
Abstract
Since edges contain symbolically important image information, their detection can be exploited for the development of an efficient image compression algorithm. This paper proposes an edge based image compression algorithm in fuzzy transform (F-transform) domain. Input image blocks are classified either as low intensity blocks, medium intensity blocks or a high intensity blocks depending on the edge image obtained using the Canny edge detection algorithm. Based on the intensity values, these blocks are compressed using F-transform. Huffman coding is then performed on compressed blocks to achieve reduced bit rate. Subjective and objective evaluations of the proposed algorithm have been made in comparisons with RFVQ, FTR, FEQ and JPEG. Results show that the proposed algorithm is an efficient image compression algorithm and also possesses low time complexity.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Problem of storage and demand of exchanging images over mobiles and internet have developed large interest of researchers in image compression algorithms. Especially high quality images with high compression ratio i.e. low bit rate is gaining advantage in various applications such as interactive TV, video conferencing, medical imaging, remote sensing etc. The main aim of image compression algorithm is to reduce the amount of data required to represent a digital image without any significant loss of visual information. This can be achieved by removing as much redundant and/or irrelevant information as possible from the image without degrading its visual quality. A number of image compression methods exists in literature. Joint photographic experts group (JPEG), JPEG2000, fuzzy based, neural networks based, optimization techniques are the commonly used image compression techniques [1–7]. However, fuzzy logic’s ability to provide smooth approximate descriptions have attracted researchers towards fuzzy based image compression methods. Fuzzy transform, motivated from fuzzy logic and system modeling, introduced by Perfilieva, possesses an important property of preserving monotonicity [8] that can be utilized significantly to improve the quality of compressed image. F-transform transforms an original function into a finite number of real numbers (called F-transform components) using fuzzy sets in such a way that universal convergence holds true.
Motivation: With the ever increasing demand of low bandwidth applications in accessing internet, images are generally exchanged at low bit rates. JPEG based on DCT is the most popularly used image compression standard. But at low bit rates, JPEG produces compressed images that often suffer from significant degradation and artifacts. Martino et al. [9] proposed an image compression method based on F-transform (FTR) that performed better than fuzzy relation equations (FEQ) based image compression and similar to JPEG for small compression rate. Later Petrosino et al. [10] proposed rough fuzzy set vector quantization (RFVQ) method of image compression that performed better than JPEG and FTR. Since F-transform has an advantage of producing a simple and unique representation of original function that makes computations faster and also has an advantage of preserving monotonicity that results in an improved quality of reconstructed compressed image, hence this paper proposes edge based image compression algorithm in F-transform domain named edgeFuzzy. The encoding of the proposed algorithm consists of following three steps:
-
1.
Edge detection using Canny algorithm: In this step, each input image block is classified into either a low intensity (LI), a medium intensity (MI) or a high intensity (HI) block using canny edge detection algorithm.
-
2.
Intensity based compression using the fuzzy transform (F-transform): The blocks classified into LI, MI and HI blocks are compressed using the F-transform algorithm.
-
3.
Huffman coding: The intensity based F-transform compressed image data is further encoded using Huffman coding technique to achieve low bit rate.
Contribution: It is well known that edges provide meaningful information present in an image. Thus, an image compression algorithm that exploits edge information is proposed. Input image blocks based on the number of edge pixels detected using canny edge detection algorithm are classified as either as LI, MI or HI blocks. Since LI blocks carry less information (because it contains less number of edge pixels) hence they can be compressed more as compared to MI and HI blocks using F-transform. Huffman coding is then performed on the compressed image, that further helps in reducing the achieved bit rate.The proposed algorithm produces a better visual quality of compressed image with well preserved edges. There is a significant improvement in the visual quality of compressed images obtained using the proposed algorithm as measured by PSNR over other state of art techniques as shown in Figs. 4, 5, 6, 7 and 8. The proposed algorithm also possess low time complexity as observed from Tables 1, 2, 3, 4, 5, 6, 7 and 8.
The rest of chapter is organized as follows: Literature review about the recent fuzzy based image compression algorithm is given in Sect. 2. F-transform based image compression is discussed in Sect. 3, and the proposed method is presented in Sect. 4. Results and discussions are provided in Sect. 5 and finally the conclusions are drawn in Sect. 6.
