
Abstract
Ontology plays an important role in the recent years. Its applications now are more popular and variety. Ontologies are used in the different areas related to Information Technology, Biology, and Medicine, especially in Information Retrieval, Information Extraction, and Question Answering. Ontologies capture background knowledge by providing relevant terms and the formal relations between them, so that they can be used in a machine-processable way. Depending on the different applications, the structure of ontologies has been built and designed with different models. Good ontologies lead directly to a higher degree of reuse and a better cooperation over the boundaries of applications and domains. However, there are a number of challenges that must be faced when evaluating ontologies. In this paper, we propose a novel approach based on data-driven and information extraction system for evaluating the lexicon/vocabulary and consistency of a domain specific ontology. Furthermore, we evaluate the ontological structure and the relations of some terms of the ontology.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
The methodological approaches for evaluating ontologies have become an active field of research in recent years. Depending on different applications and the structure of ontologies, ontology evaluation can be applied in many ways. There are a lot of researches which are relevant to this field. Pérez [1] proposed a method to evaluate ontology which consists of two steps. The first one is to describe a set of initial and general ideas that guide the evaluation of ontologies. The second one is to apply empirically some of these ideas in the evaluation of the Bibliographic-Data ontology. Fahad et al. [2] proposed a framework for evaluating ontology. His proposal presented the ontological errors based on design principles for evaluation of ontologies. It provided the overview of ontological errors and design anomalies that reduces reasoning power and creates ambiguity while inferring errors from concepts. Velardi [3] proposed an approach for evaluation of an actual ontology-learning system. His approach consists of twofold: first, he provided a detailed quantitative analysis of the ontology learning algorithms. Second, he automatically generated natural language descriptions of formal concept specifications in order to facilitate per concept qualitative analysis by domain specialists. In general, there are a number of researches related to evaluating ontology. However, these researches evaluate the ontologies based on either the design principles or the vocabulary of ontology. They do not combine all of them in order to evaluate ontology more accurately. In this paper, we introduce an approach for ontological evaluation based on the structure, axioms of the ontology and semantics among concepts.
Our key contributions are as follows: (i) the lexicon/vocabulary and consistency of a domain specific ontology are evaluated, which based on the data-driven related to computing domain; (ii) we build an information extraction system to evaluate the lexicon/vocabulary and consistency of the ontology; (iii) we also evaluate the ontological structure and the relations of terms based on data constraints.
The rest of this paper is organized as follows: Sect. 2 examines related work and overviews a sample of approaches; Sect. 3 introduces the proposed methodology; Sect. 4 illustrates the experimental results; Sect. 5 discusses the conclusions and future works.
2 Related Work
There are a number of frameworks for ontology evaluation, such as OntoClean [4], OntoManager [5], OntoMetric [6], etc. Each framework has its own advantages and disadvantages depending on the complexities of ontologies. As outline from Netzer et al. [7] proposed a new method to evaluate a search ontology, which relied on mapping ontology instances to textual documents. On the basis of this mapping, he evaluated the adequacy of ontology relations by measuring their classification potential over the textual documents. This data-driven method provided concrete feedback to ontology maintainers and a quantitative estimation of the functional adequacy of the ontology relations towards search experience improvement. He specifically evaluated whether an ontology relation can help a semantic search engine support exploratory search. Soysal et al. [8] built the domain specific ontology focusing on movie domain. He used three measures, namely Precision, Recall, and F-measure for ontology evaluation.
The above-mentioned researches and frameworks lack in a general approach for evaluating the ontologies by combining the features of the ontologies, such as, the structure of the ontologies, the concepts and axioms in the ontologies. According to Obrst et al. [9], he suggests that there are a number of methods to evaluate the ontologies. They are:
-
The evaluation of the use of an ontology in an application.
-
The comparison against a source of domain data.
-
Assessment by humans against a set of criteria.
-
Natural language evaluation techniques. Natural language processing tasks such as information extraction, question answering and abstracting are knowledge-hungry tasks. It is, therefore, natural to consider evaluation of ontologies in terms of their impact on these tasks.
