
Abstract
A technique for automatic high-level C program mapping onto compute systems with programmable pipeline architecture is presented in this article. An example of such a system could be a CPU with an FPGA accelerator or the corresponding system on a chip. The mapping is implemented on the base of Optimizing Parallelizing System (www.ops.rsu.ru) and C2HDL converter from C to the hardware description language (VHDL). HDL code generating from OPS internal representation would allow to utilize the user dialog to generate a family of equivalent chips, from which the user could select the most suitable one for various characteristics. The development of the current work would allow to create for the first time the C language compiler for the programmable pipeline architecture.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Reconfigurable computing
- Pipeline computing
- High-level synthesis
- Parallelizing compiler
- High level internal representation
- HDL
- FPGA
1 Introduction
The use of programmable pipeline computing devices increases each year, while the development of high-level programming design tools for them still remains way behind. In this article a project of a compiler from C language to the computer with programmable architecture is considered as well as the current work on its implementation. The “target platform” here stands either for a system on a chip, which contains both the central processing core and the configurable logic block (CLB) matrix, or for a common CPU with an FPGA accelerator. Designing a C language compiler for programmable architectures could accelerate their application and development.
The pipeline computational systems stay apart from the well-known Flynn parallel computer classification: MIMD or SIMD. Pipeline computers are sometimes separated into MISD class (Multiple Instructions, Single Data flow). These computers are efficient for many those problems for which computers of MIMD or SIMD architectures are inefficient or poorly efficient.
The pipeline computers are used in many hardware-software systems and, for some problems, they show considerably higher performance (up to 2–3 orders) than the multi-purpose processors. The substantial progress in pipeline computing development is brought by the technologies of field-programmable gate arrays (FPGA). Conventionally, pipeline computers are used in hardware-software systems. The bottleneck of such computers is long time needed for an FPGA to be reprogrammed. The works of K. Bondalapati are dedicated to this problem [3]. To speed up FPGA reprogramming, a special buffer holding the next configuration, is used. In the Research Institute for Multiprocessor Computing Systems of the Southern Federal University the reconfigurable pipeline computers are designed with only the connections between the computing elements being able for reprogramming to achieve fast reconfiguration speed. Another architecture, which is being developed under V. Corneyev’s direction, is also positioned as pipeline-based. In this architecture, it is possible to select pipeline configurations in the grid consisting of compute cores. The cluster with nodes equipped with programmable FPGA accelerators has been assembled under A. Lacis’ direction. The language named Autocode-FPGA is suggested for software development for this cluster and is more high-level than VHDL but still is at the level close to Assembler.
The computing units with programmable and reprogrammable architectures are being developed for the wide range of applications and show high efficiency [9]. Particularly, multi-pipeline (or parallel pipeline) systems, which could be considered as a generalization of both the pipeline and the multi-core systems, are of great interest [13]. The algorithms for automatic mapping of a high-level language onto multi-pipeline systems are studied in [11]. In this work automatic generation of multi-pipeline circuits and mapping high-level programs onto them are discussed.
The compiler under development is based on Optimizing Parallelizing System (http://www.ops.rsu.ru/). It includes the converter from OPS program internal representation to the language of electronic circuits description (VHDL) [6]. This converter is able to accept input data ranges in addition to the source code as its input. It would be much more difficult to implement a pipeline system’s VHDL code automatic generation using a low-level register-based internal representation, such as LLVM of Clang compiler or RTL and Gimple of GCC compiler family. Apart from OPS, a high-level internal representation (in which optimization analysis and transformations are performed) is used in ROSE compiler infrastructure [10] and SUIF parallelizing system [1].
2 Related Works Overview
High-level synthesis tools gain more interest in our days. The major electronic design automation (EDA) tool vendors incorporate converters from high-level language to electronic design into their products. These tools are targeted either to standalone FPGAs/ASICs, or to hybrid systems with FPGAs [5].