2 Literature Review
The process of image compression deals with the reduction of redundant and irrelevant information present in an image thereby reducing the storage space and time needed for its transmission over mobile and internet. Image compression techniques may either be lossless (reversible) or lossy (irreversible) [11]. In lossless compression techniques, compression is achieved by removing the information theoretic redundancies present in an image such that the compressed image is exactly identical to the original image without any loss of information. Run-length coding, entropy coding and dictionary coders are widely used methods for achieving lossless compression. Graphics interchange format (GIF), ZIP and JPEG-LS (based on predictive coding) are the standard lossless file formats. These techniques are widely used in medical imaging, computer aided design, video containing text etc. However, in lossy compression techniques, compression is achieved by permanently removing the psycho-visual redundancies contained in image such that the compressed image is not identical but only an approximation of the original image. Video conferencing and mobile applications are various applications using lossy image compression techniques. JPEG (based on DCT coding) is the most popularly used lossy image compression standard file format. Only lossy image compression techniques can lead to higher value of compression ratio.
Apart from providing semantically important image information, edges play an important role in image processing and computer vision. Edges contain meaningful data, hence their detection can be exploited for image compression. The main aim of edge detection algorithms is to significantly reduce the amount of data needed to represent an image, while simultaneously preserving the important structural properties of object boundaries. Du [12] proposed two algorithms for edge base image compression. First algorithm is based on transmission of SPIHT bit stream at encoder and detection of edge pixels in the reconstructed image whereas second algorithm is based on detection of edges at the encoder and their extraction followed by combination at the decoder. The clarity of edges is further improved by using edge enhancement algorithm. Desai et al. [13] proposed an edge based compression scheme by extracting edge and mean information for very low bit rate applications. Mertins [14] proposed an image compression method based on edge based wavelet transform. Edges are detected and coded as secondary information. Wavelet transform is performed in such a way that the previously detected edges are not filtered out and hence are successfully preserved in reconstructed image. Avramovic [15] presents a lossless image compression algorithm based on edge detection and local gradient. The algorithm combines the important features of median edge detector and gradient adjusted predictor. In past few years, many edge detection image compression algorithm using fuzzy logic have been developed that are more robust and flexible compared to the classical approaches. Gambhir et al. [16] proposed adaptive quantization coding based image compression algorithm. The algorithm uses fuzzy edge detector for based on entropy optimization for detecting edge pixels and modified adaptive quantization coding for compression and decompression. Petrosino et al. [10] proposed a new image compression algorithm named as rough fuzzy vector quantization (RFVQ). This method is based on the characteristics of rough fuzzy sets. Encoding is performed by exploiting the quantization capabilities of fuzzy vectors and decoding uses specific properties of these sets to reconstruct the original image blocks. Amarunnishad et al. [17] proposed Yager Involutive Fuzzy Complement Edge Operator (YIFCEO) based block truncation coding algorithm for image compression. The method uses fuzzy LBB (Logical Bit Block) for encoding the input image along with statistical parameters like mean and the standard deviation. Gambhir et al. [18] proposed an image compression algorithm based on fuzzy edge classifier and fuzzy transform. Fuzzy classifier first classifies input image blocks into either a smooth or an edge block. These blocks are further compressed and decompressed using fuzzy transform (F-transform). The algorithm relies on automatic detection of edges in images to be compressed using fuzzy classifier. Here edge detection parameters once set for an image is assumed to be working with other images. Further, encoding a block to single mean value results in loss of information. Gambhir et al. [19] also proposed an algorithm named pairFuzzy that classifies blocks using competitive fuzzy edge detection algorithm and also reduces artifact using fuzzy switched median filter.
3 Fuzzy Transform Based Image Compression
Perfilieva proposed F-transform based image compression algorithm in [8, 20, 21] and compared its performance with the performance of JPEG and fuzzy relation equations (FEQ). Fuzzy transform converts a discrete function on the closed interval [A, B] to a set of M finite real numbers called components of F-transform, using basis functions that forms the fuzzy partition of [A, B]. An inverse F-transform assigns a discrete function to these components, that approximates the original function up to a small quantity \(\epsilon \).