-
Using reality as a benchmark. Here the notion of a “portion of reality” is introduced, to which the ontology elements are compared.
In order to evaluate a more effective one for the ontology, in this paper, we will propose an approach combining the data-driven and data constraints related to computing domain. Moreover, we build an information extraction system based on this ontology for evaluating the accuracy of concepts in the ontology.
3 Automatic Evaluation of the Computing Domain Ontology
3.1 Overview of the Computing Domain Ontology
Ontology is a formal and explicit specification of a shared conceptualization of a domain of interest. Their classes, relationships, constraints and axioms define a common vocabulary to share knowledge. Conceptualization refers to an abstract model of some phenomenon in the world. Explicit specification means that the type of concepts used and the limitations of their use are explicitly defined. Formal specification refers to the fact that the ontology should be machine-readable. Shared knowledge reflects the notion that ontology captures consensual knowledge, which is not private to some individual but accepted by a group.
Formally, an ontology can be defined as the tuple [10]:
Where,
-
C, is set to consist of classes. In this ontology, C represents categories of computing domain (for example, “Artificial Intelligent, hardware devices, NLP” ∈ C)
-
I is set of instances belong to categories. In this ontology, set I consists of computing vocabulary (for example, “robotic, Random Access Memory” ∈ I)
-
S = NS ∪ HH ∪ YH is the set of synonyms, hyponyms and hypernyms of instances of set I.
-
N = NS is set of synonyms of instances of set I.
-
H = HH is set of hyponyms of instances of set I.
-
Y = YH is set of hypernyms of instances of set I. (e.g., “ADT”, “data structure”, “ADT is a kind of data structure that is defined by programmer” are synonymous, hyponymous and hypernymous of “Abstract data type”)
-
B = {belong_to (i, c) | i ∈ I, c ∈ C} is set of semantic relationships between concepts of set C and instances of set I and are denoted by {belong_to (i, c) | i ∈ I, c ∈ C} mean that i belongs to category c. (e.g., belong_to (“robotic”, “Artificial Intelligent”)
-
R = {rel (s, i) | s ∈ S, i ∈ I} is the set of relationships between terms of set S and instances of set I and are denoted by hierarchy and are denoted by {rel (s, i) | s ∈ S, i ∈ I} mean that s is relationship with i. The relationships can be synonymous, hyponymous or hypernymous. (e.g., synonym (“ADT”, “Abstract data type”), hyponym (“data structure”, “Abstract data type”), hypernym (“ADT is a kind of data structure that is defined by programmer”, “Abstract data type”). According to Fig. 1, the following sets can be identified as below:
Fig. 1. 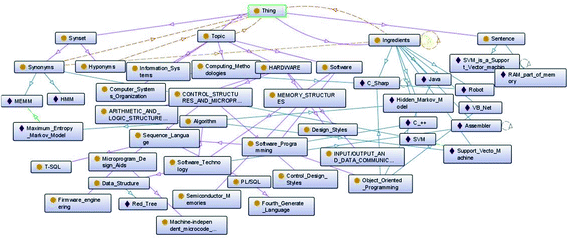
CDO hierarchy is presented by Protégé
-
C = {Software, Software programming, Software technology, Object oriented programming, data structure, Sequence language}
-
I = {Abstract data type, Random access memory, Read only memory}
-
N = {ADT, RAM, ROM}
-
H = {Data structure, database, memory}
-
Y = {EPROM, EEPROM, DDRAM, DDRAM2, DDRAM3}

In addition, all concepts and instances of this ontology focus on computing domain; therefore this ontology is known as Computing Domain Ontology (CDO).
We separate CDO into four layers:
The first layer is known as the topic layer. In order to build it, we extract terms from ACM Categories [11]. We obtain over 170 different categories from this site and rearrange them in this layer.
Next layer is known as the ingredient layer. In this layer, there are many different instances, which are defined as nouns or compound nouns from vocabulary about Computing domain, e.g., “robot”, “Super vector machine”, “Local Area network”, “wireless”, “UML”, etc. In order to setup this layer, we use Wikipedia to focus on English language and computing domain.
