ted Cruz won general election. He is the first Hispanic American to serve as a U.S. Senator representing Texas. Then in 2015, he declared to join the election again so the phrase bursts at 2015 summer. Cluster 2 only has three peaks, which are related to phrases about isolated events, including illegal immigrants. In Sept. 2015, a new policy for immigration was in effect, and the relationship between this event and the burst is obvious. Cluster 3 is similar to cluster 1, but in cluster 3 two main bursts share the same level, which can be linked to political news in 2012 and 2015 on presidential elections. In cluster 4, there is no obvious burst, and most phrases in this cluster are common nouns which are quite frequent in articles.
We compared temporal clustering results without burst detection, and clustering by Euclidian distance. Due to space limitation, we show overviews of the results. When the burst detection step was omitted, the time sequences contained sharp peaks and noises. Also, when the Euclidean metric was used instead of DTW, time shifting ability was lost. In both cases, cluster qualities were inferior than Table 2, and resulting clusters contain phrases that are difficult to link to real-world events. We therefore conclude that both burst detection and DTW steps are necessary in our scheme.
6 Conclusion and Future Work
In this paper, we proposed a novel approach for capturing topical trends, by analyzing changes of phrase frequencies in edit revisions of articles. We combine burst detection and DTW for temporal clustering of phrases, where phrases that were edited around the same time periods were grouped. Bust detection of phrases are utilized to simplify phrase time series. Our experimental results show that the proposed method produces meaningful clusters of phrases that share similar burst patterns. In future, we will focus on improving clustering qualities and efficiency.
References
Aji, A., Wang, Y., Agichtein, E., et al.: Using the past to score the present: extending term weighting models through revision history analysis. In: Proceedings 19th ACM International Conference on Information and Knowledge Management, pp. 629–638 (2010)
Adwan, S., Arof, H.: On improving dynamic time warping for pattern matching. Measurement 45(6), 1609–1620 (2012)
Doan, A., Ramakrishnan, R., Halevy, A.Y.: Crowdsourcing systems on the world-wide web. Commun. ACM 54(4), 86–96 (2011)
Kalogeratos, A., Zagorisios, P., Likas, A.: Improving text stream clustering using term burstiness and co-burstiness. In: Proceedings of the 9th Hellenic Conference Artificial Intelligence, p. 16. ACM (2016)
Kleinberg, J.: Bursty and hierarchical structure in streams. Data Mining Knowl. Discov. 7(4), 373–397 (2003)
Liu, Y., Gao, Z., Iwaihara, M.: Identifying evolutionary topic temporal patterns based on bursty phrase clustering. DEIM Forum C5-1, March 2017
A Press: Wikipedia and Artificial Intelligence: An Evolving Synergy
Subašic, I., Berendt, B.: From bursty patterns to bursty facts: the effectiveness of temporal text mining for news. In: Proceedings of the ECAI (2010)
Tran, T., Ceroni, A., Georgescu, M., et al: Wikipevent: leveraging Wikipedia edit history for event detection. In: International Conference on Web Information Systems Engineering. Springer International Publishing, pp. 90–108 (2014)
Wikipedia: http://en.wikipedia.org/wiki/Wikipedia
Yang, J., Leskovec, J.: Patterns of temporal variation in online media. In: Proceedings of the 4th ACM International Conference on Web Search and Data Mining, pp. 177–186 (2011)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Liu, Y., Gao, Z., Iwaihara, M. (2017). Identifying Evolutionary Topic Temporal Patterns Based on Bursty Phrase Clustering. In: Chen, L., Jensen, C., Shahabi, C., Yang, X., Lian, X. (eds) Web and Big Data. APWeb-WAIM 2017. Lecture Notes in Computer Science(), vol 10367. Springer, Cham. https://doi.org/10.1007/978-3-319-63564-4_22
Download citation
DOI: https://doi.org/10.1007/978-3-319-63564-4_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-63563-7
Online ISBN: 978-3-319-63564-4
eBook Packages: Computer ScienceComputer Science (R0)