Fuzzy partition of the Universe:
Consider M \((M \ge 2)\) number of fixed nodes, \(x_1 \le x_2 \le x_3 \cdots \le x_M\), in a closed interval [A, B] such that \(x_1 = A\) and \(x_M =B\). The fuzzy sets \([A_1, A_2,\ldots A_M]\) identified with their membership functions \([A_1(x), A_2(x),\ldots A_M(x)]\) defined on [A, B] forms the fuzzy partition of the universe, if the following conditions hold true for \(k = 1,2,3\ldots M\).
-
1.
\(A_k(x)\) is a continuous function over the interval [A, B].
-
2.
\(A_k(x_k) = 1\) and \(A_k(x) = 0\) if \(x \notin (x_{k-1},x_{k+1})\).
-
3.
\(A_k : [A,B] \rightarrow [0,1]\) and \(\sum _{k=1}^{M}A_k (x)=1\) for all x.
-
4.
\(A_k(x)\) increases monotonically on \([x_{k-1},x_k]\) and decreases monotonically on \([x_k,x_{k+1}]\).
For equidistant set of M points, \([A_1, A_2, \ldots A_M]\) forms a uniform fuzzy partition if the following additional conditions are satisfied for all x and \(k {=} 2,\ldots M{-}1 (M{\ge }2)\):
-
a.
\(A_k(x_k-x) = A_k(x_k+x)\),
-
b.
\(A_{k+1}(x) = A_k(x-\delta )\) where \(\delta =(x_M-x_1)/(M-1)\).
3.1 Discrete Fuzzy Transform for Two Variables
Consider \((M+N)\) fixed nodes (where \(M,N \ge 2\)), \(x_1, x_2, x_3,\ldots x_M\) and \(y_1, y_2, y_3,\ldots y_N\) of a two dimensional function, f(x, y) on closed interval \([A,B] \times [C,D]\) such that \(x_1=A\), \(x_M=B\), \(y_1=C\) and \(y_N=D\). Let \([A_1, A_2, A_3, \dots A_M]\) be the fuzzy partition of [A, B] identified with their membership functions \([A_1(x), A_2(x),\ldots A_M(x)]\) such that \(A_i(x)> 0\) for \([i=1,2,3,\ldots M]\) and \([B_1, B_2, B_3,\ldots B_N]\) be the fuzzy partition of [C, D] identified with their membership functions \([B_1(y), B_2(y),\ldots B_N(y)]\) such that \(B_j(y)>0\) for \([j=1,2,3\ldots N]\). The discrete fuzzy-transform of the function f(x, y) is then defined as:
for \(k=1,2,3,\ldots m\) and \(l=1,2,3,\ldots n\).
And the inverse discrete fuzzy transform of F with respect to \(\{A_1, A_2,\ldots A_M\}\) and \(\{B_1, B_2, \ldots B_N\}\) is defined as:
for \(i = 1,2,3 \ldots M\) and \(j = 1,2,3,\ldots N\).
Let f(x, y) be an image with M rows and N columns. The discrete F-transform compresses this image f(x, y) into F-components \(F_{k,l}\) using the Eq. (1) for \(k=1,2,\dots m\) and \(l=1,2,\dots n\). The compressed image \(f_{FN}(i,j)\) can be reconstructed using related inverse F-transform using Eq. (2) for \(i=1,2,\dots M\) and \(j=1,2,\dots N\). Perfilieva and Martino [9, 20] proposed a method of lossy image compression and its reconstruction based on discrete F-transform.

Proposed method
4 Proposed Method
The proposed image compression method follows three steps:
-
1.
Edge detection using Canny algorithm
-
2.
Intensity based compression and decompression using F-transform
-
3.
Huffman coding and decoding.
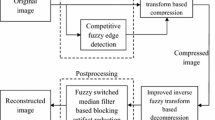
Figure 1 shows the block diagram for the proposed algorithm. The next subsections give the details of each step.

