
Abstract
This chapter proposes a non-dominated sorting genetic algorithm (NSGAII) for the multi-objective optimal operation management (MOOM) for distributed microgrid. The main objective of the MOOM is to maximize the safe instantaneous system load, and minimizing the pollutant emission produced by the generating sources. Particle swarm optimization (PSO), genetic algorithm (GA) and NSGAII artificial intelligence techniques are studied and optimized for microgrid. The NSGAII control algorithm projected to maintain the grid voltage and angle stability within the IEEE standards while increased penetration. To construct the microgrid structure, the renewable energy sources such as wind energy, solid oxide fuel cells (SOFC) and solar photo-voltaic (SPV) are considered. The robust NSGAII based optimization algorithm continuously monitors the grid conditions and regulates grid parameters for maximizing the instantaneous safe bus loading. Power system stability indices such as fast voltage stability indices (FVSI), line stability indices (LSI) and line stability factor (LQP).
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others

Keywords
- NSGA-II
- Micro grid
- Maximizing loadability
- Stability indices
- System security
- Distributed generators
- Islanding operation
1 Introduction
The advancement in technology, economic and environmental factor influences the electrical power generation, transmission and distribution to change to new scenarios such as microgrid concept. The existing centralized vertical power system structure is actively shifting to distributed structure. In this distributed power system structure, the customer is getting more freedom to choose the distribution companies [1–4]. Figure 1 depicts the typical structure of a centralized and vertical power system.

Centralized and distributed power system architecture
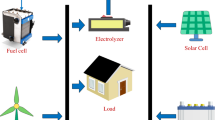
Microgrid is one of the key advancements in the power system industry. It is basically a dynamic distribution system by combining different DG networks and distinctive loads at distribution voltage level. The sources utilized in the microgrid are normally renewable/non-conventional [5–7]. Power electronics converers are the one of integral part of microgrid [8–10]. Figure 2 shows the typical structure of a microgrid equipped with different sources and security arrangements. In order to improve the reliability and security of the microgrid in the combatting power industry, need to implement highly reliable energy management system (EMS) [11–13]. Real time optimization is incorporated with the microgrid to ensure the optimal utilization of available DGs [14–18].

Microgrid architecture
The microgrid operation has been classified as islanded and grid connected. In grid connected mode of operation, the microgrid is connected to the main grid through a point of common coupling (PCC). Depending on the power exchange through the PCC, the grid connected mode can be divided into two viz power matched and power mismatched operation. In power matched operation, the power exchange through the PCC will be zero. This is most favourable economic operation of the microgrid. In power mismatched operation, the microgrid exchanges power with the distribution network. In islanded mode, the microgrid will operate as an isolated system and it will satisfy its own load requirements from the available DGs.
The islanded mode is most suitable for remote locations [19–22]. The same microgrid can be operated in grid connected or islanded mode depending on the command from the central control system [23–25]. Figure 3 shows the transfer between these two operating mode. When the microgrid is not in operation, it can be converted to grid connected mode by grid connection control or it can work as islanded mode by grid disconnection control. The microgrid can be shutdown at any time using shutdown control for maintenance purposes. The proposed NSGAII controller facilitates transfer operation between the two modes. In grid connected mode the NSGAII measure the power mismatch through the PCC and based on the power mismatch the controller absorb/deliver power to/from the main grid. In case of any emergency condition at the main grid the NSGAII controller sent a control signal for disconnecting the microgrid from the main grid to the control centre. The proposed controller enables the shutdown signal also for scheduled maintenance of the microgrid. The NSGAII optimization technique is illustrated in Sect. 3 for microgrid optimization. The MOOM based microgrid management system is intended to maximize the power penetration from the SOFC. The line flows across distribution network and voltage profile at each bus are tested for the stability analysis.

Transfer between grid connected and islanded mode
2 Microgrid Energy Management and Monitoring
The monitoring and management of microgrid serves the observation and utilization of microgrid efficiently. The typical functional architecture of EMS and monitoring software for microgrid is shown in Fig. 4. The monitored data from the DGs, energy storage (ES) and loads is used for analysis and data manipulation purposes. The grid management system is controls the entire grid to ensure the stability and economic operation. The grid management and monitoring system are working together to make the microgrid flexible. Therefore, it is the brain of the microgrid control structure [26–30].

Functional architecture of EMS and monitoring software for microgrid
2.1 Microgrid Monitoring
The function of microgrid monitoring system is to collect the data from the remote station and display the collected data on the screen situated at the centralized control centre [31–35]. The main purposes of the monitoring system are listed below,
-
Real time monitoring and visualization of supervisory control, distributed generation and the data acquisition system.
-
Service management monitoring such as power forecasting, energy storage system and tie line power.
-
Optimized dispatch of energy available.
The power flow regulation by the monitoring system depends on the system operation constraints and the energy balance constraints [36–40]. A typical monitoring system consists of PV monitoring system, wind monitoring system and micro turbine monitoring system to monitor the different DG in included in the system [41–46].
2.1.1 PV Monitoring System
The PV monitoring system provides operation information of the PV module. The data provided by the PV monitoring system can be used for comprehensive statistics, analysis and control of PV system. This monitoring system delivers the following functions.
-
i.
Real time monitoring and display of solar PV characteristics, solar power, daily power and total power profile on hourly basis.
-
ii.
Display the inverter parameters such as DC link voltage, DC link power, AC voltage, power and frequency, power factor, total power and instantaneous power.
-
iii.
Monitor the inverter operation and provide alarm indication in case of any component failure.
-
iv.
Control the start and stop of inverter to optimize the power delivery.
2.1.2 Wind Power Monitoring System
Wind power monitoring system monitors the wind power sources connected to the microgrid and provide the data for analysis, efficient control and utilization of wind power sources. The wind power monitoring system mainly intended to fulfill the following functions.
-
i.
Monitor the power generation from the wind power generation station in real time. The power monitoring system displays the total power generated, consumed from the wind power sources, daily power profile and hourly power generation profile.
-
ii.
Observe the wind turbine generator and collect both electrical and mechanical data. The monitoring system displays the AC voltage, frequency, power factor, temperature, speed of turbine and generator for analysis purposes.
-
iii.
Monitor and display the wind speed profile, pitch angle, turbine speed for the efficient operation of Maximum Power Point Tracking (MPPT) controller.
-
iv.
Adjust the power flow and control the start and stop of inverters.
2.1.3 Micro Turbine Monitoring
The operation of micro turbine is monitored in real time and provides alarm indication for any emergency. The data available from the monitoring system can be used for efficient control of the micro turbine based power system by accurate analysis and manipulation of the data. The main functions of the micro turbine monitoring system are as follows.
-
i.
Monitor the major operational data like speed, gas flows, temperature, valve pressures and display these monitored data on the screen for comprehensive statistics and analysis.
-
ii.
Monitor and display the voltage, frequency, power and power factor to ensure the efficient operation of the micro turbine.
-
iii.
Adjust the operational parameter for optimal utilization.
Similar to this manner all the distributed generation sources connected to the microgrid is monitored by the respective monitoring system. Based on these monitored and displayed data, the energy management algorithm controls the operation of the whole DGs in a coordinated manner.
2.1.4 ES Monitoring System
The objective of ES monitoring system is to monitor the energy storage system connected to the microgrid. The data collected by the monitoring system is utilized for the economical and optimal energy storage system management. The main functions handled by the ES monitoring systems are as follows.
-
i.
Monitoring and displaying the charge level, energy that can be charged, current discharge power, total charge stored and total energy discharged in real time fashion.
-
ii.
Communication and protection of the DC-DC bidirectional converter and charge controller by observing the DC voltage level, load condition and generation conditions located at remote locations.
-
iii.
Remote control of battery charging and discharging.
2.1.5 Load Monitoring
Load monitoring is one of the major functions handled by the microgrid monitoring system. The entire operation and management of the microgrid depends on the nature of load that connected to the microgrid. The load monitoring system provides the loading information for comprehensive statistics, analysis and efficient load generation balancing. The main function of load monitoring system is as follows.
-
i.
Monitor the types of load, power consumption, real and reactive power, load voltage and current.
-
ii.
Recording the loading conditions in hourly manner.
-
iii.
Provide warning alarm indication in case of overload, frequency mismatch.
2.2 Microgrid Management
Microgrid management is meant to maintain the operation stability and security of the microgrid. Figure 5 shows the functional block diagram of a microgrid EMS system. The management system improves the efficiency of the system by efficient DG forecasting, load forecasting and energy storage (ES) forecasting. The energy management system (EMS) uses historical as well as real-time data to forecast the DG, ES and loads [47–49].

