
Abstract
Families of DFAs (FDFAs) have recently been introduced as a new representation of \(\omega \)-regular languages. They target ultimately periodic words, with acceptors revolving around accepting some representation \(u\cdot v^\omega \). Three canonical FDFAs have been suggested, called periodic, syntactic, and recurrent. We propose a fourth one, limit FDFAs, which can be exponentially coarser than periodic FDFAs and are more succinct than syntactic FDFAs, while they are incomparable (and dual to) recurrent FDFAs. We show that limit FDFAs can be easily used to check not only whether \(\omega \)-languages are regular, but also whether they are accepted by deterministic Büchi automata. We also show that canonical forms can be left behind in applications: the limit and recurrent FDFAs can complement each other nicely, and it may be a good way forward to use a combination of both. Using this observation as a starting point, we explore making more efficient use of Myhill-Nerode’s right congruences in aggressively increasing the number of don’t-care cases in order to obtain smaller progress automata. In pursuit of this goal, we gain succinctness, but pay a high price by losing constructiveness.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



1 Introduction
The class of \(\omega \)-regular languages has proven to be an important formalism to model reactive systems and their specifications, and automata over infinite words are the main tool to reason about them. For example, the automata-theoretic approach to verification [24] is the main framework for verifying \(\omega \)-regular specifications. The first type of automata recognizing \(\omega \)-regular languages is nondeterministic Büchi automata [6] (NBAs) where an infinite word is accepted if one of its runs meets the accepting condition for infinitely many times. Since then, other types of acceptance conditions, such as Muller, Rabin, Streett and parity automata [25], have been introduced. All the automata mentioned above are finite automata processing infinite words, widely known as \(\omega \)-automata [25].
The theory of \(\omega \)-regular languages is more involved than that of regular languages. For instance, nondeterministic finite automata (NFAs) can be determinized with a subset construction, while NBAs have to make use of tree structures [21]. This is because of a fundamental difference between these language classes: for a given regular language R, the Myhill-Nerode theorem [18, 19] defines a right congruence (RC) \(\backsim _R\) in which every equivalence class corresponds to a state in the minimal deterministic finite automata (DFA) accepting R. In contrast, there is no similar theorem to define the minimal deterministic \(\omega \)-automata for the full class of \(\omega \)-regular languagesFootnote 1. Schewe proved in [23] that it is NP-complete to find the minimal deterministic \(\omega \)-automaton even given a deterministic \(\omega \)-automaton. Therefore, it seems impossible to easily define a Myhill-Nerode theorem for (minimal) \(\omega \)-automata.
Recently, Angluin, Boker and Fisman [2] proposed families of DFAs (FDFAs) for recognizing \(\omega \)-regular languages, in which every DFA can be defined with respect to a RC defined over a given \(\omega \)-regular language [3]. This tight connection is the theoretical foundation on which the state of the art learning algorithms for \(\omega \)-regular languages [3, 12] using membership and equivalence queries [1] are built. FDFAs are based on well-known properties of \(\omega \)-regular languages [6, 7]: two \(\omega \)-regular languages are equivalent if, and only if, they have the same set of ultimately periodic words. An ultimately periodic word w is an infinite word that consists of first a finite prefix u, followed by an infinite repetition of a finite nonempty word v; it can thus be represented as a decomposition pair (u, v). FDFAs accept infinite words by accepting their decomposition pairs: an FDFA \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^{q}\})\) consists of a leading DFA \(\mathcal {M}\) that processes the finite prefix u, while leaving the acceptance work of v to the progress DFA \(\mathcal {N}^q\), one for each state of \(\mathcal {M}\). To this end, \(\mathcal {M}\) intuitively tracks the Myhill-Nerode’s RCs, and an ultimately periodic word \(u\cdot v^\omega \) is accepted if it has a representation \(x \cdot y^\omega \) such that x and \(x \cdot y\) are in the same congruence class and y is accepted by the progress DFA \(\mathcal {N}^x\). Angluin and Fisman [3] formalized the RCs of three canonical FDFAs, namely periodic [7], syntactic [16] and recurrent [3], and provided a unified learning framework for them.
In this work, we first propose a fourth one, called limit FDFAs (cf. Section 3). We show that limit FDFAs are coarser than syntactic FDFAs. Since syntactic FDFAs can be exponentially more succinct than periodic FDFAs [3], so do our limit FDFAs. We show that limit FDFAs are dual (and thus incomparable in the size) to recurrent FDFAs, due to symmetric treatment for don’t care words. More precisely, the formalization of such FDFA does not care whether or not a progress automaton \(\mathcal {N}^x\) accepts or rejects a word v, unless reading it in \(\mathcal {M}\) produces a self-loop. Recurrent progress DFAs reject all those don’t care words, while limit progress DFAs accept them.
We show that limit FDFAs (families of DFAs that use limit DFAs) have two interesting properties. The first is on conciseness: we show that this change in the treatment of don’t care words not only defines a dual to recurrent FDFAs but also allows us to identify languages accepted by deterministic Büchi automata (DBAs) easily. It is only known that one can identify whether a given \(\omega \)-language is regular by verifying whether the number of states in the three canonical FDFAs is finite. However, if one wishes to identify DBA-recognizable languages with FDFAs, a straight-forward approach is to first translate the input FDFA to an equivalent deterministic Rabin automaton [2] through an intermediate NBA, and then use the deciding algorithm in [10] by checking the transition structure of Rabin automata. However, this approach is exponential in the size of the input FDFA because of the NBA determinization procedure [8, 21, 22]. Our limit FDFAs are, to the best of our knowledge, the first type of FDFAs able to identify the DBA-recognizable languages in polynomial time (cf. Sect. 4).
We note that limit FDFAs also fit nicely into the learning framework introduced in [3], so that they can be used for learning without extra development.
We then discuss how to make more use of don’t care words when defining the RCs of the progress automata, leading to the coarsest congruence relations and therefore the most concise FDFAs, albeit to the expense of losing constructiveness (cf. Sect. 5).
2 Preliminaries
In the whole paper, we fix a finite alphabet \(\varSigma \). A word is a finite or infinite sequence of letters in \(\varSigma \); \(\epsilon \) denotes the empty word. Let \(\varSigma ^*\) and \(\varSigma ^\omega \) denote the set of all finite and infinite words (or \(\omega \)-words), respectively. In particular, we let \(\varSigma ^+= \varSigma ^*\setminus \{\epsilon \}\). A finitary language is a subset of \(\varSigma ^*\); an \(\omega \)-language is a subset of \(\varSigma ^\omega \). Let \(\rho \) be a sequence; we denote by \(\rho {[i]}\) the i-th element of \(\rho \) and by \(\rho {[i..k]}\) the subsequence of \(\rho \) starting at the i-th element and ending at the k-th element (inclusively) when \(i \le k\), and the empty sequence \(\epsilon \) when \(i > k\). Given a finite word u and a word w, we denote by \(u \cdot w\) (uw, for short) the concatenation of u and w. Given a finitary language \(L_{1}\) and a finitary/\(\omega \)-language \(L_{2}\), the concatenation \(L_{1} \cdot L_{2} \) (\(L_{1} L_{2}\), for short) of \(L_{1}\) and \(L_{2}\) is the set \(L_{1} \cdot L_{2} = \{\, uw \mid u \in L_{1}, w \in L_{2} \,\}\) and \(L^{\omega }_{1}\) the infinite concatenation of \(L_{1}\).
Transition System. A (nondeterministic) transition system (TS) is a tuple \(\mathcal {T}= (Q, q_0, \delta )\), where \(Q\) is a finite set of states, \(q_0\in Q\) is the initial state, and \(\delta : Q\times \varSigma \rightarrow 2^{Q}\) is a transition function. We also lift \(\delta \) to sets as \(\delta (S, \sigma ) := \bigcup _{q\in S}\delta (q, \sigma )\). We also extend \(\delta \) to words, by letting \(\delta (S, \epsilon ) = S\) and \(\delta (S, a_{0} a_{1} \cdots a_{k}) = \delta (\delta (S, a_{0}), a_1 \cdots a_{k})\), where we have \(k \ge 1\) and \(a_{i} \in \varSigma \) for \(i \in \{0, \cdots , k\}\).
The underlying graph \(\mathcal {G}_{\mathcal {T}}\) of a TS \(\mathcal {T}\) is a graph \(\langle Q, E\rangle \), where the set of vertices is the set \(Q\) of states in \(\mathcal {T}\) and \((q, q') \in E\) if \(q' \in \delta (q, a)\) for some \(a \in \varSigma \). We call a set \(C \subseteq Q\) a strongly connected component (SCC) of \(\mathcal {T}\) if, for every pair of states \(q, q' \in C\), q and \(q'\) can reach each other in \(\mathcal {G}_{\mathcal {T}}\).
Automata. An automaton on finite words is called a nondeterministic finite automaton (NFA). An NFA \(\mathcal {A}\) is formally defined as a tuple \((\mathcal {T}, F)\), where \(\mathcal {T}\) is a TS and \(F\subseteq Q\) is a set of final states. An automaton on \(\omega \)-words is called a nondeterministic Büchi automaton (NBA). An NBA \(\mathcal {B}\) is represented as a tuple \((\mathcal {T}, \varGamma )\) where \(\mathcal {T}\) is a TS and \(\varGamma \subseteq \{(q, a, q'): q,q'\in Q, a\in \varSigma , q'\in \delta (q,a)\}\) is a set of accepting transitions. An NFA \(\mathcal {A}\) is said to be a deterministic finite automaton (DFA) if, for each \(q \in Q\) and \(a \in \varSigma \), \(|\delta (q, a)| \le 1\). Deterministic Büchi automata (DBAs) are defined similarly and thus \(\varGamma \) is a subset of \( \{(q, a): q\in Q, a \in \varSigma \}\), since the successor \(q'\) is determined by the source state and the input letter.
A run of an NFA \(\mathcal {A}\) on a finite word u of length \(n \ge 0\) is a sequence of states \(\rho = q_{0} q_{1} \cdots q_{n} \in Q^{+}\) such that, for every \(0 \le i < n\), \(q_{i+1} \in \delta (q_{i}, u{[i]})\). We write \(q_{0} {\xrightarrow []{{u}}} q_{n}\) if there is a run from \(q_{0}\) to \(q_{n}\) over u. A finite word \(u \in \varSigma ^*\) is accepted by an NFA \(\mathcal {A}\) if there is a run \(q_{0} \cdots q_{n}\) over u such that \(q_{n} \in F\). Similarly, an \(\omega \)-run of \(\mathcal {A}\) on an \(\omega \)-word w is an infinite sequence of transitions \(\rho = (q_{0}, w{[0]}, q_{1}) (q_1, w{[1]}, q_2)\cdots \) such that, for every \(i \ge 0\), \(q_{i+1} \in \delta (q_{i}, w[i])\). Let \(\inf (\rho )\) be the set of transitions that occur infinitely often in the run \(\rho \). An \(\omega \)-word \(w \in \varSigma ^\omega \) is accepted by an NBA \(\mathcal {A}\) if there exists an \(\omega \)-run \(\rho \) of \(\mathcal {A}\) over w such that \(\inf ({\rho }) \cap \varGamma \ne \emptyset \). The finitary language recognized by an NFA \(\mathcal {A}\), denoted by \(\mathcal {L}_{*}(\mathcal {A})\), is defined as the set of finite words accepted by it. Similarly, we denote by \(\mathcal {L}(\mathcal {A})\) the \(\omega \)-language recognized by an NBA \(\mathcal {A}\), i.e., the set of \(\omega \)-words accepted by \(\mathcal {A}\). NFAs/DFAs accept exactly regular languages while NBAs recognize exactly \(\omega \)-regular languages.
