
Abstract
Algebraic effects are a long-studied programming language construct allowing the implementation of complex control flow in a structured way. With OCaml 5, such features are finally available in a mainstream programming language, giving us a great opportunity to experiment with varied concurrency constructs implemented as simple libraries. In this article, we explore how to implement concurrency features such as futures and active objects using algebraic effects, both in theory and in practice. On the practical side, we present a library of active objects implemented in OCaml, with futures, cooperative scheduling of active objects, and thread-level parallelism. On the theoretical side, we formalise the compilation of a future calculus that models our library into an effect calculus similar to the primitives available in OCaml; we then prove the correctness of the compilation scheme.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others



1 Introduction
A future [1, 9] is a standard synchronisation artefact used in programming languages with concurrency. It provides a data-flow oriented synchronisation at a higher level of abstraction than locks or monitors. A future is a promise of a result from a spawned task: it is a cell, initially empty, and filled with a value when the task finishes. Accessing this value synchronises the accessor with the end of the task. Promises [17] is a notion similar to futures except that a promise must be filled explicitly by the programmer. Promises are more flexible but also more difficult to use because one could try to fill a promise several times and this raises many issues.
Future pay a crucial role in the implementation of asynchronous computations, particularly in object-oriented languages. ABCL/f [23] proposed the first occurrence of typed futures as a mean for asynchronous method invocation, where a spawned task fills the future later. Then Creol [13] and ProActive [4] introduced active objects [3]; which are both an object (in the sense of object oriented programming) and an actor. As a consequence, an active object has its own logical thread and communications between active objects is done by asynchronous method invocations, using futures to represent the result of asynchronous calls.
Futures, promises, and concurrency primitives in general, have been implemented using a wide variety of techniques, often via dedicated runtime support. Many concurrency primitives require suspending, manipulating and resuming arbitrary computations. This need for non-local control flow appears as soon as task scheduling is not trivial. It turns out that effect handlers [2] precisely enable users to define new control-flow operators. This was quickly identified as a potential technique to implement concurrency primitives while developing Multicore OCaml. Multicore OCaml [21, 22] is an ensemble of new features, including effect handlers, which enable parallel and concurrent programming in OCaml. Crucially, since effects are user-defined, they allow implementing concurrency operators such as futures as libraries. This remark is not a contribution of this article, and seems to be well known folklore among algebraic effects practitioners. It is also how eio [15], the new concurrency library for OCaml, is implemented.
This article expands beyond this folklore in two direction: First, we showcase how to use effects to implement other concurrency primitives, active objects, that were not previously explored. Second, we formalise the translation between futures and algebraic effects, and prove it correct.
Contribution 1: An Actor Library Based on Algebraic Effects. On the practical side, we present a new implementation of active objects based on algebraic effects. It takes the form of an OCaml library that features all the characteristics of active objects, adapted to the OCaml ecosystem. The implementation heavily relies on effect handlers. The library is presented in Sect. 3.
Our implementation only requires effect handlers and objects. To our knowledge and at the time of writing, both are only conjointly present in OCaml. However, as effect handlers are gaining interest and are developed in different contexts, we believe our methodology is applicable to develop active object libraries in any language that support both features.
Contribution 2: A Formalised Translation from Actors into Effect Handlers and Its Proof of Correctness. On the theoretical side, we present the formal arguments showing that our implementation of active objects by effect handlers fully follows the paradigms of active object languages, more precisely:
-
In Sect. 4 we describe our calculi: first, an imperative \(\lambda \)-calculus similar to what can be found in the literature; second, Fut, which expands this \(\lambda \)-calculus with operations on futures: parallelism, tasks, futures, cooperative scheduling inside a thread; finally, Eff which expands the \(\lambda \)-calculus with effects and effect handlers in a parallel setting.
-
Section 5 defines a compilation scheme from Fut to Eff that expresses the principles of the implementation of our active object library based on effects. We formally prove the correctness of our translation and show that the behaviours of the effect compilation of futures mimics exactly the future semantics. Our main theorem states that the compiled program faithfully behaves like the original one.
2 Context and Positioning: Futures, Promises, Effects
We start by revisiting, in a streamlined fashion, the context of our works. We first present the formal models that exist to define semantics of futures and effects, explaining why we need a new semantics to formalise our work. Then we present the programming patterns we rely on: an API for promises as it would appear in OCaml, and how to implement such API using algebraic effects.
2.1 Formal Model for Futures and Effects
In order to formalise our translation, we need a calculus modeling the core of active objects. Compared to existing active object languages, we base our work on a simple \(\lambda \)-calculus enhanced with imperative operations and futures featuring cooperative scheduling. This calculus does not reflect the object-oriented nature of active object languages. Indeed, while the object layer provides an effective programming abstraction and strong static guarantees, we are mostly interested in operational aspects where objects play little role. Conversely, we consider that cooperative scheduling is essential, as it precisely captures the dynamic behavior we want to reproduce after translation to algebraic effects.
Among previously existing calculi, we position ourselves compared to the following ones. On one hand, several previous calculi [6, 7] rely on a pure \(\lambda \)-calculus, lacking any imperative features. We consider modeling imperative code essential, as it allows us to encode the stateful nature of active objects. In particular pure calculi are not able to represent cycles of futures [10]. On the other hand, a concurrent \(\lambda \)-calculus with futures [18] and the DeF calculus [5] feature imperative aspects but no cooperative scheduling, which is crucial to many active objects languages. Additionally, DeF separates cleanly global state and local variables and uses a notion of functions closer to object methods instead of \(\lambda \)-calculus. We do not believe these features are needed in our context. Finally, some formalisation efforts such as ABS [14] cover much more ground, including a full-blown object system and “concurrent object groups” to model the concurrent semantics. We believe such semantics can also be modeled by simpler mechanisms, such as threads and remote execution of pieces of code.
In the remaining of this work, we use a minimal \(\lambda \)-calculus that includes the following features, that are, from our point of view, the core runtime characteristics of actors and active object languages with futures:
-
Impure \(\lambda \)-calculus with a store and memory locations,
-
Cooperative scheduling among tasks on the same parallelisation entity.
-
Request-reply interaction mechanism based on asynchronous calls targeting a given thread, and replies by mean of futures. Without loss of generality, asynchronous calls are simply performed by remote execution of a given \(\lambda \)-calculus expression.
One crucial aspect of actors and active objects that we omit in this work is the separation of the memory into separate entities manipulated by a single thread (like e.g. ABS “concurrent object groups”). While this feature is crucial and allows reasoning about the deterministic nature of some active object languages [11] we would not use it in our developments. We also believe this crucial separation could be added by separating the memory in our configurations into a single memory per thread, either syntactically or using some kind of separation logic.
On the algebraic effect side, we use an imperative \(\lambda \)-calculus with shallow effect handlers, similar to Hillerström and Lindley [12]. This fits well with OCaml, which supports both imperative and functional features. Note that both deep and shallow handlers are available in OCaml.
2.2 Promises in OCaml
Promises are not a new addition to OCaml. Historically, the libraries Lwt [24] and Async implemented monadic promise-based cooperative multitasking in OCaml. Due to OCaml’s limitation at the time, neither library implemented parallelism. Multicore OCaml introduced parallelism (with a new garbage collector and supporting libraries for thread parallelism) [21] along with algebraic effects [22], with the objective for users to implement their own concurrency primitives. In recent time, several libraries implement their own flair of futures and promises, this time using a direct-style instead of the previous monadic one. Most of them, including the most developed library eio [15], and our own implementation, use a core API summarised in Fig. 1.

A simple API for promises
The different elements of the API are commented in the figure. The type  is parameterised by its content (denoted by the type variable
is parameterised by its content (denoted by the type variable  ). There are two ways to create a promise:
). There are two ways to create a promise:  creates a promise and also returns the resolution function, while
creates a promise and also returns the resolution function, while  associates a computation to the promise, actually creating a future. This library can be used in any setting, we thus differentiate between non-blocking operations such as await, which yield to another task, and blocking operations such as get, whose evaluation is stuck and blocks the current logical thread. It is then up to the invoker of this function and the scheduler to deal with this blocked state conveniently.
associates a computation to the promise, actually creating a future. This library can be used in any setting, we thus differentiate between non-blocking operations such as await, which yield to another task, and blocking operations such as get, whose evaluation is stuck and blocks the current logical thread. It is then up to the invoker of this function and the scheduler to deal with this blocked state conveniently.
2.3 Promising Effects
Following [20], we now summarise a simplistic implementation of the get primitive for promises or futures using effects, as a way to introduce effects in the context of concurrency. As noted before, A promise, denoted here by the promise type is an atomic mutable box containing a status. The status is either  , containing a value of type ’a, or
, containing a value of type ’a, or  waiting for a value.
waiting for a value.