Illustration of microgrid EMS
2.2.1 Forecasting
The data forecasted by the forecasting system is used for the optimization purpose by the control system; therefore accuracy of forecasting is crucial. The EMS uses historical and real-time environmental operational data for accurate forecasting of DG, ES and loads. Forecasting is one of the challenging problems in microgrid EMS due to the unpredictable nature of DGs (PV and wind) and temporal uncertainties in controllable loads (Electric vehicles). The forecasting system can be divided into DG forecasting, and load forecasting.
DG forecasting is necessary in microgrid management in order to run the microgrid economically as well as eco-friendly. In general, the DG forecasting is intended to predict short term and super short term output of a DG on the basis of optimized energy dispatch. Objective of the DG forecasting is to maximize the utilization of all the DGs connected to the microgrid. In earlier days statistical methods are used to forecast the DG output based on the trend analysis depending on the historical data. Now statistical method is replaced by the soft computing technics like, Fuzzy logic controller, PSO, NSGAII, etc.…
Load forecast is to predict the future load demand, so that the operators can predict the operation status of the network. It is a remarkable for the measure of future operation of electrical microgrid network. Forecasting load plays a major part in control, operation, and planning of the microgrid. Therefore, enhancing the forecast accuracy can play a crucial role in higher security and a superior economy operation of the microgrid. The load forecasting methods can be classified as traditional methods like regression analysis, sequential analysis and modern methods like expert system theory, neural network theory, wavelet analysis, gray system theory, fuzzy theory and combinational method.
2.2.2 Data Analysis
The characteristics of the DGs, loads, and cost effectiveness of the market data should be analysed, which is utilized to adjust the forecast and the optimization models for better performances. It is also useful for the microgrid operator to design control policies for new applications.
2.2.3 Human Machine Interface (HMI)
HMI is a PC-based program for on-demand monitoring and collect system information through microgrid communication network. This program should be capable of visualizing and archiving the collected data and receiving commands and additional information from operators. Some DGs need operator manual interpolations for starting. In this case, the command of supervisory controller should be transferred ahead of time to the HMI to inform operators to manually start the selected DG at the right time. In addition, the operator should be capable of commanding supervisory controller through HMI to exclude a DG from the microgrid control system for maintenance or include the maintained DG. Another important role of enhanced HMI is in the case of failure of supervisory controller or any special operation. In this case, HMI is used to control the system manually by operator commands.
3 Optimization Techniques in Microgrid
Optimization is meant by solving a problem by mathematical modelling with hard limitations or constraints, generalization and/or simplifications. After modelling, the problem will be solved using arithmetical tools to realize the solution for the problems [50–52]. Optimization is one of the major parts of the EMS; it optimizes the power and economically dispatches the power available from the DGs among the loads connected. Different optimization is performed by the EMS depending on the applications (power management, EV charging and vehicle to grid). The optimization is designed as nonlinear objective functions for different applications. From the optimization point of view, these optimization techniques are broadly classified into three categories [53]. The chapter is focused on mainly GA, PSO and NSGAII optimization techniques for microgrid applications with MATLAB® illustration. These Artificial intelligence based optimization techniques are inspired by the biological phenomenon. These techniques are introduced to the power system optimization area to reduce the complexity that is faced by the conventional techniques. AI techniques optimize the objective function with respect to equality and inequality constraints. Depending on the number of objective functions, AI optimization techniques are classified into single objective and multi objective optimization techniques [54–56].
3.1 Particle Swarm Optimization (PSO)
The PSO is a population based evolutionary computation technique developed by Eberhart and Kennedy in 1995 [57]. It is based on the ideas of social behavior of organisms such as animal flocking and fish schooling. Yoshida et al., proposed a particle swarm optimization (PSO) for reactive power and voltage/var control (VVC) considering voltage security assessment [58–60]. It determines an on-line VVC strategy with continuous and discrete control variables such as AVR operating values of generators, tap positions of OLTC of transformers and the number of reactive power compensation equipment. Park et al. (2005) suggested a modified particle swarm optimization (MPSO) for economic dispatch with non-smooth cost functions [61]. A position adjustment strategy is proposed to provide the solutions satisfying the inequality constraints. The equality constraint is resolved by reducing the dynamic search space. The results obtained from the proposed method are compared with those obtained by GA, tabu search (TS), evolutionary programming (EP), and numerical methods. It has shown superiority to the conventional methods. Wang et al. presented a modified particle swarm optimization (MPSO) algorithm to solve economic dispatch problem. In this approach, particles not only studies from itself and the best one but also from other individuals [62]. By this enhanced study behavior, the opportunity to find the global optimum is increased and the influence of the initial position of the particles is decreased. The particle also adjusts its velocity according to two extremes. One is the best position of its own and the other is not always the best one of the group, but selected randomly from the group. Vlachogiannis and Lee formulated the multi-objective optimization problem by considering generators power flow contribution in transmission line and calculates using a parallel vector evaluated particle swarm optimization (VEPSO) algorithm. VEPSO accounts for nonlinear characteristics of the generators and lines. The contributions of generators are modeled as positions of agents in swarms. Generator constraints such as prohibited operating zones and line thermal limits are considered. It can obtain precise solutions compared to analytical methods [63].
PSO has its essence in social psychology, artificial life, as well as in computer science and engineering. In PSO, the population is termed as “swarm” and the individual in the swarm is termed as “particle”. Each particle is represented by its position, and velocity in n-dimensional search space. The particles fly through the problem hyperspace with some given initial velocities. In each iteration process, the particles’ velocities are stochastically adjusted in consideration of the historical best position of the particles. Thus, the movement of each particle naturally results to an optimal or near-optimal solution. The particle has memory, and every particle keeps track of its previous finest position and the comparable fitness value. The fitness value is also stored and this value is termed as P best. When a particle captures all the population as its topological neighbors, the best value is a global best and is termed as G best. After determining the two best values, both velocity and positions of the particle are updated according to Eqs. (1) and (2). Figure 6 shows the basic flowchart of the PSO technique [64–69]. Figures 6 and 7 shows the basic MATLAB® implementation of PSO algorithm used for wind power maximization technique in microgrid (Fig. 8).

