
Abstract
One of the biggest challenges in Recommendation Algorithms (RA) is how to obtain user and item embeddings from sparse interaction history. To take this challenge, most graph neural network based RAs explicitly incorporate high-order collaborative filtering signals on the user-item bipartite graph with either multi-layer semantics on the Knowledge Graph (KG) or multi-level neighbors on the social network. However, none of them fully integrate these three types of graph-structured data, which decreases embeddings’ precision. Based on this consideration, this paper integrates the three types of data by proposing a knowledge-rich influence propagation RA based on the graph attention mechanism. Specifically, in the semantic propagation, we categorize user preferences into deep interest obtained by multiple graph attention message propagations on related KG parts, and shallow interest generated from the interaction history. Moreover, the influence weight between items is determined by the number of co-interactions and the semantic similarity. These two factors as well as social relations together decide the influence weight between users. With these influence weights, final user and item embeddings are calculated through multi-layer message propagation. The experimental results show that the proposed recommendation algorithm outperforms several compelling baselines on six scaled-down real-world datasets. This work has confirmed the effectiveness of combining these three types of data to increase RAs’ coverage and accuracy.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
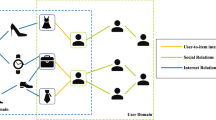
As one of the most popular recommendation Algorithms (RA), Collaborative Filtering (CF) is able to detect inter-user or inter-item similarities to make recommendations for users accordingly. Since user-item interaction history is represented as a bipartite graph, Graph Neural Networks (GNN) are utilized to predict the missing user-item interactions [3]. However, user preference inference based only on the sparse user-item interaction history yields insufficient and coarse-grained results. The widely used approach of solving the sparsity problem is to combine side information collected from the system. Side information includes attributes in the form of text or images, social relationships among users and users’ comments on items and other contents [10]. In particular, as shown in Fig. 1, GNNs can be used to fully merge two kinds of graph-structured side information: triplets between items and attributes on the Knowledge Graph (KG) and user-user connections on the social network with the bipartite graph [4].

An example with three kinds of graph-structured data in Yelp2018
Specifically, GNN-based collaborative filtering RAs usually combine the bipartite graph with either the KG or the social network. The former incorporates rich semantics to enhance the accuracy and interpretability of recommendations, and the latter leverages high-order social effects to modify user interests [17, 21]. Yet, neither of them is fully satisfactory as they mainly rely on limited data. On the one hand, the KG-based RAs fail to account for user attribute-level interests despite that users choose items for specific reasons. On the other hand, they neglect to explicitly model high-order CF signals reflecting directly inter-user and inter-item influences [19]. In addition, they do not appreciate the importance of social diffusion. Without mixing high-order CF signals expressing user interest similarities with social influences, the social network-based RAs also fail to take advantage of available item attributes to infer user preferences.
To address these issues, this paper proposes a Knowledge-Rich Influence Propagation Recommendation (KIPRec) that seamlessly fuses the KG, the social network, and the user-item bipartite graph. To obtain reasonably precise user and item embeddings, multi-layer Graph ATtention networks (GAT) are employed to aggregate neighbor messages. There are two main components in KIPRec. The first part is to explore semantic information, where user preferences are divided into shallow-level interests derived from interacted item sequences and deep-level interests obtained by aggregating semantics from their KG subgraphs. The second part is to propagate influence information. User-user connections in the social network are combined with user-user co-interactions from the bipartite graph to organize an influence graph and refine user interests. In particular, the main contributions of this paper are summarized as follows:
-
A comprehensive RA is proposed by integrating three types of side information with graph structures to alleviate the sparsity problem in RAs.
-
The validity of the proposed RA is fully and extensively investigated in two commonly used recommendation scenarios: Click-Through-Rate (CTR) prediction and Top-K recommendation. Specifically, for the Recall@20 metric, our RA improves by 1.92% and 5.64% on the Last-FM and Yelp2018 datasets, respectively, compared to the state-of-the-art (SOTA) KG-based RA, and it improves by 10.05% and 11.54% over the SOTA social network-based RA, respectively.
-
Ablation experiments are conducted to analyze the functions of KIPRec’s two main components.
The rest of this paper is organized as follows: Sect. 2 reviews the related work on GNN-based collaborative filtering RAs based on the KG or the social network. Section 3 presents the main problem addressed in this paper. The structure of proposed model is detailedly explained in Sect. 4. Extensive comparisons among KIPRec and its baselines as well as other studies are provided in Sect. 5. Finally, we conclude this paper with a discussion of the future directions in Sect. 6.
2 Related Work
By explicitly modeling high-order CF signals on the user-item bipartite graph via multiple forms of message passing, the current graph convolutional neural network-based methods such as LightGCN [5], GAT-based methods, and graph sampling aggregate network-based methods have achieved significant improvements compared with the traditional matrix decomposition methods [12] and most deep learning-based methods [26]. However, these GNN-based approaches fail to satisfactorily perform the task of acquiring useful information on heterogeneous graphs with multiple node or edge types. We will discuss the most related work in terms of the following aspects.
