
Abstract
Drought is a well-known yet incredibly difficult to understand hydro-meteorological natural hazard that occurs around the globe as a result of major climate change occurrences. For the central Gujarat region, we examined the drought periodicities during the previous 30 years for this study. The patterns of drought conditions are a sign of climatic and environmental change, and recognizing these trends is crucial for the sustainable management of water resources. Application of the MK test to the first SPI series revealed that the post-monsoon SPI series had a negligible upward trend. The MK test on the original SPEI series indicated several time series with large declining trends prior to the monsoon, whereas every post-monsoon SPEI series displayed an insignificant growing trend. The findings demonstrate that (1) due to the various time series, the SPI and SPEI's identification of the characteristics of drought were quite distinct in space at various timescales, (2) The SPI and SPEI differed most at the shortest time scale, and (3) The drought represented by the two indicators may be consistent over long periods of time. (4) The SPEI may be more suitable than the SPI for drought monitoring in the study region when compared to typical drought occurrence. It should be emphasized that future research will need to examine whether the SPI and SPEI's adaptability varies among regions and historical periods.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others
Keywords
- Drought
- Standardized Precipitation Index (SPI)
- Standardized Precipitation Evapotranspiration Index (SPEI)
- MK test
- Discrete wavelet transform (DWT)
1 Introduction
Climate change could have a significant and enduring impact on all major natural disasters known to mankind (Krishnamurthy et al. 2014). A perception of climate change can be obtained by examining the long-term trend and variability associated to hydro-climatic variables such as rainfall, temperature, and drought (Rashed et al. 2015; Yerdelen et al. 2021). In general, it is anticipated that drought intensity and frequency would rise due to global warming, decreased precipitation, and similarly increased thermometer readings (Das et al. 2020; Paras et al. 2022). Understanding the main physical processes affecting droughts can help improve current drought monitoring, forecasting, and management systems as well as reduce the vulnerability to and effects of drought. An investigation of changes in drought magnitude, severity, and duration can provide insight into the governing physical and atmospheric phenomena (Joshi et al. 2016; Luhaim et al. 2021; Menna et al. 2022). Drought, one of the most significant hydrometeorological conditions, is typically characterised as a prolonged shortage of freshwater on Earth (Yang et al. 2018; Menna et al. 2022).
Droughts can be classified as meteorological, agricultural, hydrological, or economical in nature. Each has distinctive qualities all of its own. The most severe of them is the meteorological drought, which is most clearly caused by a decrease in precipitation. The effects of the other three forms of drought on individuals and society are more severe. One may contend that the meteorological drought is what causes the other three types of drought. Due to the complexity and severity of drought, defining and evaluating drought features is particularly challenging (Asadi et al. 2015). To evaluate and monitor drought occurrences, numerous drought indices have been developed in recent years. Among these are the composite meteorological drought index, standardised precipitation evapotranspiration index, Palmer drought index, and standardised precipitation index (CI). Two of them, the SPI and SPEI, both have the characteristics of several timeframes, which can represent various types of droughts and more accurately illustrate the variations in drought aspects (Salehnia & Ahn 2022). These indexes are therefore widely used across the globe. Although the concepts behind the SPI and SPEI are similar, the parameters used in each computation are very different (Pande et al. 2023a, b). The SPEI is based on the cumulative difference between precipitation (P) and potential evapotranspiration (PET), which may properly reflect changes in the surface water balance. The SPI solely considers precipitation, which is easy to compute and has strong geographical and temporal flexibility.
However, the increase in evaporation brought on by warming is not trivial for an accurate assessment of drought with global warming (Bera et al. 2021). As a result, the SPEI is substantially better than the SPI in tracking drought, but its application in arid areas may be limited (Ojha et al. 2021). Furthermore, the SPI is still widely used worldwide. Therefore, there is still room for debate regarding the distinctions between the SPI and the SPEI in terms of tracking droughts as well as their geographical applicability in light of overall climate change.