The third layer of CDO is known as the Synset layer. To set up this layer, we use the WordNet ontology. Similar to Wikipedia, we only focus on computing domain. This layer encloses a set of synset. A synset includes synonyms, hyponyms, and hypernyms of instances of the ingredient layer.
The last layer of CDO is known as the sentence layer. Instances of this layer are sentences that represent syntactic relations extracted from preprocessing stage. Hence, these sentences are linked to one or many terms of the ingredient layer. This layer also includes sentences that represent semantic relations between terms of ingredient layer, such as, IS-A, PART-OF, MADE-OF, RESULT-OF, etc. The overall hierarchy of CDO is shown in Fig. 1.
3.2 The CDO Evaluation
Many techniques are being used for ontology evaluation in the life sciences and more generally. In this section, we look at a number of the techniques: evaluation with respect to the use of this ontology in an information extraction system, with respect to data-driven and the use of data constraints.
Evaluating the Lexicon/Vocabulary and Consistency based on the Data-Driven
Definition 1.
Axioms are the smallest unit of knowledge within an ontology. It can be either TERMINOLOGICAL AXIOM, a FACT or an ANNOTATION. Terminological axioms are either CLASS AXIOMS or PROPERTIES AXIOMS. An Axiom defines the formal relation between ontology entities and their name.
Definition 2.
Literals are the names that are mapped to concrete data values, i.e. instead of using URI to identify an external entity, literals can be directly interpreted.
All of axioms, entities in the Computing Domain Ontology are literals.
To evaluate the lexicon/vocabulary or axioms, in the first method, we use three measures: Precision (P), Recall (R) and F-measure (F). They are calculated as follows
Where Ci represents a category in CDO and correct, wrong, missing represent the number of terms, which are correct, wrong, missing, respectively.
The evaluation of a number of terms, which are wrong or missing in CDO, can only be carried out by validation with respect to other publicity available computing sources. We therefore manually verify the knowledge base with respect to benchmark information provided by the three computing dictionaries as follows:
-
Networking dictionary [12] for evaluating the categories related to the network.
-
Dictionary of IBM and Computing Terminology [13] for evaluating the categories related to hardware and devices
-
Microsoft Computer Dictionary (Microsoft corporation [14]) for evaluating the categories related to software, programming language, etc.
Definition 3.
Given an ontology T and a dictionary D, a term I belongs to category C with C ⊂ T, I is called “Wrong” iff there exists a term I′ belongs to category C′ ⊂ D such as I′ ≡ I with C′ ≠ C.
Definition 4.
Given an ontology T and a dictionary D, a term I belonging to category C’ with C′ ⊂ D, I is called “Missing” iff there exists no term I belonging to T.
We propose the evaluated algorithm for calculating three measures: Precision, Recall, and F-measure as follows

Evaluating the Lexicon/Vocabulary and Consistency based on the Application.
Once again, consistency and vocabulary of CDO are evaluated based on the application. Application-based evaluation offers a useful framework for measuring practical aspects of ontology deployment. The accuracy of responses provided by the system will show the accuracy of the ontology. In case, the application is an information extraction system, which is built based on CDO. The model of this system is shown as Fig. 2.

Model of the information extraction system
According to Fig. 2, the results, which reply to user’s queries are filtered and extracted from the different layers of CDO. The accuracy of the results will reflect the accuracy of the terms of CDO and the results will be shown in the next section.
Evaluation of the CDO’s Structure and the Relations of Terms.
This is primarily of interest in manually constructed ontologies. The structural ontology concerns involve the organization of the ontology and its suitability for application development. There are some of the approaches for evaluating the structure of ontologies. They are:
-
Using anti-pattern and heuristic to discover structure errors in ontologies [15]. According to Lam [15], the structure of ontologies is an error because of these anti-patterns.
-
Constraint validations in ontologies [4]
Definition 5.
Data constraint is a limitation that was placed on data when it is inserted into ontology.
