
Abstract
We present a novel sparse modeling approach to non-rigid shape matching using only the ability to detect repeatable regions. As the input to our algorithm, we are given only two sets of regions in two shapes; no descriptors are provided so the correspondence between the regions is not know, nor do we know how many regions correspond in the two shapes. We show that even with such scarce information, it is possible to establish very accurate correspondence between the shapes by using methods from the field of sparse modeling, being this, the first non-trivial use of sparse models in shape correspondence. We formulate the problem of permuted sparse coding, in which we solve simultaneously for an unknown permutation ordering the regions on two shapes and for an unknown correspondence in functional representation. We also propose a robust variant capable of handling incomplete matches. Numerically, the problem is solved efficiently by alternating the solution of a linear assignment and a sparse coding problem. The proposed methods are evaluated qualitatively and quantitatively on standard benchmarks containing both synthetic and scanned objects.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Matching of deformable shapes is a notoriously difficult problem playing an important role in many applications [17]. Unlike rigid matching where the correspondence can be parametrized by a small number of parameters (rotation and translation of one shape w.r.t. the other [5, 10]), non-rigid matching typically uses point-wise representation of correspondence, which results in the number of degrees of freedom growing exponentially with the number of matched points.
Non-rigid correspondence methods try to find correspondence by minimizing some structure distortion. The structures can be point-wise (local descriptors [3, 14, 33, 37]), pair-wise (distances [6, 8, 13, 23]), or higher order [38].
In order to make the matching problem computationally feasible, it is crucial to reduce the size of the search space [34]. Most methods use a combination of point- and pair-wise structure matching in order to achieve this, and typically consist of three main components: feature detection, feature description, and regularization. Given two shapes, a feature detector allows to find a set of landmarks (points or regions) that are repeatable, i.e., appear (possibly with some inaccuracy) on both shapes. A feature descriptor then assigns to each feature a vector capturing some local geometric properties of the shape; very often, the two processes are combined into a single one. Using the descriptors, landmarks on two shapes can be matched (it has been shown [27] that under some conditions, correct landmark matching fully determines the intrinsic correspondence between the shapes). Such a matching reduces the search space size to points with similar descriptors. However, since the matching uses only local information, such correspondence can be noisy, and some kind of regularization based on higher-order information is needed to rule out bad or inconsistent correspondences. This information is also used to establish the correspondence between the rest of the points on the shapes. Often, the process is applied hierarchically, restricting the candidate matches to points in the proximity of the landmarks [31].
Computer graphics and geometry processing literature contains a plethora of approaches for each of the aforementioned components. Feature detection methods try to locate stable points or regions [11, 21] that are invariant under isometric deformations and robust to noise. Popular feature descriptors include the heat kernel signature (HKS) [14, 33], wave kernel signature (WKS) [3], global point signature (GPS) [30] or methods adopted from the domain of image analysis [37]. As regularization, pairwise structures such as geodesic [6, 23] or diffusion distances [8] and higher-order structures [38] have been used.
Alternatively, there have been several attempts to represent correspondences with a small set of parameters. Elad and Kimmel [13] used multidimensional scaling (MDS)-type methods to embed the intrinsic structure of the shapes into a low-dimensional Euclidean space, posing the problem of non-rigid matching as a problem of rigid matching of the corresponding embeddings (“canonical forms”). Mateus et al. [22] used spectral embeddings instead of MDS. Lipman and Funkhouser [20] embedded the shapes into a disk by means of conformal maps and represented the correspondence as a Möbius transformation.
More recently, Ovsjanikov et al. [26] introduced the functional representation of correspondences, allowing to perform a “calculus” of correspondences. In this approach, correspondence is modeled as a correspondence between functions on two shapes rather than points, and can be compactly represented in the Laplace-Beltrami eigenbasis as a matrix of coefficients of decomposition of the basis functions of the first shape in the basis of the second one. In this paper, we will be relying upon this latter representation.
1.1 Main Contribution
The main practical contribution of this paper is an approach for finding dense intrinsic correspondence between near-isometric shapes with very little known information: we only assume to be able to detect regions in two shapes in a repeatable enough way (i.e., that at least some regions in one shape correspond accurately enough to some other regions in another shape). No region descriptors are given, so the correspondence of the regions is unknown. The assumption of near-isometry assures that in the functional representation of [26], the unknown correspondence can be represented as a sparse matrix. The assumption of repeatable regions implies that there exists some unknown permutation that orders the regions according to their correspondence.
We formulate the problem of permuted sparse coding, in which we simultaneously look for the permutation and the correspondence, thereby introducing the very successful area of sparse modeling into efficient and state-of-the-art shape correspondence. We note that with the permutation fixed, our problem becomes the standard sparse coding problem; having the correspondence fixed, the problem becomes a linear assignment. This allows efficient numerical solution by alternating the two aforementioned problems and employing efficient solvers that exist for both.
Our method relies on a pretty common assumption that the shapes are nearly-isometric (though our experimental results show our approach still works even when departing from this assumption), and out of all methods we are aware of, it uses perhaps the scarcest amount of data to establish dense correspondence between the shapes. For example, sandard region detectors with high repeatability such as [21] are sufficient.
