
Abstract
We present VeyMont: a deductive verification tool that aims to make reasoning about functional correctness and deadlock freedom of parallel programs (relatively complex) as easy as that of sequential programs (relatively simple). The novelty of VeyMont is that it “inverts the workflow”: it supports a new method to parallelise verified programs, in contrast to existing methods to verify parallel programs. Inspired by methods for distributed systems, VeyMont targets coarse-grained parallelism among threads (i.e., whole-program parallelisation) instead of fine-grained parallelism among tasks (e.g., loop parallelisation).
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



1 Introduction


Deductive verification is a classical approach to reason about functional correctness of programs. The idea is to annotate programs with logic assertions about state. A proof system can subsequently be used to statically check whether or not annotations are true (i.e., whether or not state dynamically evolves as asserted).
As multicore hardware and multithreaded software have become ubiquitous, deductive verification has been facing an elusive open problem: the approach is much harder to apply to parallel programs than to sequential programs. Towards addressing this issue, in this paper, we present VeyMont. It is a deductive verification tool that aims to make reasoning about functional correctness and deadlock freedom of parallel programs as easy as that of sequential programs. The novelty of VeyMont is that it “inverts the workflow”: it supports a new method to parallelise verified programs, in contrast to existing methods to verify parallel programs. Unlike traditional model checkers, VeyMont proves properties generally for all (possibly infinitely many) initial values of variables, instead of specifically for instances. Unlike parallelising compilers, VeyMont targets coarse-grained parallelism among threads (i.e., whole-program parallelisation), instead of fine-grained parallelism among instructions (e.g., loop parallelisation).

Example of deductive verification (swapping values)
Background. In the state-of-the-art on verification of sequential and parallel programs, typically, proof systems based on (extensions of) Hoare logic [4, 21] and separation logic [40, 45] are used to prove properties of annotated programs. To demonstrate the main concepts, Fig. 1 shows four functionally equivalent programs to swap the values of variables
 and
and
 :
:
-
Figure 1a shows a sequential program; it uses auxiliary variable z.
The program is annotated with two assertions (in
 ), expressed in Hoare logic: the precondition (top) specifies what must be true before the program is run; the postcondition (bottom) specifies what will be true after.
), expressed in Hoare logic: the precondition (top) specifies what must be true before the program is run; the postcondition (bottom) specifies what will be true after. -
Figure 1c shows a parallel program, with two threads; it uses a barrier b and auxiliary variables z1 and z2. First, the “left thread” copies x into z1; next, it waits on b (until the “right thread” has copied y into z2); next, it copies z2 into x. In parallel, the “right thread” behaves symmetrically. The barrier is crucial: without it, the threads can prematurely copy z1 and z2.
The program is annotated with seven assertions (in
 ), expressed in a variant of separation logic [22, 23]: the “global” and “local” pre/postconditions specify the behaviour of the whole program and of the separate threads; the barrier contract specifies for every thread what must be true before it passes the barrier, and what will be true after (i.e., transfer of ownership and data).
), expressed in a variant of separation logic [22, 23]: the “global” and “local” pre/postconditions specify the behaviour of the whole program and of the separate threads; the barrier contract specifies for every thread what must be true before it passes the barrier, and what will be true after (i.e., transfer of ownership and data). -
To offer also a more practical perspective, Fig. 1b and Fig. 1d show excerpts of the same programs, but represented in the input format of VerCors [9, 11], a state-of-the-art deductive verifier. Keywords
 ,
,
 , and
, and
 indicate preconditions, postconditions, and method invariants, respectively. For instance, the pre/postconditions in Fig. 1a and Fig. 1c correspond to lines 5–6 in Fig. 1b and lines 47–48 in Fig. 1d. Furthermore, an assertion of the form
indicate preconditions, postconditions, and method invariants, respectively. For instance, the pre/postconditions in Fig. 1a and Fig. 1c correspond to lines 5–6 in Fig. 1b and lines 47–48 in Fig. 1d. Furthermore, an assertion of the form
 in Fig. 1d indicates the permission to write to variable x (\(q\,{=}\,1\)) or to read from it (\(q\,{<}\,1\)). That is, \(x \mapsto v\) in Fig. 1c is written as the conjunction of
in Fig. 1d indicates the permission to write to variable x (\(q\,{=}\,1\)) or to read from it (\(q\,{<}\,1\)). That is, \(x \mapsto v\) in Fig. 1c is written as the conjunction of
 and
and
 in Fig. 1d.
in Fig. 1d.We organised the code in Fig. 1d differently from the code in Fig. 1c, as VerCors does not support such barriers. Instead we implemented a custom channel to transfer data/ownership between threads (lines 39–40), using VerCors’s locking mechanism. The lock invariant (lines 4–8) specifies what is assumed upon acquiring, and asserted upon releasing, an object’s lock.
 ), expressed in Hoare logic: the precondition (top) specifies what must be true before the program is run; the postcondition (bottom) specifies what will be true after.
), expressed in Hoare logic: the precondition (top) specifies what must be true before the program is run; the postcondition (bottom) specifies what will be true after. ), expressed in a variant of separation logic [
), expressed in a variant of separation logic [ ,
,
 , and
, and
 indicate preconditions, postconditions, and method invariants, respectively. For instance, the pre/postconditions in Fig.
indicate preconditions, postconditions, and method invariants, respectively. For instance, the pre/postconditions in Fig.  in Fig.
in Fig.  and
and
 in Fig.
in Fig. Open Problem. Based on Fig. 1, we make two observations:
-
Fig. 1a and Fig. 1b show that deductive verification of simple sequential programs is simple (i.e., relatively little effort to annotate).
-
However, Fig. 1c and Fig. 1d show that deductive verification of corresponding parallel programs is surprisingly hard (i.e., relatively big effort).
Moreover, while VerCors automatically checks the truth of the annotations (advantage relative to pen-and-paper proofs), manually writing these annotations can be burdensome, as seen by comparing Fig. 1c and Fig. 1d. Specifically, the “local” pre/postconditions of the “left thread” in Fig. 1c are more concise than those for method
 in class
in class
 in Fig. 1d.
in Fig. 1d.
 in class
in class
 in Fig.
in Fig. Thus, in existing approaches, verification of parallel programs is substantially more laborious than that of sequential programs; already in theory, using pen and paper, but—paradoxically—sometimes more so in practice, using tool support. We illustrate these findings with the simplest non-trivial example we could think of. This problem is only aggravated as the complexity of the programs increases.
Essentially, the reason why annotations of parallel programs are complicated, is because synchronisation (of data accesses/mutations) among threads needs to be specified explicitly with permissions. This is already non-trivial when using the high-level barrier in Fig. 1c (writing the barrier contract); getting synchronisation among threads right costs even more intellectual effort when we are forced to implement the custom channels in Fig. 1d using lower-level locks (VerCors does not have such built-in barriers). In the sequential programs in Fig. 1a and Fig. 1b, we need not worry about synchronisation among threads at all; this is the level of simplicity that VeyMont aims to provide (e.g., we added support in VeyMont to auto-generate permissions, so the user needs not write them).
Contributions. Existing methods (e.g., [12, 15, 22, 23, 29, 39, 41, 42]) and tools (e.g. [11, 27, 52]) for deductive verification of parallel programs have this workflow:

However, step 2 requires significant extra, and non-trivial, annotation effort. As demonstrated above, this makes deductive verification of parallel programs much harder than that of sequential programs. To address this issue, we are developing a new method and tool that have an “inverted workflow”:
Step 1: Verify a sequential-ish program. Step 2: Parallelise it.
The idea behind sequential-ish programs is that they have sequential syntax and sequential axiomatic semantics (i.e., proof system), but parallel operational semantics. That is, they look and feel as sequential programs, but they are run as parallel programs. More concretely, the user uses Hoare logic to annotate a sequential-ish program \(P_\text {seq}\)—without worrying about synchronisation—after which a functionally correct, deadlock-free parallel program \(P_\text {par}\) is generated:
-
“Functionally correct” means that if the precondition of \(P_\text {seq}\) holds in the initial state of \(P_\text {par}\), then the postcondition of \(P_\text {seq}\) holds in the final state of \(P_\text {par}\) (i.e., functional correctness of \(P_\text {seq}\) is preserved in \(P_\text {par}\)).
-
“Deadlock free” means that threads do not get stuck waiting on each other, e.g. because two threads are both reading from a channel but expect the other thread to write. No additional manual annotations are needed.
In a previous paper [30], we presented the theoretical foundations of this new method and its “inverted workflow”, targetting coarse-grained parallelism among threads (inspired by distributed systems). In this paper, we present the first deductive verification tool that supports it. The novel contributions are:
-
1.
We designed and implemented VeyMont: it accepts an annotated sequential-ish program as input and offers a functionally correct, deadlock-free parallel program in Java as output. Section 2 and Sect. 3 provide an overview of the workflow and features of VeyMont, by example; Sect. 4 contains details.
-
2.
We evaluated VeyMont along two dimensions. As case studies in applicability, we used VeyMont to verify and parallelise sequential-ish versions of distributed algorithms. As case studies in efficiency, we used VeyMont to produce parallel programs in Java that have comparable performance to third-party reference implementations. Section 5 describes our findings.
The artifact for reproducing the experiments of this paper is available at [51].
Related Work. Existing tools for deductive verification of parallel programs include Frama-C [5], KeY-ABS [20], VeriFast [27], and Gobra [52]. However, these tools verify parallel programs, whereas VeyMont parallelises verified programs.
The “inverted workflow”—verify first, parallelise second—of the method supported by VeyMont is strongly inspired by the methods of choreographic programs [17, 18] and multiparty session types [24] for construction/analysis of deadlock-free distributed systems. The idea behind those methods is: first, to implement/specify distributed systems as choreographies/global types (cf. sequential-ish programs); second, to generate sets of processes/local types (cf. parallel programs with threads) that are formally guaranteed to be deadlock-free. Existing tools that support these methods include Chor [17], Scribble [25] and its dialects [19, 35, 36, 46], Pabble [37], and ParTypes [34]. However, these tools offer deadlock freedom, but not functional correctness; VeyMont offers both.
The literature on parallelising compilers that target fine-grained parallelism among tasks is rich (e.g., loop parallelisation [2, 13, 16, 33, 38, 49]) and goes back to the 1970 s [31]. In contrast, VeyMont is a parallelising verifier that targets coarse-grained parallelism among threads (i.e., whole-program parallelisation). We discuss the integration of fine-grained parallelism into VeyMont in Sect. 6.
2 Overview of VeyMont – The “Inverted Workflow”

“Inverted workflow” using VeyMont
Figure 2 visualises the “inverted workflow” of the method supported by VeyMont.