Proposed fuzzy transform based encoder
4.1 Edge Detection Using Canny Algorithm
Edge detection is a method of determining sharp discontinuities contained in an image. These discontinuities are sudden changes in pixel intensity which characterize boundaries of objects in an image. Canny edge detection [22], proposed by John F. Canny in 1986, is one of the most popular method for detecting edges. The performance of Canny detector depends upon three parameters: the width of the Gaussian filter used for smoothening the image and the two thresholds used for hysteresis threshold. Large width of the Gaussian function decreases its sensitivity to noise but at the cost of increased localization error and also some loss of detail information present in an image. The upper threshold should be set too high and the lower threshold should be set too low. Setting too low value of upper threshold increases the number of undesirable and spurious edge fragments in the final edge image and setting too high value of lower threshold results in break up of noisy edges. In MATLAB, lower threshold is taken to be 40 % of the upper threshold, if only the value of upper threshold is specified.
4.2 Intensity Based Image Compression and Decompression Using F-Transform
Monotonicity of a function is an important property preserved by F-transform that helps in improving the quality of compressed (reconstructed) image. Input image is first divided into blocks of size \(n \times n\). Based on the edge image obtained from Canny edge detection algorithm, the input image blocks are classified into LI blocks, MI blocks and HI blocks. A block with small number of edge pixels (less than T1) is classified as LI block, with high number of edge pixels (greater than T2) as HI blocks and rest (with edge pixels between T1 and T2) as MI blocks. These blocks are further compressed using F-transform into different size blocks. Since LI blocks contain less information (as it contains less edge pixels) hence can be compressed more as compared to HI blocks. For example: a LI \(n \times n\) block is compressed to \(3 \times 3\) block, a MI \(n \times n\) block is compressed to \(5 \times 5\) block and a HI \(n \times n\) block is compressed to \(7 \times 7\) block. These compressed blocks are further encoded using lossless Huffman encoding to achieve lower bit rate. Figure 2 shows the proposed encoder.
4.3 Introduction of Huffman Coding and Decoding
The compressed image is further encoded using Huffman coding scheme to achieve more compression. Huffman code is a popular method used for lossless data compression introduced by Huffman [23], is optimum in sense that this method of encoding results in shortest average length. This coding technique is also fast, easy to implement and conceptually simple.
Summary: The proposed algorithm is summarized as: The proposed algorithm edgeFuzzy, creates an edge image using Canny edge detection algorithm and classifies input image blocks as either LI, MI or HI blocks based on this edge image. Based on the intensity, these blocks are then compressed into different size blocks using the F-transform. These compressed blocks are encoded using Huffman coding that further reduces the bit rate.The proposed algorithm can produce different bit rates depending on the number of edge pixels detected by the Canny algorithm. Too many edge pixels detected by the Canny algorithm will result in low compression and hence high bit rate. Thus the bit rate achieved by the algorithm is sensitive to the edge detection algorithm. Since Huffman coding is a lossless compression technique, therefore its utilization can further reduce the bit rate without any loss of visual information at the cost of minutely increased time complexity.
5 Results and Discussions

row 1: Original images, Lenna, Bridge, House, Cameraman; Canny edge detected images at row 2: T = 0.005, row 3: T = 0.2 for the \(\sigma \) = 0.5
To reduce the storage space, bandwidth and time for uploading and downloading from internet and mobile, this paper proposes an edge based image compression algorithm in F-transform domain. The proposed algorithm exploits edge information extracted using Canny algorithm for compressing an image. Original images (row 1), Canny edge detected images with threshold T \(=\) 0.005 and width \(\sigma =1\) (row 2) and Canny edge detected images with threshold T \(=\) 0.2 and width \(\sigma =1\) is shown in Fig. 3. It is also observed that an increase in the value of threshold decreases the number of detected edge pixels. To evaluate the performance of the proposed algorithm, it has been tested on eight set of test images: Lenna, Bridge, House, Cameraman, Goldhill, peppers, Airplane and Lake of size \(256 \times 256\) as well as on eight different set of test images: Tank, Straw, Aerial, Boat, Elaine, Lake, Pentagon and Wall of size \(512\times 512\). These set of images are downloaded from SIPI image database [24]. The process of compression is done on the PC with 4 GB RAM, Intel core i7 @ 2.50 GHZ with windows 8.1, 64 bit operating system using MATLAB 8.2, R2013b. The bit rate achieved