
Abstract
The process of steganalysis involves feature extraction and classification based on feature sets. The high dimension of feature sets used for steganalysis makes classification a complex and time-consuming process, thus it becomes important to find an optimal subset of features while retaining high classification accuracy. This paper proposes a novel feature selection algorithm to select reduced feature set for multi-class steganalysis. The proposed algorithm FS-EHS is based on the swarm optimization technique Harmony Search using Extreme Learning Machine. The classification accuracy computed by Extreme Learning Machine is used as fitness criteria, thus taking advantage of the fast speed of this classifier. Steganograms for conducting the experiments are created using several common JPEG steganography techniques. Experiments were conducted on two different feature sets used for steganalysis. ELM is used as classifier for steganalysis. The experimental results show that the proposed feature selection algorithm, FS-EHS, based on Harmony Search effectively reduces the dimensionality of the features with improvement in the detection accuracy of the steganalysis process.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
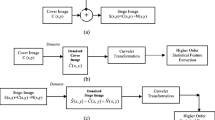
Steganography is the branch of information hiding in which communication of a secret message, m, is done by hiding it in some other information (cover-object, c), thus hiding the existence of the communicated information [1]. Sender therefore changes the cover, c to a stego-object, s. The cover object (e.g. an image) should have sufficient amount of redundant data which can be replaced by secret information in order to be used for embedding message without suspicion.
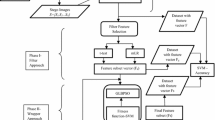
Steganalysis detects the presence of messages hidden using steganography inside digital data [1]. Based on whether an image includes hidden message or not, images can be categorized into stego-images and non-stego-images. The steganalysis methods work on the principal that steganography procedures on images alter the statistical properties of the image, which can be used to detect presence of messages. Steganalysis is similar to a pattern recognition process and its main aim is to identify the presence of a covert communication by using the statistical features of the cover and stego image as clues. Framework of steganalysis involves two phases: training phase and testing phase. In former, the multidimensional feature set from the training images consisting of cover images and stego-images are extracted and this set is used to train the classifier. In the testing phase, the trained classifier is used to distinguish between stego and non-stego images.
Image steganalysis techniques have been developed with feature extraction done from several domains like spatial, DCT, and DWT etc. [2]. Several studies have led to development of different feature extraction models for steganalysis such as statistical [3], histogram, co-occurrence matrix [4], IQM [5], SPAM [6], CF moments [7], Neighboring joint density probabilities (NJD) [8] and Markov model [9, 10] etc. Pevny and Fridrich [11] have merged the features from different models, i.e. DCT and Markov model, to improve accuracy of steganalysis method. Some authors [10, 12] have used calibrated features to get better detection results.
Feature based steganalysis involves large dimensionality of feature vectors. The pattern-recognition research has indicated that training the classifier with the high-dimensional features causes difficulty and result in problems like ‘over-fitting’ and ‘curse of dimensionality’. Thus to improve the efficiency of steganalysers, the classification process can be optimized by using reduced number of features required for classification. The individual features from the extracted high-dimensional feature set as well as their correlations need to be analyzed. It is possible that there are features which are more valuable for classification. There might be some features which together don’t give performance better than their individual performance and hence some of them can be considered redundant. Thus, to increase the efficiency and practicality of steganalysis it is important to reduce the dimension of feature space by selecting features with better classification performance while distinguishing stego-images from non-stego-images.
In this paper, FS-EHS a Feature selection algorithm for steganalysis based on the swarm intelligence technique Harmony Search (HS) is proposed, that uses Extreme Learning Machine (ELM) as classifier. Harmony Search captures the coordinating nature of musicians [13]. Each musician produces a note. All the notes together generate one harmony. Different harmonies form the harmony memory. New harmonies are generated using improvisation. If a new harmony performs better than the worst harmony in the harmony memory, the worst harmony is replaced with the newly generated harmony. At the end, the best harmony is chosen. For FS-EHS, the steganalytic feature selection algorithm proposed in this paper, a harmony corresponds to a feature subset and a harmony is evaluated on the basis of computation of the classification accuracy when this feature subset is used by ELM for classification.
The steganalytic feature sets used for experiments are the Markov based Features (MB-features) proposed by Chen et al. [9], and Neighboring Joint Density based features (NJD-Features) proposed by Liu et al. [8, 14], with 486 and 338 as dimensions, respectively. FS-EHS is applied for these feature sets and experiments show that FS-EHS yields a reduced feature set that also improves the classification efficiency of the steganalyzers.
