
Abstract
The energy transition requires profound changes to the power grid, both on the transmission and distribution level. The ability to assess the impact of these changes, e.g., the integration of more solar power or electric mobility, requires data and tools that only exist partially today. The goal of this paper is to introduce OpenGridMap, a new project with the goal of creating an open platform for inferring realistic power grids based on actual data. Our vision is to provide a tool to researchers and practitioners that is able to produce realistic input data for simulation studies. OpenGridMap will support the entire process from data collection to formatting grid data for various purposes. We explore innovative ways to capture data and produce power grid approximations, e.g., using smartphone apps, expert classification, existing map APIs, and graph inference algorithms. The latest developments of the project can be found at opengridmap.com.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In many countries around the world, governments have committed to ambitious sustainability goals. In many cases, these goals include a transition to renewable power generation, mostly from wind and solar. Apart from being intermittent, wind and solar power generation is distributed and therefore supplies electricity at lower voltage. In Germany, over 90 % of the installed renewable energy capacity is connected at the distribution level [12]. In addition to the integration of variable renewables, electricity demand will change substantially, as well. On the one hand, further electrification is well underway, e.g., in the form of electric mobility and heat pumps. On the other hand, various initiatives are trying to reduce the energy consumption of traditional electric loads. Thus, even without actively controlling demand, the current developments will radically change the way power flows in the existing power grids. Several efforts to overcome these challenges using computer science techniques are currently beeing investigated as part of the Energy Informatics research field.
The current power grid infrastructure, in particular on the distribution level, was designed with certain assumptions in mind that will not hold in the future. Many recent studies have shown that this could lead to stability issues [12, 28, 29]. However, the level at which these important issues can be analyzed given todays data availability and analysis methods is modest. In fact, most available studies are based on such extreme simplifications that practical results cannot be expected. Academic studies are often carried out using standardized test feeders [12], not actual ones. Some distribution grid operators own digitized distribution grid data. However, in most cases, this data is either not digitized, or not available at all. A recent survey in the US revealed that 23 % of the electric distribution utility companies have incomplete data of their networks and over 30 % have outdated data [13].
The obvious solution to the problem of data availability is to actually collect the data and store it for further use, be it scenario-based simulation, or to enable new Smart Grid control approaches. Unfortunately, the traditional method for collecting this data is difficult, expensive, and intrusive [13]. The purpose of OpenGridMap is to overcome this problem using computer science techniques, including mobile app based crowdsourcing of grid data, machine learning based classification of visible grid components, and rule-based inference of invisible components. This paper presents a description and the latest results of the OpenStreetMap project.
Our paper is structured as follows: Sect. 2 offers an overview of the technical landscape for geographical power grid datasets, geographical information systems and crowdsourcing. The features of OpenGridMap are described in Sect. 3. The current components of OpenGridMap are presented in Sect. 4. Finally, Sect. 5 provides an outlook on the future project activities.
2 Technical Landscape
The digitalization of power grid data and the use of Geographical Information Systems (GIS) to display and analyze this data is not a new concept. Crowdsourcing is also an established concept. In the following, we review the technical landscape of this topics and explain how OpenGridMap builds on previous result to offer a solution to power grid inference based on crowdsourced data.
2.1 Availability of Power Grid Data
To simulate power flows, a identification and mapping of power grid infrastructure to geographic coordinates is necessary precondition. Many of the operational and business decisions of utilities rely on an accurate estimate of the state of their infrastructure. While this data is relatively well known on the level of the transmission grid, it is often not accurate and is sometimes even unknown on the sub-transmission and distribution level. As we already pointed out, a recent survey in the US revealed that 23 % of the electric distribution utility companies have incomplete data of their networks, and over 30 % have outdated data [13]. However, even this data is not openly available to researchers. Usually, the access to actual power grid data is very restricted. The main argument for these restrictions is security, i.e., the risk of someone sabotaging or attacking the power grid infrastructure. With these restrictions in place, researchers are forced to work with fabricated test cases. For distribution networks several such test cases exist, in particular the IEEE radial distribution test feeders [22], the CIGRE test feeders [27], and the PNNL feeders [26]. Although these test cases are often used and have certainly contributed to the reproducibility, and thus the comparability, of research results, it is important to point out the they are still invented and thus not usable in practice. In reality, power grids can be highly individual, e.g., due to geographic features, utility strategies, regional legislation, or simply coincidence. Thus, to establish a realistic grid data base for practical applications, we have to find new ways to collect actual grid data, even without the help of utilities.