Right Congruences. A right congruence (RC) relation is an equivalence relation \(\backsim \) over \(\varSigma ^*\) such that \(x \backsim y\) implies \(xv \backsim yv\) for all \(v \in \varSigma ^*\). We denote by \(|\backsim |\) the index of \(\backsim \), i.e., the number of equivalence classes of \(\backsim \). A finite RC is a RC with a finite index. We denote by \(\varSigma ^*/_{\backsim }\) the set of equivalence classes of \(\varSigma ^*\) under \(\backsim \). Given \(x \in \varSigma ^*\), we denote by \([x]_{\backsim }\) the equivalence class of \(\backsim \) that x belongs to.
For a given RC \(\backsim \) of a regular language R, the Myhill-Nerode theorem [18, 19] defines a unique minimal DFA D of R, in which each state of D corresponds to an equivalence class defined by \(\backsim \) over \(\varSigma ^*\). Therefore, we can construct a DFA \(\mathcal {D}[\backsim ]\) from \(\backsim \) in a standard way.
Definition 1
([18, 19]). Let \(\backsim \) be a right congruence of finite index. The TS \(\mathcal {T}[\backsim ]\) induced by \(\backsim \) is a tuple \((S, s_{0}, \delta )\) where \(S = \varSigma ^*/_{\backsim }\), \(s_{0} = [\epsilon ]_{\backsim }\), and for each \(u \in \varSigma ^*\) and \(a \in \varSigma \), \(\delta ([u]_{\backsim }, a) = [ua]_{\backsim }\).
For a given regular language R, we can define the RC \(\backsim _{R}\) of R as \(x \backsim _{R} y \text { if, and only if, } \forall v \in \varSigma ^*.\ xv \in R \Longleftrightarrow yv \in R\). Therefore, the minimal DFA for R is the DFA \(\mathcal {D}[\backsim _{R}] = (\mathcal {T}[\backsim _R], F_{\backsim _R})\) by setting final states \(F_{\backsim _R}\) to all equivalence classes \([u]_{\backsim _R}\) such that \(u \in R\).
Ultimately Periodic (UP) Words. A UP-word w is an \(\omega \)-word of the form \(uv^{\omega }\), where \(u \in \varSigma ^*\) and \(v \in \varSigma ^+\). Thus \(w = uv^{\omega }\) can be represented as a pair of finite words (u, v), called a decomposition of w. A UP-word can have multiple decompositions: for instance (u, v), (uv, v), and (u, vv) are all decompositions of \(uv^{\omega }\). For an \(\omega \)-language L, let \(\text {UP}(L) = \{\, uv^{\omega } \in L \mid u \in \varSigma ^*\wedge v \in \varSigma ^+ \,\}\) denote the set of all UP-words in L. The set of UP-words of an \(\omega \)-regular language L can be seen as the fingerprint of L, as stated below.
Theorem 1
([6, 7]). (1) Every non-empty \(\omega \)-regular language L contains at least one UP-word. (2) Let L and \(L'\) be two \(\omega \)-regular languages. Then \(L = L'\) if, and only if, \(\text {UP}(L) = \text {UP}(L')\).
Families of DFAs (FDFAs). Based on Theorem 1, Angluin, Boker, and Fisman [2] introduced the notion of FDFAs to recognize \(\omega \)-regular languages.
Definition 2
([2]). An FDFA is a pair \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^{q}\})\) consisting of a leading DFA \(\mathcal {M}\) and of a progress DFA \(\mathcal {N}^{q}\) for each state q in \(\mathcal {M}\).
Intuitively, the leading DFA \(\mathcal {M}\) of \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^{q}\})\) for L consumes the finite prefix u of a UP-word \(uv^{\omega } \in \text {UP}(L)\), reaching some state q and, for each state q of \(\mathcal {M}\), the progress DFA \(\mathcal {N}^{q}\) accepts the period v of \(uv^{\omega }\). Note that the leading DFA \(\mathcal {M}\) of every FDFA does not make use of final states—contrary to its name, it is really a leading transition system.
Let A be a deterministic automaton with TS \(\mathcal {T}= (Q, q_0, \delta )\) and \(x \in \varSigma ^*\). We denote by A(x) the state \(\delta (q_0, x)\). Each FDFA \(\mathcal {F}\) characterizes a set of UP-words \(\text {UP}(\mathcal {F})\) by following the acceptance condition.
Definition 3 (Acceptance)
Let \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^{q}\})\) be an FDFA and w be a UP-word. A decomposition (u, v) of w is normalized with respect to \(\mathcal {F}\) if \(\mathcal {M}(u) = \mathcal {M}(uv)\). A decomposition (u, v) is accepted by \(\mathcal {F}\) if (u, v) is normalized and we have \(v \in \mathcal {L}_{*}(\mathcal {N}^{q})\) where \(q = \mathcal {M}(u)\). The UP-word w is accepted by \(\mathcal {F}\) if there exists a decomposition (u, v) of w accepted by \(\mathcal {F}\).
Note that the acceptance condition in [2] is defined with respect to the decompositions, while ours applies to UP-words. So, they require the FDFAs to be saturated for recognizing \(\omega \)-regular languages.
Definition 4
(Saturation [2]). Let \(\mathcal {F}\) be an FDFA and w be a UP-word in \(\text {UP}(\mathcal {F})\). We say \(\mathcal {F}\) is saturated if, for all normalized decompositions (u, v) and \((u', v')\) of w, either both (u, v) and \((u', v')\) are accepted by \(\mathcal {F}\), or both are not.
We will see in Sect. 4.1 that under our acceptance definition the saturation property can be relaxed while still accepting the same language.
In the remainder of the paper, we fix an \(\omega \)-language L unless stated otherwise.
3 Limit FDFAs for Recognizing \(\omega \)-Regular Languages
In this section, we will first recall the definitions of three existing canonical FDFAs for \(\omega \)-regular languages, and then introduce our limit FDFAs and compare the four types of FDFAs.
3.1 Limit FDFAs and Other Canonical FDFAs
Recall that, for a given regular language R, by Definition 1, the Myhill-Nerode theorem [18, 19] associates each equivalence class of \(\backsim _R\) with a state of the minimal DFA \(\mathcal {D}[\backsim _R]\) of R. The situation in \(\omega \)-regular languages is, however, more involved [4]. An immediate extension of such RCs for an \(\omega \)-regular language L is the following.
Definition 5 (Leading RC)
For two \(u_1, u_2 \in \varSigma ^*\), \(u_1 \backsim _L u_2\) if, and only if \(\forall w \in \varSigma ^\omega \). \(u_1 w \in L \Longleftrightarrow u_2 w \in L\).
Since we fix an \(\omega \)-language L in the whole paper, we will omit the subscript in \(\backsim _L\) and directly use \(\backsim \) in the remainder of the paper.
Assume that L is an \(\omega \)-regular language. Obviously, the index of \(\backsim \) is finite since it is not larger than the number of states in the minimal deterministic \(\omega \)-automaton accepting L. However, \(\backsim \) is only enough to define the minimal \(\omega \)-automaton for a small subset of \(\omega \)-regular languages; see [4, 15] for details about such classes of languages. For instance, consider the language \(L = (\varSigma ^*\cdot aa)^{\omega }\) over \(\varSigma = \{a, b\}\): clearly, \(|\backsim | = 1\) because L is a suffix language (for all \(u \in \varSigma ^*\), \(w \in L \Longleftrightarrow u \cdot w \in L\)). At the same time, it is easy to see that the minimal deterministic \(\omega \)-automaton needs at least two states to recognize L. Hence, \(\backsim \) alone does not suffice to recognize the full class of \(\omega \)-regular languages.
Nonetheless, based on Theorem 1, we only need to consider the UP-words when uniquely identifying a given \(\omega \)-regular language L with RCs. Calbrix et al. proposed in [7] the use of the regular language \(L_{\$} = \{ u {\$} v: u \in \varSigma ^*, v \in \varSigma ^+, uv^{\omega } \in L\}\) to represent L, where \( {\$} \notin \varSigma \) is a fresh letterFootnote 2. Intuitively, \(L_{\$}\) associates a UP-word w in \(\text {UP}(L)\) by containing every decomposition (u, v) of w in the form of \(u{\$} v\). The FDFA representing \(L_{\$}\) is formally stated as below.
Definition 6
(Periodic FDFAs [7]). The \(\backsim \) is as defined in Definition 5.
Let \([u]_{\backsim }\) be an equivalence class of \(\backsim \). For \(x, y \in \varSigma ^*\), we define periodic RC as: \( x \approx ^{u}_{P} y\) if, and only if, \(\forall v \in \varSigma ^*\), \(u\cdot (x \cdot v)^{\omega } \in L \Longleftrightarrow u\cdot (y\cdot v)^{\omega } \in L\).
The periodic FDFA \(\mathcal {F}_P = (\mathcal {M}, \{\mathcal {N}^{u}_P\})\) of L is defined as follows.
The leading DFA \(\mathcal {M}\) is the tuple \((\mathcal {T}[\backsim ], \emptyset )\). Recall that \(\mathcal {T}[\backsim ]\) is the TS constructed from \(\backsim \) by Definition 1.
The periodic progress DFA \(\mathcal {N}^{u}_P\) of the state \([u]_{\backsim } \in \varSigma ^*/_{\backsim }\) is the tuple \((\mathcal {T}[\approx ^u_P], F_u)\), where \([v]_{\approx ^u_P} \in F_u\) if \(uv^{\omega } \in L\).
One can verify that, for all \(u, x, y, v \in \varSigma ^*\), if \(x \approx ^u_P y\), then \(xv \approx ^u_P y v\). Hence, \(\approx ^u_P\) is a RC. It is also proved in [7] that \(L_{\$}\) is a regular language, so the index of \(\approx ^u_P\) is also finite.
Angluin and Fisman in [3] showed that, for a variant of the family of languages \(L_n\) given by Michel [17], its periodic FDFA has \(\varOmega (n!)\) states, while the syntactic FDFA obtained in [16] only has \(\mathcal {O}(n^2)\) states. The leading DFA of the syntactic FDFAs is exactly the one defined for the periodic FDFA. The two types of FDFAs differ in the definitions of the progress DFAs \(\mathcal {N}^u\) for some \([u]_{\backsim }\). From Definition 6, one can see that \(\mathcal {N}^u_P\) accepts the finite words in \(V_u = \{v \in \varSigma ^+: u \cdot v^{\omega } \in L\}\). The progress DFA \(\mathcal {N}^u_S\) of the syntactic FDFA is not required to accept all words in \(V_u\), but only a subset \(V_{u,v} = \{v \in \varSigma ^+: u\cdot v^{\omega } \in L, u \backsim u \cdot v\}\), over which the leading DFA \(\mathcal {M}\) can take a round trip from \(\mathcal {M}(u)\) back to itself. This minor change makes the syntactic FDFAs of the language family \(L_n\) exponentially more succinct than their periodic counterparts.