Example of VeyMont (swapping values)
Step 0: The user writes a sequential-ish program \(P_\text {seq}\) in VeyMont’s input language \(\mu \)PVL (core fragment of VerCors’s language PVL [50]). This is a programming/assertion language that combines object-oriented sequential programs with Hoare logic assertions (similar to sequential Java, enriched with JML [32]).
For instance, Fig. 3a shows a sequential-ish program in \(\upmu \)PVL (cf. Figure 1d). It is split into two parts: fields s1 and s2 of class SeqProgram define the data (lines 1–12), while method run defines the sequence of operations (lines 16–21). The precondition of run is trivial (line 13); the postcondition uses the
 predicate for the old values of s1.v and s2.v at the start of run (lines 14–15). As s1.v and s2.v are initialised to x and y (lines 12–13), which are free program arguments (line 9), all possible initial values of s1.v and s2.v are quantified over.
predicate for the old values of s1.v and s2.v at the start of run (lines 14–15). As s1.v and s2.v are initialised to x and y (lines 12–13), which are free program arguments (line 9), all possible initial values of s1.v and s2.v are quantified over.
Step 1a: VeyMont checks whether or not \(P_\text {seq}\) has a parallelisable (“par’able”) structure. This is a set of syntactic conditions, beyond \(\upmu \)PVL’s grammar, that \(P_\text {seq}\) must meet to be able to generate a grammatical parallel program (step 2).
Step 1b: VeyMont generates annotations for \(P_\text {seq}\)—in addition to those the user has written in step 0—to be able to check that it has parallelisable behaviour (step 1c). This is a set of semantic conditions, encoded as logic assertions, that \(P_\text {seq}\) must meet to guarantee that functional correctness of \(P_\text {seq}\) will be preserved.
Step 1c: VeyMont checks the truth of the annotations in \(P_\text {seq}\), using the state-of-the-art VerCors–Viper–Z3 tool stack [9, 11]. If so, \(P_\text {seq}\) is guaranteed to be functionally correct (the user’s annotations; step 0), functional correctness is guaranteed to be preserved through parallelisation (VeyMont’s annotations; step 1b), and parallelisation does not introduce deadlocks.
Step 2: VeyMont generates a parallel program \(P_\text {par}\) in Java. Step 1a guarantees that \(P_\text {seq}\) is parallelisable; steps 1b–1c and the theoretical foundations of VeyMont guarantee that \(P_\text {par}\) is functionally correct and deadlock-free [30].
For instance, Fig. 3b shows an excerpt of the parallel program generated for the sequential-ish program in Fig. 3a. The idea is to parallelise coarse-grained, at the level of granularity of top-level fields. For every field \(f \in \{\texttt {s1}, \texttt {s2}\}\) of class SeqProgram in Fig. 3a, there is a corresponding subclass fThread of class Thread in Fig. 3b (which defines a Java thread); this subclass alone is responsible for managing the data of f and performing its operations in class ParProgram.
fThread has three fields: the Storage that it is responsible for, and Channels to explicitly transfer data between Storages. Meanwhile, method run of fThread defines the operations that it needs to perform, derived from method run of class SeqProgram: if only f occurs in an assignment in run of SeqProgram, then the assignment is copied into run of fThread, verbatim (e.g., line 17 in Fig. 3a, line 16 in Fig. 3b); alternatively, if also \(g \in \{\texttt {s1}, \texttt {s2}\} \setminus \{f\}\) occurs in the assignment, then an explicit data transfer between Storages is introduced (i.e., fThread is forbidden to use data of gThread directly). Transfers are synchronous: method read blocks until method write is called, and vice versa. In this way, Channels are an alternative synchronisation mechanism to the barrier in Fig. 1c.
Generally, explicit data transfers are the only form of synchronisation that VeyMont needs to introduce to guarantee functional correctness (given step 1c). Specifically, the values of s1.v and s2.v are swapped in run of ParProgram, just as asserted by the postcondition of run of SeqProgram. Finally, we note that ParProgram really is parallel: lines 16 and 25 can be executed simultaneously.
3 Overview of VeyMont – More Features

Another example of VeyMont (tic–tac–toe on an arbitrary \(m\,{\times }\,n\) grid)
To demonstrate some more features of \(\upmu \)PVL/VeyMont, Fig. 4 shows an excerpt of another sequential-ish program in \(\upmu \)PVL. Two threads—implicitly declared in top-level fields p1 and p2 of class SeqProgram—take turns to simulate a game of tic–tac–toe on an arbitrary \(m\,{\times }\,n\) grid (i.e., beyond \(3\,{\times }\,3\), all possible grid sizes are quantified over). Each thread has its own copy of the grid; when a move is made, the active thread informs the passive thread accordingly, so the passive thread can update its grid to match. In the active thread’s turn, the passive thread can “think ahead” to ponder its next move. This makes the program really parallel.
We highlight the noteworthy features, as supported by \(\upmu \)PVL/VeyMont:
-
Turing completeness: Method run of class SeqProgram shows that \(\upmu \)PVL has if/while-statements. This is actually significant: automatically parallelising the conditions of if/while-statements, while guaranteeing functional correctness and deadlock freedom, has been a key challenge in developing VeyMont’s theoretical foundations [30]. It is also a reason why VeyMont needs to check if a sequential-ish program has parallelisable behaviour in steps 1b–1c.
-
Data structures: The fields of class Player show that \(\upmu \)PVL/VeyMont has multidimensional arrays (field grid) and nesting of classes (field move).
-
Trusted code: Methods think and play of class Player show that \(\upmu \)PVL/VeyMont has abstract methods: they have a specification (precondition and postcondition), but no implementation (method body). This allows the user to integrate external trusted code into parallel programs generated by VeyMont. If the trusted code truly implements the specification (proved using VeyMont, or proved using a different tool, or estimated with code reviews, etc.), then functional correctness and deadlock freedom are guaranteed.
An excerpt of the parallelisation generated by VeyMont appears in Sect. A.
4 Design and Implementation
VeyMont has five main components, each of which enables a (sub)step in Fig. 2.
4.1 Parser (Step 1a)