There are several projects making an effort to offer realistic geographic power grid data. For instance, a publicly funded initiative in Bavaria, Energie-Atlas Bayern [3], offers a complete GIS energy solution for the state of Bavaria in Germany. The project EnergyMap [4] offers geographical information of several renewable energy generators for Germany. Furthermore, the German DENA reports [12] use geographical information of several utilities in Germany to study the future distribution grid expansions requirements. The OpenGridMap project differs from the aforementioned projects in that it aims to develop a novel system for inferring the power grid infrastructure at the level of distribution grids, and freely providing it in the required format for detailed computer simulations.
2.2 Geographic Information Systems
Geographic Information Systems (GIS) are systems designed to capture, store, manipulate, analyze, manage, and visualize all types of geographical data, in particular built infrastructure, such as streets and buildings.
A popular commercial software solution for integrating maps with application-specific data is ArcGIS [1]. ArcGIS is a platform that provides ready-to-use maps, apps, and templates to analyze geographical data. A free and open-source alternative to ArcGIS is Q-GIS [6]. Nonetheless, both platforms require a lot of customization in order to function as a power grid GIS. In contrast, OpenGridMap will be tailored for this specific purpose.
The most important asset of a GIS is its data. There are several freely available services that offer geographical data. Probably the best known is Google Maps [15]. However, after a certain number of requests has been reached, the data service of Google Maps is no longer available without charge. Also there are several restrictions for the API [7]: (i) no unauthorized copying, modification, creation of derivative works, or display of the content, (ii) no pre-fetching, caching, or storage of content, (iii) no mass downloads or bulk feeds of content. These restrictions make Google Maps unattractive for OpenGridMap.
An alternative to Google Maps is OpenStreetMap [17]. OpenStreetMap is a project that creates and distributes free worldwide geographic data. The project was initiated because most maps we think of as free actually have legal or technical restrictions on their use, precluding people from using them in creative, productive, or unexpected ways. The advantage of the OpenStreetMap is that it relies on a community to crowdsource its data. This allows it to have a huge database of information that is not available anywhere else, for free.
The use of GIS is not new to the power industry. However, not all utilities have access to a comprehensive GIS. In fact, according to the authors of [23], no utility currently has complete and up to date data on their system, let alone tools to manage it. After all, the introduction and maintenance of a GIS comes at a significant cost. There have been some efforts to develop freely available open source tools to handle geographic power systems data [9]. However, such efforts will not be successful without an efficient, scalable approach for collecting and managing this data. OpenGridMap sets out to tackle this challenge by relying on crowdsourcing and automatic inference.
2.3 Crowdsourcing Geographical Data
The collection of detailed geographical data is a time-consuming and complicated task. Crowdsourcing has proven to be an efficient method for the rapid and cost-effective collection of such data [18]. The most prominent example is OpenStreetMap [17]. The OpenStreetMap project uses a community approach to collect geographical data of streets and buildings. Its contributors organize “mapping events” to collect the most relevant data within a predefined area in a couple of days, which has proven to be highly effective. One of the core features that makes OpenStreetMap so successful is that anybody can edit the database. Some power grid elements have already been mapped in OpenStreetMap. However, most of the required data on the sub-transmission and distribution system level is missing. Furthermore, the elements that have been mapped are often not tagged correctly, e.g., transformers are tagged as substations. For the purpose outlined above we need highly reliable data. Thus, a method for verifying incoming data is required. In OpenGridMap, we plan to address this by exploiting features of contemporary mobile devices. The collection of data using smartphones has gained a lot of momentum over the last years and is usually referred to under the umbrella of participatory sensing [21]. The main challenge that the OpenGridMap project faces is the definition of incentive schemes to kick-start and sustain the collection of relevant data by contributors. Currently, we plan to use a community approach similar to the one used by OpenStreetMap.