Formally, syntactic FDFAs are defined as follows.
Definition 7
(Syntactic FDFA [16]). The \(\backsim \) is as defined in Definition 5.
Let \([u]_{\backsim }\) be an equivalence class of \(\backsim \). For \(x, y \in \varSigma ^*\), we define syntactic RC as: \( x \approx ^u_{S} y\) if and only if \(u \cdot x \backsim u \cdot y\) and for \(\forall v \in \varSigma ^*\), if \(u\cdot x \cdot v \backsim u \), then \( u\cdot (x \cdot v)^{\omega } \in L \Longleftrightarrow u\cdot (y\cdot v)^{\omega } \in L\).
The syntactic FDFA \(\mathcal {F}_S = (\mathcal {M}, \{\mathcal {N}^{u}_S\})\) of L is defined as follows.
The leading DFA \(\mathcal {M}\) is the tuple \((\mathcal {T}[\backsim ], \emptyset )\) as defined in Definition 6.
The syntactic progress DFA \(\mathcal {N}^{u}_S\) of the state \([u]_{\backsim } \in \varSigma ^*/_{\backsim }\) is the tuple \((\mathcal {T}[\approx ^u_S], F_u)\) where \([v]_{\approx ^u_S} \in F_u\) if \(u \cdot v \backsim u\) and \(uv^{\omega } \in L\).
Angluin and Fisman [3] noticed that the syntactic progress RCs are not defined with respect to the regular language \(V_{u,v} = \{v \in \varSigma ^+: u\cdot v^{\omega } \in L, u \backsim u \cdot v\}\) as \(\backsim _{V_{u,v}}\) that is similar to \(\backsim _R\) for a regular language R. They proposed the recurrent progress RC \(\approx ^u_R\) that mimics the RC \(\backsim _{V_{u,v}}\) to obtain a DFA accepting \(V_{u, v}\) as follows.
Definition 8
(Recurrent FDFAs [3]). The \(\backsim \) is as defined in Definition 5.
Let \([u]_{\backsim }\) be an equivalence class of \(\backsim \). For \(x, y \in \varSigma ^*\), we define recurrent RC as: \( x \approx ^u_{R} y\) if and only if \(\forall v \in \varSigma ^*\), \((u \cdot x \cdot v \backsim u \wedge u\cdot (x v)^{\omega } \in L) \Longleftrightarrow (u\cdot y v \backsim u \wedge u\cdot (y \cdot v)^{\omega } \in L)\).
The recurrent FDFA \(\mathcal {F}_R = (\mathcal {M}, \{\mathcal {N}^{u}_R\})\) of L is defined as follows.
The leading DFA \(\mathcal {M}\) is the tuple \((\mathcal {T}[\backsim ], \emptyset )\) as defined in Definition 6.
The recurrent progress DFA \(\mathcal {N}^{u}_R\) of the state \([u]_{\backsim } \in \varSigma ^*/_{\backsim }\) is the tuple \((\mathcal {T}[\approx ^u_R], F_u)\) where \([v]_{\approx ^u_R} \in F_u\) if \(u \cdot v \backsim u\) and \(uv^{\omega } \in L\).
As pointed out in [3], the recurrent FDFAs may not be minimal because, according to Definition 3, FDFAs only care about the normalized decompositions, i.e, whether a word in \(C_u = \{v \in \varSigma ^+: u \cdot v \backsim u\}\) is accepted by the progress DFA \(\mathcal {N}^u_R\). However, there are don’t care words that are not in \(C_u\) and recurrent FDFAs treat them all as rejectingFootnote 3.
Our argument is that the don’t care words are not necessarily rejecting and can also be regarded as accepting. This idea allows the progress DFAs \(\mathcal {N}^u\) to accept the regular language \(\{v \in \varSigma ^+: u \cdot v \backsim u \implies u \cdot v^{\omega } \in L\}\), rather than \(\{v \in \varSigma ^+: u \cdot v \backsim u \wedge u \cdot v^{\omega } \in L\}\). This change allows a translation of limit FDFAs to DBAs with a quadratic blow-up when L is DBA-recognizable language, as shown later in Sect. 4. We formalize this idea as below and define a new type of FDFAs called limit FDFAs.
Definition 9 (Limit FDFAs)
The \(\backsim \) is as defined in Definition 5.
Let \([u]_{\backsim }\) be an equivalence class of \(\backsim \). For \(x,y \in \varSigma ^*\), we define limit RC as: \( x \approx ^{u}_L y\) if and only if \(\forall v \in \varSigma ^*\), \((u \cdot x \cdot v \backsim u \Longrightarrow u\cdot (x \cdot v)^{\omega } \in L) \Longleftrightarrow (u \cdot y\cdot v \backsim u \Longrightarrow u\cdot (y \cdot v)^{\omega } \in L)\).
The limit FDFA \(\mathcal {F}_L = (\mathcal {M}, \{\mathcal {N}^{u}_L\})\) of L is defined as follows.
The leading DFA \(\mathcal {M}\) is the tuple \((\mathcal {T}[\backsim ], \emptyset )\) as defined in Definition 6.
The progress DFA \(\mathcal {N}^{u}_L\) of the state \([u]_{\backsim } \in \varSigma ^*/_{\backsim }\) is the tuple \((\mathcal {T}[\approx ^u_L], F_u)\) where \([v]_{\approx ^u_L} \in F_u\) if \(u \cdot v \backsim u \implies uv^{\omega } \in L\).
We need to show that \(\approx ^u_L\) is a RC. For \(u, x, y , v' \in \varSigma ^*\), if \(x \approx ^u_L y\), we need to prove that \(xv' \approx ^u_L yv'\), i.e., for all \(e \in \varSigma ^*\), \((u \cdot xv' \cdot e \backsim u \implies u \cdot (xv'\cdot e)^{\omega } \in L) \Longleftrightarrow (u \cdot yv' \cdot e \backsim u \implies u \cdot (yv'\cdot e)^{\omega } \in L)\). This follows immediately from the fact that \(x \approx ^u_L y\) by setting \(v = v'\cdot e\) for all \(e\in \varSigma ^*\) in Definition 9.
Let \(L = a^{\omega } + ab^{\omega }\) be a language over \(\varSigma = \{a, b\}\). Three types of FDFAs are depicted in Fig. 1, where the leading DFA \(\mathcal {M}\) is given in the column labeled with “Leading” and the progress DFAs are in the column labeled with “Syntactic”, “Recurrent” and “Limit”. We omit the periodic FDFA here since we will focus more on the other three in this work. Consider the progress DFA \(\mathcal {N}^{aa}_L\): there are only two equivalence classes, namely \([\epsilon ]_{\approx ^{aa}_L}\) and \([a]_{\approx ^{aa}_L}\). We can use \(v = \epsilon \) to distinguish \(\epsilon \) and a word \(x \in \varSigma ^+\) since \(aa \cdot \epsilon \backsim aa \implies aa \cdot (\epsilon \cdot \epsilon )^{\omega } \in L\) does not hold, while \(aa \cdot x \backsim aa \implies aa \cdot (x \cdot \epsilon )^{\omega } \in L\) holds. For all \(x, y \in \varSigma ^+\), \(x \approx ^{aa}_L y\) since both \(aa \cdot x \backsim aa \implies aa \cdot (x \cdot v)^{\omega } \in L\) and \(aa \cdot y \backsim aa \implies aa \cdot (y\cdot v)^{\omega } \in L\) hold for all \(v \in \varSigma ^*\). One can also verify the constructions for the syntactic and recurrent progress DFAs. We can see that the don’t care word b for the class \([aa]_{\backsim }\) are rejecting in both \(\mathcal {N}_S^{aa}\) and \(\mathcal {N}^{aa}_R\), while it is accepted by \(\mathcal {N}^{aa}_L\). Even though b is accepted in \(\mathcal {N}^{aa}_L\), one can observe that (aa, b) (and thus \(aa\cdot b^{\omega }\)) is not accepted by the limit FDFA, according to Definition 3. Indeed, the three types of FDFAs still recognize the same language L.

Three types of FDFAs for \(L = a^{\omega } + ab^{\omega }\). The final states are marked with double lines.
When the index of \(\backsim \) is only one, then \(\epsilon \backsim u\) holds for all \(u \in \varSigma ^*\). Corollary 1 follows immediately.
Corollary 1
Let L be an \(\omega \)-regular language with \(|\backsim | = 1\). Then, periodic, syntactic, recurrent and limit FDFAs coincide.
We show in Lemma 1 that the limit FDFAs are a coarser representation of L than the syntactic FDFAs. Moreover, there is a tight connection between the syntactic FDFAs and limit FDFAs.
Lemma 1
For all \(u, x, y \in \varSigma ^*\),
-
1.
\(x \approx ^u_S y\) if, and only if \(u\cdot x \backsim u \cdot y\) and \(x \approx ^u_L y\).
-
2.
\(|\approx ^u_L| \le |\approx ^u_S| \le |\backsim | \cdot |\approx ^u_L|\); \(|\approx ^u_L| \le |\backsim | \cdot |\approx ^u_P|\).
Proof
-
1.
-
Assume that \(ux \backsim uy\) and \(x \approx ^u_L y\). Since \(x \approx ^u_L y\) holds, then for all \(v \in \varSigma ^*\), \((u x v \backsim u \implies u \cdot (xv)^{\omega } \in L) \Longleftrightarrow (u y v \backsim u \implies u \cdot (yv)^{\omega } \in L)\). Since \(u x \backsim u y\) holds, then \(u \cdot x v \backsim u \Longleftrightarrow u \cdot y v \backsim u\) for all \(v \in \varSigma ^*\). Hence, by Definition 7, if
 (and thus
(and thus  ), it follows that \(x \approx ^u_S y\) by definition of \(\approx ^u_S\); otherwise we have both \(u xv \backsim u\) and \(u yv \backsim u\) hold, and also \(u\cdot (xv)^{\omega } \in L\Longleftrightarrow u\cdot (yv)^{\omega } \in L\), following the definition of \(\approx ^u_L\). It thus follows that \(x \approx _S^u y\).
), it follows that \(x \approx ^u_S y\) by definition of \(\approx ^u_S\); otherwise we have both \(u xv \backsim u\) and \(u yv \backsim u\) hold, and also \(u\cdot (xv)^{\omega } \in L\Longleftrightarrow u\cdot (yv)^{\omega } \in L\), following the definition of \(\approx ^u_L\). It thus follows that \(x \approx _S^u y\). -
Assume that \(x \approx ^u_S y\). First, we have \(ux \backsim u y\) by definition of \(\approx ^u_S\). Since \(u x \backsim u y\) holds, then \(u \cdot x v \backsim u \Longleftrightarrow u \cdot y v \backsim u\) for all \(v \in \varSigma ^*\). Assume by contradiction that \(x \approx ^u_L y\). Then there must exist some \(v \in \varSigma ^*\) such that \(u \cdot x v \backsim u \cdot y v \backsim u\) holds but \(u\cdot (xv)^{\omega } \in L \Longleftrightarrow u\cdot (yv)^{\omega } \in L\) does not hold. By definition of \(\approx ^u_S\), it then follows that \(x \not \approx ^S_u y\), violating our assumption. Hence, both \(ux \backsim uy\) and \(x \approx ^u_L y\) hold.