Compared to recent techniques for region-wise shape matching (see, e.g., [15, 16, 28, 36]), our approach has several important practical advantages: First, we do not use any feature descriptor. Second, most region-wise correspondence approaches require an additional step of extending the correspondence between matched regions to the rest of the points.
The rest of the paper is organized as follows. In Sect. 10.2, we overview the functional representation of correspondences, allowing to work with correspondences as algebraic structures, and state the main notions in sparse modeling. In Sect. 10.3, we formulate our problem of permuted sparse coding for establishing correspondence from a set of repeatable regions given in unknown order. We then extend the problem to the general setting where the region detection process is not perfectly repeatable. In Sect. 10.4, we describe the numerical optimization used to solve our permuted sparse coding problem. Experimental results are shown in Sect. 10.5. Finally, Sect. 10.6 discusses the limitations and possible extensions of the proposed framework and concludes the paper.
2 Background
2.1 Functional Representation of Correspondences
The direct representation of correspondences as maps between two non-Euclidean spaces limits the range of tools that can be employed for correspondence computation due to the lack of an algebraic structure. In this paper, we rely on the functional representation of correspondences introduced in [26], which overcomes this limitation. In what follows, we briefly review the main idea of such functional representations .
Let X and Y be two shapes, modeled as compact smooth Riemannian manifolds, related by a bijective correspondence t: X → Y. Then, for any real function \(f: X \rightarrow \mathbb{R}\), we can construct a corresponding function \(g: Y \rightarrow \mathbb{R}\) as g = f ∘ t −1. The correspondence t uniquely defines a mapping between two function spaces \(T: \mathcal{F}(X, \mathbb{R}) \rightarrow \mathcal{F}(Y, \mathbb{R})\), where \(\mathcal{F}(X, \mathbb{R})\) denotes the space of real functions on X. Such a representation is linear, since for every pair of functions f 1, f 2 and scalars α 1, α 2,
Assuming that X is equipped with a basis {ϕ i } i ≥ 1, any \(f: X \rightarrow \mathbb{R}\) can be represented as
with the a i being some representation coefficients (in case of an orthonormal basis, a i = 〈 f, ϕ i 〉; in the general case, the coefficients are found by projecting the function f on the bi-orthonormal basis). Due to the linearity of T,
If the shape Y is further equipped with a basis {ψ j } j ≥ 1, then for every i there exists coefficients c ij such that
and we can write
Let us now assume finite sampling of X and Y, with m samples (for simplicity, we assume that the shapes are sampled at the same number of samples m. The extension to the case with a different number of samples is straightforward). The bases are represented as the m × n matrices \(\boldsymbol{\Phi }\) and \(\boldsymbol{\Psi }\) containing, respectively, n discretized functions ϕ i and ψ j as the columns. The functions f and g = T( f) can now be represented as n-dimensional vectors \(\mathbf{f} =\boldsymbol{ \Phi }\mathbf{a}\) and \(\mathbf{g} =\boldsymbol{ \Psi }\mathbf{b}\) with the coefficients a and b. Using this notation, Equation (10.5) can be rewritten as \(\boldsymbol{\Psi }\mathbf{b} = T(\boldsymbol{\Phi }\mathbf{a}) =\boldsymbol{ \Psi }\mathbf{C}^{\mathrm{T}}\mathbf{a}\); since \(\boldsymbol{\Psi }\) is invertible, this simply means that
Thus, the n × n matrix C fully encodes the linear map T between the functional spaces, and contains the coordinates in the basis \(\boldsymbol{\Psi }\) of the mapped elements of the basis \(\boldsymbol{\Phi }\).
2.2 Point-to-Point Correspondence
Point-to-point correspondences assume that each point i on X corresponds to some point j on Y. In functional representation, this is equivalent to having C that makes each row of \(\boldsymbol{\Psi }\mathbf{C}^{\mathrm{T}}\) coincide with some row of \(\boldsymbol{\Phi }\) [26]. In applications requiring point-to-point correspondence, given some C, it can be converted into a point-to-point correspondence by thinking of \(\boldsymbol{\Phi }\) and \(\boldsymbol{\Psi }\) as n-dimensional points clouds, and orthogonal matrix C as a rigid alignment transformation between them. This procedure is equivalent to iterative closest point (ICP) in n dimensions [26], initialized with the given C 0: first, for each row i of \(\boldsymbol{\Psi }\mathbf{C_{0}}^{\mathrm{T}}\), find the closest row j i ∗ in \(\boldsymbol{\Phi }\) (this operation can be performed efficiently using approximate nearest neighbor algorithms). Then, find orthonormal C minimizing \(\sum _{i}\|\boldsymbol{\Phi }_{j_{i}^{{\ast}}}-\boldsymbol{ \Psi }\mathbf{C}^{\mathrm{T}}\|_{2}\) and set C 0 = C. This operation is repeated until convergence and can be performed efficiently over all the vertexes of X and Y using approximate nearest neighbor algorithms.