PSO flowchart

PSO running optimization

PSO converging
3.2 Genetic Algorithm (GA)
A genetic algorithm (GA) is a search and enhancement strategy which works by imitating the evolutionary standards and chromosomal handling in common hereditary qualities. GA starts its search in a random manner as a rule coded in double strings. Each iteration is relegated a fitness which is straightforwardly identified with the target dimensions of the search. From there on, the number of inhabitants in arrangements is altered to another population by applying three operators like to normal hereditary operator reproduction, crossover, and mutation. It works iteratively by progressively applying these three operators in every generation till an end paradigm is fulfilled. GAs has been effectively applied to various optimization problems due to their straightforwardness and global approach. (Fig. 9)

MATLAB® implementation of Genetic Algorithm
-
(i)
Basic Concepts and working principle
The GA is an iterative technique and works with a self-contained arrangement in iteration. GA works with various solutions (known as population) in the every iteration. A flowchart of the working standard of a basic GA is depicted in Fig. 10. Without any knowledge of the problem, GA starts its search from a random population of solutions. If a termination criterion is not satisfied, three different operators—reproduction, crossover and mutation—are applied to update the population of strings. One iteration of these three operators is known as a generation in the case GAs. Since the representation of a solution in a GA is like a characteristic chromosome and GA operators are like genetic operators, the above method is known as a GA. Figure 11 shows the basic working principle and steps involved in GA.

GA flowchart

Anatomy of GA
-
(ii)
Various Steps involved in GA Procedure
The various steps that are included in the GA process are representation, reproduction, crossover and mutation [70–74].
-
(a)
Representation
The first step in the GA is the represent the codes in the form of binary string as given in the example below.
The ith problem variable is coded in a binary substring of length l i, the total number of alternatives allowed in that variable is \(2^{{l_{i} }}\). The lower bound solution x min i is represented by solution (0, 0, 0 … 0) and the upper bound solution x max i is represented by the solution (1, 1, 1 … 1). The other substring s i decodes to a solution x i as follows:
where, DV (s i ) is the decoded value of string s i . The decoded value of the binary substring \(s \equiv (s_{l - 1} s_{l - 2} \ldots s_{2} s_{1} s_{0} )\) is calculated by \(\mathop \sum \nolimits_{j = 0}^{l - 1} 2^{j}\), where \(s_{j} \in \left\{ {0,1} \right\}\). The length of substring is usually decided by precision needed in a variable. For example if three decimal places of accuracy are needed in the ith variable, total number of alternatives in the variable must be set equal to \(2^{{l_{i} }}\) and l i can be computed as follows:
Here, the parameter \(\varepsilon_{i}\) is desired precision in ith variable. The total string length of a N variable solution is then \(l = \mathop \sum \nolimits_{i = 1}^{N} l_{i}\). In the population of, 1 bit strings are made indiscriminately (at each of positions, there is an equivalent likelihood of making a 0 or 1). Once such string is made, the principal li bits can be extricated from the complete string and relating estimation of the variable x i can be figured utilizing Eq. 4 and utilizing the lowerpicked and maximum breaking points of variable x 1. This procedure is preceded until all N-variables are gotten from complete string. Consequently, a 1-bit string speaks to a complete arrangement indicating all N variables particularly. Once these qualities are known, the objective function f(x 1, x 2, x N ), can be registered.
In a GA, every string made either in the initial population or in the resulting generation must be allotted a fitness value which is identified with objective function value. For maximization problems, a string’s fitness can be equivalent to string’s objective function value. In minimization problem, the objective is to discover an answer having least objective function value. In this way, the fitness can be figured as the negative of the goal work with comparable objective function value get larger fitness.
There are number of advantages for utilizing a string representation to code variables. In the first place, this permits a protecting between working of GA and actual problem. The same GA code can be utilized for various problems by just changing meaning of coding a string. This permits a GA to have broad pertinence. Second, a GA can exploit the likenesses in string coding to make its search quicker, a matter which is vital in working of a GA.
-
(b)
Reproduction
Reproduction (or selection) is typically the principal operator connected to a population. Reproduction chooses best strings in a population and structures a mating pool. The crucial thought is that above-normal strings are picked from the present population and copies of them are embedded in the mating pool. The normally utilized reproduction operator is the proportionate determination operator, where a string in the present population is chosen with likelihood relative to the string’s fitness. That is the ith population is generated based on a probability function f i . One approach to accomplish this proportionate choice is to utilize a roulette-wheel with the boundary set apart for every string proportionate to the string’s fitness.
-
(c)
Crossover
The crossover operator is an operator in GA which is applied next to the string in the mating pool. In this operation two strings are selected from the mating pool randomly and some portion of the strings will get exchanged to produce the new offspring. In a single crossover operation each string will cut at arbitrary points and right side of each string swaps each other as shown below:
It is fascinating to note from the development that good substrings from either parent string can be joined to frame better kid string if a fitting site is picked. Since the information of a suitable site is normally not known, an arbitrary site is generally picked. In any case, understand that the decision of an arbitrary site does not make this search operation irregular. With a random point the crossover on two 1—bit parent strings, the search can just find at most 2(i − 1) distinctive strings in the search space, while there are a sum of 2i strings in the search space. With an arbitrary space, the kids strings delivered could conceivably have a blend of good substrings from parent strings relying upon whether the intersection site falls in the proper site or not. If great strings are made by crossover; there will be more duplicates of them in the following mating pool produced by the generation operation. If great strings are not made by crossover; they won’t get by past people to come, since reproduction won’t choose poor strings for the following mating pool. In a two-point crossover operation, two irregular locales are picked. This thought can be reached out to make multi-point crossover operator and the compelling of this augmentation is known as a uniform crossover operator. In a uniform crossover for paired strings, every piece from either parent is chosen with a probability of 0.5. The fundamental motivation behind the crossover operator is to seek the parameter space. Other perspective is that the search should be performed in an approach to safeguard the data put away in the parent string maximally, on the grounds that these parent strings are occurrences of good strings chose utilizing the reproduction operator. In the single-point crossover operator search is not broad, but rather the most extreme data is saved from parent to offspring. In another ways, in the uniform crossover, the search is exceptionally broad however least data is saved amongst parent and offspring strings. On other hand the crossover probability is utilized as a part of the population. In the event that a crossover probability of p c is utilized then 100 p c % strings in the population are utilized as a part of the crossover operation and 100(1 − p c ) of the population are basically duplicated to the new population. Figure 12 shows the crossover mechanism of a GA.