-
-
2.
As an immediate result of the Item (1), we have that \(|\approx ^u_L| \le |\approx ^u_S| \le |\backsim | \cdot |\approx ^u_L|\). We prove the second claim by showing that, for all \(u, x,y \in \varSigma ^*\), if \(u x \backsim u y\) and \(x \approx ^u_P y\), then \(x \approx ^u_S y\) (and thus \(x \approx ^u_L y\)). Fix a word \(v \in \varSigma ^*\). Since \(ux \backsim uy\) holds, it follows that \(u x \cdot v \backsim u \Longleftrightarrow uy\cdot v \backsim u\). Moreover, we have \(u\cdot (xv)^{\omega } \in L \Longleftrightarrow u\cdot (yv)^{\omega } \in L\) because \(x \approx ^u_P y\) holds. By definition of \(\approx _S^u\), it follows that \(x \approx _S^u y\) holds. Hence, \(x \approx ^u_L y\) holds as well. We then conclude that \(| \approx ^u_L | \le |\backsim | \cdot |\approx ^u_P|\). \(\square \)
 (and thus
(and thus  ), it follows that
), it follows that According to Definition 1, we have \(x \backsim y\) iff \(\mathcal {T}[\backsim ](x) = \mathcal {T}[\backsim ](y)\) for all \(x, y \in \varSigma ^*\). That is, \(\mathcal {M}= (\mathcal {T}[\backsim ], \emptyset )\) is consistent with \(\backsim \), i.e., \(x \backsim y\) iff \(\mathcal {M}(x) = \mathcal {M}(y)\) for all \(x,y\in \varSigma ^*\). Hence, \(u \cdot v \backsim u\) iff \(\mathcal {M}(u) = \mathcal {M}(u \cdot v)\). In the remaining part of the paper, we may therefore mix the use of \(\backsim \) and \(\mathcal {M}\) without distinguishing the two notations.
We are now ready to give our main result of this section.
Theorem 2
Let L be an \(\omega \)-regular language and \(\mathcal {F}_L {=} (\mathcal {M}[\backsim ], \{ \mathcal {N}[\approx _u]\}_{[u]_{\backsim } \in \varSigma ^*/_{\backsim }})\) be the limit FDFA of L. Then (1) \(\mathcal {F}_L\) has a finite number of states, (2) \(\text {UP}(\mathcal {F}_L) = \text {UP}(L)\), and (3) \(\mathcal {F}_L\) is saturated.
Proof
Since the syntactic FDFA \(\mathcal {F}_S\) of L has a finite number of states [16] and \(\mathcal {F}_L\) is a coarser representation than \(\mathcal {F}_S\) (cf. Lemma 1), \(\mathcal {F}_L\) must have finite number of states as well.
To show \(\text {UP}(\mathcal {F}_L) \subseteq \text {UP}(L)\), assume that \(w \in \text {UP}(\mathcal {F}_L)\). By Definition 3, a UP-word w is accepted by \(\mathcal {F}_L\) if there exists a decomposition (u, v) of w such that \(\mathcal {M}(u) = \mathcal {M}(u \cdot v)\) (equivalently, \(u \cdot v \backsim u\)) and \(v \in \mathcal {L}_{*}(\mathcal {N}^{\tilde{u}}_L)\) where \(\tilde{u} = \mathcal {M}(u)\). Here \(\tilde{u}\) is the representative word for the equivalence class \([u]_{\backsim }\). Similarly, let \(\tilde{v} = \mathcal {N}^{\tilde{u}}_L(v)\). By Definition 9, we have \(\tilde{u} \cdot \tilde{v} \backsim \tilde{u}\implies \tilde{u} \cdot \tilde{v}^{\omega } \in L\) holds as \(\tilde{v}\) is a final state of \(\mathcal {N}^{\tilde{u}}_L\). Since \(v \approx ^{\tilde{u}}_L \tilde{v}\) (i.e., \(\mathcal {N}^{\tilde{u}}_L(v) = \mathcal {N}^{\tilde{u}}_L(\tilde{v})\)), \(\tilde{u} \cdot v \backsim \tilde{u}\implies \tilde{u} \cdot v^{\omega } \in L\) holds as well. It follows that \(u \cdot v \backsim u \implies u \cdot v^{\omega } \in L\) since \(u \backsim \tilde{u}\) and \(u \cdot v \backsim \tilde{u} \cdot v\) (equivalently, \(\mathcal {M}(u \cdot v) = \mathcal {M}(\tilde{u} \cdot v)\)). Together with the assumption that \(\mathcal {M}(u \cdot v) = \mathcal {M}(u)\) (i.e., \(u \backsim u \cdot v\)), we then have that \(u \cdot v^{\omega } \in L\) holds. So, \(\text {UP}(\mathcal {F}_L) \subseteq \text {UP}(L)\) also holds.
To show that \(\text {UP}(L) \subseteq \text {UP}(\mathcal {F}_L)\) holds, let \(w \in \text {UP}(L)\). For a UP-word \(w \in L\), we can find a normalized decomposition (u, v) of w such that \(w = u\cdot v^{\omega }\) and \(u \cdot v \backsim u\) (i.e., \(\mathcal {M}(u) = \mathcal {M}(u \cdot v)\)), since the index of \(\backsim \) is finite (cf. [3] for more details). Let \(\tilde{u} = \mathcal {M}(u)\) and \(\tilde{v} = \mathcal {N}^{\tilde{u}}_L(v)\). Our goal is to prove that \(\tilde{v}\) is a final state of \(\mathcal {N}^{\tilde{u}}_L\). Since \(u \backsim \tilde{u}\) and \(u\cdot v^{\omega } \in L\), then \(\tilde{u}\cdot v^{\omega } \in L\) holds. Moreover, \(\tilde{u} \cdot v \backsim \tilde{u}\) holds as well because \(\tilde{u} = \mathcal {M}(\tilde{u}) = \mathcal {M}(u)= \mathcal {M}(\tilde{u} \cdot v) = \mathcal {M}(u \cdot v)\). (Recall that \(\mathcal {M}\) is deterministic.) Hence, \(\tilde{u} \cdot v \backsim \tilde{u} \implies \tilde{u}\cdot v^{\omega } \in L\) holds. Since \(\tilde{v} \approx ^{\tilde{u}}_L v\), it follows that \(\tilde{u} \cdot \tilde{v} \backsim \tilde{u} \implies \tilde{u}\cdot \tilde{v}^{\omega } \in L\) also holds. Hence, \(\tilde{v}\) is a final state. Therefore, (u, v) is accepted by \(\mathcal {F}_L\), i.e., \(w \in \text {UP}(\mathcal {F}_L)\). It follows that \(\text {UP}(L) \subseteq \text {UP}(\mathcal {F}_L)\).
Now we show that \(\mathcal {F}_L\) is saturated. Let w be a UP-word. Let (u, v) and (x, y) be two normalized decompositions of w with respect to \(\mathcal {M}\) (or, equivalently, to \(\backsim \)). Assume that (u, v) is accepted by \(\mathcal {F}_L\). From the proof above, it follows that both \(u\cdot v \backsim u \) and \( u\cdot v^{\omega } \in L\) hold. So, we know that \(u\cdot v^{\omega } = x\cdot y^{\omega } \in L\). Let \(\tilde{x} = \mathcal {M}(x)\) and \(\tilde{y} = \mathcal {N}^{\tilde{x}}_L(y)\). Since (x, y) is a normalized decomposition, it follows that \(x \cdot y \backsim x\). Again, since \(\tilde{x} \backsim x\), \(\tilde{x} \cdot y \backsim \tilde{x}\) and \(\tilde{x} \cdot y^{\omega } \in L\) also hold. Obviously, \(\tilde{x}\cdot y \backsim \tilde{x} \implies \tilde{x} \cdot y^{\omega } \in L\) holds. By the fact that \(y \approx ^{\tilde{x}}_L \tilde{y}\), \(\tilde{x}\cdot \tilde{y} \backsim \tilde{x} \implies \tilde{x} \cdot \tilde{y}^{\omega } \in L\) holds as well. Hence, \(\tilde{y}\) is a final state of \(\mathcal {N}^{\tilde{x}}_L\). In other words, (x, y) is also accepted by \(\mathcal {F}_L\). The proof for the case when (u, v) is not accepted by \(\mathcal {F}_L\) is similar. \(\square \)
3.2 Size Comparison with Other Canonical FDFAs
As aforementioned, Angluin and Fisman in [3] showed that for a variant of the family of languages \(L_n\) given by Michel [17], its periodic FDFA has \(\varOmega (n!)\) states, while the syntactic FDFA only has \(\mathcal {O}(n^2)\) states. Since limit FDFAs are smaller than syntactic FDFAs, it immediately follows that:
Corollary 2
There exists a family of languages \(L_n\) such that its periodic FDFA has \(\varOmega (n!)\) states, while the limit FDFA only has \(\mathcal {O}(n^2)\) states.
Now we consider the size comparison between limit and recurrent FDFAs. Consider again the limit and recurrent FDFAs of the language \(L = a^{\omega } + ab^{\omega }\) in Fig. 1: one can see that limit FDFA and recurrent FDFA have the same number of states, even though with different progress DFAs. In fact, it is easy to see that limit FDFAs and recurrent FDFAs are incomparable regarding the their number of states, even when only the \(\omega \)-regular languages recognized by weak DBAs are considered. A weak DBA (wDBA) is a DBA in which each SCC contains either all accepting transitions or non-accepting transitions.
Lemma 2
If L is a wDBA-recognizable language, then its limit FDFA and its recurrent FDFA have incomparable size.
Proof
We fix \(u, x, y \in \varSigma ^*\) in the proof. Since L is recognized by a wDBA, the TS \(\mathcal {T}[\backsim ]\) of the leading DFA \(\mathcal {M}\) is isomorphic to the minimal wDBA recognizing L [15]. Therefore, a state \([u]_{\backsim }\) of \(\mathcal {M}\) is either transient, in a rejecting SCC, or in an accepting SCC. We consider these three cases.
-
Assume that \([u]_{\backsim }\) is a transient SCC/state. Then for all \(v \in \varSigma ^*\),
 and
and 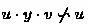 .
.By the definitions of \(\approx ^u_R\) and \(\approx ^u_L\), there are a non-final class \([\epsilon ]_{\approx ^u_L}\) and possibly a sink final class \([\sigma ]_{\approx ^u_L}\) for \(\approx ^u_L\) where \(\sigma \in \varSigma \), while there is a non-final class \([\epsilon ]_{\approx ^u_R}\) for \(\approx ^u_R\). Hence, \( x \approx ^u_L y\) implies \(x \approx ^u_R y\).