The rest of the paper is structured as follows. Section 2 gives a brief account of feature selection and related work in it. Section 3 introduces HS process. Section 4 presents FS-EHS, the proposed feature selection using HS. The experimental setup and results are given in Sect. 5, followed by the conclusion in Sect. 6.
2 Feature Selection
The feature selection is the process of electing a subset of features. It can be described as a search into a space consisting of all possible subsets of the features and finding the optimal solutions. Traversing the whole space for a full search is impractical for a large number of features, as for an n-dimensional feature set this space contains 2n different subsets. To explore the search space, a heuristic or random approach can be applied. In first case, the search can be started with an empty subset or with a full set of features and during the iterations the features are either added to or deleted from the subset for evaluation. A random approach generates random subsets within the search space and evaluates them, several bio inspired and genetic algorithms use this approach.
Every feature subset generated is evaluated. According to the method of this evaluation process, feature selection methods can be classified into two main categories: filter and wrapper. In filter methods, filtering, based on some weight values assigned to each feature, is performed before the classification process. The features that have better weight values get selected in the final subset of features; therefore, they are independent of the classification algorithm. On the other hand, wrapper approaches generate candidate subsets of features and employ accuracy predicted by a classifier to evaluate these feature subsets. Wrapper methods usually achieve superior results than filter methods, but are limited by the speed of the classifier. A fast classifier, like ELM, can be used with wrapper method to speed up the classification process.
Feature selection methods can also be categorized into univariate and multivariate. Univariate methods examine individual features for classification abilities, whereas multivariate methods consider the correlations between features and examine subsets of features.
The comparison of performance for different types of features or analysis of the components of high-dimensional features is being generally used in research on steganalytic feature selection. Univariate method based on Bhattacharyya distance, for steganalytic feature selection, has been proposed by Xuan et al. [15]. Pevný et al. [16, 17] and Kodovský and Fridrich [18] have used comparison-based feature selection in their works. Wang et al. [19] in their univariate and sequential search based algorithms used comparison of the absolute moments of the CF (characteristic function) and the absolute moments of the PDF (probability density function) of the histogram of the wavelet coefficients for reduced feature dimensionality. Hui et al. [7] used Principal Component Analysis (PCA) for feature dimension reduction.
Avcıbas et al. [5] uses variance analysis and multiple regression analysis for reduction of feature set with features consisting of multiple values of image quality metrics. In sequential search based algorithms by Miche et al. [20], K-nearest-neighbor is used for calculating contribution of each feature to classification.
For feature selection, Mahalanobis distances and Fisher criterion has been used to evaluate the separability of each single-dimension feature by Davidson and Jalan [21] and Ji-Chang et al. [22] respectively. However, the sequential algorithms become very time-consuming as the dimensions of feature space increases. Many evolutionary algorithms have also been used for feature selection, which include genetic algorithms and swarm algorithms like Ant Colony Optimization (ACO) [23], Particle Swarm Optimization (PSO) [24], and Artificial Bee Colony [25]. Diao and Shen [26] in their stochastic method for feature selection have used a modified harmony search. Harmony search has been used for simultaneous clustering and feature selection by Sarvari et al. [27].
The proposed feature selection algorithm FS-EHS is multivariate wrapper method. It is using Harmony Search with ELM for selecting optimal feature subset. ELM being a fast classifier when used in wrapper method of feature selection provides a fast algorithm to classify image as stego or non-stego.
3 Harmony Search
Harmony Search (HS) [13] is an evolutionary algorithm inspired by the improvisation process of musicians. It follows a simple principle, requiring very few parameters. To obtain solution for an optimization problem, the process followed by musicians to create a new song is used. Each optimizing parameter is a note produced by one musician and a particular combination of these notes form a harmony, which is considered a possible solution. Different harmonies are kept in the Harmony Memory (HM). They are evaluated on the basis of some optimization criteria, new ones are created to replace the worst in the memory and the best harmony, at the end, is chosen as solution. The principal steps followed in a typical HS are:
-
Initialize HM with randomly generated solutions or harmonies
-
Improvise a new solution (or harmony)
-
Update the HM—replace a worst member with the new solution if the new has better fitness
-
Repeat the two steps of improvisation and updating for a predefined number of iterations.