GNN-based RAs on the KG are divided into the following three categories: embedding-based methods, path-based methods, and propagation-based methods [6]. Items in the bipartite graph are mapped to entities in the KG, hence embedding-based approaches like MKR [14] combine the KG embedding algorithms and the recommendation module in a certain sequence. However, it might be difficult to accurately correlate the embeddings learned by these two modules. Path-based approaches, such as KPRN [18], merge the bipartite graph and the KG into a unified graph according to the correlations between items and entities. Paths between users and items are extracted from the graph to generate embeddings. Yet, path-based approaches require expert knowledge to decrease space and time consumption for processing huge volumes of paths.
Differently, propagation-based approaches apply GNNs directly to the KG, deriving node semantic embeddings by message propagation. Typical procedures for this sort of algorithms are outlined below. RippleNet [13] initializes item embeddings and refines user embeddings based on related multi-layer triplets. Starting from the user-interacted items, these triplets are obtained by aligning head and tail entities in triplets on the KG. KGCN [15] first randomly initializes user embeddings but constructs item embeddings for the target user by aggregating the neighbor messages from the items’ receptive fields with GAT. By correlating intents with relations on the KG, KGIN [17] provides an explicit interpretation of intentions and a finer granularity of user and item embeddings. Besides exploring semantics in the KG, CKAN [19] additionally employs CF signals on the item side. CKAN first refreshes entity embeddings on the KG using a multi-layer GAT, then considers embeddings of the user-interacted items on the KG as the user embedding, and finally pools embeddings of all items on the KG that share at least one users on the bipartite graph into the item embedding. In this paper, the semantic propagation component adopts a KGCN-like technique to construct semantic propagation trees and refine embeddings, which provides a reasonable explanation of users’ preferences and items’ features. CKAN does not involve the interest similarities between users with co-interactions.
GNN-based RAs on the social network aim to rationally leverage the bipartite graph and the social network with diverse topologies to strengthen user interests. GATs are employed to evaluate the impacts of social connections and CF signals on each user’s interest, as some users are easily swayed by their peers while others tend to adhere to their own preferences [1]. GraphRec [2] only considers users’ first-order CF signals and social neighbors, and Diffnet++ [21] takes into account users’ high-order contexts. Furthermore, some approaches like DISGCN [9] are proposed to disentangle the correspondence between the social connection and interest similarity into multiple dimensions, and some self-supervised approaches such as SEPT [24] are designed to eliminate fragile and noisy social relationships.
In addition, GSIRec [8] is equipped with a knowledge assistance module as the bridge between knowledge-aware recommendation and social-aware recommendation. However, this multi-task method may encounters the problem of negative transfer when knowledge gained in one task lowers performance in another [27]. Social-RippleNet [7] additionally utilizes the KG to adjust item embeddings and applies the social network to modify user preferences. Yet, users’ profiles would be more transparent if the KG were used to extend the tags that define users.
3 Problem Formulation
In this paper, the user-item bipartite graph is denoted as a binary-valued symmetric matrix \(Y\in \mathbb {R}^{m \times n}\) as usual, where \(y_{ui}=y_{iu}=1\) indicates there is an observed interaction between a user \(u \in U\) and an item \(i \in I\). The KG \(\mathcal {G}=\{( \mathcal {h},\mathcal {r},\mathcal {t}) \mid \mathcal {h}, \mathcal {t} \in \mathcal {E}, \mathcal {r} \in \mathcal {R} \}\) is a directed graph made up of the entity set \(\mathcal {E}\) and relation set \(\mathcal {R}\), where \(( \mathcal {h},\mathcal {r},\mathcal {t})\) refers to a triplet containing a head entity \(\mathcal {h}\), a tail entity \(\mathcal {t}\) and a relation \(\mathcal {r}\) connecting them. Most items in the bipartite graph have corresponding entities in the KG, i.e., \(I \subseteq \mathcal {E}\). The social network is an undirected graph represented by \(S \in \mathbb {R}^{m \times m}\) , with \(s_{uu^{'}}=s_{u^{\prime }u}=1\) indicating the existence of a following or followed relationship for users \(u,u^{\prime } \in U\). Given a bipartite graph Y, a KG \(\mathcal {G}\) and a social network S, our model optimizes parameters in \(\varTheta \) to learn embeddings of user \(u_p\) and item \(i_q\), which in turn predict the likelihood \(\hat{y}_{pq}\) of the interaction between them via the function \(\mathcal {F}\): \(\hat{y}_{pq}=\mathcal {F}(u_p,i_q \mid Y,\mathcal {G},S,\varTheta )\). We will specify \(\varTheta \) in Sect. 4.4.