Two main approaches of the high level synthesis tools could be distinguished. The first one involves using traditional programming languages like C and C++ to express hardware algorithm implementation. Catapult C, Vivado Design Suite, Impulse CoDeveloper, Altium Designer, and HDL Coder for MATLAB are the examples of commercial products using such an approach. Academic research projects include PandA (http://panda.dei.polimi.it/), C-to-Verilog [2], TCE [7], and Parallel Intellectual Compiler. Sometimes the means of high-level languages used in these systems are not sufficient for expressing the reconfigurable schematics. For example, Trident Compiler [12] requires from the user to manually partition the code into software and hardware parts.
Other systems, namely Mitrion-C, Handel-C, and HaSCoL [4] use specially designed language constructs to express the hardware abstractions missing in traditional programming languages: manipulating with separate bits, parallel processes with data communications, synchronizations, etc. This makes the user to rewrite old programs and also makes these languages more low-level. However these languages still have advantages over HDL: many time-consuming routine tasks could be done automatically (for example, pipeline generating). On the other hand, tools that use traditional input languages try to incorporate more elaborate program analysis to extract the missing information. For example, a generalization of data-flow graph, called bit-flow graph, may help to generate efficient hardware implementations of the algorithms expressed with C bitwise operators (bit shfting, reversing, extraction, etc.) [14].
3 The Implementation
3.1 Structure of the Compiler from C to the Programmable Computational System
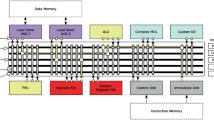
The task of compiling the C language source code into the program for the system with a programmable architecture consists of four subtasks, with the separate compilation module is dedicated to each of them (Fig. 1).

The structure of the compiler from C to the programmable computational system.
-
The converter from C to VHDL (C2HDL). Loop pipelining and transformation of the initial program fragments into computational core descriptions in VHDL language takes place here.
-
The configurable driver consisting of modules written in C and VHDL which provide:
-
Data and control commands transfer between a CPU and computational cores on FPGAs using the selected protocol;
-
Data exchange synchronization and the data transfer channel optimal bandwidth distribution;
-
Synchronization of FPGA computational threads with the CPU main control thread.
-
-
The build manager. Using all the generated files, it assembles two projects in C and VHDL respectively, with compilation settings for each of them. It also manages the source code compilation process into the executable files for the target platforms.
The compiler takes a source code and the compilation settings as its input. The output is the transformed program in C language and the computational core description in VHDL.
3.2 Mapping Programs onto a Programmable Computer
Parallel computing, including the pipeline one, should be applied to the program fragments with long computational time. In this work we consider acceleration of code fragments which contain loop nests. Let us consider a nest of n nested loops:

The innermost nested loop is subject to be pipelined. The counters of the outer loops could be considered as parameters defining a cluster node with an accelerator that should execute the innermost loop (the same loop for different values of outer loops’ counters should be executed on different nodes).
The main idea for the current project involves the system under development, which takes a C program with a loop nest as input. The loop nest is transformed into the form convenient for mapping it onto a pipeline architecture using the parallelizing system. The innermost loop of the nest is transformed into a VHDL description of a pipeline with C to VHDL converter (C2HDL). The programmable part of the compute node is then flashed with the obtained description. The original loop nest is transformed with the innermost loop being replaced with the call for the pipeline accelerator which will compute the given loop. The following techniques are used:
-
The methods of loop nests mapping onto the multi-pipeline architecture described in [11] and partially implemented in OPS.
-
C2HDL converter which adjusts the programmable part of the target platform according to the given code.
3.3 C2HDL Converter and a Multi-pipeline System Generating
Currently the converter supports the subset of input C programs with the following constraints:
-
Integer arithmetics on int types.
-
One-dimensional pipelineable loops with assignment expression statements.
-
Variable occurrences containing regular linear index expressions.