A more naive approach not imposing orthonormality of C is simply to map every standard Euclidean basis vector e i in \(\mathbb{R}^{m}\) representing a delta function centered at point i on X to the band-limited approximation, \(\boldsymbol{\Psi }\mathbf{C}\boldsymbol{\Phi }^{\mathrm{T}}\mathbf{e}_{i}\), of the corresponding indicator function on Y. If the maximum value of the latter vector is attained at point j on Y, the correspondence between point i on X and point j on Y is established.
2.3 Sparse Modeling
One of the main tools that will be used in this paper are sparse models . In what follows, we give a very brief overview of this vast field, and refer the reader to [12] for a comprehensive treatise. The central assertion of sparse modeling is that many families of signals (and later operations as here introduced) can be represented as a sparse linear combination in an appropriate domain, usually referred to as the dictionary. This can be written as x ≈ Dz, where x denotes the signal, D the dictionary, and z the sparse vector of representation coefficients. The dictionary is often selected to be overcomplete, i.e., with more columns than rows.
Finding the representation of a signal x in a given dictionary D is usually referred to as sparse representation pursuit or sparse coding. Among the variety of pursuit methods, we will focus on the so-called Lasso formulation [35] that finds z as the solution to the unconstrained convex program
The first term is the data fitting term, while the second term involving the ℓ 1 norm, \(\|\mathbf{z}\|_{1} = \vert z_{1}\vert + \mathop{\ldots } + \vert z_{n}\vert\), promotes a sparse solution; the parameter λ controls the relative importance of the latter. Proximal splitting methods [24] are among the most efficient and most frequently used numerical tools to solve problem (10.7); in Sect. 10.4, we present a variant of the proximal splitting algorithms for the solution of the pursuit problem arising in shape correspondence as detailed in the sequel.
In some cases, signals not admitting the simplistic model of element-wise sparsity still manifest more intricate types of structured sparsity. In structured sparse models, the non-zero elements of z come in groups or, more generally, in hierarchies of groups. A common class of structured pursuit problems can be formulated as convex programs of the form
where the ℓ 1, 2 norm, ∥ z ∥ 1, 2 = ∥ z 1 ∥ 2 + ⋅ + ∥ z k ∥ 2, assumes that the vector z is decomposed into k non-overlapping sub-vectors z i , and promotes group-wise sparse solutions (i.e., the solution will have a small number of groups with non-zero coefficients, but the sub-vectors representing each such non-zero group will be dense).
While structured sparse models enforce group structure of each representation vector independently, it is often useful to consider the structure shared by multiple vectors. Collaborative sparse models operate on data matrices X, in which each column corresponds to a data vector, and assert that the patterns of non-zero coefficients are shared across the corresponding representation vectors, Z. This is achieved by solving a pursuit problem of the form
where the first term involving the Frobenius norm serves as the data fitting term, and the second term with the ℓ 2, 1 norm promotes row-wise sparsity of the solution. The ℓ 2, 1 norm is defined as ∥ Z ∥ 2, 1 = ∥ z 1 T ∥ 2 + ⋯ + ∥ z m T ∥ 2, where z i T denotes the i-th row of Z (note the difference from the ℓ 1, 2 column-wise counterpart!).
In this paper, we use formulate the shape correspondence problem using a sparse model, and use sparse modeling tools to efficiently solve it.
3 Sparse Modeling of Correspondences
In case the shapes X and Y are isometric and the corresponding Laplace-Beltrami operators have simple spectra (no eigenvalues with multiplicity greater than one), the harmonic bases (Laplacian eigenfunctions) have a compatible behavior, ψ i = T(ϕ i ) such that c ij = ±δ ij . Choosing the discretized eigenfunctions of the Laplace-Beltrami operator as \(\boldsymbol{\Phi }\) and \(\boldsymbol{\Psi }\) causes every low-distortion correspondence being represented by a nearly diagonal, and therefore very sparse, matrix C.

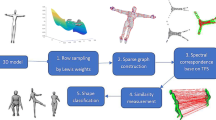
Near isometric shape correspondence as a sparse modeling problem (see details in text): Indicator functions of repeatable regions on two shapes are detected and represented as matrices of coefficients A and B in the corresponding orthonormal harmonic bases \(\boldsymbol{\Phi }\) and \(\boldsymbol{\Psi }\). When the regions are brought into correspondence, the point-to-point correspondence between the shapes can be encoded by an approximately diagonal matrix C. In the proposed procedure termed as permuted sparse coding, we solve \(\boldsymbol{\Pi }\mathbf{B} = \mathbf{A}\mathbf{C} + \mathbf{O}\) simultaneously for an approximately diagonal C and the permutation \(\boldsymbol{\Pi }\) bringing the indicator functions into correspondence. To cope with imperfectly matching regions, we relax the surjectivity of the permutation and absorb the mismatches into a row-wise sparse outlier matrix O. For visualization purposes, the coloring of the regions is consistent as after the application of the permutation. Correspondence is shown between a synthetic TOSCA and scanned SCAPE shape
In practice, due to lack of perfect isometry and numerical inaccuracies, the diagonal structure of C is manifested for the first eigenfunctions corresponding to the small eigenvalues (low frequencies), and is gradually lost with the increase of the frequency (see, e.g., Fig. 10.1). However, a correspondence with low metric distortion will usually be represented by a sparse C. We use this property to formulate the computation of correspondences in terms of a sparse representation pursuit problem.