4 Methodology
This paper focuses on implicit binary-valued user behaviors without considering the effect of time. As mentioned before, the goal is to predict the probability of an interaction between a user-item pair (p, q). To this end, Fig. 2 and Fig. 3 illustrate the overall structure of the proposed RA. It consists of four components: an initialization layer, a semantic propagation layer, an influence propagation layer, and a prediction layer. We will elaborate them in the following.

The initialization layer and semantic propagation layer in KIPRec
4.1 The Initialization Layer
To begin with, we represent all nodes and edges on all graphs with trainable embeddings of a fixed length d. The notations \(e_{u_p}^f\), \(e_{i_q}^f\), \(e_{\mathfrak {e}_c}^f\), \(e_{r_d}^f\) \(\in \mathbb {R}^d\) respectively denote the free embedding of user \(u_p\), item \(i_q\), entity \(\mathfrak {e}_c\), relation \(r_d\). The influence propagation layer’s initial embeddings are derived from the semantic propagation layer’s outputs. Before proceeding to the semantic propagation layer, we need to calculate the context information for the user-item pair (p, q) in the influence propagation layer, i.e., all the users and items related to (p, q).
The inter-user and inter-item influence matrices \(Y_{inf} \in \mathbb {R}^{m \times m}\) and \(A_{inf} \in \mathbb {R}^{n \times n}\) are calculated by multiplying the user-item interaction matrix \(Y \in \mathbb {R}^{m \times n}\) with the item-user interaction matrix \(A \in \mathbb {R}^{n \times m}\). Values in \(Y_{inf}\) and \(A_{inf}\) reflect numbers of common interactions. (p, q)’s user-level context information is represented as \(U_{con(p,q)} =U_{con(p,q)}^1 \cup U_{con(p,q)}^2 \cup U_{con(p,q)}^3\). In detail, \(U_{con(p,q)}^1\) contains the users who have shared items with \(u_p\). \(U_{con(p,q)}^2\) represents the users that might share similar interests with \(u_p\) in the absence of co-interactions. And \(U_{con(p,q)}^3\) denotes users who have social connections with \(u_p\). \(U_{con(p,q)}^t=\cup _{k=1}^K U_{con(p,q)}^{t(k)}\), where \(U_{con(p,q)}^{0}=\{u_p\}\), \(k\in \{1,2,...,K\}\) and \(t\in \{1,2,3\}\). Each user group contains K parts, since the influence propagation procedure is repeated K times.

The influence propagation layer and the interaction prediction layer in KIPRec
Specifically, during the k-th influence propagation, \(U_{con(p,q)}^{1(k)}\) consists of the first-order neighbors of all users in \(U_{con(p,q)}^{1(k-1)}\), with column subscripts of the non-zero elements in \(Y_{inf}\). Similarly, \(U_{con(p,q)}^{3(k)}\) is formed by all users in the first-order neighbors of \(U_{con(p,q)}^{3(k-1)}\) under the direction of the social matrix S. Regarding \(U_{con(p,q)}^{2(k)}\), user interaction histories are frequently restricted to a narrow area, resulting in users with similar interests rarely having shared items, so we randomly choose a L fraction from \(U-U_{con(p,q)}^{1(k)}\) to generate \(U_{con(p,q)}^{2(k)}\).
The item-level context information of (p, q) lies in \(I_{con(p,q)} = I_{con(p,q)}^1 \cup I_{con(p,q)}^2 \cup I_{con(p,q)}^3\). Alternatively, we use a similar method as before to obtain \(I_{con(p,q)}^1\) and \(I_{con(p,q)}^2\). During the k-th influence propagation, \(I_{con(p,q)}^{3(k)}\) is formed by first-order neighbors of all users in \(U_{con(p,q)}^{(k-1)}\) under the direction of the interaction matrix Y. \(I_{con(p,q)}^3=\cup _{k=1}^K I_{con(p,q)}^{3(k)}\), where \(k\in \{1,2,...,K\}\). Figure 2 displays how to obtain the third-order context information for the target user and item.
4.2 The Semantic Propagation Layer
This section shows how to generate semantic propagation trees and update their roots’ embeddings. For all users from the user contexts and items from the item contexts of the target user-item pair (p, q) described in Sect. 4.1, we establish their semantic propagation trees according to the user-item bipartite graph Y and the KG \(\mathcal {G}\). Initial embeddings of these users and items are then updated through extended GAT operations on the trees.
Constructing Semantic Propagation Trees. \(T_{q^{\prime }}^h\) and \(T_{p^{\prime }}^h\) respectively represent triplet sets related to an item \(i_{q^{\prime }}\) in \(I_{con(p,q)}\) and a user \(u_{p^{\prime }}\) in \(U_{con(p,q)}\) during the h-th semantic propagation. From corresponding entity of \(i_{q^{\prime }}\) on the KG as root, related subgraph of \(i_{q^{\prime }}\) is extracted by aligning the tail of one triplet with the head of another for H times as described in Eq. (1), where the symbol \(*\) indicates an arbitrary entity or relationship, and \((\mathcal {h},\mathcal {r},\mathcal {t})\) is a triplet on the KG \(\mathcal {G}\). We limit the number of entities per layer \(\mid T_{q^{\prime }}^h \mid \) as \(w_1\) to save memory space.