The Harmony search algorithm for improvising a New Harmony (candidate solution) has to assign values to various notes either by choosing any value from HM, choosing a random value from the possible value range or choosing an adjacent value from HM. HS uses two parameters Harmony Memory Considering Rate (HMCR) and Pitch Adjustment Rate (PAR). HMCR decides which of the first two options will be chosen and PAR is the probability of choosing the third option. This improvisation method ensures the solution start converging towards the best solution.
In this paper, we propose a novel Harmony Search based feature selection algorithm using ELM, for image steganalysis. To the best of our knowledge, this is the first attempt to use Harmony Search with ELM for selecting the reduced feature set for image steganalysis.
4 FS-EHS—Harmony Search Based Feature Selection Algorithm using ELM
The principle of HS is modeled on the process followed by musicians to improvise new melodies. Harmony Search captures the coordinating nature of musicians. Each musician produces a note. All the notes together generate one harmony. Different notes leads to the production of different harmonies and all these harmonies reside in harmony memory (HM). All the harmonies have a fitness score associated with them. Depending on Harmony Memory Considering rate (HMCR), a new harmony is produced. If the newly created harmony yields better fitness than the fitness of the worst harmony in HM, then the worst harmony is replaced with the newly created harmony otherwise the harmonies in harmony memory remains the same. This process repeats for predefined number of iterations. After the completion, the harmony with best fitness is selected as solution.
In the proposed feature selection algorithm using HS, each feature corresponds to one note, thus the number of notes (and number of musicians) is equal to the number of features in original feature set. HM is a collection of binary strings, each string representing one harmony. A harmony corresponds to a feature subset and is represented as a binary string where one (‘1’) represents the presence of feature and zero (‘0’) represents its absence in that harmony. The harmonies are initially produced randomly and the number of harmonies is equal to harmony memory size (HMS). The fitness score of each harmony is the accuracy with which ELM classify images if trained using the features present in the harmony, i.e. those features corresponding to ones in a harmony. Thus, Harmony Memory is a matrix of size HMS × N, where N is the number of features in original feature set. Another vector, Fitness Score keeps track of the fitness scores of the harmonies in HM.
4.1 Parameters for the Algorithm
The parameters to be specified, for this algorithm, are:
-
Harmony Memory Size (HMS) decides how many harmonies are kept in memory.
-
Harmony Memory Considering rate (HMCR) specifies that whether a new harmony will be produced from the existing values stored within the harmony memory (exploiting the known good solution space) or will be a randomly produced afresh (exploring new solution space). HMCR, which varies between 0 and 1, is the probability of choosing one value for a note from the historical notes stored in the harmony memory, while (1—HMCR) is the probability of randomly generating a new value for the note.
-
The number of iterations (I) specifies how many times new harmonies are generated and compared with the ones in HM.
PAR is not needed while adapting HS for feature selection, as the HM contains binary values i.e., the only values that can be assigned to HM elements is 1 or 0.
4.2 Fitness Score
For any optimization technique a Fitness criteria is required to evaluate the candidate solutions. In the case of feature selection, this fitness score should reflect how good a subset of features is in distinguishing different classes. In the proposed algorithm, FS-EHS, the accuracy of classification by Extreme Learning Machine (ELM) trained using selected features is used as Fitness Score.
ELM was proposed by Huang et al. [28] as a learning algorithm for Single-hidden Layer Feed-forward neural Networks (SLFNs). ELM randomly chooses and then fixes the input weights (i.e., weights of the connections between input layer neurons and hidden layer neurons) and the hidden neurons’ biases; and analytically determines the output weights (i.e., the weights of the connections between hidden neurons and output neurons) of SLFNs. Thus, the only parameter to be determined in ELM is the number of neurons in the hidden layer. As a result ELM is much simpler and saves tremendous time.
4.3 Algorithm for FS-EHS
The algorithm for FS-EHS is given in the Algorithm 1 and in the two subroutines.



5 Experimental Setup and Results
Image Set: The experiments are conducted on an image dataset consisting of 2000 colored JPEG images of size 256 × 256. The cover images include images captured by the authors’ camera and images available freely in public domain on internet. The images are of various content and textures, spanning a range of indoor and outdoor scenes. The stego-images are created using publicly available JPEG image Steganographic tools OutGuess, F5 and Model-based steganography [2]. The image dataset is divided randomly into non-overlapping training set and testing set.