India is one of the world's most susceptible and drought-prone nations (Mishra & Singh 2010). In India, the south-west monsoon, which lasts from June to September, is responsible for 70–90% of the nation's average annual precipitation (Kumar et al. 2013). Failure of the monsoon season could result in a lack of water accessible across the nation, which could cause droughts (Fung et al. 2019). According to the Indian Meteorological Department, a drought year occurs when the seasonal rainfall anomaly averaged throughout the nation as a whole is less than 10% of its long-term norm (IMD).
The standardised precipitation index (SPI), which was created at Colorado State University to measure precipitation deficiencies (Mckee et al. 1993; Asadi et al., 2015), has gained widespread acceptance as a tool for studying droughts (Mundetia & Sharma 2015; Qaisrani et al. 2021). The World Meteorological Department uses the SPI as the index for analyzing agricultural and hydrological drought because of its simplicity, stability, and adaptability (Mundetia & Sharma 2015). Despite SPI's widespread acceptance and use, it ignores other elements that can cause drought, such as temperature, evapotranspiration volume, wind speed, and soil water-holding capacity (Vicente-serrano et al. 2010). Consequently, the SPEI will be used to counteract the benefits of the SPI (Ojha et al. 2021). SPEI is particularly useful for analyzing, observing, and researching how drought is affected by climate change (Ghasemi et al. 2021).
Because its performance is unaffected by the assumptions of uniform data distribution and the requirement for skewed data distribution, the Mann–Kendall test is determined to be durable (Onoz & Bayazit, 2003; Afshar et al., 2022). The MK test has a noteworthy drawback in that it cannot handle data with serial correlation, which is typically present in hydro-climatic data (Salehnia & Ahn 2022). When examining trends in hydroclimatic time series, it's crucial to consider how these changes fluctuate across various time periods in addition to whether the trend direction is increasing or decreasing (Onoz & Bayazit 2003; Yerdelen, et al. 2021). A common method for identifying oscillatory signals is the Fourier Transform (FT), which uses sine- and cosine-based functions (Tefera et al. 2019).
A relatively new method for processing time and frequency domain signals for time series analysis is the wavelet transformation (WT) (Araghi et al. 2015; Mundetia & Sharma 2015). WT is employed to break down time series data into several sub-time series data with various periodicities using various scales and amplitudes (Labat 2005; Wang & Lu 2009). Time series data naturally have physical properties including trends, periodicity, discontinuities, and change points. Wavelet analysis has been shown to be an advanced technique for capturing these properties (Partal 2010; Nikhil raj & Azeez 2012; Araghi et al. 2015). Having tremendous possibilities of SPI and SPEI indices for drought assessment, these Due to the climate change and its variability, which could be accounted to the undulating topography of the research area, and variation in drought ratings from SPI and SPEI is expected (Bera et al. 2021). As a result, this study looked at the level of agreement between the SPI and SPEI ratings as instruments for assessing the drought in the Gujarat region.
This chapter has been focus on four main sections, which includes the introduction as 1st Sec. In Sect. 2 we present the materials and methods used in this study, while in Sect. 3 we present detail results of our study. In Sect. 4 we present the main conclusions and outcomes of the research objective.
2 Materials and Methods
2.1 Data and Methods
The main region of analysis for this study is Middle Gujarat, but for most of the analyses employed through the paper we split the Middle Gujarat domain into three separate micro-regions such as Dahod, Chhota Udaipur, Vadodara. Monthly rainfall data of 17 Grids under study area of 30 years (1986–2015) is used for calculate the seasonal and annual SPI drought index (Table 1 and Fig. 1). Monthly precipitation and mean temperature are used for calculate seasonal and annual SPEI drought index for 42 Grids. The data quality was rigorously monitored, and the average values of the data from the adjacent meteorological stations were used to fill in any missing values. We acquired the gridded dataset (Precipitation & Temperature) from the Climate Research & Services, Pune (IMD, Pune Lab) (https://www.imdpune.gov.in/). For detection of seasonal SPI and SPEI, four seasons are considered as Winter (December to February), Pre-monsoon (March to May), Monsoon (June to August) and Post-monsoon (September to November).