As described in Eq. (2), for each user \(u_{p^{\prime }}\) in \(U_{con(p,q)}\), we sample \(w_2\) attributes from the first-order entity neighbors of \(u_{p^{\prime }}\)’s interacted items, i.e., \(|T_{p^{\prime }}^1|=w_2\), and connect \(u_{p^{\prime }}\) with these entities. \(y_{p^{\prime } \mathcal {h}} = 1\) means there is an interaction between \(u_{p^{\prime }}\) and the item corresponding to entity \(\mathfrak {e}_{\mathcal {h}}\). Afterwards, the semantic propagation trees are built for users in the same way, i.e., \(\mid T_{p^{\prime }}^h \mid =w_1\) when \(h\ge 2\). Figure 2 illustrates four semantic propagation trees with \(H,w_1=2\) and \(w_2=4\).
Implementing Semantic Propagation Operations. We represent an arbitrary user or item with the uniform symbol o. The semantic propagation procedure is executed \((H-v)\) times for each node in \(N_o^v\). \(N_o^v\) includes all nodes on the v-th layer of the semantic tree with node o as the root, where \(v\in \{0,1,\ldots ,H\}\). Assumed that the l-th message propagation is to be performed (\(l\in \{1,\ldots ,H-v\}\)) and the g-th node on the v-th layer is \(\mathfrak {e}_g \in N_o^v\), related triplets of \(\mathfrak {e}_g\) are contained in \(T_{o(g)}^{v+1}=\{(\mathcal {h}, \mathcal {r}, \mathcal {t}) \mid (\mathcal {h},\mathcal {r},\mathcal {t})\in T_o^{v+1} \; and \; \mathcal {h}=\mathfrak {e}_g \}\). We first map the tail entity \(\mathfrak {e}_\mathcal {t}\)’s embedding derived from the \((l-1)\)-th message propagation onto the same level with relation \(r_\mathcal {r}\) via the Hadamard product operation \(\odot \). This not only decouples \(\mathfrak {e}_\mathcal {t}\)’s features, but also preserves semantics along message propagation paths, as described in KGIN [17]. Further, the contribution of the t-th (\(t\in \{1,...,|T_{o(g)}^{v+1}|\}\)) triplet to the head entity \(\mathfrak {e}_g\), i.e., \(\alpha _t^l\), is valued in Eq. (3) as the similarity between the root o and \(\mathfrak {e}_\mathcal {t}\) by concatenating the two embeddings labeled with \(\mid \mid \) and then obtaining a numerical value via a two-layer perceptron.
Moreover, \(\widetilde{\alpha }_t^l\) is the result of softmax normalization on \(\alpha _t^l\). The embedding of \(\mathfrak {e}_g\) after the l-th message propagation results from aggregated relevant features and the embedding of \(\mathfrak {e}_g\) after the \((l-1)\)-th propagation, shown in Eq. (4).
The symbol n denotes a user, an item or an entity. \(\mathcal {r}\) refers to a relation. In general, the initial embeddings of n and \(\mathcal {r}\) in the semantic propagation layer come from the initialization layer, i.e., \(e_{n}^0=e_{n}^f\) and \(e_{r_\mathcal {r}}=e_{r_\mathcal {r}}^f\). After the propagation procedure is performed H times, semantics related to the root nodes (\(u_{p^{\prime }} \in U_{con(p,q)}\) and \(i_{q^{\prime }} \in I_{con(p,q)}\)) on the semantic propagation trees, is distilled into their embeddings \(e_{u_{p^{\prime }}}^H\) and \(e_{i_{q^{\prime }}}^H\). Primary characteristics of \(i_{q^{\prime }}\) are indicated by \(e_{i_{q^{\prime }}}^s\) (equal to \(e_{i_{q^{\prime }}}^H\)). However, as in Eqs. (5) and (6), interests of \(u_{p^{\prime }}\) are also expressed by user-item interactions \(\mathcal {Y}_{u_{p^{\prime }}}\) except for deep-level user interests marked by \(e_{u_{p^{\prime }}}^{deep}\) (equal to \(e_{u_{p^{\prime }}}^H\)) [20]. The contribution \(\widetilde{\beta }_{p^{\prime }\mathcal {v}}\) of \(u_{p^{\prime }}\)’s interactive item \(i_\mathcal {v}\) to shallow interest embedding \(e_{u_{p^{\prime }}}^{shallow}\) is generated through an extended GAT operation and normalization. Eventually, deep interest \(e_{u_{p^{\prime }}}^{deep}\) and shallow interest \(e_{u_{p^{\prime }}}^{shallow}\) of \(u_{p^{\prime }}\) both contribute to the preliminary embedding \(e_{u_{p^{\prime }}}^s\).