Let us assume to have some region (or feature) detection process that given a shape X produces a collection of functions \(\{\,f_{i}: X \rightarrow \mathbb{R}\}\) based on the intrinsic properties of the shape only. For example, the f i ’s can be indicator functions of the maximally stable components (regions) of the shape [21]. Since the process is intrinsic, given a nearly isometric deformation Y or X, it should produce a collection of similar functions \(\{g_{j}: Y \rightarrow \mathbb{R}\}\).
To simplify the presentation, let us assume that the process is perfectly repeatable in the sense that it finds q functions on X and Y, such that for every f i there exists a g j = f i ∘ t related by the unknown correspondence t. We stress that the ordering of the f i ’s and g j ’s is unknown, i.e., we do not know to which g j in Y a f i in X corresponds. This ordering can be expressed by an unknown q × q permutation matrix \(\boldsymbol{\Pi }\) (in Sect. 10.3.2, we consider the more general case when the number of functions detected on X and Y can be different, i.e., \(\boldsymbol{\Pi }\) is non-square).
Representing the functions in the bases on each shape, we have \(\mathbf{f}_{i} =\boldsymbol{ \Phi }\mathbf{a}_{i}\) and \(\mathbf{g}_{j} =\boldsymbol{ \Psi }\mathbf{b}_{j}\). Since each pair of corresponding f i and g j shall satisfy (10.6), we can write
where A and B are the q × n matrices containing, respectively, a i T and b j T as the rows, and π ij = 1 if a i corresponds to b j and zero otherwise.
3.1 Permuted Sparse Coding
Note that in relation (10.10), both \(\boldsymbol{\Pi }\) and C are unknown, and solving for them is a highly ill-posed problem. However, by recalling that the correspondence we are looking for should be represented by a nearly-diagonal C, we formulate the following problem
where the minimum is sought over n × n matrices C (capturing the correspondence t between the shapes in the functional representation) and q × q permutations \(\boldsymbol{\Pi }\) (capturing the correspondence between the detected regions on the shapes). The first term containing the Frobenius norm can be interpreted as the data term, while the second term, containing the weighted ℓ 1 norm promotes a sparse C; ⊙ denotes element-wise multiplication, and the non-negative parameter λ determines the relative importance of the penalty. Small weights w ij in W are assigned close to the diagonal, while larger weights are selected for the off-diagonal elements. This promotes diagonal solutions.
The solution of (10.11) can be obtained using alternating minimization iterating over C with fixed \(\boldsymbol{\Pi }\), and \(\boldsymbol{\Pi }\) with fixed C. Note that with fixed \(\boldsymbol{\Pi }\), we can denote \(\mathbf{B}' =\boldsymbol{ \Pi }\mathbf{B}\) and reduce problem (10.11) to
which resembles the Lasso problem frequently employed for the pursuit of sparse representations. On the other hand, when C is fixed, we set A′ = AC, reducing the optimization objective to
Since \(\boldsymbol{\Pi }\) is a permutation matrix, \(\boldsymbol{\Pi }^{\mathrm{T}}\boldsymbol{\Pi } = \mathbf{I}\), and the only non-constant term remaining in the objective is the second linear term. Problem (10.11) thus becomes
where E = A′B T = ACB T and the maximization is performed over permutation matrices. To make it practically solvable, we allow \(\boldsymbol{\Pi }\) to be a double-stochastic matrix, which yields the following linear assignment problem:
We refer to problem (10.11) as permuted sparse coding, and propose to solve it by alternating the solution of the standard sparse coding problem (10.12) and the solution of the linear assignment problem (10.15). The sparsity constraint has a regularization effect on this, otherwise extremely ill-posed, problem, and the following strong property holds:
Proposition 10.1
The process alternating subproblems (10.12) and (10.15) converges to a local minimizer of the permuted sparse coding problem (10.11) .
Due to lack of space, the proof will be provided in an extended version of this contribution. This result means, among other, that despite the relaxation of the permutation matrix to a double-stochastic matrix in the assignment subproblem (10.15), we are actually recovering a true permutation matrix. This follows from the total unimodularity of the constraints in (10.15).
We further conjecture that when the solution of (10.12) attains a sufficiently small value of the data fitting term (the ℓ 2 term), global convergence to a unique minimizer can be guaranteed under non-restrictive technical assumptions. While we do not yet have a formal proof for this empirically observed behavior, we believe that techniques similar to [1] can be used to prove this conjecture.