As the result, the converter generates VHDL code for the synchronous pipeline computational circuit, which supports buffers at operations’ inputs and initial pipeline loading stage, if needed. The circuit’s input data may be sent to its input connectors from an external source, with the flow synchronized with the circuit operation. Likewise, the computation output flow may be read from the device’s output connectors and sent to an external receiver (a memory storage, a control unit, etc.) Signed values of given bit widths (VHDL “signed (N - 1 downto 0)” type) are used as operands, standard VHDL operations (“+”, “-”, etc.) redefined for the given types in standard packages, are used as expression operations.
As an intermediate structure between the parallelizing system internal representation and a pipeline HDL description, the computational graph is used.
Future project development involves implementing the ability to generate several pipelines (for a loop nest) with synchronizing their functioning, if needed, with special delays between pipeline starts. Computing such delays involves information dependencies analysis between iteration space points. Such information dependencies are described with lattice graphs which are represented in memory as functions [8].
Example 1
Let us consider the following piece of code consisting of two nested loops:

The data dependency graph between the iteration space points (lattice graph or algorithm graph) is presented on Fig. 2.

The lattice graph of the program which represents dependencies between different points of the iteration space. Such information dependencies arise in some grid methods solving mathematical physics problems and in nucleotide sequences aligning.
It is possible to split the iteration space of this loop nest into stripes which have widths of two points. The iterations of each such a stripe could be computed with two pipelines with one being left behind by another (Fig. 3). The algorithms for delay computation in case of such a lag in time are presented in [11].

Managing computations with information exchange between distinct pipelines.
3.4 Optimizing Parallelizing System (OPS)
OPS parallelizing system has the following advantages over the other programming systems:
-
Dialogue-based optimization mode;
-
Automatic data range analysis;
-
Automatic delay computation for the multi-pipeline compute system.
-
Optimized code generation not only for compute systems with shared memory, but also for the systems with distributed memory.
-
Advanced methods of analysis and transformations of high-level programs which excel the analogs in the field of optimizing compilers and parallelizing systems:
-
lattice graphs;
-
SSA forms of arrays;
-
symbolic analysis;
-
recurrent loops parallelizing methods;
-
several new finer methods of loop parallelizing;
-
methods of program transformation testing.
-
The higher quality of HDL descriptions generating with C2HDL converter will be achieved with OPS utilization. Namely, it is beneficial to generate a whole family of equivalent HDL descriptions (instead of just one) for the given input C program. Then it would be possible to choose the one which will be optimal for each particular case (depending on restrictions of performance, chip area, etc).
For the currently existing systems of automatic program optimizing and parallelizing the user must set the optimization parameters before compiling a program (using compiler directives and options). This approach cannot give the satisfactory results in many cases, since the user does not know beforehand what can the system do automatically and for what aspects the system needs special indications. It is planned to use analysis (including symbolic one) to formulate questions for the user about those few particular variables, the value ranges of which would allow to apply required transformations or take certain engineering decisions. This approach is already partially implemented in OPS system and is considered to be fruitful for semi-automatic VHDL description construction for the given high-level program and semi-automatic program parallelization as well. No similar approaches are used worldwide yet.
Other advanced methods offered by OPS could be utilized by the programming systems. For example, lattice graphs is a useful tool for generating designs for multi-pipeline compute systems.
3.5 Chip Area Optimizing
When designing schematic implementation of the given functionality, the developer has always to take the hardware restrictions into account. In our work we use the following methods to achieve this:
-
It is possible to set the ranges for input data. The user may also define the ranges for the output and intermediate data, the system uses this information to compute the bit widths of the generated arithmetic operations and communication lines. Optionally the system could profile the user code to compute the ranges for the intermediate and output data knowing initially only the input data ranges, using interval analysis. This technique is described in [6]. Knowing data ranges is essential for saving the FPGA resources. It gives an opportunity to get full advantage of this technology over general-purpose CPUs, where data registers and ALUs always have the fixed bit widths regardless the problem requirements.
-
The system uses special arithmetic libraries where different schematic implementations of elementary operations (adders, multipliers, etc.) are stored. The user may have an option to select one for each arithmetic unit in the configuration to meet the particular requirements. For example, certain addition schemes may have better performance over the others at the cost of hardware resources use. The user may prefer the slower implementation to fit the particular computational algorithm into the given FPGA model. All arithmetic schemes are parametrized with the operands’ bit widths.