4.3 The Influence Propagation Layer
For further adjustment of user and item embeddings, the influence propagation is required to be performed over K iterations by absorbing relevant information from their K-nearest neighbors. The inital embedding of any user u in context \(U_{con(p,q)}\) of \(u_p\), indicated by \(e_u^{r(0)}\), is equal to \(e_u^s\). Similarly, each item i in context \(I_{con(p,q)}^1 \cup I_{con(p,q)}^2\) of \(i_q\) has the condition \(e_i^{r(0)} = e_i^s\). K-nearest neighbors of \(u_p\) and \(i_q\) are respectively included in \(U_{con(p,q)}\) and \(I_{con(p,q)}^1 \cup I_{con(p,q)}^2\).
During the k-th message propagation, item \(i_p\) needs to gain influence from its first-order neighbors in \(I_{con(p,q)}^{(1)} = I_{con(p,q)}^{1(1)} \cup I_{con(p,q)}^{2(1)}\), where \(k\in \{1,2,...,K\}\). \(I_{con(p,q)}^{1(1)}\) denotes items with which \(i_p\) shares users, while \(I_{con(p,q)}^{2(1)}\) indicates items with similar semantics but no shared user. These items that may affect form \(I_{con(p,q)}^{(1)}\). For an item \(i_\mathfrak {q} \in I_{con(p,q)}^{(1)}\), we measure the semantic similarity between \(i_\mathfrak {q}\) and \(i_q\) via the inner product of \(e_{i_q}^{r(k-1)}\) and \(e_{i_\mathfrak {q}}^{r(k-1)}\), then amplify it by multiplying with the number of their co-interactions denoted as \(a_{q\mathfrak {q}}\) from \(A_{inf}\) in Eq. (7), and finally get the influence degree \(\gamma _{q\mathfrak {q}}^{(k)}\). As shown in Eq. (8), the embedding of \(i_q\) after the k-th influence propagation is the total of the \((k-1)\)-th outcome and the weighted sum of its first-order neighbors’ embeddings during this propagation.
During the k-th propagation, the embedding of \(u_p\) is affected by users with social relationships, in addition to users with co-interactions or similar semantics, i.e., \(U_{con(p,q)}^{(1)} = U_{con(p,q)}^{1(1)} \cup U_{con(p,q)}^{2(1)} \cup U_{con(p,q)}^{3(1)}\). Therefore in Eq. (9), the semantic similarity between \(u_p\) and \(u_{\mathfrak {p}} \in U_{con(p,q)}^{(1)}\) is amplified by the number of co-interactions \(\mathfrak {y}_{p\mathfrak {p}}\) and the social influence \(\mathfrak {s}_{p\mathfrak {p}}\), where we set \(\mathfrak {s}_{p\mathfrak {p}}\) to \(\lambda \) times the most co-interactions as described in Eq. (10) since friends tend to orient user interests more. \(s_{p\mathfrak {p}}>0\) implies that there is a social relationship between \(u_p\) and \(u_{\mathfrak {p}}\). As described in Eq. (11), the embedding of \(u_p\) after the k-th propagation combines each neighbor’s embedding based on an weight \(\widetilde{\delta }_{p\mathfrak {p}}^{(k)}\) and its own embedding on the \((k-1)\)-th propagation together.
4.4 The Interaction Prediction Layer
The results after K iterations of influence propagation represented by \(e_{u_p}^{r(K)}\) and \(e_{i_q}^{r(K)}\) are supposed as the final embeddings of \(u_p\) and \(i_q\). They fully incorporate the semantics of the KG, social influences amongst users, and the numbers of co-interactions. The inner product of \(e_{u_p}^{r(K)}\) and \(e_{i_q}^{r(K)}\) predicts whether there is an interaction between them. As shown in Eq. (12), this paper applies the gradient descent to the BPR loss function to optimize parameters in \(\varTheta \), including embeddings of all users, items, relationships as well as entities denoted as \(\varTheta _1\) and the perceptrons’ factors labeled as \(\varTheta _2\), i.e., \(\varTheta _1=\{e_{u_p}^f, e_{i_q}^f, e_{\mathfrak {e}_c}^f, e_{r_d}^f \mid u_p\in U, i_q\in I, \mathfrak {e}_c \in \mathcal {E}, r_d\in \mathcal {R}\}\) and \(\varTheta _2=\{[W_i, b_i]_{i=1,2,3,4}\}\). We sample one item \(i_j\) without observed interaction for each observed user-item pair \((u_p,i_q)\) in the training set, contributing to the collection \(\mathcal {O}\). Moreover, the L2 regularization technique is served to avoid overfitting, where \(\eta \) is the related hyper-parameter.