3 The OpenGridMap Project
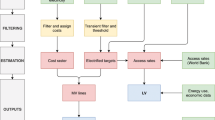
One of the main challenges for Smart Grid researchers and industry experts is the access to realistic power grid data. We believe that the access to more accurate and realistic data will lead to tailored solutions that address specific issues on the current power grid. With this in mind, we launched the project OpenGridMap. Its goal is to create an open platform for inferring realistic power grids based on available and crowdsourced data. OpenGridMap has several core features: data collection, verification, inference and analysis (cf. Fig. 1). In the following, we describe these features in more detail. We plan to have several feedback loops between the core features, in particular between analysis and inference, and between analysis and collection.

OpenGridMap features
3.1 Data Collection
OpenGridMap uses freely available geographical data sources, namely the ones mentioned in Subsect. 2.3. Nonetheless, as we have previously mentioned, this data is neither complete nor can its correctness be guaranteed.
Therefore, OpenGridMap collects data using a crowdsourcing approach. To facilitate this approach on the contributors’ side, we offer a mobile data collection application (a mobile “app”) specially tailored for the collection of power grid data. Contributors can use this app to take a picture of a potential power grid component they see and annotate it. The app adds the geographic coordinates of the picture and sends the data to the OpenGridMap’s backend.
To develop a community around OpenGridMap, we plan to develop gamification schemes which provide incentives for contributors to actively participate in the project. We plan to use a combination of OpenStreetMap’s community schemes and the gamification approaches used in location-based games like Geocaching [25] or Ingress [20]. Geocaching is a pastime, where a container holding a number of items is virtually hidden in a particular location for GPS users to find by means of coordinates posted on the Web. The players are rewarded with the possibility of finding an object in the container. Ingress is an augmented reality massive multi-player online role-playing game, where players are organized in two teams and battle over the control of certain key locations marked on a map that correspond with actual geographic locations. The continuous success of these two games shows that gamification is an effective method for building and sustaining a user community without having to provide monetary incentives. We therefore believe that this could be an effective approach to foster participation in OpenGridMap.
We are considering other collection methods for geographical data, as well. Lately, the use of unmanned aerial vehicles or drones has shown to be very effective for the inspection of power lines [16]. Drones have the potential to drastically reduce the amount of time required to accurately map power grid elements. Thus, in OpenGridMap we are also planning to research the use of inexpensive drones for data collection.
3.2 Verification
Since we allow anyone to contribute to OpenGridMap, the crowdsourced data needs to the verified to obtain a reliable database. First, we need to verify that the device mapped is actually part of the power grid and does not belong to a different infrastructure, such as the telecommunication network. Unfortunately, the classification of the mapped device and correct tagging is not trivial task for a common contributor. To address this issue, we envision the participation of experts in the loop, who review the submitted data and either discard incorrectly mapped elements or correct their classification. To facilitate the experts’ task, OpenGridMap provides a visualization of mapped devices that includes the pictures taken by the contributors. We also plan to automate the verification process, at least partially using machine learning algorithms. For instance, these algorithms could take advantage of the fact that elements of the power grid usually carry high voltage warning signs.
3.3 Inference
Via its crowdsourcing approach, OpenGridMap has the potential to collect the visible power grid infrastructure. However, a major share of the power grid’s infrastructure is not visible. Furthermore, many details cannot be determined by visual inspection only. To still be able to obtain all data required for simulation purposes, the missing data has to come from other sources or be inferred in a reliable way.