A Geographical location map of the study location
2.2 Description of Drought Indices
2.2.1 Standardized Precipitation Index (SPI)
The SPI is a popularly used drought index that is based only on rainfall measurements and may be summed up as the likelihood of precipitation being seen at a particular time range. Regardless of climate and land use, this probabilistic measure is independent and can be applied in various regions. Applying the following equation, the data were initially fitted to the gamma probability distribution function and transformed into a normal distribution:
If the amount of precipitation fell during a specific time period was x, the G distribution of the probability density function was as follows:
where, x is the monthly accumulated precipitation amount, and α and β are the shape and scale parameters of gamma distribution, respectively.
The Z or SPI values is more easily obtained computationally using an approximation that converts cumulative probability to the standard normal random variable Z;
where, \({\varvec{t}}=\sqrt{{\varvec{l}}{\varvec{n}}\left(\frac{1}{{\left({\varvec{H}}\left({\varvec{x}}\right)\right)}^{2}}\right)}\) and \({\varvec{t}}=\sqrt{{\varvec{l}}{\varvec{n}}\left(\frac{1}{{\left(1-{\varvec{H}}\left({\varvec{x}}\right)\right)}^{2}}\right)}\) are for \(0<{\varvec{H}}\left({\varvec{x}}\right)\le 0.5\) and \(0.5<{\varvec{H}}\left({\varvec{x}}\right)<1\), , respectively. (The constants are \({{\varvec{C}}}_{0}=2.515517\), \({{\varvec{C}}}_{1}= 0.802853\), \({{\varvec{C}}}_{2}= 0.010328\), \({{\varvec{d}}}_{1}= 1.432788\), \({{\varvec{d}}}_{2}= 0.189269\), and \({{\varvec{d}}}_{3}\)= 0.001308).
Values from SPI indicate both dry and wet situations. Extreme wet (> 2), severely wet (1.5 to 1.99), moderately wet (1.00 to 1.49), slightly wet (0 to 0.99), mildly dry (0 to -0.990), moderately dry (−1.00 to -1.49), severely dry (−1.5 to −1.99), and extreme dry (–2.00) are the eight classifications that the SPI drought portion is randomly divided. When SPI approaches 0.0, a drought event begins, and it ends when SPI turns positive (World Meteorological Organization, 2012).
2.2.2 Standardized Precipitation Evapotranspiration Index
Vicente Serrano and associates suggested the SPEI in 2010 as an improvement of the SPI. Based on the water balance principle, the SPEI assesses the dry and wet conditions of the region using the difference between precipitation (P) and potential evapotranspiration (PET) (Tirivarombo et al. 2018). The SPEI has a significant advantage over other commonly used drought indices that take the impact of PET on drought severity into account because its multi-scalar properties make it possible to identify various drought types and their effects in the context of global warming.
Using a discrepancy between precipitation and evapotranspiration from the average condition, the SPEI is used to detect drought in a region (Vicente-serrano et al. 2010). The Penmen Monteith (PM) equation is used to calculate PET (Allen et al., 1998) as follows;
where, ETo represents evapotranspiration (mm/day); ∆ = saturated vapor pressure slope (kPa/°C); G = heat flux density of soil (MJ/m2 /day); Rn = net radiation (MJ/m2 per day); T = mean temperature (°C); u2 = average daily speed of wind (m/s); es − ea = deficit of vapor pressure; γ = psychrometric constant (kPa/°C).