5 Experiments
In this section, we conduct experiments on six datasets including KGs or social networks to evaluate our proposed method and address the three questions: RQ1: Can KIPRec outperform the SOTA KG-based RAs and social network-based ones on real-world datasets ? RQ2: What exactly is the function of each component of KIPRec ? RQ3: How do user-user influence, item-to-item influence and multi-layer user interest affect KIPRec based on a real-world example ?
5.1 Experimental Settings
Dataset Description.
Six real datasets are applied: Last-FM (music), Yelp2018 (business), Movie-Lens20M (film), Book-Crossing (book), Epinions (e-commerce) and Flickr (image). Last-FM, Movie-Lens20M and Book-Crossing are collected from CKAN [19], which contains the interaction history and the KG. Epinions and Flickr are obtained from GraphRec [2] and Diffnet++ [21] separately. KGAT [16] provides the bipartite graph and the KG of Yelp2018. We further extract its social network from the official dataset. We finally divide all users and items into four groups according to the number of their observed interactions, and narrow down all the datasets by randomly picking about 10% from each group. The statistics of all datasets are summarized in Table 1. All the datasets are randomly divided into training (60%), validation (20%) and testing (20%).
Evaluation Metrics. We investigate the performance of the proposed model with the Area Under Curve (AUC) metric in the CTR prediction, and the Recall (Recall@20) as well as Normalized Discounted Cumulative Gain (NDCG@20) metrics in top-K recommendation. From items other than those in the training set, the model is required to recommend 20 items to each user.
Baselines. Seven GNN-based RAs on the KG are chosen, including embedding-based approaches (CKE, MKR, KGAT) and propagation-based methods (RippleNet, KGCN, CKAN and KGIN), and Diffnet and Diffnet++ in the second category are selected. In addition, BPRMF is not dependent on either the KG or the social network. CKE [25] is an embedding-based approach in the co-learning category that integrates the loss functions in the KG embedding and recommendation task into a whole, while MKR [14] is a multi-task learning strategy with the cross &compress units. KGAT [16] proposes a novel GAT-based approach inspired by transR to maintain the adjacency matrix between entities. RippleNet [13] emphasizes description of user interests, on the contrary, KGCN [15] focuses on the exploration of items’ semantics. KGIN [17] explains recommendation actions with intents. In contrast to the KG-based RA mentioned above, CKAN [19] also takes into account items’ first-order CF signals. Diffnet [22] conveys high-order impacts between users on the social network to enhance user embeddings. Diffnet++ [21] additionally weights the contributions of the user’s high-order CF signals and high-order social neighbors.
Parameter Settings. Our KIPRec model is implemented with the Pytorch deep learning framework. To be fair, the embedding size of all nodes and edges is 64, the mini-batch size is 128, and the maximum number of training epochs is 250 for all methods across all datasets. We initialize all parameters with the Xavier initializer and optimize them with the Adam optimizer. We tune the hyper-parameters within given ranges via a grid search. The training phrase is terminated if Recall@20 on the training set does not improve in the subsequent 10 epochs. Each result in this section is the average of five repeated experiments with different random seeds under the best hyper-parameter setup.
5.2 RQ1: Performance Evaluation
We compare KIPRec with its baselines with Recall@20 and NDCG@20 as shown in Table 2 and Table 3, and AUC in Fig. 4. The main experimental results are summarized as follows.
Compared with the KG-based KGIN, Recall@20 and NDCG@20 evaluated on KIPRec are respectively improved by 1.92% and 1.25% on Last-FM, and by 5.64% and 2.86% on Yelp2018. In comparison with the social network-based Diffnet++, the two metrics on KIPRec increases by 10.05% and 12.81% on Last-FM, and by 11.54% and 7.91% on Yelp2018. Side information is reasonably utilized by KIPRec to generate more accurate user and item embeddings. In particular, the gap between KIPRec and Diffnet++ is more noticeable than that between KIPRec and KGIN, proving that the KG provides richer materials than the social network. It is feasible in KIPRec to obtain the preliminary embeddings from the KG. Moreover, BPRMF is the least effective, because it makes absolutely no use of any side information other than the bipartite graph.
On the other hand, on Movie-Lens20M and Book-Crossing including only the KG, KIPRec decreases by 0.03% and 0.27% respectively in terms of Recall@20, and by 4.67% and 1.97% relative to NDCG@20 compared with KGIN. This is because KIPRec incorporates the intention dimension associated with relationships on the KG. Yet, KIPRec achieves the similar goal, slightly less effective, by developing the multi-layer user interests structure. Figure 4 illustrates that CKAN or KIPRec is always the optimal or suboptimal model in the CTR prediction on Last-FM, Yelp2018 and Book-Crossing, since CF signals on the bipartite graph modify embeddings from the KG.