-
Assume that \([u]_{\backsim }\) is in a rejecting SCC. Obviously, for all \(v \in \varSigma ^*\), we have that \(u \cdot x \cdot v \backsim u \implies u\cdot (x\cdot v)^{\omega } \notin L\) and \(u \cdot y \cdot v \backsim u \implies u\cdot (y \cdot v)^{\omega } \notin L\). Therefore, there is only one equivalence class \([\epsilon ]_{\approx ^u_R}\) for \(\approx ^u_R\). It follows that \( x \approx ^u_L y\) implies \(x \approx ^u_R y\).
-
Assume that \([u]_{\backsim }\) is in an accepting SCC. Clearly, for all \(v \in \varSigma ^*\), we have that both \(u \cdot x \cdot v \backsim u \implies u\cdot (x\cdot v)^{\omega } \in L\) and \(u \cdot y \cdot v \backsim u \implies u\cdot (y\cdot v)^{\omega } \in L\) hold. That is, we have either \(u \cdot x \cdot v \backsim u \wedge u\cdot (x\cdot v)^{\omega } \in L\) hold, or
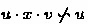 . If \(x \approx ^u_R y\) holds, it immediately follows that \((u \cdot x \cdot v \backsim u \implies u\cdot (x\cdot v)^{\omega } \in L) \Longleftrightarrow (u \cdot y \cdot v \backsim u \implies u\cdot (y\cdot v)^{\omega } \in L )\) holds. Hence, \(x \approx ^u_R y\) implies \(x \approx ^u_L y\).
. If \(x \approx ^u_R y\) holds, it immediately follows that \((u \cdot x \cdot v \backsim u \implies u\cdot (x\cdot v)^{\omega } \in L) \Longleftrightarrow (u \cdot y \cdot v \backsim u \implies u\cdot (y\cdot v)^{\omega } \in L )\) holds. Hence, \(x \approx ^u_R y\) implies \(x \approx ^u_L y\).
 and
and 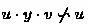 .
.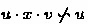 . If
. If Based on this argument, it is easy to find a language L such that its limit FDFA is more succinct than its recurrent FDFA and vice versa, depending on the size comparison between rejecting SCCs and accepting SCCs. Therefore, the lemma follows. \(\square \)
Lemma 2 reveals that limit FDFAs and recurrent FDFAs are incomparable in size. Nonetheless, we still provide a family of languages \(L_n\) in Lemma 3 such that the recurrent FDFA has \(\varTheta (n^2)\) states, while its limit FDFA only has \(\varTheta (n)\) states. One can, of course, obtain the opposite result by complementing \(L_n\). Notably, Lemma 3 also gives a matching lower bound for the size comparison between syntactic FDFAs and limit FDFAs, since syntactic FDFAs can be quadratically larger than their limit FDFA counterparts, as stated in Lemma 1. The language which witnesses this lower bound is given as its DBA \(\mathcal {B}\) depicted in Fig. 2. We refer to [13, Appendix A] for detailed proof.

The \(\omega \)-regular language \(L_n\) represented with a DBA \(\mathcal {B}\). The dashed arrows are \(\varGamma \)-transitions and \(*\)-transitions represent the missing transitions.
Lemma 3
Let \(\varSigma _n = \{0, 1,\cdots , n\}\). There exists an \(\omega \)-regular language \(L_n\) over \(\varSigma _n\) such that its limit FDFA has \(\varTheta (n)\) states, while both its syntactic and recurrent FDFAs have \(\varTheta ({n^2})\) states.
Finally, it is time to derive yet another “Myhill-Nerode" theorem for \(\omega \)-regular languages, as stated in Theorem 3. This result follows immediately from Lemma 1 and a similar theorem about syntactic FDFAs [16].
Theorem 3
Let \(\mathcal {F}_L\) be the limit FDFA of an \(\omega \)-language L. Then L is regular if, and only if \(\mathcal {F}_L\) has finite number of states.
For identifying whether L is DBA-recognizable with FDFAs, a straight forward way as mentioned in the introduction is to go through determinization, which is, however, exponential in the size of the input FDFA. We show in Sect. 4 that there is a polynomial-time algorithm using our limit FDFAs.
4 Limit FDFAs for Identifying DBA-Recognizable Languages
Given an \(\omega \)-regular language L, we show in this section how to use the limit FDFA of L to check whether L is DBA-recognizable in polynomial time. To this end, we will first introduce how the limit FDFA of L looks like in Sect. 4.1 and then introduce the deciding algorithm in Sect. 4.2.
4.1 Limit FDFA for DBA-Recognizable Languages
Bohn and Löding [5] construct a type of family of DFAs \(\mathcal {F}_{BL}\) from a set \(S^+\) of positive samples and a set \(S^-\) of negative samples, where the progress DFA accepts exactly the language \(V_u = \{x \in \varSigma ^+: \forall v \in \varSigma ^*.\ \text {if } u\cdot xv \backsim u, \text { then } u \cdot (xv)^{\omega } \in L\}\)Footnote 4. When the samples \(S^+\) and \(S^-\) uniquely characterize a DBA-recognizable language L, \(\mathcal {F}_{BL}\) recognizes exactly L.
The progress DFA \(\mathcal {N}^u_L\) of our limit FDFA \(\mathcal {F}_L\) of L usually accepts more words than \(V_u\). Nonetheless, we can still find one final equivalence class that is exactly the set \(V_u\), as stated in Lemma 4.
Lemma 4
Let L be a DBA-recognizable language and \(\mathcal {F}_L {=} (\mathcal {M}, \{\mathcal {N}^u_L\}_{[u]_{\backsim }\in \varSigma ^*/_{\backsim }})\) be the limit FDFA of L. Then, for each progress DFA \(\mathcal {N}^u_L\) with \(\mathcal {L}_{*}(\mathcal {N}^u_L) \ne \emptyset \), there must exist a final state \(\tilde{x} \in F_{u}\) such that \([\tilde{x}]_{\approx ^u_L} = \{ x \in \varSigma ^+: \forall v \in \varSigma ^*.\ u \cdot (x \cdot v) \backsim u \implies u\cdot (x\cdot v)^{\omega } \in L\}\).
Proof
In [5], it is shown that for each equivalence class \([u]_{\backsim }\) of \(\backsim \), there exists a regular language \(V_u = \{x \in \varSigma ^+: \forall v \in \varSigma ^*.\ \text {if } u\cdot xv \backsim u, \text { then } u \cdot (xv)^{\omega } \in L\}\). We have also provided the proof of the existence of \(V_u\) in [13, Appendix C], adapted to our notations. The intuition of \(V_u\) is the following. Let \(\mathcal {B}= (\varSigma , Q, \iota , \delta , \varGamma )\) be a DBA accepting L. Then, \([u]_{\backsim }\) corresponds to a set of states \(S = \{q \in Q: q = \delta (\iota , u'), u' \in [u]_{\backsim }\}\) in \(\mathcal {B}\). For each \(q \in S\), we can easily create a regular language \(V_q\) such that \(x \in V_q\) iff over the word x, \(\mathcal {B}^q\) (the DBA derived from \(\mathcal {B}\) by setting q its initial state) visits an accepting transition, \(\mathcal {B}^q\) goes to an SCC that cannot go back to q, or \(\mathcal {B}^q\) goes to a state that cannot go back to q unless visiting an accepting transition. Then, \(V_u = \cap _{q \in S} V_q\).
Now we show that \(V_u\) is an equivalence class of \(\approx ^u_L\) as follows. On one hand, for every two different words \(x_1, x_2 \in V_u\), we have that \(x_1 \approx ^u_L x_2\), which is obvious by the definition of \(V_u\). On the other hand, it is easy to see that \(x' \not \approx ^u_L x\) for all \(x' \notin V_u\) and \(x \in V_u\) because there exists some \(v \in \varSigma ^*\) such that \(u \cdot x' \cdot v \backsim u\) but \(u\cdot (x' \cdot v)^{\omega } \notin L\). Hence, \(V_u\) is indeed an equivalence class of \(\approx ^u_L\). Obviously, \(V_u \subseteq \mathcal {L}_{*}(\mathcal {N}^u_L)\), as we can let \(v = \epsilon \), so for every word \(x \in V_u\), we have that \(u \cdot x \backsim u \implies u \cdot x^{\omega } \in L\). Let \(\tilde{x} = \mathcal {N}^u_L(x)\) for a word \(x \in V_u\). It follows that \(\tilde{x}\) is a final state of \(\mathcal {N}^u_L\) and we have \([\tilde{x}]_{\approx ^u_L} = V_u\). This completes the proof. \(\square \)
By Lemma 4, we can define a variant of limit FDFAs for only DBAs with less number of final states. This helps to reduce the complexity when translating FDFAs to NBAs [2, 7, 12]. Let n be the number of states in the leading DFA \(\mathcal {M}\) and k be the number of states in the largest progress DFA. Then the resultant NBA from an FDFA has \(\mathcal {O}(n^2k^3)\) states [2, 7, 12]. However, if the input FDFA is \(\mathcal {F}_B\) as in Definition 10, the complexity of the translation will be \(\mathcal {O}(n^2k^2)\), as there is at most one final state, rather than k final states, in each progress DFA.
Definition 10 (Limit FDFAs for DBAs)
The limit FDFA \(\mathcal {F}_B\! =\! (\mathcal {M}, \{\mathcal {N}^{u}_B\})\) of L is defined as follows.
The transition systems of \(\mathcal {M}\) and \(\mathcal {N}^u_B\) for each \([u]_{\backsim } \in \varSigma ^*/_{\backsim }\) are exactly the same as in Definition 9.
The set of final states \(F_{u}\) contains the equivalence classes \([x]_{\approx ^u_L}\) such that, for all \(v \in \varSigma ^*\), \(u \cdot xv \backsim u \Longrightarrow u\cdot (xv)^{\omega } \in L\) holds.
The change to the definition of final states would not affect the language that the limit FDFAs recognize, but only their saturation properties. We say an FDFA \(\mathcal {F}\) is almost saturated if, for all \(u, v \in \varSigma ^*\), we have that if (u, v) is accepted by \(\mathcal {F}\), then \((u, v^k)\) is accepted by \(\mathcal {F}\) for all \(k \ge 1\). According to [12], if \(\mathcal {F}\) is almost saturated, then the translation algorithm from FDFAs to NBAs in [2, 7, 12] still applies (cf. [13, Appendix B] about details of the NBA construction).
Theorem 4
Let L be a DBA-recognizable language and \(\mathcal {F}_B\) be the limit FDFA induced by Definition 10. Then (1) \(\text {UP}(\mathcal {F}_B) = \text {UP}(L)\) and (2) \(\mathcal {F}_B\) is almost saturated but not necessarily saturated.