using the proposed algorithm without lossless Huffman coding (i.e. bpp), using the proposed algorithm with lossless Huffman coding (i.e. bpp_H) and using the proposed algorithm with lossless arithmetic coding (i.e. bpp_A) in place of lossless Huffman coding is summarizes in Table 1 and Table 2 for images of size \(256\times 256\). These results are obtained by dividing input images of size \(256\times 256\) into blocks of size \(16 \times 16\) and size \(8 \times 8\) respectively and reducing to \(7\times 7\) for HI block, \(5\times 5\) for MI block and \(3\times 3\) for LI block. The number of LI blocks, MI blocks and HI blocks for different images and different value of thresholds T1 and T2 is also shown in tables. It is also observed that small values of T1 and T2 increases the number of MI and HI blocks, this results in high bit-rate i.e. reduced compression. From these tables it is also observed that with the proposed algorithm different bit rate is achieved for different images at same values of T1 and T2. This is because compression using proposed method depends on the number of LI, MI and HI blocks and these number of blocks depends on the detected edge pixels. These number of detected edge pixels in turn depends on the parameters of Canny detection algorithm as well as on the nature of original image that is to be compressed. It is observed in Table 1 that the proposed algorithm achieved bit rate ranging from 0.032 bpp to 0.097 bpp approximately, while compressing original images of size \(256\times 256\) with the block size of \(16\times 16\). It is observed in Table 2 that the proposed algorithm achieved bit rate ranging from 0.118 bpp to 0.409 bpp approximately, while compressing original images of size \(256\times 256\) with the block size of \(8\times 8\). This increase in bit rate results in improvement of the visual image quality of the reconstructed image. Visual results of proposed algorithm for achieving compression of images of size \(256 \times 256\) for blocks of size \(16 \times 16\) (row 1–row 3) and for blocks of size \(8 \times 8\) (row 4–row 6) is shown in Figs. 4 and 5 respectively. Alongwith the subjective evaluation, the proposed algorithm is also objectively evaluated using various quality measures such as: PSNR, RMSE and SAD. RMSE (root mean square error) [25] measures the square root of the cumulative squarer error between the original image and the compressed image. Mathematically
where \(M\times N\) is total number of pixels in an image. I(i, j) and C(i, j) are the intensity values of original and compressed images at location (i, j) respectively.
PSNR (peak signal to noise ratio) calculates the peak signal-to-noise ratio, in dB between two images and is defined as
where L is the maximum possible value of intensity (for 8 bit image, \(L=255\)).
SAD (sum of absolute difference) is used to measure the similarity between two images and is obtained using
Low value of RMSE, high value of PSNR and low value of SAD are generally desirable. Though these measures are most commonly used measures for objective analysis but these measures does not agree with human visual perception and hence SSIM and FSIM are also used for performance evaluation.

Compressed images obtained using proposed algorithm (i) row 1 to row 3 for block size \(16\times 16\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively and (ii) row 4 to row 6 for block size \(8\times 8\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively for the test images of size \(256\times 256\)

Compressed images obtained using proposed algorithm (i) row 1 to row 3 for block size \(16\times 16\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively and (ii) row 4 to row 6 for block size \(8\times 8\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively for the test images of size \(256\times 256\)
SSIM (Structural similarity index measure) [26] measures the structural similarity between the two images and is calculated using:
where \(\mu _i, \mu _c\) and \(\sigma _i, \sigma _c\) are mean intensities and standard deviations respectively, \(K_1\) and \(K_2\) are constants as, \( 0<K_1,K_2<1\) and W is the number of local windows of the image. A large value of SSIM indicate the ability of algorithm to retain the original image.
The FSIM (feature similarity index measure) [27] measures the similarity between two images by computing locally the combination of the phase congruency (PC) [28] and gradient magnitude (GM) information using
where
The corresponding values of these measures (PSNR, RMSE, SAD, SSIM and FSIM) for various images of size \(256 \times 256\) at different code rates is shown in Table 3. It is also observed from the table, that low bit rate results degrade in quality of the reconstructed image. An idea about the time needed during coding and decoding images of size \(256\times 256\) using proposed algorithm, FTR and JPEG for achieving almost similar compression rates for various images when run on the same environment is given by Table 4. The proposed algorithm is much faster than its counterparts is also observed in Table 4.