After a standard normal distribution process, the \({\varvec{S}}{\varvec{P}}{\varvec{E}}{\varvec{I}}\) can be obtained by below equation:
When, P \(\le\) 0.5, P = 1 - F(x); P > 0.5, P = 1 – P. (\({{\varvec{C}}}_{0}=2.515517\), \({{\varvec{C}}}_{1}= 0.802853\), \({{\varvec{C}}}_{2}= 0.010328\), \({{\varvec{d}}}_{1}= 1.432788\), \({{\varvec{d}}}_{2}= 0.189269\), and \({{\varvec{d}}}_{3}\)= 0.001308 (Vicente-serrano et al. 2010).
2.3 Mann–Kendall (MK) Trend Tests
The Mann Kendall (MK) statistical test is used to detect trends in hydrological time series data that have been recorded (precipitation, runoff, water quality, temperature). Analysis of time series data trends has proven to be a useful technique for efficient management, planning, and design of water resources (Mallick et al. 2021). For each study location, the MK test and its variance were identified in order to derive the test's standard normal value (Z). The essential two-tailed Z-value (area under the normal curve) corresponding to the significant level of α /2 (this study used = 5%) then was compared to the absolute value of this Z. (Ali et al. 2019). The Z values for α of 5% in a two-tailed test are ± 1.96. If the Z-value obtained from the MK calculation is found outside the -1.96 and + 1.96 boundaries, then this indicates that the trends detected are significant.
The calculation of the MK test statistic, which is also known as the Kendall’s tau, is as follows (Yue et al. 2002):
where, \({{\varvec{X}}}_{{\varvec{c}}}\) and \({{\varvec{X}}}_{{\varvec{d}}}\) are data points, and \({\varvec{n}}\) is the number of the dataset.
\({\varvec{s}}{\varvec{i}}{\varvec{g}}{\varvec{n}}\left({\varvec{t}}\right)\) is defined as:
The Mann–Kendall statistic \({\varvec{Z}}\) is given as:
where, \({{\varvec{t}}}_{{\varvec{c}}}\) indicates the cumulative sum of \({\varvec{t}}\), which is the size of ties or duplicates of the extent \({\varvec{c}}\).
2.4 Magnitude of Trend Using Sen’s Slope Estimator
In order to determine the magnitude and variability of the trend in time series of SPI and SPEI Sen’s slope estimator was used (Ali et al. 2019) with the following set of equations:
The slope of the dataset is obtained from:
where, \({{\varvec{m}}}_{{\varvec{i}}}\), \({\varvec{N}}\), \({{\varvec{x}}}_{{\varvec{j}}}\), and \({{\varvec{x}}}_{{\varvec{k}}}\) denote the slope, the number of data points and \({\varvec{j}}\) and \({\varvec{k}}\) \(({\varvec{j}}>{\varvec{k}})\) represent the time points, respectively.
The median of these \({\varvec{N}}\) value of \({{\varvec{m}}}_{{\varvec{i}}}\) is termed as Sen’s estimator of slopes and is calculated by the following formulae:
A positive value means an increasing or upward trend, and a negative value means a decreasing or downward trend (Jain et al. 2013; Agarwal et al. 2021).
3 Results and Discussion
3.1 Temporal Evolution of the SPI and SPEI Analysis
3.1.1 Pre Monsoon
Since the turn of the century, the frequency and severity of droughts in the middle Gujarat region have increased, with the tendency becoming more obvious the further back in time one goes. In this study, we examined the differences between the pre-monsoon (May) and post-monsoon seasons using 3-month SPI & SPEI values (November). The 12-month SPI values (SPI-12) and 12-month SPEI values (SPEI-12) for December are used to detect annual SPI and SPEI values (Yang et al. 2018; He et al. 2015). The temporal distribution of SPI & SPEI for pre monsoon are clearly indicated in Fig. 2.