-
The system uses the heuristic procedure to estimate the required chip area for the given HDL description. The procedure traverses the HDL code internal representation tree to accumulate the user-defined weights for different language constructs (expression operators, variables, etc.) The language construct type is taken into consideration: for example, the effect of VHDL “generate” statement which duplicates its contents for the given number of times. We are planning to implement automatic selection of the alternative arithmetic implementations from the libraries according to their characteristics. It is possible to estimate the chip area for different implementations of the same operation using the above mentioned procedure.
3.6 Efficiency of Parallel Computing Use
It is well known that for modern processors main memory access takes tens of times longer than executing standard arithmetic operations. As to the distributed memory, these accesses take longer time than arithmetic operations almost more than two orders. Therefore, optimizing for program performance should be targeted, in the first place, to memory use.
Using programmable pipeline and parallel-pipeline architectures is considered to be rational only in case if the data for computations are able to be supplied in time. Therefore, in case of programmable computers, as well as of any other modern processors, data locality should be guaranteed first of all, afterwards it would be possible to process the data in parallel. For efficient data localization loop nest splitting into blocks is used. Additional acceleration could be achieved using array block placement in RAM.
4 A Running Example
Example 2
To keep the generated code size reasonable let us consider the following trivial program which implements summation of two arrays:

To run this program we used the following hardware:
-
Xilinx Virtex-4 family FPGA, model: XC4VLX25-FF668-10;
-
Xilinx ML401 evaluation platform (used to communicate the FPGA with the PC via the Ethernet cable);
-
A regular Intel Core2-based system running Windows 7 operating system.
We also used the following Xilinx development software and design components:
-
ISE 14.7;
-
A FIFO queue component generated with LogiCORE FIFO Generator;
-
1-Gigabit Ethernet MAC v8.5.
We used our components presented on Fig. 1. Some of the steps we still need to implement manually at the current stage of the compiler development: generating the control program code for the PC, adjusting communication of ports in the driver code (VHDL part) and executing the different external tools instead of using the build manager. The main steps for setting up the computational system are the following:
-
1.
Running C2HDL converter for the above code, fixing possible errors. As the result the pipeline computational component code is generated (see below).
-
2.
Adding the generated component to the Xilinx ISE project. The project already contains the reusable description of other components implementing Ethernet, IPv4, UDP protocols, and other primitives. The port communications are needed to be adjusted. Also the shift register component is adjusted according to the input/output data bit widths. We plan to automate this work in the future with a driver generator component.
-
3.
Generating an FPGA firmware using ISE tools (iMPACT) with the project adjusted at the previous step.
-
4.
Creating a C project for the PC control program which uses the PC part of the driver implemented in a library. The program basically copies the structure of the original program with the following differences:
-
Additional initialization of the used sockets and input/output buffers;
-
The computational loop is replaced with the library call which implements communications with an FPGA.
-
-
5.
Flashing the FPGA with the firmware obtained at step 3.
-
6.
Running the PC program created at step 4.
A fragment of the VHDL code generated at step 1 is presented below. The code is slightly reformatted to save space and improve readability.

5 Conclusion
A method of mapping high-level programs onto compute systems with programmable architecture is presented in this work. A distinctive feature of this method is that the compute system is adjusted to the program automatically at compile time. Due to this feature, an optimizing parallelizing compiler from a high-level language to the compute system with programmable architecture could be developed. Not only such a compiler could optimize high-level program mapping onto the hardware, it could also optimize the hardware to run the given program. Developing such a compiler is possible on the base of a parallelizing system with high-level internal representation and HDL code generator from this representation.
The presented project aims the substantial simplification of the parallel-pipeline systems access. As the result of this the range of applied problems for this computational field should be expanded; the time needed for parallel-pipeline program developing should be decreased; the development of systems on a chip with programmable architecture should be encouraged.