Function Promise.get and its effect handler
Using effects, Fig. 2 showcases the implementation of blocking reads ( primitive) as explained below. On Line 1, we declare a new effect, called
primitive) as explained below. On Line 1, we declare a new effect, called  . From the usage perspective, an effect is a parameterised operation whose semantics is not specified, but whose typing is fixed: here, performing the
. From the usage perspective, an effect is a parameterised operation whose semantics is not specified, but whose typing is fixed: here, performing the  effect takes as parameter a promise and returns the content. The
effect takes as parameter a promise and returns the content. The  function, on Line 4, directly returns the value if the promise is fulfilled, or performs the
function, on Line 4, directly returns the value if the promise is fulfilled, or performs the  effect otherwise. We still need to define what performing
effect otherwise. We still need to define what performing  actually does. This is done via an effect handler, one Line 9. From the definition perspective, effects behave similarly to exceptions, except they allow resumption. The
actually does. This is done via an effect handler, one Line 9. From the definition perspective, effects behave similarly to exceptions, except they allow resumption. The  function executes a task in the context of a handler. When an effect is performed, it triggers the evaluation of the appropriate branch in the handler (here, Line 11) and binds the value contained in the effect (here, variable p is the promise to get). The handler also gives access to the continuation
function executes a task in the context of a handler. When an effect is performed, it triggers the evaluation of the appropriate branch in the handler (here, Line 11) and binds the value contained in the effect (here, variable p is the promise to get). The handler also gives access to the continuation  at the point where the effect was performed. To implement
at the point where the effect was performed. To implement  , we repeatedly poll the content of the promise until a value is obtained, and resume the continuation
, we repeatedly poll the content of the promise until a value is obtained, and resume the continuation  with the value, thus resuming the execution of the task.
with the value, thus resuming the execution of the task.
The continuation  , which is applied directly here, is in fact a first class value and can be passed around and stored. This allows implementing other operations on promises and other concurrency primitives, by defining a scheduler that manipulates continuations directly in user-land.
, which is applied directly here, is in fact a first class value and can be passed around and stored. This allows implementing other operations on promises and other concurrency primitives, by defining a scheduler that manipulates continuations directly in user-land.
As indicated before, this implementation exactly mirrors (albeit with some simplifications) the ones in the current OCaml ecosystem. We now move on to a novel usage of algebraic effects by combining them with objects to implement active objects in OCaml.
3 An OCaml Library for Active Objects
Our first contribution is an OCaml library, actors-ocaml available at https://github.com/Marsupilami1/actors-ocaml, which implements promises and active objects on top of OCaml’s new features: effect handlers, to handle concurrency; and “domains”, threads accompanied by their memory-managed heap, which acts as OCaml’s parallelism units. We start by a showing our overlay for active objects before presenting its translation to effects.
3.1 Active Objects
We showcase a first example of active object in OCaml in Fig. 3. To create a new active object, we introduce a new dedicated syntaxFootnote 1  Footnote 2. It functions similarly to an OCaml object, with private fields, introduced by
Footnote 2. It functions similarly to an OCaml object, with private fields, introduced by  and public
and public  s. Here, we create an active object with one local field
s. Here, we create an active object with one local field  initialised to 0, and three methods to
initialised to 0, and three methods to  the local field,
the local field,  it, and
it, and  it by a provided integer. Accessing private fields is transparent inside the active object, as if it was a normal variable, but forbidden outside the active object. We will see below that we use OCaml domains to implement such a local memory.
it by a provided integer. Accessing private fields is transparent inside the active object, as if it was a normal variable, but forbidden outside the active object. We will see below that we use OCaml domains to implement such a local memory.
In OCaml, objects are typed structurally, with a type that reflects all their methods. Our active objects follow a similar trend: the object type is delimited by  and contains a list of all methods. For instance,
and contains a list of all methods. For instance,  (Line 3), indicates that the method
(Line 3), indicates that the method  takes no argument and returns an integer.
takes no argument and returns an integer.  marks a method taking an integer and returning nothing. Note that the field is not shown in the type, since it represents internal state. This is crucial for active objects, as local fields are stored locally and shouldn’t be accessed by other active objects. To distinguish active objects from normal objects, the structural type that consists of the methods is wrapped, giving the type
marks a method taking an integer and returning nothing. Note that the field is not shown in the type, since it represents internal state. This is crucial for active objects, as local fields are stored locally and shouldn’t be accessed by other active objects. To distinguish active objects from normal objects, the structural type that consists of the methods is wrapped, giving the type  .
.

A simple example using active object
Actual usage of active objects is where we depart from traditional OCaml objects. Indeed, active objects support two types of method calls:  , in Line 1, is synchronous. Such calls are either blocking if made externally, similarly to
, in Line 1, is synchronous. Such calls are either blocking if made externally, similarly to  , or direct if made internally by the actor itself.
, or direct if made internally by the actor itself.  in Line 2 is asynchronous, which wraps the result in a Promise.
in Line 2 is asynchronous, which wraps the result in a Promise.  is called to create the promise and associates a dedicated resolver with the triggered call. The promise is returned to the invoker that can then perform
is called to create the promise and associates a dedicated resolver with the triggered call. The promise is returned to the invoker that can then perform  and
and  on it. The programmer cannot explicitly resolve the promise and can only access its value: promises returned by active objects are in fact futures, similarly to other active object languages.
on it. The programmer cannot explicitly resolve the promise and can only access its value: promises returned by active objects are in fact futures, similarly to other active object languages.
3.2 Encapsulation and Data-Race Freedom
Our library takes advantage of the OCaml type system to provide safe encapsulation of state and safe abstraction. Indeed, local variables, such as the  field in Fig. 3, are hidden. Access can thus only be made inside methods. This ensures proper abstraction since only fields that are exposed through getters and setters can be accessed. It also ensures the absence of data-races, since methods are not executed concurrently (unless programmer explicitly use lower-level constructs, such as shared memory). Naturally, this is only true if two crucial properties are ensured: mutable access cannot be captured, and it is impossible to return mutable values shared with the internal state.
field in Fig. 3, are hidden. Access can thus only be made inside methods. This ensures proper abstraction since only fields that are exposed through getters and setters can be accessed. It also ensures the absence of data-races, since methods are not executed concurrently (unless programmer explicitly use lower-level constructs, such as shared memory). Naturally, this is only true if two crucial properties are ensured: mutable access cannot be captured, and it is impossible to return mutable values shared with the internal state.
Capture. Methods calls in OCaml are currified by default. For instance  returns a closure of type
returns a closure of type  encapsulating message sending to
encapsulating message sending to  and retrieval of a result from
and retrieval of a result from  . Furthermore, functions are first class, and can be returned by methods. While this provides great integration into the rest of the language, this means that we need to be particularly careful with captures in methods. We illustrate this in Fig. 4, with an incorrect implementation of the
. Furthermore, functions are first class, and can be returned by methods. While this provides great integration into the rest of the language, this means that we need to be particularly careful with captures in methods. We illustrate this in Fig. 4, with an incorrect implementation of the  method. Here, we return a closure capturing an access to the internal field
method. Here, we return a closure capturing an access to the internal field  . Such closure should never be executed in the context of another active object. We detect such ill-conceived code and return the error shown below, instructing the user to first access the state before capturing the value.
. Such closure should never be executed in the context of another active object. We detect such ill-conceived code and return the error shown below, instructing the user to first access the state before capturing the value.
In theory, this is a simple matter of name resolution. In practice, name resolution in OCaml is complex, and relies on typing information which can’t be accessed by syntax extensions such as the one we develop. We implement a conservative approximation.

An example of illegal capture and its error message
Mutability and Sharing. Code that respects the criterion mentioned above can still exhibit data-races, for instance by returning the content of a field which manifest internal mutability, such as arrays. Preventing such mistakes is a bit more delicate: with the strong abstraction of OCaml, the implementation of a data-structure can be completely hidden, and hence its potential mutability. A static type analysis is therefore insufficient. A dynamic analysis of the value is similarly insufficient (mutable and immutable records are represented similarly in OCaml). The last common solution to this problem, to make a deep copy of returned values, is costly both in terms of time and loss of sharing.
So far, we opted to only support immutable values in fields, and do not provide any guarantees when mutable values are used. Thankfully, immutable values are the default in OCaml and are largely promoted for most use-cases. In the future, we plan to combine static and dynamic analysis to inform where to insert deep copies.

Simple active object code (top) and its translation (bottom)
3.3 Active Object Desugaring
We now have all the ingredients to explain how the OCaml code for the active object is generated from the programmer’s input. An example of such translation is given in Fig. 5. The first important notion is to use memory local to the domain to store the internal fields. Using domains, this is done via the  (for Domain Local Storage, analogous to thread local storage), see for instance line 2 of the translated code. All reads and writes are then replaced by
(for Domain Local Storage, analogous to thread local storage), see for instance line 2 of the translated code. All reads and writes are then replaced by  functions. The second transformation aims to separate method calls (i.e., message sent), and execution, and can be observed on line 3 and 4: Each method is split in two. The first hidden method, shown on line 3, contains the computational content. The second is the actual entry point: it proceeds by creating a promise; launch a new task; and return the promise. The goal of the task is to queue a message in the actor’s mailbox, via
functions. The second transformation aims to separate method calls (i.e., message sent), and execution, and can be observed on line 3 and 4: Each method is split in two. The first hidden method, shown on line 3, contains the computational content. The second is the actual entry point: it proceeds by creating a promise; launch a new task; and return the promise. The goal of the task is to queue a message in the actor’s mailbox, via  , and then launch a process which eventually resolves the promise; this is done by
, and then launch a process which eventually resolves the promise; this is done by  .
.
3.4 Forward
While handling a method, one might want to delegate the computation to another active object or method. With traditional asynchronous calls such as  or
or  , this would involve unwrapping and rewrapping the promises. Dealing efficiently with delegation in asynchronous invocations is a well-studied problem [5,6,7]. In [6], one construct called forward was suggested for such delegations; it was then shown that directly forwarding an asynchronous invocation (return(async(e))) could be efficiently and safely implemented using promises.
, this would involve unwrapping and rewrapping the promises. Dealing efficiently with delegation in asynchronous invocations is a well-studied problem [5,6,7]. In [6], one construct called forward was suggested for such delegations; it was then shown that directly forwarding an asynchronous invocation (return(async(e))) could be efficiently and safely implemented using promises.

Simple use of delegation
We can easily adapt this approach to our actors. We also implement delegation calls by syntactically identifying such optimisable situation with the primitive:  . Figure 6 illustrates a simple program using such method delegation; the statement
. Figure 6 illustrates a simple program using such method delegation; the statement  delegates the current invocation to another one. These calls act as
delegates the current invocation to another one. These calls act as  in many languages, and ignore any computations that would come after in the method. From the functional programming point of view, this is analogous to tail-calls. Tail-calls exploit synchronous calls in return positions to eschew using additional stack space. Forward statement exploits asynchronous calls in return position to eschew indirection of promises.
in many languages, and ignore any computations that would come after in the method. From the functional programming point of view, this is analogous to tail-calls. Tail-calls exploit synchronous calls in return positions to eschew using additional stack space. Forward statement exploits asynchronous calls in return position to eschew indirection of promises.
In a more general case, we can simply forwardFootnote 3 a promise as the future resolution of the current promise. A statement similar to the one of Encore, Actors.forward p performs such a shortcut where p is a ’a Promise.t.
We implement the two forwarding constructs presented above as effects in the library. Similarly to capturing issues highlighted in previous sections, delegation calls should not be captured in a closure: indeed, it wouldn’t be clear which indirection to avoidFootnote 4. We forbid such situations (dynamically, via a runtime test).
3.5 Runtime Support
From a parallelism point of view, we rely on domains, which are threads equipped with a private heap and a garbage collector. There is also a global, shared heap. In practice, we spawn a pool of domains at the start of the execution. This pool of domains is fixed for the whole execution. Similarly to many other implementations, multiple actors may share a domain, and will use cooperative scheduling together.
Cooperative scheduling is implemented using effects and continuations, similarly to the one implemented in the introduction. To make this scheduler more realistic and fair, we implement the following optimisations:
-
Each domain contains a first round-robin scheduler in charge of scheduling between active objects hosted on the same domain. Spawning of new actors is implemented at this layer, enabling the choice of an arbitrary domain to spawn it. Synchronous method calls in the same domain are transparently turned into direct calls (instead of asynchronous calls followed by a synchronisation when the domain is different).
-
Each active object contains an OCaml object with the methods of the object, as described above, and a second round-robin scheduler which schedules the promises currently executed by this actor. Instead of a traditional mailbox of messages, active objects contain a queue of thunks to be executed. In the case of method calls, each thunk contains a call to the underlying OCaml object as a closure. Forwards and delegation calls are implemented at this second layer, which is aware of all the details pertaining to the actor.
-
Unresolved promises contain a list of callbacks, i.e., other promises that are currently waiting on it. This allows the implementation of passive waits for unresolved promise reads.
Note that this implies we have two effects handlers, both providing slightly differing implementation of the base effects related to promises (Async, Get, Await). Indeed, promises can appear outside of actors, but should be handled locally if they appear inside one.
4 Future and Effect \(\lambda \)-Calculi
The rest of this article is dedicated to the formal description of the compilation of Futures to Effects. For this purpose, we first introduce our protagonists: A common imperative base (Sect. 4.1), the source future calculus (Sect. 4.2) often characterised in  , and the target effect calculus (Sect. 4.3) often characterised in
, and the target effect calculus (Sect. 4.3) often characterised in  . For all these calculi, we define small-step operational semantics in the sequential and parallel cases.
. For all these calculi, we define small-step operational semantics in the sequential and parallel cases.
4.1 A Functional-Imperative Base
We define a standard \(\lambda \)-calculus with imperative operations that will be the base language for our other definitions and semantics. The syntax is given in Fig. 7. As meta-syntactic notations, we use overbar for lists (\(\overline{e}\) a list of expressions) and brackets for association maps (\(\left[ \overline{\ell \mapsto e}\right] \)). \({{\,\textrm{Dom}\,}}(M)\) is the domain of M and \(\emptyset \) is the empty map. \(M\left[ v \mapsto v'\right] \) is a copy of M where v is associated to \(v'\), \(M \setminus v\) is a copy of M where v is not mapped to anything (\(v\not \in {{\,\textrm{Dom}\,}}(M \setminus v)\)).
Most expression and values are classical. The substitution of x by \(e'\) in e is denoted \(e\left[ x \leftarrow e'\right] \). Stores are maps indexed by location references, denoted \(\ell \). \(\textbf{Id}\) denotes unique identifiers that can be crafted during execution, which will be useful in our two main calculi. Location references and identifiers should not occur in the source programs and only appear during evaluation. We also define evaluation contexts C that are expressions with a single hole \(\square \). Evaluation contexts are used in the semantics to specify the point of evaluation in every term, ensuring a left-to-right call-by-value evaluation. We classically rely on evaluation contexts, C[e] is the expression made of the context C where the hole is filled with expression e. Figure 8 defines a semantics for this base calculus; it is similar to what can be found in the literature. It expresses a reduction relation, denoted  , of pairs store\(\times \)expression.
, of pairs store\(\times \)expression.