Proof
The proof for \(\text {UP}(\mathcal {F}_B) \subseteq \text {UP}(L)\) is trivial, as the final states defined in Definition 10 must also be final in Definition 9. The other direction can be proved based on Lemma 4. Let \(w \in \text {UP}(L)\) and \(\mathcal {B}= (Q, \varSigma , \iota , \delta , \varGamma )\) be a DBA accepting L. Let \(\rho \) be the run of \(\mathcal {B}\) over w. We can find a decomposition (u, v) of w such that there exists a state q with \(q = \delta (\iota , u) = \delta (\iota , u \cdot v)\) and \((q, v[0]) \in \varGamma \). As in the proof of Lemma 4, we are able to construct the regular language \(V_u = \{x \in \varSigma ^+: \forall y \in \varSigma ^*, u\cdot x \cdot y \backsim u\implies u \cdot (x\cdot y)^{\omega } \in L\}\). We let \(S = \{p \in Q: \mathcal {L}(\mathcal {B}^q) = \mathcal {L}(\mathcal {B}^p)\}\). For every state \(p \in S\), we have that \(v^{\omega } \in \mathcal {L}(\mathcal {B}^p)\). For each \(p \in S\), we select an integer \(k_p > 0\) such that the finite run \(p \xrightarrow {v^{k_p}} \delta (p, v^{k_p})\) visits some accepting transition. Then we let \(k = \max _{p \in S} k_p\). By definition of \(V_u\), it follows that \(v^{k} \in V_u\). That is, \(V_u\) is not empty. According to Lemma 4, we have a final equivalence class \([x]_{\approx ^u_L} = V_u\) with \(v^k \in [x]_{\approx ^u_L}\). Moreover, \(u \cdot v^k \backsim u\) since \(q = \delta (\iota , u) = \delta (q, v)\). Hence, \((u, v^k)\) is accepted by \(\mathcal {F}_B\), i.e., \(w \in \text {UP}(\mathcal {F}_B)\). It follows that \(\text {UP}(\mathcal {F}_B) = \text {UP}(L)\).
Now we prove that \(\mathcal {F}_B = (\mathcal {M}, \{\mathcal {N}^u_B\})\) is not necessarily saturated. Let \(L = (\varSigma ^*\cdot aa)^{\omega }\). Obviously, L is DBA recognizable, and \(\backsim \) has only one equivalence class, \([\epsilon ]_{\backsim }\). Let \( w = a^{\omega } \in \text {UP}(L)\). Let \((u= \epsilon , v = a)\) be a normalized decomposition of w with respect to \(\backsim \) (thus, \(\mathcal {M}\)). We can see that there exists a finite word x (e.g., \(x=b\) is such a word) such that \( \epsilon \cdot a \cdot x \backsim \epsilon \) and \(\epsilon \cdot (a \cdot x)^{\omega } \notin L\). Thus, \((\epsilon , a)\) will not be accepted by \(\mathcal {F}_B\). Hence \(\mathcal {F}_B\) is not saturated. Nonetheless, it is easy to verify that \(\mathcal {F}_B\) is almost saturated. Assume that (u, v) is accepted by \(\mathcal {F}_B\). Let \(\tilde{u} = \mathcal {M}(u)\) and \(\tilde{v} = \mathcal {N}^{\tilde{u}}_B(v)\). Since \(\tilde{v}\) is the final state, then, according to Definition 10, we have for all \(e \in \varSigma ^*\) that \(\tilde{u} \cdot \tilde{v} e \backsim \tilde{u} \implies \tilde{u} \cdot (\tilde{v} e)^{\omega } \in L\). Since \(v \approx ^u_L \tilde{v}\), \(\tilde{u} \cdot v e \backsim \tilde{u} \implies \tilde{u} \cdot (v e)^{\omega } \in L\) also holds for all \(e \in \varSigma ^*\). Let \(e = v^k\cdot e'\) where \(e' \in \varSigma ^*, k \ge 0\). It follows that \(\tilde{u} \cdot v^k e' \backsim \tilde{u} \implies \tilde{u} \cdot (v^k e')^{\omega } \in L\) holds for \(k \ge 1\) as well. Therefore, for all \(e' \in \varSigma ^*, k \ge 1\), \((\tilde{u} \cdot \tilde{v} e' \backsim \tilde{u} \implies \tilde{u} \cdot (\tilde{v} e')^{\omega } \in L ) \Longleftrightarrow (\tilde{u} \cdot v^k e' \backsim \tilde{u} \implies \tilde{u} \cdot (v^k e')^{\omega } \in L )\) holds. In other words, \(\tilde{v} \approx ^{\tilde{u}}_L v^k\) for all \(k \ge 1\). Together with that \(u v^k\backsim u\), \((u, v^k)\) is accepted by \(\mathcal {F}_B\) for all \(k \ge 1\). Hence, \(\mathcal {F}_B\) is almost saturated. \(\square \)
4.2 Deciding DBA-Recognizable Languages
We show next how to identify whether a language L is DBA-recognizable with our limit FDFA \(\mathcal {F}_L\). Our decision procedure relies on the translation of FDFAs to NBAs/DBAs. In the following, we let n be the number of states in the leading DFA \(\mathcal {M}\) and k be the number of states in the largest progress DFA. We first give some previous results below.
Lemma 5
([12, Lemma 6]). Let \(\mathcal {F}\) be an (almost) saturated FDFA of L. Then one can construct an NBA \(\mathcal {A}\) with \(\mathcal {O}(n^2k^3)\) states such that \(\mathcal {L}(\mathcal {A}) = L\).
Now we consider the translation from FDFA to DBAs. By Lemma 4, there is a final equivalence class \([x]_{\approx ^u_L}\) that is a co-safety language in the limit FDFA of L. Co-safety regular languages are regular languages \(R \subseteq \varSigma ^*\) such that \(R \cdot \varSigma ^*= R\). It is easy to verify that if \(x' \in [x]_{\approx ^u_L}\), then \(x'v\in [x]_{\approx ^u_L}\) for all \(v\in \varSigma ^*\), based on the definition of \(\approx ^u_L\). So, \([x]_{\approx ^u_L}\) is a co-safety language. The DFAs accepting co-safety languages usually have a sink final state f (such that f transitions to itself over all letters in \(\varSigma \)). We therefore have the following.
Corollary 3
If L is DBA-recognizable then every progress DFA \(\mathcal {N}^u_L\) of the limit FDFA \(\mathcal {F}_L\) of L either has a sink final state, or no final state at all.
Our limit FDFA \(\mathcal {F}_B\) of L, as constructed in Definition 10, accepts the same co-safety languages in the progress DFAs as the FDFA obtained in [5], although they may have different transition systems. Nonetheless, we show that their DBA construction still works on \(\mathcal {F}_B\). To make the construction more general, we assume an FDFA \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^q\}_{q \in Q})\) where \(\mathcal {M}= (Q, \varSigma , \iota , \delta )\) and, for each \(q \in Q\), we have \(\mathcal {N}^q = (Q_q, \varSigma ,\iota _{q}, \delta _q, F_q)\).
Definition 11
([5]). Let \(\mathcal {F}= (\mathcal {M}, \{ \mathcal {N}^q\}_{q \in Q})\) be an FDFA. Let \(\mathcal {T}[\mathcal {F}]\) be the TS constructed from \(\mathcal {F}\) defined as the tuple \(\mathcal {T}[\mathcal {F}] = (Q_{\mathcal {T}}, \varSigma , \iota _{\mathcal {T}}, \delta _{\mathcal {T}})\) and \(\varGamma \subseteq \{(q, \sigma ): q \in Q_{\mathcal {T}}, \sigma \in \varSigma \}\) be a set of transitions where
-
\(Q_{\mathcal {T}} := Q\times \bigcup _{q\in Q} Q_q\);
-
\(\iota _{\mathcal {T}} := (\iota , \iota _{\iota })\);
-
For a state \((m, q) \in Q_{\mathcal {T}}\) and \(\sigma \in \varSigma \), let \(q' = \delta _{\widetilde{m}}(q, \sigma )\) where \(\mathcal {N}^{\widetilde{m}}\) is the progress DFA that q belongs to and let \(m' = \delta (m, \sigma )\). Then
$$\begin{aligned} \delta ((m, q), \sigma ) = {\left\{ \begin{array}{ll} (m', q') &{} \text {if } q' \notin F_{\widetilde{m}}\\ (m', \iota _{m'}) &{} \text {if } q' \in F_{\widetilde{m}} \end{array}\right. } \end{aligned}$$ -
\(((m, q), \sigma ) \in \varGamma \) if \(q' \in F_{\widetilde{m}}\)
Lemma 6
If \(\mathcal {F}\) is an FDFA with only sink final states. Let \(\mathcal {B}[\mathcal {F}] = (\mathcal {T}[\mathcal {F}], \varGamma )\) as given in Definition 11. Then, \(\text {UP}(\mathcal {L}(\mathcal {B}[\mathcal {F}])) \subseteq \text {UP}(\mathcal {F})\).
Proof
Let \(w \in \text {UP}(\mathcal {L}(\mathcal {B}[\mathcal {F}]))\) and \(\rho \) be its corresponding accepting run. Since w is a UP-word and \(\mathcal {B}[\mathcal {F}]\) is a DBA of finite states, then we must be able to find a decomposition (u, v) of w such that \((m, \iota _m) = \mathcal {B}[\mathcal {F}](u) = \mathcal {B}[\mathcal {F}](u \cdot v)\), where \(\rho \) will visit a \(\varGamma \)-transition whose destination is \((m, \iota _m)\) for infinitely many times. It is easy to see that \(\mathcal {M}(u \cdot v) =\mathcal {M}( u)\) since \(\mathcal {B}[\mathcal {F}](u) = \mathcal {B}[\mathcal {F}](u \cdot v)\). Moreover, we can show there must be a prefix of v, say \(v'\), such that \(v' \in \mathcal {L}_{*}(\mathcal {N}^m)\). Since \(\mathcal {L}_{*}(\mathcal {N}^m)\) is co-safety, we have that \(v \in \mathcal {L}_{*}(\mathcal {N}^m)\). Thus, (u, v) is accepted by \(\mathcal {F}\). By Definition 3, \(w \in \text {UP}(\mathcal {F})\). Therefore, \(\text {UP}(\mathcal {L}(\mathcal {B}[\mathcal {F}])) \subseteq \text {UP}(\mathcal {F})\). \(\square \)
By Corollary 3, \(\mathcal {F}_B\) has only sink final states; so, we have that \(\text {UP}(\mathcal {L}(\mathcal {B}[\mathcal {F}_B])) \subseteq \text {UP}(\mathcal {F}_B)\). However, Corollary 3 is only a necessary condition for L being DBA-recognizable, as explained below. Let L be an \(\omega \)-regular language over \(\varSigma = \{1, 2, 3, 4\}\) such that a word \(w \in L\) iff the maximal number that occurs infinitely often in w is even. Clearly, L has one equivalence class \([\epsilon ]_{\backsim }\) for \(\backsim \). The limit FDFA \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^{\epsilon }_L\})\) of L is depicted in Fig. 3. We can observe that the equivalence class \([4]_{\approx ^{\epsilon }_L}\) corresponds to a co-safety language. Hence, the progress DFA \(\mathcal {N}^{\epsilon }_L\) has a sink final state. However, L is not DBA-recognizable. If we ignore the final equivalence class \([2]_{\approx ^{\epsilon }_L}\) and obtain the variant limit FDFA \(\mathcal {F}_B\) as given in Definition 10, then we have \(\text {UP}(\mathcal {F}_B) \ne \text {UP}(L)\) since the \(\omega \)-word \(2^{\omega }\) is missing. But then, by Theorem 4, this change would not lose words in L if L is DBA-recognisable, leading to contradiction. Therefore, L is shown to be not DBA-recognizable. So the key of the decision algorithm here is to check whether ignoring other final states will retain the language. With Lemma 7, we guarantee that \(\mathcal {B}[\mathcal {F}_B]\) accepts exactly L if L is DBA-recognizable.