Crossover mechanism of a genetic algorithm
-
(d)
Mutation
Crossover operator is fundamentally in charge of the search part of GA, even in spite of the fact that the mutation operator is likewise utilized for this reason sparingly. The mutation operator changes a1 to a0 and the other way around with a little mutation probability p m:
In the above given example the third bit is changed from 0 to 1. This transformation will affect in the new generation and the mutation operator is used to give best fitness value for the newly generated offspring.
After reproduction, crossover and mutation are applied to entire population, one generation of GA is finished. These three operators are basic and direct. The reproduction operator chooses great strings and the crossover operator recombines good substrings from two good strings together to ideally frame a superior substring. The mutation operator adjusts a string locally to ideally make a superior string. Despite the fact that none of these cases ensured and/or tried while making another population strings, it is normal that if poor strings are made they will be dispensed with by the reproduction operator in next generation to come and if good strings are made, they will be stressed. To make a speedier meeting of a GA to real problems, particular operator are frequently created and utilized, yet the above three operators depict basic operations of a GA and encourage a relatively simpler numerical treatment.
3.3 Non Dominated Sorting Genetic Algorithm II (NSGAII)
The major drawback of the PSO and GA explained in the previous sections are they are applicable to only for single objective optimization problems. As we are considering the microgrid the optimization problem will be multi objective function based. In this case the non-dominated sorting genetic algorithm ii (NSGAII) is the suitable option [75].
Basic operation
Figure 13 shows the basic operation modes of the NSGAII. The population is initialized randomly as in the case of GA. Once the population in initialized the population is sorted in light of non-domination into every front. The primary front being totally non-dominating set in the present population and the second front being ruled by the individuals in the primary front just and the front goes so on. Each individual in the every front are appointed rank (fitness) values or taking into account front in which they belongs to. Individual in primary front are given a fitness value of 1 and people in second are relegated fitness value as 2 and so on [76].

NSGAII operation modes
A crowding distance also calculated for each individual in order to make the iterative process fast. The crowding distance gives the idea about how far an individual each other. The large average crowding distance is the best indication of diversity of the search space. Based on the rank and the crowding distance the parents are selected and from these parents the offspring are produced by crossover and mutation. The newly generated population is again sorted on non-dominated manner and best individuals will select from this sorting. The basic steps involved in NSGAII is explained [77].
-
(i)
Population Initialization
The population is initialized based on the problem range and constraints if any.
-
(ii)
Non - Dominated sort
The second step is to sort the population initialized based on the rank for better population by a non-dominated sorting method. The steps involved in non-dominated sorting are described below:
-
Initialize S p = ф. This set of individuals that are being dominated by p.
-
Initialize n p = 0. The number of individuals that dominate p.
-
for each individual q in P
-
if p dominated q then
add q to the set S p i.e. S p = S p ∪ {q}
-
else if q dominates p then
increment the domination counter for p i.e. n p = n p + 1
-
-
if n p = 0 i.e. no individuals dominate p then p belongs to the first front; Set rank of individual p to one i.e. p rank = 1. Update the first front set by adding p to front one i.e. F1 = F1 ∪ {p}
-
This is carried out for all the individuals in main population P.
-
Initialize the front counter to one. i = 1
-
Following is carried out while the ith front is nonempty i.e. Fi ≠ ф.
-
Q = ∅. The set for storing the individuals for (i + 1)th front.
-
for each individual p in front Fi
-
for each individual q in Sp (Sp is the set of individuals dominated by p)
-
nq = nq − 1, decrement the domination count for individual q.
-
If nq = 0 then none of the individuals in the subsequent fronts would dominate q. Hence set q rank = i + 1. Update the set Q with individual q i.e. Q = Q ∪ q.
-
-
-
Increment the front counter by one.
-
Now the set Q is the next front and hence Fi = Q.
-
-
(iii)
Crowding Distance
Once the non-dominated sort is finished the crowding distance is allotted. Since the individuals are chosen taking into account rank and crowding distance every one of the people in the population are relegated a crowding distance value. Crowding distance is relegated front wise and looking at the crowding distance between two individuals in various fronts is meaningless. The crowing separation is ascertained as below:
-
For each front Fi, n is the number of individuals.
-
Initialize the distance to be zero for all the individuals i.e. Fi (dj) = 0, where j corresponds to the jth individual in front Fi.
-
for each objective function m
-
Sort the individuals in front Fi based on objective m i.e. I = sort(Fi, m).
-
Assign infinite distance to boundary values for each individual in Fi i.e. I (d1) = ∞ and I (dn) = ∞
-
for k = 2 to (n − 1)
$$I(d_{k} ) = I(d_{k} ) + \frac{I(k + 1)m - I(k - 1)m}{{f_{m}^{\hbox{max} } - f_{m}^{{\text{min}}} }}$$(9)-
I(k).m is the value of the mth objective function of the kth individual in I
-
-
-
The basic idea behind the crowding distance is to find out the Euclidian distance between the two individual in the same front.
-
(iv)
Selection
After initialization, non-dominated sorting and assigning crowding distance, next stage is selection using a crowding distance comparison operator (n) and the comparison process is as explained below:
-
(a)
Non-domination rank p rank i.e. individuals in front F i will have their rank as p rank = i.
-
(b)
Crowding distance Fi(dj)
-
p ≺ n q if
-
p rank < q rank or
-
if p and q belong to the same front Fi then Fi(d p ) > Fi(d q ) i.e. the crowing distance should be more.
-
-
The individuals are selected by binary tournament selection procedure using the crowd selection operator.
-
(v)
Genetic Operators
The genetic operation is carried out by simulated binary crossover and polynomial mutation.
-
(a)
Simulated binary crossover
The simulated binary crossover is inspired from nature and is mathematically given as follows.
Here, c i,k is the ith offspring with kth component, p i,k is the selected parent and β k (≥0) is a sample from, a random number generated with the probability density,
This distribution can be obtained from a uniformly sampled random number u between (0, 1). η c is the distribution index for crossover. That is
-
(b)
Polynomial Mutation
The polynomial mutation can be given mathematically as,
where, c k and p k are the offspring and parent respectively with upper bound p k u and lower bound p l u on the parent component. δ k is the small deviation as given below,
where η m is the mutation distribution index and r k is the random space between (0, 1)
-
(vi)
Recombination and Selection
The last stage of iteration is to combine the offspring with the current generation to obtain the best fitness individuals. In this process the superiority is ensured due to the involvement of all the current and previous best solutions. The new generation is filled by every front in this manner until the population size surpasses the present population size. If by including every one of the individual in front Fj the population surpasses N then individual in front Fj are chosen based on their crowding distance in the descending manner until the population size is N. By this method the process repeats generates the new generations.
This chapter explained the most efficient optimization tools that can be used for microgrid optimization purpose. Besides this a lot of tools are available in the literature (refer Table 4).
4 Illustration of NSGAII in Microgrid Application
This section illustrates the simulation of the above explained three optimization tool in modified IEEE 14 bus test system.
4.1 Microgrid Modeling
Figure 15 shows the test system used for analyzing the proposed NSGAII optimization algorithm (Fig. 14). The microgrid under the analysis consists of solar PV, fuel cell distributed generation sources and the loads under consideration are frequency dependent load, voltage dependent loads, MIX loads and PQ loads. The goal of the optimization problem is to maximize the safe instantaneous system loadability, minimize the total losses, and the total grid emission. Voltage and angle instability are the main limiting factors for synchronous operation of distributed generators hence grid control authorities are limiting the distributed generator penetration level for maintaining grid stability. Optimal DG placement methodology for maximizing the system loadability has been suggested by taking into account, small signal stability, voltage sensitivity index and line stability index.