3.2 Robust Permuted Sparse Coding
So far, we have assumed the existence of a bijective, albeit unknown, correspondence between the f i ’s and the g j ’s. In practice, the process detecting these functions (e.g., stable regions) is often not perfectly repeatable. In what follows, we will make a more realistic assumption that q functions f i are detected on X, and r functions g j detected on Y (without loss of generality, q ≤ r), such that some f i ’s have no counterpart g j , and vice versa. This partial correspondence can be described by a q × r partial permutation matrix \(\boldsymbol{\Pi }\) in which now some columns and rows may vanish.
Let us assume that s ≤ q f i ’s have corresponding g j ’s. This means that there is no correspondence between r − s rows of B and q − s rows of A, and the relation \(\boldsymbol{\Pi }\mathbf{B} \approx \mathbf{A}\mathbf{C}\) holds only for an unknown subset of its rows. The mismatched rows of B can be ignored by letting some columns of \(\boldsymbol{\Pi }\) vanish, meaning that the correspondence is no more surjective. This can be achieved by relaxing the equality constraint \(\boldsymbol{\Pi }^{\mathrm{T}}\mathbf{1} = \mathbf{1}\) in (10.15) replacing it with \(\boldsymbol{\Pi }^{\mathrm{T}}\mathbf{1} \leq \mathbf{1}\). However, dropping injectivity as well and relaxing \(\boldsymbol{\Pi }\mathbf{1} = \mathbf{1}\) to \(\boldsymbol{\Pi }\mathbf{1} \leq \mathbf{1}\) would result in the trivial solution \(\boldsymbol{\Pi } = \mathbf{0}\). To overcome this difficulty, we demand every row of A to have a matching row in B, and absorb the r − s mismatches in a row-sparse q × n outlier matrix O that we add to the data term of (10.11). This results in the following problem
which we refer to as robust permuted sparse coding. The last term involves the ℓ 2, 1 norm
which can be thought of as the ℓ 1 norm of the vector of the ℓ 2 norms of the rows o i T of O. The ℓ 2, 1 norm promotes row-wise sparsity, allowing to absorb the errors in the data term corresponding to the rows of A having no corresponding rows in B; the parameter μ ≥ 0 controls the amount of regularization. The q × r matrix \(\boldsymbol{\Pi }\) is searched over all injective correspondences.
As before, problem (10.16) is split into two sub-problems, one with the fixed permutation \(\boldsymbol{\Pi }\),
with \(\mathbf{B}' =\boldsymbol{ \Pi }\mathbf{B}\), and the other one with the fixed C,
with \(\mathbf{E} = \left (\mathbf{A}\mathbf{C}\right )\mathbf{B}^{\mathrm{T}}\). Note that an injective correspondence is relaxed into a row-wise stochastic and column-wise sub-stochastic matrix \(\boldsymbol{\Pi }\). Proposition 10.1 simply extends to the robust formulation as well.
4 Numerical Solution
The solution of the robust permuted sparse coding problem (10.16) is reduced to alternating two relatively standard optimization problems , and there exist many readily available efficient numerical tools to solve them. For the sake of completeness, we provide a concise description of the involved numerics.
Problem (10.19), being a simple linear assignment problem, is solved using the Hungarian algorithm. As an alternative, linear programming can be employed. To reduce the search space size, we disallow certain impossible permutations such as those relating regions with very distinct sizes.
In order to solve (10.18), we use the family of forward-backward splitting algorithms [24] designed for solving unconstrained optimization problems in which the cost function can be split into the sum of two terms,
one, h 1, convex and differentiable with an α-Lipschitz continuous gradient and another, h 2, convex extended real valued and possibly non-smooth. Clearly, problem (10.18) falls in this category.
The forward-backward splitting method with fixed constant step defines a series of iterates, {x k} k ,
where
denotes the proximal operator of h 2. Many alternatives have been studied in the literature to improve the convergence rate of forward-backward splitting algorithms [4, 24]. Accelerated versions reach quadratic convergence rates (the best possible for the class of first order methods). The discussion of theses methods is beyond of the scope of this paper.
In our case, the objective comprises a quadratic function h 1 = ∥ B′ −AC −O ∥ F 2 and the non-smooth function h 2 = λ ∥ W ⊙C ∥ 1 +μ ∥ O ∥ 2, 1. The proximal operator splits into two operators, one in C and another one in O, both having closed forms. The proximal operator corresponding to the ℓ 1 norm term is given by the weighted soft threshold function
where the absolute value and the sign functions are applied element-wise. The i-th row of the proximal operator corresponding to the ℓ 2, 1 norm term is given by
The gradient of the quadratic data term with respect to C and O is given straightforwardly by
The Lipschitz constant of the gradient determining the step size is bounded by the maximum eigenvalue
Plugging the above expressions together into (10.21) yields the forward-backward splitting optimization summarized in Algorithm 1.
Algorithm 1: Forward-backward splitting method for the solution of (10.18)

5 Experimental Results
In order to evaluate our approach, we performed several experiments on data from the TOSCA [7], SHREC’11 [9] and SCAPE [2] datasets. The TOSCA set contains high-quality (10–50 K vertices) synthetic triangular meshes of humans and animals in different poses with known ground truth correspondences between them. SHREC’11 contains meshes from the TOSCA set undergoing simulated transformations. The SCAPE set contains high-resolution (12 K vertices) scans of a real human in different poses.