Grammar of \(\upmu \)PVL (types omitted for simplicity)
The first main component of step 1a is a parser for \(\upmu \)PVL. It accepts sequential-ish programs that comply with the grammar in Fig. 5. We split the grammar into an “external fragment” and an “internal fragment”. The difference is that the internal fragment supports more complicated assertions, which the user should never write manually; instead, they are always inserted by VeyMont automatically (step 1b; Sect. 4.4). Regarding the external fragment:
-
Basic notation: Let n range over class names, f over field names, m over method names, and x over variable names. We write \(\tilde{\Box }\) to mean a list of \(\Box \)s.
-
Programs, classes, fields, methods, annotations: A program P consists of a list of classes. A class C consists of a name, a list of fields, and a list of methods, including a constructor that has the same name as the class. A method M consists of a list of annotations (contract), a list of variable names (formal parameters), and an optional list of statements (body). A method without a body is abstract (for external trusted code). An annotation A is a precondition, a postcondition, or a method invariant.
-
Statements, variables, expressions: A statement S is an assertion, an assignment, a method call, a conditional choice, or a conditional loop. A variable X is a variable name, a (qualified) field name, or a (qualified) array cell. An expression E is a variable, a self reference, a null reference, a Boolean expression, a primitive value/operation, an object constructor call/field access/method call, or an array constructor call/cell access. In Boolean expressions, light grey shading indicates that implication and quantification can be used only in annotations, assertions, and loop invariants.
Regarding the internal fragment, let q range over “fractions” between 0 (exclusive) and 1 (inclusive). Effectively, the grammar of Boolean expressions in Fig. 5a is extended to the grammar of permission-based, concurrent separation logic [12, 14] in Fig. 5b to support ownership-like assertions for mutable data. That is,
 indicates that an annotated piece of code has read permission for X (if \(0\,{<}\,q\,{<}\,1\)) or read+write permission (if \(q\,{=}\,1\)); the sum of different fractions for the same variable can never exceed 1. Operators
indicates that an annotated piece of code has read permission for X (if \(0\,{<}\,q\,{<}\,1\)) or read+write permission (if \(q\,{=}\,1\)); the sum of different fractions for the same variable can never exceed 1. Operators
 and
and
 are the standard separating conjunction and separating quantification in separation logic [40, 45]. Regarding notation,
are the standard separating conjunction and separating quantification in separation logic [40, 45]. Regarding notation,
 is equivalent to
is equivalent to
 .
.
Remark 1
\(\upmu \)PVL is also statically typed, but as type checking is not a contribution of this paper, we omit types to keep the presentation of \(\upmu \)PVL concise.
4.2 Linter (Step 1a)
The second main component of step 1a is a linter. It checks if \(P_\text {seq}\) has a parallelisable structure. This is needed for applying the transformation rules in step 2 (Sect. 4.5). The linter checks the following syntactic conditions:
-
1.
\(P_\text {seq}\) has a class SeqProgram that consists of k fields (\(f_1, \ldots , f_k\)), a constructor (\(m_1\)), a main method run (\(m_2\)), and any auxiliary methods (\(m_3, \ldots , m_l\)). All fields are instances of classes; all methods (except the constructor) are parameterless and non-recursive. The constructor initialises all fields.
-
2.
For every assignment in \(m_2, \ldots , m_l\): (a) the left-hand side is of the form \(f_i.X\); (b) at most one field \(f_j\) occurs in the right-hand side. For instance,
 and
and
 and
and
 are fine;
are fine;
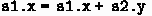 is not.
is not. -
3.
For every if/while-statement in \(m_2, \ldots , m_l\): (a) the condition is of the form
 ; (b) \(f_i\) is the only field that occurs in every \(E_i\). For instance,
; (b) \(f_i\) is the only field that occurs in every \(E_i\). For instance,
 is fine;
is fine;
 is not.
is not. -
4.
For every method call on field \(f_i\) in \(m_2, \ldots , m_l\): \(f_i\) is the only field that occurs in the arguments. For instance,
 is fine;
is fine;
 is not.
is not.
 and
and
 and
and
 are fine;
are fine;
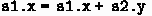 is not.
is not. ; (b)
; (b)  is fine;
is fine;
 is not.
is not. is fine;
is fine;
 is not.
is not.These syntactic conditions constrain only class SeqProgram (i.e., structural parallelisability depends only on SeqProgram). Other classes in \(P_\text {seq}\) are unrestricted.
Remark 2
In our experience (e.g., Sect. 5), conditions 1–4 are straightforward to meet. Notably, many potential violations can be fixed using auxiliary fields. For instance,
 violates condition 2, but it can be rewritten to
violates condition 2, but it can be rewritten to
 , which is functionally equivalent. Similarly,
, which is functionally equivalent. Similarly,
 violates condition 3, but it can be rewritten to:
violates condition 3, but it can be rewritten to:

with
 and
and
 . (In these examples,
. (In these examples,
 and
and
 are fresh.) A complete formal characterisation of the class of sequential-ish programs that can be rewritten in this way, including a mechanical procedure to automatically perform the necessary rewrites to meet the conditions, is still an open problem.
are fresh.) A complete formal characterisation of the class of sequential-ish programs that can be rewritten in this way, including a mechanical procedure to automatically perform the necessary rewrites to meet the conditions, is still an open problem.
Remark 3
The conditions checked by the linter result from our design decision to target coarse-grained parallelism (i.e., every top-level field of SeqProgram is turned into a separate thread in step 2; Sect. 4.5) instead of fine-grained (e.g., loop parallelisation). We discuss their combination in Sect. 6.
4.3 Annotator (Step 1b)
The main component of step 1b is an annotator. It inserts additional annotations into the input program to be able to check if \(P_\text {seq}\) has parallelisable behaviour (step 1c; Sect. 4.4), in terms of two properties:
-
i.
Alias freedom. For every piece of mutable data in \(P_\text {seq}\) (object fields and array cells), VeyMont inserts ownership-like assertions to specify that it cannot be aliased. As a result, the threads of \(P_\text {par}\) will operate on disjoint fragments of memory, so data races are avoided.
Example 1
VeyMont amends the constructor of class Storage in Fig. 3:

VeyMont amends the methods of class SeqProgram, too:

The key idea is to assert write permissions of 1, for all data, everywhere. As the sum of fractional permissions can never exceed 1, there can be no aliases.
-
ii.
Branch unanimity. For every condition of the form
 of if/while-statements in methods \(m_2, \ldots , m_l\) of class SeqProgram, VeyMont inserts an assertion of the form
of if/while-statements in methods \(m_2, \ldots , m_l\) of class SeqProgram, VeyMont inserts an assertion of the form
 (i.e.,
(i.e.,

 ) to specify that, when \(E_1, \ldots , E_k\) are evaluated, they are all equivalent. This implies that the threads of \(P_\text {par}\) all choose the same branch.
) to specify that, when \(E_1, \ldots , E_k\) are evaluated, they are all equivalent. This implies that the threads of \(P_\text {par}\) all choose the same branch.
 of if/while-statements in methods
of if/while-statements in methods  (i.e.,
(i.e.,

 ) to specify that, when
) to specify that, when Example 2
VeyMont amends the while-statement in method run in Fig. 4:

Alias freedom and branch unanimity are sufficient to guarantee that functional correctness is preserved through parallelisation, and that parallelisation does not introduce deadlocks [30]; we clarify the importance of the latter after having discussed parallelisation (step 2; Sect. 4.5).

Summary of transformation rules for statements, by example
4.4 VerCors (Step 1c)
The main component of step 1c is the VerCors–Viper–Z3 tool stack [9, 11] (whose language, PVL, is a superset of \(\upmu \)PVL). To check that \(P_\text {seq}\) is functionally correct and has parallelisable behaviour, it verifies the truth of the user’s annotations (step 0) and VeyMont’s (step 1b).
4.5 Code Generator (Step 2)
The main component of step 2 is a code generator into Java. Non-SeqProgram classes in \(P_\text {seq}\) are copied to \(P_\text {par}\), while SeqProgram is parallelised into classes \(f_1\)Thread, ..., \(f_k\)Thread (each \(f_i\) is a field of SeqProgram), and class ParProgram for forking. The methods of each \(f_i\)Thread are derived from methods \(m_2, \ldots , m_l\) of SeqProgram, by applying the transformations in Fig. 6 to every statement S:
-
If S is an assignment, then due to condition 2 of the linter (Sect. 4.2), S contains the field either of one thread (“store”) or of two threads (“transfer”). In the former case, S is added to the thread; in the latter case, a
 /
/
 on a Channel are added to the threads. Nothing is added to other threads.
on a Channel are added to the threads. Nothing is added to other threads. -
If S is an if/while-statement, then due to condition 3 of the linter, for every thread, S contains a corresponding subcondition. An if/while-statement with exactly that corresponding subcondition is added to every thread.
-
If S is a call, then due to condition 4 of the linter, S contains the field of one thread. S is added to that thread. Nothing is added to other threads.
 /
/
 on a
on a The theoretical foundations of our method ensure that if steps 1a, 1b, and 1c have succeeded, then the transformation rules in Fig. 6 indeed result in a functionally correct, deadlock-free parallel program [30].