NSGAII flowchart
The proposed algorithm for finding the optimal location of distributed generator for maximizing the system loadability has been implemented using MATLAB®. The performance of the algorithm is studied on IEEE 14 bus standard test system. The power flow analysis is carried out using Newton Raphson method. The test system used in this work is shown in Fig. 15. All per-unit quantities used in this study are on a 100-MVA base. Wind farm consisting of 300 wind turbines and 600 MVA/69 kV capacity has been connected to bus 3 as identified using wind farm placement index by creating another bus (bus 15) through a transformer of tap ratio unity. Maximum penetration of wind power can be achieved by connecting wind turbine generator at bus 3, solid oxide fuel cell (SOFC) generator is connected at bus 10 and Solar PV generator (Spv) is connected as a static generator at bus 14. Loads were modeled as static loads (constant PQ) with constant power factor, and increased according to Eqs. (1) and (2). The decision variables considered are the locations of fuel cell, voltage and angle settings of the slack buses, and voltage settings of the PV buses. All the buses of the system except the voltage controlled bus and the bus with generators are selected to be the optimal location of the fuel cell. In this case, buses 4, 5, 7, 9, 10, 11, 12 and 13 are suitable for DG placement as they already has generators on them.

Proposed microgrid
4.2 Modelling of the Robust Controller
With the knowledge of the maximum loading condition the system operator can take corrective actions to provide a maximum security margin. The load is increased in the system by:
where P Di is the base case total active loads at bus i and N b is the total number of buses in the system, λ ∈ R is a loading parameter, i.e., a scalar independent parameter that multiplies all generator and load powers.
-
(i)
Objective Function and Constraints
The optimal location and settings of SOFC is formulated as a real constrained mixed integer non-linear multi-objective optimization problem. The combined objective function is defined as
F 1 represents the objective function to maximize the system load ability given by,
F 2 represents the function to minimize the system losses given by,
F 3 represents the function to minimize the fuel cell generator and substation bus emissions [99].
The load factor λ represents the variation of system real and reactive loads P Di and Q Di , defined as in Eqs. (21) and (22) where, m is the total number of generator buses, λ = 1 indicates the base load case. The fuel cell generator and the substation bus emissions are given by [75].
where E FC is the emission of SOFC, E Grid is emission of large-scale sources (substation bus that connects to grid), NO xFC is nitrogen oxide pollutants of SOFC, SO2FC is sulphur oxide pollutants of SOFC, NO xGrid is nitrogen oxide pollutants of grid and SO2Grid is sulphur oxide pollutants of grid.
Objective function should be optimal, considering technical constraints. Figure 16 show the basic block diagram of the control strategy implemented in this work. The data from the IEEE 14 bus test system is fetched by the NSGAII controller and after manipulating the data the NSGAII is fed back the control signals to the DFIG based wind generating system to maximize the penetration.

Block diagram of the proposed control strategy
-
(ii)
Equality Constraints
The optimization problem is subjected to the equality constraints as given in Eq. (25). Total real and reactive power of the system is taken as inequality constraints. The total real and reactive power generation by each generator should be maintaining the load-generation profile.
Here \(P_{i}\) and \(Q_{i}\) are the injected real and reactive power to the system, \(P_{{G_{i} }}\) and \(Q_{{G_{i} }}\) are the real and reactive power generation, \(P_{{D_{i} }}\) and \(Q_{{D_{i} }}\) are the real and reactive power demanded by the load and \(N_{b}\) is the total number of buses.
-
(iii)
Inequality constraints
They are the limits of maximum and minimum allowable operating values of different power system parameters for stable grid operation. They include generator active power (\(P_{{G_{i} }}\)) limit, reactive power (\(Q_{{G_{i} }}\)) limit, voltage (\(V_{i}\)) limit, and phase angle (\(\delta_{i}\)) limit which are restricted as follows.
The constraint of transmission loading (\(P_{ij}^{{}}\)) i.e., line flow limit is represented as
The loading factor of each bus also consider as an inequality constrain and its limit is given by,
The loading factor should me maintain with in the safe limit in order to load the bus safely.
-
(iv)
Power System Stability Constraints
The optimization problem here is carried out by considering the stability of the entire power system. To enhance and ensure the stability of the system after implementing the control algorithm some power system constraints and indices are also incorporated with the control system.
-
(v)
Small signal stability
Small signal stability ensures the stability of the power system in S domain (Eigen value stability) [78]. For the small signal stability analysis, the power system with distributed generators is modelled as a set of differential equations and a set of algebraic equations as given below:
Here \(x,y\) represents the vector of the state variables and the vector of the algebraic variables respectively. \(f\), \(g\) are the vector of differential equations and the vector of algebraic equations.
The Eigen value analysis is carried out by the analysis of the state matrix \(A_{s}\). The state matrix \(A_{s}\) is obtained by manipulating the complete Jacobian matrix \(A_{c}\) that is defined by the linearization of the DAE system equations Eq. (19) at the equilibrium point.
The state matrix \(A_{s}\) is obtained by eliminating the algebraic variables and, thus, it is implicitly assumed that \(g_{y}\) is not singular (i.e., absence of singularity-induced bifurcations):
-
(vi)
Fast voltage stability indices (FVSI)
Fast voltage stability index (FVSI) is utilized in this paper to assure the safe bus loading [79]. The FVSI is given in Eq. (32).
Here \(Z\) represents the impedance of the system, \(Q_{j}\) represents the reactive power and \(V_{i}\) is the voltage at ith bus. The line that exhibits FVSI close to 1.00 implies that it is approaching its instability point. If FVSI goes beyond 1.00, one of the buses connected to the line will experience a sudden voltage drop leading to the collapse of the system. FVSI index incorporation in the controller assures that no bus will collapse due to overloading.
-
(vii)
Line stability index
The line stability index symbolized by \(L_{mn}\) is formulated based on a power transmission concept in a single line. The line stability index \(L_{mn}\) is given by [80],
Here \(X\) is the line reactance, \(Q_{r}\) is the reactive power at the receiving end, \(V_{s}\) is the sending end voltage, \(\theta\) is the line impedance angle, and \(\delta\) is the angle difference between the supply voltage and the receiving voltage. The value of \(L_{mn}\) must be less than 1.00 to maintain a stable system.
-
(viii)
Line stability factor
System Stability is also assured by Line Stability Factor (\(L_{QP}\)) as given in (24). The LQP should be less than 1.00 to maintain a stable system [81].
4.3 Analysis of NSGAII Optimization Method in Microgrid
Maximum load ability analysis discussed in previous section has been applied to modified IEEE 14-bus standard test system. The optimization result recorded the maximum instantaneous safe bus loading, when fuel cell was placed at bus 4. Total generation and load at maximum system loading is given in Table 1.
From the table it is obvious that with optimal placement and setting of SOFC, more load demand can be met. In the present work, for IEEE 14 bus test system 1.46 p.u additional active load i.e. an increase of 56.37% loading could be handled without driving the system into instability. Accordingly the line limit settings and slack limit settings are considered in the control algorithm.
The system active power losses for the three case studies analyzed viz. base case, base case with DG, and at maximum loading condition, is shown in Table 2. From the table it can be seen that as the system is integrated with DG, the losses are significantly reduced.
Table 3 shows the fuel cell and grid emissions for the three cases considered. The proposed robust controller is efficient to obtain an optimal solution where the emissions are the least. Voltage profile of power system with DG at bus 4 and without DG is compared in Fig. 17. The variation of voltage at each bus is studied to analyze the impact of loadability enhancement through fuel cell DG placement. The x axis indicates the bus numbers 1 through 15 and y axis represents the voltage magnitude in per unit. It can be seen that at maximum system loading the voltages are maintained within the stipulated limits of 0.9 and 1.1 p.u. Here base case indicates without any microgrid integration. Without controller indicate the operation of grid with microgrid without the proposed controller. The third case is the operation of the microgrid with the integration of proposed NSGAII controller.