The bit rate achieved using proposed algorithm (i.e. bpp_H) by dividing input images of size \(512\times 512\) into blocks of size \(16 \times 16\) and size \(8 \times 8\) is summarizes in Table 5 and Table 6 respectively. The results obtained using intensity based F-transform compression (i.e. bpp) with edge detection algorithm, intensity based F-transform compression with lossless arithmetic coding (i.e. bpp_A) is also given in the table. Although it is observed in results that the arithmetic coding provides better compression as compared to Huffman coding, but since the presented algorithm supports achieving faster compression at superior quality. Thus, the Huffman code is chosen over the arithmetic code. This result is in line with [29], where it is clearly proved that the Huffman code is having higher performance than arithmetic coding.

Compressed images obtained using proposed algorithm (i) row 1 to row3 for block size \(16\times 16\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively and (ii) row 4 to row 6 for block size \(8\times 8\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively for the test images of size \(512\times 512\)

Compressed images obtained using proposed algorithm (i) row 1 to row3 for block size \(16\times 16\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively and (ii) row 4 to row 6 for block size \(8\times 8\) and thresholds (0.4 and 0.5), (0.3 and 0.4) and (0.2 and 0.35) respectively for the test images of size \(512\times 512\)
Results of the proposed algorithm for achieving compression of images of size \(512\times 512\) is shown in Figs. 6 and 7. The corresponding values of these measures (PSNR, RMSE, SAD, SSIM and FSIM) for various images of size \(512 \times 512\) at different code rates is shown in Table 7. An idea about the time needed during coding and decoding images of size \(512 \times 512\) using proposed algorithm, FTR and JPEG for achieving almost similar compression rates for various images is given in Table 8. Comparison of PSNR for different compressed images, achieved using proposed method, RFVQ, FTR, FEQ and JPEG methods of compression with respect to code rate is shown in Fig. 8 for four images of size \(256 \times 256\) and four images of size \(512\times 512\). The increasing curve of the proposed method over other methods shows the superiority of the proposed algorithm. At some bit rate, the RFVQ supersedes proposed edgeFuzzy algorithm but results in higher time complexity because of large number of clusters needed.
In comparison to authors’ pairFuzzy [19] algorithm high compression ratio and high PSNR is achieved using proposed algorithm. The use of artifact reduction algorithm reduces the artifacts but at the cost of blurring the compressed image.
6 Conclusion
This chapter presents an edge based image compression algorithm in F-transform domain named edgeFuzzy. Input image blocks are first classified as LI, MI and HI blocks based on the edge image obtained using canny edge detection algorithm. Since LI blocks contain small number of edge pixels and hence less information, is therefore compressed more as compared to MI and HI blocks using F-transform. Huffman encoding is further performed on the compressed image to achieve low bit rate. Both subjective and objective evaluation shows that the proposed algorithm outperforms over other state of art image compression algorithms.

PSNR comparison of Proposed, RFVQ, FTR, FEQ and JPEG methods
References
Lossy image compression, in Encyclopedia of GIS (Springer, US, 2008)
M. Biswas, S. Kumar, T.Q. Nguyen, N. Balram, Support vector machine (SVM) based compression artifact-reduction technique. J. Soc. Inf. Display 15(8), 625–634 (2007)
S. Saha, Image compression: from DCT to wavelets: a review. ACM Crossroads 6(3), 12–21 (2000)
S. Wang, T. Lin, United coding method for compound image compression. Multimedia Tools Appl. 71(3), 1263–1282 (2014)
W. Xiaolin, X. Zhang, X. Wang, Low bit-rate image compression via adaptive down-sampling and constrained least squares upconversion. IEEE Trans. Image Process. 18(3), 552–561 (2009)