The result of AUC in the CTR prediction scenario
Diffnet++ and KIPRec surpass Diffnet by integrating high-order CF signals and social influence. Recall@20 of KIPRec on Epinions and Flickr increases by 1.59% and 17%, and NDCG@20 is improved by −7.53% and 6.85% compared with Diffnet++. Inter-user and inter-item influences directly enable more accurate embeddings with less noise in KIPRec. In addition, KIPRec promotes embedding learning by broadening influence ranges through random sampling.
5.3 RQ2: Ablation Experiments
We conduct two ablation experiments to estimate two layer’s effects in KIPRec (\(\textrm{KIPRec}_\mathrm{w/o \; Semantic}\) and \(\textrm{KIPRec}_\mathrm{w/o \; Propagation}\)). Their performances have significantly been decreased compared to KIPRec. As shown in Table 4, their performances indicates that both are indispensable. Further, both \(\textrm{KIPRec}_\mathrm{w/o \; DI}\) and \(\textrm{KIPRec}_\mathrm{w/o \; SI}\) outperform the \(\textrm{KIPRec}_\mathrm{w/o \; Semantic}\) on Last-FM and Yelp2018, but they are less effective than \(\textrm{KIPRec}\), which reveals that capturing multi-layer user interests is essential. The effectiveness improvement in \(\textrm{KIPRec}_\mathrm{w/o \; Sample}\) or \(\textrm{KIPRec}_\mathrm{w/o \; Social}\) is significant over \(\textrm{KIPRec}_\mathrm{w/o \; Propagation}\), since RAs cannot adequately capture user interests from semantics without rich interaction history.
In addition, this paper explores the impact of different embedding dimensions on information capture ability through the experiment results in Table 5. It can be seen that KIPRec’s recommendation effect performs best when \(d=64\) on three datasets. The optimal performances on the other three datasets are not particularly better than that of 64 dimensional setting. It is worth mentioning that larger dimensions on the large-scale dataset (Yelp2018) lead to GPU’s usage exceeding the limit.
5.4 RQ3: Case Study
To illustrate the effect of KIPRec’s semantic propagation layer at the attribute level, we select users and items associated with \(u_{268}\) and \(i_{73}\), as shown in Fig. 5.

A real-word example from Yelp2018 related to the semantic propagation layer (The solid line connects a user or item with the attributes that it values the most. Number on the line indicates how much the importance the attribute is placed.)
From the perspectives of whether users or items attach the same level of importance to each attribute and whether their most valued attributes are the same, we find that the semantic similarities to \(i_{73}\) and \(u_{475}\) in descending order are \(i_{229}>i_{503}>i_{81}>i_{74}>i_{75}\) and \(u_{475}>u_{660}>u_{393}>u_{638}\), which is consistent with the statistics in Table 6 and Table 7.
KIPRec aggregates messages from neighbors based on the overall similarity among users or items. The overall similarity is mainly determined by the semantic similarity, followed by co-interactions and social relationships. Thus, compared to \(i_{74}\), \(i_{229}\) has a higher semantic similarity to \(i_{73}\) and thus a higher overall similarity; compared to \(i_{75}\), \(i_{81}\) has a lower number of interactions in common with \(i_{73}\), and thus a lower overall similarity.
Because social influence plays a greater role in user representations, users that have social relationships with \(u_{268}\) are more similar in general to those have no social relationship. Furthermore, \(i_{73}\) and \(u_{268}\) respectively absorb user information from \(i_{503}\) and \(u_{475}\), which are only semantically similar. The number of users’ co-interactions in the testing set is essentially consistent with their overall similarity. The exception to this is that \(u_{660}\) and \(u_{268}\) have the highest overall similarity yet with one common interaction. This is because there are a few interaction records in the dataset for \(u_{660}\).
6 Conclusion
This paper has proposed a RA based on GATs that naturally combines the knowledge graph, the bipartite graph and the social network to enrich user and item embeddings. A multi-layer user interest structure is designed at the attribute and item levels to achieve user embeddings with rich semantics. Besides the similarity from the semantic propagation layer, the inter-user and inter-item influence weights in the influence propagation layer are further acquired based on the bipartite graph and the social network. Multiple graph attention message propagation are performed in the two layers to obtain more precise user and item embeddings. Extensive experiments and comparative analysis on two datasets demonstrate the advantage of the proposed model over the SOTA baselines.
The future work is manifold. It would be interesting to study how to reduce GAT operations’ time and space costs in the semantic propagation layer on large-scale graphs using sample strategies [11, 23]. It is also worth investigating self-supervised methods to generate more accurate recommendations by identifying relationships among the refined item embeddings from the user-item bipartite graph, the item-item co-interaction graph, and the KG.