Voltage profile
Figure 18 shows the generations at different buses. It can be seen that with optimal placement and setting of fuel cell at bus 4, the conventional generations can be reduced and the whole load disturbance is absorbed by the fuel cell. Bus 3 has the largest load share and the robust controller is able to accurately locate the best suitable location for placement of fuel cell at bus 4. During the maximum loading the fuel cell share 2.32 pu, from the base case value of 0.30 pu.

Generation scheduling
Figure 19 shows the maximum loadability at different buses with and without DG. It can be seen that bus 3 has the largest load share. The loading of the IEEE 14 bus test system without integration of DG can only be increased up to 1.2 times. With the optimal placement and setting of SOFC at bus 4 the loadability was able to be increased from the base case loading of 2.59 p.u to 4.9 p.u.

Load scheduling
In Fig. 20 line power flows with and without DG is shown. The line active power flows increases as the system loading is increased. The stability constraints assure that the increase in line flows are within the permissible limits as per the standards of IEEE 14-bus system.

Line flows
The stability constraints at the best compromise solution represented by their eigenvalue, FVSI, LSI and LQP are shown in Figs. 21 and 22. It is evident that the incorporation of small signal stability constraint into the robust controller assures grid stability. Also it can be seen that voltage and line stability indices (FVSI and LQP) are well within acceptable limits.