Steganalytic Feature Sets: Feature extraction is a key part of Steganalysis and various steganalysis methods differ mainly in the feature sets that are extracted from images. In this paper, the experiments are conducted on two types of feature sets Markov based Features (MB-features) and Neighboring Joint Density based features (NJD-Features) with 486 and 338 as dimensions, respectively. The feature set of MB Features, proposed by Chen et al. [9], contains features extracted from the inter block as well as intra-block correlation in frequency domain using Markov Process. This Process is applied on the original image, to obtain 324 intra-blocks and 162 inter-blocks features, together forming the feature set of size 486. The feature set of NJD-Features, proposed by Liu et al. [8, 14], include features based on Intra-block Neighboring Joint Density and Inter-block Neighboring Joint Density.
Extreme Learning Machine (ELM) as classifier: In the experiments, ELM is adopted as classifier. It is used to compute classification accuracy during feature selection and also as the classifier for steganalysis. ELM with sigmoid activation function and 160 hidden neurons is used for experiments.
The feature set computed from training set is used for feature selection by FS-EHS. The reduced feature set, so obtained, is used to train ELM. The images of testing set are then classified into stego and non-stego images by this trained ELM using the selected features from testing images. The implementation is done in MATLAB.
The classification accuracy percentage and the features selected are employed to determine the performance of the proposed FS-EHS for steganalysis. For both the feature sets (NJD-features and MB-Features), the experiment has been conducted 10 times employing ten-fold cross validation. All the results are then averaged.
The experimental results, for different feature sets, as given in Table 1 indicate that: FS-EHS proposed in this paper not only can reduce the dimension greatly, but improves the steganalytic efficiency as well. These results verify the effectiveness and rationality of the proposed feature selection method, FS-EHS when it is used in steganalysis process.
6 Conclusion
This paper presented a novel feature selection method FS-EHS for blind steganalysis method of JPEG images using Harmony Search with ELM. To show the usefulness and effectiveness of FS-EHS, experiments were conducted using two types of steganalytic feature sets. The ELM was used as classifier as it is a fast learning SLFN. The experiments were conducted on JPEG images. The stego images were created using F5, Outguess and Model-based steganography techniques. The experimental results show a significant reduction in the number of features being selected with improvement in classification rate when the proposed feature selection method is used as a step in the steganalysis process.
References
Davidson, J.L., Jalan, J.: Feature selection for steganalysis using the Mahalanobis distance. In: SPIE Proceedings Media Forensics and Security, vol. 7541. San Jose, CA, USA (2010)
Abolghasemi, M., Aghainia, H., Faez, K., Mehrabi, M.A.: LSB data hiding detection based on gray level co-occurrence matrix. In: International symposium on Telecommunications, pp. 656–659. Iran, Tehran (2008)
Avcıbas, I., Memon, N., Sankur, B.: Steganalysis using image quality metrics. IEEE Trans. Image Process. 12(2), 221–229 (2003)
Bhasin, V., Bedi, P.: Steganalysis for JPEG images using extreme learning Machine. In: IEEE International Conference on Systems, Man, and Cybernetics, pp. 1361–1366. IEEE, Manchester, UK (2013)
Chen, C., Shi, Y.Q.: JPEG image steganalysis utilizing both intrablock and interblock correlations. In: IEEE ISCAS, International Symposium on Circuits and Systems, pp. 3029–3032. Seattle, Washington, USA (2008)
Chen, G., Chen, Q., Zhang, D., Zhu, W.: Particle swarm optimization feature selection for image steganalysis. In: Fourth International Conference on Digital Home (ICDH), pp. 304–308. Guangzhou (2012)
Diao, R., Shen, Q.: Feature selection with harmony search. IEEE Trans. Syst. Man Cybern. B Cybern. 42(6), 1509–1523 (2012)