The time series of the pre monsoon SPI and SPEI in the study region during 1986–2015
The SPI based analysis indicates that pre monsoon indices from 3.22 to -0.25 (Extremely wet to Mildly dry state), while SPEI vary between 2.49 to – 4.39 which means extremely wet to extremely dry state. At 3-month time scale, strongest wet year identify by SPI & SPEI were 2000. Unlikely for the dentification of extremely driest year found by SPEI is 2010. Temporal distribution of SPI & SPEI are clearly indicated in Fig. 2 and it reviled that the maximum drought occurrence at 3-month time scale is highest in SPEI than SPI. Less fluctuation of extreme wet to extreme dry observed in SPI compared to SPEI, which means it give linear response-based rainfall data. While SPEI give quite good response by combination of rainfall and evapotranspiration data.
3.1.2 Post Monsoon
Figure 3 shows that post monsoon SPI & SPEI drought apical severity vary from 2.51 to –3.08 and 2.42 to –2.40 (Extremely wet to Extremely dry) respectively. In SPI identify year 2013 (Gride A05) is an extremely wet year while 1998 (AE10) year is based on SPEI. 3-month time scale SPI found 1986 is extremely dry drought severity while in SPEI 1987 year is extremely dry drought severity and intensity respectively.

The time series of the post monsoon SPI and SPEI in the study region during 1986–2015
Additionally, SPEI performed well in capturing the drought in 3-month time scale. Figure 2 shows that the SPEI identify higher draught year in all year compared to SPI. Regardless of their difference, however SPI and SPEI able to identify major recorded drought year in the study area including 1986, 1987, 2000, & 2015 in most cases. The SPI and SPEI were essentially consistent in representing drought periods, but the SPI's reflection of the severity of the drought was higher than the SPEI's.
3.2 Serial Correlation and Seasonality Factors
Here we used lag-1 autocorrelation for assessment of seasonality patterns, and it is applied to each and every SPI and SPEI data sets. Figures 4, 5 illustrate the lag-1 correlation graph for pre monsoon and post monsoon SPI. The frequency of statistical significance correlation at 0.4 and –0.4 levels is marked with red and grey color respectively (Figs. 4, 5) and investigated time scale of the analysis indicated an acceptable degree of agreement between SPI & SPEI. Correlograms for whole dataset was also prepared and we observed that no any significant seasonality pattern follows by SPI pre and post monsoon time series data set.

Lag-1 correlograms for pre & post monsoon SPI

Lag-1 correlograms for pre & post monsoon SPEI
3.3 Seasonal and Annual Trends in SPI
MK test is employed to analyze the trend for SPI and SPEI drought indices of all stations over the period of 1986 to 2015. This is done with 3-month cumulative time series data and 5% significance level. Results of the Mann Kendall trend test and Sen’s slope for 3-month time scale seasons of SPI & SPEI are exhibited in Tables 2, 3. Pre monsoon SPI series significantly increases in its trend in most of the grids, only A05, A06 indicates negative trend which means trend of these two grids are not at its significant level. In pre monsoon Sen’s slope estimator indicates no change on SPI series while in post monsoon all SPI series for sen’s slope are positive trend. Highest significant tread observed in A06 grid (Z = 2.48 & β = 0.049). Sen’s slope indicates weighted median of the difference in all values. Here is a simplest possibility illustration of zero is shorter upward trending segments.
Seasonal SPEI trend series period of 1986 to 2015 for 17 different grids into the study area (Table 3). Based on results, it found that the pre monsoon were significant decreasing trend in the study areas. On other hand post monsoon analysis indicates insignificantly increasing trend of SPEI over the study locations. Sen’s slope indicates difference between major and minor value is significant in both pre monsoon and post monsoon. SPEI capture tall the major drought years between 1986 to 2015 at time scale, while SPI fail to capture extreme drought events (Tables 2, 3). SPI value appears little lower than the SPEI values. This type of dissimilarity observed in our study and in other studies also. Wang et al. 2014 reported difference between SPI and SPEI based drought assessment. SPI predict extreme event based only precipitation data, while SPEI uses precipitation and temperature variability to predict climate extreme events (Mckee et al. 1993; Guttmann 1999; Vicente, et al. 2010). However, difference between SPI and SPEI values doesn’t mean that they give complete opposite results. In lower temperature variation regions, SPI can give equal results as strong as SPEI does. This indicates inability of SPI to count the effect of global warming in drought monitoring.