Power system stability indices

Eigen value plot
5 Summary
In this chapter, a comprehensive analysis of artificial intelligence optimization methods are used for microgrid technologies and described in details. The different challenges and steps involved in the microgrid energy management system have been reviewed. Artificial intelligence based optimization techniques such as GA, PSO and NSGAII have been studied and analyzed for the microgrid application. Among these, NSGAII algorithm is found to be suitable for the microgrid optimization due to its fast operation, which is the desirable quality for a real time controller. The NSGAII algorithm is applied to the microgrid for solving the MOOM. Power system security and stability are considered as the constraints for the optimization problem. The control algorithm maximizes the system loadability to a safe limit without violating any power system security constraint. The best location for the placement of fuel cell has been identified through the static voltage study and the grid settings by the controller. The proposed control algorithm was tested and verified on IEEE 14-bus standard test system using Newton Raphson power flow method and modal analysis. Total system losses and grid emissions are significantly reduced by the NSGAII. The voltage profile, real power flow and stability indices are plotted for stability analysis purpose. The different heuristic and meta-heuristic algorithms that can be used for the microgrid planning, optimization and management are given in Table 4.
References
Ramakumar R (2001) Role of distributed generation in reinforcing the critical electric power infrastructure. Paper presented at power engineering society winter meeting, vol 1. IEEE. pp 139–139
Lasseter RH, Paolo P (2004) Microgrid: a conceptual solution. Paper presented in power electronics specialists conference, 20 Jun 2004
Lasseter R et al (2002) The CERTS microgrid concept. White paper for Transmission Reliability Program, Office of Power Technologies, US Department of Energy, vol 2, p 30
Lasseter, Robert H (2002) Microgrids. In: Power engineering society winter meeting, Vol 1, pp 305–308
Chowdhury S, Crossley P (2009) Microgrids and active distribution networks. The Institution of Engineering and Technology
Jiayi H, Chuanwen J, Rong X (2008) A review on distributed energy resources and MicroGrid. Renew Sustain Energy Rev 12:2472–2483
Lasseter R et al (2002) The CERTS microgrid concept, white paper on integration of distributed energy resources. California Energy Commission, Office of Power Technologies-US Department of Energy, Available via, http://certs.lbl.Gov. Accessed 10 June 2016
Biczel P (2007) Power electronic converters in DC microgrid. In: IEEE proceedings of the compatibility in power electronics, 29 May 2007
Ito Y, Zhongqing Y, Akagi H (2004) DC microgrid based distribution power generation system. In: IPEMC’04: topics in power electronics. 4th International conference on power electronics and motion control, vol 3. IEEE, pp 1740–1745, Aug 2004
Arulampalam A et al (2004) Control of power electronic interfaces in distributed generation microgrids. Int J Electron 91:503–523
Momoh J (2012) Smart grid: fundamentals of design and analysis. Wiley, New York
Jiang Z, Dougal RA (2008) Hierarchical microgrid paradigm for integration of distributed energy resources. In: Power and Energy Society general meeting. Conversion and delivery of electrical energy in the 21st century
Perea E, Oyarzabal JM, Rodríguez R (2008) Definition, evolution, applications and barriers for deployment of microgrids in the energy sector. E&I Elektrotechnik and Informationstechnik 125(12):432–437
Marzband M et al (2013) Experimental evaluation of a real time energy management system for stand-alone microgrids in day-ahead markets. Appl Energy 106:365–376
Colson CM, Nehrir MH (2009) A review of challenges to real-time power management of microgrids. In: IEEE Power and Energy Society general meeting
Khodaei A, Bahramirad S, Shahidehpour M (2015) Microgrid planning under uncertainty. IEEE Trans Power Syst 30(5):2417–2425
Marzband M et al (2014) Experimental validation of a real-time energy management system using multi-period gravitational search algorithm for microgrids in islanded mode. Appl Energy 128:164–174
Narayanaswamy B, Garg VK, Jayram TS (2012) Online optimization for the smart (micro) grid. In: Proceedings of the 3rd international conference on future energy systems: where energy, computing and communication meet, May 2012
Mehrizi-Sani A, Iravani R (2010) Potential-function based control of a microgrid in islanded and grid-connected modes. IEEE Trans Power Syst 25:1883–1891
Katiraei F et al (2008) Microgrids management. IEEE Power Energ Mag 6:54–65
Katiraei F, Iravani MR, Lehn PW (2005) Micro-grid autonomous operation during and subsequent to islanding process. IEEE Trans Power Delivery 20:248–257
Hatziargyriou N (ed) (2013) Microgrids: architectures and control. Wiley, New York
Tsikalakis AG, Hatziargyriou ND (2011) Centralized control for optimizing microgrids operation. In: IEEE power and energy society general meeting
Lopes JAP, Moreira CL, Madureira AG (2006) Defining control strategies for microgrids islanded operation. IEEE Trans Power Syst 21:916–924
Dimeas AL, Hatziargyriou ND (2005) Operation of a multiagent system for microgrid control. IEEE Trans Power Syst 20:1447–1455
Sanseverino ER et al (2011) An execution, monitoring and re-planning approach for optimal energy management in microgrid. Energy 36:3429–3436
Katiraei F et al (2008) Microgrids management. IEEE Power Energy Mag 6:54–65
Vaccaro A et al (2011) An integrated framework for smart microgrids modeling, monitoring, control, communication, and verification. Proc IEEE 99:119–132
Logenthiran T et al (2010) Multi-agent system (MAS) for short-term generation scheduling of a microgrid. In: ICSET’10. IEEE international conference on sustainable energy technologies, 6 Dec
Logenthiran T et al (2012) Multiagent system for real-time operation of a microgrid in real-time digital simulator. IEEE Trans Smart Grid 3:925–933
Jian F, Li J-Q, Wu X-Y (2012) Microgrid monitoring system based on IEC 61850. High Power Converter Technol 2:008
Kanchev H et al (2010) Smart monitoring of a microgrid including gas turbines and a dispatched PV-based active generator for energy management and emissions reduction. Paper presented in IEEE PES innovative smart grid technologies conference Europe, 11 Oct 2010
Shamshiri M, Gan CK, Tan CW (2012) A review of recent development in smart grid and micro-grid laboratories. Paper presented in IEEE power engineering and optimization conference Melaka, Malaysia, 6 June 2012
Yoo B-K et al (2011) Communication architecture of the IEC 61850-based micro grid system. J Electr Eng Technol 6:605–612
Liang H et al (2012) Multiagent coordination in microgrids via wireless networks. IEEE Wirel Commun 19:14–22
Jingding R, Yanbo C, Lihua Z (2011) Discussion on monitoring scheme of distributed generation and micro-grid system. Paper presented in IEEE 4th international conference on power electronics systems and applications, 8 June 2011
Vaccaro A et al (2005) A self-organizing architecture for decentralized smart microgrids synchronization, control, and monitoring. IEEE Trans Ind Inf 11:289–298
Özdemir MT, Sönmez M, Akbal A (2014) Development of FPGA based power flow monitoring system in a microgrid. Int J Hydrogen Energy 39:8596–8603
Aung HN et al (2010) Agent-based intelligent control for real-time operation of a microgrid. Paper presented in power electronics, drives and energy systems (PEDES), 20 Dec 2010
Islam FR, Gabbar HA, Pots HR (2014) Power quality improvement of distribution network using V2G. Paper presented in international conference on smart energy grid engineering (SEGE), Canada, 27 Aug 2014
Farhangi Hassan (2010) The path of the smart grid. IEEE Power Energy Mag 8:18–28
Wilshaw AR, Pearsall NM, Hill R (1997) Installation and operation of the first city centre PV monitoring station in the United Kingdom. Sol Energy 59:19–26
Finkelstein PL et al (1986) Comparison of wind monitoring systems. Pad II: Doppley. Sodars. J Atmospheric Oceanic Technol 3:594–604
Ebrahim M, Lakov G, Oliver S (2006) Microturbine engine system having stand-alone and grid-parallel operating modes. U.S. Patent No. 7,078,825. 18 Jul 2006
Fu Q et al (2012) Microgrid generation capacity design with renewables and energy storage addressing power quality and surety. IEEE Trans Smart Grid 3:2019–2027
Zaidi AA et al (2010) Load recognition for automated demand response in microgrids. Paper presented in 36th annual conference on IEEE industrial electronics, 7 Nov 2010
Shi W et al (2014) Evaluating microgrid management and control with an implementable energy management system. Paper presented in IEEE international conference on smart grid communications (SmartGridComm), 3 Nov 2014