L. Xi, L. Zhang, A study of fractal image compression based on an improved genetic algorithm. Int. J. Nonlinear Sci. 3(2), 116–124 (2007)
Q. Xia, X. Li, L. Zhuo, K.M. Lam, A novel low-bit-rate image compression algorithm, in Advances in Multimedia Information Processing-PCM 2010 (Springer, 2011), pp. 100–110
I. Perfilieva, B. De Baets, Fuzzy transforms of monotone functions with application to image compression. Inf. Sci. 180(17), 3304–3315 (2010)
F. Di Martino, V. Loia, I. Perfilieva, S. Sessa, An image coding/decoding method based on direct and inverse fuzzy transforms. Int. J. Approx. Reason. 48(1), 110–131 (2008)
A. Petrosino, A. Ferone, Rough fuzzy set-based image compression. Fuzzy Sets Syst. 160(10), 1485–1506 (2009)
L. Wang, L. Jiao, W. Jiaji, G. Shi, Y. Gong, Lossy-to-lossless image compression based on multiplier-less reversible integer time domain lapped transform. Signal Process.: Image Commun. 25(8), 622–632 (2010)
D. Ke, L. Peng, New algorithms for preserving edges in low-bit-rate wavelet-based image compression. IEEJ Trans. Electr. Electron. Eng. 7(6), 539–545 (2012)
U. Desai, I. Masaki, A. Chandrakasan, B.K.P. Horn, Edge and mean based image compression, in Proceedings of IEEE Acoustics, Speech, and Signal Processing, ICASP 1996, vol. 49 (1996)
A. Mertins, Image compression via edge-based wavelet transform. Opt. Eng. 38(6), 991–1000 (1999)
A. Avramovic, Lossless compression of medical images based on gradient edge detection, in Proceedings of the 19th Telecommunications Forum (TELFOR), Belgrade (2011), pp. 1199–1202
D. Gambhir, N. Rajpal, Fuzzy edge detector based adaptive quantization image coding: FuzzAQC, in Proceedings of the Recent Advances in Information Technology (RAIT) (2012), pp. 101–106
T.M. Amarunnishad, V.K. Govindan, A.T. Mathew, Improving BTC image compression using a fuzzy complement edge operator. Signal Process. 88(12), 2989–2997 (2008)
D. Gambhir, N. Rajpal, Image coding using fuzzy edge classifier and fuzzy f-transform: dualFuzzy. Int. J. Fuzzy Comput. Modell. 1(3), 235–251 (2015)
D. Gambhir, N. Rajpal, Improved fuzzy transform based image compression and fuzzy median filter based its artifact reduction: pairfuzzy. Int. J. Mach. Learn. Cybern. 6(6), 935–952 (2015)
I. Perfilieva, Fuzzy transforms. Fuzzy Sets Syst. 15(8), 993–1023 (2006)
I. Perfilieva, R. Valásek, Data compression on the basis of fuzzy transforms, in EUSFLAT Conference (Citeseer, 2005), pp. 663–668
J. Canny, A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 6, 679–698 (1986)
D.A Huffman et al., A method for the construction of minimum redundancy codes, in Proceedings of I.R.E (1952), pp. 1099–1101
USC-SIPI image database. http://sipi.usc.edu/database/
Z. Wang, A.C. Bovik, Mean squared error: love it or leave it? a new look at signal fidelity measures. IEEE Signal Process. Mag. 26(1), 98–117 (2009)
Z. Wang, A.C. Bovik, H.R. Sheikh, E.P. Simoncelli, Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 13(4), 600–612 (2004)
L. Zhang, D. Zhang, X. Mou, FSIM: a feature similarity index for image quality assessment. IEEE Trans. Image Process. 20(8), 2378–2386 (2011)
S. Serikawa, H. Lu, L. Zhang, Maximum local energy: an effective approach for image fusion in beyond wavelet transform domain. Comput. Math. Appl. 64(5), 996–1003 (2012)
A. Shahbahrami, R. Bahrampour, M. Sabbaghi Rostami, M.A. Mobarhan, Evaluation of huffman and arithmetic algorithms for multimedia compression standards. arXiv:1109.0216 (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Gambhir, D., Rajpal, N. (2017). Edge and Fuzzy Transform Based Image Compression Algorithm: edgeFuzzy. In: Lu, H., Li, Y. (eds) Artificial Intelligence and Computer Vision. Studies in Computational Intelligence, vol 672 . Springer, Cham. https://doi.org/10.1007/978-3-319-46245-5_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-46245-5_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46244-8
Online ISBN: 978-3-319-46245-5
eBook Packages: EngineeringEngineering (R0)