References
Affine transformations for optimizing parallelism and locality. http://suif.stanford.edu/research/affine.html. Accessed: 13 February 2015
Ben-Asher, Y., Rotem, N., Shochat, E.: Finding the best compromise in compiling compound loops to Verilog. J. Syst. Archit. 56(9), 474–486 (2010). http://dx.doi.org/10.1016/j.sysarc.2010.07.001
Bondalapati, K.: Modeling and mapping for dynamically reconfigurable hybrid architecture. Ph.D. thesis, University of Southern California, August 2001
Boulytchev, D., Medvedev, O.: Hardware description language based on message passing and implicit pipelining. In: Design Test Symposium (EWDTS), 2010 East-West, pp. 438–441, September 2010. http://dx.doi.org/10.1109/EWDTS.2010.5742095
Cardoso, J.M.P., Diniz, P.C.: Compilation Techniques for Reconfigurable Architectures. Springer, US (2009). http://dx.doi.org/10.1007/978-0-387-09671-1
Dubrov, D., Roshal, A.: Generating Pipeline integrated circuits using C2HDL converter. In: East-West Design and Test Symposium, pp. 1–4, September 2013. http://dx.doi.org/10.1109/EWDTS.2013.6673108
Esko, O., Jääskeläinen, P., Huerta, P., de La Lama, C.S., Takala, J., Martinez, J.I.: Customized exposed datapath soft-core design flow with compiler support. In: Proceedings of the 2010 International Conference on Field Programmable Logic and Applications, FPL 2010, pp. 217–222. IEEE Computer Society, Washington, DC (2010). http://dx.doi.org/10.1109/FPL.2010.51
Feautrier, P.: Parametric integer programming. RAIRO Recherche Opérationnelle 22, 243–268 (1988)
Gokhale, M., Graham, P.S.: Reconfigurable Computing. Accelerating Computation with Field-Programmable Gate Arrays. Springer US (2005). http://dx.doi.org/10.1007/b136834
Liao, C., Quinlan, D.J., Willcock, J.J., Panas, T.: Semantic-aware automatic parallelization of modern applications using high-level abstractions. Int. J. Parallel Program. 38(5–6), 361–378 (2010). http://dx.doi.org/10.1007/s10766-010-0139-0
Steinberg, R.B.: Mapping loop nests to multipipelined architecture. Program. Comput. Softw. 36(3), 177–185 (2010). http://dx.doi.org/10.1134/S0361768810030060
Tripp, J.L., Gokhale, M.B., Peterson, K.D.: Trident: from high-level language to hardware circuitry. Computer 40(3), 28–37 (2007). http://dx.doi.org/10.1109/MC.2007.107
Yadzhak, M.S., Tyutyunnyk, M.I.: An optimal algorithm to solve digital filtering problem with the use of adaptive smoothing. Cybern. Syst. Anal. 49(3), 449–456 (2013). http://dx.doi.org/10.1007/s10559-013-9528-x
Zhang, J., Zhang, Z., Zhou, S., Tan, M., Liu, X., Cheng, X., Cong, J.: Bit-level optimization for high-level synthesis and FPGA-based acceleration. In: Proceedings of the 18th Annual ACM/SIGDA International Symposium on Field Programmable Gate Arrays, FPGA 2010, pp. 59–68. ACM, New York (2010). http://doi.acm.org/10.1145/1723112.1723124
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Ya. Steinberg, B., V. Dubrov, D., Mikhailuts, Y., Roshal, A.S., Steinberg, R.B. (2015). Automatic High-level Programs Mapping onto Programmable Architectures. In: Malyshkin, V. (eds) Parallel Computing Technologies. PaCT 2015. Lecture Notes in Computer Science(), vol 9251. Springer, Cham. https://doi.org/10.1007/978-3-319-21909-7_46
Download citation
DOI: https://doi.org/10.1007/978-3-319-21909-7_46
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-21908-0
Online ISBN: 978-3-319-21909-7
eBook Packages: Computer ScienceComputer Science (R0)