A key working area in the OpenGridMap project is topology inference, i.e., the inference of the location and technical features of distribution grid power lines. In Germany and many other countries, distribution lines are usually underground and thus cannot be visually mapped. However, based on data that we can obtain from other sources, in particular OpenStreetMap and crowdsourced data, it is possible to approximate power grid topologies based on certain background knowledge. The data collection and verification components of OpenGridMap should be able to deliver a dataset containing the location of most visible power grid elements, e.g., transformers, substations, poles, and cabinets. In addition, the system can access the geographic data provided via the OpenStreetMap component, in particular the location of streets and buildings. The inference task consists in determining the connections between the mapped power grid elements and the loads such that the overall grid topology complies with power grid design criteria. These design criteria might be different from one country to another, although several construction rules should be generalizable. In Germany, for instance, important guidelines for the design and construction of power lines are provided by the “Verband Deutscher Elektrotechniker” (VDE) [24]. To solve the resulting topology inference problem, we are currently considering three methods, including combinations of them: complex network theory, rule-based inference, and optimal network planning.
Several studies have applied complex network theory to power grid topology inference, but only, on the transmission level [8, 11, 19]. Unfortunately, the methods proposed in these papers cannot be directly applied to distribution grids, because their topological features are fundamentally different compared to transmission networks. Similar studies focussing on the distribution level are still missing.
The idea behind rule-based inference of power grid topologies is to connect given power grid elements based on common rules. Such rules can be extracted from various sources, e.g., expert documents [24], legal documents [14], economic calculations, or simply analysis of accessible power grid infrastructure plans. For instance, it is common to have power lines running along streets to enable easy access to the for maintenance and repairs.
The optimal planning approach is based on the formulation of an optimization problem that represents the design restrictions of power grids and uses standard optimization techniques to construct optimal grids given an objective, e.g., cost minimization.
To evaluate our inference methods, we plan to compare our results to actual distribution grid data. In case we cannot obtain enough of this data to perform reliable quality assessments, we plan to let experts inspect the results and judge their quality. We are also considering judging the quality of the inferred grid data based on the simulation results we are able to produce using the data.
To conduct power flow simulations, we not only need the topology of power lines, but also the characteristics of different power grid elements, e.g., transformer ratings, admittances of power lines, and the generation and load within a feeder over time. In case this data is not available, we will plan to make assumptions based on rules and expert knowledge. For instance, there are several criteria for defining the power rating of a transformer based on the number of loads connected to it. Furthermore, there exist standard procedures for choosing the type of cable to use for a particular demand level. Moreover, the design of power grids is also based on assumptions about future (maximum) demand.
3.4 Analysis
OpenGridMap will enable various types of analysis, including but not limited to power flow analysis. To facilitate power flow analysis, OpenGridMap will produce data representations of power grids that can be used directly by existing power flow tools, such as GridLab-D [10] or Matpower [30]. We plan to provide tools for categorizing inferred power grids based on a large number of metrics, e.g., size, location, population density, etc. This will, for instance, help OpenGridMap users find feeder subsets that are particularly relevant for the type of study they conduct.
4 Components
The development of OpenGridMap has just started. Nonetheless, we have already made several advances regarding collection, verification, and inference features. In the following, we present the current state of several components that our project team is working on.
4.1 Smartphone App
A first version of the OpenGridMap app that contributors can use to collect grid data is called “grid2osm GisApp” [5]. Currently, the app is only available for smartphones and tablets running Android. It can be downloaded without charge from Google’s play store. The decision to implement the app in Android first instead of iOS was based its greater market share and fewer number of restrictions imposed on development.
As shown in Fig. 2a, the user interface works using gestures and currently allows the user to do the following:
-
Switch to the native camera app to take a picture and record GPS coordinates of the photographed power grid element (swipe left)
-
Preview the pictures taken (swipe right)
-
Delete the pictures taken (swipe down)
-
Store the mapped element in a submission queue (swipe up)
-
Submit the picture to OpenGridMap’s backend (swipe up again)
With the procedure above, users are able to map power grid elements and take multiple pictures of them. It determines the geographic location of the grid element by recording the GPS coordinates of each picture taken. Textual data is store in a sqlite database, while photos are kept on the external storage devices. In the final step of the above procedure, both textual and binary data is sent to the backend using REST.