Example of a sequential-ish program whose parallelisation can deadlock. VeyMont statically detects this and reports an error instead.
Remark 4
To illustrate the importance of branch unanimity (Sect. 4.3) to guarantee that parallelisation does not introduce deadlocks, Fig. 7 shows a sequential-ish program (i.e., the body of method run of class SeqProgram with top-level fields a and b). This program meets the conditions of the linter, so it has a parallelisable structure; its parallelisation consists of aThread and bThread.
However, whether or not aThread and bThread can deadlock crucially depends on the initial values of
 and
and
 (intentionally omitted from Fig. 7):
(intentionally omitted from Fig. 7):
-
If
 and
and
 are initially equal, then branch unanimity is satisfied (no deadlock): after the first two assignments,
are initially equal, then branch unanimity is satisfied (no deadlock): after the first two assignments,
 and
and
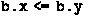 are both true. Subsequently, aThread and bThread both enter their then-branches, so aThread reads and bThread correspondingly writes.
are both true. Subsequently, aThread and bThread both enter their then-branches, so aThread reads and bThread correspondingly writes.Thus, VeyMont (step 1c) reports no error when
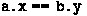 initially.
initially. -
If
 and
and
 are initially unequal, then branch unanimity is violated (deadlock):
are initially unequal, then branch unanimity is violated (deadlock):
 and
and
 are either true and false, or false and true. In the former case, aThread enters its then-branch, but bThread enters its else-branch. At this point, aThread and bThread both expect to read, but neither one of them will write, so they are stuck forever.
are either true and false, or false and true. In the former case, aThread enters its then-branch, but bThread enters its else-branch. At this point, aThread and bThread both expect to read, but neither one of them will write, so they are stuck forever.Thus, VeyMont (step 1c) reports an error when
 initially.
initially.
 and
and
 are initially equal, then branch unanimity is satisfied (no deadlock): after the first two assignments,
are initially equal, then branch unanimity is satisfied (no deadlock): after the first two assignments,
 and
and
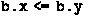 are both true. Subsequently,
are both true. Subsequently, 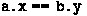 initially.
initially. and
and
 are initially unequal, then branch unanimity is violated (deadlock):
are initially unequal, then branch unanimity is violated (deadlock):
 and
and
 are either true and false, or false and true. In the former case,
are either true and false, or false and true. In the former case,  initially.
initially.We note that VeyMont guarantees deadlock freedom, but not starvation freedom: at any point in time, either all threads have terminated, or at least one thread is still running, modulo exceptions (e.g., division by zero).
5 Evaluation
Applicability. We used VeyMont to verify and parallelise sequential-ish programs for three classical distributed algorithms, for various numbers of threads n:
-
In two-phase commit (2PC) [47], 1 Client and \(n{-}1\) Servers cooperate to fulfil a joint query in a distributed database. First, the Client shares the query with the Servers. Next, the Servers locally run the query and report success/failure back to the Client. Only if all Servers succeeded will the Client instruct them to commit, and otherwise to abort. We successfully verified that the Clients consistently commit, for \(n \in \{3, 5, 8, 12, 17\}\).
-
In anonymous election (probabilistic version of Peleg’s algorithm [43] in the style of Itai and Rodeh [26]), n symmetric threads try to elect a unique leader among them. The algorithm proceeds in rounds. In every round, every thread picks a random number from some fixed range (trusted code) and shares it with every other thread. If there is a unique highest number, then the thread that picked it declares itself the leader; otherwise, another round ensues. We verified that a unique leader is elected upon termination, for \(n \in \{3, 5, 8\}\).
-
In consensus [6], n symmetric threads try to reach agreement about a common value. First, the threads share their locally preferred values. Next, every thread computes the globally preferred value (by majority); this becomes the common value. The complication is that threads can fail: non-deterministically (abstract methods), they can share the wrong locally preferred value and/or compute the wrong globally preferred value. We successfully verified that all threads set the right globally preferred value when the number of failures is at most \(\lfloor n/4 \rfloor \), for \(n \in \{3, 5\}\); this is a classical result.
As a proxy of effort, Fig. 8 shows ratios of numbers of annotations (“spec”) vs. program elements (“impl”). They are below 1; by comparison, Wolf et al. [52] recently report ratios of 2.69–3.16 to deductively verify parallel programs using a tool based on traditional methods. This is first evidence that VeyMont indeed significantly reduces the annotation burden.
Figure 8 also presents the mean run times (of 30 runs) of VeyMont for step 1c and in total (using: Intel i7-8569U CPU with 4 physical/4 virtual cores at 2.8 GHz; 16 GB memory). We can make two main observations. First, the run times are dominated by step 1c (actual verification). For instance, step 1c consumes \(\frac{6.8}{8.0} = 85\%\) of the run time for 2PC (\(n=3\)) and as much as \(\frac{62.2}{63.9} = 97\%\) for 2PC (\(n=17\)). Second, parallelisation itself is relatively cheap. For instance, it takes less than 1.2 seconds for 2PC (\(n=3\)) and less than 1.7 seconds for 2PC (\(n=17\)).
Efficiency. We compared the performance of VeyMont-generated parallel programs in Java with third-party reference implementations. Our aim was to study if the synchronisation mechanism in generated parallel programs is sufficiently lightweight to be competitive. We use different programs than above, as no third-party reference implementations were available for 2PC/election/consensus.

Case studies in applicability: ratio of number of annotations vs. program elements (\(\frac{{\textbf {spec}}}{{\textbf {impl}}}\)) and mean VeyMont run times in seconds (1c, total). Program elements are: class headers, fields, method headers, and statements.
We took the following approach. First, we selected two parallel programs from the CLBG database [1]: binary-trees (parallel tree walk) and k-nucleotide (parallel pattern matching of molecule sequences against a DNA string). Next, for each program: (1) we extracted the data sharing patterns among threads in the CLBG reference implementation and wrote them as a sequential-ish program in \(\upmu \)PVL; (2) we “completed” the sequential-ish program by adding abstract methods to represent all purely sequential computations; (3) we generated parallel programs in Java using VeyMont; (4) we concretised the abstract methods in Java with trusted sequential CLBG code; (5) we ran the CLBG version and the VeyMont version to compare performances, using CLBG-standardised input, with various numbers of threads. We note that we did not prove functional correctness; this is beyond the scope of these performance comparisons.
We ran the resulting executables on three different machines: Cartesius (Intel E5-2690 v3 CPU with 16 physical cores), MacBook (Intel i7-8569U CPU with 4 physical/4 virtual cores), and VM [28] (1 virtual core). Figure 9 show our results as speed-ups of VeyMont versions relative to CLBG versions, computed as \(\frac{\mu _\text {CLBG}}{\mu _\text {VeyMont}}\), where \(\mu _\text {VeyMont}\) and \(\mu _\text {CLBG}\) are the mean run times (of 100 runs) of a VeyMont and a CLBG version; \(\frac{\mu _\text {CLBG}}{\mu _\text {VeyMont}} < 1\) means that a VeyMont version was slower.
We can make two main observations. First, although the VeyMont versions tend to be somewhat slower than the CLBG versions, the slowdown is generally less than \(10\%\). We conjecture that there is a substantial class of programs for which a \(10\%\) slowdown is a fine price for better verifiability of functional correctness and deadlock freedom. Second, different machines exhibit different performance; a deeper study is needed to understand what exactly causes this.