Sen’s slope results agreed with (Dogan 2018), which concluded that the good relationship can be expected if scattering of points is diminished, and lie relatively close to line which represent mean. Here, existed good level of agreement for most of scattering points lie between set range of upper and lower limit.
3.4 Linear Relationship Between SPI and SPEI for Pre and Post Monsoon Reasons
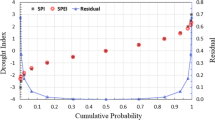
Using Pearson's correlation coefficient, it was found that SPI and SPEI have a linear relationship for different seasons. The results showed that the pre- and post-monsoon seasons did not yield significant results for the SPI and SPEI. Pre and post monsoon SPI & SPEI correlation is displayed using R2, which has values of 0.1928 & 0.1298, respectively. Scattered plot revealed that the relationship between SPI and SEPI and time was linearly decrementing (Fig. 6). This is partially due to the fact that the outcomes of the two distinct approaches do not agree, which could lead to a variety of conclusions that are either good or negative. This was supported by Dogan NO 2018, which cautioned against using correlation to gauge the comparability of different methodologies. The results clearly demonstrate that SPI and SPEI have a linear connection in this case, however there is not necessarily a degree of agreement. Furthermore, the independent Sen's slop test clearly demonstrates that the SPI and SPEI in this study do not differ significantly from one another.

Scatter plot showing the linear relationship of SPI & SPEI for all grids in pre monsoon & post monsoon season
4 Conclusion
SPI and SPEI indicators were utilized in the current study to analyze the spatial and temporal characteristics of climate extreme occurrences that occurred in Gujarat, India, before during and after the monsoon season. Drought is a devastating and slow-moving event that is influenced by both human and natural activity, in contrast to other climatic calamities. The number of severe occurrences in the study area was trended using both Sen's slope and the MK test. We can therefore infer from the results of this study that SPEI outperformed SPI in the Vadodara regions of Gujarat. However, the research for additional study locations also showed that SPEI can be used in place of SPI at time scales. SPI cannot be calculated in the absence of temperature data and a suitable analytical instrument; hence it is reasonable to assume that SPI can be used to measure drought in the research region at all-time scales.
This study's focus was on meteorological conditions based historical drought indicators. In order to make well-informed decisions for sustainable basin planning and management and to maximize the operational guidelines of existing water resources, trends in drought indices would be projected to future periods based on the anticipated outcomes from global climate models. Future studies that consider hydrologic, agricultural, and socioeconomic droughts will produce more insightful findings.
References
Afshar MH, Bulut B, Duzenli E, Amjad M, Yilmaz MT (2022) Global spatiotemporal consistency between meteorological and soil moisture drought indices. Agric for Meteorol 316:108848
Agarwal S, Suchithra AS, Singh SP (2021) Analysis and interpretation of rainfall trend using Mann-Kendall’s and Sen’s slope method. Indian J. Ecol 48:453–457
Ali R, Kuriqi A, Abubaker S, Kisi O (2019) Long-term trends and seasonality detection of the observed flow in Yangtze River using Mann-Kendall and Sen’s innovative trend method. Water 11(9):1855
Araghi A, Baygi MM, Adamowski J, Malard J, Nalley D, Hasheminia SM (2015) Using wavelet transforms to estimate surface temperature trends and dominant periodicities in Iran based on gridded reanalysis data. Atmos Res 155:52–72