One important challenge when using smartphones for mapping is that they offer a maximum GPS accuracy of about 10 m. Thus, our app allows for multiple pictures to be taken. We can thereby triangulate a more accurate position of the mapped element. In case this does not work, we can always rely on the expert to correct the element’s position, which also becomes easier with more geolocated pictures.
A survey on the usability of the current app using the Attrakdiff questionnaire service was conducted [2]. The questionnaire features 28 pairs of opposite objectives. 20 persons anonymously participated in the survey. The results revealed that the app’s quality ratings are located in the average range. It is thus clear that improvements of the app’s usability are required to increase its chances of success, since usability is usually strongly related to actual usage. Currently, we are working on a second version of the app that will significantly improve usability and also include gamification elements that are supposed to provide non-monetary incentives to users.
4.2 Web Application
The current OpenGridMap prototype features a web application that allows users to visualize the power grid elements currently stored. It allows for visualizing and editing device-specific data, as well as contributing it to OpenStreetMap.
Figure 2b shows how the user can access this data using the current version of the web application. Blue input fields contain location data and black input fields contain specific element data. The map based visualization pinpoints the stored GPS coordinates of the pictures taken. In case multiple pictures were taken, the application draws a polygon that visualizes the movement of the smartphone while taking pictures. Furthermore, all stored pictures can be viewed using the web application.
The primary purpose of the web application is to support experts in verifying and, if necessary, modifying the location and information fields. The status of the data set describing each grid element can be “edit complete”, “ready for submission to OSM”, or “submitted to OSM”. The tagging options for power system elements comply with OpenStreetMap’s tagging standards.

Current OpenGridMap components
4.3 Power Grid Inference
The starting points of power grid inference are the positions of substations and distribution level transformers. Substations are the connection points between the high-voltage transmission level of the grid, whereas distribution level transformers represent the interface between the mid- and low-voltage sections of the distribution grid. We also know that most buildings are loads, i.e., they consume power at low voltage, and that most distribution grid feeders have a tree-like structure i.e., under normal operating conditions, there is usually just one path leading from each building to a substation.
Based on the data describing the geographic location and type of grid components, we have started to investigate methods for inferring tree topologies that connect all buildings within an area to the transmission grid. In particular, we have investigated the use of Voronoi regions for determining a realistic allocation of buildings to substations. Furthermore, we are considering the use of the shortest spanning tree and the Dijkstra routing algorithm for inferring the actual power lines.
Currently, OpenGridMap contains only a few self-collected data points. However, we have imported all the power grid data that is currently available in OpenStreetMap for selected regions in Bavaria. This data is not completely reliable, especially when it comes to the location and type of distribution grid transformers. However, we have found that at least the position of substations is accurately mapped.
We have begun to define inference areas based on Voronoi partitions around substations. Voronoi partitions separate an area into smaller regions based on the distance to points in a specific subset of the area. These points are also known as seeds. For each seed, the Voronoi algorithm creates a corresponding region consisting of all points closer to that seed than to any other. The resulting regions are called Voronoi cells. In Fig. 3b one can see the Voronoi cells that result when we use the mapped substations as seeds for a major German city, and the distribution transformers as seeds for a village. In both cases, one can see that the closer one gets to the center of the urban area, the smaller the cells become. This is a result of more substations or transformers situated in the center of a populated area, which in turn is (most likely) a result of larger buildings and thus a higher maximum load in the center versus the outskirts. Thus, using Voronoi regions as starting point for grid inference algorithms could be useful because it implicitly considers load distribution.