Case studies in efficiency: the x-axis indicates the number of threads; the y-axis indicates the speed-up of VeyMont versions relative to CLBG versions.
6 Future Work
We presented VeyMont: a deductive verification tool that aims to make reasoning about functional correctness and deadlock freedom of parallel programs (relatively complex) as easy as that of sequential programs (relatively simple).
Our most-wanted feature for VeyMont is to support parametrisation (e.g., election generically for n threads instead of specifically for \(3, 5, 8, \ldots \)). However, parametrised verification is known to be undecidable in general [3, 48]. The study of this topic (e.g., identification of decidable fragments) has become a research area of its own over the past decade; the book by Bloem et al. gives an extensive overview [7, 8]. Thus, an extension of VeyMont to support parametrisation is highly non-trivial. It is our main direction for future work.
Other future work pertains to a relaxation of alias freedom and branch unanimity in the theoretical foundations of VeyMont [30]. Such a relaxation allows VeyMont to be more flexible about read/write permissions (e.g., improve support for read-only shared arrays), but maintaining the same strong guarantees.
Inspired by methods for distributed systems, VeyMont targets coarse-grained parallelism among threads (i.e., whole-program parallelisation) instead of fine-grained parallelism among tasks (e.g., loop parallelisation). We are keen to explore the combination of both approaches. A first step would be to mix VeyMont with the VerCors-based work of Blom et al. [10] on verification of loop parallelisation. Beyond that, it is interesting to extend VeyMont with complementary techniques. For instance, Raza et al. [44] developed a technique to infer dependencies among statements in sequential programs to allow their parallel execution (like us), but at the level of tasks (unlike us). Their technique and ours have different strengths: we can split the conditions of if/while-statements across separate threads, which Raza et al. cannot (they assume indivisible conditions); conversely, Raza et al. can parallelise recursive divide-and-conquer algorithms in separate tasks, which we cannot (we assume fixed numbers of processes).
Finally, more on the engineering side, we are also keen to investigate to what extent alternative deductive verification back-ends instead of VerCors can offer value both to users (e.g., faster verification) and to researchers (i.e., in principle, any deductive verification tool for sequential programs can be combined with VeyMont’s method to reason about functional correctness of parallel programs).
References
https://benchmarksgame-team.pages.debian.net/benchmarksgame/index.html
Aiken, A., Nicolau, A.: Optimal loop parallelization. In: PLDI, pp. 308–317. ACM (1988)
Apt, K.R., Kozen, D.: Limits for automatic verification of finite-state concurrent systems. Inf. Process. Lett. 22(6), 307–309 (1986)
Apt, K.R., Olderog, E.-R.: Fifty years of Hoare’s logic. Formal Aspects Comput. 31(6), 751–807 (2019). https://doi.org/10.1007/s00165-019-00501-3
Baudin, P., et al.: The dogged pursuit of bug-free C programs: the Frama-C software analysis platform. Commun. ACM 64(8), 56–68 (2021)
Berman, P., Garay, J.A., Perry, K.J.: Towards optimal distributed consensus (extended abstract). In: FOCS, pp. 410–415. IEEE Computer Society (1989)
Bloem, R., et al.: Decidability of Parameterized Verification. Synthesis Lectures on Distributed Computing Theory, Morgan & Claypool Publishers, San Rafael (2015)
Bloem, R., et al.: Decidability in parameterized verification. SIGACT News 47(2), 53–64 (2016)
Blom, S., Darabi, S., Huisman, M., Oortwijn, W.: The VerCors tool set: verification of parallel and concurrent software. In: Polikarpova, N., Schneider, S. (eds.) IFM 2017. LNCS, vol. 10510, pp. 102–110. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-66845-1_7
Blom, S., Darabi, S., Huisman, M., Safari, M.: Correct program parallelisations. Int. J. Softw. Tools Technol. Transf. 23(5), 741–763 (2021). https://doi.org/10.1007/s10009-020-00601-z
Blom, S., Huisman, M.: The VerCors tool for verification of concurrent programs. In: Jones, C., Pihlajasaari, P., Sun, J. (eds.) FM 2014. LNCS, vol. 8442, pp. 127–131. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-06410-9_9
Bornat, R., Calcagno, C., O’Hearn, P., Parkinson, M.: Permission accounting in separation logic. In: POPL, pp. 259–270. ACM (2005)
Boulet, P., Darte, A., Silber, G.-A., Vivien, F.: Loop parallelization algorithms: from parallelism extraction to code generation. Parallel Comput. 24(3–4), 421–444 (1998)
Boyland, J.: Checking interference with fractional permissions. In: Cousot, R. (ed.) SAS 2003. LNCS, vol. 2694, pp. 55–72. Springer, Heidelberg (2003). https://doi.org/10.1007/3-540-44898-5_4
Brookes, S.: A semantics for concurrent separation logic. Theor. Comput. Sci. 375(1–3), 227–270 (2007)
Burke, M., Cytron, R.: Interprocedural dependence analysis and parallelization. In: SIGPLAN Symposium on Compiler Construction, pp. 162–175. ACM (1986)
Carbone, M., Montesi, F.: Deadlock-freedom-by-design: multiparty asynchronous global programming. In: POPL, pp. 263–274. ACM (2013)
Carbone, M., Montesi, F., Schürmann, C.: Choreographies, logically. Distributed Comput. 31(1), 51–67 (2018)
Castro, D., Hu, R., Jongmans, S.S., Ng, N., Yoshida, N.: Distributed programming using role-parametric session types in Go: statically-typed endpoint APIs for dynamically-instantiated communication structures. PACMPL, 3(POPL), 29:1–29:30 (2019)
Din, C.C., Tapia Tarifa, S.L., Hähnle, R., Johnsen, E.B.: History-based specification and verification of scalable concurrent and distributed systems. In: Butler, M., Conchon, S., Zaïdi, F. (eds.) ICFEM 2015. LNCS, vol. 9407, pp. 217–233. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25423-4_14