Fridrich, J.: Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes. In: 6th Information Hiding Workshop. Toronto, ON, Canada (2004)
Fridrich, J., Kodovsky, J.: Calibration revisited. In: 11th ACM Multimedia & Security Workshop, pp. 63–74. Princeton, NJ (2009)
Fridrich, J., Pevny, T.: Merging Markov and DCT features for multiclass JPEG steganalysis. In: Proceeding SPIE Electronic Imaging, Security, Steganography, and Watermarking of Multimedia Contents IX, pp. 650503-1–650503-13. San Jose, CA (2007)
Huang, G.-B., Zhu, Q.-Y., Siew, C.-K.: Extreme learning machine: a new learning scheme of feedforward neural networks. International Joint Conference on Neural Networks (IJCNN), 2, pp. 985–990. Budapest, Hungary (2004)
Hui, L., Ziwen, S., Zhiping, Z.: An image steganalysis method based on characteristic function moments and PCA. In: Proceeding of the 30th Chinese Control Conference. Yantai, China (2011)
Kabir, M.M., Shahjahan, M., Murase, K.: An efficient feature selection using ant colony optimization algorithm. In: Neural Information Processing—16th International Conference, ICONIP 2009, pp. 242–252. Bangkok, Thailand: Springer, Berlin (2009)
Katzenbeisser, S., Petitcolas, F.: Information Hiding Techniques for Steganography and Digital Watermarking. Artech House, Boston (2000)
Kharrazi, M., Sencar, H., Memon, N.: Benchmarking steganographic and steganalysis techniques. Electron. Imaging 2005, 252–263 (2005)
Kodovsky, J., Fridrich, J.: Rich models for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 7(3), 868–882 (2012)
Liu, Q., Sung, A.H., Qiao, M.: Improved detection and evaluation for JPEG steganalysis. 17th ACM International Conference on Multimedia, pp. 873–876. ACM, Beijing, China (2009)
Liu, Q., Sung, A.H., Qiao, M.: Neighboring joint density-based JPEG steganalysis. ACM Trans. Intell. Syst. Technol. (TIST) 2(2), 16:1–16:16 (2011)
Lu, J.-C., Liu, F.-L., Luo, X.-Y.: Selection of image features for steganalysis based on the Fisher criterion. Digit. Invest. 11(1), 57–66 (2014)
Miche, Y., Roue, B., Lendasse, A., Bas, P.: A feature selection methodology for steganalysis. In: Content, Multimedia (ed.) Representation, Classification and Security, pp. 49–56. Springer, Berlin Heidelberg (2006)
Pedrini, M.S.: Data feature selection based on artificial bee colony algorithm. EURASIP J. Image Video Process. 1–8 (2013)
Pevny, T., Fridrich, J.: Multiclass detector of current steganographic methods for JPEG format. IEEE Trans. Inf. Forensics Secur. 4(3), 635–650 (2008)
Pevný, T., Bas, P., Fridrich, J.: Steganalysis by subtractive pixel adjacency matrix. IEEE Trans. Inf. Forensics Secur. 5(2), 215–224 (2010)
Pevny, T., Filler, T., Bas, P.: Using high-dimensional image models to perform highly undetectable steganography. 12th International workshop on information hiding. Calgary, Canada (2010)
Sarvari, H., Khairdoost, N., Fetanat, A.: Harmony search algorithm for simultaneous clustering and feature selection. International Conference of Soft Computing and Pattern Recognition (SoCPaR), (pp. 202–207). Paris (2010)
Wang, X., Gao, X.-Z., Zenger, K.: An Introduction to Harmony Search Optimization Method. Springer International Publishing, Berlin (2015)
Wang, Y., Moulin, P.: Optimized feature extraction for learning-based image steganalysis. IEEE Trans. Inf. Forensics Secur. 2(1), 31–45 (2007)
Xuan, G., Zhu, X., Chai, P., Zhang, Z., Shi, Y. Q., Fu, D.: Feature selection based on the Bhattacharyya distance. In: The 18th International Conference on Pattern Recognition (ICPR’06). Hong Kong (2006)
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Bhasin, V., Bedi, P., Singh, N., Aggarwal, C. (2016). FS-EHS: Harmony Search Based Feature Selection Algorithm for Steganalysis Using ELM. In: Snášel, V., Abraham, A., Krömer, P., Pant, M., Muda, A. (eds) Innovations in Bio-Inspired Computing and Applications. Advances in Intelligent Systems and Computing, vol 424. Springer, Cham. https://doi.org/10.1007/978-3-319-28031-8_34
Download citation
DOI: https://doi.org/10.1007/978-3-319-28031-8_34
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-28030-1
Online ISBN: 978-3-319-28031-8
eBook Packages: EngineeringEngineering (R0)