Syntax for the base impure \(\lambda \)-calculus

Semantics for the base impure \(\lambda \)-calculus
Important Note. The rules of Fig. 8 act on the syntax of imperative \(\lambda \)-calculus. However, in the next section we will re-use  on terms of bigger languages, with the natural embedding that
on terms of bigger languages, with the natural embedding that  rules only are able to handle the \(\lambda \)-calculus primitives but will manipulate terms and reduction contexts of the other languages. The alternative would be to define from the beginning the syntax and reduction contexts of our language as the largest syntax including all the three considered languages (\(\lambda \)-calculus, Fut, and Eff). We chose here to adopt a more progressive presentation despite the slight abuse of notation this involves on the formal side.
rules only are able to handle the \(\lambda \)-calculus primitives but will manipulate terms and reduction contexts of the other languages. The alternative would be to define from the beginning the syntax and reduction contexts of our language as the largest syntax including all the three considered languages (\(\lambda \)-calculus, Fut, and Eff). We chose here to adopt a more progressive presentation despite the slight abuse of notation this involves on the formal side.
In the rest of this article, we also assume additional constructs which can be classically encoded in the impure \(\lambda \)-calculus:
-
Let-declaration: let x = ... in ...
-
Sequence: e; e’
-
Mutually recursive declarations: let rec ... and ...
-
Mutable maps indexed by values: empty map \(\{ \}\), reads M[e], writes \(M[e] \leftarrow e'\), and deletions \(\texttt {del}\ M[e]\)
-
Pattern matching on simple values: match ... with ...
4.2 Futures and Cooperative Scheduling
Our \(\lambda \)-calculus with futures shares some similarities with the concurrent \(\lambda \)-calculus with futures [18], but without future handlers or explicit future name creation and scoping, resulting in a simpler calculus. Our calculus can also be compared to the one of Fernandez-Reyes et al. [6] but with cooperative scheduling with multiple threads, and imperative aspects.
The \(\lambda \)-calculus of previous section is extended as shown in Fig. 9. Four new constructs are added to the syntax:  spawns a new processing unit;
spawns a new processing unit;  starts a new task e in the processing unit \(e'\) and creates a future identifier f, when the task finishes, this resolves the future f;
starts a new task e in the processing unit \(e'\) and creates a future identifier f, when the task finishes, this resolves the future f;  , provided e is a future identifier, blocks the current processing unit until the future in e is resolved;
, provided e is a future identifier, blocks the current processing unit until the future in e is resolved;  is similar but releases the current processing unit until the future is resolved. Evaluation contexts are trivially extended.
is similar but releases the current processing unit until the future is resolved. Evaluation contexts are trivially extended.
As shown in Fig. 9, we suppose that future identifiers have a specific shape of the form \(\textit{fut}= (\textit{tid},\textit{lf})\) where \(\textit{tid}\) is a thread identifier and \(\textit{lf}\) is a local future identifier. Tasks map expressions to future identifiers, when the expression is fully evaluated (to a value) the future is resolved.
The dynamic syntax is expressed in two additional layers: above the \(\lambda \)-calculus layer of Fig. 8, Fig. 10 expresses the reduction relation in a given processing unit, and Fig. 11 extends this local semantics to a parallel semantics with several processing units.
The local semantics in Fig. 10 is based on configurations of the form \(\sigma , F, s\) where \(\sigma \) is a shared mutable store, \(F\) is the map of futures, and s is a state. If the expression in the current task is fully evaluated to a value, the task is finished, the future is resolved and put back into the task list, the state of the processing unit is Idle (rule return). Rule step performs a \(\lambda \)-calculus step (see Fig. 8).  can only progress if the future f has been resolved, in which case the value associated with the future is fetched (rule get). There are two rules for
can only progress if the future f has been resolved, in which case the value associated with the future is fetched (rule get). There are two rules for  : if the future is resolved
: if the future is resolved  behaves like
behaves like  ; if it is not resolved the task is interrupted (it returns to the task pool), the processing unit becomes Idle. Finally, rule Async starts a new task: the effect of \(\texttt {asyncAt}{(e,\textit{tid})}\) is first to forge a future identifier containing the thread identifier \(\textit{tid}\) and another identifier \(\textit{lf}\) so that the pair \((\textit{tid},\textit{lf})\) is fresh, a task is created, associating e to the new future.
; if it is not resolved the task is interrupted (it returns to the task pool), the processing unit becomes Idle. Finally, rule Async starts a new task: the effect of \(\texttt {asyncAt}{(e,\textit{tid})}\) is first to forge a future identifier containing the thread identifier \(\textit{tid}\) and another identifier \(\textit{lf}\) so that the pair \((\textit{tid},\textit{lf})\) is fresh, a task is created, associating e to the new future.

Syntax for the Fut language

Semantics for Fut —
The management of processing units and thread identifiers is the purpose of the parallel semantics in Fig. 11. It expresses the evaluation of configurations of the form \(\sigma , F, P\) where P is a parallel composition of processing units.  is used both to extract the execution state of thread i form the parallel composition P and to add it back. Rule one-step simply triggers a rule of the local semantics in Fig. 11. Rule spawn spawns a new thread, creating a fresh thread identifier that will be used in an AsyncAt statement to initiate work on this thread (the new thread is initially Idle). Finally, if \(s^i\) is Idle, no task is currently running and a new task can be started on the processing unit i by the rule schedule.
is used both to extract the execution state of thread i form the parallel composition P and to add it back. Rule one-step simply triggers a rule of the local semantics in Fig. 11. Rule spawn spawns a new thread, creating a fresh thread identifier that will be used in an AsyncAt statement to initiate work on this thread (the new thread is initially Idle). Finally, if \(s^i\) is Idle, no task is currently running and a new task can be started on the processing unit i by the rule schedule.
An initial configuration for an Fut program \(e_p\) consists of the program associated with a fresh task identifier i and a fresh future identifier f, with an empty store and future map: \(\emptyset , \emptyset , (f\rightarrow e_p)^i\).

Parallel semantics for Fut —
4.3 Effects
We now extend the base calculus of Sect. 4.1 with effects. For the moment this extension is independent of the previous one, they are used separately in this article even though composing the two extensions would be perfectly possible. Indeed, we transform programs with only futures into programs with only effects but having a language with at the same time futures and effects would also make sense.
Figure 12 shows the syntax of the parallel and imperative \(\lambda \)-calculus with effects. Parallelism is obtained by the keyword  that creates a new thread in the same spirit as in the previous section.
that creates a new thread in the same spirit as in the previous section.  runs the expression e under the handler h, if an effect is thrown by
runs the expression e under the handler h, if an effect is thrown by  inside e, and if h can handle this effect, the handler is triggered. Rule handle-effect in Fig. 13 specifies the semantics of effect handling. Suppose an effect E is thrown, the first encompassing handler that can handle this effect is triggered: if a rule \((E(x), k \mapsto e)\) is in the handler, then the handler e is triggered with x assigned to the effect value v and k assigned to the continuation of the expression that triggered the effect. The interplay between evaluation contexts and the \(\text {captured}\_\text {effects}()\) function captures the closest matching effect. Rule handle-step handles the case where the term e performs a reduction not related to effect handling. If e finally returns a value, Finally, rule handle-return deals with the case where the handled expression can be fully evaluated without throwing an effect; it triggers the expression corresponding to the success case \( x\mapsto e\) in the handler definition. Note that we don’t reinstall the handler after triggering the rule, corresponding to the shallow interpretation of effect handlers [12].
inside e, and if h can handle this effect, the handler is triggered. Rule handle-effect in Fig. 13 specifies the semantics of effect handling. Suppose an effect E is thrown, the first encompassing handler that can handle this effect is triggered: if a rule \((E(x), k \mapsto e)\) is in the handler, then the handler e is triggered with x assigned to the effect value v and k assigned to the continuation of the expression that triggered the effect. The interplay between evaluation contexts and the \(\text {captured}\_\text {effects}()\) function captures the closest matching effect. Rule handle-step handles the case where the term e performs a reduction not related to effect handling. If e finally returns a value, Finally, rule handle-return deals with the case where the handled expression can be fully evaluated without throwing an effect; it triggers the expression corresponding to the success case \( x\mapsto e\) in the handler definition. Note that we don’t reinstall the handler after triggering the rule, corresponding to the shallow interpretation of effect handlers [12].

