
Abstract
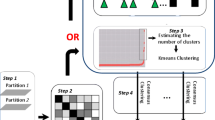
The existence of many clustering algorithms with variable performance on each dataset made the clustering task difficult. Consensus clustering tries to solve this problem by combining the partitions generated by different algorithms to build a new solution that is more stable and achieves better results. In this work, we propose a new consensus method that, unlike others, give more insight on the relations between the different partitions in the clusterings ensemble, by using the frequent closed itemsets technique, usually used for association rules discovery. Instead of generating one consensus, our method generates multiple consensuses based on varying the number of base clusterings, and links these solutions in a hierarchical representation that eases the selection of the best clustering. This hierarchical view also provides an analysis tool, for example to discover strong clusters or outlier instances.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


Keywords
References
Asur, S., Ucar, D., Parthasarathy, S.: An ensemble framework for clustering protein-protein interaction networks. Bioinformatics 23(13), i29–i40 (2007)
Ceglar, A., Roddick, J.F.: Association mining. ACM Computing Surveys 38(2) (2006)
Csardi, G., Nepusz, T.: The igraph software package for complex network research. InterJournal Complex Systems 1695 (2006). http://igraph.org
Dalton, L., Ballarin, V., Brun, M.: Clustering algorithms: on learning, validation, performance, and applications to genomics. Current Genomics 10(6), 430 (2009)
Dudoit, S., Fridlyand, J.: Bagging to improve the accuracy of a clustering procedure. Bioinformatics 19(9), 1090–1099 (2003)
Färber, I., Günnemann, S., Kriegel, H.P., Kröger, P., Müller, E., Schubert, E., Seidl, T., Zimek, A.: On using class-labels in evaluation of clusterings. In: KDD MultiClust International Workshop on Discovering, Summarizing and Using Multiple Clusterings, p. 1 (2010)
Fern, X.Z., Brodley, C.E.: Solving cluster ensemble problems by bipartite graph partitioning. In: Proceedings of the Twenty-First International Conference on Machine Learning, p. 36. ACM (2004)
Fischer, B., Buhmann, J.M.: Bagging for path-based clustering. IEEE Transactions on Pattern Analysis and Machine Intelligence 25(11), 1411–1415 (2003)
Fred, A.L., Jain, A.K.: Combining multiple clusterings using evidence accumulation. IEEE Transactions on Pattern Analysis and Machine Intelligence 27(6), 835–850 (2005)
Ghaemi, R., Sulaiman, M.N., Ibrahim, H., Mustapha, N.: A survey: Clustering ensembles techniques. WASET 50, 636–645 (2009)
Hahsler, M., Gruen, B., Hornik, K.: arules – A computational environment for mining association rules and frequent item sets. Journal of Statistical Software 14(15), 1–25 (2005)
Halkidi, M., Batistakis, Y., Vazirgiannis, M.: On clustering validation techniques. Journal of Intelligent Information Systems 17(2), 107–145 (2001)
Hornik, K.: A CLUE for CLUster Ensembles. Journal of Statistical Software 14(12) (2005)
Jaccard, P.: The distribution of the flora in the alpine zone.1. New Phytologist 11(2), 37–50 (1912). http://dx.doi.org/10.1111/j.1469-8137.1912.tb05611.x
Lichman, M.: UCI machine learning repository (2013). http://archive.ics.uci.edu/ml
Mondal, K.C., Pasquier, N., Mukhopadhyay, A., Maulik, U., Bandhopadyay, S.: A new approach for association rule mining and bi-clustering using formal concept analysis. In: Perner, P. (ed.) MLDM 2012. LNCS, vol. 7376, pp. 86–101. Springer, Heidelberg (2012)
Pasquier, N., Bastide, Y., Taouil, R., Lakhal, L.: Efficient mining of association rules using closed itemset lattices. Inf. Systems 24(1), 25–46 (1999)
R Core Team: R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria (2015). https://www.R-project.org/
Rendón, E., Abundez, I., Arizmendi, A., Quiroz, E.: Internal versus external cluster validation indexes. International Journal of Computers and Communications 5(1), 27–34 (2011)
Sarumathi, S., Shanthi, N., Sharmila, M.: A comparative analysis of different categorical data clustering ensemble methods in data mining. IJCA 81(4), 46–55 (2013)
Strehl, A., Ghosh, J.: Cluster ensembles – a knowledge reuse framework for combining multiple partitions. JMLR 3, 583–617 (2003)
Topchy, A., Jain, A.K., Punch, W.: Clustering ensembles: Models of consensus and weak partitions. IEEE Transactions on Pattern Analysis and Machine Intelligence 27(12), 1866–1881 (2005)
Ultsch, A.: Clustering with SOM: U*C. In: Proc. WSOM Workshop, pp. 75–82 (2005)
Vega-Pons, S., Ruiz-Shulcloper, J.: A survey of clustering ensemble algorithms. IJPRAI 25(03), 337–372 (2011)
Wu, O., Hu, W., Maybank, S.J., Zhu, M., Li, B.: Efficient clustering aggregation based on data fragments. IEEE Trans. Syst. Man Cybern. B Cybern. 42(3), 913–926 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Al-najdi, A., Pasquier, N., Precioso, F. (2016). Multiple Consensuses Clustering by Iterative Merging/Splitting of Clustering Patterns. In: Perner, P. (eds) Machine Learning and Data Mining in Pattern Recognition. MLDM 2016. Lecture Notes in Computer Science(), vol 9729. Springer, Cham. https://doi.org/10.1007/978-3-319-41920-6_60
Download citation
DOI: https://doi.org/10.1007/978-3-319-41920-6_60
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-41919-0
Online ISBN: 978-3-319-41920-6
eBook Packages: Computer ScienceComputer Science (R0)