References
Chen, T., Guo, J., et al.: Graph representation learning for popularity prediction problem: a survey. Discrete Math., Algorithms Appl. 14(7), 2230003 (2022)
Fan, W., Ma, Y., et al.: A graph neural network framework for social recommendations. TKDE 34(5), 2033–2047 (2020)
Gao, C., Wang, X., et al.: Graph neural networks for recommender system. In: WSDM, pp. 1623–1625 (2022)
Guo, Q., Zhuang, F., et al.: A survey on knowledge graph-based recommender systems. TKDE 34(8), 3549–3568 (2020)
He, X., Deng, K., et al.: LightGCN: simplifying and powering graph convolution network for recommendation. In: SIGIR, pp. 639–648 (2020)
Huang, C.: Recent advances in heterogeneous relation learning for recommendation. In: IJCAI, pp. 4442–4449 (2021)
Jiang, W., Sun, Y.: Social-RippleNet: jointly modeling of ripple net and social information for recommendation. Appl. Intell. 53(3), 3472–3487 (2022). https://doi.org/10.1007/s10489-022-03620-2
Li, A., Yang, B.: GSIRec: Learning with graph side information for recommendation. World Wide Web 24(5), 1411–1437 (2021). https://doi.org/10.1007/s11280-021-00910-6
Li, N., Gao, C., et al.: Disentangled modeling of social homophily and influence for social recommendation. TKDE 35(6), 5738–5751 (2022)
Liu, T., Wang, Z., et al.: Recommender systems with heterogeneous side information. In: WWW, pp. 3027–3033 (2019)
Liu, X., Yan, M., et al.: Sampling methods for efficient training of graph convolutional networks: a survey. IEEE/CAA J. Automatica Sinica 9(2), 205–234 (2022)
Rendle, S., Freudenthaler, C., et al.: BPR: bayesian personalized ranking from implicit feedback. In: UAI, pp. 452–461 (2009)
Wang, H., Zhang, F., et al.: RippleNet: propagating user preferences on the knowledge graph for recommender systems. In: CIKM, pp. 417–426 (2018)
Wang, H., Zhang, F., et al.: Multi-task feature learning for knowledge graph enhanced recommendation. In: WWW, pp. 2000–2010 (2019)
Wang, H., Zhao, M., et al.: Knowledge graph convolutional networks for recommender systems. In: WWW, pp. 3307–3313 (2019)
Wang, X., He, X., et al.: KGAT: knowledge graph attention network for recommendation. In: SIGKDD, pp. 950–958 (2019)
Wang, X., Huang, T., et al.: Learning intents behind interactions with knowledge graph for recommendation. In: WWW, pp. 878–887 (2021)
Wang, X., Wang, D., et al.: Explainable reasoning over knowledge graphs for recommendation. In: AAAI, pp. 5329–5336 (2019)
Wang, Z., Lin, G., et al.: CKAN: collaborative knowledge-aware attentive network for recommender systems. In: SIGIR, pp. 219–228 (2020)
Wang, Z., Wang, Z., et al.: Exploring multi-dimension user-item interactions with attentional knowledge graph neural networks for recommendation. IEEE Trans. Big Data, TBD 9(1), 212–226 (2023)
Wu, L., Li, J., et al.: DiffNet++: a neural influence and interest diffusion network for social recommendation. TKDE 34(10), 4753–4766 (2020)
Wu, L., Sun, P., et al.: A neural influence diffusion model for social recommendation. In: SIGIR, pp. 235–244 (2019)
Xu, X., Feng, W., et al.: Sampling methods for efficient training of graph convolutional networks: a survey. In: ICLR (2020)
Yu, J., Yin, H., et al.: Socially-aware self-supervised tri-training for recommendation. In: SIGKDD, pp. 2084–2092 (2021)
Zhang, F., Yuan, N.J., et al.: Collaborative knowledge base embedding for recommender systems. In: SIGKDD, pp. 353–362 (2016)
Zhang, S., Yao, L., et al.: Deep learning based recommender system: a survey and new perspectives. ACM Comput. Surv. 52(1), 1–38 (2019)
Zhu, F., Wang, Y., et al.: Cross-domain recommendation: challenges, progress, and prospects. In: IJCAI, pp. 4721–4728 (2021)
Acknowledgments
We are grateful to the reviewers of this paper for their constructive and insightful comments. The research reported in this paper was partially supported by the National Key R&D Program of China (NO. 2021YFB0300104), and the ANR project AGAPE ANR-18-CE23-0013.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Yang, Y., Jiang, G., Zhang, Y. (2023). Knowledge-Rich Influence Propagation Recommendation Algorithm Based on Graph Attention Networks. In: Yang, X., et al. Advanced Data Mining and Applications. ADMA 2023. Lecture Notes in Computer Science(), vol 14176. Springer, Cham. https://doi.org/10.1007/978-3-031-46661-8_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-46661-8_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-46660-1
Online ISBN: 978-3-031-46661-8
eBook Packages: Computer ScienceComputer Science (R0)