In this case, we define some of the data constrains in CDO as follows
-
Instance constraint. Given a term I belonging to Ingredient or Synset layers, ontology T, set of category C, I ∈ T ⇒ ∃C i ∈ C | I ∈ C i
-
Transitive constraint. Given a term I belonging to Ingredient and Synset layers, ontology T, set of category C with C 1 ⊂ C, C 2 ⊂ C 1 , C 3 ⊂ C 2, I ∈ C 3 ⇒ I ∈ C 2 , I ∈ C 1 , I ∈ C
-
Relational constraint. Given a relationship R(I 1 , I 2 ,…, I n ), set of category C, C i ⊂ C, ∃Ii ∈ R | I i ∈ C i with i = 1…n
The data constraint validations are implemented by Structured Query Language (SQL) since we use Relational Database System (RDBS) for ontological representation. The experiment results will be shown in the next section.
4 Experiment
4.1 Evaluating the Lexicon/Vocabulary and Consistency of CDO Based on Data-Driven
Figure 3 respectively shows the results through three above measures when applying Algorithm 3.1. We choose five categories, which are Hardware, Computer communication network, Network architecture and design, Software engineering, and Programming language for illustration.

Evaluation on the lexicon/vocabulary and consistency of CDO based on data-driven
The scores reported in Fig. 3 reveal that the ontological evaluation based on data-driven yields a performance respectably. The Precision measure has a high value. It means that the lexicon/vocabulary of CDO reflects substantially more relevant instances than irrelevant while high recall means that the lexicon/vocabulary of CDO reflects most of the relevant instances.
4.2 Evaluating the Lexicon/Vocabulary and Consistency of CDO Based on Application
As mentioned above, the user’s queries, which are inputted directly into the application, are used for application-based evaluation. We also pick the same five categories as first method of illustration. Furthermore, the queries consist of four types of sentences, as follows.
-
80 queries are only noun phrases, e.g., “Java language”, “CPU Pentium”, “Open system internetworking”, etc.
-
80 queries are simple sentences that consist of simple subjects and simple predicates [16]. A simple subject is a noun or noun phrase and the simple predicate is always a verb, verb string or compound verb, e.g., “Java language does”, “CPU Pentium makes”, “Transmission control protocol does”, etc.
-
80 queries are simple sentences that consist of subject and complex predicate [16]. The complex predicate consists of the verb and all accompanying modifiers and other words that receive the action of a transitive verb or complete its meaning, e.g., “Java is programming language”, “What is transmission control protocol”, “Transport layer provides services to the Network layer”, etc.
-
80 queries consist of complex sentences, wrong grammar sentences, and unfinished sentences, i.e. they do not contain a complete idea, e.g., “control transmission protocol”, “table routing”, “Mac Address is a unit address for a computer belongs to Data Link layer”, etc.
Figure 4 respectively shows the results.

Evaluation on the lexicon/vocabulary and consistency based on the application
The scores reported in Fig. 4 reveal that the accuracy rates of the results are returned from the information extraction system when the system extracts information related to the different queries (96 % for hardware category and 87 % for programming category).
4.3 Evaluating the CDO’s Structure and the Relations of Terms
As mentioned above, we use SQL for data constraint validations. Some of the SQL scripts are written for validations. We also pick five categories as previous sections for illustration. Figure 5 respectively shows the results.

Evaluation on the ontological structure and the relations of terms
As the above-mentioned definitions, the scores reported in Fig. 5 reveal that the minimum of the instance constraint reaches about 91 %; it means that all instances of the synset layer have a relationship with at least an instance of ingredient layer. Moreover, the transitive constraint reaches 100 %; it means that the structure of CDO is reasonable while the minimum of relational constraint reaches about 82 %.
5 Conclusions
In this paper, we dealt with the problem of the ontological evaluation. This ontology focuses only on computing domain and it has the complex structure. In order to evaluate the lexicon/vocabulary or axioms and consistency of the ontology, we proposed two methods; (i) based on data-driven; (ii) based on information extraction system. We also used the data constrains for validation of the ontological structure and the relations of terms. Results generated by such experiments show that the terms and axioms belonging to different layers of the ontology have a high accuracy rate and the ontology can be used for many different applications, such as, Information Retrieval applications, Information Extraction applications. Comparing to other frameworks for evaluating the ontologies, such as, OntoClean, OntoManager, OntoMetric, our proposed approach evaluates the lexicon/vocabulary of CDO based on not only the data-driven, but also the application and data constraint in order to check the accuracy of instances of CDO.