Based on an initial allocation of buildings to transformers, and transformers to substations, one can start to infer the actual power lines connecting the loads. We have started to investigate simple algorithms to perform this task. For instance, in Fig. 4a, one can see the result of a Minimum Spanning Tree (MST) algorithm applied to a fraction of the village area. Spanning trees are an interesting starting point because they are both trees and implicitly minimize the total length of the power lines. However, as one can readily observe, the results are hardly realistic, because the power lines are not aligned with the surrounding structures.
Another idea we have come up with is to take the position of streets into account. We thus implemented a grid inference method based on the Dijkstra routing algorithm for finding the shortest path that connects a transformer with buildings while following along the streets. The result can be seen in Fig. 4b. It looks much more promising, but certainly requires many adaptations to yield realistic results.
We are currently working in several directions to improve the grid inference methods. One the one hand, we are trying to combine the strengths of different algorithms, such as MST and routing algorithms. On the other hand, we want to consider more data in the inference process, e.g., available data on the size or use of buildings.

Voronoi partitions based on power grid devices location

Rule-based inference of power distribution network (village)
5 Outlook
This paper presents the purpose and current status of the OpenGridMap project. The goal of OpenGridMap is to provide researchers and practitioners with detailed, realistic, and readily usable data about the existing power grid infrastructure.
We discuss the technical landscape of the project and show how OpenGridMap will advance the state-of-the-art in power grid analysis and simulation. In particular, we discuss the range of different features that OpenGridMap will provide, and which cover data collection, verification, inference, and analysis. We describe the currently available prototype, which is freely available for use. The latest developments of the project can be found at opengridmap.com. OpenGridMap is also an open-source project, i.e., its entire source code can be accessed at github.com/opengridmap.
We believe that the access to more accurate and realistic power grid data will inform more efficient decision making in the context of the energy transition. It will also enable more relevant research in the area of Smart Grids, since researchers can use the data generated by OpenGridMap to evaluate their solutions in a realistic context.
References
ArcGIS platform Esri. http://www.esri.com/software/arcgis. Accessed 26 May 2015
Attrakdiff. attrakdiff.de. Accessed 26 May 2015
Energie-Atlas Bayern. www.energieatlas.bayern.de. Accessed 30 September 2010
EnergyMap. www.energymap.info. Accessed 26 May 2015
Google play store grid2osm GisApp. market.android.com/details?id=org.grid2osm.gisapp. Accessed 26 May 2015
QGIS A Free and Open Source Geographic Information System. www.qgis.org. Accessed 26 May 2015
Usage Limits for Google Maps API Web Services. developers.google.com/maps/documentation. Accessed 26 May 2015
Albert, R., Albert, I., Nakarado, G.L.: Structural vulnerability of the North American power grid. Phys. Rev. E 69(2), 025103 (2004)
Bazilian, M., Rice, A., Rotich, J., Howells, M., DeCarolis, J., Macmillan, S., Brooks, C., Bauer, F., Liebreich, M.: Open source software and crowdsourcing for energy analysis. Energy Policy 49, 149–153 (2012)
Chassin, D., Schneider, K., Gerkensmeyer, C.: GridLAB-D: an open-source power systems modeling and simulation environment. In: Transmission and Distribution Conference and Exposition, T&# x00026; D. IEEE/PES, pp. 1–5. IEEE (2008)