Asadi Zarch MA, Sivakumar B, Sharma A (2015) Droughts in a warming climate: a global assessment of standardized precipitation index (SPI) and reconnaissance drought index (RDI). J Hydrol 526:183–195
Bera B, Shit PK, Sengupta N, Saha S, Bhattacharjee S (2021) Trends and variability of drought in the extended part of Chhota Nagpur plateau (Singbhum Protocontinent), India applying SPI and SPEI indices. Environ Challs 5:100310
Das S, Ghosh A, Hazra S, Ghosh T, de Campos RS, Samanta S (2020) Linking IPCC AR4 & AR5 frameworks for assessing vulnerability and risk to climate change in the Indian Bengal Delta. Prog Disaster Sci 7:100110
Dogan NO (2018) Bland-Altman analysis: a paradigm to understand correlation and agreement. Turk J Emerg Med 18(4):139–141
Fung KF, Huang YF, Koo CH (2019) Coupling fuzzy–SVR and boosting–SVR models with wavelet decomposition for meteorological drought prediction. Environ Earth Sci 78(24):1–18
Ghasemi P, Karbasi M, Nouri AZ, Tabrizi MS, Azamathulla HM (2021) Application of Gaussian process regression to forecast multi-step ahead SPEI drought index. Alex Eng J 60(6):5375–5392
Guttmann NB (1999) Accepting the standardized precipitation index: a calculation algorithm 1. J Am Water Resour Assoc 35(2):311–322
He Y, Ye J, Yang X (2015) Analysis of the spatio-temporal patterns of dry and wet conditions in the Huai River Basin using the standardized precipitation index. Atmos Res 166:120–128
Jain SK, Kumar V, Saharia M (2013) Analysis of rainfall and temperature trends in northeast India. Int J Climatol 33(4):968–978
Joshi S, Li Y, Kalwani RM, Gold JI (2016) Relationships between pupil diameter and neuronal activity in the locus coeruleus, colliculi, and cingulate cortex. Neuron 89(1):221–234
Krishnamurthy PK, Lewis K, Choularton RJ (2014) A methodological framework for rapidly assessing the impacts of climate risk on national-level food security through a vulnerability index. Glob Environ Chang 25:121–132
Kumar KN, Rajeevan M, Pai DS, Srivastava AK, Preethi B (2013) On the observed variability of monsoon droughts over India. Weather Clim Extrem 1:42–50
Labat D (2005) Recent advances in wavelet analyses: Part 1. A review of concepts. J Hydrol, 314 (1–4), 275–288.
Luhaim ZB, Tan ML, Tangang F, Zulkafli Z, Chun KP, Yusop Z, Yaseen ZM (2021) Drought variability and characteristics in the muda river basin of Malaysia from 1985 to 2019. Atmosphere 12(9):1210
Mallick J, Talukdar S, Alsubih M, Salam R, Ahmed M, Kahla NB, Shamimuzzaman M (2021) Analysing the trend of rainfall in Asir region of Saudi Arabia using the family of Mann-Kendall tests, innovative trend analysis, and detrended fluctuation analysis. Theoret Appl Climatol 143(1):823–841
Mckee TBT, Doesken NJNJ, Kleist J (1993) The relationship of drought frequency and duration to time scales. Eighth conference on applied climatology, 17(22). Am Meteorol Soc, Boston, pp 179–183
Menna BY, Mesfin HS, Gebrekidan AG, Siyum ZG, Tegene MT (2022) Meteorological drought analysis using copula theory for the case of upper Tekeze river basin, Northern Ethiopia. Theor Appl Climatol, 1–18
Mishra AK, Singh VP (2010) A review of drought concepts. J Hydrol 391(1–2):202–216
Mundetia N, Sharma D (2015) Analysis of rainfall and drought in Rajasthan State. India. Glob NEST J 17(1):12–21
Nikhil Raj PP, Azeez PA (2012) Trend analysis of rainfall in Bharathapuzha river basin, Kerala. India. Int J Climatol 32(4):533–539
Ojha SS, Singh V, Roshni T (2021) Comparison of meteorological drought using SPI and SPEI. Civ Eng J 7(12):2130–2149
Onoz B, Bayazit M (2003) The power of statistical tests for trend detection. Turk J Eng Environ Sci 27(4):247–251