In the future work, we will focus particularly on automatically ontological enriching, but the accuracy rate in terms of the ontology is still high. Besides, the data constraint validations are also satisfied.
References
Pérez, A.G.: Some ideas and examples to evaluate ontologies. In: Proceedings of the 11th Conference on Artificial Intelligence for Applications, pp. 299–305, Los Angeles, CA (1995)
Fahad, M., et al.: A framework for ontology evaluation (2008). http://ceur-ws.org/Vol-354/p59r.pdf
Velardi, P.: Evaluation of OntoLearn, a methodology for automatic learning of domain ontologies, The Pennsylvania State University. http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.97.333&rep=rep1&type=pdf. Accessed 9 September 2015
Guarino, N., et al.: An overview of OntoClean. https://noppa.aalto.fi/noppa/kurssi/as-75.4700/materiaali/AS-75_4700_overview_of_ontoclean.pdf. Accessed 9 September 2015
Stojanovic, N., et al.: The OntoManager – a system for the usage-based ontology management. http://www.kde.cs.uni-kassel.de/ws/LLWA03/fgml/final/Stojanovic.pdf. Accessed 9 September 2015
Tello, A.L., et al.: ONTOMETRIC: a method to choose the appropriate ontology, archivo digital UPM. http://oa.upm.es/6467/1/ONTOMETRIC_A_Method.pdf. Accessed 9 September 2015
Netzer, Y., Gabay, D., Adler, M., Goldberg, Y., Elhadad, M.: Ontology evaluation through text classification. In: Chen, L., Liu, C., Zhang, X., Wang, S., Strasunskas, D., Tomassen, S.L., Rao, J., Li, W.-S., Candan, K.S., Chiu, D.K.W., Zhuang, Y., Ellis, C.A., Kim, K.-H. (eds.) WCMT 2009. LNCS, vol. 5731, pp. 210–221. Springer, Heidelberg (2009)
Soysal, E., Cicekli, I., Baykal, N.: Design and evaluation of an ontology based information extraction system for radiological reports. Comput. Biol. Med. 40(11–12), 900–911 (2010)
Obrst, L., et al: The evaluation of ontologies. In: Baker, C.J.O., Cheung, K.H. (eds.) Semantic Web: Revolutionizing Knowledge Discovery in the Life Sciences, (chap. 7), pp. 139–158. Springer, New York (2007)
Zhang, L.: Ontology based partial building information model extraction. J. Comput. Civ. Eng. 27, 1–44 (2012)
Association for Computing Machinery. http://www.acm.org/about/class/ccs98-html. Accessed 9 September 2015
Sybex corporation (2000). www.sybex.com
IBM. http://www-03.ibm.com/ibm/history/documents/pdf/glossary.pdf. Accessed 9 September 2015
Microsoft corporation. https://robot.bolink.org/ebooks/Microsoft%20Computer%20Dictionary%205e.pdf. Accessed 9 September 2015
Lam, J.: Methods for resolving inconsistencies in ontologies. Ph.D. thesis, University of Aberdeen, Aberdeen, Scotland (2007)
Capital Community College Foundation. http://grammar.ccccommnet.edu/grammar/objects.htm. Accessed 9 September 2015
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Ta, C.D.C., Thi, T.P. (2015). Automatic Evaluation of the Computing Domain Ontology. In: Dang, T., Wagner, R., Küng, J., Thoai, N., Takizawa, M., Neuhold, E. (eds) Future Data and Security Engineering. FDSE 2015. Lecture Notes in Computer Science(), vol 9446. Springer, Cham. https://doi.org/10.1007/978-3-319-26135-5_21
Download citation
DOI: https://doi.org/10.1007/978-3-319-26135-5_21
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-26134-8
Online ISBN: 978-3-319-26135-5
eBook Packages: Computer ScienceComputer Science (R0)