Cloteaux, B.: Limits in modeling power grid topology. In: Proceedings of the 2nd IEEE Network Science Workshop, NSW 2013, April 29–May 1, 2013, Thayer Hotel, West Point, NY, USA, pp. 16–22 (2013). http://dx.doi.org/10.1109/NSW.2013.6609189;http://dblp.uni-trier.de/rec/bib/conf/nsw/Cloteaux13
Deutsche Energie-Agentur: dena-Verteilnetzstudie: Ausbau- und Innovationsbedarf der Stromverteilnetze in Deutschland bis 2030. Technical report, November 2012
Esri: Enterprise GIS and the Smart Electric Grid. Technical report (2012)
Federal Minestry for Justice and Consumer Protection: Energiewirtschaftsgesetz (EnWG) (2005)
Gibson, R., Erle, S.: Google Maps Hacks: Tips & Tools for Geographic Searching and Remixing (Hacks)
Golightly, I., Jones, D.: Visual control of an unmanned aerial vehicle for power line inspection. In: Proceedings 12th International Conference on Advanced Robotics, ICAR 2005, pp. 288–295. IEEE (2005)
Haklay, M.M., Weber, P.: OpenStreetMap: user-generated street Maps. IEEE Pervasive Comput. 7(4), 12–18 (2008). http://dx.doi.org/10.1109/MPRV.2008.80
Heipke, C.: Crowdsourcing geospatial data. ISPRS J. Photogrammetry Remote Sens. 65(6), 550–557 (2010)
Hines, P., Blumsack, S., Cotilla Sanchez, E., Barrows, C.: The topological and electrical structure of power grids. In: 2010 43rd Hawaii International Conference on System Sciences (HICSS), pp. 1–10, January 2010
Hodson, H.: Google’s ingress game is a gold mine for augmented reality. New Sci. 216(2893), 19 (2012)
Kanhere, S.S.: Participatory sensing: crowdsourcing data from mobile smartphones in urban spaces. In: Hota, C., Srimani, P.K. (eds.) ICDCIT 2013. LNCS, vol. 7753, pp. 19–26. Springer, Heidelberg (2013)
Kersting, W.: Radial distribution test feeders. IEEE Trans. Power Syst. 6(3), 975–985 (1991)
Meehan, B.: Modeling Electric Distribution with GIS. Esri Press, Redlands (2013)
Nagel, H., Cichowski, R.R.: Systematische Netzplanung, 2nd edn. VDE Verlag (2008)
O’Hara, K.: Understanding geocaching practices and motivations. In: Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI 2008, pp. 1177–1186. ACM, New York (2008). http://doi.acm.org/10.1145/1357054.1357239
Pacific Northwestern National Laborattories: Modern Grid Initiative Distribution Taxonomy Final Report. Technical report (2008)
Strunz, K., Fletcher, R., Campbell, R., Gao, F.: Developing benchmark models for low-voltage distribution feeders. In: Power Energy Society General Meeting, PES 2009, pp. 1–3. IEEE, July 2009
U.S. Department of Energy: Grid 2030: A National Vision for Electricity’s Second 100 Years (2003)
U.S. Department of Energy: 2014 Smart Grid System Report (2014)
Zimmerman, R.D., Murillo-Sánchez, C.E., Thomas, R.J.: MATPOWER: Steady-state operations, planning, and analysis tools for power systems research and education. IEEE Trans. Power Syst. 26(1), 12–19 (2011)
Acknowledgement
We would like to thank Klaus Schreiber, Tanuj Ghinaiya, Clotilde Guinard and Shota Bakuraze from TU München for their contributions to the project. We would also like to thank Michael Metzger from Siemens AG for his contributions as advisor to the project. Most importantly, we would like to thank all the countless contributors that have helped crowdsource geographical data. This research was supported by a German Federal Ministry of Education and Research grant (BMBF 01IS12057) and the Alexander von Humboldt Foundation. During the cause of this work, H.A. Jacobsen held affiliations with the University of Toronto, Canada, and the Technische Universität München, Germany.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Rivera, J., Goebel, C., Sardari, D., Jacobsen, HA. (2015). OpenGridMap: An Open Platform for Inferring Power Grids with Crowdsourced Data. In: Gottwalt, S., König, L., Schmeck, H. (eds) Energy Informatics. EI 2015. Lecture Notes in Computer Science(), vol 9424. Springer, Cham. https://doi.org/10.1007/978-3-319-25876-8_15
Download citation
DOI: https://doi.org/10.1007/978-3-319-25876-8_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-25875-1
Online ISBN: 978-3-319-25876-8
eBook Packages: Computer ScienceComputer Science (R0)