Eff Syntax

Semantics for Eff —

Parallel semantics for Eff —
Figure 14 shows the parallel semantics of effects. The only specific rule is spawn, which spawns a new thread with a fresh identifier. Note that in Eff, the parameter of spawn is the expression to be evaluated in the new thread, with its own thread identifier as argument.
An initial configuration for an Eff program \(e_p\) simply consists of the program associated with a fresh task identifier i and with an empty store: \(\emptyset , e_p^i\).
5 Compilation of Futures into Effects
In this section we define a transformation from Fut to Eff that translates from our concurrent \(\lambda \)-calculus with futures into the calculus with effect handlers. We then prove its correctness.

Translation from Fut to Eff
5.1 Translating Fut into Eff
Figure 15 shows the translation  that transforms a Fut program e into an Eff program with the same semantics. The color highlighting in the definition can be ignored at first. It will be used in the proof in the next section.
that transforms a Fut program e into an Eff program with the same semantics. The color highlighting in the definition can be ignored at first. It will be used in the proof in the next section.  is the top level program transformation while
is the top level program transformation while  is used to compile expression; this transformation simply replaces Fut specific expressions into expressions throwing an effect with adequate name and parameters. The handling of effects is defined at the top level, i.e. when translating the source program.
is used to compile expression; this transformation simply replaces Fut specific expressions into expressions throwing an effect with adequate name and parameters. The handling of effects is defined at the top level, i.e. when translating the source program.
 creates a program that uses a pool of tasks called \(\textit{tasks}\) and three functions that manipulate it. \(\textit{tasks}\) is implemented by a mutable map from future identifiers to tasks, which can be of two kinds: continuations of the form \(\mathbb {C}(k)\) or values of the form \(\mathbb {V}(v)\).
creates a program that uses a pool of tasks called \(\textit{tasks}\) and three functions that manipulate it. \(\textit{tasks}\) is implemented by a mutable map from future identifiers to tasks, which can be of two kinds: continuations of the form \(\mathbb {C}(k)\) or values of the form \(\mathbb {V}(v)\).
The main function is continue, it sets up a handler dealing with all the effects of Fut. It first evaluates the thunk continuation parameter k. Then it reacts to the different possible effects as follows. The first branch describes the behavior when k() throws no effect and simply returns a value. In this case, the task is saved as a value \(\mathbb {V}(v)\) (the future is resolved). The Async effect adds a new task to the task pool and continues the execution of the current task with the continuation \(k'\) and the newly created future \(\textit{fut}'\). The Await effects checks whether the future \(\textit{fut}_a\) in the task pool has been resolved or not; if it is resolved the task continues with the future value, otherwise the task is put back in the pool of tasks (keeping the Await effect at the head of the continuation). The Get effect is similar to the resolved case of Await but does not allow the task to be returned to the pool of tasks. Instead, if the future is not resolved the thread actively polls the matching task until the future is finally resolved using the auxiliary poll function. The Spawn effect case spawns a new thread that runs the run function. In each case where the task does not continue, the body of the function run is triggered.
The function \(\textit{run}(t)\) uses the external function \(\textit{pop}(\textit{tasks}, t)\) to fetch a new unresolved task that should run on thread t, the task is thus of the form \(\mathbb {C}(k)\) and the thread continues by evaluating the thunk continuation k.
5.2 Correctness of the Compilation of Actors into Effects
We define in this section a hiding semantics and will prove strong bisimulation between the source program and the hiding semantics of the transformed program.
5.2.1 Hiding Semantics
In translation such as the one defined here, the compiled program must often take several more “administrative” steps than the source program. This makes proof by bisimulation more complex, and requires using weak bisimulation that ignores some steps marked as internal.
In this article we take a stronger approach and prove strong bisimilarity on a derived transition relation. The principle is that internal steps of the transformed program are called silent, and they are by nature deterministic and terminating. We can thus consider that we “normalise” the runtime configuration of the transformed program by systematically applying as many internal steps as possible until a stable state is reached. We discuss this idea further in Sect. 6.
We first state that \( hidden (e)\) is true if the top level node in the syntax of e is colored; where colored means the term is surrounded by a colored box:  . There should be no ambiguity on the node of the syntax that is colored (at least in our translation).
. There should be no ambiguity on the node of the syntax that is colored (at least in our translation).
Definition 1 (Hiding semantics)
We define a hiding operation to hide parts of the reduction. It works as follows. We can define a h-reduction  that puts a \(\tau \) label on the transitions that target a node of the syntax that is hidden:
that puts a \(\tau \) label on the transitions that target a node of the syntax that is hidden:

We finally define the hiding semantics as one non-hidden step followed by any number of hidden step, until no further hidden step can be performedFootnote 5:

Note that, considering the nodes colored in our translation, the transitions marked as \(\tau \) should only have a local and deterministic effect on the program state. In practice there are some hidden statements that spawn a thread or launches task for example, but they are immediately and deterministically preceded by a decision point that is visible, here the reaction to an effect. The interleaving of the tau transition have no visible effect on the global state, only the state along the visible transitions is important. This property will be made explicit in our proof of correctness. As a consequence, because the hidden step commutes with all the other steps, each execution of a Fut program compiled into Eff can be seen as a succession of  . Additionally, except when polling futures the transitive closure of hidden steps terminate. We have the following property, relating our middle-step and small-step semantics.
. Additionally, except when polling futures the transitive closure of hidden steps terminate. We have the following property, relating our middle-step and small-step semantics.
Theorem 1 (Middle-step semantics)
Consider  . Any Eff reduction of \(e_1\) can be seen as a hiding semantics reduction, modulo a few hidden steps, and a few get operations on unresolved futures:
. Any Eff reduction of \(e_1\) can be seen as a hiding semantics reduction, modulo a few hidden steps, and a few get operations on unresolved futures:

Where  is application (inside an appropriate context) of a handle-effect rule with a Get effect on an unresolved future. In particular, if all futures are resolved,
is application (inside an appropriate context) of a handle-effect rule with a Get effect on an unresolved future. In particular, if all futures are resolved,  .
.
This theorem is true because the hidden semantic steps commute, only a special case is needed for handling the polling of unresolved futures.
5.2.2 Bisimulation Definition
To help with our bisimulation definition, we now define a few execution contexts that appear commonly in the proof. \(C_{rec}\) is the context that corresponds to the recursive knot introduced by let rec. Indeed, since let rec expresses recursion as an encoding into \(\lambda \)-calculus, the encoding will appear again in each task and can be sugared/de-sugared at will. In addition, \(C_c\) and \(C_r\) are the contexts in the translated program where continue and run are respectively executed, parameterised by all their free variables. In the following we thus start each task by \(C_{rec}\), \(C_c\) or \(C_r\). More precisely:

Definition 2 (Relation over configurations)
Let R be a relation over pairs of a \(\textsc {Fut} \) configuration  and a \(\textsc {Eff} \) configuration
and a \(\textsc {Eff} \) configuration  . We also note \(R_e\) a relation over pairs of configuration states in \(\textsc {Fut} \) (i.e., \((\sigma , \ell _{threads})\)) and in \(\textsc {Eff} \) (i.e., \((\sigma , F)\)).
. We also note \(R_e\) a relation over pairs of configuration states in \(\textsc {Fut} \) (i.e., \((\sigma , \ell _{threads})\)) and in \(\textsc {Eff} \) (i.e., \((\sigma , F)\)).
Figure 16 defines both relations. The purpose of the relation is to prove the correctness of our compilation scheme. We will prove that R is a strong bisimulation. R is indexed either by  for parallel configurations, and by a given t to reason about single-threaded configurations of thread t. For single-threaded configurations, the computation can either be in the continue case, or the run case. The most complex relation is on the environments, which details the content of the \(\ell _{threads}\) values.
for parallel configurations, and by a given t to reason about single-threaded configurations of thread t. For single-threaded configurations, the computation can either be in the continue case, or the run case. The most complex relation is on the environments, which details the content of the \(\ell _{threads}\) values.

Relation between Fut terms and their compiled version
The translation  can straightforwardly be extended to contexts (where
can straightforwardly be extended to contexts (where  ). Consequently, we have the following property:
). Consequently, we have the following property:
Lemma 1 (Context compilation)

Proof
By case analysis on the translation rules (and on contexts). \(\square \)
5.2.3 Correctness of the Compilation Scheme
We now establish the correctness of our translation by proving that the relation we exhibited in the previous section is a bisimulation.
Theorem 2 (Correctness of the compilation scheme)
The relation  is a strong bisimulation where the transition on the Eff side is the hiding transition relation, and the transition on the Fut side is
is a strong bisimulation where the transition on the Eff side is the hiding transition relation, and the transition on the Fut side is  . Formally, for all configurations the following holds:
. Formally, for all configurations the following holds:

and

so that for any Fut program p the initial configuration of the program and of its effect translation are bisimilar (with \(t_0\) fresh, and \(f_0\) is the fresh future identifier that has been chosen when triggering the first continue function.).