For each pair of shapes we calculated the MSERs using 6–10 eigenfunctions and selected regions with areas of at least 5–10 % of the total shape area, resulting in about 5–15 detected regions (see Fig. 10.1). These parameters were selected empirically for our data sets.
The segments of each shape were projected onto 20 eigenfunctions and the corresponding C matrix was calculated by solving the sparse coding subproblem (10.18) using an accelerated variant of the method described in Sect. 10.4. The linear assignment subproblem (10.15) was solved using the Hungarian method [19]. We initialized the permutation matrix with \(\boldsymbol{\Pi } = \frac{1} {q}\mathbf{1}\mathbf{1}^{\mathrm{T}}\), and the correspondence matrix with C = 0. We observed a rapid convergence of the alternating minimization procedure in one or two iterations (see Fig. 10.2 where for visualization purposes, \(\boldsymbol{\Pi }\) was initialized to identity). We found that the method consistently converged to the same solution regardless of the initialization. Finally, after convergence of the alternating minimization, the resulting C was refined using the method described in Sect. 10.2.2.

Outer iterations of robust permuted sparse coding alternating the solution of the sparse representation purusit problem (10.18) with the linear assignment problem (10.19). Three iterations, shown left-to-right, are required to achieve convergence. Depicted are the permutation matrix \(\boldsymbol{\Pi }\) (first row), the correspondence matrix C (second row), and the outlier matrix O (last row). The resulting point-to-point correspondence and the correspondence matrix C refined using the ICP as described in Sect. 10.2.2 are shown in the rightmost column

Dense point-to-point correspondences obtained between the left TOSCA human shape and its approximate isometries. Corresponding points are marked with consistent colors. The average correspondence distortion is depicted in units of the reference shape diameter. The highest distortions are obtained on the non-isometric joints, but do not exceed 6 % of the diameter

Dense point-to-point correspondences obtained between the left SCAPE human shape and various other poses. Corresponding points are marked with consistent colors

First row: point-to-point correspondences obtained between different non-isometric shapes: male and female (left); two strongly non-isometric deformations of the dog shape from the TOSCA set (middle); TOSCA and SCAPE human shapes (right). Second row: Point-to-point correspondences obtained between SHREC shapes undergoing nearly isometric deformations and (from left to right) spike noise, Gaussian noise, and topological noise in the form of large and small holes

Top: dense point-to-point correspondences obtained between two SCAPE human shapes using 45 and 43 WKS point features (rejected features are marked in red). Corresponding points are marked with consistent colors. Bottom, left-to-right: recovered permutation matrix \(\boldsymbol{\Pi }\) (rejected matches are marked in red); outlier matrix O; and correspondence matrix C


Dense point-to-point correspondences obtained between the left TOSCA human shape and various other non-isometric shapes. The approach fails for significantly non-isometric shapes due to deviation from the diagonal form of C
The robustness of the method is demonstrated in Figs. 10.3, 10.4, and 10.5; correct correspondences are computed even when the shapes undergo non-isometric deformations and are contaminated by geometric or topological noise. In Fig. 10.6, we used around 45 WKS features detected on two SCAPE shapes, to demonstrate that our method works equally well with point features. Observe how robust permuted sparse coding detects and ignores features without matches, and note the effect of such outliers on the matrices \(\boldsymbol{\Pi }\) and O. Figure 10.7 shows a quantitative evaluation and comparison of our algorithm to other correspondence algorithms on the SCAPE data set. The evaluation was performed using the code and data from [18]. Comparison to [26] was performed in two settings: In the first setting, k = 20 basis functions were used with indicator functions of the detected stable regions (about ten regions per shape). In the second setting, k = 100 harmonics were used, and 200 wave kernel maps were automatically generated for each region, following verbatim [26]. Our method outperforms existing methods while using less information. Finally, Fig. 10.8 shows the failure of our approach for very non-isometric shapes.
The code used in the experiments was implemented in Matalb with parts written in C. The approximate nearest neighbor search in the ICP refinement step was accelerated using the FLANN library. The experiments were run on a 2.4 GHz Intel Xeon CPU. End-to-end execution time varied from 10 to 50 s, with the detailed breakdown summarized in Table 10.1.
6 Discussion and Conclusion
In this paper, we posed the problem of finding intrinsic correspondence between near-isometric deformable shapes as a problem of sparse modeling. Given only two sets of regions in the two shapes with unknown correspondence, we are able to infer a dense correspondence between the shapes from two assumptions: that at least some of the regions in the two sets are corresponding; and that the shapes are nearly-isometric. The latter assumption implies that in functional representation in harmonic bases the unknown correspondence between the shapes is modeled as a sparse nearly-diagonal matrix; the former assumption implies that there exists an unknown permutation that reorders the regions in corresponding order. To find both the permutation and the correspondence, we formulate the novel permuted sparse coding problem and propose its efficient solution. An additional sparse coding term addressing outliers is added to the model for handling partial matching and formulated as the robust permuted sparse coding.