Pande CB, Costache R, Sammen SS et al (2023a) Combination of data-driven models and best subset regression for predicting the standardized precipitation index (SPI) at the Upper Godavari Basin in India. Theor Appl Climatol 152:535–558. https://doi.org/10.1007/s00704-023-04426-z
Pande CB, Kushwaha NL, Orimoloye IR et al (2023b) Comparative assessment of improved SVM method under different Kernel functions for predicting multi-scale drought index. Water Resour Manage 37:1367–1399. https://doi.org/10.1007/s11269-023-03440-0
Paras H, Sanjay P, Vaibhav R (2022) The significance impact assessment of morphological parameters on watershed: a review. Agric Rev 43(1):110–115
Partal T (2010) Wavelet transform-based analysis of periodicities and trends of Sakarya basin (Turkey) streamflow data. River Res Appl 26(6):695–711
Qaisrani ZN, Nuthammachot N, Techato K (2021) Drought monitoring based on standardized precipitation index and standardized precipitation evapotranspiration index in the arid zone of Balochistan province. Pakistan. Arab J Geosci 14(1):1–13
Rashed M, Idris Y, Shaban M (2015) Integrative approach of GIS and remote sensing to represent the hydrogeological and hydro chemical conditions of Wadi Qena Egypt. In the 2nd International Conference On Water Resources And Arid Environment, Saudi Arabia. pp 26–29
Salehnia N, Ahn J (2022) Modelling and reconstructing tree ring growth index with climate variables through artificial intelligence and statistical methods. Ecol Ind 134:108496
Tefera AS, Ayoade JO, Bello NJ (2019) Comparative analyses of SPI and SPEI as drought assessment tools in Tigray Region. Northern Ethiopia. SN Applied Sciences 1(10):1–14
Tirivarombo S, Osupile D, Eliasson P (2018) Drought monitoring and analysis: Standardized Precipitation Evapotranspiration Index (SPEI) and Standardized Precipitation Index (SPI). Phys Chem Earth Parts 106:1–10
Vicente-Serrano SM, Beguería S, López-Moreno JI (2010) A multiscalar drought index sensitive to global warming: the standardized precipitation evapotranspiration index. J Clim 23(7):1696–1718
Wang N, Lu C (2009) Two-dimensional continuous wavelet analysis and its application to meteorological data. J Atmos Oceanic Tech 27(4):652–666
Wang W, Zhu Y, Xu R, Liu J (2014) Drought severity change in China during 1961–2012 indicated by SPI and SPEI. Nat Hazards 75(3):2437–2451
World Meteorological Organization (2012) Standardized Precipitation Index User Guide. Svoboda, M., Hayes, M., & Wood, D, Geneva
Yang P, Xia J, Zhan C, Zhang Y, Hu S (2018) Discrete wavelet transform-based investigation into the variability of standardized precipitation index in Northwest China during 1960–2014. Theoret Appl Climatol 132(1–2):167–180
Yerdelen C, Abdelkader M, Eris E (2021) Assessment of drought in SPI series using continuous wavelet analysis for Gediz Basin. Turkey. Atmospheric Research 260:105687
Yue S, Pilon P, Phinney B, Cavadias G (2002) The influence of autocorrelation on the ability to detect trend in hydrological series. Hydrol Process 16(9):1807–1829
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this chapter

Cite this chapter
Hirapara, P., Brahmbhatt, M., Tiwari, M.K. (2023). Investigation of Trends and Variability Associated with the SPI and SPEI as a Drought Prediction Tools in Gujarat Regions, India. In: Pande, C.B., Kumar, M., Kushwaha, N.L. (eds) Surface and Groundwater Resources Development and Management in Semi-arid Region. Springer Hydrogeology. Springer, Cham. https://doi.org/10.1007/978-3-031-29394-8_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-29394-8_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-29393-1
Online ISBN: 978-3-031-29394-8
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)