Proof (sketch)
The proof of bisimulation follows a standard structure. For each pair of related configurations we show that the possible reductions made by one configuration can be simulated by the equivalent configuration (in the other calculus). Then a case analysis is performed depending on the rule applied. The set of rules is different between Fut and Eff calculi but on the Eff side, we need to distinguish cases based on the name of the triggered effect, leading to a proof structure similar to the different rules of Fut. Appendix A details the proof that the compiled program simulates the original one. By case analysis on the rule that makes the relation true and the involved reduction. This leads to seven different main cases; we prove simulation in each case. \(\square \)
Finally, Theorems 1 and 2 allow us to conclude regarding the correctness of our compilation scheme. Indeed, each execution of a compiled program is equivalent to a middle-step reduction that itself simulates one of the possible executions of our Fut program. Conversely, any execution of our Fut program corresponds (modulo polling of unresolved futures) to a middle-step execution of its compilation, which is in fact one of the Eff executions of the compiled program.
6 Conclusion and Discussion
We have presented an active object library based on effect handlers and proved the correctness of its implementation principles. To prove this correctness, we expressed the implementation as a translation from a future calculus to an effect calculus and proved a bisimulation relation between the source and the transformed program. This illustrates that effects are a very general and versatile construct which can be leveraged to implement concurrency constructs as libraries, including futures. We discuss below a few alternatives that we considered and, more generally, extensions of this work we envision.
Deep and Shallow Handlers. As highlighted at multiple points, we use shallow effect handlers, both in our implementation and in our formal development. Shallow effect handlers are not automatically reinstalled upon resuming a continuation, while deep handlers are automatically reinstalled.
In theory, Hillerström and Lindley [12] show that both deep and shallow handlers are equivalent, and showcase code transformation from one to the other. In addition, OCaml provides both versions. In practice, however, for the purpose of implementing a scheduler, shallow handlers offer numerous advantages. First, they make recursion in the continue function uniform over all tasks, be they continuations or new tasks. Furthermore, since they allow precise control over when handlers are installed, we can ensure that we never install nested handlers. In our implementation, this was essential to make continue and run tail-recursive.
Unfortunately, shallow handlers are a bit more delicate to implement for language designers. Furthermore, deep handlers admit a more precise small-step semantics [19]. It remains to be seen if the deep version of our scheduler can be expressed as elegantly as the one showcased in our formalisation.
Relation to Existing Promise-as-Effect Libraries. To develop our active object library, we made our own implementation of promises. This was convenient, as full-control allowed us to tie both together, which was essential for implementing forward, notably.
However, implementing an industrial-strength promise library with efficient scheduling, parallelism, and system integration is a significant task. Making several such libraries work together is delicate. In practice, eio [15] is trending towards being the standard promise library in OCaml.
Now that we formalised our semantics independently, one of the next steps is to adapt our developments to rely on an existing scheduling library. There are two difficulties here:
-
Adapting to different underlying primitives (eio uses “suspend”, similar to a form of yielding, and “fork” to create new promises).
-
Finding a way to extend the scheduler implemented by an existing library, accessing its internal state, without completely breaking its invariants, nor breaking abstraction.
Optimisation on Forward. As we mentioned in Sect. 3, forward is a construct that allows efficient delegation of asynchronous method invocations by making shortcuts when a future is resolved with another one [6]. For simplicity, we decided not to specify forward in our formal development. Its specification and proof is rather straightforward, by introducing an additional effect. In the future, in addition to this formal aspect, we would like to experiment with introducing delegated method calls automatically, following the analogy with tail-call optimisations.
Hiding Semantics and Middle-Step Reductions. Proof of correctness of translations between languages and calculi often reduce to simulation or bisimulation proofs [5, 6, 16] between a source program and a transformed program. Often, it is however necessary for the transformed program to do more steps than the original one. These additional internal steps are necessary to maintain internal information on the program state. Sometimes, even the source program must also do some internal steps. The usual tool to prove the equivalence in this case is to use a weak bisimulation that “ignores” some steps marked as internal. However, weak bisimulations do not guarantee the preservation of all program properties, in particular liveness properties [8]. In such situations, some previous work prove branching bisimilarity which is stronger but not always sufficient.
In this article, we developed a new “hiding” semantics and a middle-step reduction which executes one non-hidden step, followed by as many hidden steps as possible. This allows us to decide exactly in the specification of the translation which code is “administrative” and which code must really be synchronised. Naturally, in our context, such code is deterministic.
While we developed this in an ad-hoc manner here, we believe this approach can be adapted to many other program translations, simplifying simplifying the proof of correctness for compilers, and program transformations in general.
Notes
- 1.
In our implementation we choose to adopt the Actor terminology instead of active objects because we believe actors are better known in the functional programming community.
- 2.
For this purpose, we use PPX, a specific hook that allow to extend OCaml with new lightweight syntax extensions.
- 3.
In the future, we hope to turn asynchronous calls in a
 into delegation automatically.
into delegation automatically. - 4.
Already in [6], the authors prevented forward from appearing inside a closure.
- 5.
 denotes the reflexive transitive closure of the relation
denotes the reflexive transitive closure of the relation  .
. - 6.
A few substitutions have occurred inside poll by definition of \(C_c\). We omit them here not to clutter the proof.
- 7.
Resp. \(\sigma _1(\ell _{threads})[f_2] = \mathbb {C}\left( \lambda () . ((\lambda x. C[x]) ~e)\right) \).
- 8.
Resp.
 and \(e_2=\mathbb {C}\left( \lambda () . ((\lambda x. C[x]) ~e)\right) \).
and \(e_2=\mathbb {C}\left( \lambda () . ((\lambda x. C[x]) ~e)\right) \). - 9.
Resp. with two steps of beta-reductions.
 into delegation automatically.
into delegation automatically. denotes the reflexive transitive closure of the relation
denotes the reflexive transitive closure of the relation  .
. and
and References
Baker Jr., H.G., Hewitt, C.: The incremental garbage collection of processes. In: Proceedings Symposium on Artificial Intelligence and Programming Languages, New York, NY, USA, pp. 55–59 (1977)
Bauer, A., Pretnar, M.: Programming with algebraic effects and handlers. J. Log. Algebraic Methods Program. 84(1), 108–123 (2015). https://doi.org/10.1016/j.jlamp.2014.02.001
de Boer, F., et al.: A survey of active object languages. ACM Comput. Surv. 50(5), 76:1–76:39 (2017). Article 76
Caromel, D., Henrio, L., Serpette, B.: Asynchronous and deterministic objects. In: Proceedings of the 31st ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, pp. 123–134. ACM Press (2004)
Chappe, N., Henrio, L., Maillé, A., Moy, M., Renaud, H.: An optimised flow for futures: from theory to practice. CoRR abs/2107.07298 (2021). https://arxiv.org/abs/2107.07298
Fernandez-Reyes, K., Clarke, D., Castegren, E., Vo, H.P.: Forward to a promising future. In: Di Marzo Serugendo, G., Loreti, M. (eds.) COORDINATION 2018. LNCS, vol. 10852, pp. 162–180. Springer, Cham (2018). https://doi.org/10.1007/978-3-319-92408-3_7
Fernandez-Reyes, K., Clarke, D., Henrio, L., Johnsen, E.B., Wrigstad, T.: Godot: all the benefits of implicit and explicit futures. In: Donaldson, A.F. (ed.) 33rd European Conference on Object-Oriented Programming (ECOOP 2019). Leibniz International Proceedings in Informatics (LIPIcs), vol. 134, pp. 2:1–2:28. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik, Dagstuhl (2019). https://drops.dagstuhl.de/opus/volltexte/2019/10794. Distinguished artefact
Graf, S., Sifakis, J.: Readiness semantics for regular processes with silent actions. In: Ottmann, T. (ed.) ICALP 1987. LNCS, vol. 267, pp. 115–125. Springer, Heidelberg (1987). https://doi.org/10.1007/3-540-18088-5_10
Halstead, R.H., Jr.: MULTILISP: a language for concurrent symbolic computation. ACM Trans. Program. Lang. Syst. (TOPLAS) 7(4), 501–538 (1985)
Henrio, L.: Data-flow explicit futures. Research report, I3S, Université Côte d’Azur (2018). https://hal.archives-ouvertes.fr/hal-01758734
Henrio, L., Johnsen, E.B., Pun, V.K.I.: Active objects with deterministic behaviour. In: Dongol, B., Troubitsyna, E. (eds.) IFM 2020. LNCS, vol. 12546, pp. 181–198. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-63461-2_10
Hillerström, D., Lindley, S.: Shallow effect handlers. In: Ryu, S. (ed.) APLAS 2018. LNCS, vol. 11275, pp. 415–435. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-02768-1_22
Johnsen, E.B., Blanchette, J.C., Kyas, M., Owe, O.: Intra-object versus inter-object: concurrency and reasoning in Creol. In: Proceedings of the 2nd International Workshop on Harnessing Theories for Tool Support in Software (TTSS 2008). Electronic Notes in Theoretical Computer Science, vol. 243, pp. 89–103. Elsevier (2009)
Johnsen, E.B., Hähnle, R., Schäfer, J., Schlatte, R., Steffen, M.: ABS: a core language for abstract behavioral specification. In: Aichernig, B.K., de Boer, F.S., Bonsangue, M.M. (eds.) FMCO 2010. LNCS, vol. 6957, pp. 142–164. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-25271-6_8
Leonard, T., et al.: Eio 1.0 - effects-based IO for OCaml 5. OCaml Workshop (2023)
Leroy, X.: Formal certification of a compiler back-end, or: programming a compiler with a proof assistant. In: 33rd ACM Symposium on Principles of Programming Languages, pp. 42–54. ACM Press (2006). https://xavierleroy.org/publi/compiler-certif.pdf
Liskov, B., Shrira, L.: Promises: linguistic support for efficient asynchronous procedure calls in distributed systems. In: PLDI 1988, pp. 260–267. Association for Computing Machinery, New York (1988). https://doi.org/10.1145/53990.54016
Niehren, J., Schwinghammer, J., Smolka, G.: A concurrent lambda calculus with futures. Theor. Comput. Sci. 364(3), 338–356 (2006)
Sieczkowski, F., Pyzik, M., Biernacki, D.: A general fine-grained reduction theory for effect handlers. Proc. ACM Program. Lang. 7(ICFP) (2023). https://doi.org/10.1145/3607848
Sivaramakrishnan, K.C.: https://github.com/kayceesrk/ocaml5-tutorial. Accessed 30 May 2023
Sivaramakrishnan, K.C., et al.: Retrofitting parallelism onto OCaml. Proc. ACM Program. Lang. 4(ICFP), 113:1–113:30 (2020). https://doi.org/10.1145/3408995
Sivaramakrishnan, K.C., Dolan, S., White, L., Kelly, T., Jaffer, S., Madhavapeddy, A.: Retrofitting effect handlers onto OCaml. In: Freund, S.N., Yahav, E. (eds.) PLDI 2021: 42nd ACM SIGPLAN International Conference on Programming Language Design and Implementation, Virtual Event, Canada, 20–25 June 2021, pp. 206–221. ACM (2021). https://doi.org/10.1145/3453483.3454039
Taura, K., Matsuoka, S., Yonezawa, A.: ABCL/f: a future-based polymorphic typed concurrent object-oriented language - its design and implementation. In: Proceedings of the DIMACS Workshop on Specification of Parallel Algorithms, pp. 275–292. American Mathematical Society (1994)
Vouillon, J.: LWT: a cooperative thread library. In: Sumii, E. (ed.) Proceedings of the ACM Workshop on ML, 2008, Victoria, BC, Canada, 21 September 2008, pp. 3–12. ACM (2008). https://doi.org/10.1145/1411304.1411307
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A Proof of the Bisimulation Theorem (Theorem 2)
A Proof of the Bisimulation Theorem (Theorem 2)
A proof of bisimulation involves two simulation proofs for the same relation. We detail the proof for the first direction: the behaviour of the compiled program is one of the behaviours of the original one. This direction is more complex because of the middle-step semantics and is also more important as it states that the behaviour of the compiled program is a valid one. The other direction is done very similarly with the same arguments as the ones used in the first direction. It however has a different structure as the SOS semantics provides more different cases (but the proof below often needs to distinguish cases according to the current state of the configuration, leading to a similar set of cases overall). We omit the other direction.
Consider  , and
, and  . Let i be the thread identifier of the thread involved in the reduction
. Let i be the thread identifier of the thread involved in the reduction  (in case of spawn i is the thread that performs the spawn).
(in case of spawn i is the thread that performs the spawn).
We have  and
and  for some \(Q_1\) and \(Q'_1\). Additionally,
for some \(Q_1\) and \(Q'_1\). Additionally,  and
and  .
.
We do a case analysis on the rule used to prove the \(\text {R}_i\) relation; two cases are possible:
-
Continue:
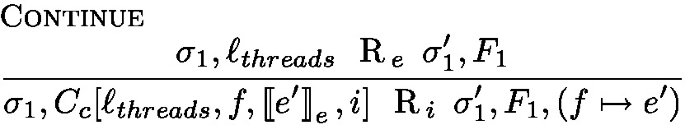
In this case, the top level of continue is a handle thanks to the context \(C_c\).
 can result from three possible rules (modulo a seq rule at the configuration level and a \(\lambda \)-calculus context rule to reach the reducible statement):
can result from three possible rules (modulo a seq rule at the configuration level and a \(\lambda \)-calculus context rule to reach the reducible statement):-
HANDLE-RETURN
 must be of the form
must be of the form  (and is inside a handle because of \(C_c\)).
(and is inside a handle because of \(C_c\)).We have
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 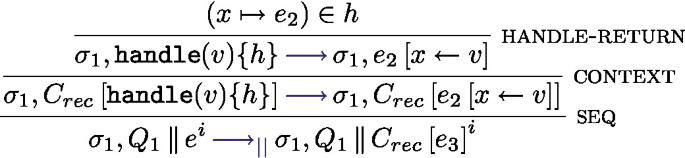
Where:

The hidden rules then update the appropriate task in the store and start the run function. Overall, we obtain:
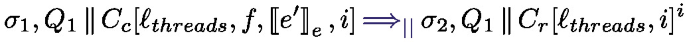
Where
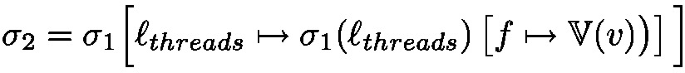
Since \(e= C_{rec}[\texttt {handle}{(v)}\{h\}]\), by case analysis on the compilation rules, we must have the source expression \(e' = v'\) be a Fut value with
 . Then we have:
. Then we have: 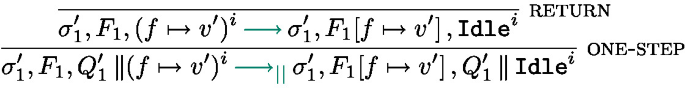
We then need to establish that the new future map and stores are in relation, i.e., \(\sigma _2, \ell _{threads} \text {R}_e \sigma '_1, F_1\!\left[ f\mapsto v'\right] \).
We recall the env rule below:
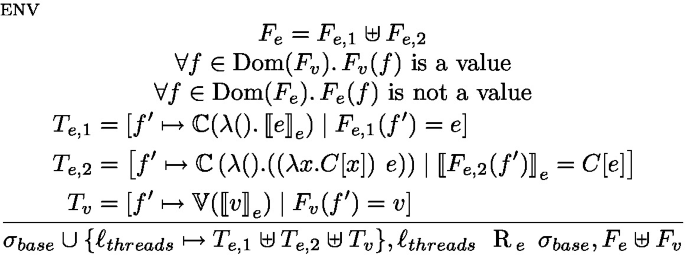
By inversion on
 , we obtain three maps \(T_{e,1} \uplus T_{e,2} \uplus T_v\) that ensure the relation. We extend \(T_v\) so that \(T_v[f]\mapsto \mathbb {V}(v)\) to obtain the relation.
, we obtain three maps \(T_{e,1} \uplus T_{e,2} \uplus T_v\) that ensure the relation. We extend \(T_v\) so that \(T_v[f]\mapsto \mathbb {V}(v)\) to obtain the relation.Recall that
 ; this is sufficient to conclude that
; this is sufficient to conclude that 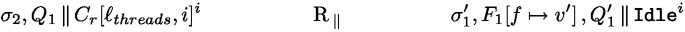
-
HANDLE-STEP
 must be of the form
must be of the form  where
where  can only be reduced by a \(\lambda \)-calculus reduction.
can only be reduced by a \(\lambda \)-calculus reduction.We have
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 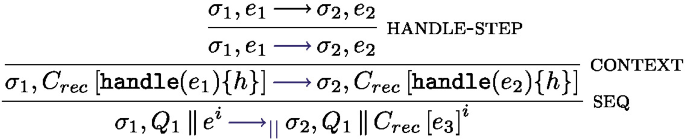
Where:
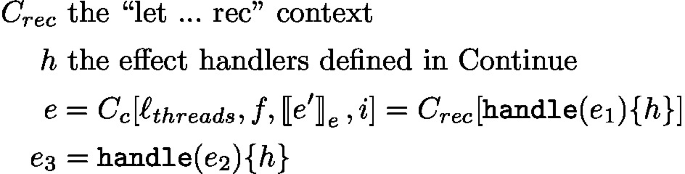
The translation leave \(\lambda \)-calculus terms unchanged, without any hiding, thus there are no follow up hidden rules.
Overall, we obtain:
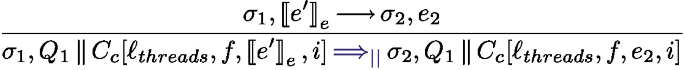
We know that \(\sigma _1, \ell _{threads} ~\text {R}_e~ \sigma '_1, F_1\). By definition, this means that \(\sigma _1 = \sigma '_1 \cup \{ \ell _{threads} \mapsto T \}\) for some map T. By definition of the translation, \(\ell _{threads}\) is not accessible by user code, and thus left unchanged by the reduction on
 . As such, we have:
. As such, we have: 
By case analysis on the translation and the \(\lambda \)-calculus reduction rules, \(e'\) must be reduced by the same \(\lambda \)-calculus reduction rule than
 . Thus:
. Thus: 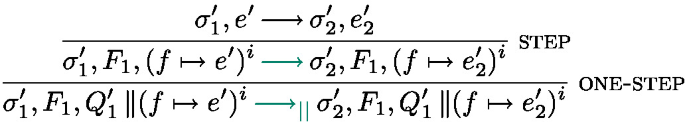
This case analysis and by determinism of our \(\lambda \)-calculus, we have
 . We also have \(\sigma _2, \ell _{threads} \text {R}_e \sigma '_2, F_1\).
. We also have \(\sigma _2, \ell _{threads} \text {R}_e \sigma '_2, F_1\).This is sufficient to conclude that
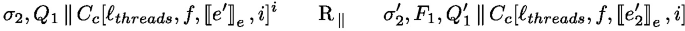
-
HANDLE-EFFECT
 must be of the form
must be of the form  (and is inside a handle because of \(C_c\)). We distinguish by the effect captured:
(and is inside a handle because of \(C_c\)). We distinguish by the effect captured:-
\({\boldsymbol{Async}}({\boldsymbol{job}},t')\). We have
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 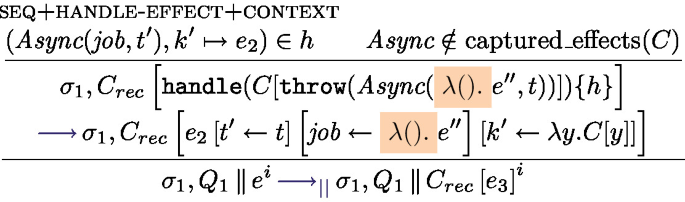
Where:

By definition of the translation, and because the reduction is possible, the arguments of the Async effect must be a thunk task, and its second argument must be a thread identifier (it can be an expression but this one is entirely evaluated before triggering the effect). This as some consequences on the considered Fut configuration, e.g. \(e'\) is of the form \(\texttt {AsyncAt}(e_0,t)\). Additionally, t is the same on both side as thread identifiers are preserved by the translation (this can be proven by case analysis on the definition of \(\text {R}_i\)).
The hidden rules apply then update the suspended tasks in the store and start the continue function. The last hidden reduction rule is the beta-reduction that de-thunks the continuation \( \lambda ().(\lambda y.C[y])(\textit{fut}')\) inside the handler of continue and puts \(\textit{fut}'\) back into the invocation context.
Overall, we obtain:
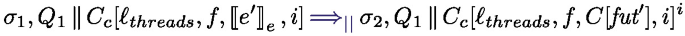
Where

Since
 , by case analysis on the compilation rules, we must have the source expression
, by case analysis on the compilation rules, we must have the source expression  where
where  and
and  by Lemma 1. Note also that the set of future identifiers are the same in the Fut program and in its translation, and thus \(\textit{fut}' = (t,\textit{fresh}())\) is a fresh future in the Fut configuration. Then we have:
by Lemma 1. Note also that the set of future identifiers are the same in the Fut program and in its translation, and thus \(\textit{fut}' = (t,\textit{fresh}())\) is a fresh future in the Fut configuration. Then we have: 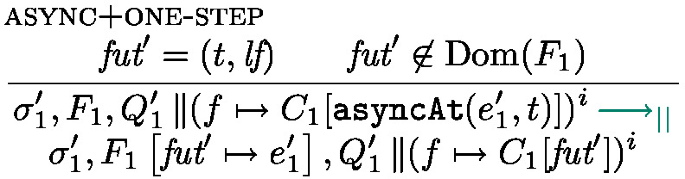
We then need to establish that the new future map and stores are in relation, i.e., \(\sigma _2, \ell _{threads} \text {R}_e \sigma '_1, F_1\!\left[ \textit{fut}'\mapsto e'_1\right] \).
We recall the env rule below:
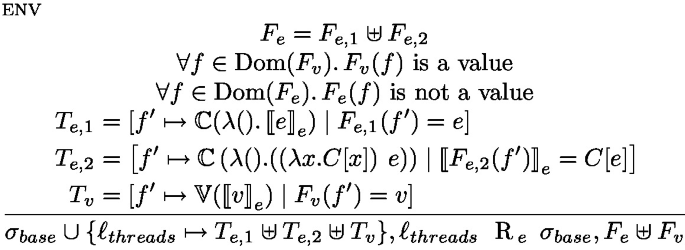
By inversion on \(\sigma _1,\ell _{threads} ~\text {R}_{e}~ \sigma _1',F_1\), we obtain tree maps \(T_{e,1} \uplus T_{e,2} \uplus T_v\) that ensure the relation. We then extend \(T_{e,1}\) so that
 to obtain the relation.
to obtain the relation.This is sufficient to conclude that
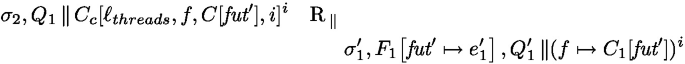
-
\({\boldsymbol{Get}}(f')\). We have
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 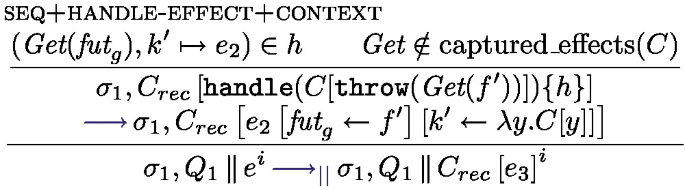
WhereFootnote 6:

The argument of the Get effect must be a future reference that is totally evaluated for the rule to succeed. If it is not a future the evaluation of poll fails. If it is not fully evaluated, the reduction should first occur inside the argument of the Get effect.
Details on Poll Reductions. At this point, we look at hidden reductions, which must start in the body of poll. If the future is unresolved, poll loops forever and the medium step reduction diverges. This means either that the future never resolves, and this divergence in Eff simulates a deadlock in Fut; or that we could make reductions in other threads to resolve the deadlock. In the second case, the semantics for Eff would interleave loops in poll and reduction in other threads. Such interleaving is equivalent to triggering the Get event at the end, with a single loop in poll. The current theorem only consider this last interleaving. Overall, if there is a medium step reduction it means that the future is resolved.
In this case, the future has been resolved, and, by bisimilarity on the stores (\(\text {R}_e\)) we have \(F_1(f')=v\) and \(\sigma _1(\ell _{threads})[f']=v\) for some v. We obtain after a couple of steps of beta-reduction:

Since \(e= C_{rec}[\texttt {handle}{(C[\texttt {throw}({\textit{Get}(f'))}]}){h}]\), by case analysis on the compilation rules, we have
 where
where  by Lemma 1. Then we have:
by Lemma 1. Then we have: 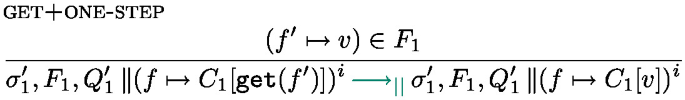
This is sufficient to conclude that
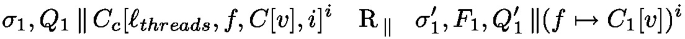
-
Await\((f')\) . The case when the awaited future is resolved is similar to the case of the Get effect just above. We only detail the proof in case the future is still unresolved.
We have
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 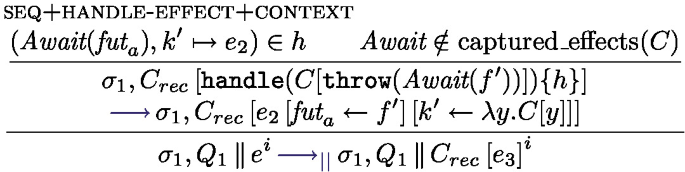
Where:

Like in the Get case, the argument of the Await effect must be a future reference that is totally evaluated for the rule to succeed.
When the future is unresolved, \(\ell _{threads}[f']\) is not a value (it is not mapped or mapped to a \(\mathbb {C}{}\)). By definition of \(\texttt {R}_e\) we necessarily have: \(\not \exists v.\, (f' \mapsto v)\in F_1 \). Then a few hidden beta reduction steps lead to the following configuration:
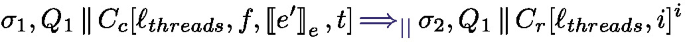
Where
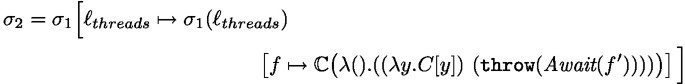
Since \(e= C_{rec}[\texttt {handle}{(C[\texttt {throw}({\textit{Await}(f'))}]}){h}]\), by case analysis on the compilation rules, we have
 where
where  by Lemma 1. Thus on the Fut side, we have:
by Lemma 1. Thus on the Fut side, we have: 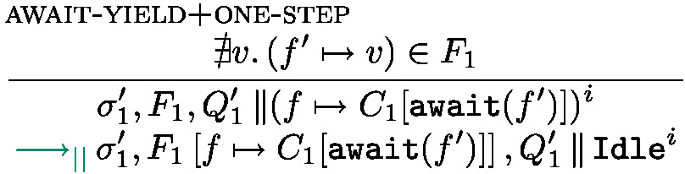
We easily obtain that
 by expanding the environment \(T_{e,2}\) in the env rule.
by expanding the environment \(T_{e,2}\) in the env rule.With the arguments above and the case run of
 we conclude:
we conclude: 
-
\({\boldsymbol{Spawn}}()\). We have
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 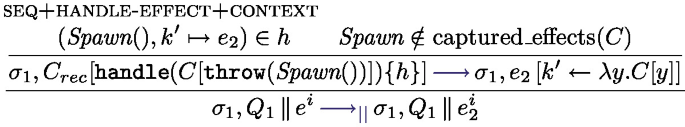
With: \(C_{rec}\) the “let ... rec” context of the continue handler inside \(C_c\), h the effect handlers defined in Continue, additionally:
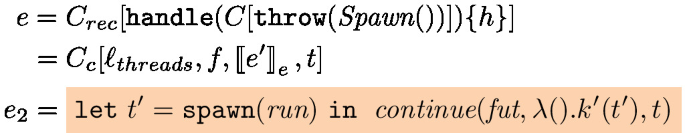
The first hidden rule applied is
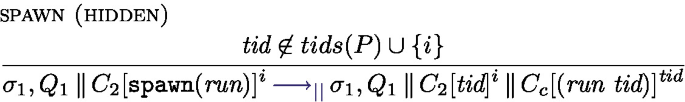
Where \(e_2= C_2[\texttt {spawn}({\textit{run}})]\). This is followed by steps of beta reduction to reduce the \(\texttt{let}\ t' =\ldots \) construct, trigger continue, pass the associated \(\textit{tid}\) and de-thunk the \(\lambda ().\lambda y.C[y](\textit{tid})\) inside continue. We obtain the following configuration
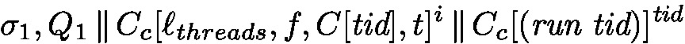
Finally, by a step of beta reduction in the thread \(\textit{tid}\) we obtain the right evaluation context \(C_r\)
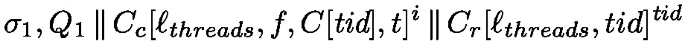
This configuration is not reducible by a hidden transition. Thus
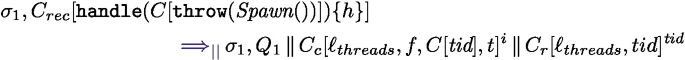
By case analysis on the terms involved in
 we have
we have  where
where  by Lemma 1. We then have:
by Lemma 1. We then have: 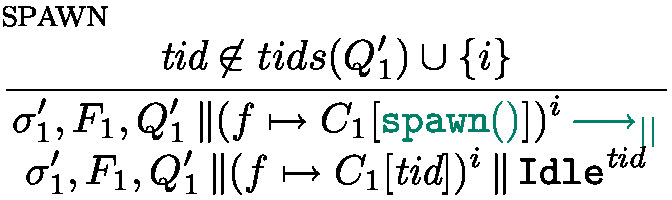
Note that by definition of
 the set of used thread identifiers is the same in both configurations, wo we can take the same fresh \(\textit{tid}\). Note also that the store and the future map are unchanged. Comparing thread by thread, we can directly apply rule run and rule cont for the two processes \(\textit{tid}\) and i, which leads to the conclusion:
the set of used thread identifiers is the same in both configurations, wo we can take the same fresh \(\textit{tid}\). Note also that the store and the future map are unchanged. Comparing thread by thread, we can directly apply rule run and rule cont for the two processes \(\textit{tid}\) and i, which leads to the conclusion: 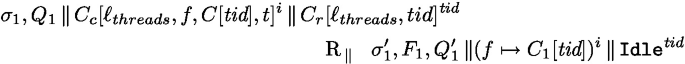
-
-
-
Run:
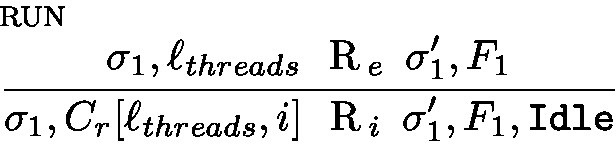
The only first applicable rule is the pop operation reduction that picks a new available thread:
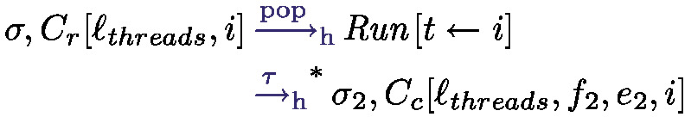
Note that pop ensures that \(f_2\) is of the form \(f_2=(i, \textit{lf})\). Using only reductions in the thread i and such that:
 Footnote 7 by definition of \(\text {R}_i\) and
Footnote 7 by definition of \(\text {R}_i\) and 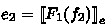 Footnote 8 by definition of pop. Note that the last step of reduction is inside continue and de-thunks the new task (
Footnote 8 by definition of pop. Note that the last step of reduction is inside continue and de-thunks the new task ( )Footnote 9. We additionally have:
)Footnote 9. We additionally have: 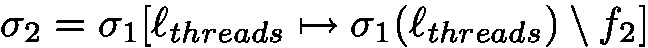
From the points above, we obtain (with \(f_2=(i, \textit{lf})\)):
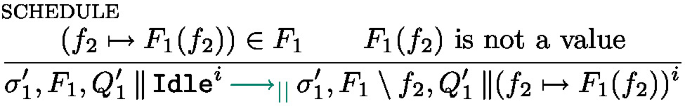
Note that
 by construction of the equivalence on stores (Fig. 16). Finally (the equivalence on the store can be trivially checked):
by construction of the equivalence on stores (Fig. 16). Finally (the equivalence on the store can be trivially checked): 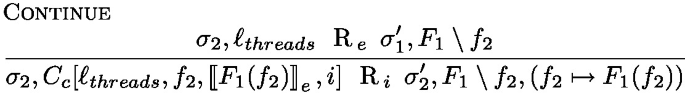
This immediately concludes by adding the other threads (in \(Q_1\) and \(Q'_1\)) and obtaining the
 relation on the obtained configurations. \(\square \)
relation on the obtained configurations. \(\square \)
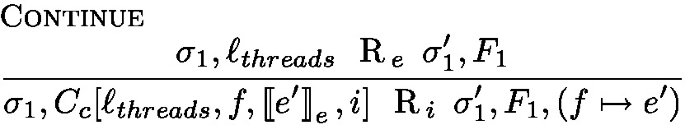
 can result from three possible rules (modulo a
can result from three possible rules (modulo a  must be of the form
must be of the form  (and is inside a handle because of
(and is inside a handle because of  . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 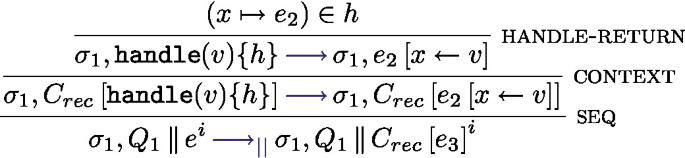