To the best of our knowledge, among other dense correspondence techniques, our method relies on the smallest amount of information (the ability to find some repeatable regions) and quite generic assumption (near-isometric shapes). In particular, it allows us to use only a region detector without a feature descriptor to find a high-quality correspondence between two shapes.
We note that, as in [26], we explicitly assume that the shapes are nearly isometric, and that their Laplacians have simple spectrum. This assumption assures that the Laplacian eigenbases \(\boldsymbol{\Phi }\) and \(\boldsymbol{\Psi }\) have a compatible behavior, and as a result C has a nearly-diagonal structure. If we try to relax the restriction on multiplicity, C will still be sparse, but with unknown sparse structure. We can still use our problem in this setting, imposing a different sparsity constraint on C.
Relaxing the assumptions even more, we can depart from the near-isometric model, e.g. considering applications where one wishes to match shapes with roughly similar geometry but very different details (such as a horse and an elephant). In such a generic setting, the Laplacian eigenbases may differ dramatically, and thus C have a non-sparse structure. It is possible to incorporate the bases \(\boldsymbol{\Phi }\) and \(\boldsymbol{\Psi }\) as variables into our problem, and in addition to finding the permutation \(\boldsymbol{\Pi }\) and correspondence C find also the bases in which C will have a diagonal structure. This problem is akin to dictionary learning used in the sparse modeling literature. In future research, we will study such a generalization of our framework in the hope to find correspondences between non-isometric shapes. Another possible generalization of our problem is for finding correspondence between collections of shapes [18, 25].
It is also worthwhile noting that the novel structured sparse modeling techniques introduced in [32] provide an alternative to the optimization-based pursuit by replacing the iterative proximal algorithm with a learned fixed-complexity feed-forward network. Approaching shape correspondence as a learning problem from this perspective seems a very attractive future research direction.
Finally, being purely intrinsic, the described correspondence computation algorithms are agnostic to intrinsic symmetries [29], i.e., automorphisms that do not affect the manifold metric. Incorporating extrinsic information such as the direction of the normal to the surface, or adding knowingly corresponding seed points [1] can resolve these ambiguities. We leave these issues for future research.
References
Aflalo, Y., Bronstein, A., Kimmel, R.: On convex relaxation of graph isomorphism. Proc. Nat. Acad. Sci. 112 (10), 2942–2947 (2015)
Anguelov, D., Srinivasan, P., Koller, D., Thrun, S., Rodgers, J., Davis, J.: Scape: shape completion and animation of people. In: Proceedings of the SIGGRAPH Conference, Los Angeles (2005)
Aubry, M., Schlickewei, U., Cremers, D.: The wave kernel signature: a quantum mechanical approach to shape analysis. In: Proceeding of Workshop on Dynamic Shape Capture and Analysis, Barcelona (2011)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Img. Sci. 2, 183–202 (2009)
Besl, P.J., McKay, N.D.: A method for registration of 3D shapes. Trans. PAMI 14, 239–256 (1992)
Bronstein, A.M., Bronstein, M.M., Kimmel, R.: Generalized multidimensional scaling: a framework for isometry-invariant partial surface matching. PNAS 103 (5), 1168–1172 (2006)
Bronstein, A.M., Bronstein, M.M., Kimmel, R.: Numerical Geometry of Non-rigid Shapes. Springer, New York (2008)
Bronstein, A.M., Bronstein, M.M., Kimmel, R., Mahmoudi, M., Sapiro, G.: A Gromov-Hausdorff framework with diffusion geometry for topologically-robust non-rigid shape matching. IJCV 89 (2–3), 266–286 (2010)
Bronstein, M.M., Bustos, B., Darom, T., Horaud, R., Hotz, I., Keller, Y., Keustermans, J., Kovnatsky, A., Litman, R., Reininghaus, J., Sipiran, I., Smeets, D., Suetens, P., Vandermeulen, D., Zaharescu, A., Zobel, V., Boyer, E., Bronstein, A.M.: Shrec 2011: robust feature detection and description benchmark. In: EUROGRAPHICS Workshop on 3D Object Retrieval (3DOR), Llandudno (2011)
Chen, Y., Medioni, G.: Object modeling by registration of multiple range images. In: Proceeding of Conference on Robotics and Automation, Sacramento (1991)
Digne, J., Morel, J.M., Audfray, N., Mehdi-Souzani, C.: The level set tree on meshes. In: Proceeding 3DPVT, Paris (2010)
Elad, M.: Sparse and redundant representations: from theory to applications in signal and image processing. Springer, New York (2010)