Katiraei Farid et al (2008) Microgrids management. IEEE Power Energ Mag 6:54–65
Molderink A et al (2010) Management and control of domestic smart grid technology. IEEE Trans Smart Grid 1:109–119
Tsikalakis AG, Hatziargyriou ND (2011) Centralized control for optimizing microgrids operation. Paper presented in IEEE power and energy society general meeting, 3 Nov 2011
Wang R-Q, Li Ke, Zhang C-H (2011) Optimization allocation of microgrid capacity based on chaotic multi-objective genetic algorithm. Power Syst Protect Control 39:16–22
Russell SJ et al (2003) Artificial intelligence: a modern approach. Prentice Hall, Upper Saddle River
Pearl J (1984) Heuristics: intelligent search strategies for computer problem solving. Addison-Wesley Publication, Boston
Schwefel H-PP (1993) Evolution and optimum seeking: the sixth generation. Wiley, New York
Lai LL et al (1997) Improved genetic algorithms for optimal power flow under both normal and contingent operation states. Int J Electr Power Energy Syst 19:287–292
Somasundaram P, Kuppusamy K, Kumudini Devi RP (2004) Evolutionary programming based security constrained optimal power flow. Electr Power Syst Res 72:137–145
Li Fu-Dong et al (2012) Optimal control in microgrid using multi-agent reinforcement learning. ISA Trans 51:743–751
Bhuvaneswari R et al (2010) Intelligent agent based auction by economic generation scheduling for microgrid operation. Paper presented in IEEE innovative smart grid technologies, 19 Jan 2010
Leitão P, Barbosa J, Trentesaux D (2012) Bio-inspired multi-agent systems for reconfigurable manufacturing systems. Eng Appl Artif Intell 25:934–944
Yoshida H et al (2000) A particle swarm optimization for reactive power and voltage control considering voltage security assessment. IEEE Trans Power Syst 15:1232–1239
Park J-B et al (2005) A particle swarm optimization for economic dispatch with non-smooth cost functions. IEEE Trans Power Syst 20:34–42
Wang C-R et al (2005) A modified particle swarm optimization algorithm and its application in optimal power flow problem. Paper presented in IEEE international conference on machine learning and cybernetics, 18 Aug 2005
Vlachogiannis JG, Lee KY (2005) Determining generator contributions to transmission system using parallel vector evaluated particle swarm optimization. IEEE Trans Power Syst 20:1765–1774
Hassan MA, Abido MA (2011) Optimal design of microgrids in autonomous and grid-connected modes using particle swarm optimization. IEEE Trans Power Electron 26:755–769
Al-Saedi Waleed et al (2012) Power quality enhancement in autonomous microgrid operation using particle swarm optimization. Int J Electr Power Energy Syst 42:139–149
Wu Z et al (2011) Economic optimal schedule of CHP microgrid system using chance constrained programming and particle swarm optimization. Paper presented in IEEE power and energy society general meeting, 24 Jul 2011
Al-Saedi W et al (2013) Power flow control in grid-connected microgrid operation using particle swarm optimization under variable load conditions. Int J Electr Power Energy Syst 49:76–85
Walters DC, Sheble GB (1993) Genetic algorithm solution of economic dispatch with valve point loading. IEEE Trans Power Syst 8:1325–1332
Chen P-H, Chang H-C (1995) Large-scale economic dispatch by genetic algorithm. IEEE Trans Power Syst 10:1919–1926
Wang R-Q, Li Ke, Zhang C-H (2011) Optimization allocation of microgrid capacity based on chaotic multi-objective genetic algorithm. Power Syst Protect Control 39:16–22
Haesens E et al (2005) Optimal placement and sizing of distributed generator units using genetic optimization algorithms. Electr Power Qual Utilisation J 11:97–104
Mohamed FA, Koivo HN (2012) Online management genetic algorithms of microgrid for residential application. Energy Convers Manag 64:562–568
Liang HZ, Gooi HB (2010) Unit commitment in microgrids by improved genetic algorithm. Paper presented in IEEE conference proceedings IPEC’10, 27 Oct 2010
Ismail MS, Moghavvemi M, Mahlia TMI (2014) Genetic algorithm based optimization on modeling and design of hybrid renewable energy systems. Energy Convers Manag 85:120–130
Mohammadi M, Hosseinian SH, Gharehpetian GB (2012) GA-based optimal sizing of microgrid and DG units under pool and hybrid electricity markets. Int J Electr Power Energy Syst 35:83–92
Nagasaka K et al (2012) A research on operation planning of multi smart micro grid. Paper presented in IEEE international conference on advanced mechatronic systems, 18 Sep 2012
Yang X et al (2013) Optimization allocation of energy storage for microgrid based on economic dispatch. Power Syst Protect Control 41:53–60
Reeves CR (1995) A genetic algorithm for flowshop sequencing. Comput Oper Res 22:5–13
Beasley JE, Chu PC (1996) A genetic algorithm for the set covering problem. Eur J Oper Res 94:392–404
Whitley D (1994) A genetic algorithm tutorial. Stat Comput 4:65–85
Deb K et al (2002) A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans Evol Comput 6:182–197
Buayai K, Ongsakul W, Mithulananthan N (2012) Multiobjective microgrid planning by NSGAII in primary distribution system. Eur Trans Electr Power 22:170–187
Hamdani TM et al (2007) Multi-objective feature selection with NSGAII. In: Proceedings of international conference on adaptive and natural computing algorithms. Springer Berlin, 11 April 2007
Michalak K (2015) Improving the NSGA-II performance with an external population. In: proceedings of international conference on intelligent data engineering and automated learning. Springer, Berlin, 14 Oct 2015
Kundur P (1994) Power system stability and control. McGraw-hill, New York
Musirin I, Abdul Rahman TK (2002) Novel fast voltage stability index (FVSI) for voltage stability analysis in power transmission system. Paper presented in IEEE students conference on research and development
Moghavvemi M, Omar FM (1998) Technique for contingency monitoring and voltage collapse prediction. IEE Proc Gener Trans Distrib 145:634–640
Mohamed A, Jasmon GB (1989) Voltage contingency selection technique for security assessment. IEE Proc C-Gener Trans Distrib 136:24–28
Logenthiran T et al (2010) Optimal sizing of an islanded microgrid using evolutionary strategy. Paper presented in IEEE 11th international conference on probabilistic methods applied to power systems (PMAPS), 14 June 2010
Kirthiga MV, Arul Daniel S, Gurunathan S (2013) A methodology for transforming an existing distribution network into a sustainable autonomous micro-grid. IEEE Trans Sustain Energy 4:31–41
Mohamed FA, Koivo HN (2008) Multiobjective genetic algorithms for online management problem of microgrid. Int Rev Electr Eng-IREE 3:46–54
Yang Y, Pei W, Qi Z (2012) Optimal sizing of renewable energy and CHP hybrid energy microgrid system. Paper presented in IEEE PES innovative smart grid technologies, 21 May 2012
Verda Vittorio, Ciano Chiara (2005) Procedures for the search of the optimal configuration of district heating networks. Int J Thermodyn 8:143–153
Basu AK, Chowdhury S, Chowdhury SP (2009) Strategic deployment of CHP-based distributed energy resources in microgrids. Paper presented in IEEE power & energy society general meeting, 26 July 2009
Mohamed FA, Koivo HN (2013) System modeling and online optimal management of microgrid using mesh adaptive direct search. Int J Electr Power Energy Syst 32:398–407
Tan S, Xu J, Kumar Panda S (2012) Optimization of distribution network incorporating microgrid using vaccine-AIS. Paper presented in IEEE 8th annual conference on Industrial Electronics Society, 25 Oct 2012
Mohamed FA, Koivo HN (2012) Multiobjective optimization using Mesh Adaptive Direct Search for power dispatch problem of microgrid. Int J Electr Power Energy Syst 42:728–735
Niknam T, Golestaneh F, Reza Malekpour A (2013) Probabilistic model of polymer exchange fuel cell power plants for hydrogen, thermal and electrical energy management. J Power Sources 229:285–298
Mohammadi S et al (2013) An adaptive modified firefly optimisation algorithm based on Hong’s point estimate method to optimal operation management in a microgrid with consideration of uncertainties. Energy 51:339–348
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this chapter
Cite this chapter
Das, V., Karuppanan, P., Karthikeyan, V., Rajasekar, S., Singh, A.K. (2017). Energy Grid Management, Optimization and Economic Analysis of Microgrid. In: Islam, F., Mamun, K., Amanullah, M. (eds) Smart Energy Grid Design for Island Countries. Green Energy and Technology. Springer, Cham. https://doi.org/10.1007/978-3-319-50197-0_10
Download citation
DOI: https://doi.org/10.1007/978-3-319-50197-0_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-50196-3
Online ISBN: 978-3-319-50197-0
eBook Packages: EnergyEnergy (R0)