An example limit FDFA \(\mathcal {F}= (\mathcal {M}, \{\mathcal {N}^{\epsilon }_L\})\)
Lemma 7
Let L be a DBA-recognizable language. Let \(\mathcal {F}_B\) be the limit FDFA L, as constructed in Definition 10. Let \(\mathcal {B}[\mathcal {F}_B] = (\mathcal {T}[\mathcal {F}_B], \varGamma )\), where \(\mathcal {T}[\mathcal {F}_B]\) and \(\varGamma \) are the TS and set of transitions, respectively, defined in Definition 11 from \(\mathcal {F}_B\). Then \(\text {UP}(\mathcal {F}_B) = \text {UP}(L) \subseteq \text {UP}(\mathcal {L}(\mathcal {B}[\mathcal {F}_B])) \).
Proof
We first assume for contradiction that some \(w \in L\) is rejected by \(\mathcal {B}[\mathcal {F}_B]\). For this, we consider the run \(\rho = (q_0,w[0],q_1)(q_1,w[1],q_2)\ldots \) of \(\mathcal {B}[\mathcal {F}_B]\) on w. Let \(i \in \omega \) be such that \((q_{i-1},w[i-1],q_i)\) is the last accepting transition in \(\rho \), and \(i=0\) if there is no accepting transition at all in \(\rho \). We also set \(u=w[0\cdots i-1]\) and \(w' = w[i\cdots ]\). By Definition 11, this ensures that \(\mathcal {B}[\mathcal {F}_B]\) is in state \(([u]_{\backsim },\iota _{[u]_{\backsim }})\) after reading u and will not see accepting transitions (or leave \(\mathcal N^{[u]_{\backsim }}_B\)) while reading the tail \(w'\).
Let \(\mathcal D = (Q',\varSigma ,\iota ',\delta ',\varGamma ')\) be a DBA that recognizes L and has only reachable states. As \(\mathcal D\) recognizes L, it has the same right congruences as L; by slight abuse of notation, we refer to the states in \(Q'\) that are language equivalent to the state reachable after reading u by \([u]_{\backsim }\) and note that \(\mathcal D\) is in some state of \([u]_{\backsim }\) after (and only after) reading a word \(u' \backsim u\).
As \(u\cdot w'\), and therefore \(u' \cdot w'\) for all \(u' \backsim u\), are in L, they are accepted by \(\mathcal D\), which in particular means that, for all \(q \in [u]_{\backsim }\), there is an \(i_{q}\) such that there is an accepting transition in the first \(i_q\) steps of the run of \(\mathcal {D}^{q}\) (the DBA obtained from \(\mathcal {D}\) by setting the initial state to q) on \(w'\). Let \(i_+\) be maximal among them and \(v=w[i \cdots i+i_+]\). Then, for \(u' \backsim u\) and any word \(u' v v'\), we either have  , or \(u' v v' \backsim u\) and \(u' \cdot (v v')^\omega \in L\). (The latter is because v is constructed such that a run of \(\mathcal D\) on this word will see an accepting transition while reading each v, and thus infinitely many times.) Thus, \(\mathcal N^{[u]_{\backsim }}_B\) will accept any word that starts with v, and therefore be in a final sink after having read v.
, or \(u' v v' \backsim u\) and \(u' \cdot (v v')^\omega \in L\). (The latter is because v is constructed such that a run of \(\mathcal D\) on this word will see an accepting transition while reading each v, and thus infinitely many times.) Thus, \(\mathcal N^{[u]_{\backsim }}_B\) will accept any word that starts with v, and therefore be in a final sink after having read v.
But then \(\mathcal {B}[\mathcal {F}_B]\) will see another accepting transition after reading v (at the latest after having read uv), which closes the contradiction and completes the proof. \(\square \)
So, our decision algorithm works as follows. Assume that we are given the limit FDFA \(\mathcal {F}_L = (\mathcal {M}, \{\mathcal {N}^q_L\})\) of L.
-
1.
We first check whether there is a progress DFA \(\mathcal {N}^q_L\) such that there are final states but without the sink final state. If it is the case, we terminate and return “NO”.
-
2.
Otherwise, we obtain the FDFA \(\mathcal {F}_B\) by keeping the sink final state as the sole final state in each progress DFA (cf. Definition 10). Let \(\mathcal {A}= \texttt {NBA}(\mathcal {F}_L)\) be the NBA constructed from \(\mathcal {F}_L\) (cf. Lemma 5) and \(\mathcal {B}= \texttt {DBA}(\mathcal {F}_B)\) be the DBA constructed from \(\mathcal {F}_B\) (cf. Definition 11). Obviously, we have that \(\text {UP}(\mathcal {L}(\mathcal {A})) = \text {UP}(L)\) and \(\text {UP}(\mathcal {L}(\mathcal {B})) \subseteq \text {UP}(\mathcal {F}_B) = \text {UP}(L)\).
-
3.
Then we check whether \(\mathcal {L}(\mathcal {A}) \subseteq \mathcal {L}(\mathcal {B})\) holds. If so, we return “YES”, and otherwise “NO”.
Now we are ready to give the main result of this section.
Theorem 5
Deciding whether L is DBA-recognizable can be done in time polynomial in the size of the limit FDFA of L.
Proof
We first prove our decision algorithm is correct. If the algorithm returns “YES”, clearly, we have \(\mathcal {L}(\mathcal {A}) \subseteq \mathcal {L}(\mathcal {B})\). It immediately follows that \(\text {UP}(L) = \text {UP}(\mathcal {L}(\mathcal {A})) \subseteq \text {UP}(\mathcal {L}(\mathcal {B})) \subseteq \text {UP}( \mathcal {F}_B)\subseteq \text {UP}(\mathcal {F}_L) = \text {UP}(L)\) according to Lemmas 5 and 6. Hence, \(\text {UP}(\mathcal {L}(\mathcal {B})) = \text {UP}(L)\), which implies that L is DBA-recognizable. For the case that the algorithm returns “NO”, we analyze two cases:
-
1.
\(\mathcal {F}\) has final states but without sink accepting states for some progress DFA. By Corollary 3, L is not DBA-recognizable.
-
2.
\(\mathcal {L}(\mathcal {A}) \not \subseteq \mathcal {L}(\mathcal {B})\). It means that \(\text {UP}(L) \not \subseteq \text {UP}(\mathcal {L}(\mathcal {B}))\) (by Lemma 5). It follows that L is not DBA-recognizable by Lemma 7.
The algorithm is therefore sound; its completeness follows from Lemmas 6 and 7.
The translations above are all in polynomial time. Moreover, checking the language inclusion between an NBA and a DBA can also be done in polynomial time [11]. Hence, the deciding algorithm is also in polynomial time in the size of the limit FDFA of L. \(\square \)
Recall that, our limit FDFAs are dual to recurrent FDFAs. One can observe that, for DBA-recognizable languages, recurrent FDFAs do not necessarily have sink final states in progress DFAs. For instance, the \(\omega \)-regular language \(L = a^{\omega } + ab^{\omega }\) is DBA-recognizable, but its recurrent FDFA, depicted in Fig. 1, does not have sink final states. Hence, our deciding algorithm does not work with recurrent FDFAs.
5 Underspecifying Progress Right Congruences
Recall that recurrent and limit progress DFAs \(\mathcal {N}^u\) either treat don’t care words in  as rejecting or accepting, whereas it really does not matter whether or not they are accepted. So why not keep this question open? We do just this in this section; however, we find that treating the progress with maximal flexibility comes at a cost: the resulting right progress relation \(\approx ^u_N\) is no longer an equivalence relation, but only a reflexive and symmetric relation over \(\varSigma ^*\times \varSigma ^*\) such that \(x \approx ^u_N y\) implies \(xv \approx ^u_N yv\) for all \(u, x, y, v\in \varSigma ^*\).
as rejecting or accepting, whereas it really does not matter whether or not they are accepted. So why not keep this question open? We do just this in this section; however, we find that treating the progress with maximal flexibility comes at a cost: the resulting right progress relation \(\approx ^u_N\) is no longer an equivalence relation, but only a reflexive and symmetric relation over \(\varSigma ^*\times \varSigma ^*\) such that \(x \approx ^u_N y\) implies \(xv \approx ^u_N yv\) for all \(u, x, y, v\in \varSigma ^*\).
For this, we first introduce Right Pro-Congruences (RP) as relations on words that satisfy all requirements of an RC except for transitivity.
Definition 12 (Progress RP)
Let \([u]_{\backsim }\) be an equivalence class of \(\backsim \). For \(x, y \in \varSigma ^*\), we define the progress RP \(\approx ^u_N\) as follows:
Obviously, \(\approx ^u_N\) is a RP, i.e., for \(x, y, v'\in \varSigma ^\omega \), if \(x \approx ^u_N y\), then \(xv' \approx ^u_N yv'\). That is, assume that \(x \approx ^u_N y\) and we want to prove that, for all \(e \in \varSigma ^*\), \((u \cdot x v' e \backsim u \wedge u \cdot y v' e \backsim u) \implies (u \cdot (x v' e)^{\omega } \in L \Longleftrightarrow u \cdot (yv'e)^{\omega } \in L)\). This follows immediately by setting \(v = v' e\) in Definition 12 for all \(e \in \varSigma ^*\) since \(x \approx ^u_N y\). As \(\approx ^u_N\) is not necessarily an equivalence relationFootnote 5, so that we cannot argue directly with the size of its index. However, we can start with showing that \(\approx ^u_N\) is coarser than \(\approx ^u_P, \approx ^u_S, \approx ^u_R\), and \(\approx ^u_L\).
Lemma 8
For \(u, x, y \in \varSigma ^*\), we have that if \(x \approx ^u_K y\), then \(x \approx ^u_N y\), where \(K \in \{P, S, R, L\}\).
Proof
First, if \(x \approx ^u_P y\), \(x \approx ^u_N y\) holds trivially.