Elad, A., Kimmel, R.: Bending invariant representations for surfaces. In: Proceedings of CVPR, Colorado, pp. 168–174 (2001)
Gebal, K., Bærentzen, J.A., Aanæs, H., Larsen, R.: Shape analysis using the auto diffusion function. Comput. Graph. Forum 28 (5), 1405–1413 (2009)
Golovinskiy, A., Funkhouser, T.: Consistent segmentation of 3d models. Comput. Graph. 33 (3), 262–269 (2009)
Huang, Q., Koltun, V., Guibas, L.: Joint shape segmentation with linear programming. TOG 30, 125 (2011)
Kaick, O.V., Zhang, H., Hamarneh, G., Cohen-Or, D.: A survey on shape correspondence. Comput. Graph. Forum 20, 1–23 (2010)
Kim, V.G., Lipman, Y., Funkhouser, T.: Blended intrinsic maps. TOG 30 (4), 79 (2011)
Kuhn, H.W.: The Hungarian method for the assignment problem. Nav. Res. Logist. Quart. 2, 83–97 (1955)
Lipman, Y., Funkhouser, T.: Mobius voting for surface correspondence. ACM Trans. Graph. (Proc. SIGGRAPH) 28 (3), 72 (2009)
Litman, R., Bronstein, A.M., Bronstein, M.M.: Diffusion-geometric maximally stable component detection in deformable shapes. Comput. Graph. 35 (3), 549–560 (2011)
Mateus, D., Horaud, R., Knossow, D., Cuzzolin, F., Boyer, E.: Articulated shape matching using Laplacian eigenfunctions and unsupervised point registration. In: Proceeding CVPR, Anchorage (2008)
Memoli, F., Sapiro, G.: A theoretical and computational framework for isometry invariant recognition of point cloud data. Found. Comput. Math. 5 (3), 313–347 (2005)
Nesterov, Y.: Gradient methods for minimizing composite objective function. In: CORE Discussion Paper 2007/76, Center for Operations Research and Econometrics (CORE). Catholic University of Louvain, Louvain-la-Neuve (2007)
Nguyen, A., Ben-Chen, M., Welnicka, K., Ye, Y., Guibas, L.: An optimization approach to improving collections of shape maps. Comput. Graph. Forum 30, 1481–1491 (2011)
Ovsjanikov, M., Ben-Chen, M., Solomon, J., Butscher, A., Guibas, L.: Functional maps: a flexible representation of maps between shapes. TOG 31 (4), 129–139 (2012)
Ovsjanikov, M., Mérigot, Q., Mémoli, F., Guibas, L.: One point isometric matching with the heat kernel. Comput. Graph. Forum 29, 1555–1564 (2010)
Pokrass, J., Bronstein, A.M., Bronstein, M.M.: A correspondence-less approach to matching of deformable shapes. In: Proceeding SSVM, Ein-Gedi (2011)
Raviv, D., Bronstein, A.M., Bronstein, M.M., Kimmel, R.: Symmetries of non-rigid shapes. In: Proceeding of Workshop on Non-rigid Registration and Tracking Through Learning (NRTL), Stony Brook (2005)
Rustamov, R.M.: Laplace-Beltrami eigenfunctions for deformation invariant shape representation. In: Proceeding of SGP, Barcelona, pp. 225–233 (2007)
Sahillioglu, Y., Yemez, Y.: Coarse-to-fine combinatorial matching for dense isometric shape correspondence. Comput. Graph. Forum 32, 177–189 (2012)
Sprechmann, P., Bronstein, A.M., Sapiro, G.: Learning efficient structured sparse models. In: Proceedings of ICML, Edinburgh (2012)
Sun, J., Ovsjanikov, M., Guibas, L.J.: A concise and provably informative multi-scale signature based on heat diffusion. In: Proceedings of SGP, Berlin (2009)
Tevs, A., Berner, A., Wand, M., Ihrke, I., Seidel, H.P.: Intrinsic shape matching by planned landmark sampling. Comput. Graph. Forum 30, 543–552 (2011)
Tibshirani, R.: Regression shrinkage and selection via the LASSO. J. R. Stat. Soc. Ser. B 58 (1), 267–288 (1996)
Van Kaick, O., Tagliasacchi, A., Sidi, O., Zhang, H., Cohen, D.-Or, Wolf, L., Hamarneh, G.: Prior knowledge for part correspondence. Comput. Graph. Forum 30, 553–562 (2011)
Zaharescu, A., Boyer, E., Varanasi, K., Horaud, R.: Surface feature detection and description with applications to mesh matching. In: Proceedings of CVPR, Miami (2009)
Zeng, Y., Wang, C., Wang, Y., Gu, X., Samaras, D., Paragios, N.: Dense non-rigid surface registration using high-order graph matching. In: Proceedings of CVPR, San Francisco (2010)
Acknowledgements
Work partially supported by GIF, ISF, and BSF. M.B. is supported by the ERC Starting grant No. 307047. A.B. is supported by the ERC Starting Grant No. 335491.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Pokrass, J., Bronstein, A.M., Bronstein, M.M., Sprechmann, P., Sapiro, G. (2016). Sparse Models for Intrinsic Shape Correspondence. In: Breuß, M., Bruckstein, A., Maragos, P., Wuhrer, S. (eds) Perspectives in Shape Analysis. Mathematics and Visualization. Springer, Cham. https://doi.org/10.1007/978-3-319-24726-7_10
Download citation
DOI: https://doi.org/10.1007/978-3-319-24726-7_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-24724-3
Online ISBN: 978-3-319-24726-7
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)