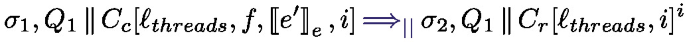
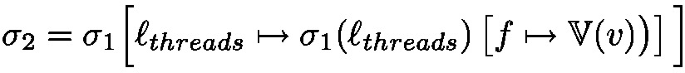
 . Then we have:
. Then we have: 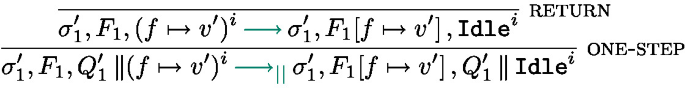
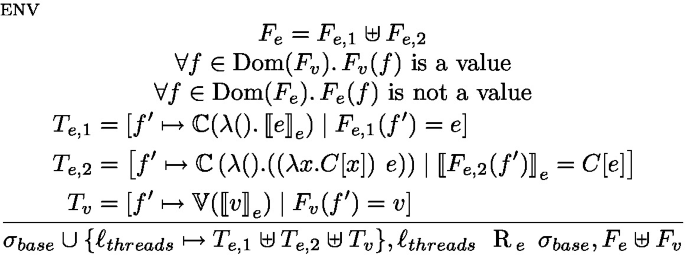
 , we obtain three maps
, we obtain three maps  ; this is sufficient to conclude that
; this is sufficient to conclude that 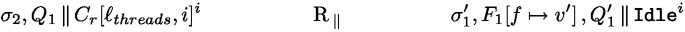
 must be of the form
must be of the form  where
where  can only be reduced by a
can only be reduced by a  . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 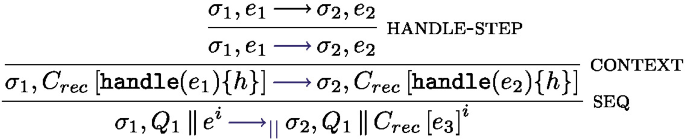
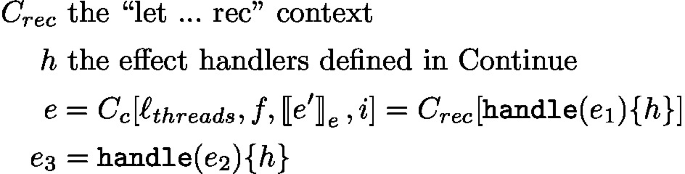
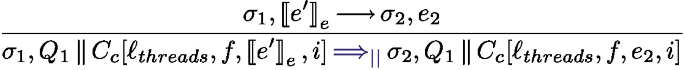
 . As such, we have:
. As such, we have: 
 . Thus:
. Thus: 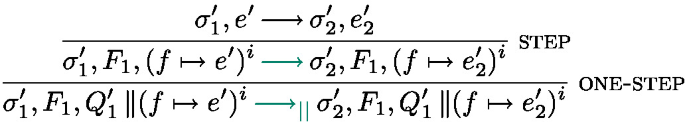
 . We also have
. We also have 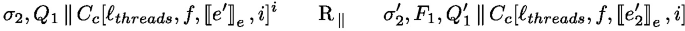
 must be of the form
must be of the form  (and is inside a handle because of
(and is inside a handle because of  . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 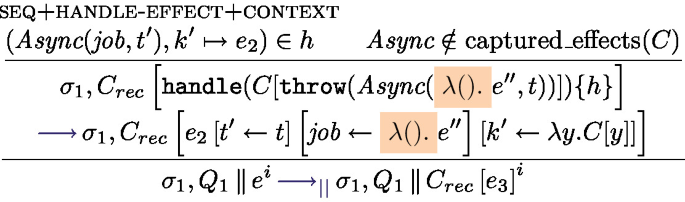

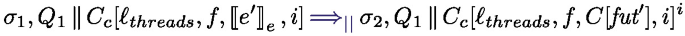

 , by case analysis on the compilation rules, we must have the source expression
, by case analysis on the compilation rules, we must have the source expression  where
where  and
and  by Lemma
by Lemma 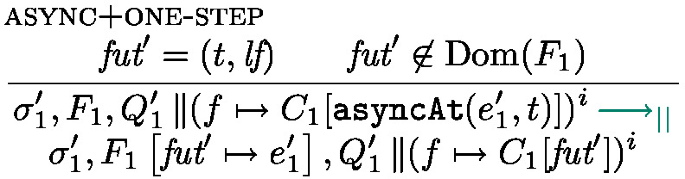
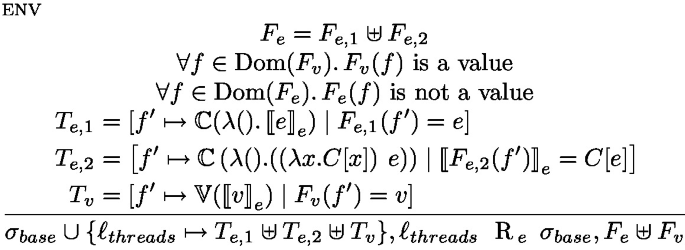
 to obtain the relation.
to obtain the relation.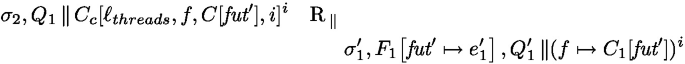
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 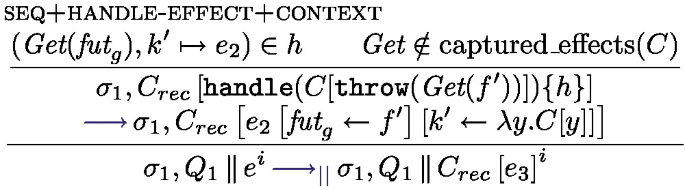


 where
where  by Lemma
by Lemma 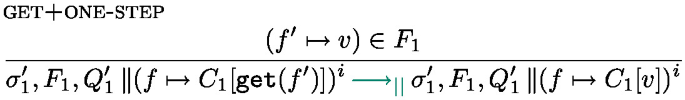
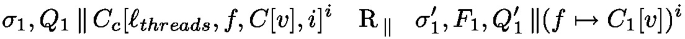
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 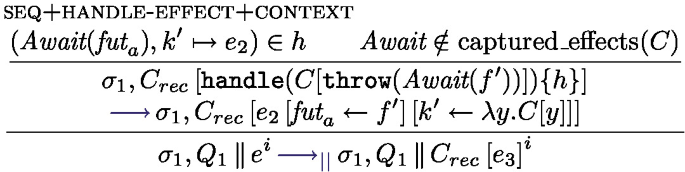

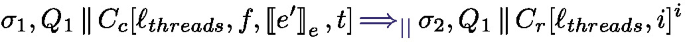
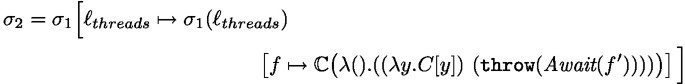
 where
where  by Lemma
by Lemma 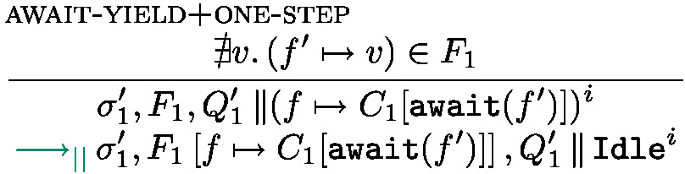
 by expanding the environment
by expanding the environment  we conclude:
we conclude: 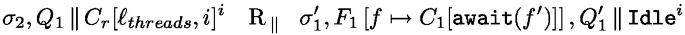
 . Its first visible reduction rule must be:
. Its first visible reduction rule must be: 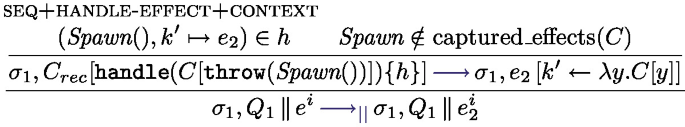
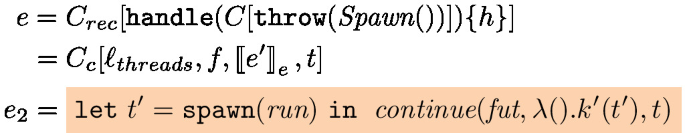
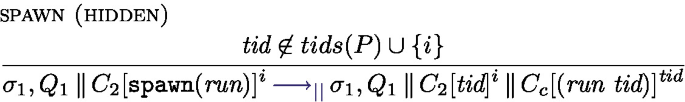
 we have
we have  where
where  by Lemma
by Lemma 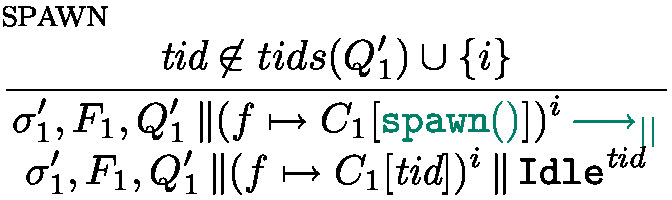
 the set of used thread identifiers is the same in both configurations, wo we can take the same fresh
the set of used thread identifiers is the same in both configurations, wo we can take the same fresh 
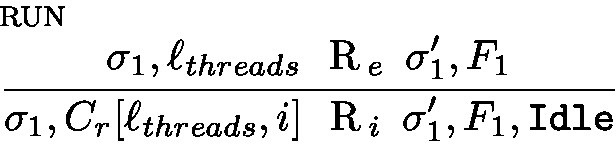
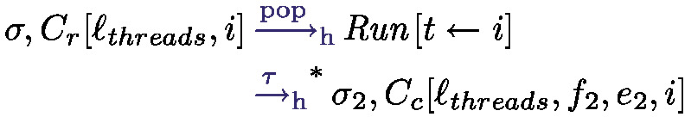

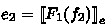
 )
)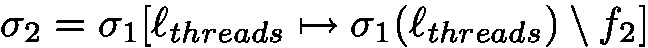
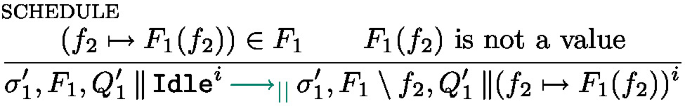
 by construction of the equivalence on stores (Fig.
by construction of the equivalence on stores (Fig. 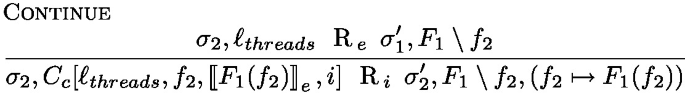
 relation on the obtained configurations.
relation on the obtained configurations. Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Andrieux, M., Henrio, L., Radanne, G. (2024). Active Objects Based on Algebraic Effects. In: de Boer, F., Damiani, F., Hähnle, R., Broch Johnsen, E., Kamburjan, E. (eds) Active Object Languages: Current Research Trends. Lecture Notes in Computer Science, vol 14360. Springer, Cham. https://doi.org/10.1007/978-3-031-51060-1_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-51060-1_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-51059-5
Online ISBN: 978-3-031-51060-1
eBook Packages: Computer ScienceComputer Science (R0)