For syntactic, recurrent, and limit RCs, we first argue for fixed \(v \in \varSigma ^*\) that
-
\(ux \backsim uy \Longrightarrow uxv \backsim uyv\), and therefore
\(ux \backsim uy \wedge \big ( u\cdot x \cdot v \backsim u \Longrightarrow (u\cdot (x \cdot v)^{\omega } \in L \Longleftrightarrow u\cdot (y\cdot v)^{\omega } \in L)\big )\)
\(\models (u xv \backsim u \wedge u yv \backsim u) \implies (u\cdot (xv)^{\omega } \in L \Longleftrightarrow u\cdot (yv)^{\omega } \in L)\),
-
\((u \cdot x \cdot v \backsim u \wedge u\cdot (x v)^{\omega } \in L) \Longleftrightarrow (u\cdot y v \backsim u \wedge u\cdot (y \cdot v)^{\omega } \in L)\)
\(\models (u xv \backsim u \wedge u yv \backsim u) \implies (u\cdot (xv)^{\omega } \in L \Longleftrightarrow u\cdot (yv)^{\omega } \in L)\), and
-
\((u \cdot x \cdot v \backsim u \Longrightarrow u\cdot (x \cdot v)^{\omega } \in L) \Longleftrightarrow (u \cdot y\cdot v \backsim u \Longrightarrow u\cdot (y \cdot v)^{\omega } \in L)\)
\(\models (u xv \backsim u \wedge u yv \backsim u) \implies (u\cdot (xv)^{\omega } \in L \Longleftrightarrow u\cdot (yv)^{\omega } \in L)\),
which is simple Boolean reasoning. As this holds for all \(v \in \varSigma ^*\) individually, it also holds for the intersection over all \(v \in \varSigma ^*\), so that the claim follows. \(\square \)
Now, it is easy to see that we can use any RC \(\approx \) that refines \(\approx ^u_N\) and use it to define a progress DFA. It therefore makes sense to define the set of RCs that refine \(\approx ^u_N\) as \(\textsf{RC}(\approx ^u_N) = \{\approx \ \mid \ \approx \subset \approx ^u_N\) is a RC\(\}\), and the best index \(|\approx ^u_N|\) of our progress RP as \(|\approx ^u_N| = \min \{|\approx | \ \mid \ \approx \in \textsf{RC}(\approx ^u_N)\}\). With this definition, Corollary 4 follows immediately.
Corollary 4
For \(u\in \varSigma ^*\), we have that \(|\approx ^u_N| \le |\approx ^u_K|\) for all \(K \in \{P, S, R, L\}\).
We note that the restriction of \(\approx ^u_N\) to \(C_u \times C_u\) is still an equivalence relation, where \(C_u = \{v\in \varSigma ^*: u v \backsim u\}\) are the words the FDFA acceptance conditions really care about. This makes it easy to define a DFA over each \(\approx \in \textsf{RC}(\approx _N^u)\) with finite index: \(C_u/_{\approx _N^u}\) is good if it contains a word v s.t. \(u\cdot v^\omega \in L\), and a quotient of \(\varSigma ^*/_\approx \) is accepting if it intersects with a good quotient (note that it intersects with at most one quotient of \(C_u\)). With this preparation, we now show the following.
Theorem 6
Let L be an \(\omega \)-regular language and \(\mathcal {F}_L {=} (\mathcal {M}[\backsim ], \{ \mathcal {N}[\approx _u]\}_{[u]_{\backsim } \in \varSigma ^*/_{\backsim }})\) be the limit FDFA of L s.t. \(\approx _u \in \textsf{RC}(\approx _N^u)\) with finite index for all u. Then (1) \(\mathcal {F}_L\) has a finite number of states, (2) \(\text {UP}(\mathcal {F}_L) = \text {UP}(L)\), and (3) \(\mathcal {F}_L\) is saturated.
The proof is similar to the proof of Theorem 2 and can be found in [13, Appendix D].
6 Discussion and Future Work
Our limit FDFAs fit nicely into the learning framework for FDFAs [3] and are already available for use in the learning library ROLLFootnote 6 [14]. Since one can treat an FDFA learner as comprised of a family of DFA learners in which one DFA of the FDFA is learned by a separate DFA learner, we only need to adapt the learning procedure for progress DFAs based on our limit progress RCs, without extra development of the framework; see [13, Appendix E] for details. We leave the empirical evaluation of our limit FDFAs in learning \(\omega \)-regular languages as future work.
We believe that limit FDFAs are complementing the existing set of canonical FDFAs, in terms of recognizing and learning \(\omega \)-regular languages. Being able to easily identify DBA-recognizable languages, limit FDFAs might be used in a learning framework for DBAs using membership and equivalence queries. We leave this to future work. Finally, we have looked at retaining maximal flexibility in the construction of FDFA by moving from progress RCs to progress RPs. While this reduces size, it is no longer clear how to construct them efficiently, which we leave as a future challenge.
Notes
- 1.
- 2.
This enables to learn L via learning the regular language \(L_{\$}\) [9].
- 3.
Minimizing DFAs with don’t care words is NP-complete [20].
- 4.
Defining directly a progress RC \(\approx ^u\) that recognizes \(V_u\) is hard since \(V_u\) is quantified over all v-extensions.
- 5.
In the language \(L = a^{\omega } + ab^{\omega }\) from the example of Fig. 1, for example, we have \(a \approx ^{ab}_N \epsilon \) and \(a \approx ^{ab}_N b\), but \(b \not \approx ^{ab}_N \epsilon \).
- 6.
References
Angluin, D.: Learning regular sets from queries and counterexamples. Inf. Comput. 75(2), 87–106 (1987). https://doi.org/10.1016/0890-5401(87)90052-6
Angluin, D., Boker, U., Fisman, D.: Families of DFAs as acceptors of \(\omega \)-regular languages. Log. Methods Comput. Sci. 14(1), 1–21 (2018)
Angluin, D., Fisman, D.: Learning regular omega languages. Theor. Comput. Sci. 650, 57–72 (2016). https://doi.org/10.1016/j.tcs.2016.07.031
Angluin, D., Fisman, D.: Regular \(\omega \)-languages with an informative right congruence. Inf. Comput. 278, 104598 (2021). https://doi.org/10.1016/j.ic.2020.104598
Bohn, L., Löding, C.: Passive learning of deterministic Büchi automata by combinations of DFAs. In: Bojanczyk, M., Merelli, E., Woodruff, D.P. (eds.) 49th International Colloquium on Automata, Languages, and Programming, ICALP 2022, 4–8 July 2022, Paris, France. LIPIcs, vol. 229, pp. 114:1–114:20. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2022). https://doi.org/10.4230/LIPIcs.ICALP.2022.114
Büchi, J.R.: On a decision method in restricted second order arithmetic. In: 1960 Proceedings of the International Congress on Logic, Method, and Philosophy of Science, pp. 1–12. Stanford University Press (1962)
Calbrix, H., Nivat, M., Podelski, A.: Ultimately periodic words of rational \(\omega \)-languages. In: Brookes, S., Main, M., Melton, A., Mislove, M., Schmidt, D. (eds.) MFPS 1993. LNCS, vol. 802, pp. 554–566. Springer, Heidelberg (1994). https://doi.org/10.1007/3-540-58027-1_27
Colcombet, T., Zdanowski, K.: A tight lower bound for determinization of transition labeled Büchi automata. In: Albers, S., Marchetti-Spaccamela, A., Matias, Y., Nikoletseas, S., Thomas, W. (eds.) ICALP 2009, Part II. LNCS, vol. 5556, pp. 151–162. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-02930-1_13
Farzan, A., Chen, Y.-F., Clarke, E.M., Tsay, Y.-K., Wang, B.-Y.: Extending automated compositional verification to the full class of omega-regular languages. In: Ramakrishnan, C.R., Rehof, J. (eds.) TACAS 2008. LNCS, vol. 4963, pp. 2–17. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-78800-3_2
Krishnan, S.C., Puri, A., Brayton, R.K.: Deterministic \(\omega \) automata vis-a-vis deterministic Buchi automata. In: Du, D.-Z., Zhang, X.-S. (eds.) ISAAC 1994. LNCS, vol. 834, pp. 378–386. Springer, Heidelberg (1994). https://doi.org/10.1007/3-540-58325-4_202
Kurshan, R.P.: Complementing deterministic büchi automata in polynomial time. J. Comput. Syst. Sci. 35(1), 59–71 (1987). https://doi.org/10.1016/0022-0000(87)90036-5
Li, Y., Chen, Y., Zhang, L., Liu, D.: A novel learning algorithm for büchi automata based on family of DFAs and classification trees. Inf. Comput. 281, 104678 (2021). https://doi.org/10.1016/j.ic.2020.104678
Li, Y., Schewe, S., Tang, Q.: A novel family of finite automata for recognizing and learning \(\omega \)-regular languages (2023)
Li, Y., Sun, X., Turrini, A., Chen, Y.-F., Xu, J.: ROLL 1.0: \(\omega \)-regular language learning library. In: Vojnar, T., Zhang, L. (eds.) TACAS 2019, Part I. LNCS, vol. 11427, pp. 365–371. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-17462-0_23
Maler, O., Pnueli, A.: On the learnability of infinitary regular sets. Inf. Comput. 118(2), 316–326 (1995). https://doi.org/10.1006/inco.1995.1070
Maler, O., Staiger, L.: On syntactic congruences for omega-languages. Theor. Comput. Sci. 183(1), 93–112 (1997). https://doi.org/10.1016/S0304-3975(96)00312-X
Michel, M.: Complementation is more difficult with automata on infinite words. CNET, Paris 15 (1988)
Myhill, J.: Finite automata and the representation of events. In: Technical Report WADD TR-57-624, pp. 112–137 (1957)
Nerode, A.: Linear automaton transformations. In: American Mathematical Society, pp. 541–544 (1958)
Pfleeger, C.P.: State reduction in incompletely specified finite-state machines. IEEE Trans. Comput. 22(12), 1099–1102 (1973). https://doi.org/10.1109/T-C.1973.223655
Safra, S.: On the complexity of omega-automata. In: 29th Annual Symposium on Foundations of Computer Science, White Plains, New York, USA, 24–26 October 1988, pp. 319–327. IEEE Computer Society (1988). https://doi.org/10.1109/SFCS.1988.21948
Schewe, S.: Tighter bounds for the determinisation of Büchi automata. In: de Alfaro, L. (ed.) FoSSaCS 2009. LNCS, vol. 5504, pp. 167–181. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-00596-1_13
Schewe, S.: Beyond hyper-minimisation—minimising dbas and DPAs is NP-complete. In: Lodaya, K., Mahajan, M. (eds.) IARCS Annual Conference on Foundations of Software Technology and Theoretical Computer Science, FSTTCS 2010, 15–18 December 2010, Chennai, India. LIPIcs, vol. 8, pp. 400–411. Schloss Dagstuhl - Leibniz-Zentrum für Informatik (2010). https://doi.org/10.4230/LIPIcs.FSTTCS.2010.400
Vardi, M.Y., Wolper, P.: An automata-theoretic approach to automatic program verification (preliminary report). In: Proceedings of the Symposium on Logic in Computer Science (LICS 1986), Cambridge, Massachusetts, USA, 16–18 June 1986, pp. 332–344. IEEE Computer Society (1986)
Wilke, T., Schewe, S.: \(\omega \)-automata. In: Pin, J. (ed.) Handbook of Automata Theory, pp. 189–234. European Mathematical Society Publishing House, Zürich, Switzerland (2021). https://doi.org/10.4171/Automata-1/6
Acknowledgements
We thank the anonymous reviewers for their valuable feedback. This work has been supported by the EPSRC through grants EP/X021513/1 and EP/X017796/1.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Li, Y., Schewe, S., Tang, Q. (2023). A Novel Family of Finite Automata for Recognizing and Learning \(\omega \)-Regular Languages. In: André, É., Sun, J. (eds) Automated Technology for Verification and Analysis. ATVA 2023. Lecture Notes in Computer Science, vol 14215. Springer, Cham. https://doi.org/10.1007/978-3-031-45329-8_3
Download citation
DOI: https://doi.org/10.1007/978-3-031-45329-8_3
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45328-1
Online ISBN: 978-3-031-45329-8
eBook Packages: Computer ScienceComputer Science (R0)