Hoare, C.A.R.: An axiomatic basis for computer programming. Commun. ACM 12(10), 576–580 (1969)
Hobor, A., Gherghina, C.: Barriers in concurrent separation logic. In: Barthe, G. (ed.) ESOP 2011. LNCS, vol. 6602, pp. 276–296. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-19718-5_15
Hobor, A., Gherghina, C.: Barriers in concurrent separation logic: now with tool support! Log. Methods Comput. Sci., 8(2) (2012)
Honda, K., Yoshida, N., Carbone, M.: Multiparty asynchronous session types. In: POPL, pp. 273–284. ACM (2008)
Hu, R., Yoshida, N.: Hybrid session verification through endpoint API generation. In: Stevens, P., Wasowski, A. (eds.) FASE 2016. LNCS, vol. 9633, pp. 401–418. Springer, Heidelberg (2016). https://doi.org/10.1007/978-3-662-49665-7_24
Itai, A., Rodeh, M.: Symmetry breaking in distributive networks. In: FOCS, pp. 150–158. IEEE Computer Society (1981)
Jacobs, B., Smans, J., Philippaerts, P., Vogels, F., Penninckx, W., Piessens, F.: VeriFast: a powerful, sound, predictable, fast verifier for C and Java. In: Bobaru, M., Havelund, K., Holzmann, G.J., Joshi, R. (eds.) NFM 2011. LNCS, vol. 6617, pp. 41–55. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-20398-5_4
Jacobs, S., Reynolds, A.: TACAS 22 Artifact Evaluation VM - Ubuntu 20.04 LTS (2021). https://doi.org/10.5281/zenodo.5562597
Jones, C.B.: Tentative steps toward a development method for interfering programs. ACM Trans. Program. Lang. Syst. 5(4), 596–619 (1983)
Jongmans, S., van den Bos, P.: A predicate transformer for choreographies. In: ESOP 2022. LNCS, vol. 13240, pp. 520–547. Springer, Cham (2022). https://doi.org/10.1007/978-3-030-99336-8_19
Lamport, L.: The parallel execution of DO loops. Commun. ACM 17(2), 83–93 (1974)
Leavens, G.T., Baker, A.L., Ruby, C.: Preliminary design of JML: a behavioral interface specification language for Java. ACM SIGSOFT Softw. Eng. Notes 31(3), 1–38 (2006)
Lim, A.W., Lam, M.S.: Maximizing parallelism and minimizing synchronization with affine transforms. In: POPL, pp. 201–214. ACM Press (1997)
López, H.A., et al.: Protocol-based verification of message-passing parallel programs. In: OOPSLA, pp. 280–298. ACM (2015)
Neykova, R., Hu, R., Yoshida, N., Abdeljallal, F.: A session type provider: compile-time API generation of distributed protocols with refinements in F#. In: CC, pp. 128–138. ACM (2018)
Neykova, R., Yoshida, N.: Let it recover: multiparty protocol-induced recovery. In: CC, pp. 98–108. ACM (2017)
Ng, N., Yoshida, N.: Pabble: parameterised scribble. Serv. Oriented Comput. Appl. 9(3–4), 269–284 (2015)
Oancea, C.E., Rauchwerger, L.: Logical inference techniques for loop parallelization. In PLDI, pp. 509–520. ACM (2012)
O’Hearn, P.W.: Resources, concurrency, and local reasoning. Theor. Comput. Sci. 375(1–3), 271–307 (2007)
O’Hearn, P.: Separation logic. Commun. ACM 62(2), 86–95 (2019)
Owicki, S.S., Gries, D.: An axiomatic proof technique for parallel programs I. Acta Informatica 6, 319–340 (1976)
Owicki, S.S., Gries, D.: Verifying properties of parallel programs: an axiomatic approach. Commun. ACM 19(5), 279–285 (1976)
Peleg, D.: Time-optimal leader election in general networks. J. Parallel Distrib. Comput. 8(1), 96–99 (1990)
Raza, M., Calcagno, C., Gardner, P.: Automatic parallelization with separation logic. In: Castagna, G. (ed.) ESOP 2009. LNCS, vol. 5502, pp. 348–362. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-00590-9_25
Reynolds, J.C.: Separation logic: a logic for shared mutable data structures. In: LICS, pp. 55–74. IEEE Computer Society (2002)
Scalas, A., Dardha, O., Hu, R., Yoshida, N.: A linear decomposition of multiparty sessions for safe distributed programming. In: ECOOP, volume 74 of LIPIcs, pp. 24:1–24:31. Schloss Dagstuhl - Leibniz-Zentrum fuer Informatik (2017)
Skeen, D.: Nonblocking commit protocols. In: SIGMOD Conference, pp. 133–142. ACM Press (1981)
Suzuki, I.: Proving properties of a ring of finite-state machines. Inf. Process. Lett. 28(4), 213–214 (1988)
Tournavitis, G., Wang, Z., Franke, B., O’Boyle, M.F.: Towards a holistic approach to auto-parallelization: integrating profile-driven parallelism detection and machine-learning based mapping. In: PLDI, pp. 177–187. ACM (2009)
VerCors Wiki. https://github.com/utwente-fmt/vercors/wiki
VeyMont Artifact. https://doi.org/10.5281/zenodo.7410640
Wolf, F.A., Arquint, L., Clochard, M., Oortwijn, W., Pereira, J.C., Müller, P.: Gobra: modular specification and verification of Go programs. In: Silva, A., Leino, K.R.M. (eds.) CAV 2021. LNCS, vol. 12759, pp. 367–379. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-81685-8_17
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
A Appendix: Parallelisation of Tic-Tac-Toe
A Appendix: Parallelisation of Tic-Tac-Toe
The following listing shows the two threads for top-level fields p1 and p2 in the parallelisation of the sequential-ish program in Fig. 4, generated by VeyMont (functionally correct and deadlock-free). We note that p1Thread and p2Thread have “opposite” behaviour in their methods turn1 and turn2.

The remaining classes that are part of the parallelisation are:
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
van den Bos, P., Jongmans, SS. (2023). VeyMont: Parallelising Verified Programs Instead of Verifying Parallel Programs. In: Chechik, M., Katoen, JP., Leucker, M. (eds) Formal Methods. FM 2023. Lecture Notes in Computer Science, vol 14000. Springer, Cham. https://doi.org/10.1007/978-3-031-27481-7_19
Download citation
DOI: https://doi.org/10.1007/978-3-031-27481-7_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-27480-0
Online ISBN: 978-3-031-27481-7
eBook Packages: Computer ScienceComputer Science (R0)